はじめに
先日、AWS Amplify AI Kitを使用して、簡単なAIアプリを構築してみました。
他にどんなことできるのかなーとドキュメントを見ていると、Amazon Bedrockのナレッジベースも活用できそうなので、今回試してみました。
概要
AWS Amplify AI Kitって?
AWS Amplifyは、開発者がフルスタックアプリケーションを効率的に開発するための統合プラットフォームとなるサービスです。
AWS Amplify AI kitは、AWS Amplifyが提供する機能の1つで、Amazon Bedrockという生成AIサービスを活用し、Webアプリケーションを簡単に構築するための機能を提供します。
Amazon Bedrockのナレッジベースって?
Amazon Bedrockは、様々なAIモデルをAPI経由で利用できるマネージドサービスです。

引用元:https://pages.awscloud.com/rs/112-TZM-766/images/AWS-Black-Belt_2024_Amazon-Bedrock-Overview_v1.pdf
中でもBedrockは、ナレッジベースという機能を提供しています。
一般的なナレッジベースは、知識、経験、ノウハウなどをまとめたデータベースのようなものを指し、Bedorokから見ればデータソースという扱いになります。
Amazon Bedrockの機能であるナレッジベースは、例えばデータソースに保存された社内文書といったアクセスが限られたプライベートなデータをAIに提供することで、AIはよりカスタマイズされた応答を生成することができるようになります。
これによりRAGのような特定の知識に強いAIアプリを簡単に構築できるようになります。
つまり?
AWS Amplify AI kitとAmazon Bedrockのナレッジベースを活用すれば、サクッとRAGアプリが作れるのではないか。ということです。
やってみた
実際にAWS Amplify AI kitを使用してAmazon Bedrockのナレッジベースに接続してみます。
最終的に以下のような構成になります。

1. ナレッジベースのデータソースを構築する

1.1. Amazon S3のバケットを新規作成する
1. マネジメントコンソールを開いて、Amazon S3の画面を開きます。
2. 画面右から「バケットを作成」ボタンを押します。
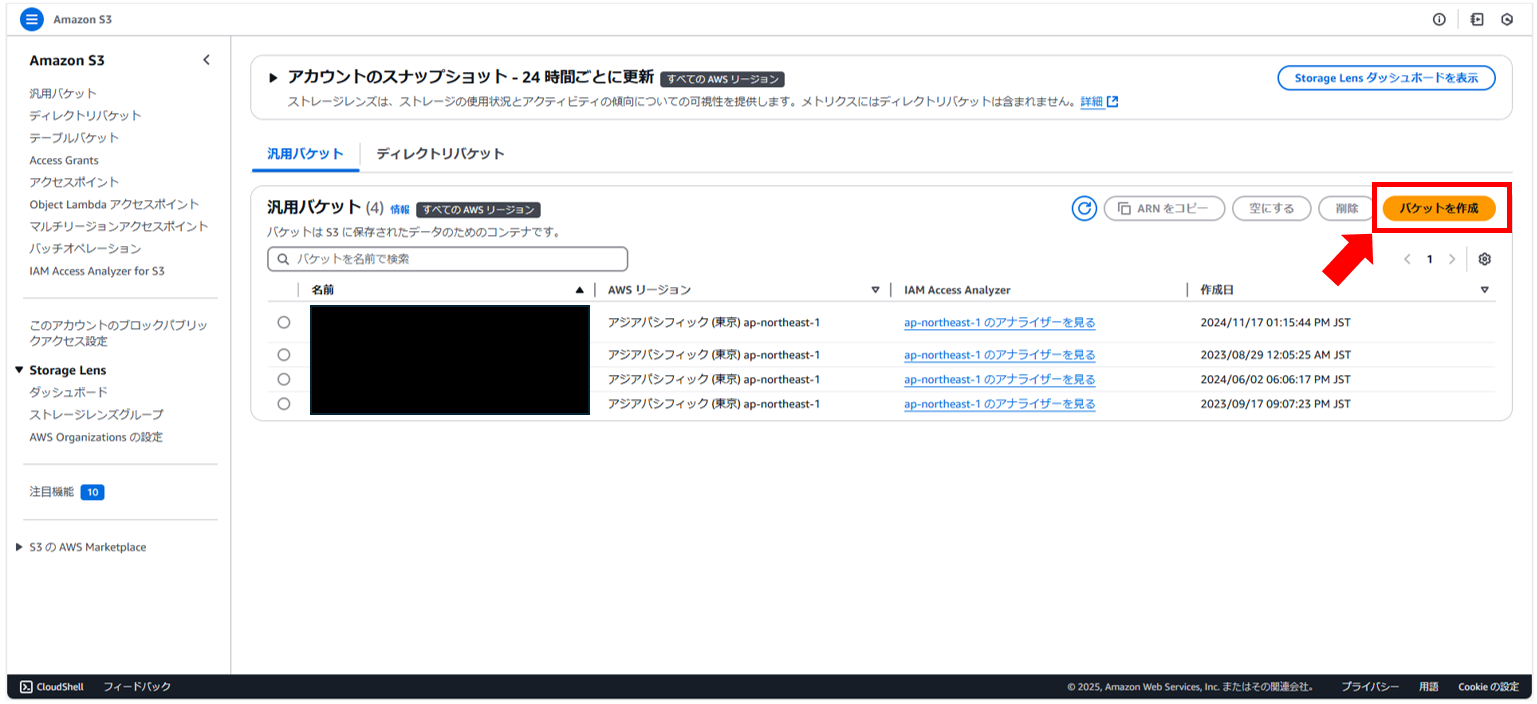
3. 任意のバケット名を入力して、画面右下の「バケットを作成」ボタンを押します。

