delika Advent Calendar 2022
はじめに
ぼくのはたらく場所のちかくには3軒のごはんどころがある。
1.ばんのう定食屋「やよい軒」
2.早さ最つよ「すき家」
3.コスパ神「スシロー」
ぼくはこの3軒をループする。
そんなある日、ぼくに突然の通知が来た。
あなたはメタボリックシンドロームです
これは店のせいではない。
完全に、ぼくのせいだ。
あの券売機に表示される「肉」、
あのタブレット端末が誘惑する「特盛」、
あのまわって誘惑する「べつばらデザート」。
いったいどれだけのカロリーをせっしゅしているというのだ。
delikaにまとめてみよう。
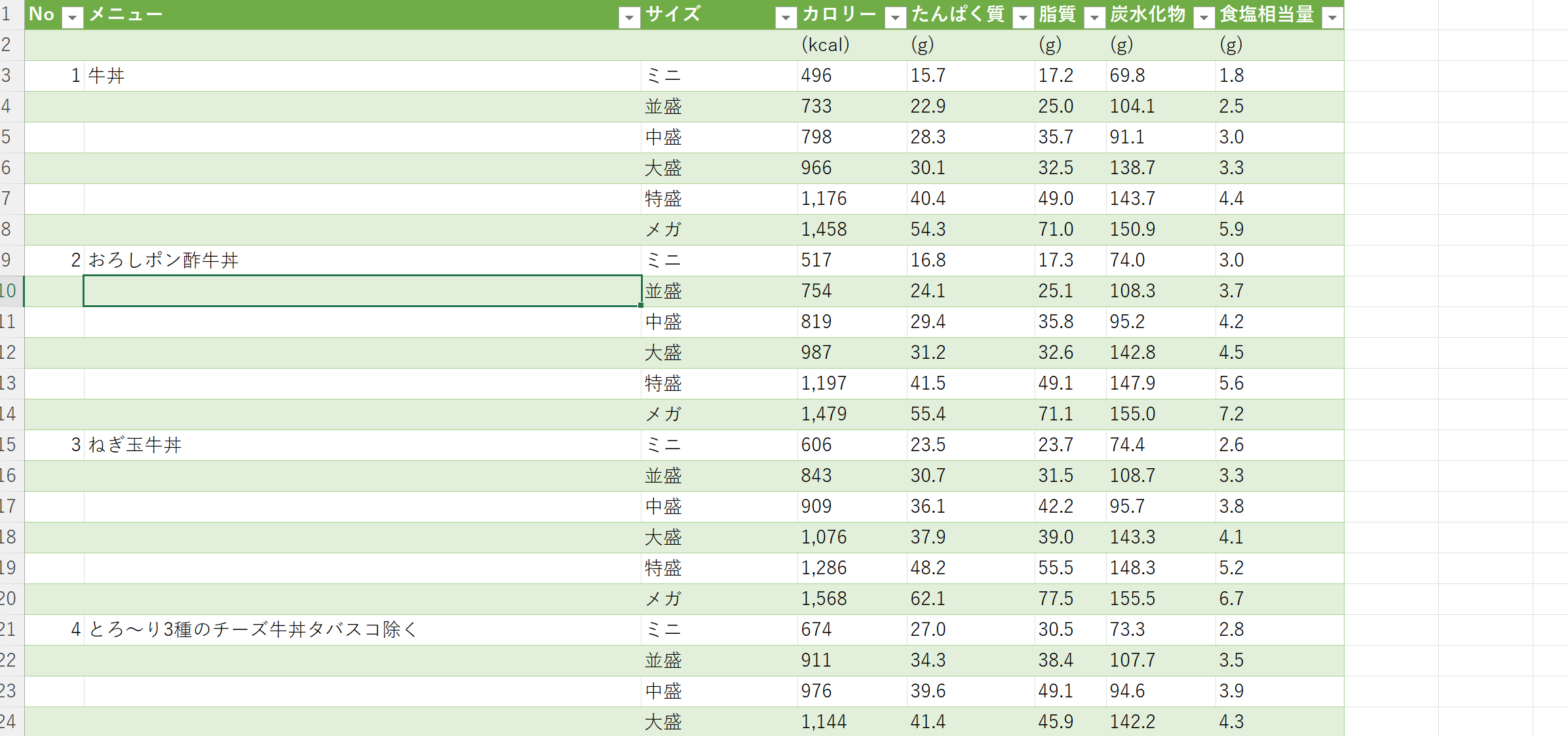
カロリーデータの取得 やよい軒
「やよい軒 カロリー」で検索しトップに表示されたページへいってみる。
https://www.yayoiken.com/menu_list/info/9
うーん、アレルギー情報だけで、カロリー情報はないか?とおもったら、
真ん中の「栄養成分情報」のタブにありました。
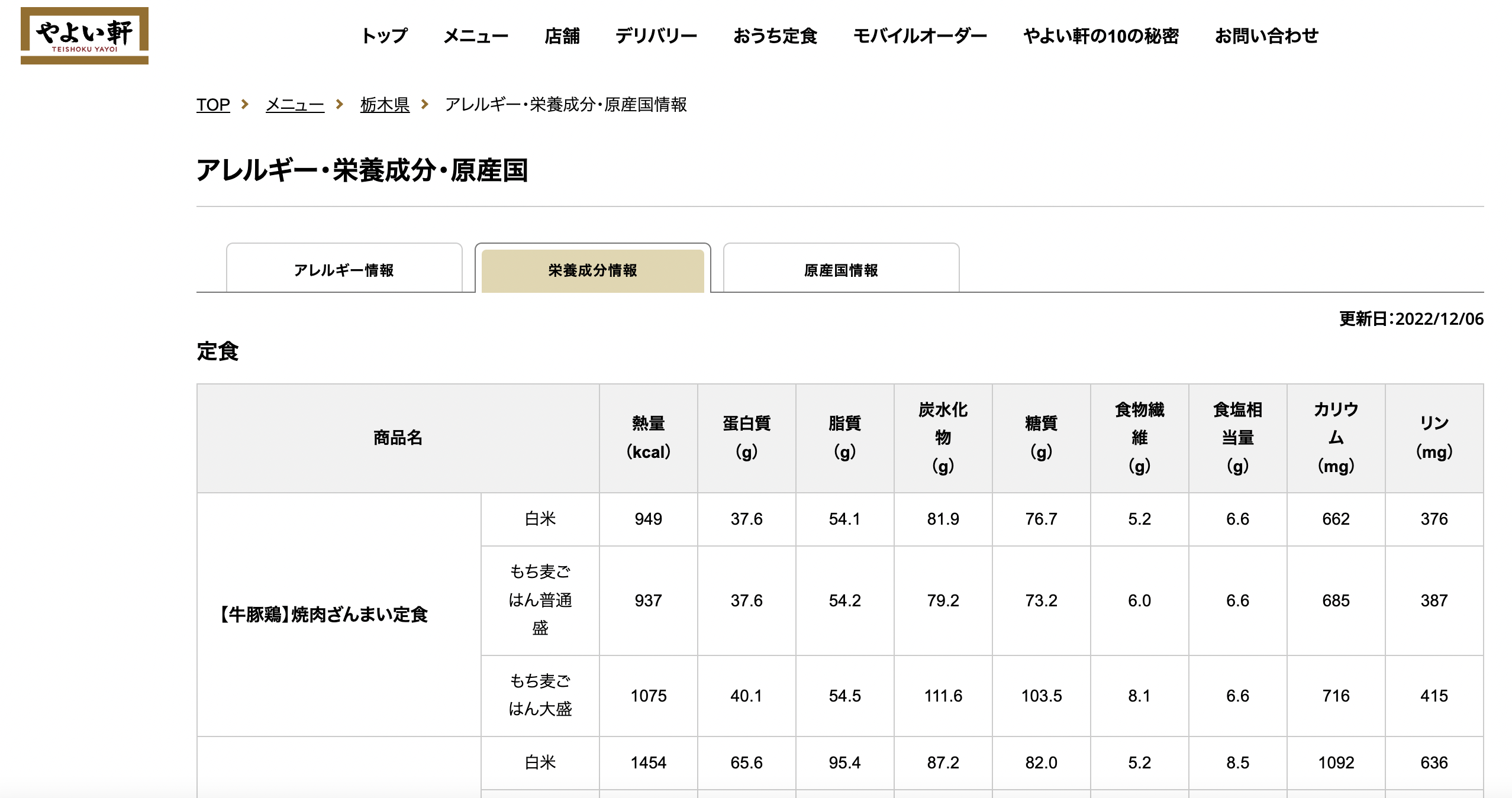
おー、さすが。しかも、テーブルで一覧になっている。ありがたや。
手作業でのスクレイピングを試行。
このページを「名前を付けて保存」し、保存されたhtmlファイルをExcelで読み込む。
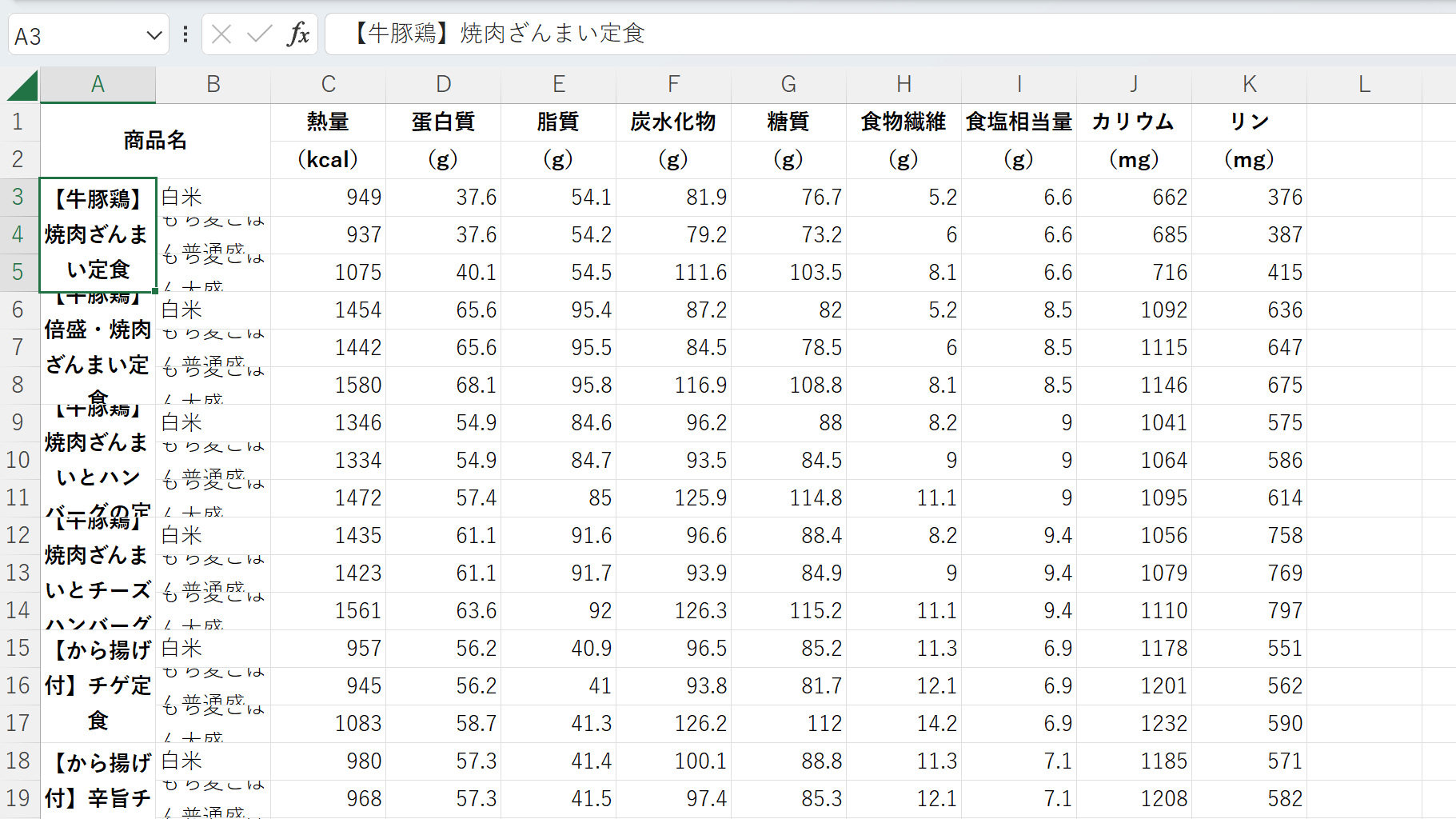
うまく読み込めたようだ。ただ、A3,A4,A5セルのように、結合セルになってしまっているので、結合を解除する。
セル全体を選択して、右クリックし「セルの書式設定」を選択する。

表示される「セルの書式設定」ダイアログの「文字の制御」の「セルを結合する」のチェックを外して「OK」を押す。
セルの結合が解除された。
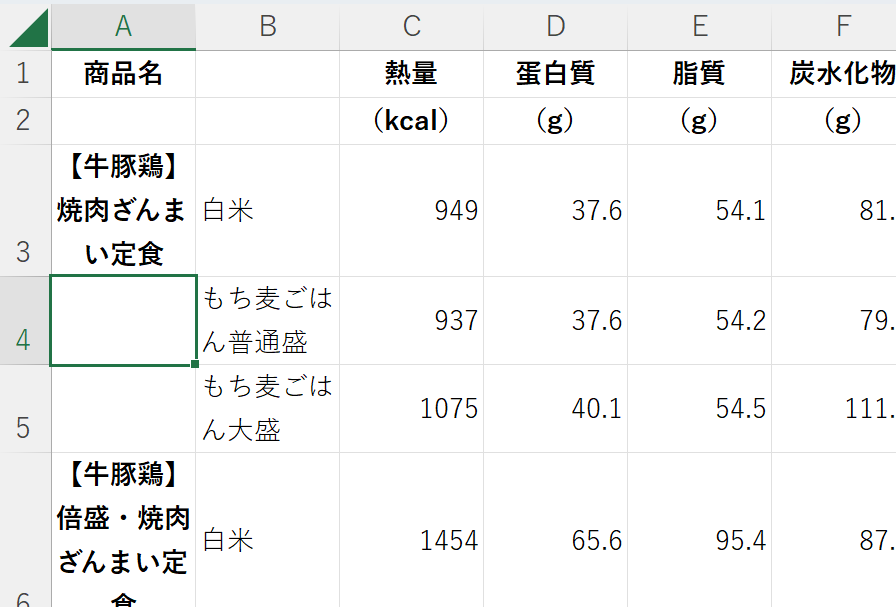
B1,B2セルが空欄なので「ご飯」「種類」と入力した。
A2,A4,A5セルなど、結合解除により空欄になってしまっていることに気づいた。
上のセルの値で埋めたい。
こちらを参考にやってみる。
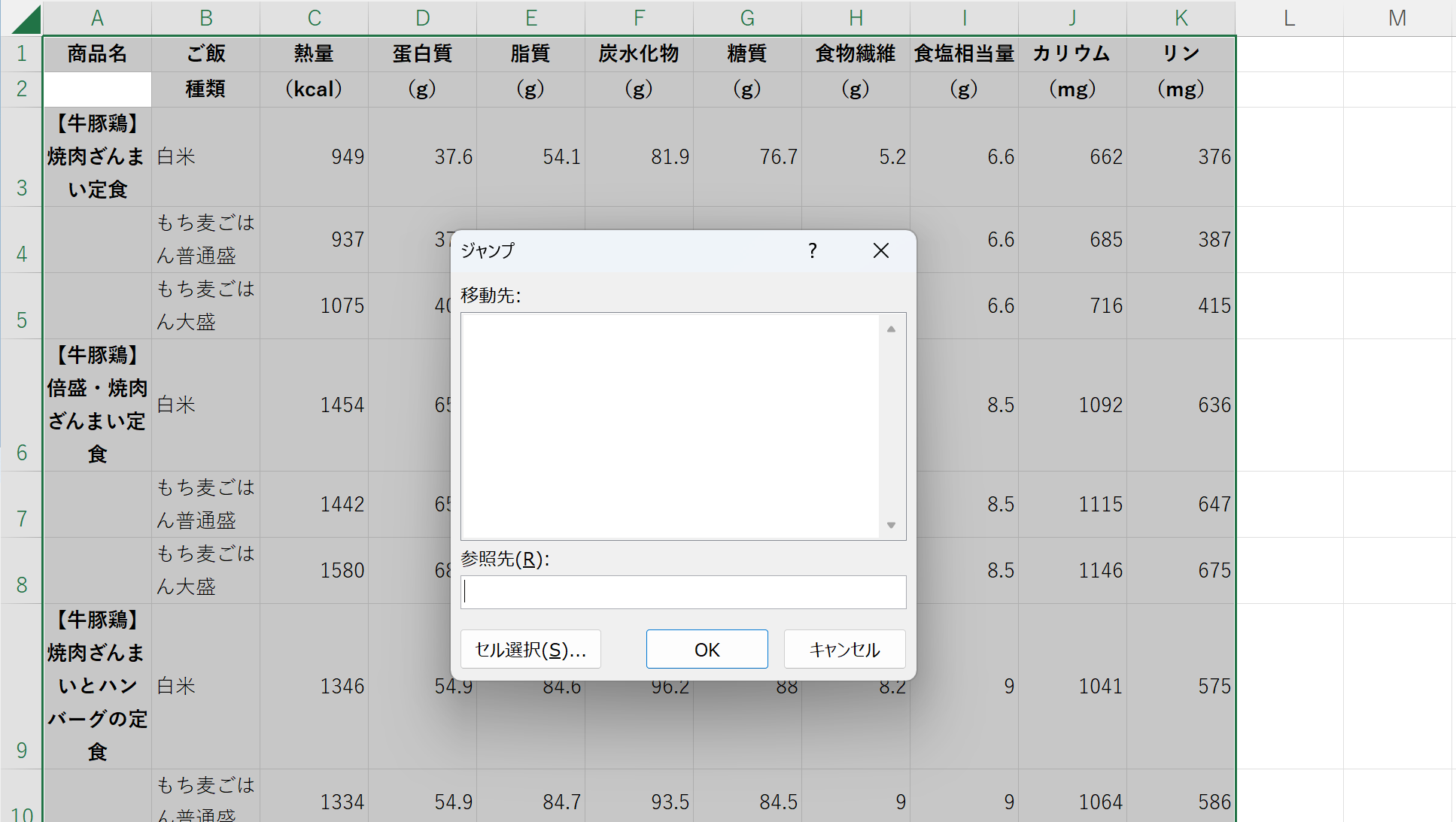
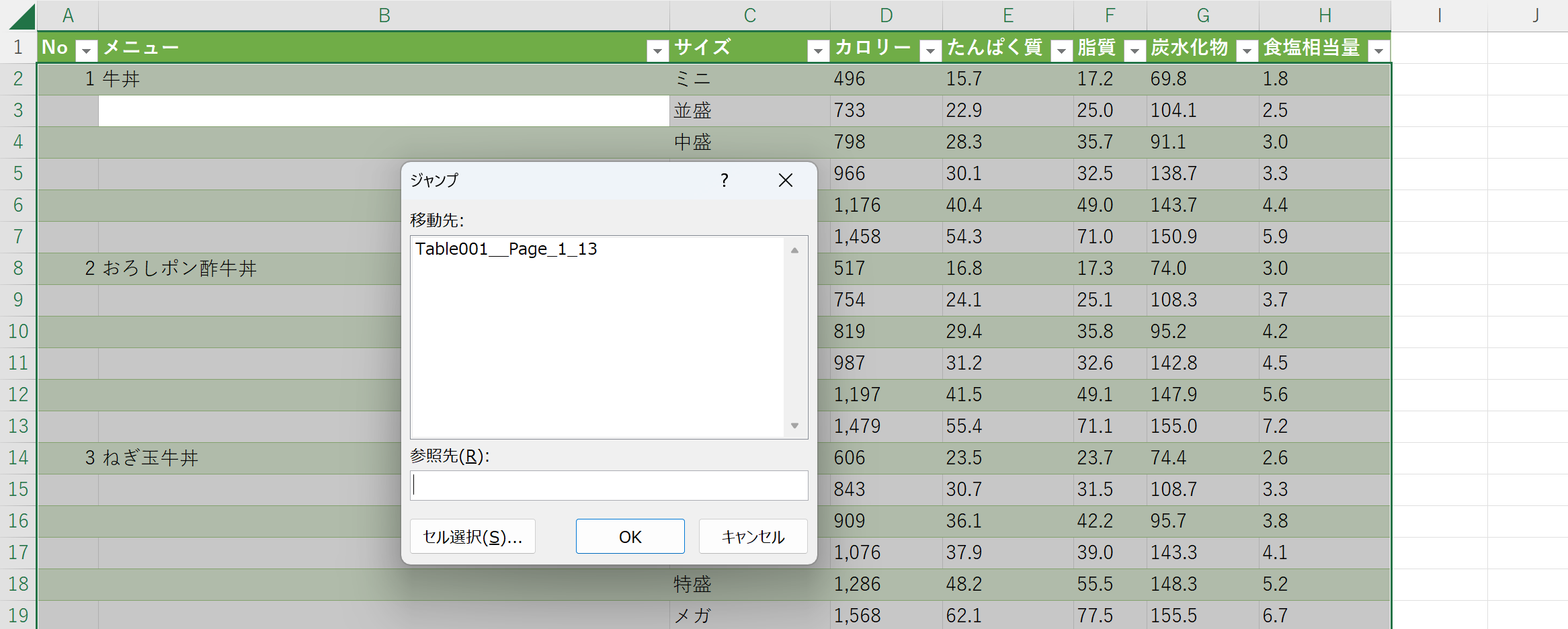
Ctrl+Aで全体を選択する。
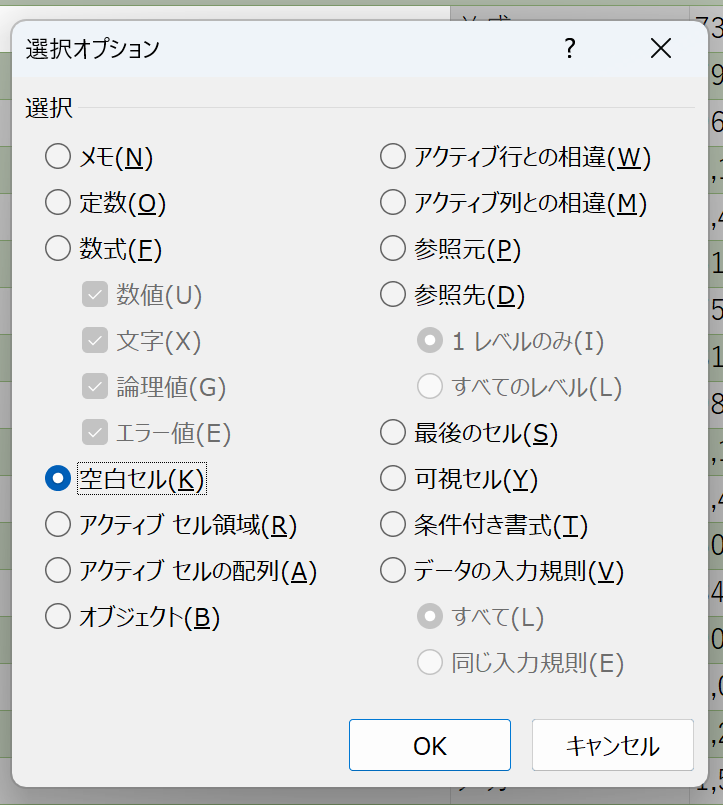
Ctrl+Gを押して「ジャンプ」ダイアログを表示させ、「セルを選択」を押す。
「選択オプション」ダイアログで「空白セル」のラジオボタンを押して「OK」を押す。
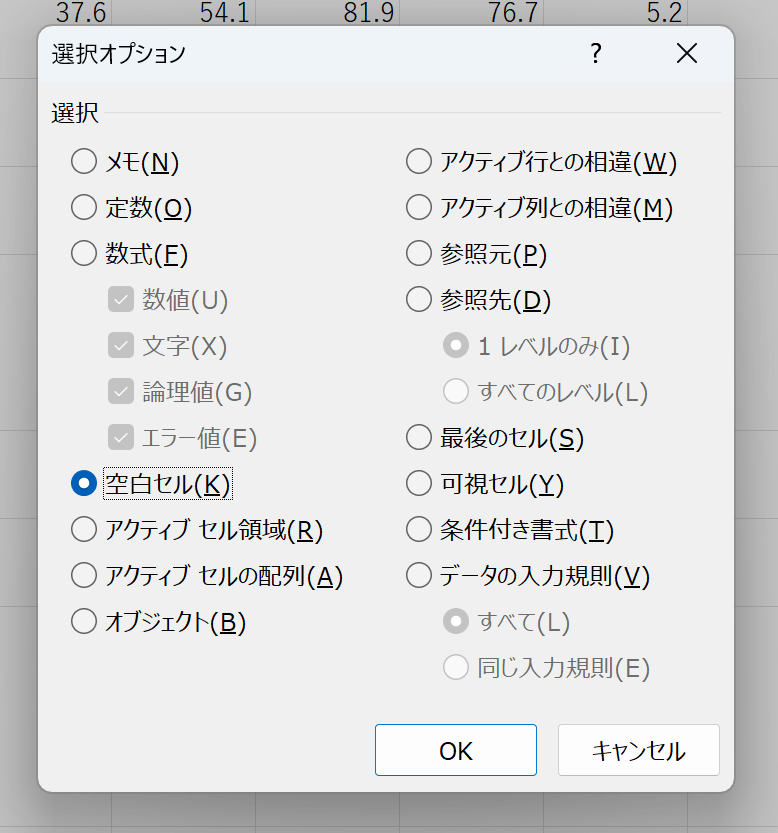
空白セルだけが選択された。
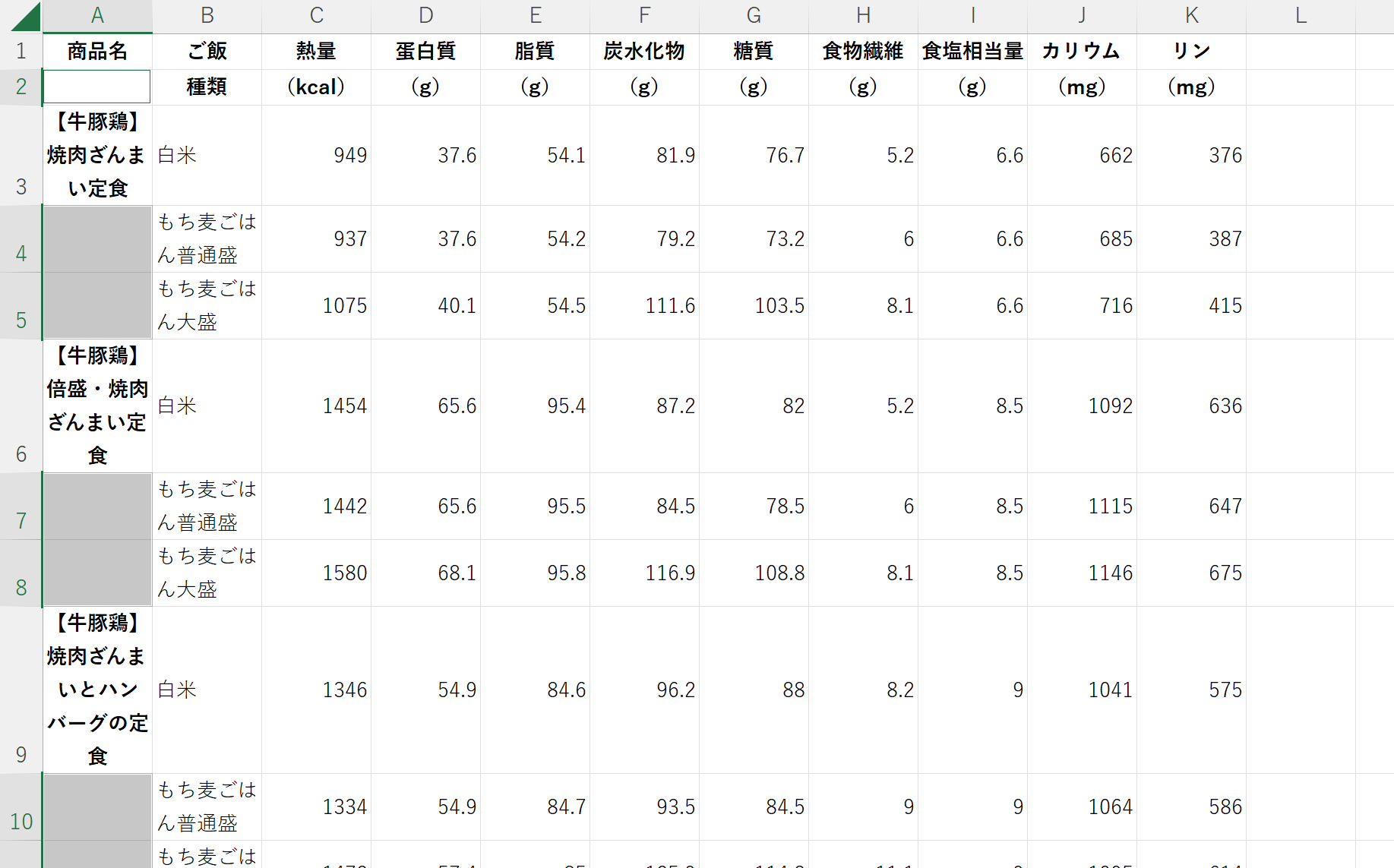
A2セルに「=A1」として一つ上のセルを選択し、ここでCtrl+Enterを押す。
Ctrl+Enterにより、選択されたセルに同じものが入力される。

