はじめに
物体検出モデルの進展Part3になります。今回はFPN(Feature Pyramid NetとRetinaNet)とRetinaNetを紹介します。Part1, Part2の内容は知っている前提で話を進めていきます。
間違っている箇所がありましたらご指摘お願いします!
FPN(Feature Pyramid Net)
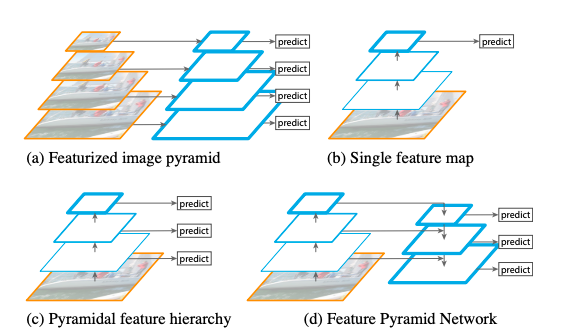
様々なスケールの物体を認識することは物体検出で大きな課題です。上図の(a)はfeaturized image pyramidを図示したものです。様々なスケールで画像を処理していく手法になります。これは物体のスケールが変わっても変化が生じない(scale-invariant)ですが、様々なスケールの画像を扱う必要があり計算に時間がかかってしまいます。またその上にDNNを用いることはメモリーの面からも現実的ではありません。そこで、ConvNetsで出力される特徴を利用したのが(b)Single feature mapです。Convnetsはスケールに対してロバストでインプットは画像一枚ですみますが、さらに良い精度が必要です。ConvNetsは各層でスケールの違う特徴階層(feature hierarchy)を生み出しています。このネットワークの中にある特徴階層は複数のスケールに対応できピラミッド型です。その特性を利用したのが(c)Pyramid feature hierarchyです。しかし低レベルの特徴を使うのを避けるために下層に存在する高解像の特徴階層は利用していません。今回のモデルFPNは(d)に該当し、トップダウンの方向と潜在的な結びつき(lateral connection)により、低解像だが意味的に強い(semantically strong)特徴と高解像だが意味的に弱い(semantically weak)特徴の両方を利用しています。結果として豊富なsementicsを持つfeature pyramidを作成することが可能になっています。
この論文ではRPNとFast R-CNNを使ったモデルにFPNを活用しています。このFPNはボトムアップの方向とトップダウンの方向と潜在的な結びつきの三つで構成されています。

- ボトムアップ
ボトムアップはConvNetsのfeedforwardになります。それは様々なスケールのfeature mapを構成する特徴階層を算出します。同じサイズのmapを出力することがあるので、それらの層は同じネットワーク階層に位置するとします。それぞれのネットワーク階層の最後の層をfeature mapとして用い、ピラミッドを作成していきます。
- トップダウン
トップダウンの方向では空間的には粗いが意味的には強い高層からのfeature mapをupsamplingすることで高解像の特徴を作り出しています。さらに、これらの特徴は潜在的な結びつき(lateral connection)でボトムアップからの特徴と結びつけられています。それぞれの潜在的結びつきはボトムアップとトップダウンの同じサイズのfeature mapを結合します。ボトムアップの特徴は意味的には弱いですが、正確に場所が把握できています。上図のようにnearest neighbor upsamplingを用いて2ずつ解像度をupsamplingしていきます。そしてupsampleされたmapは対応するボトムアップの画像とelement wiseに足されます。粗い画質のmapを作成するため、ボトムアップの最後のlayerに1×1のconvolutional layerを付け足します。最後に、upsamplingによって画像の境界がギザギザになってしまうエイリアシング効果を減らすために、結合された各mapに3×3のconvolutionを加えます。
- FPN for RPN
Faster R-CNNでは単一のスケールのfeature mapの上に"3×3のconvとふたつの1×1のconvs"(head)がありましたが、その単一のスケールのfeature mapをFPNに今回は置き換えます。そして、feature pyramidの各レベルに、先ほどと同様の"3×3のconvと二つの1×1のconvs"(head)を付け加えます。Faster R-CNNの時ではanchorのサイズと比率を複数用意する必要がありましたが、FPNではすでに様々なスケールのmapが生成されているので、比率の違うanchorだけを用意すれば大丈夫です。使う比率は{1:1,1:2,2:1}となります。ラベル付けは、ある正解領域とのIOUが一番高いanchorあるいはIOUが0.7以上のanchorをpositive、IOUが0.3以下をnegativeとします。
また、headのパラメーターは全てのfeature pyramidで共有されています。これは全てのfeature pyramidが同じぐらいの意味をもっているということを表します。
- FPN for Fast R-CNN
Fast R-CNNは単一のスケールのfeature mapに基づいていたので、一つのスケールのRoIで大丈夫でしたが、FPNではfeature pyramidに合わせて様々なscaleのRoIを利用しなければいけません。$P_k$レベルのfeature pyramidにあるRoIは以下のようなwとhを持ちます。