4. バケットが作成されたことを確認し、作成したバケット名のリンクを押します。

1.2. バケットにサンプルファイルを格納する
- 「アップロード」ボタンからファイルをアップロードします。

今回は、私のプロフィールを記載した、以下のようなテキストファイルを用意しました。
一般的な内容をナレッジベースにしても、生成AIがそれを参考にしたか判断しにくいので、ナレッジベースを参考にしないとわからない情報を格納しました。
好きな食べ物:牡蠣
嫌いな食べ物:ゴーヤ
好きなAWSサービス:最近はAWS Amplify
2. アップロードが正常に完了したことを確認します。

これでナレッジベースの構築に必要なデータソースの準備は完了です。
2. ナレッジベースを構築する

2.1 Amazon Bedrock ナレッジベースを作成する
1. マネージドコンソールから「Amazon Bedrock」の画面を開きます。
2. 画面左のメニューからオーケストレーションの中の「ナレッジベース」を押します。

3. 「ナレッジベースを作成」ボタンを押します。

4. 「Knowledge Base with vector store」を選択します。

5. 「ナレッジベースの詳細の入力」ページは、初期値のままにして、下までスクロールします。


6. 「次へ」ボタンを押します。

7. 「データソースを設定」ページは、先ほど作成したS3バケットを指定する必要があるので、「S3を参照」ボタンを押します。
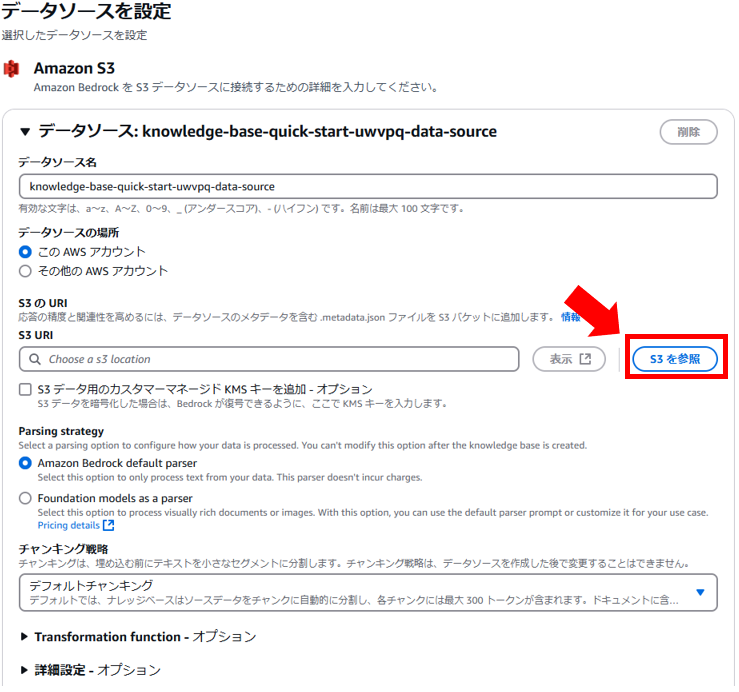
8. 「S3でアーカイブを選択」ダイアログが表示されるので、先ほど作成したバケットを選択して、右下の「選択」ボタンを押します。
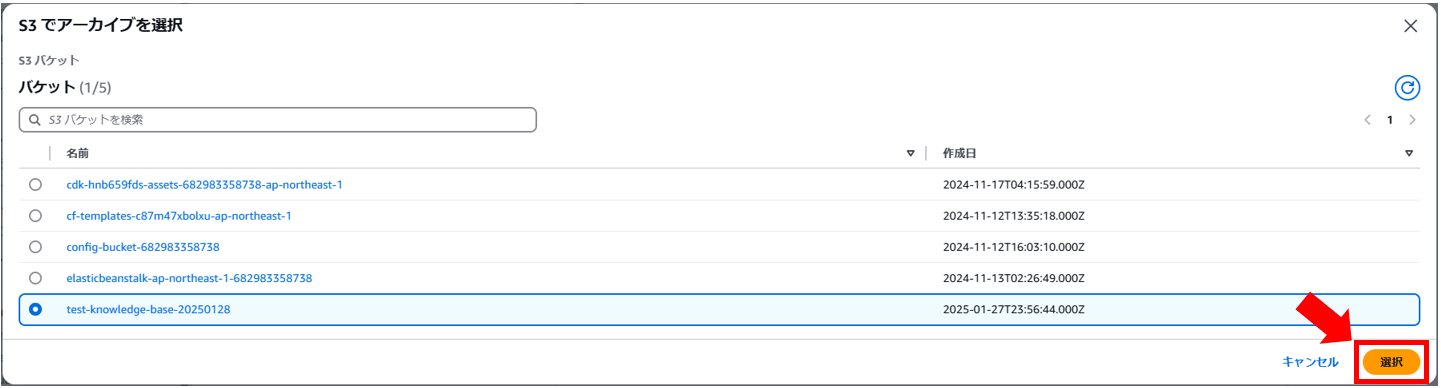
9. ダイアログが閉じるので、画面下部の「次へ」ボタンを押します。