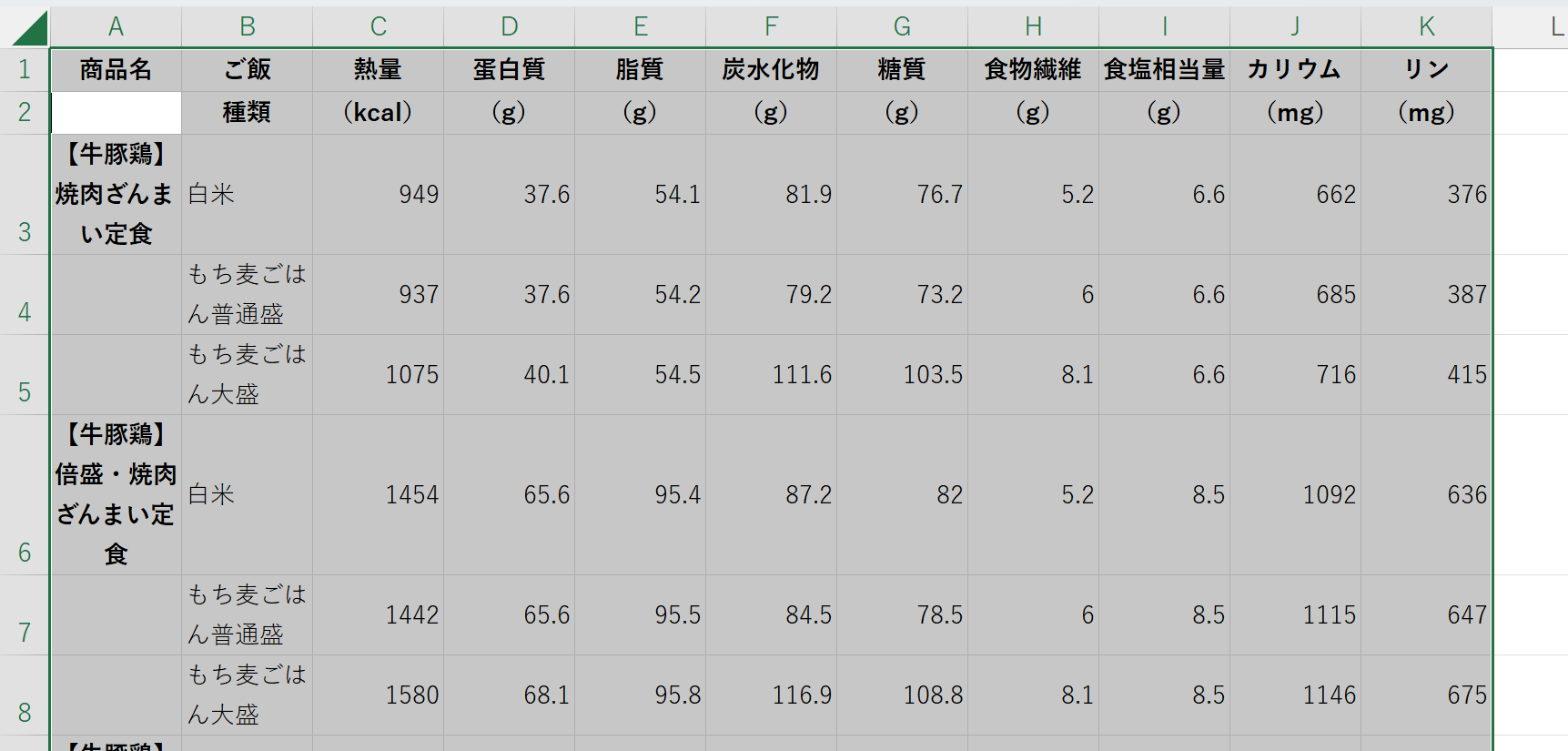
A4,A5セルにはA3セルの値が、A7,A8セルにはA6セルの値が、A10,A11セルにはA9セルの値が入った。
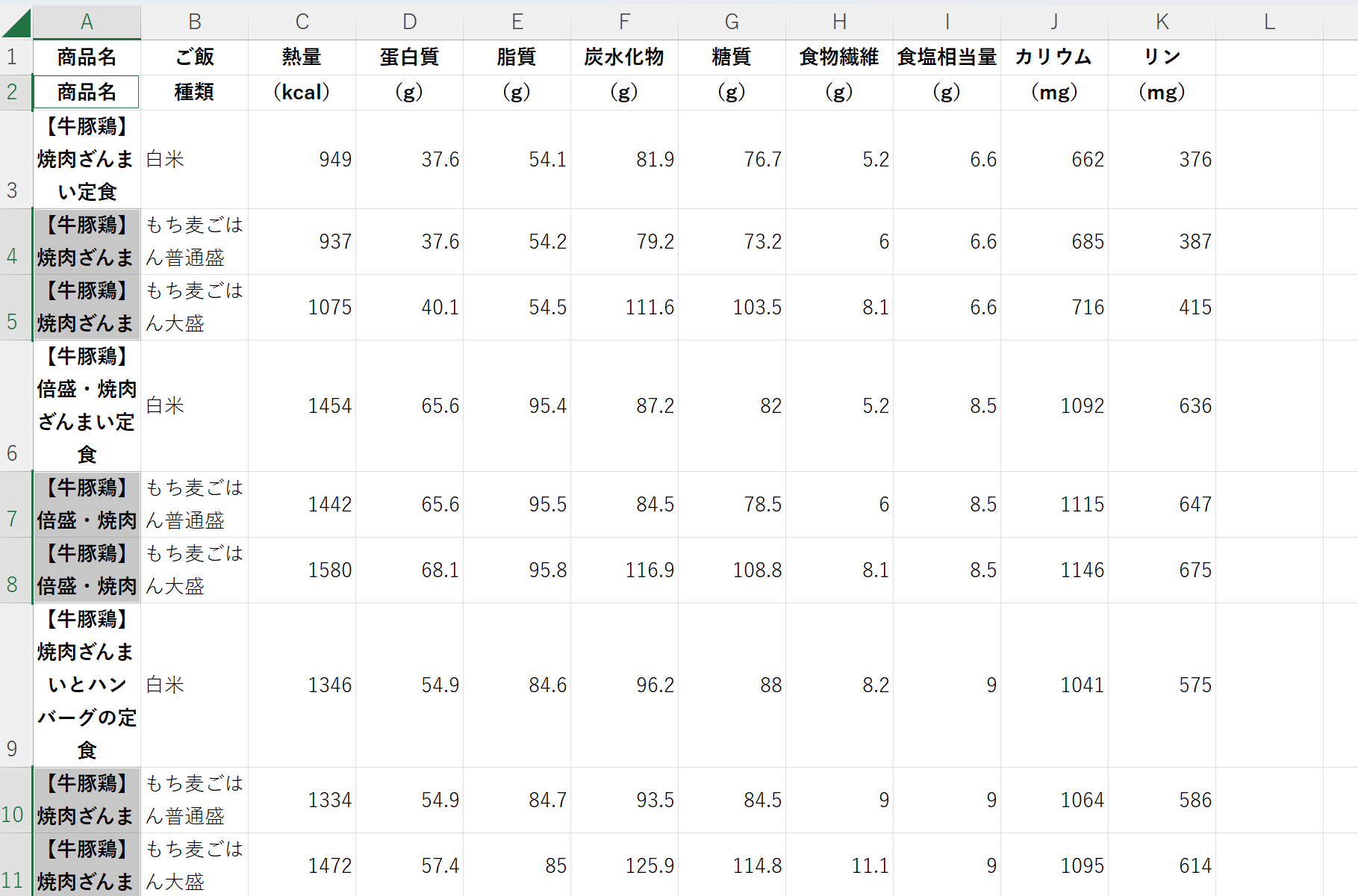
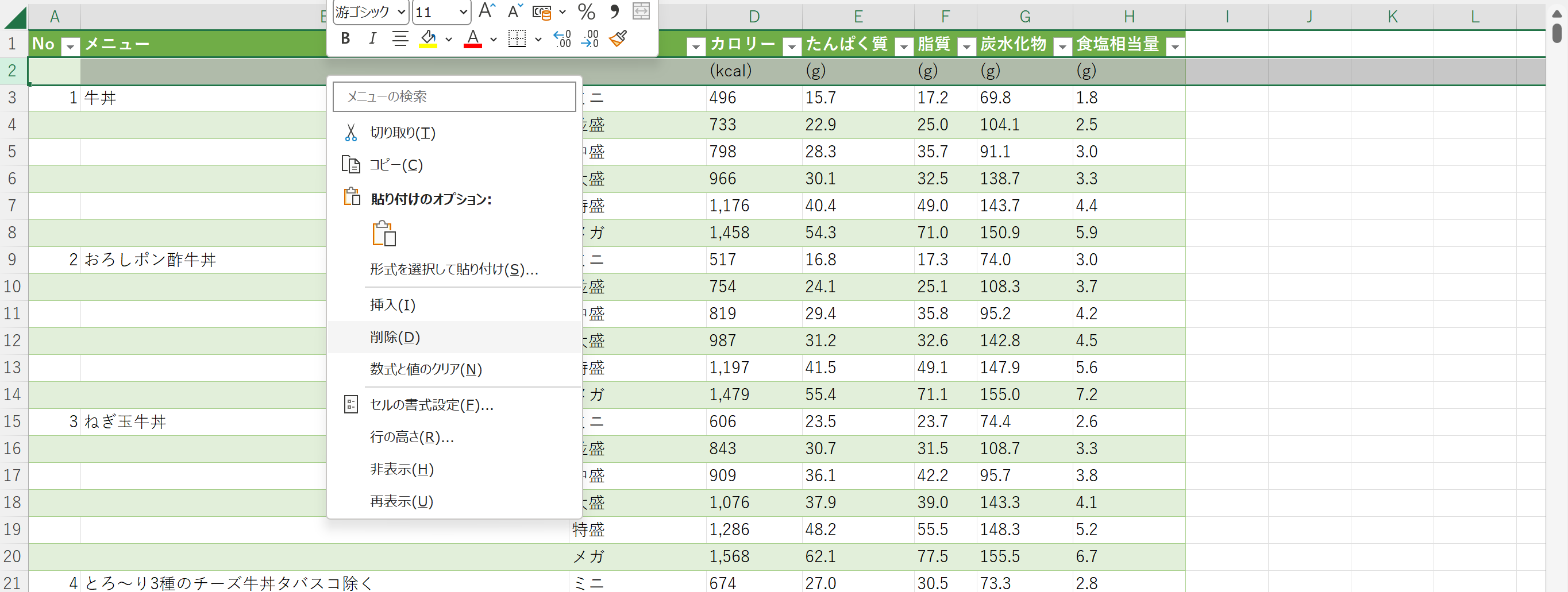
2行目を削除する。
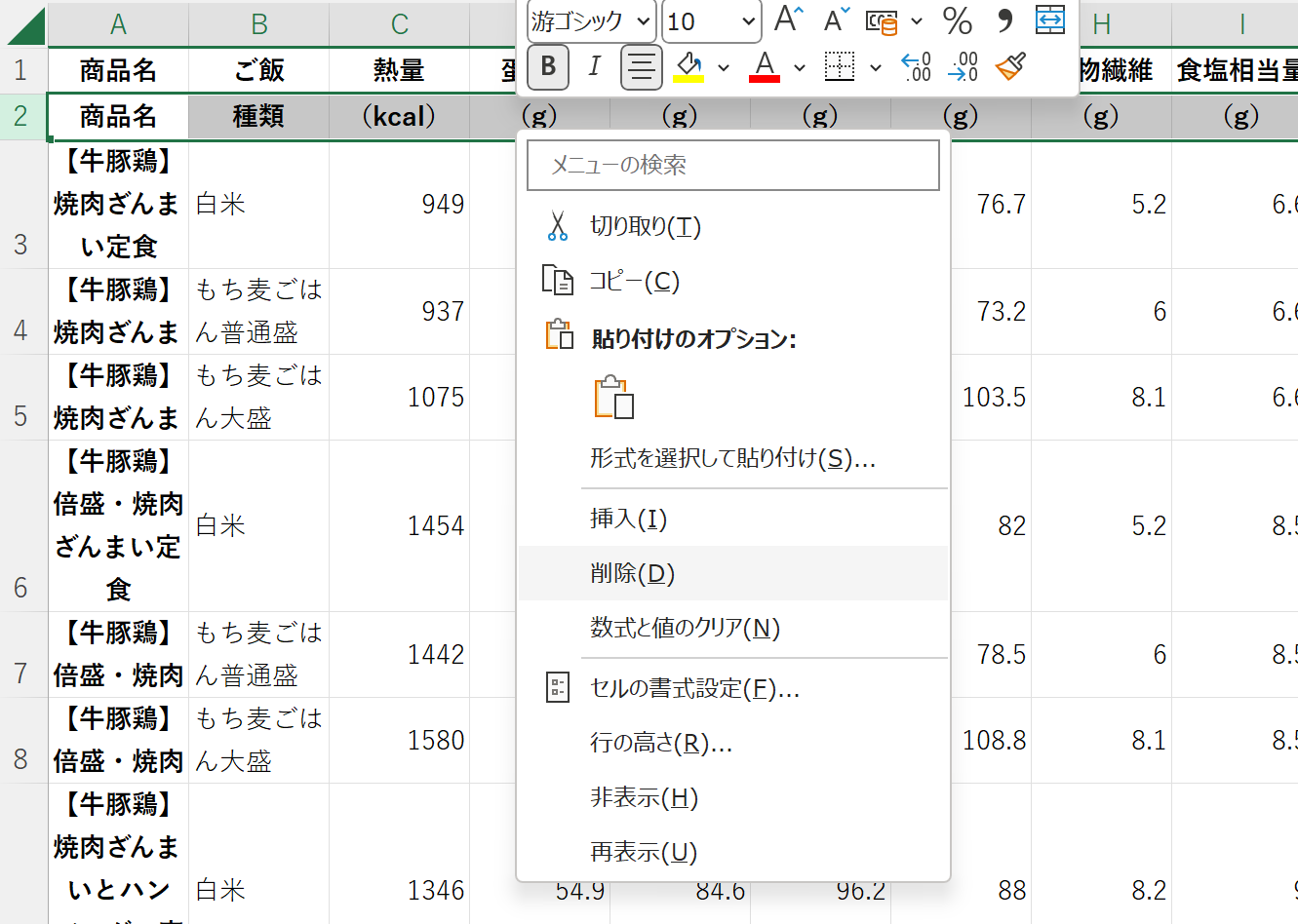
このシートをCSV形式で保存する。

