はじめに
物体検出モデルの進展をR-CNNからFaster R-CNNまで解説していきたいと思います。基礎的な機械学習の知識はあることを前提に書いています。
今回扱うモデルは以下になります。この先の物体認識モデルの基礎となるので是非おさえておいてください。
間違っている箇所があれば指摘してください。正しい情報を手に入れたい場合は論文を読むことをお勧めします。
R-CNN
R-CNNは3つのパートに別れています。Region Proposals, CNN, linear SVMsです。
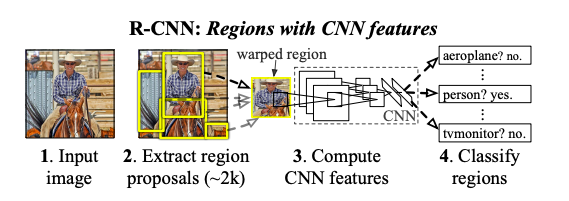
- Region Proposals
Region Proposalsは検出可能な候補を複数提案します。R-CNNでは"Selective Search"という手法を用いてRegion Proposalsを作成します。"Selective Search"とは様々なスケールの物体を認識するためのボトムアップの階層的グループアルゴリズムです。アルゴリズムは以下のようになっています。

ここで、$s(r_i,r_j)$は以下のように求められます。
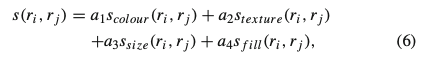
ここでcolor histogramを75binで表し、region $r_i$のcolor histogramを$C_i$とおき、同様に$C_j$をおくと、$C_i$と$C_j$のsimilarity:$S_{color}(r_i,r_j)$は
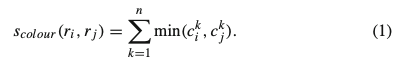
で求められます。$r_i$と$r_j$が統合された領域のcolor histogramは以下のように求められ、再度pixelから計算する必要なく効率的に計算できます。
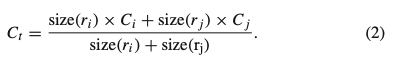
同様に240binのtexture histogramを作成し、region $r_i$のtexture histogramを$t_i$、同様に$t_j$を定義すると、$t_i$と$t_j$のsimilarity:$S_{texture}(r_i,r_j)$は
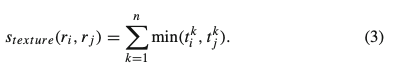
で求められ、$r_i$と$r_j$統合された時のtexture histogramの求め方はcolor histogramの時と同様です。
$S_{size}(r_i,r_j)$は以下のように求められます。
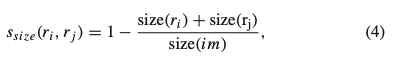
ここで$size(im)$は画像全体のサイズになります。
$S_{fill}(r_i,r_j)$は以下のようにして求められます。
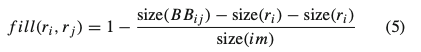
詳細はここから論文を参照してください。
- CNN
提案された領域を画像変形することで227*227のピクセルサイズにし、その画像をConv Netに受け渡すことで、固定された長さの特徴ベクトルを抽出します。CNNモデルはImage NetでPre trainedされたものを用い、今回の物体認識の課題でfine tuneを行います。推論の時は特徴ベクトルのみを抽出しますが、fine tuneの段階では提案された領域のn+1クラスの分類推測(nは物体のクラス、1は背景クラス)から学習を行います。その際、正解領域とIoUが0.5以上のところをpositiveとしそれ以外をnegativeとします。postiveを32枚、negativeを96枚、合計128枚のミニバッチでfine tuneが行われます。