10. 「埋め込みモデルを選択し、ベクトルストアを設定する」ページは、「Embed Multilingual v3」を選択します。

11. 「次へ」ボタンを押します。

12. 最後に「確認して作成」ページでは、設定内容を確認の上、画面下部の「ナレッジベースを作成」ボタン押します。


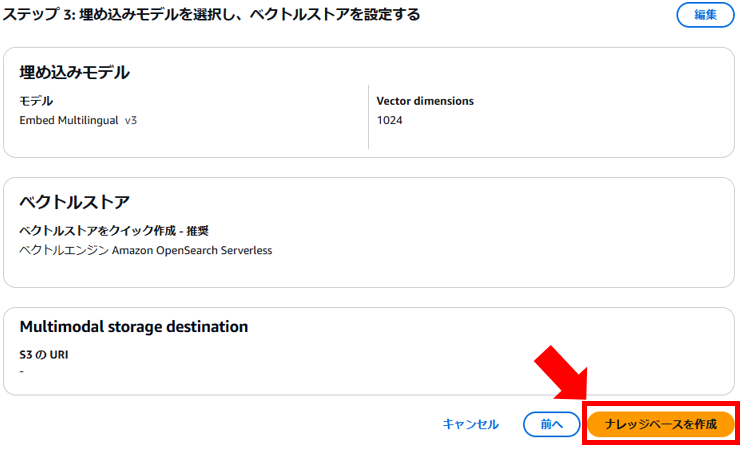
これでナレッジベースを作成されました。

!!後ほど、AWS Amplifyの実装時に「ナレッジベースID」を使用します。どこかに保存しておいてください。

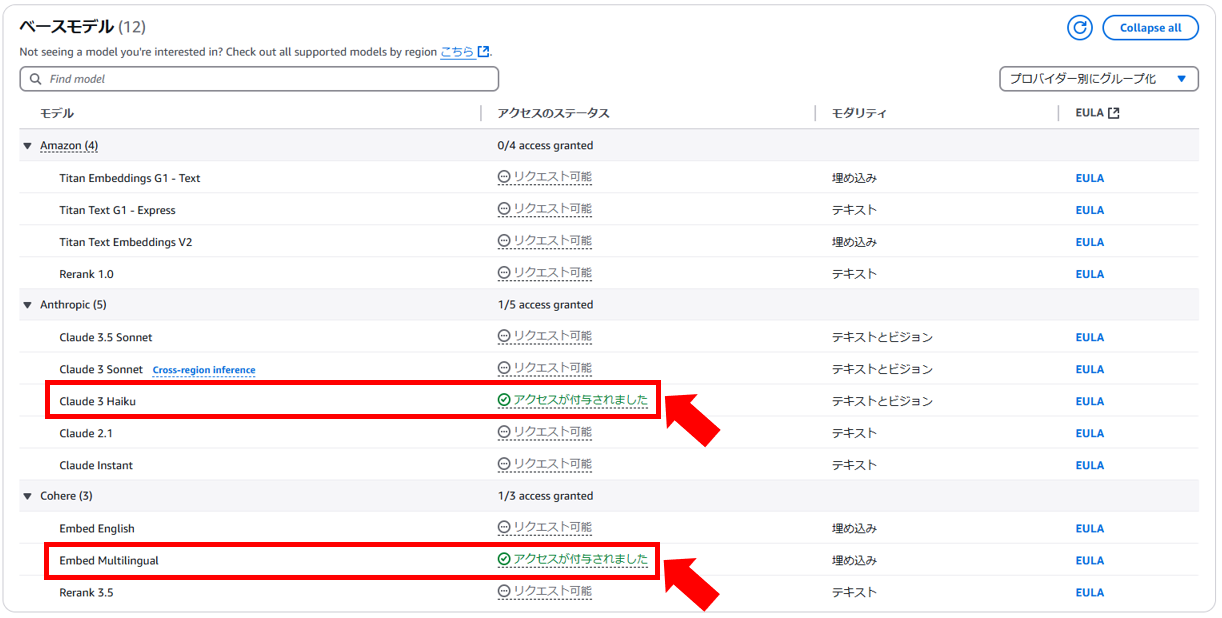