保存したCSVファイルをテキストエディタで開いてみる
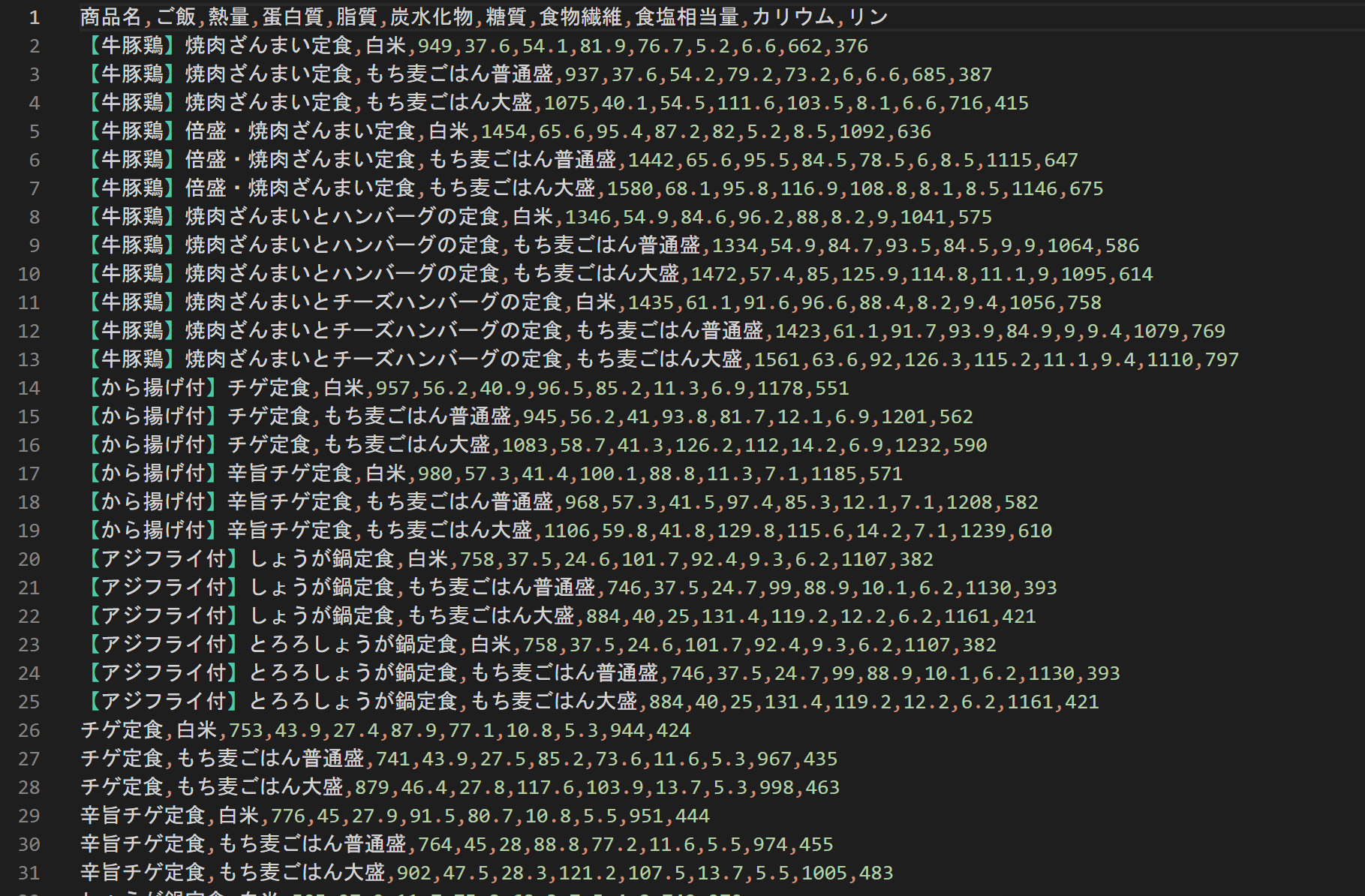
やよい軒のデータは、うまくできているようだ。
やよい軒のデータのdelikaへの登録
サインアップする。
「Sign up」を押して登録作業を行う。
「Proceed」を押す。
GithubかEmailでサインアップできるようだ。Emailでやってみる。
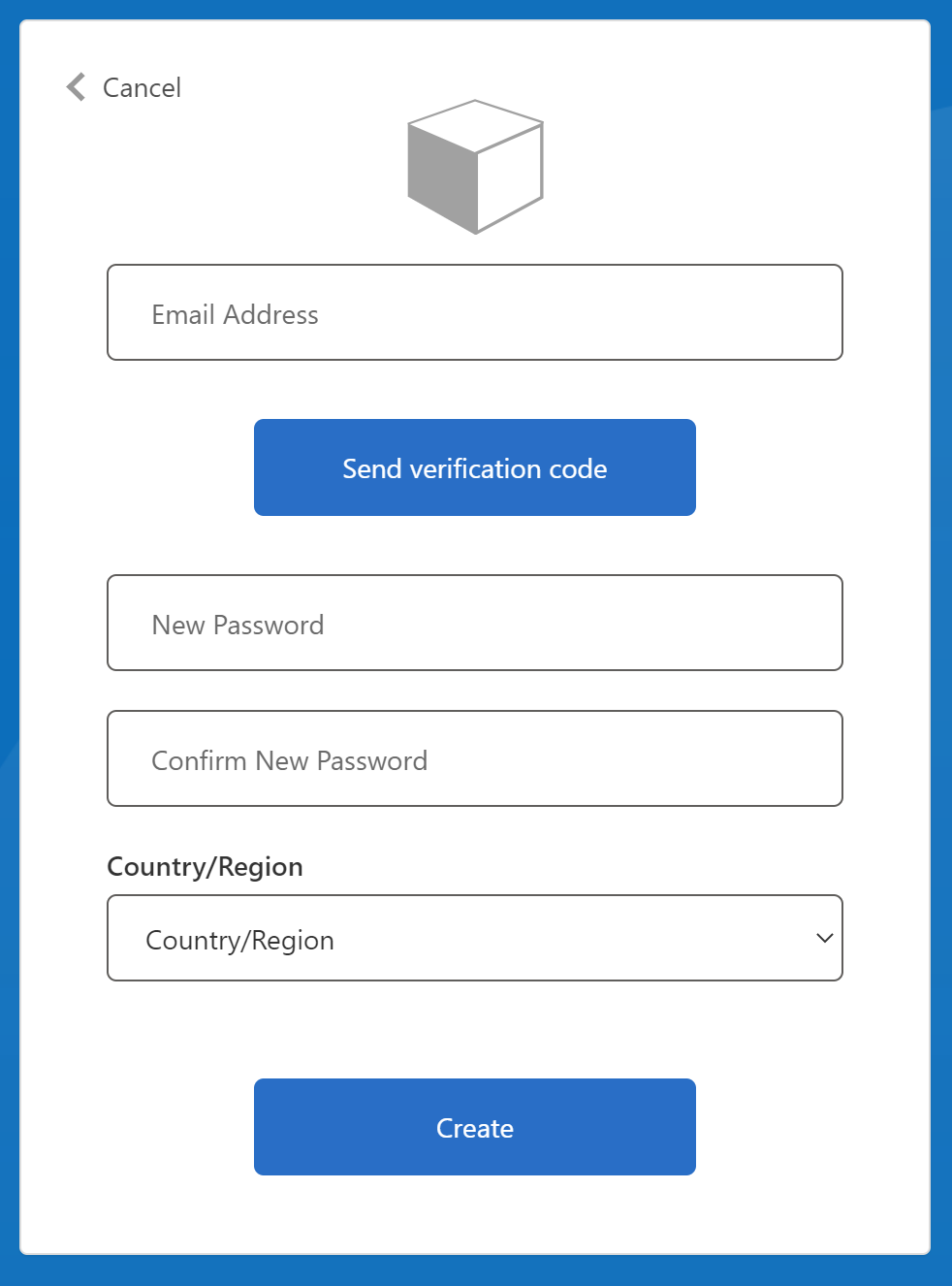
Emailアドレスを入力して、Send verification codeを押す。
届いた verification codeを入力して、パスワードを入力して、国を選び、Createを押す。
Agreeを押す

User Nameを入力してUpdateを押す。
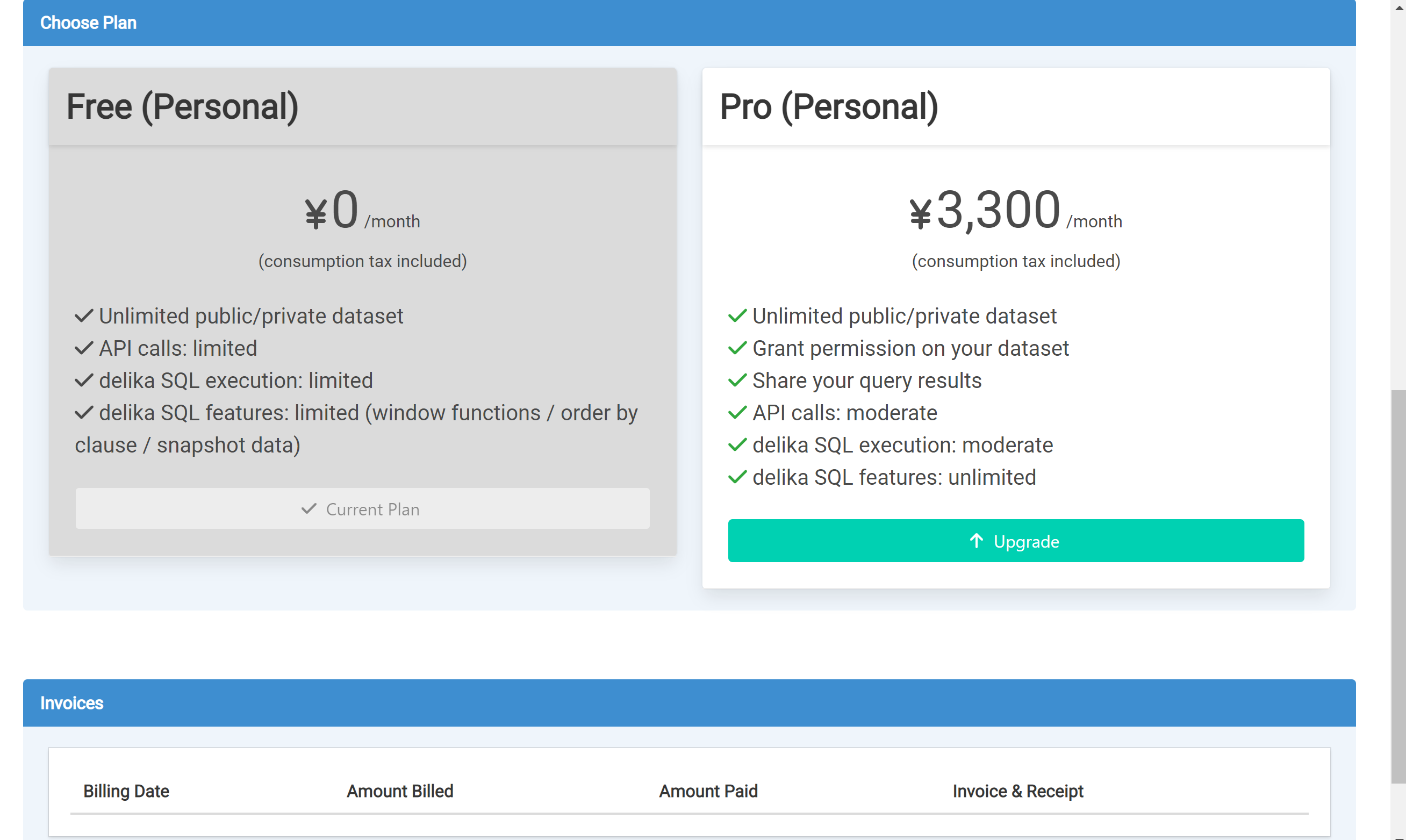
FreeプランとProプランがある。
登録が完了した。黒い帯の中にあるDocsを押してみる

ドキュメントを参照できる。

黒い帯の中にあるExploreを押してみる
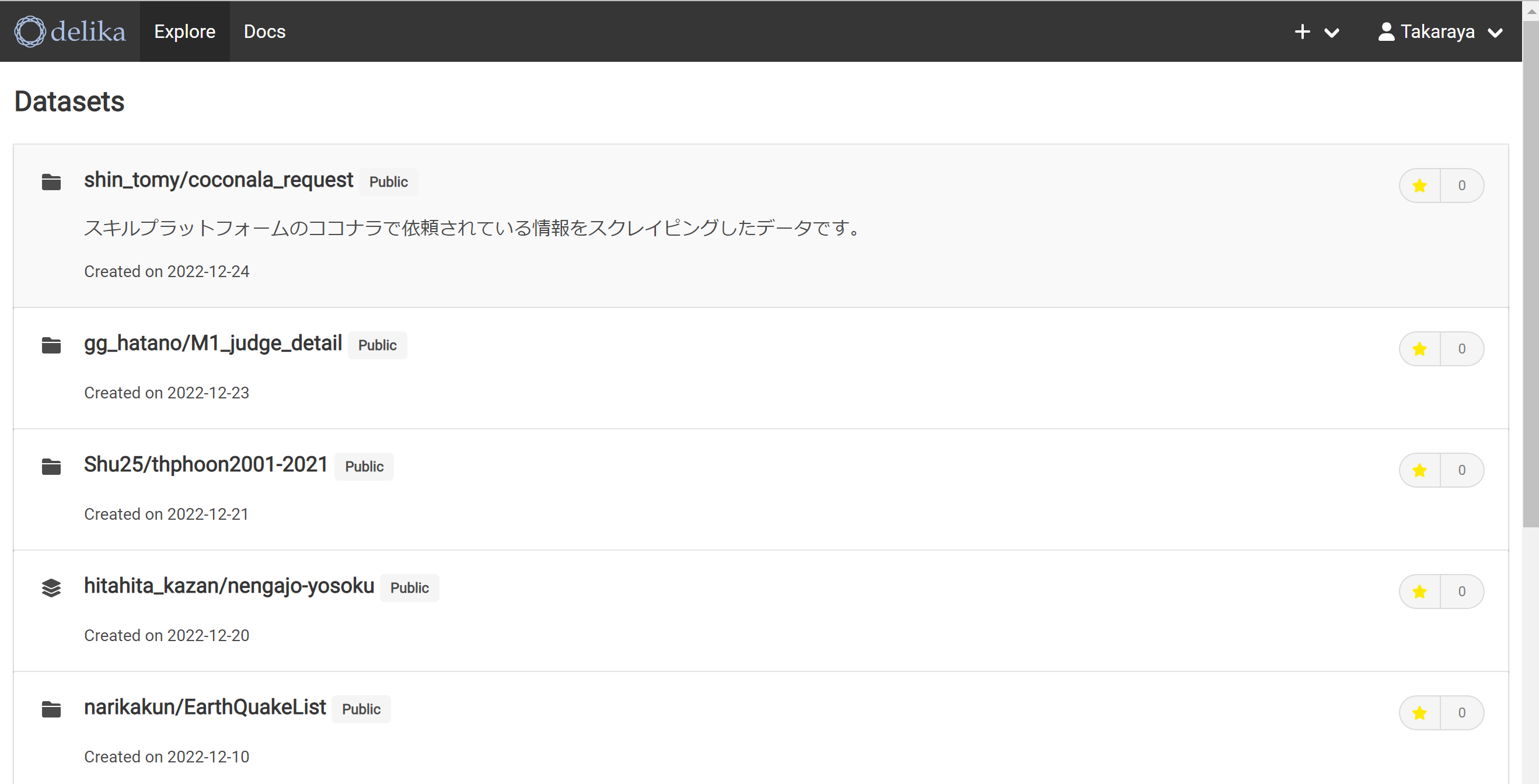
みなさんがアップされているデータを参照できる。
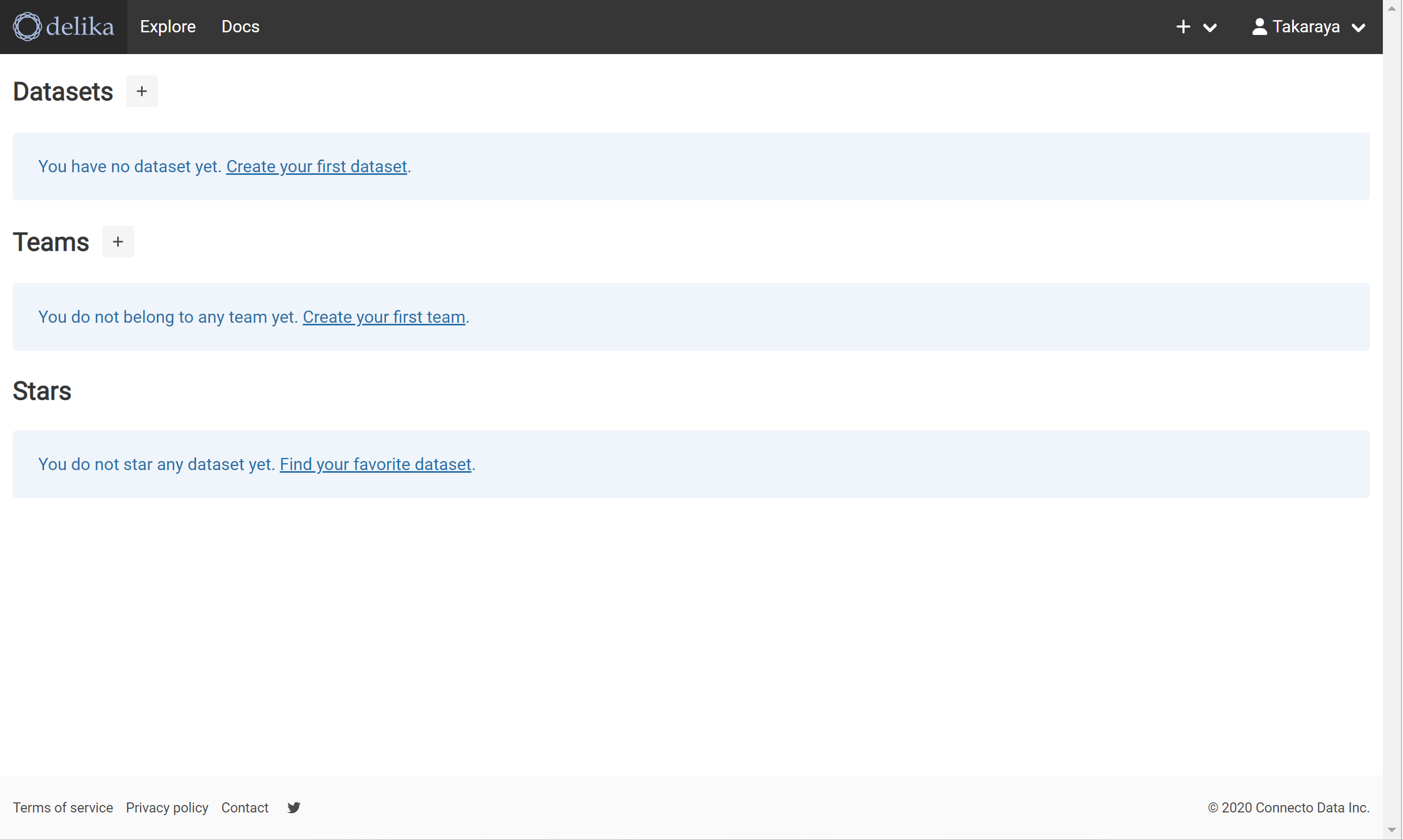
黒い帯の左側の「delika」を押してみる。自分のデータセットが参照できるようだ。
Datasetの右の+を押す。
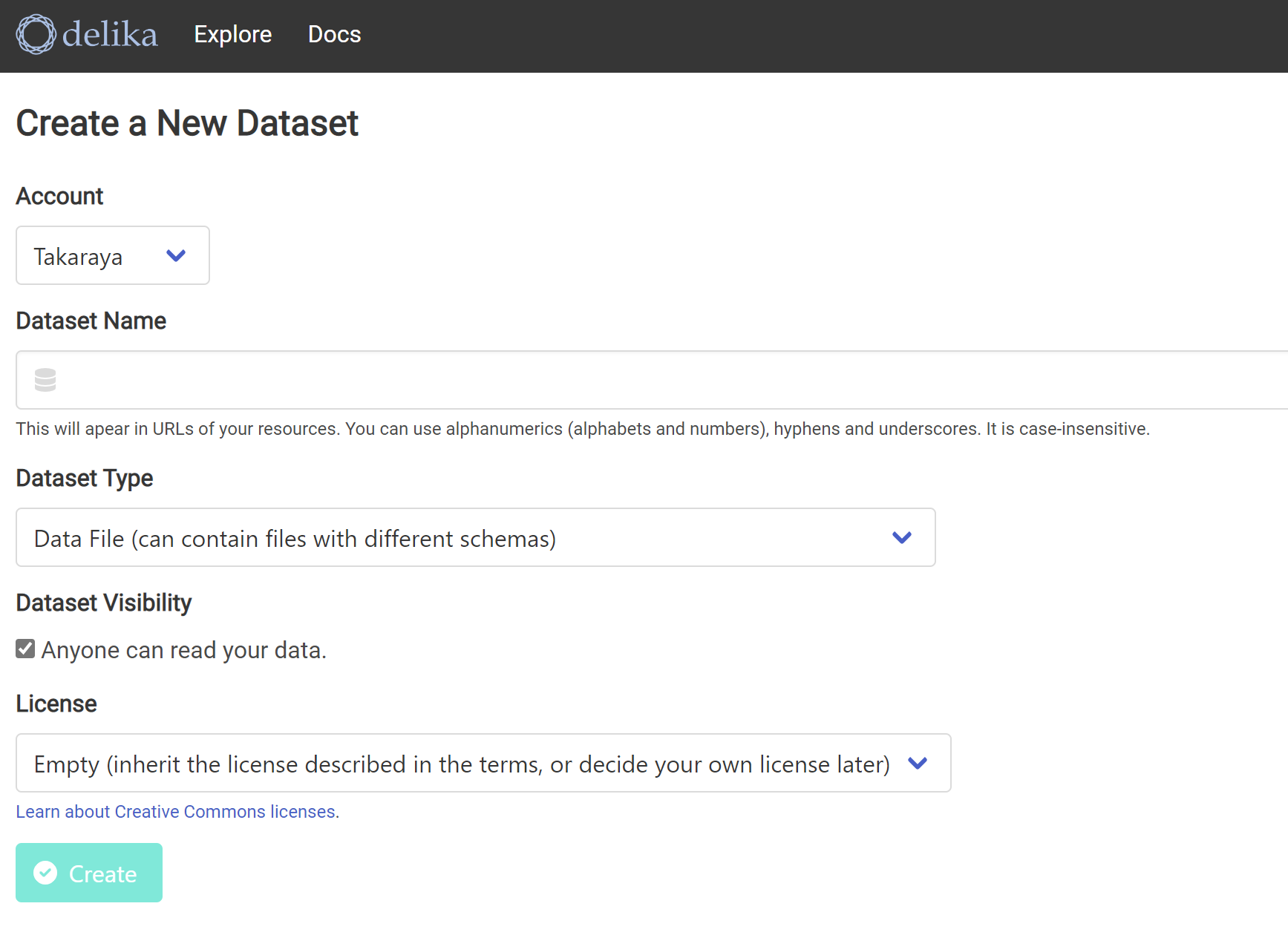
Dataset Nameを入力する。16文字を超えてしまったようだ。
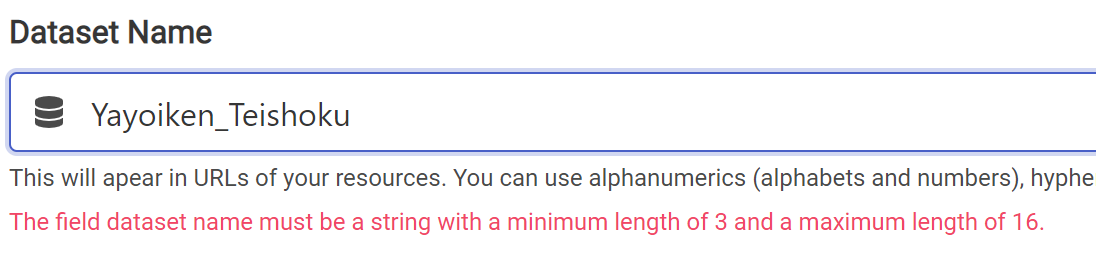
16文字以内にする。
DatasetType と Licenseを選ぶ。
Createを押す

