はじめに
早いものでAWS Summit Japan 2025から既に1週間が経過しようとしていますね。
今回は、2日目のCmunity Stageで下記の発表を拝見して、便利そうだなーと思っていたStrands Agentsを試したいと思います。
作ったアプリの概要
アプリの画面
アプリは、サイドバーと地図の画面で構成され、下記のような流れで操作して画像を生成します。
- 地図から座標を指定する
- 生成したい画像の情報を入力する
- 画像スタイル (リアル、油絵など)
- 時間帯 (夕方など)
- 天気 (晴れ、雪など)
- 補足情報 (何かあれば)
- 画像の保存先を指定する
- 画像生成を実行する

※待機時間はカットしているので、待ち時間を含めると3分ほどかかります...
アプリ自体はローカル実行していて、画像もローカルのフォルダに保存しています。
ちなみに札幌 大通りの座標(43.058855, 141.352329)をしてして生成された画像は以下になります。

同じ位置をGoogle Mpaの衛星写真で見てみると...
全然違いますね!札幌の大通にテレビ塔は実際にあるのですが、指定した位置からは見えないはず...そして雰囲気がかなり昔なような...
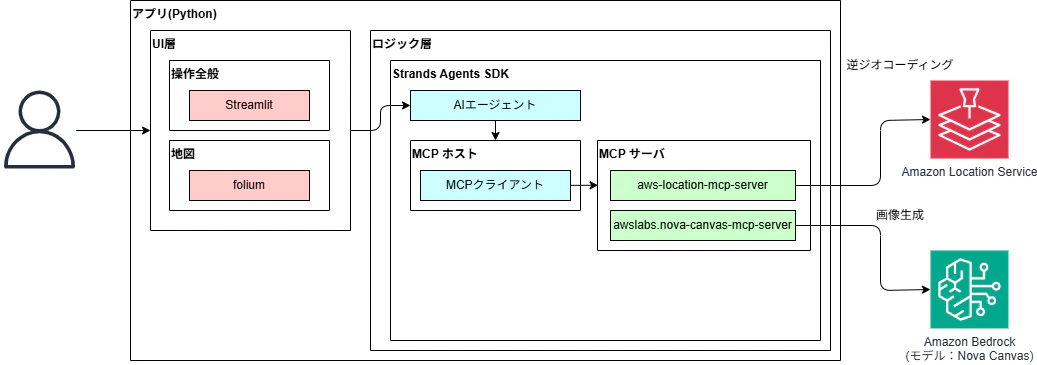
アプリの構成
アプリの構成は下記になります。
本実装については「VibeCoding」→「調べる」→「VibeCoding」→「調べる」のような流れで行っています。
UI層
アプリのUI周りはStreamlitを使ってます。
また地図の表示にはfoliumを使っています。
(Streamlitにも一応地図を表示する機能は合ったのですが、クリック操作が出来なかったのでfoliumを使用しました)
今回は、Strands Agentsが主題なので、UI周りの話は割愛したいと思います。
ロジック層
ロジックは、Strands AgentsでAIエージェントを構築し、その裏でMCPを使って画像を生成しています。
具体的には、UIで指定した座標をaws-location-mcp-serverで逆ジオコーディングして周辺の情報を収集して、そのあとnova-canvas-mcp-serverを使用して、画像を生成しています。
ロジック層をもう少し掘り下げ
Strands Agentsは、アプリ内にAIエージェントを構築するためのAWS製のPythonフレームワークです。
特徴は、シンプルさで公式のWellcomeページを見ると下記のように3行でAIエージェントを構築できてしまいます。
(ほかにも特徴は色々と挙げられているのですが、他のAIエージェント系のSDKを使ったことないので、今回触った感じたシンプルさだけを挙げておきます...)