2.2. Amazon Bedrockのモデルアクセスを有効にする
1. 下記の2つのモデルは構築するアプリで使用するため、アクセス許可を申請しておきます。
- Claude 3 Haiku
- Embed Multilingual
2. ステータスが「アクセスが付与されました」の状態になっていることを確認してください。
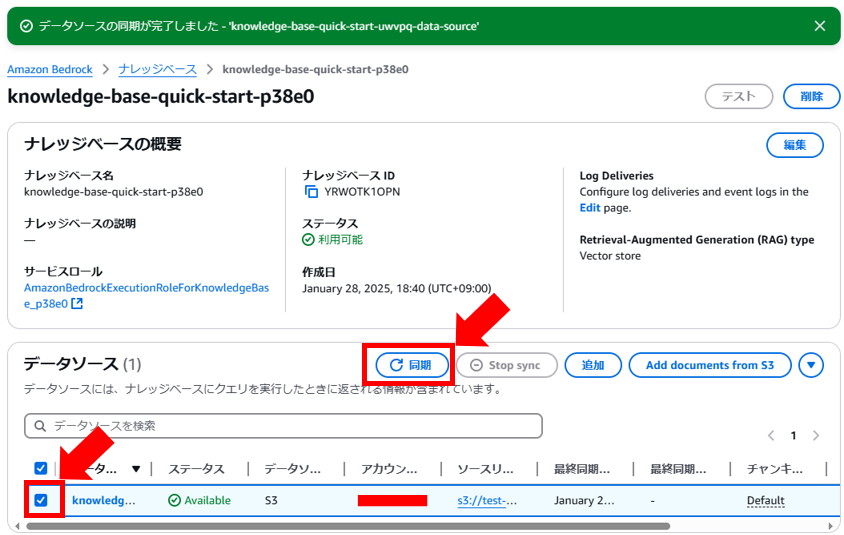
2.3. データソースとナレッジベースを同期する
1. 作成したナレッジベースのデータソースを選択し、「同期」ボタンを押します。
3. 環境を構築する