生成されたようだ。

Update Filesを押す。灰色の領域にCSVファイルをドロップする。
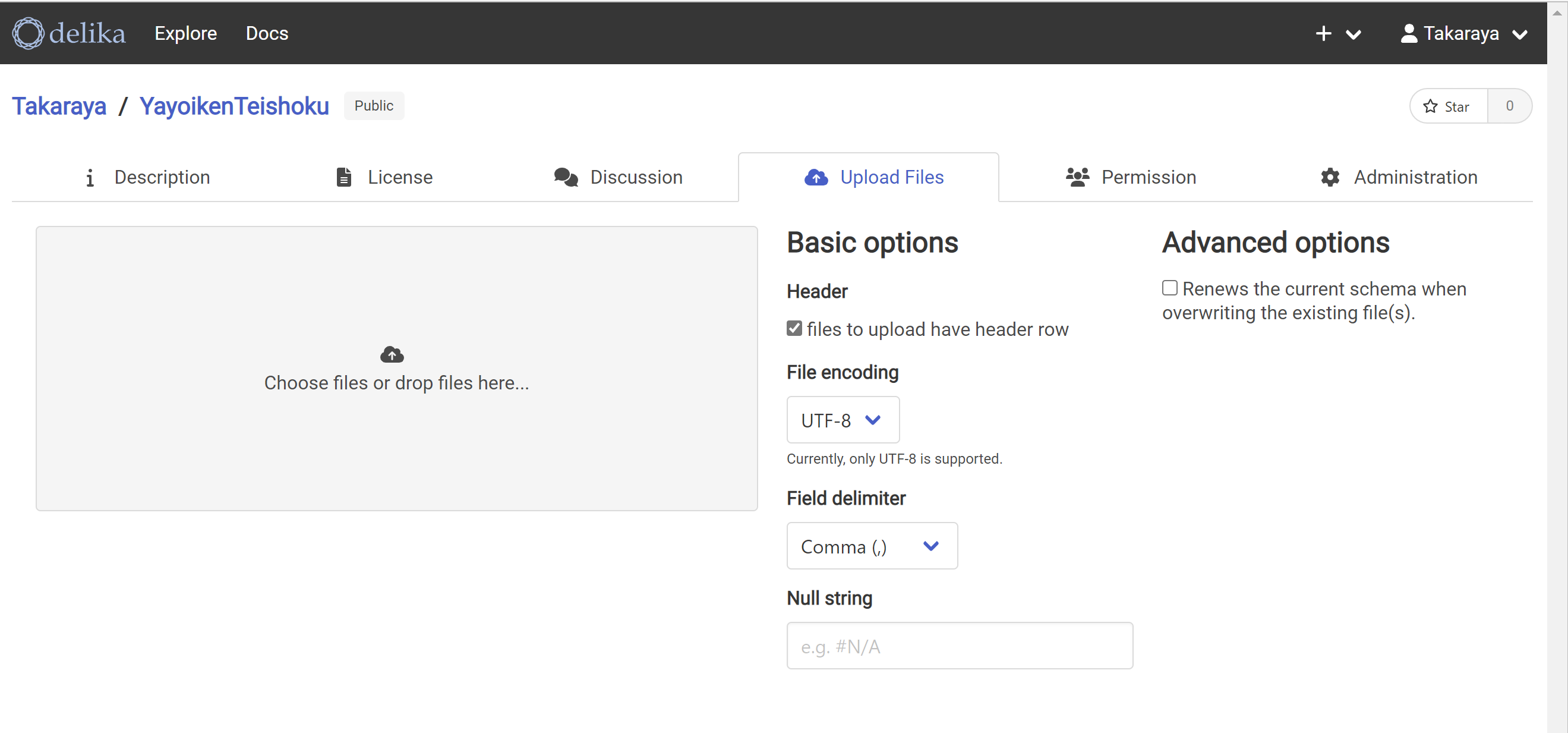
CSVファイルが読み込まれた。

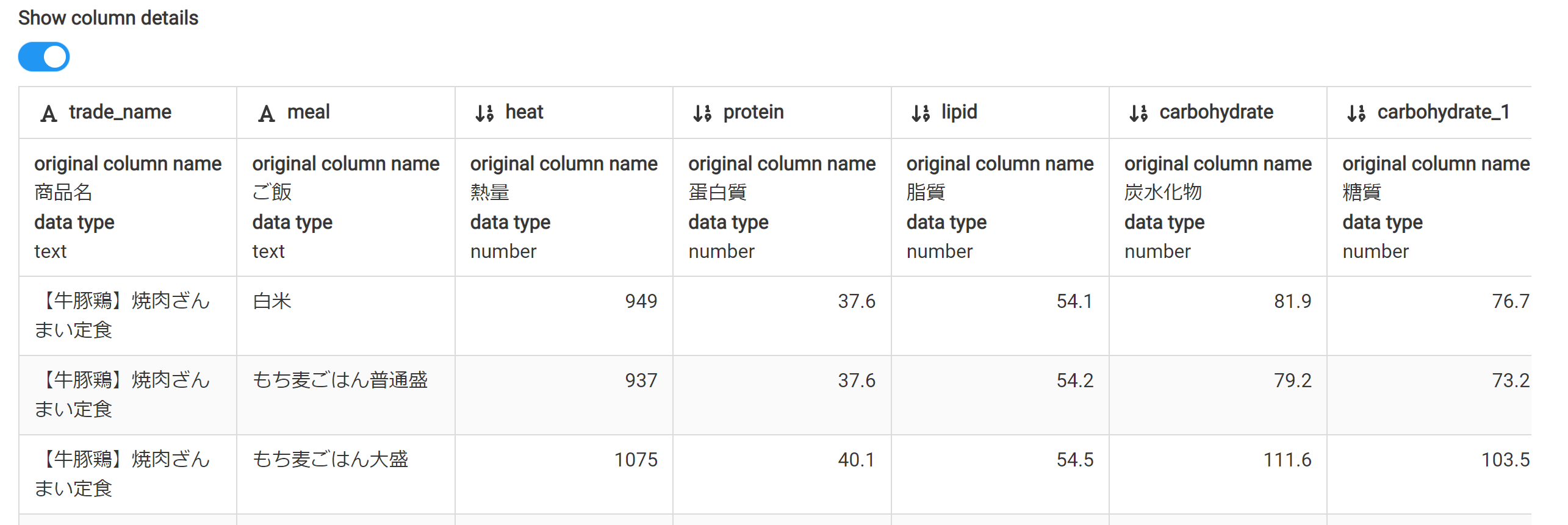
Show column detailsを押す。

詳細が表示された

Show example queryを押す

クエリーの入力画面が表示される
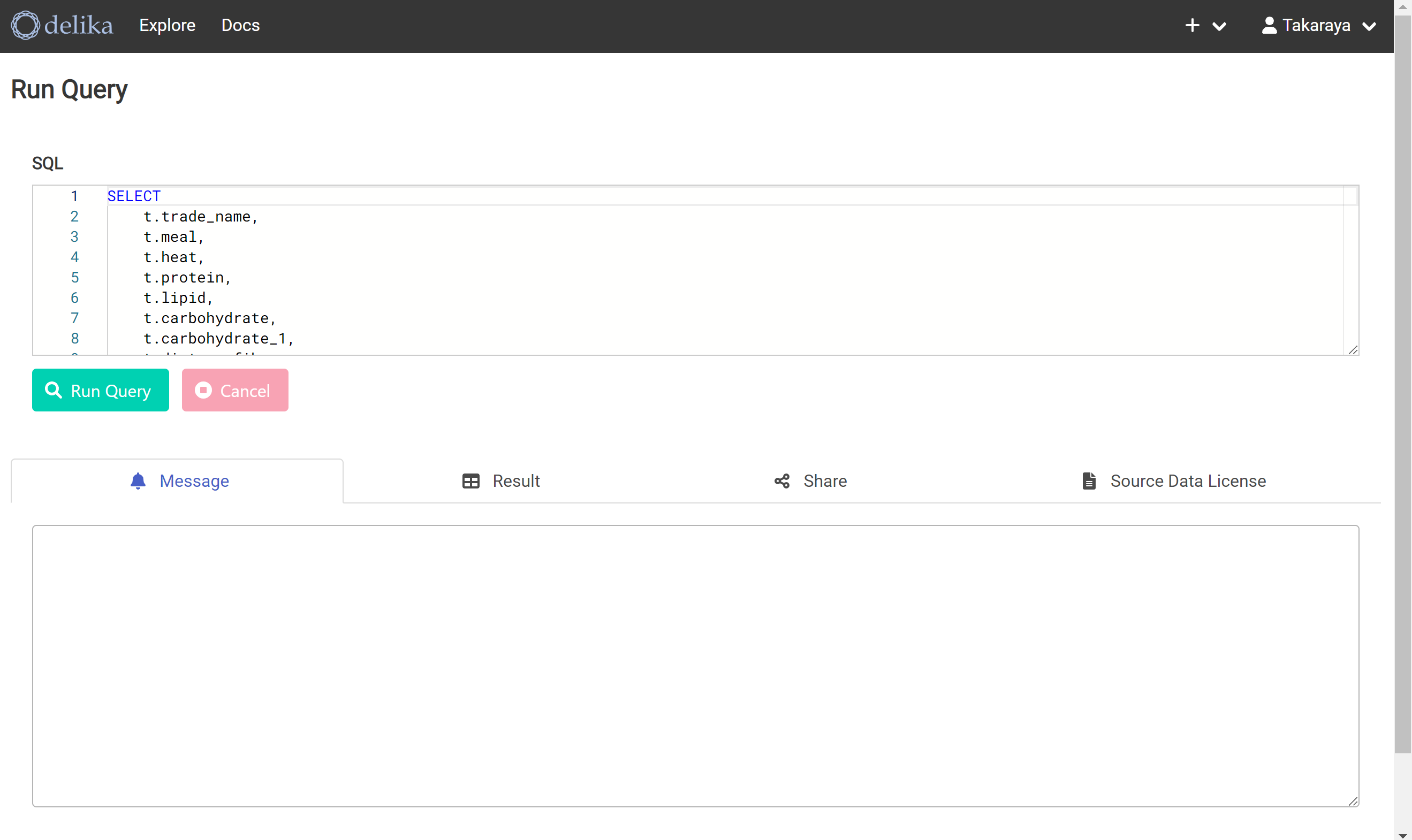
以下のクエリーが入力されていた。

Run Queryを押す。
Resultを押す。おー。ちゃんと抽出できた。
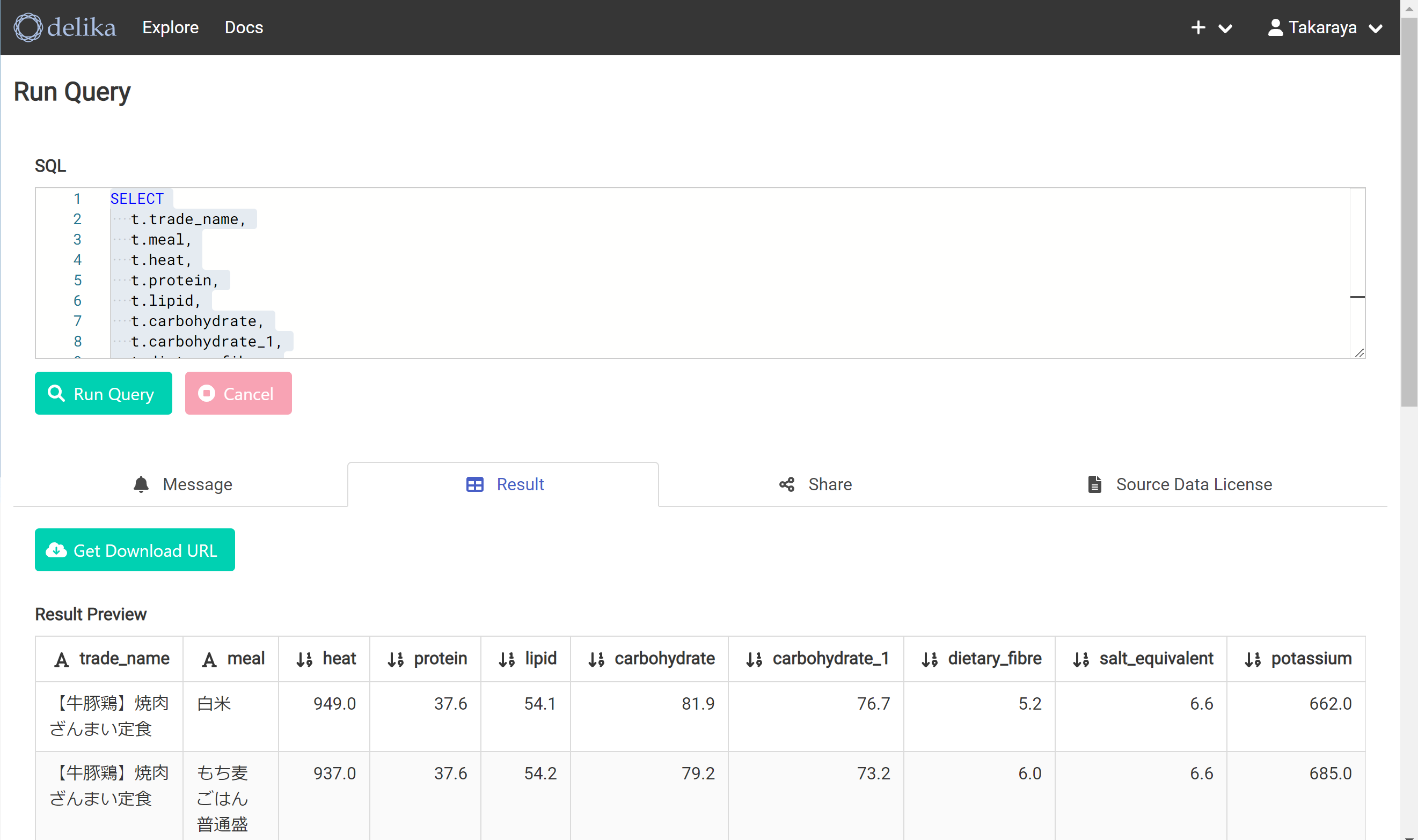
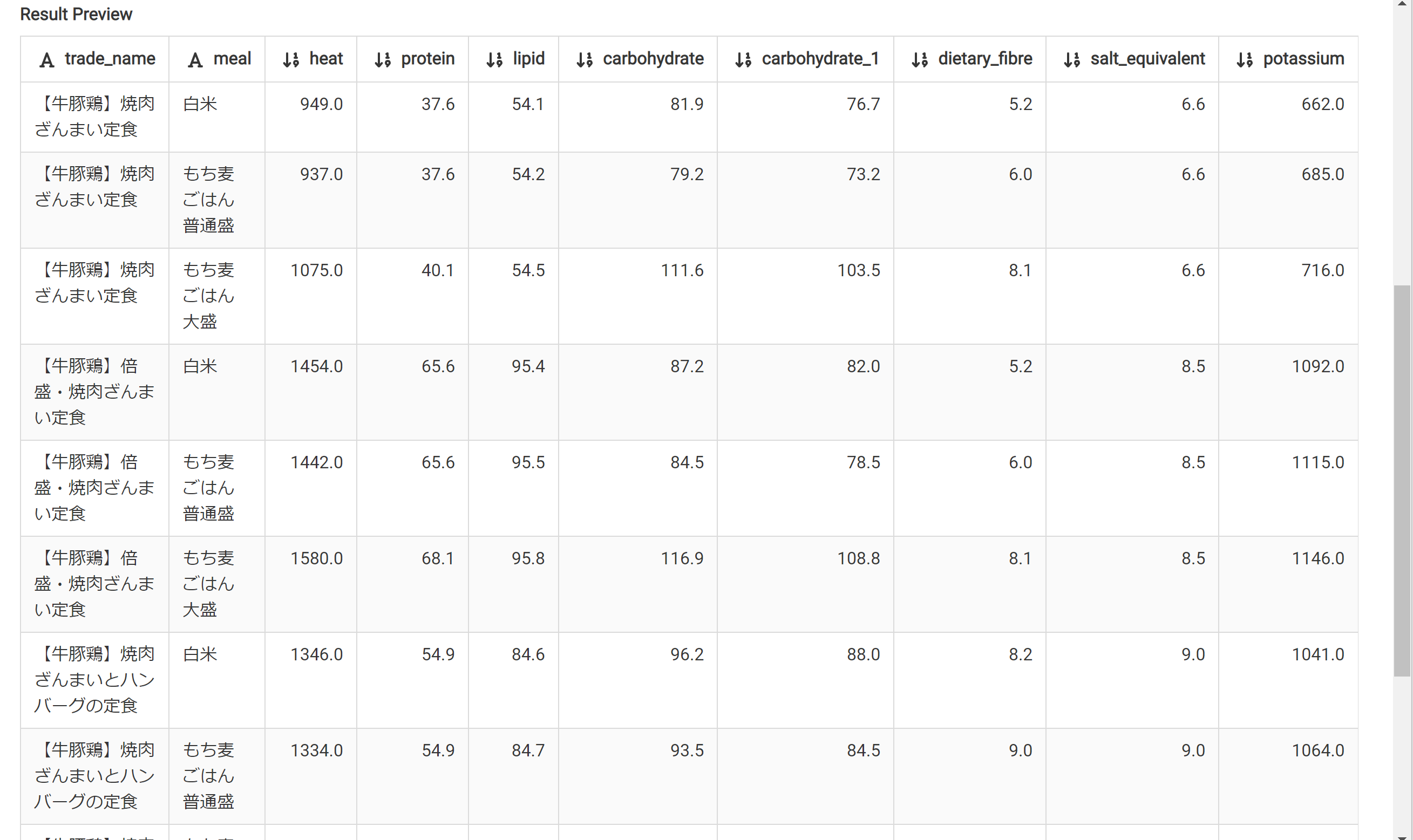
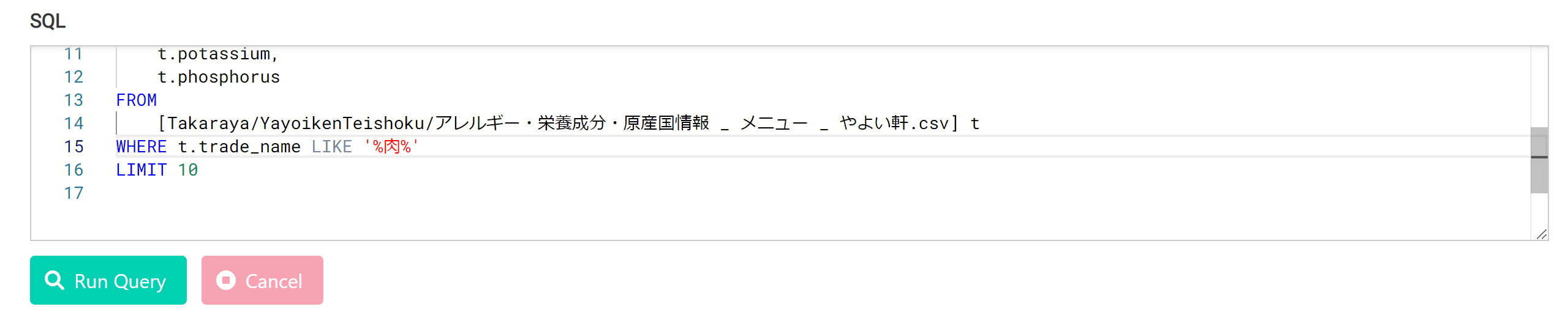
メニューに「肉」の文字があるものを抽出する。
カロリー高い。