ちなみにIoUは$\frac{重なっている部分の面積}{二つの領域の合計の面積}$で求めることが可能です。
- linear SVMs
各クラスごとにSVMでスコアをつけます。訓練する際は、IoUが0.3以下を背景とし、背景ラベルと正解ラベルに分け、CNNからの特徴量をもとに訓練を行います。テスト時には、スコアがつけられた全てのregionにgreedy nonmaximun supression(ある領域が、重複しているある閾値以上のスコアを持つ領域より低いスコアのとき、それを棄却する)を適用します。
Fast R-CNN
Fast R-CNNはR-CNNと違い、Region Proposalsだけでなく、画像全体もinputにとります。
画像全体をCNNとmax poolingで処理し、feature mapを出力します。そして各Proposed RegionについてRoI(region of interest) pooling(提案された領域に相当する範囲でpooling)を行い固定された長さの特徴ベクトルを抽出しfully connected layerに受け渡します。それから、softmaxでK個の物体分類+背景、合計K+1個の分類分けと、各クラスにつきbounding box(下図のinputされた写真の赤枠)の位置を表す4つの実数を返します。
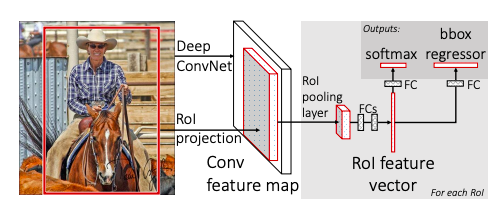
- RoI Pooling
CNNから出力されたfeature mapから特定のobject proposalに対応する箇所の特徴をmaxpoolし、H*W(ともにハイパーパラメター)サイズに変換する作業になります。
- 訓練済みモデルによるパラメーターの初期化
ImageNetで訓練済みのモデルを利用しますが、モデルの最後のmax poolingはRoI poolingに変更し、モデルの最後のfully connected layerとsoftmaxはK+1個の分類分けを行うfully connected layer+softmaxとそのbounding boxの位置を特定するregressorに変更します。また、モデルが画像全体とRegion Proposal を入力できるようにします。
- Fine Tuning
このモデルはend to endで学習ができます。R-CNNのミニバッチではRoIは違う画像から取得されていますが、Fast R-CNNでは2枚の画像から64個ずつRoIを取りミニバッチとしているので、画像の特徴を一回の推論で共有することができコンピュテーションもメモリも効率的になります。
- Multi Task Loss
このモデルで出力されるのは、カテゴリK+1個の確率分布$p=(p_0,\cdot \cdot,p_k)$とbounding box regressionの位置$t^k=(t_x^k,t_y^k,t_w^k,t_h^k)$です。正解クラスを$u$、正解のbouding box regressionの位置を$v$とすると損失関数は以下のようになります。
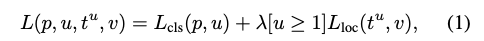
ここで、$L_{cls}(p,u)$はlog lossであり$L_{loc}$は
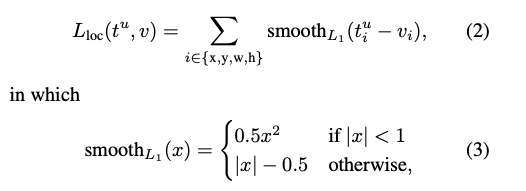
です。論文中では(1)の$\lambda$は1が用いられています。