ここで、224はImageNetのPre trainの時の画像のサイズで$k_0$はw×h=$224^2$のときのターゲットレベルになります。
そして全てのRoIにクラス分類器とbounding box regressorを付け加え(predictor heads)、全てのheadでパラメーターを共有しています。
RetinaNet
one stageの物体検出モデル(YOLOやSSD)は計算スピードは早いですが、精度ではtwo stage(Fast R-CNNなど)に劣ります。なぜ、こうなったのかを確かめたところ、背景と背景じゃない領域の比率が均衡でないことが原因でした。Two stageのモデルではproposal stageで背景のサンプルをフィルターし候補数をまず減らしています。その後の分類ステージでは背景と背景でない領域の数の比率を3:1に固定にしたり、OHEMを利用したりすることでバランスを保っています。しかし、one stageのモデルでは、簡単に背景に分類された領域が多すぎて、これらの手法は非効率です。そこで、この論文では新しい損失関数Focal Lossを導入することでこの問題に取り組んでいます。
Focal Loss

まずはバイナリーの場合のcross entrophy lossからFocal Lossを紹介していきます。
cross entrophy lossは以下のように表せます。
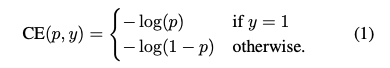
ここでpはラベルがy=1となる確率の予測を表します。また、$p_t$を以下のように定義すると、

CE($p,y$)=CE($p_t$)=-log($p_t$)と表せます。この時、簡単に分類できる$p_t>>0.5$のケースでもそれなりの損失を発生させていることがわかります。(上図の青色のカーブを参照)
- Balanced Cross Entrophy
クラスの不均衡によく使われる方法は、重みを導入する方法です。クラス1には$\alpha\in[0,1]$の重みをクラス-1には$1-\alpha$の重みをつけます。$\alpha_t$を$p_t$と同様に定義すると、
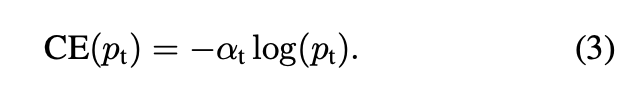
のように定義できます。
- Focal Loss
先ほども述べたように、one stageの物体検出モデルでは簡単にnegative(背景)に分類された領域が損失の大部分を占めてしまいます。$\alpha$はpositiveとnegativeの重要性の均衡は取れますが、分類が簡単/難しい(easy/hard)例は差別化していません。そこでFocal Lossはeasyな例は重みを小さくしhard negativeの訓練に焦点を当てています。
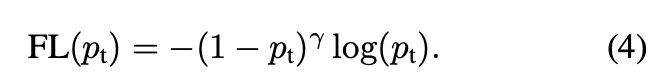
ここで$\gamma\in[0,5]$。
ここで二つの特徴を見ていきます。1) $p_t$が小さく分類を間違えた場合、重みは1に近くなり、損失は影響を受けまん。一方$p_t$→1の時、重みはゼロに近くなり損失は小さくなります。2)$\gamma$はeasy exampleの重みをどれほど小さくするかを表す指標になります。

実際には上の損失を用います。
- Class Imbalance and Model Initialization
バイナリー分類の場合、どちらのクラスも同じ確率で出力されるように初期化されますが、しかし不均衡データの場合、よく現れるクラスの損失が支配的になってしまいます。そこで、推定されるpのためにprior $\pi$という概念を導入します。推定される確率pの値が低くなるように$\pi$を設定します。
RetinaNet
Retinaはconvolutional feature mapを計算するbackbone networkと二つのsub networks(分類器とbounding box regression)で構成されています。backbone networkとしてはFPNを採用し、基本的には先ほど紹介したFPNの論文と同じ構成です。少し違う点は各feature pyramidでオリジナルの3つの比率のanchorに{$2^0,2^{\frac{1}{3}},2^{\frac{2}{3}}$}の大きさのanchorも加えます。IoUが0.5以上のanchorは正解領域として0から0.4は背景とします。各anchorは多くとも一つのobject boxに属するので、その対応するクラスを正解クラスとし、anchorとobject boxの相対的位置からbox regressionのターゲットを決めます。
- Classification subnet
分類器のsubnetは小さいfully convolution networkが各FPNの階層に付け加えられる形になります。これらのsubnetのパラメーターは全てのpyramidレベルで共有されています。A個のanchorとK個のクラスがあり、C channelのfeature mapをfeature pyramidから受け取った場合、それに対して4つのC channelの3×3 conv layer+reluと1つのKA channelの3×3 conv layerを適用します。この分類器subnetはbox regression subnetとはパラメーターを共有していません。
- Box regression subnet
分類器subnetと同じ構造ですが、最後4A linear outputsになるようにします。
Inference and Training
- Inference
推論の時間を短くするために、各Feature pyramidの層でトップ1000個のboxだけ予測を行います。その後threshold0.5のnon-maximum suppressionを適用します。