メニューに「魚」の文字があるものを抽出する。

魚を選べば、1000Kcalは超えないようだ。
カロリー順に並べてみようとしたが、Freeプランではできないようだ。
800Kcal未満を抽出してみる。しょうが鍋定食がカロリー低くて、よさそうだ。
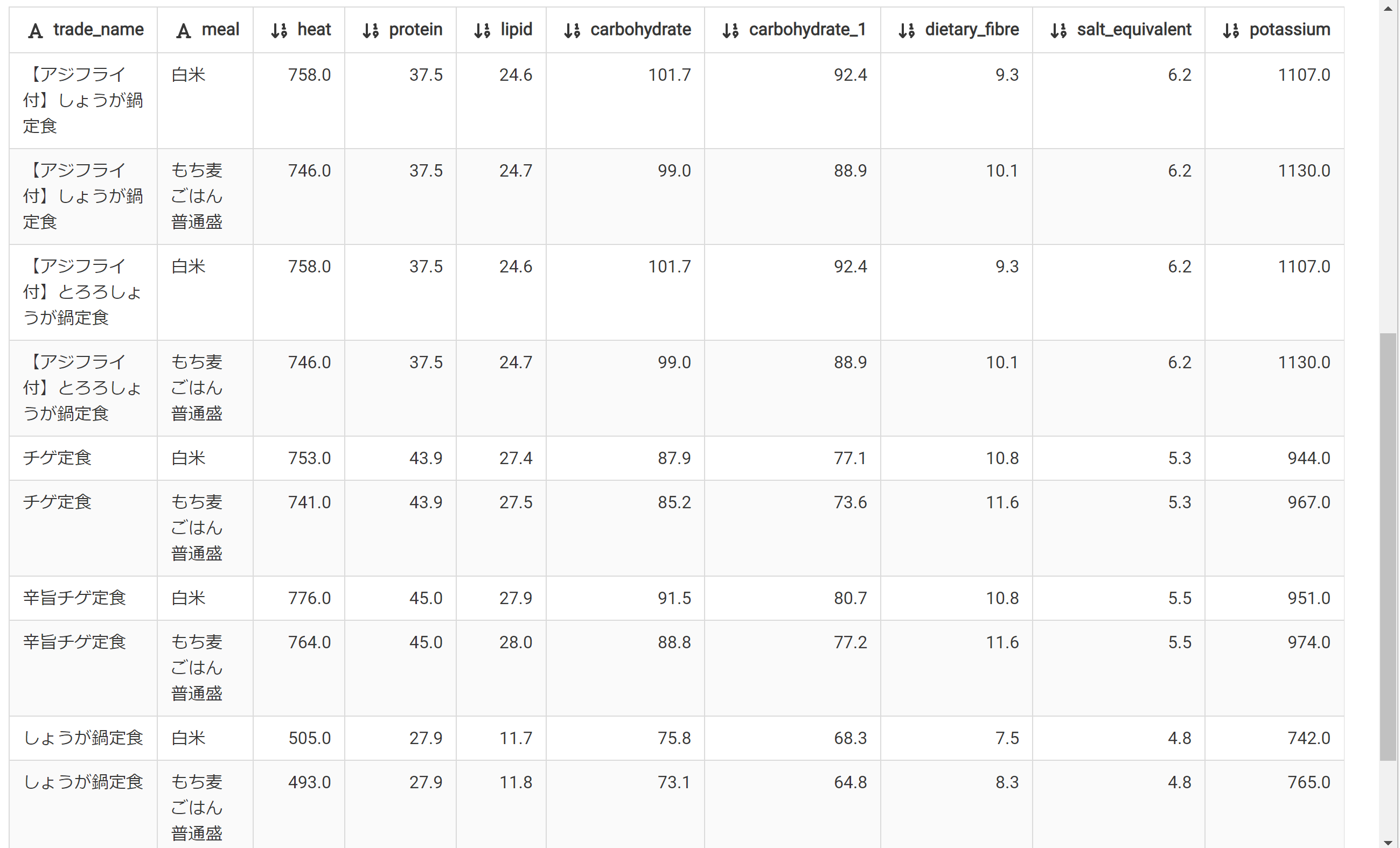
とういうわけで、やよい軒の定食のカロリーデータをdelikaに登録できた。
カロリーデータの取得とdelikaへの取り込み すき家
次はすき家 PDF形式だ。
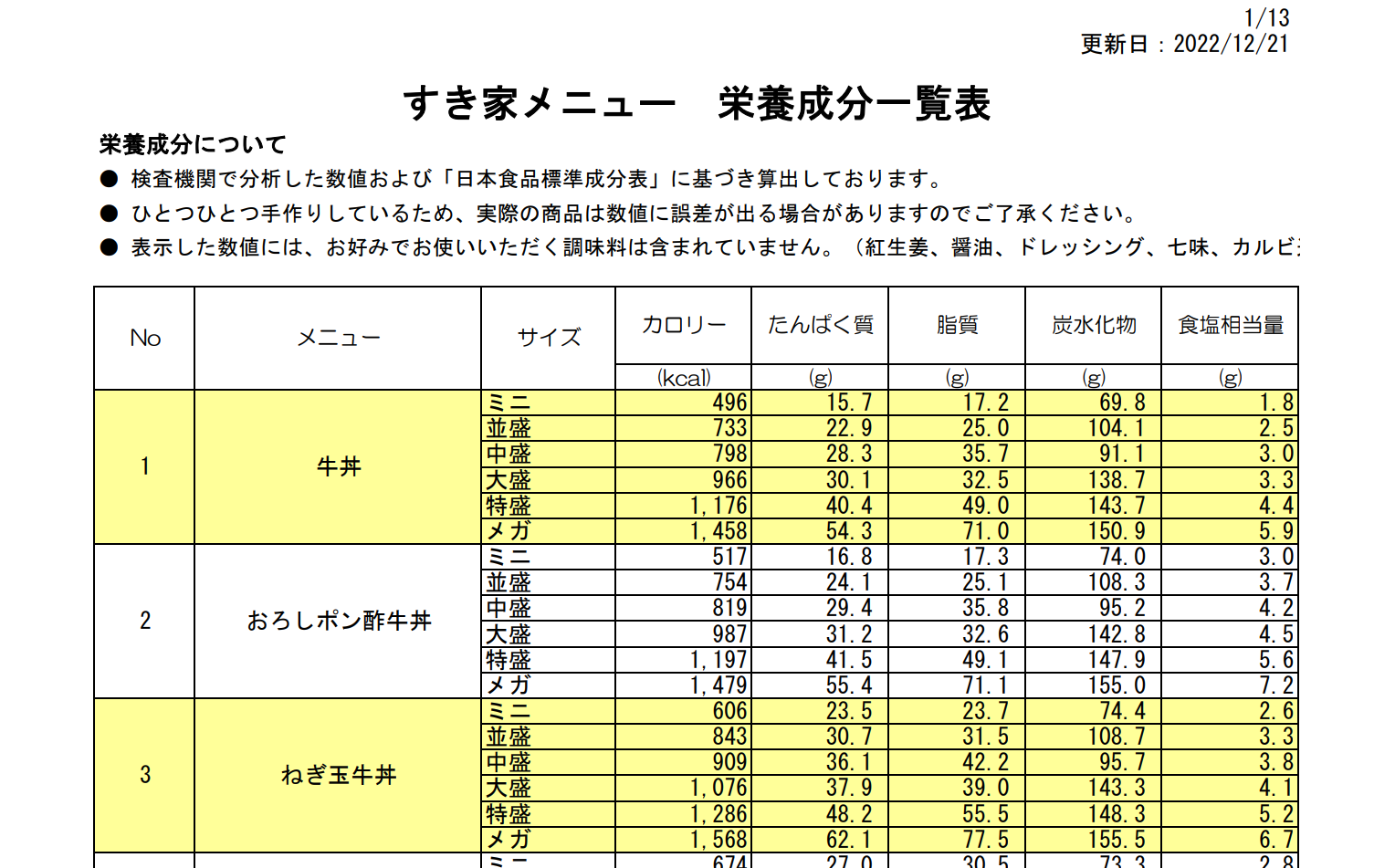
どうしたものか、PDF。Excelでとりこんでみよう。
「データ」-「データの取得」-「ファイルから」-「PDFから」を選ぶ。