3.1. フロントエンドの環境を構築する
1. フロントエンドの環境として、Viteというツールを使用し、 React と TypeScript のプロジェクトを作成します。
npm create vite@latest
√ Project name: ... ai_kit_knowledge_base_app
√ Select a framework: » React
√ Select a variant: » TypeScript
2. 次にプロジェクトディレクトリへ移動し、必要な依存パッケージをインストールします。
cd <プロジェクト名>
npm install
3. ローカル環境でアプリケーションを起動してみます。
npm run dev
4. ブラウザでhttp://localhost:5173/ にアクセスし、以下の画面が表示されれば準備完了です。

3.2. バックエンドの環境を構築する
1. バックエンドの環境として、AWS Amplifyのプロジェクトを作成します。
npm create amplify@latest
? Where should we create your project? amplify_dir
2. 作成したプロジェクトをサンドボックス環境にデプロイします。
cd .\amplify_dir\
npx ampx sandbox
5. バックエンドを実装する

5.1. Conversationを実装する
AWS Amplify AI kitでは、Amazon Bedrockとやり取りするため、以下2種類のAI機能を提供します。今回は、Conversationを使用します。
| AI機能 | 概要 | ユースケース |
|---|---|---|
| Conversation |
(こっちを実装します!) リアルタイムに複数回の会話のやり取り(マルチターン)を考慮したAI機能を提供します |
英会話のレッスンなど対話型のアプリ |
| Generation | 指定した定義に従って構造化されたデータを同期的に生成するAI機能を提供します | 文章の要約など |
1. ./amplify/data/resourece.tsを以下のように修正します。
import { type ClientSchema, a, defineData } from '@aws-amplify/backend';
const schema = a.schema({
+ chat: a.conversation({
+ aiModel: a.ai.model("Claude 3 Haiku"),
+ systemPrompt: `You are a helpful assistant.`,
+ .authorization((allow) => allow.owner()),
});
export type Schema = ClientSchema<typeof schema>;
export const data = defineData({
schema,
authorizationModes: {
+ defaultAuthorizationMode: 'userPool',
},
});
5.2. ツールの設定
Amzaon Bedrcokには、Tool useという機能があります。AWS Amplify AI kitからでも使用することができ、ナレッジベースを活用するために本機能を利用します。
~Tool useとは~
Tool useは、AIモデルにメッセージと一緒に処理を渡すことで、AIモデルの能力を拡張する機能です。
- BedrockへのConverse APIリクエスト時に、メッセージと合わせてツールの定義を渡します
- AIモデルがメッセージを応答するためにツールが必要か判断し、
必要ならConver APIのレスポンスでツールのリクエスト情報を返します - 受け取ったリクエスト情報をConversAPI に設定し、
再度Converse APIをリクエストします - AIモデルはツールを駆使してメッセージの応答を生成し、生成結果を返します
~AWS Amplify AI kitからTool useを使用するには~
Amplify AI Kitでツールを定義する方法は以下の通りです。
今回は、ナレッジベースに対してHTTPでクエリを投げるため、クエリツールを使用します。
| ツールの種類 | 概要 |
|---|---|
| モデルツール | a.moded()で定義したDynamoDBのレコード一覧をツールとして使用します |
| クエリツール |
(こっちを実装します!) a.query()で定義したAppSyncのAPI結果をツールとして使用します |
| Lambdaツール | Lambdaの実行結果をツールとして使用します |
1. ./amplify/data/resourece.tsを以下のように修正します。
import { type ClientSchema, a, defineData } from '@aws-amplify/backend';
const schema = a.schema({
chat: a.conversation({
aiModel: a.ai.model("Claude 3 Haiku"),
systemPrompt: `You are a helpful assistant.`,
+ tools: [
+ a.ai.dataTool({
+ name: 'searchDocumentation',
+ description: 'Performs a similarity search over the documentation for ...',
+ query: a.ref('knowledgeBase'),
+ }),
+ ]
})
.authorization((allow) => allow.owner()),
});
export type Schema = ClientSchema<typeof schema>;
export const data = defineData({
schema,
authorizationModes: {
defaultAuthorizationMode: 'userPool',
},
});
5.3. カスタムクエリの作成
ナレッジベースを使用しない場合は、AWS Amplify AI kitが自動作成するクエリで事足りるのですが、ナレッジベースへのアクセスが必要となる場合は、カスタムクエリが必要となります。
今回は、AppSyncのクエリ経由でナレッジベースにアクセスするため、カスタムクエリを作成します。
~ AppSyncとは~
AWS Amplify では、クライアントとバックエンドの通信にAWS AppSyncが用いられます。
AWS AppSyncとは、GraphQL APIが容易に構築できるマネージドサービスです。