from strands import Agent
# Create an agent with default settings
agent = Agent()
# Ask the agent a question
agent("Tell me about agentic AI")
前提
- 実行環境:Windows11
準備:uvで開発環境を作成する
詳細はこちら
uvをインストールする (windowsの場合)
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
インストールできたか確認する
uv version
プロジェクトを初期化する
uv init application
cd application
仮想環境を作成する (Python 3.12でバージョン指定)
uv venv --python 3.12
仮想環境を有効化する
.\.venv\Scripts\Activate.ps1
下記を参考にさせていただきました。
https://speakerdeck.com/mickey_kubo/pythonpatukeziguan-li-uv-wan-quan-ru-men
ローカル実行用にAWS認証情報を環境変数に設定する
$env:AWS_PROFILE="xxxx"
アプリに必要なパッケージをインストールする。
(エージェントだけ試す場合streamlitは不要です)
uv add streamlit strands-agents strands-agents-tools
Step1. ツールの初期化
Strands Agentsは、ツールを使用してAIエージェントを拡張させることが出来ます。
-
Strands Agentsに標準搭載されたPythonツール - MCP(Model Context Protocol)ツール
- 独自のPythonツール
今回はMCPツールのみ使用しました。
MCPツールを使用するには、MCPClientを作成します。
下記ではaws-location-mcp-serverとawslabs.nova-canvas-mcp-serverのMCPClientを作成しています。
from strands.tools.mcp import MCPClient
from mcp import stdio_client, StdioServerParameters
def create_location_mcp_client():
"""Amazon Location Service MCPクライアントを作成"""
return MCPClient(lambda: stdio_client(
StdioServerParameters(
command="uvx",
args=[
"--from",
"awslabs.aws-location-mcp-server@latest",
"awslabs.aws-location-mcp-server.exe"
],
env={
"FASTMCP_LOG_LEVEL": "ERROR",
"AWS_PROFILE": "xxxx",
"AWS_REGION": "ap-northeast-1",
}
)
))
def create_nova_canvas_mcp_client():
"""Nova Canvas MCPクライアントを作成"""
return MCPClient(lambda: stdio_client(
StdioServerParameters(
command="uvx",
args=[
"--from",
"awslabs.nova-canvas-mcp-server@latest",
"awslabs.nova-canvas-mcp-server.exe"
],
env={
"FASTMCP_LOG_LEVEL": "ERROR",
"AWS_PROFILE": "xxxx",
"AWS_REGION": "ap-northeast-1",
}
)
))
# MCPクライアントを作成
location_mcp_client = create_location_mcp_client()
nova_canvas_mcp_client = create_nova_canvas_mcp_client()
StdioServerParametersの指定方法は、WindowsとmacOS/Linuxで異なるので注意です。
上記は、Windowsの場合の記述です。
Step2. AIエージェントの初期化
Strands Agentsは、数行のコードでAIエージェントを構築することが出来ます。
先ほど作成したMCPClientを使用して、Agentを作成します。
from strands import Agent
def create_agent(location_mcp_client, nova_canvas_mcp_client):
"""エージェントを作成"""
return Agent(
model=BedrockModel(model_id=MODEL_ID),
tools=location_mcp_client.list_tools_sync() + nova_canvas_mcp_client.list_tools_sync()
)
# MCPクライアントを使用してエージェントを作成
with location_mcp_client, nova_canvas_mcp_client:
agent = create_agent(location_mcp_client, nova_canvas_mcp_client)
システムプロンプト
今回は指定していませんが、Agentにシステムプロンプトを指定することも可能です。
https://strandsagents.com/latest/user-guide/concepts/agents/prompts/#system-prompts
Step3. プロンプトの作成
実際にAIエージェントを実行するにあたり、プロンプトを作成します。
今回は、MCPサーバーのツールを利用してほしいので、明示的に使ってほしいツール名を指定しています。
あとはUI上でユーザーが入力した内容に従って、プロンプトを作成します。
def create_prompt(lat, lng, style, time, weather, custom, save_folder, filename_format, custom_filename=None):
"""プロンプトを生成"""
# ファイル名の生成
timestamp = datetime.datetime.now().strftime("%Y%m%d_%H%M%S")
if filename_format == "coordinates_timestamp":
filename = f"lat_{lat:.6f}_lng_{lng:.6f}_{timestamp}"
elif filename_format == "timestamp_only":
filename = f"generated_{timestamp}"
elif filename_format == "coordinates_only":
filename = f"lat_{lat:.6f}_lng_{lng:.6f}"
elif filename_format == "custom" and custom_filename:
filename = f"{custom_filename}_{timestamp}"
else:
filename = f"generated_{timestamp}"
return f"""
以下の条件に従って、画像を生成してください
### 条件1:緯度、経度からsearch_nearbyツールを使って情報を取得する
- 緯度 {lat:.6f}, 経度 {lng:.6f}
### 以下の条件と条件1の取得結果から、generate_imageツールを使用して画像生成する
- スタイル: {style}
- 時間帯: {time}
- 天気: {weather}
- 追加要求: {custom}
生成した画像は以下の条件で保存してください
### 保存設定
- 保存先フォルダ: {save_folder}
- ファイル名: {filename}
- workspace_dir パラメータに {save_folder} を設定してください
- filename パラメータに {filename} を設定してください
### generate_imageツールでエラーの場合
- 詳細なエラーコードやメッセージを表示してください。
"""
# プロンプトを作成
enhanced_question = create_prompt(
current_lat, current_lng, settings["image_style"],
settings["time_of_day"], settings["weather"], settings["custom_prompt"],
settings["save_folder"], settings["filename_format"],settings["custom_filename"]
)
Step4. AIエージェントの実行(ストリーミング)
Strands Agentsは、下記のストリーミング処理で実行することが出来ます。
(ストリーミングは、処理が完了したデータを非同期で逐次受け取りながら処理する仕組みです。)
-
非同期イテレータ
-
stream_async()を使用することで、エージェントの応答を非同期に受け取り、リアルタイムで処理することが出来ます - 詳細:https://strandsagents.com/latest/user-guide/concepts/streaming/async-iterators/
-
-
コールバックハンドラ
- エージェントの実行中に発生する各種イベントに対して、コールバック関数を指定することでイベントごとに適宜処理することが出来ます
-
Agentの初期化時にcallback_handlerを指定することで、任意のコールバック関数を設定します。 - 詳細:https://strandsagents.com/latest/user-guide/concepts/streaming/callback-handlers/
今回は、非同期イテレータ(stream_async())を使用しています。
以下の記述で、エージェントからのレスポンスをchunkで逐次受け取ることができます。
async for chunk in agent.stream_async(question):
さらにchankの中にevent属性が存在するので、このevent属性をもとにイベントの種類ごとに処理を振り分けることが出来ます。
import asyncio
async def stream_response(agent, question, container):
"""レスポンスをストリーミング表示"""
text_holder = container.empty()
buffer = ""
shown_tools = set()
generated_images = []
try:
async for chunk in agent.stream_async(question):
if isinstance(chunk, dict):
# ツール実行を検出して表示
tool_id, tool_name = extract_tool_info(chunk)
if tool_id and tool_name and tool_id not in shown_tools:
shown_tools.add(tool_id)
if buffer:
text_holder.markdown(buffer)
buffer = ""
container.info(f"🔧 **{tool_name}** ツールを実行中...")
text_holder = container.empty()
# 画像生成結果を検出
if 'toolResult' in chunk.get('event', {}):
tool_result = chunk['event']['toolResult']
if 'content' in tool_result:
for content in tool_result['content']:
if content.get('type') == 'image':
# 画像データを取得
image_data = content.get('data')
if image_data:
generated_images.append(image_data)
# 画像生成完了を通知のみ
container.success("🎨 画像生成完了!")
# テキストを抽出して表示
if text := extract_text(chunk):
buffer += text
text_holder.markdown(buffer + "▌")
except asyncio.CancelledError:
container.warning("⚠️ 処理がキャンセルされました")
raise
except Exception as e:
container.error(f"❌ ストリーミング中にエラーが発生: {str(e)}")
raise
finally:
# 最終表示
if buffer:
text_holder.markdown(buffer)
return generated_images
# 非同期実行
loop = None
try:
# 既存のイベントループがある場合は新しいループを作成
try:
loop = asyncio.get_event_loop()
if loop.is_running():
# 既存のループが実行中の場合は新しいループを作成
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
except RuntimeError:
# イベントループが存在しない場合は新しいループを作成
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
# タスクを実行
generated_images = loop.run_until_complete(
stream_response(agent, enhanced_question, container)
)
最終的なコード
最終的なコードは以下になります。
まとめ
今回は、AWS Summitで気になっていたStrands Agentsを使ってみました。
率直な感想としては、確かにシンプルに書けるなーという印象です。どちらかというとStramlitのUI構築の方が難しかったです...
作ったのが簡素なアプリでしたが、Strands Agentsはマルチエージェントも作れるようなので、次回はもう少し複雑なアプリに挑戦したいと思います!
おまけ:生成した画像たち (後で追加するかも)
支笏湖 (なんで温泉?)