Faster R-CNN
Faster R-CNNは二つのモジュールを持ち、一つは領域を提案するCNN(RPN)でもう一つはFast R-CNNです。しかしR-CNNやFast R-CNNと違い、この二つは統合されており、より早い推論が可能となりました。
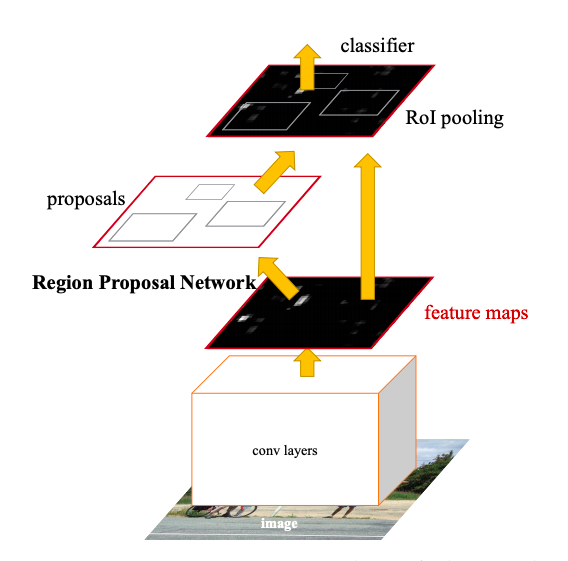
- RPN(Region Proposal Networks)
RPNはFast R-CNNとコンピュテーションを共有することが目的なので、convolution layersをFast R-CNNと共有しています。共有された最後のconvolution layerの出力であるfeature mapにn*nのwindowをスライドさせます。windowによって低次元になったfeature mapを基に、box regression layer(reg)とbox classification layer(cls)に別れ予測をおこないます。それぞれのwindowでk個領域が提案されるので、regは4k個の出力(座標、高さ、幅)、clsは2k個(物体か物体じゃないか)の出力になります。このk個の領域はanchorと呼ばれます。anchorは各windowの真ん中に位置し比率やスケールはまちまちです。デフォルトでは3つのスケール、3つの比率、計9個のacnhorが作られています。これはtranslation invariant(物体を移動させても変化が生じない)、multi scale デザイン(様々なスケールの物体に対応できる)の性質があります。
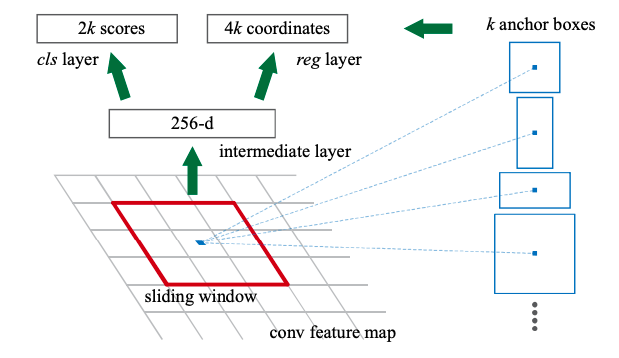
正解ラベルと一番高いIoUを持つanchorとIoUが0.7以上のanchorはpositiveラベルが付与され、IoUが0.3以下のanchorはnegativeのラベルが付与されます。損失関数は以下のようになります。
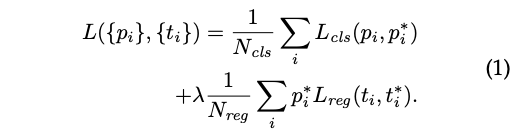
ここで、$p_i$はanchor $i$ が物体である確率予測であり$p_i^*$は正解ラベルです。$t_i$は予測されたbouding box $i$ の座標であり$t_i^*$は正解の座標です。$L_{cls}$や$L_{reg}$はFast R-CNNと同じです。$\lambda$は10としています。
- 共有された層の訓練
RPNとFast R-CNNの共有部分を学習するために、この論文では4 step alternating trainingが使われています。まずはRPNを訓練させます。ImageNetで訓練済みのモデルを用い、region proposal taskをend-to-endでfine tuneします。2段階目では1段階目で訓練されたRPNを使い提案された領域を用いて、Fast R-CNN(Detector)を学習させます。この時、Fast R-CNNのモデルもImageNetで訓練済みのモデルで初期化を行っています。3段階目ではRPNを訓練させるために2段階目で学習したモデルの共通部分を初期化するときに用い、RPNにのみ属する部分をfine tuneします。最後に共通部分は固定したままDetectorをfine tuneします。推論時には、non-maximum suppressionが用いられます。
おわりに
今回がはじめてのQiita投稿なので、是非応援よろしくお願いします!CV、NLP、レコメンドシステムをメインに投稿していく予定です。