引用元:https://aws.amazon.com/jp/builders-flash/202111/awsgeek-appsync/
1. ./amplify/data/resourece.tsを以下のように修正して、カスタムクエリの定義を追加します。
※handlerに設定しているdataSourceとentryは、この後の手順で作成します。
import { type ClientSchema, a, defineData } from '@aws-amplify/backend';
const schema = a.schema({
+ knowledgeBase: a
+ .query()
+ .arguments({ input: a.string() })
+ .handler(
+ a.handler.custom({
+ dataSource: "KnowledgeBaseDataSource",
+ entry: "./resolvers/kbResolver.js",
+ }),
+ )
+ .returns(a.string())
+ .authorization((allow) => allow.authenticated()),
chat: a.conversation({
aiModel: a.ai.model("Claude 3 Haiku"),
systemPrompt: `You are a helpful assistant.`,
tools: [
a.ai.dataTool({
name: 'searchDocumentation',
description: 'Performs a similarity search over the documentation for ...',
query: a.ref('knowledgeBase'),
}),
]
})
.authorization((allow) => allow.owner()),
});
export type Schema = ClientSchema<typeof schema>;
export const data = defineData({
schema,
authorizationModes: {
defaultAuthorizationMode: 'userPool',
},
});
5.4. カスタムリゾルバーの実装
AppSyncのリゾルバーは、クライアントからのリクエストを接続先のデータソース向けに変換するロジックです。
request関数は、データソースの呼び出し前に呼ばれるロジックです。
response関数は、データソースの呼び出し後に呼ばれるロジックです。
今回は、Amazon Bedrockのナレッジベースにアクセスするため、RetrieveAPIにリクエストする実装を行います。