PDFファイルを選ぶ。
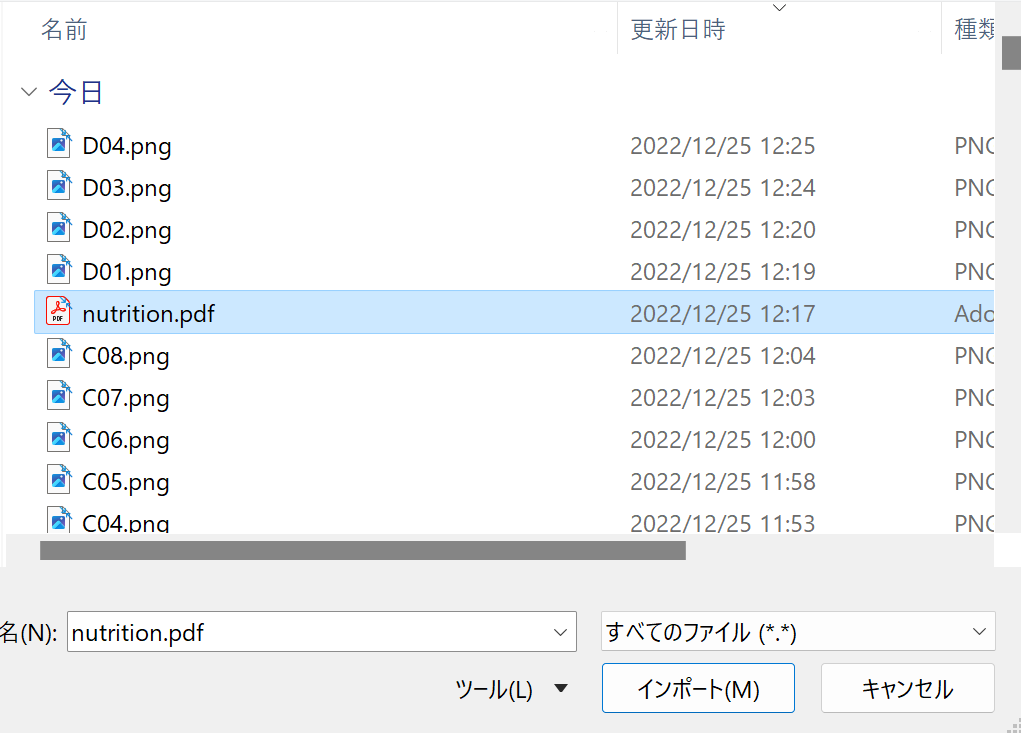
ナビゲーターが表示される

Table001を選ぶ。おお、良さそう。「読み込み」を押す
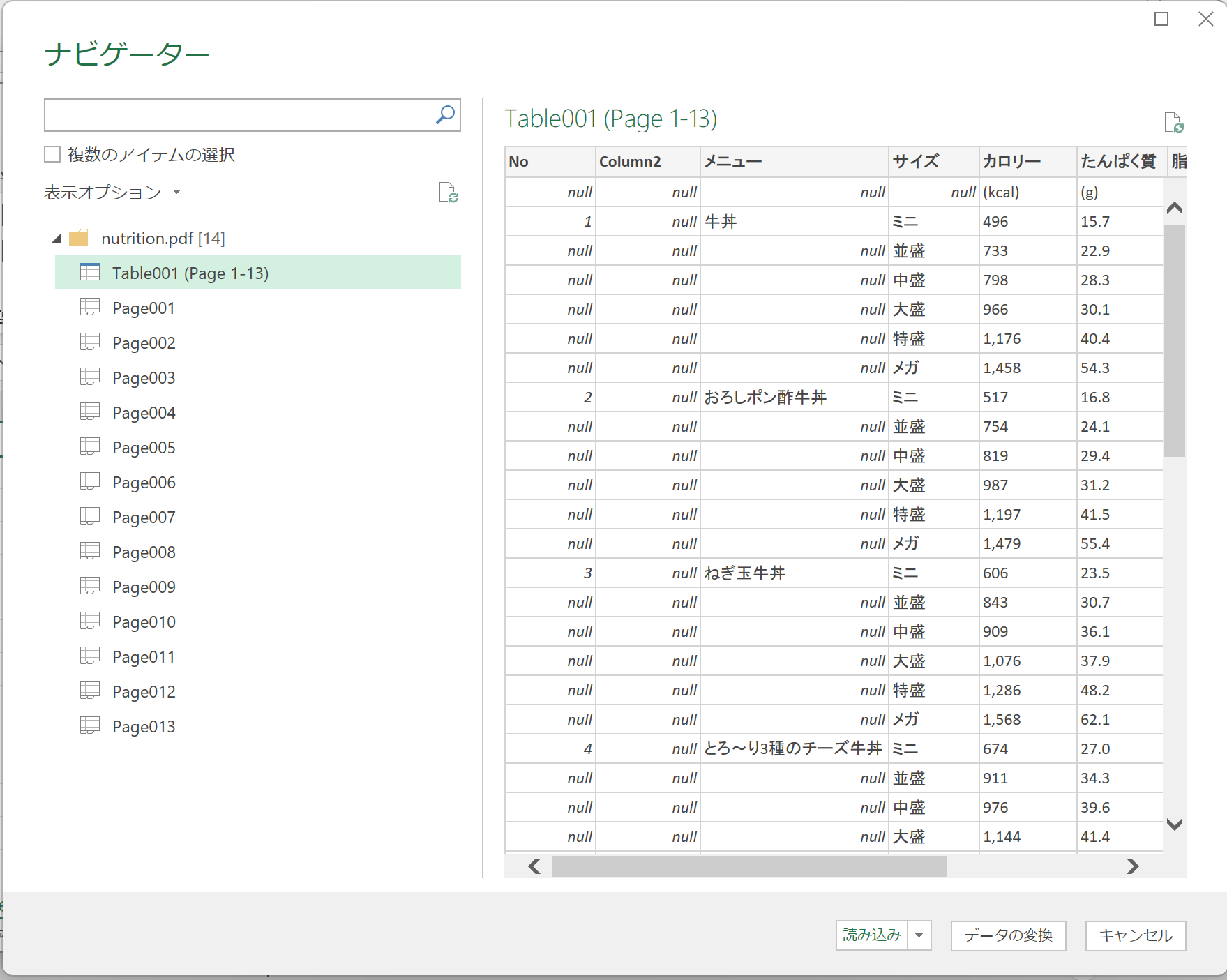

読み込まれた。でもB列が空欄。下の方の行をみてみる。
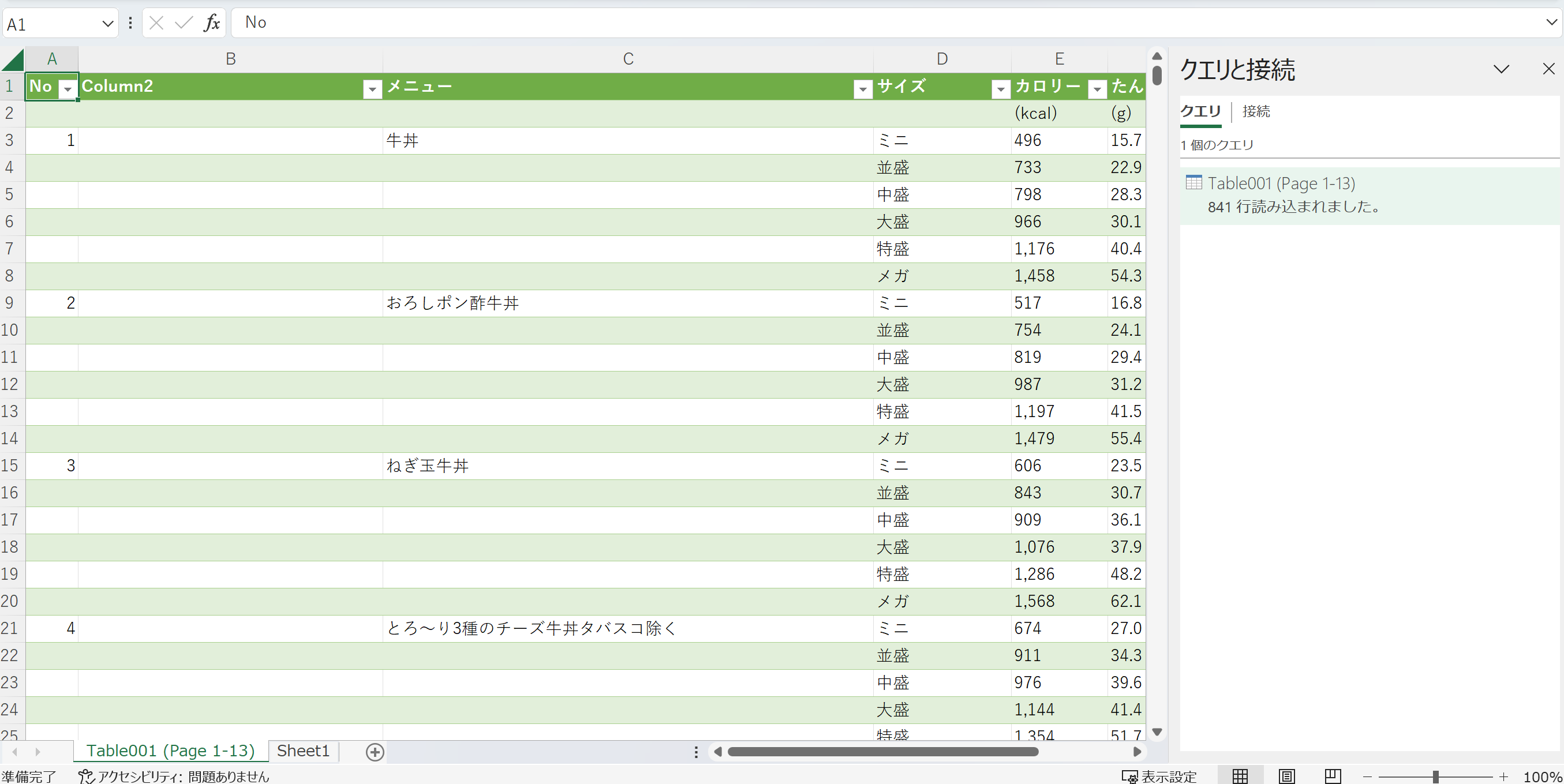
んん?どうなってるの?
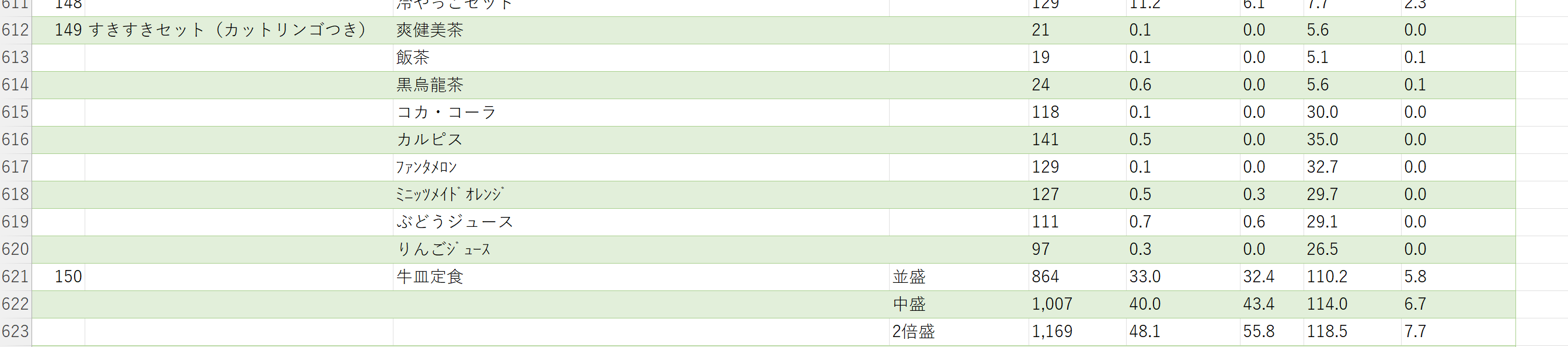
元のPDFをみてみる。これは・・・w。すきすきセット(カットリンゴつき)
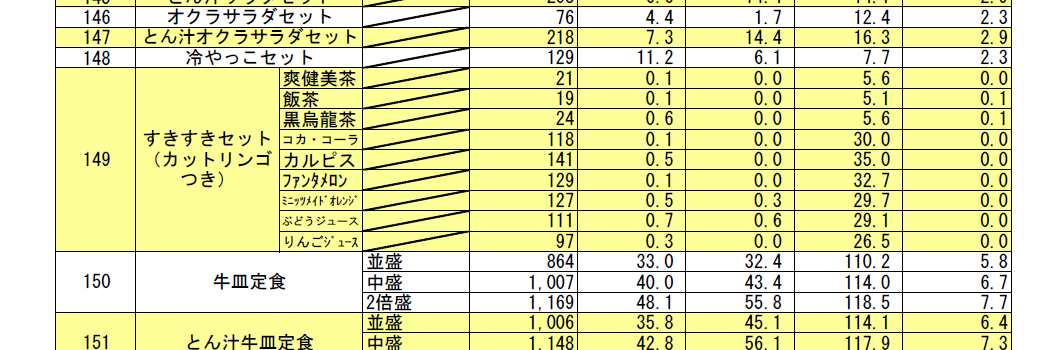
「すきすきセット(カットリンゴつき)」はC列に手動でコピーして移動する。
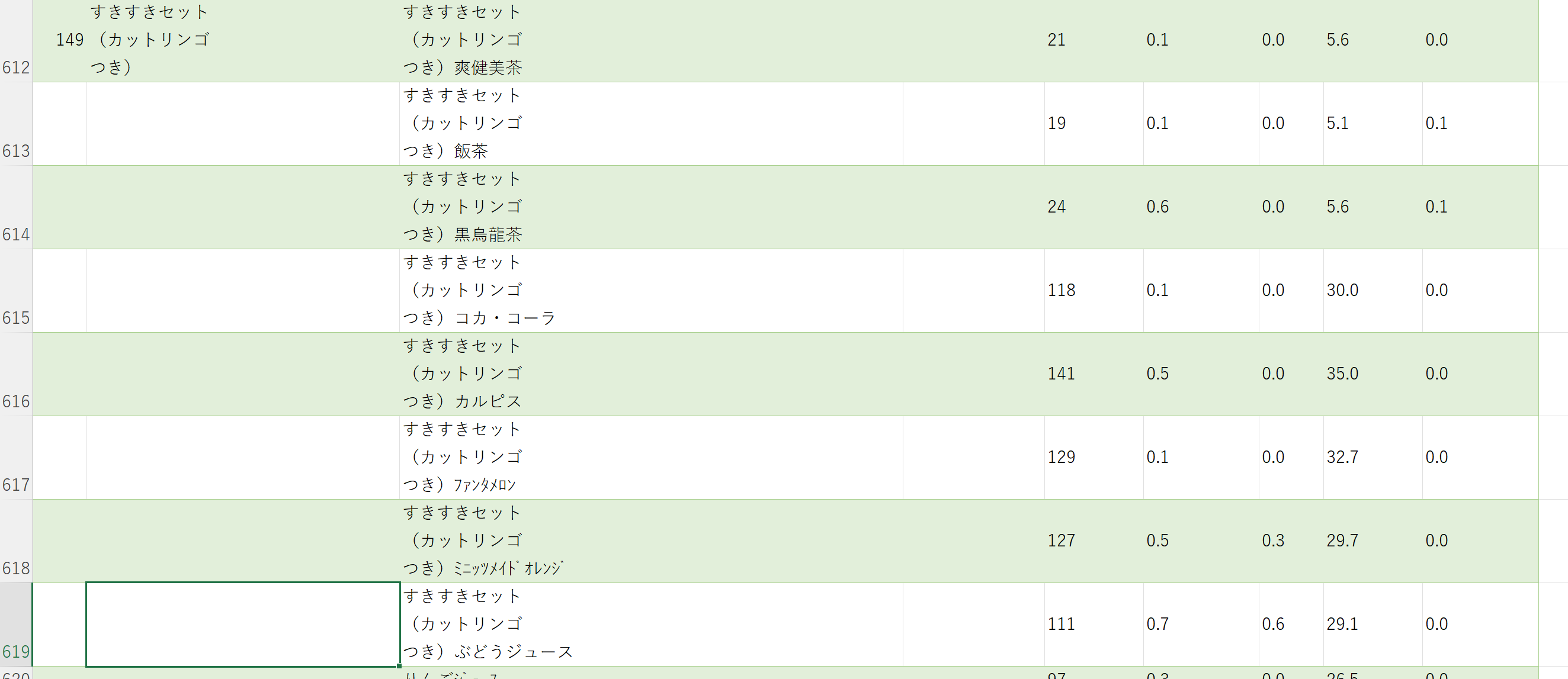
B列は削除する。
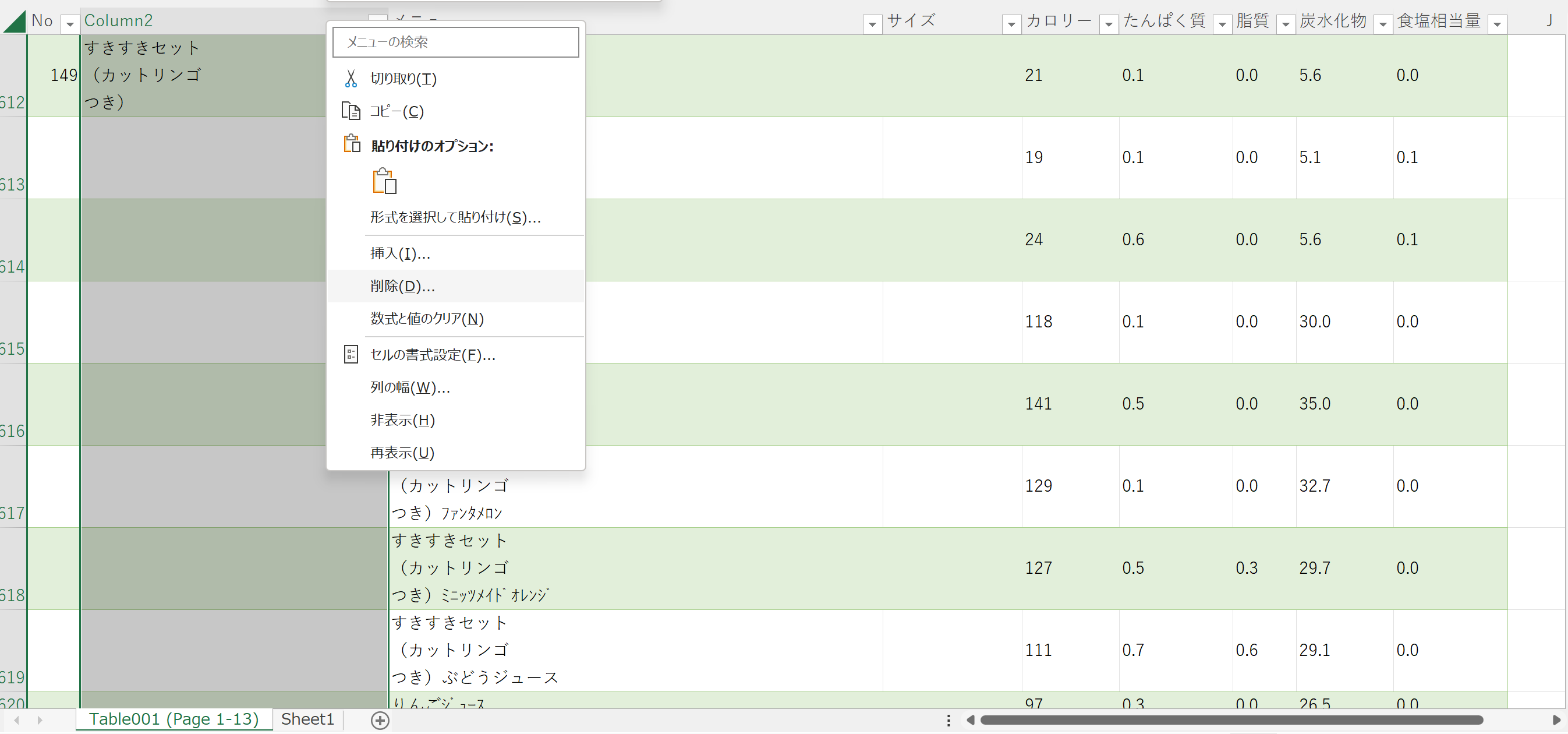
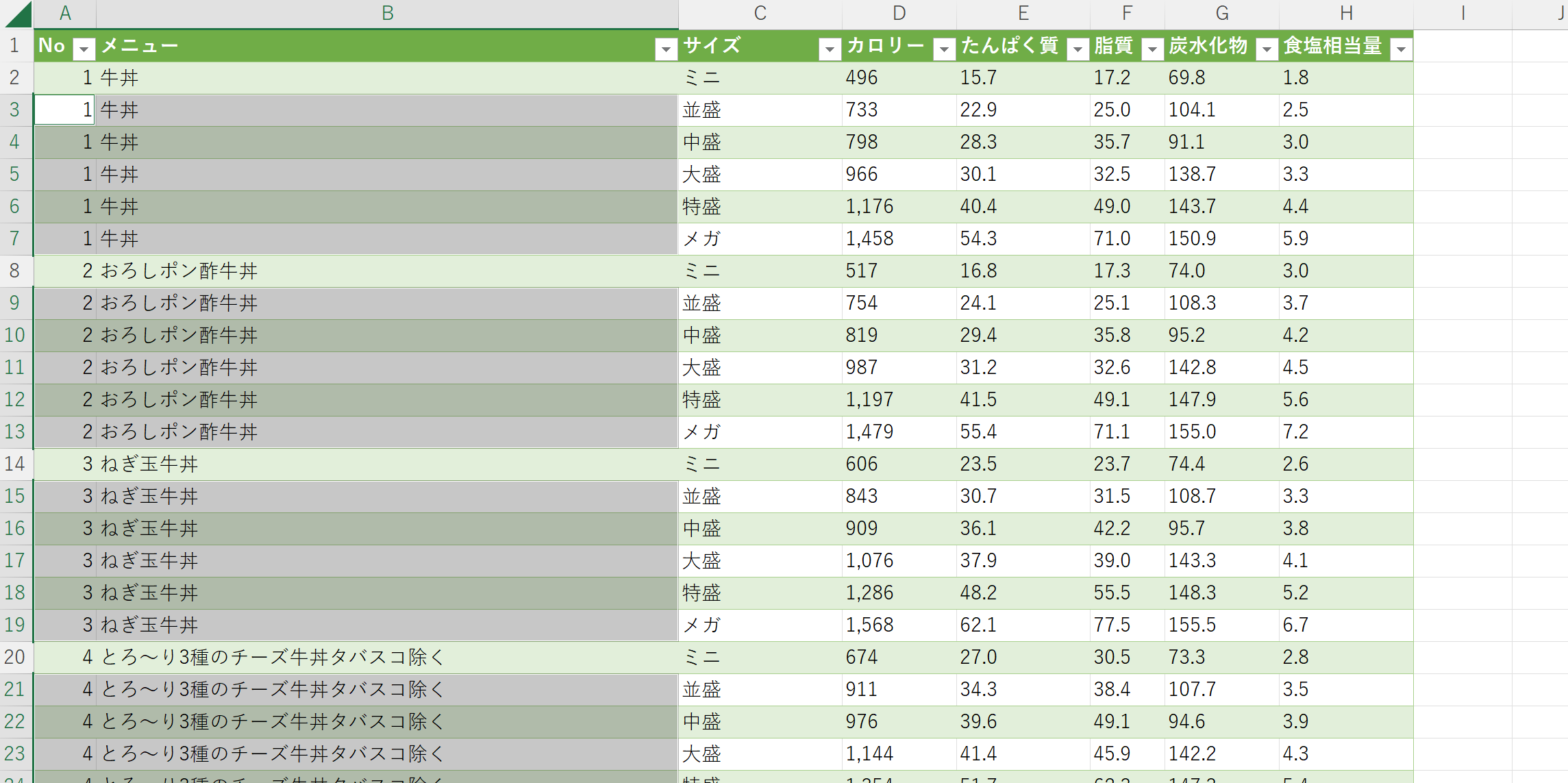
やよい軒の時と同じ操作で空白セルを埋める
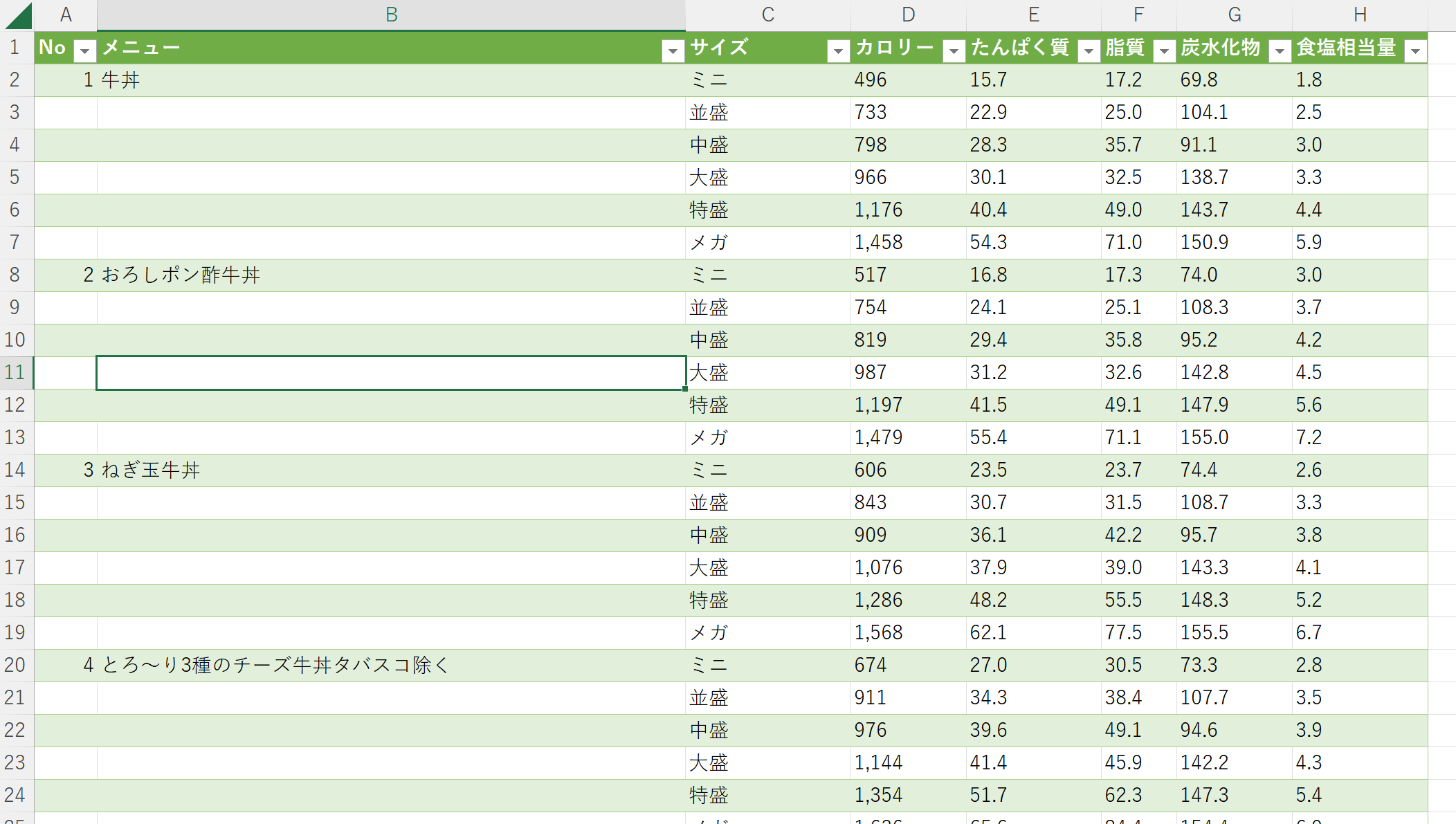


空白セルが埋まった。
CSVファイルに保存する。

やよい軒の時と同じ操作でdelikaに取り込む。んん?文字化け?
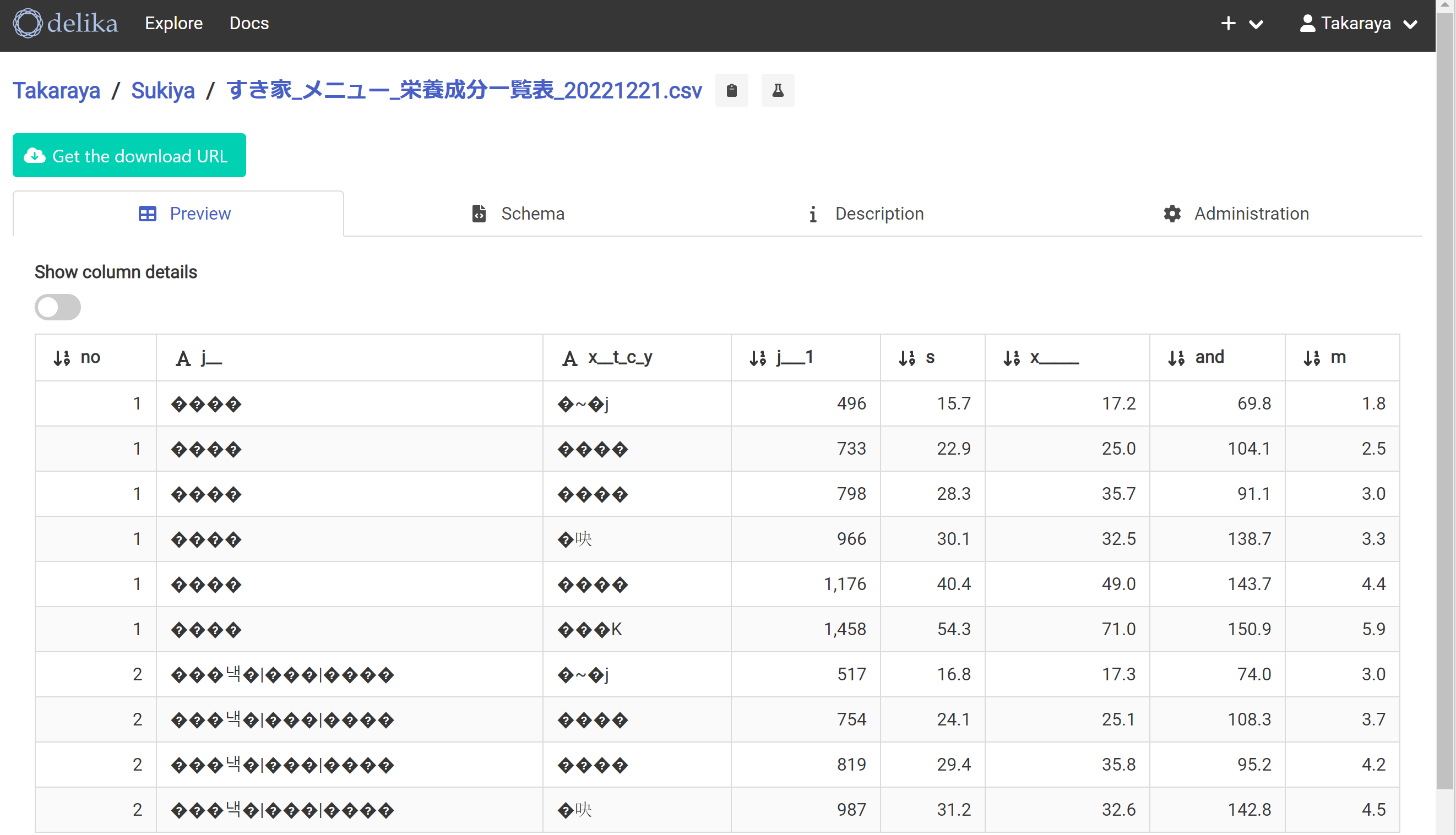
ここでファイルの種類の選択を間違えていた
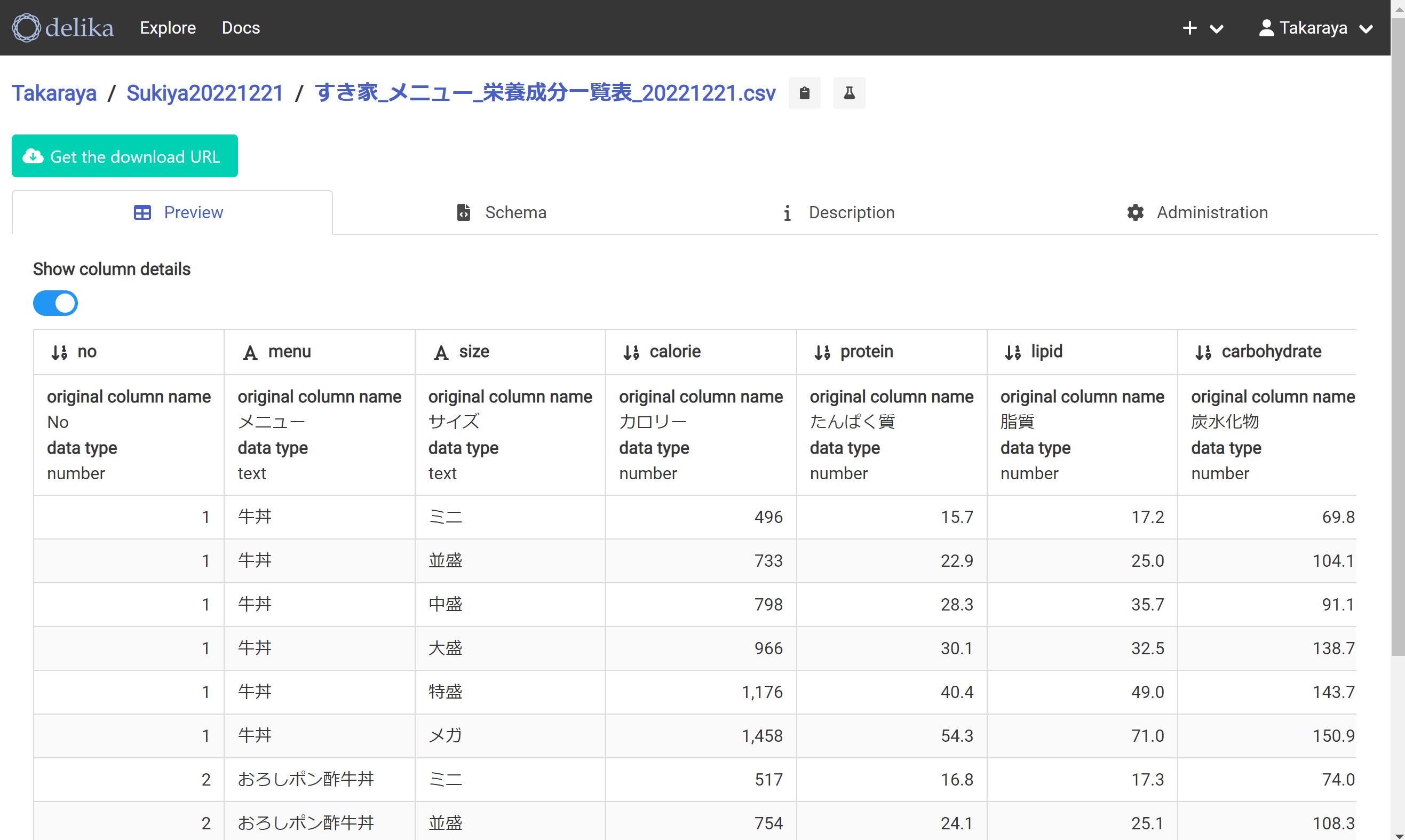
正しくはこちら