1. /amplify/data/resolvers/kbResolver.jsを新規作成します。
+ export function request(ctx) {
+ const { input } = ctx.args;
+ return {
+ resourcePath: "/knowledgebases/[KNOWLEDGE_BASE_ID]/retrieve",
+ method: "POST",
+ params: {
+ headers: {
+ "Content-Type": "application/json",
+ },
+ body: JSON.stringify({
+ retrievalQuery: {
+ text: input,
+ },
+ }),
+ },
+ };
+ }
+
+ export function response(ctx) {
+ return JSON.stringify(ctx.result.body);
+ }
ソースコード上の[KNOWLEDGE_BASE_ID]は、先ほどメモしたご自身の「ナレッジベースID」に書き換えてください。
5.5. データソースの設定
HTTPデータソースを使用することで、外部HTTPエンドポイント(=今回はナレッジベース)へ接続するように設定します。
1. /amplify/backend.tsを以下のように修正します。
import { defineBackend } from '@aws-amplify/backend';
import { auth } from './auth/resource';
import { data } from './data/resource';
+ import { PolicyStatement } from 'aws-cdk-lib/aws-iam';
defineBackend({
auth,
data,
});
+ const KnowledgeBaseDataSource =
+ backend.data.resources.graphqlApi.addHttpDataSource(
+ "KnowledgeBaseDataSource",
+ `https://bedrock-agent-runtime.ap-northeast-1.amazonaws.com`,
+ {
+ authorizationConfig: {
+ signingRegion: "ap-northeast-1",
+ signingServiceName: "bedrock",
+ },
+ },
+ );
+KnowledgeBaseDataSource.grantPrincipal.addToPrincipalPolicy(
+ new PolicyStatement({
+ resources: [
+ `arn:aws:bedrock:ap-northeast-1:[account ID]:knowledge-base/[knowledge base ID]`
+ ],
+ actions: ["bedrock:Retrieve"],
+ }),
+ );
ソースコード上の[KNOWLEDGE_BASE_ID]は、先ほどメモしたご自身の「ナレッジベースID」に書き換えてください。他、[account ID]も書き換えてください。
Amazon Bedrockのエンドポイントは、以下を指定してください。
https://bedrock-agent-runtime.ap-northeast-1.amazonaws.comを指定してください。
公式ドキュメントのサンプルコード上では、以下が指定されていましたが、動きませんでした (´;ω;`)
https://bedrock-runtime.ap-northeast-1.amazonaws.com,
カスタムクエリでは、AmazonBedrockのRetrieveAPIを呼ぶため、bedrock-agent-runtimeのエンドポイントを指定する必要があります。
6. フロントエンドのUI実装

UI関しては過去の実装を使いまわします。こちらの「2.4. フロントエンドの設定」を参照ください。
最終的に以下のような画面が表示されます。


7. 動かしてみる
実際にナレッジベース版のAIアプリを動かしてみます。
ナレッジベースが上手く利用できていれば、私の好きな食べ物を答えられるはずです。

お、期待通り答えてくれました。うまくナレッジベースを参照できているようです。
8. 後始末
- Ctrl + Cキー で Amplify Sandboxを終了します。
- その後、以下のコマンドでAWS上のリソースを削除します。
npx ampx sandbox delete
まとめ
ポジティブ
- フロントエンドとバックエンドをつなぐロジックを記述しなくても済むため、素早くアプリを作成できる点はやはり魅力的だなと思いました。
- Bedrockのナレッジベースを初めて使ってみましたが、さまざまな可能性を感じました。実業務でもチェックシートが大量にあるものの活用できていない…といった課題があり、そうした眠っている情報を有効活用するアプリを今後作ってみたい!と検討中...
ネガティブ
- Amazon BedrockのナレッジベースをAmplify上から構築できるようになれば、さらに便利になると感じました。
- また、途中でエンドポイントの設定に苦戦しました。知識があればすぐに理解できる話とは思うのですが、Amplifyによって抽象化されており、内部の仕組みを十分に理解していないと詰まってしまう場面がありました。デバッグも難しく、結果的にAppSyncの基礎から学び直すことになりました...
改めて、Amplifyを活用する上でも、裏で動くAWSサービスの知識は不可欠だと痛感しました。今後も引き続き学習を進めていきたいと思います...
参考
AWS Amplify AI kitについては、公式ドキュメントを参考にしました。
またAmazon Bedrock ナレッジベースについては、下記の書籍を参考にさせてもらいました。