こちらのCSV形式では正常に表示された
クエリーを投げてみる
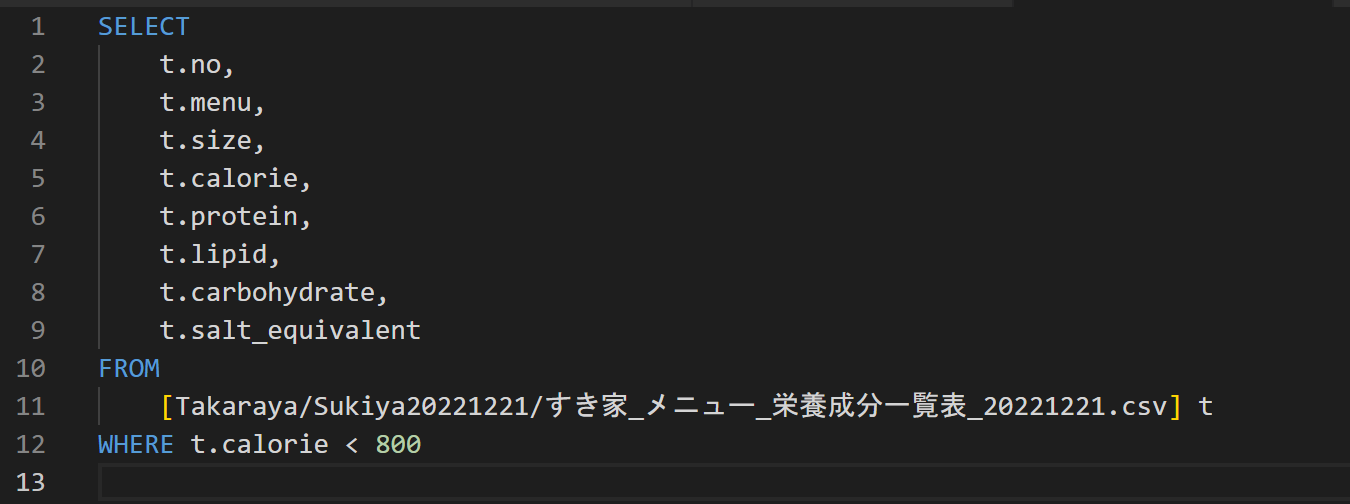
んん?下から4行目から2行目の列がずれている・・・
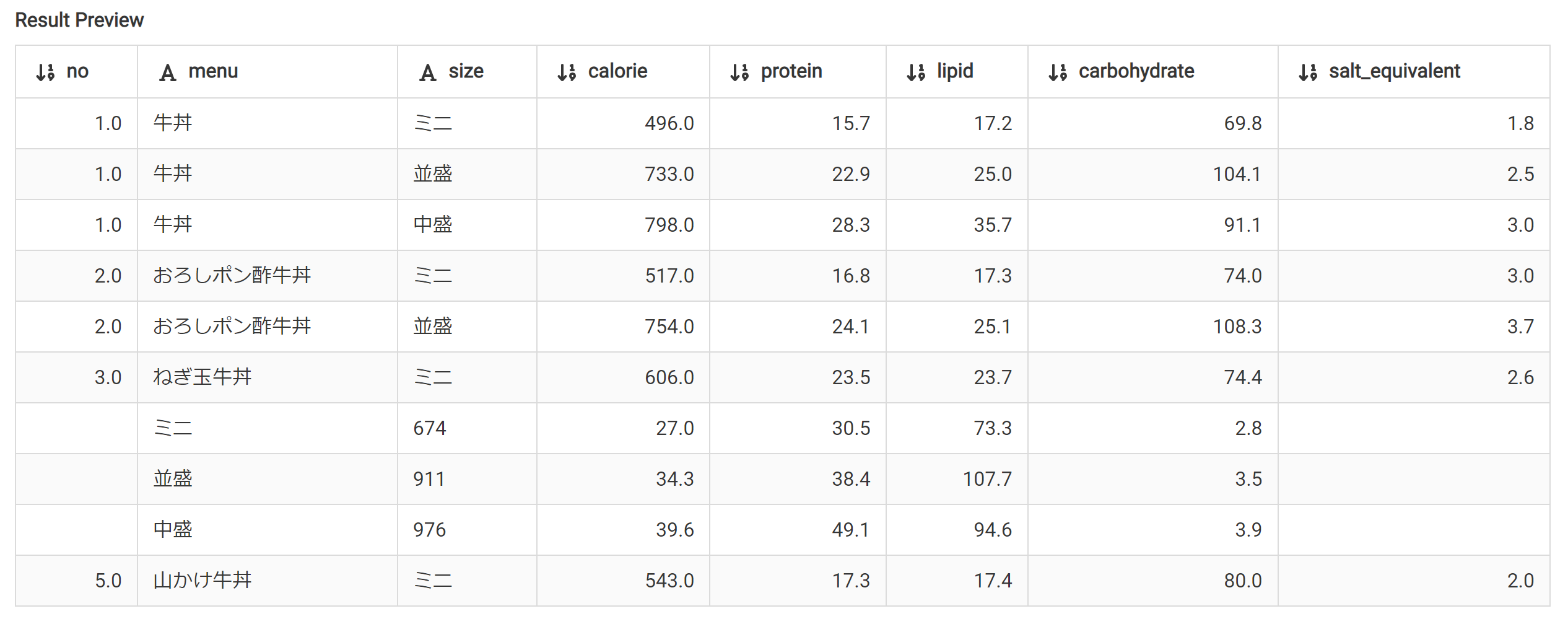
該当箇所を確認してみると、改行が入ってしまっているようだ。
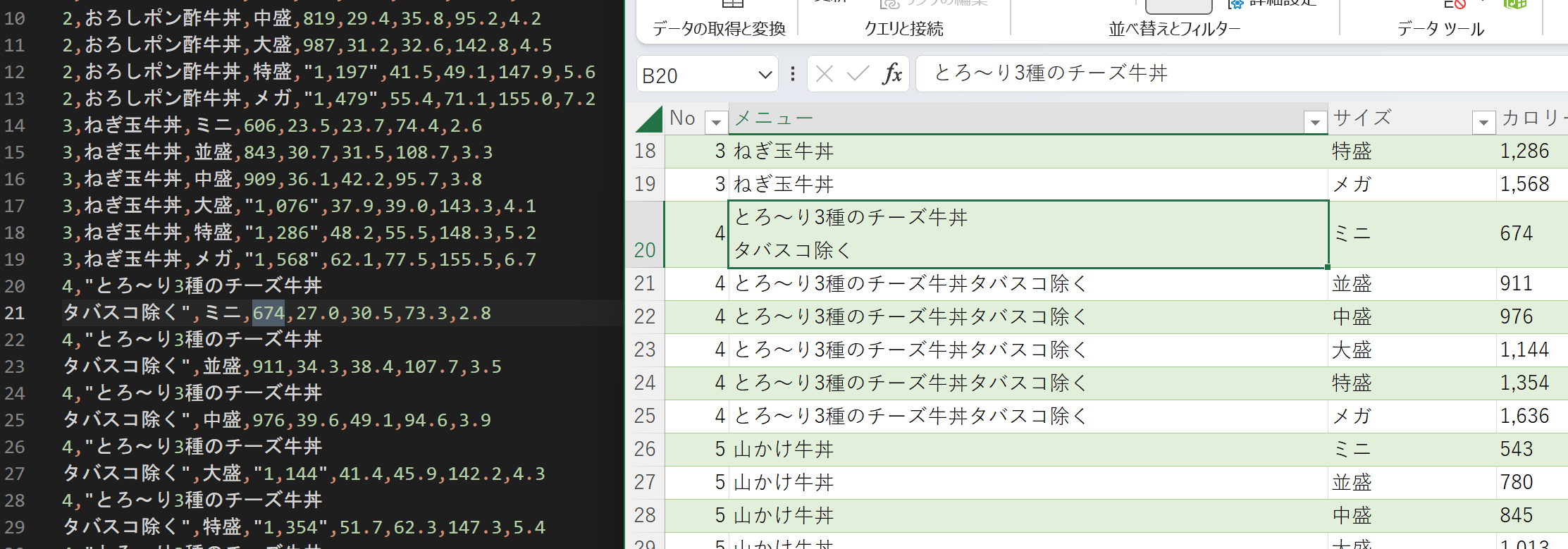
新しいシートに、改行を削除したものを作る。新しいシートのA1セルに以下のように入力し
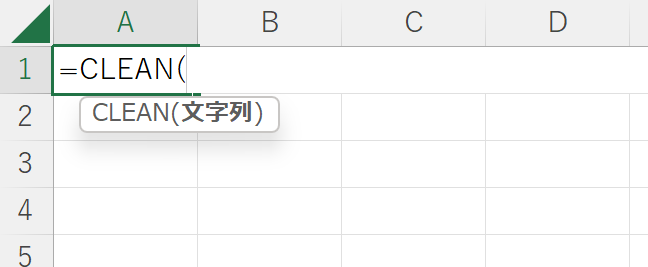
元のシートのA1セルを選択して
Enterを押す。

新しいシートの1行目全体にコピー

2行目も同様。



最後の行まで行全体をコピーする
最後の部分が元のものと一致しているか確認。

新しいシートをCSV形式で保存する(今度はファイルの種類(エンコーディング)を間違えない、UTF-8を選ぶ)

テキストエディタで開いて改行されていないことを確認。
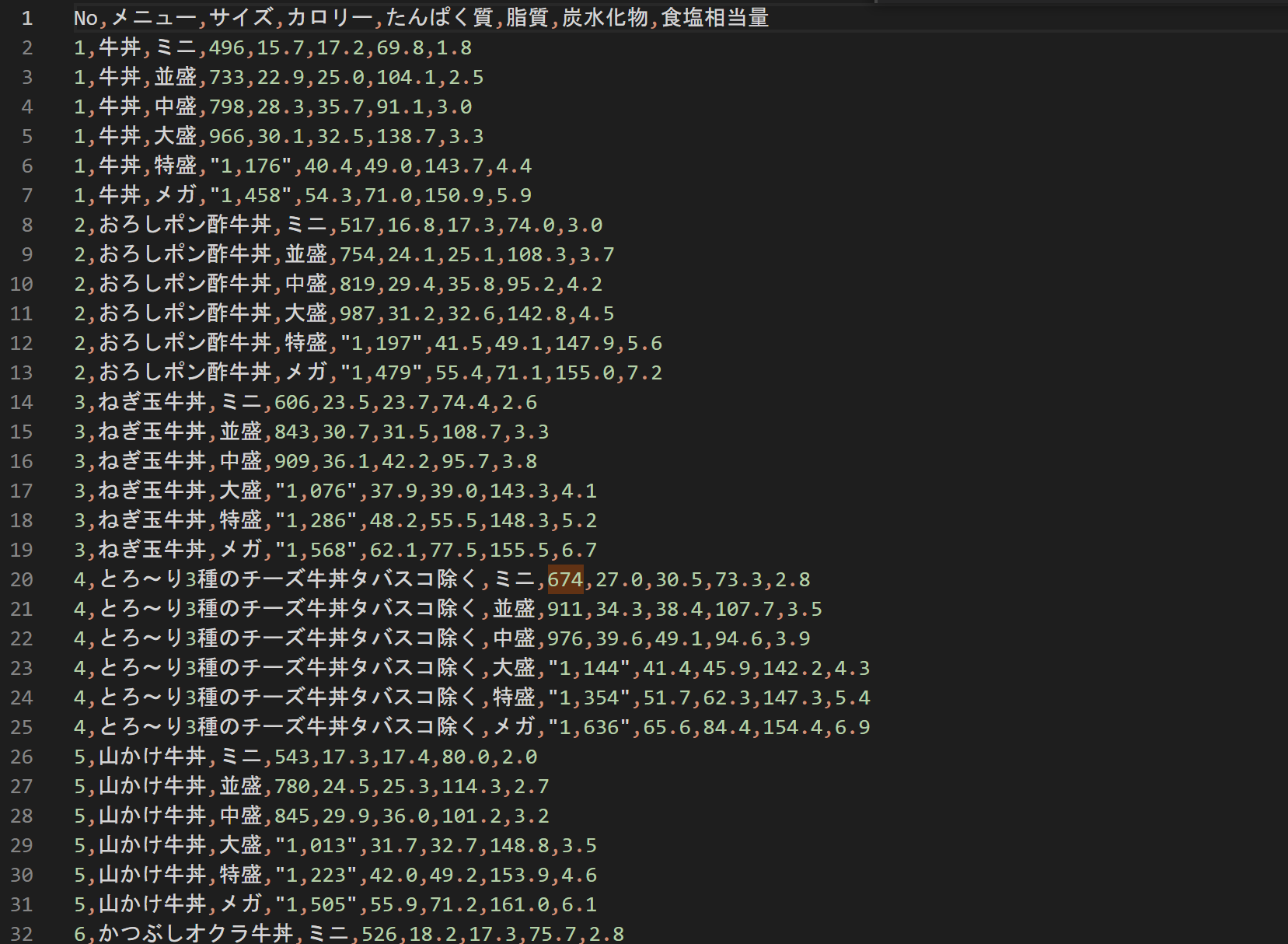
delikaに取り込んでクエリーを投げてみる。

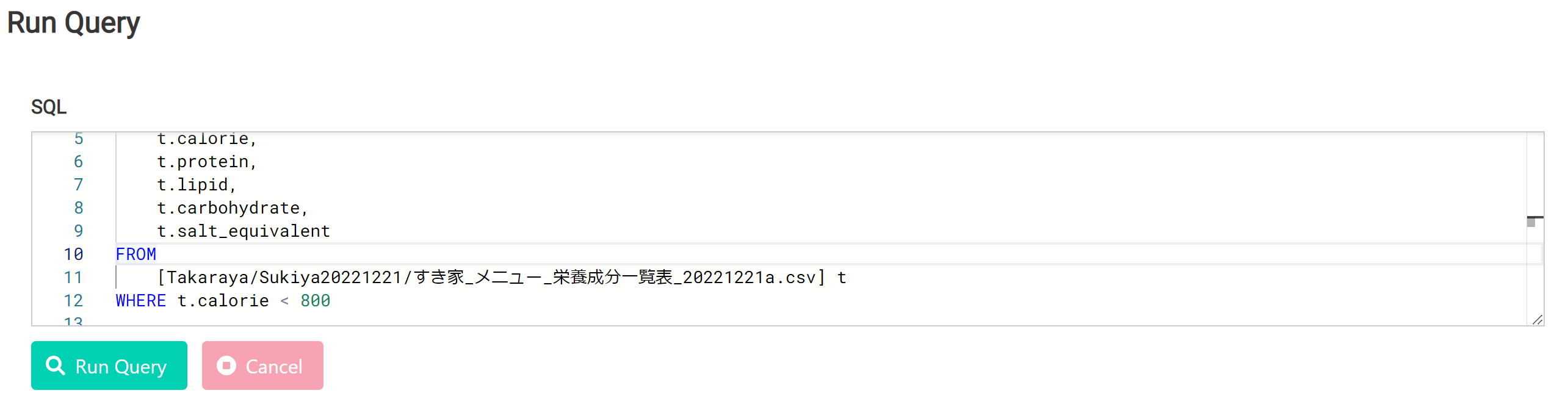
今度は列がずれていない。すき家もdelikaへの取り込み、大成功!
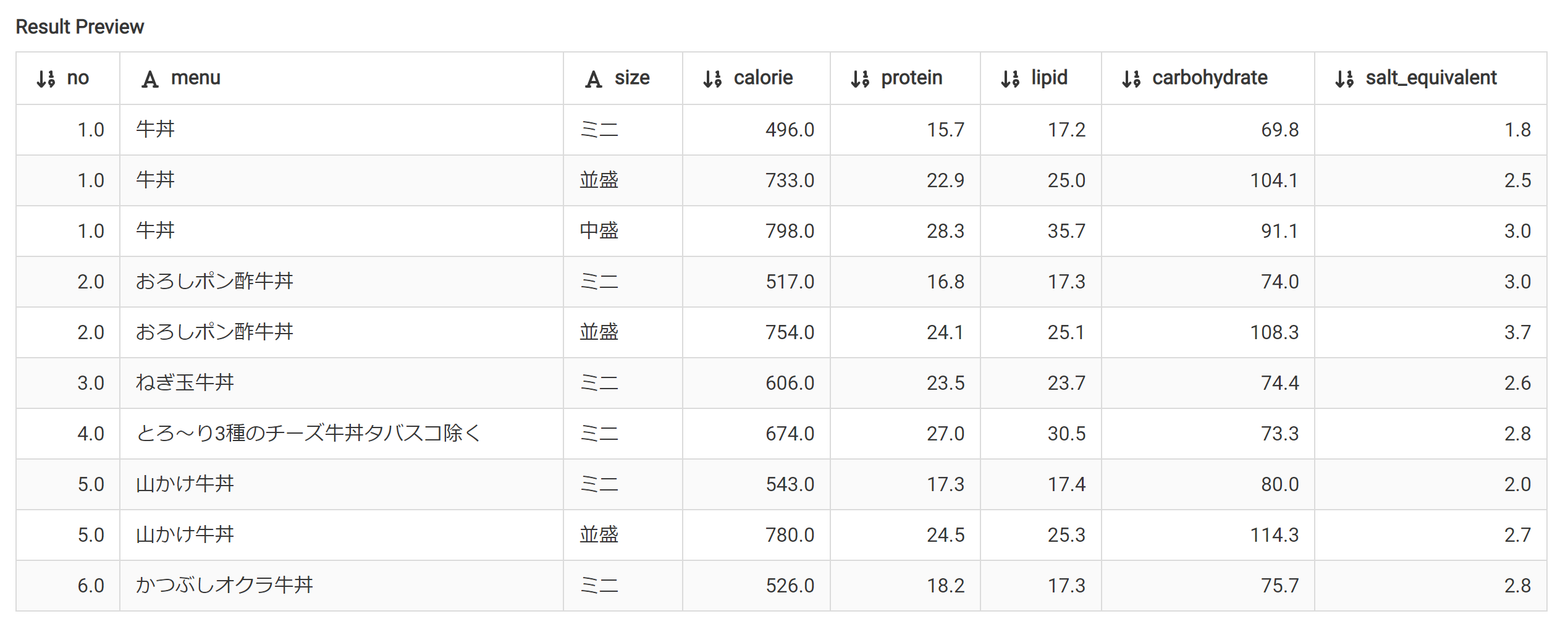
カロリーデータの取得とdelikaへの取り込み スシロー
カロリーはどこかにまとまって記載があるかな?
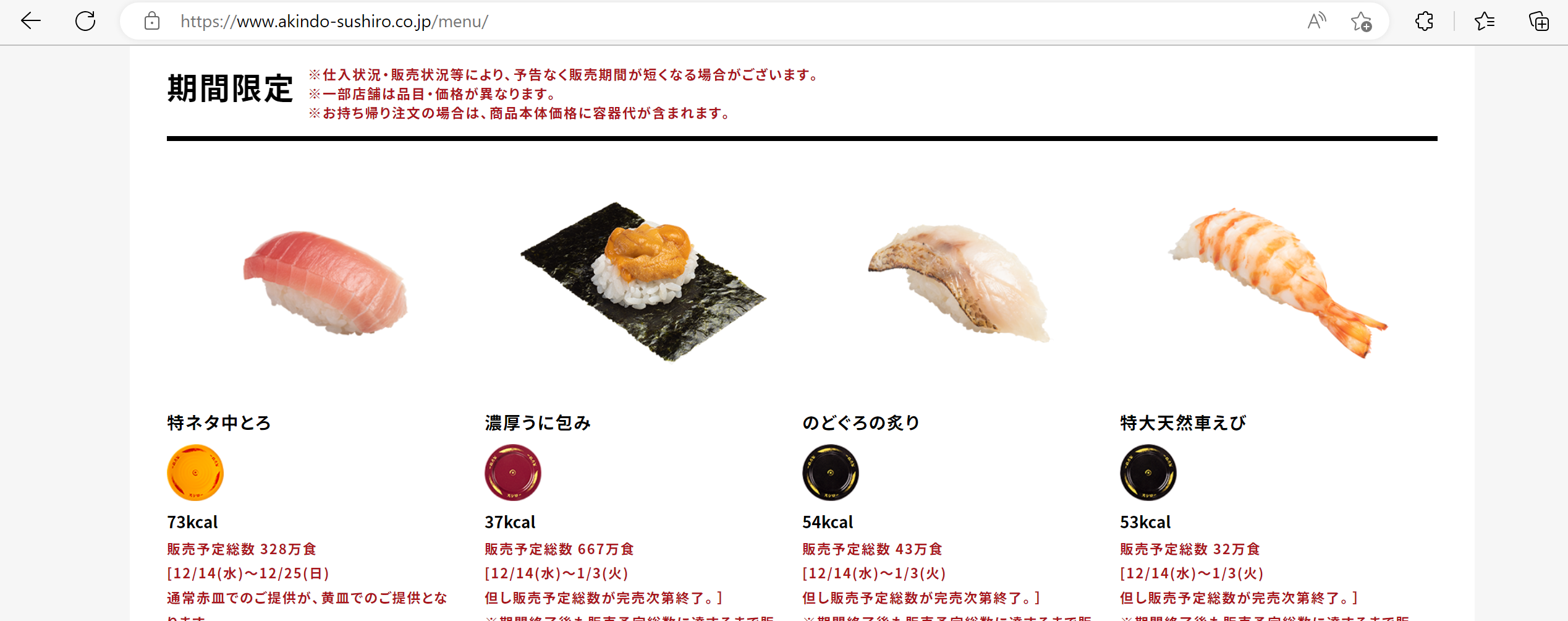
「「スシローのメニュー」から商品ごとに確認することができます」の記載。
これは、もしや一つづつ取得するしかない?
がーーん。Excelで横着できないじゃないか・・。
これ一個づつ取得するしかなさそう・・・。
Scrapyを使ってみる。
スシローのメニューのWebページの構造を確認して、メニューの名称とカロリーの箇所のXPathを求める。
Chromeのその他ツールから「デベロッパーツール」を選ぶ
右側に表示されているこのアイコンを押す。

カロリーの箇所をクリックする。
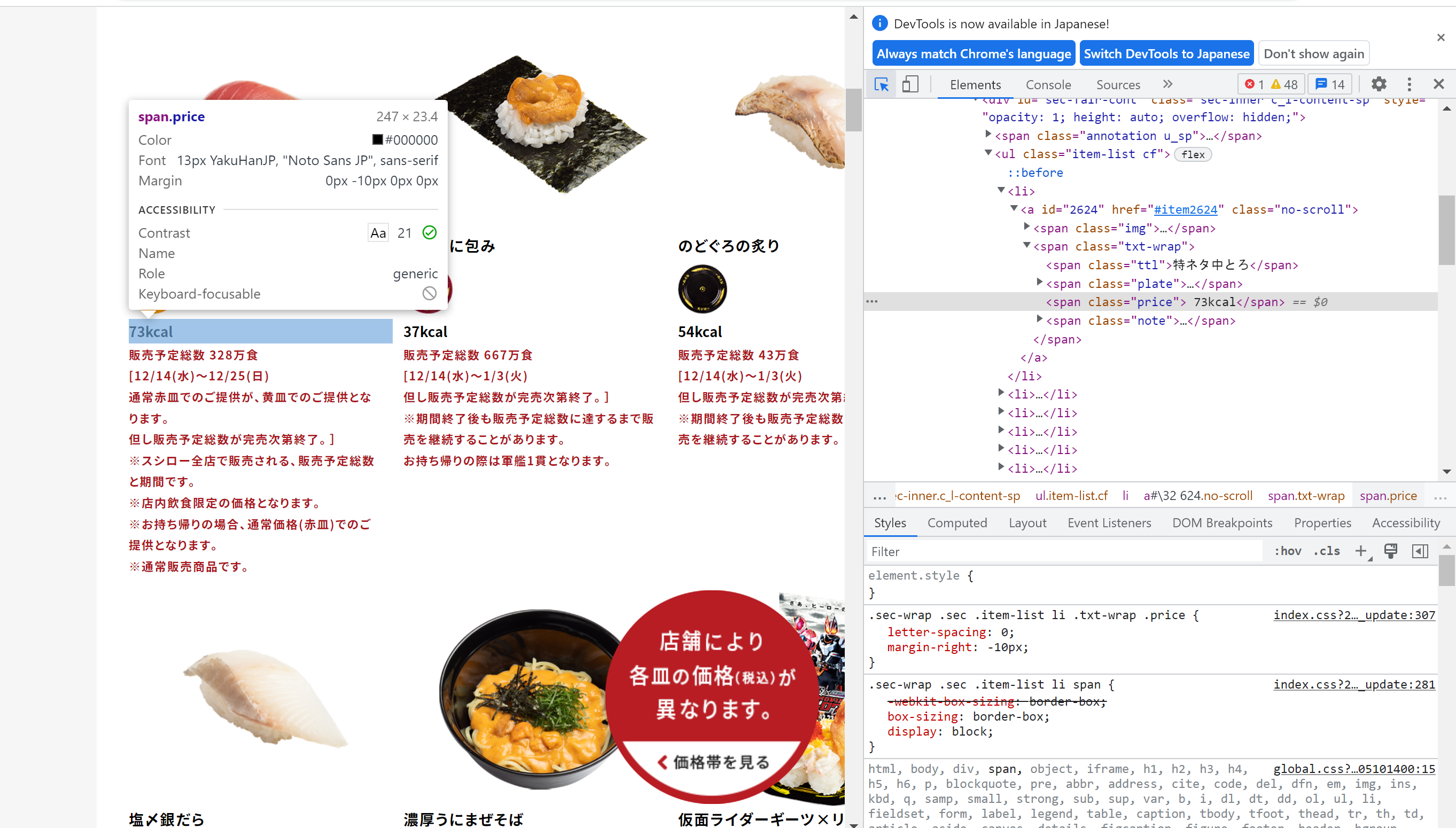
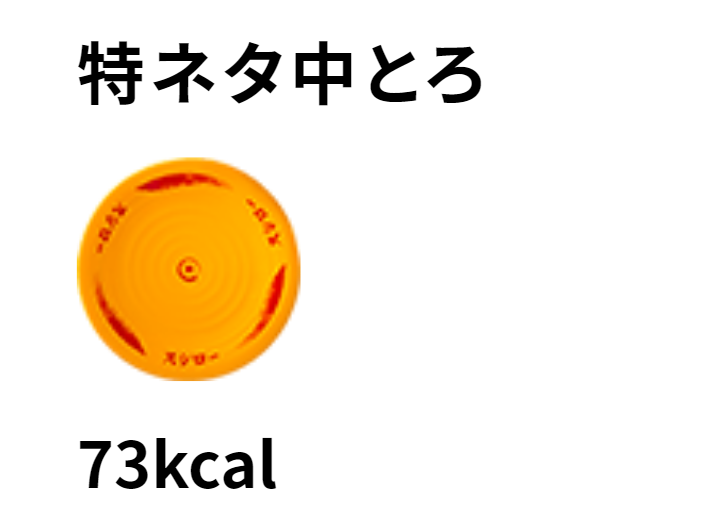
XPATHは //span[@class="price"][position()=last()]/text() で良さそう。

タイトルの箇所をクリックする。
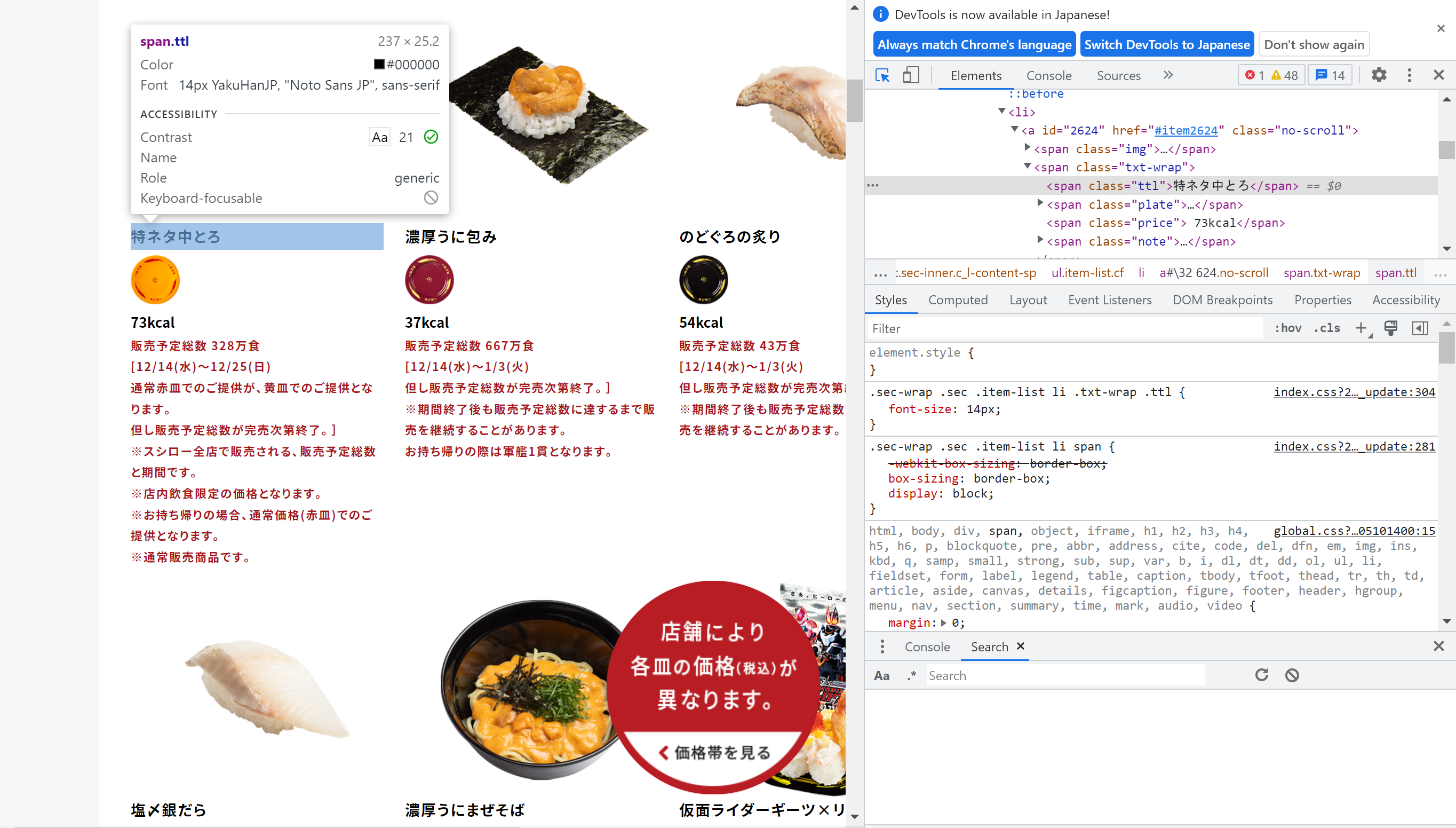
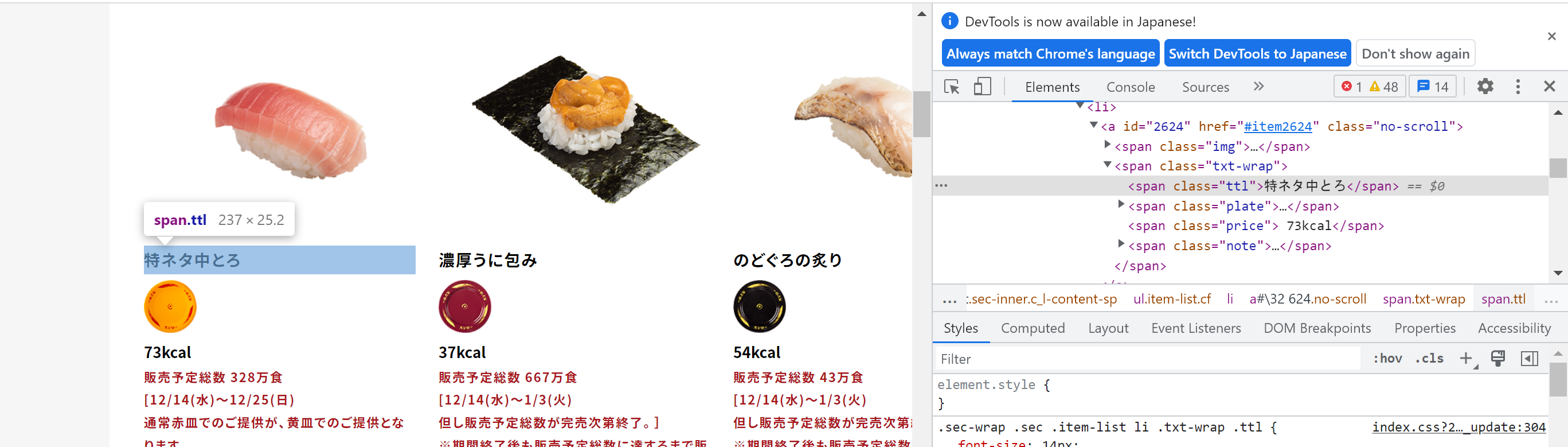
XPATHは //span[@class="ttl"]/text() で良さそう。

Scrapyをインストールする。
$ pip install scrapy
$ scrapy version
Scrapy 2.7.1
プロジェクトを作成する。
$ scrapy startproject susiro
New Scrapy project 'susiro', using template directory '/Users/takaraya/opt/anaconda3/envs/scrapy_env/lib/python3.8/site-packages/scrapy/templates/project', created in:
/Users/takaraya/pythonscrapy/susiro
You can start your first spider with:
cd susiro
scrapy genspider example example.com
$ cd susiro
$ scrapy genspider susiro_menu www.akindo-sushiro.co.jp
Created spider 'susiro_menu' using template 'basic' in module:
susiro.spiders.susiro_menu
susiro_menu.pyを開く
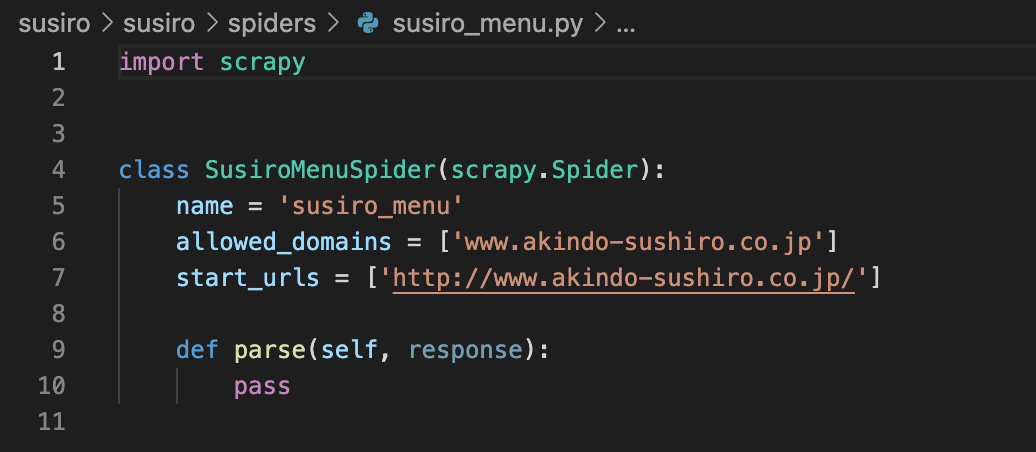
start_urlsをスシローのメニューのURLに修正する httpsに注意。
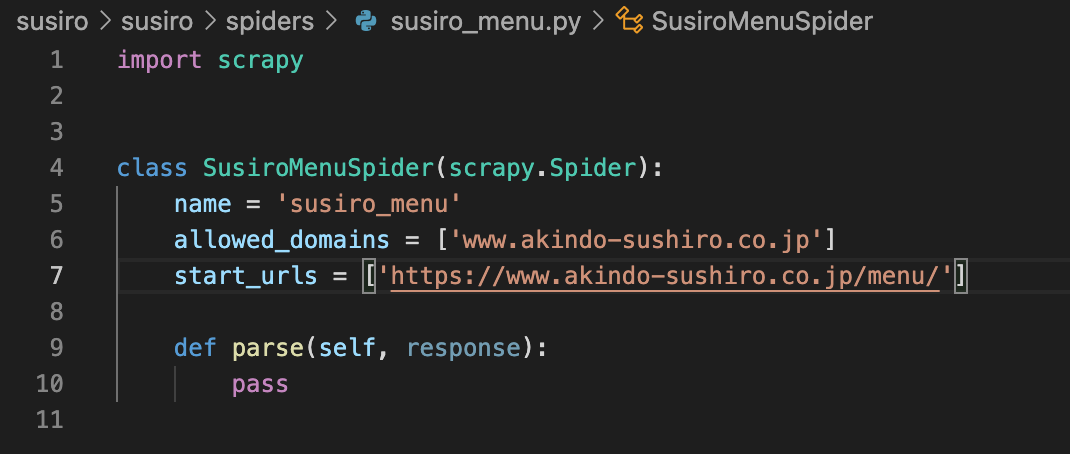
def parseの中にさきほどchromeで調べてXPATHで、メニューとカロリーを取得するコードと、CSVで書き出すコードを追加する。

susiro_menu.pyを拡大すると以下のような内容。
import scrapy
class SusiroMenuSpider(scrapy.Spider):
name = 'susiro_menu'
allowed_domains = ['www.akindo-sushiro.co.jp']
start_urls = ['https://www.akindo-sushiro.co.jp/menu/']
def parse(self, response):
menu = response.xpath('//span[@class="ttl"]/text()').getall()
cal = response.xpath('//span[@class="price"][position()=last()]/text()').getall()
data = yield {
'menu' : menu,
'cal' : cal
}
for menu, cal in zip(menu, cal):
print('"'+menu+'","'+cal+'"')
以下のコマンドでクロールを実行する。
$ scrapy crawl susiro_menu>susiro.csv
保存されたsusiro.csvを開いて、Webページと照合する。正しく抽出されているようだ。
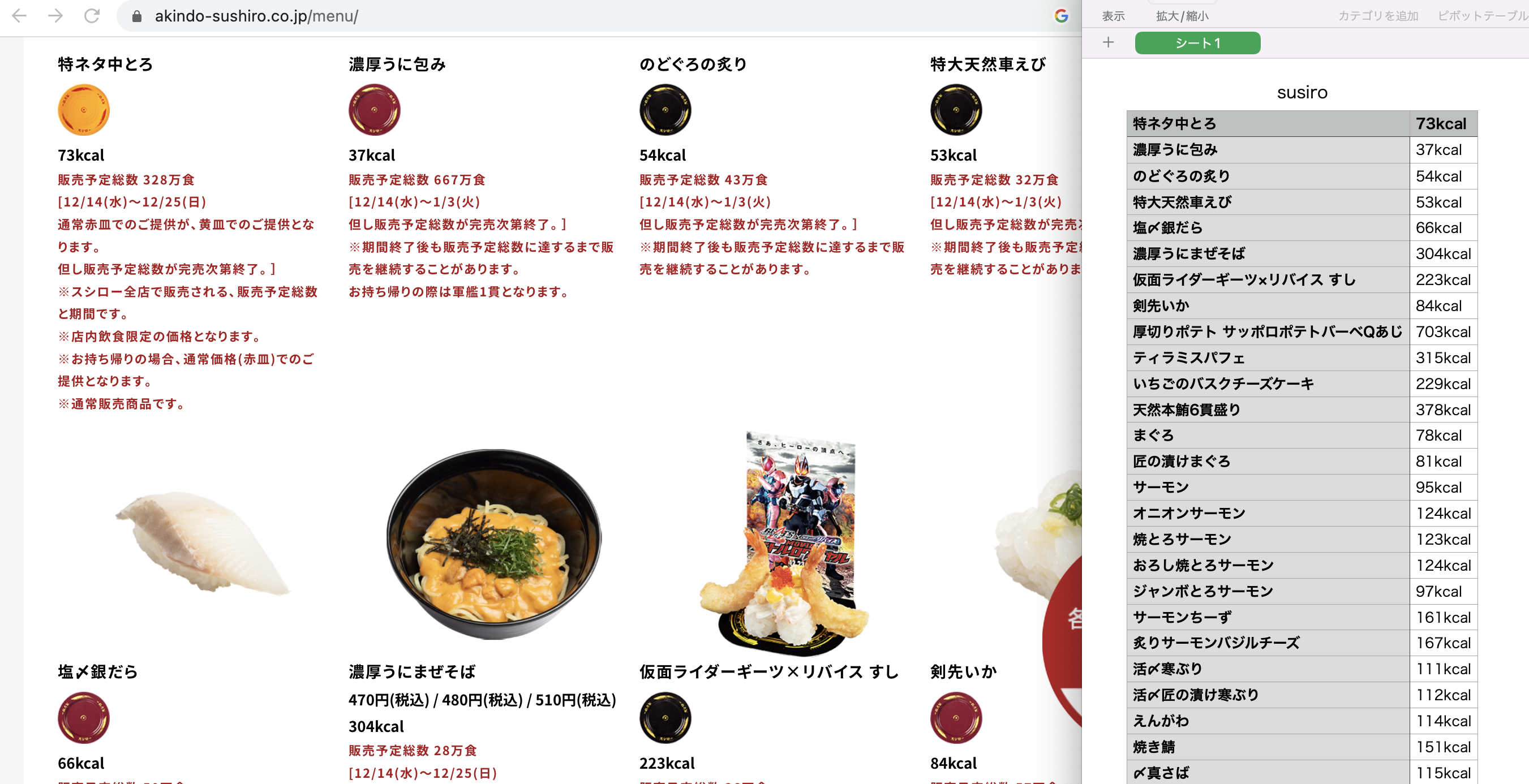
最後の部分も確認する。正しいようだ。
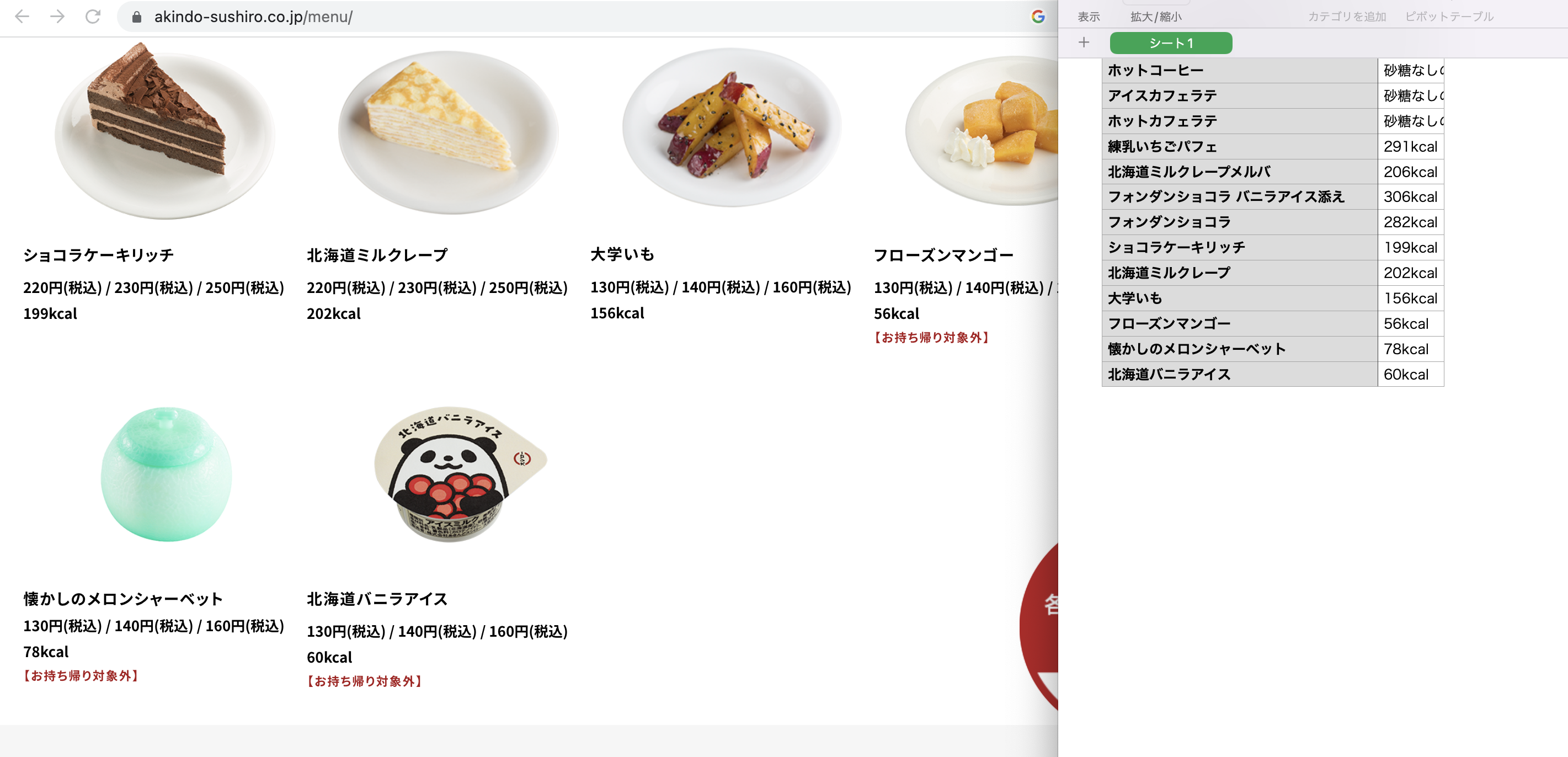
CSVファイルを開いて1行目に列名menuとcalを追加してcsv形式で保存する。

delikaに取り込む。スシローもうまく取り込めた。

あー、おなかがすいた。
まとめ
カロリーの記載が、やよい軒はhtmlの表、すき家はPDFの表、スシローはWebページ内にバラバラに存在と、それぞれまちまちな形式でしたが、いずれも、簡便な方法で、うまくスクレイピングして、delikaに取り込むことができました。
最初は手間取りますが、慣れればそんなに時間はかからず、取り込めそうです。
これでメタボにならないメニュー選びもできるかも。
delikaは、非常に分かりやすく、取り込みが容易でした。
みなさんもさまざまな外食のチェーンのカロリーを取り込んでいただき、活用させてもらえるとありがたいなと感じました。