はじめに
物体検出モデルの進展Part2になります。Part1の知識はあることを前提に話をすすめるので、R-CNN、Fast R-CNN、Faster R-CNNを聞いたことない人はPart1を先によんでください。
今回扱うモデルは
YOLO v1 (論文はこちら)
SSD (論文はこちら)
R-FCN (論文はこちら)
です。
ミスがあったらぜひご指摘お願いいたします。
YOLO v1
YOLOはYou Only Look Onceの略であり、その名の通り推論の速さに焦点を当てたモデルになります。
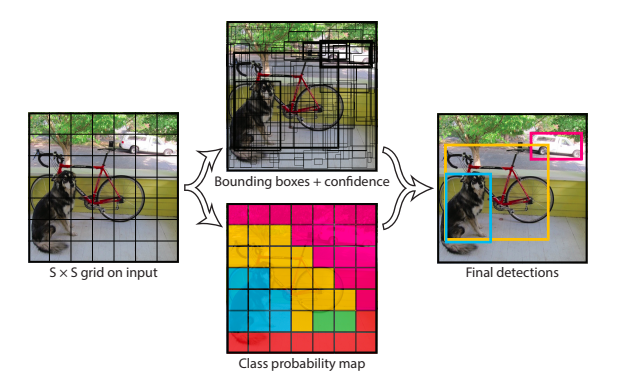
まず画像をS×Sのgridに分割し、もし物体の中心が分割されたセルに位置すれば、そのセルは物体を検出することになります。それぞれのセルはB個のBounding Boxと信頼スコアを予測します。信頼スコアは Pr(Object)* $IOU_{pred}^{truth}$で計算されます。Bounding BoxはPart1まででもよくでてきたようにBounding Boxの座標と高さ、幅で表現されます。
これらに加え、Bounding Boxの数に関係なく各セルごとに、Pr($Class_i$|Object)を予測します。テスト時にはPr($Class_i$|Object)Pr(Object)$IOU_{pred}^{truth}$=Pr($Class_i$)*$IOU_{pred}^{truth}$と計算します。
- Training
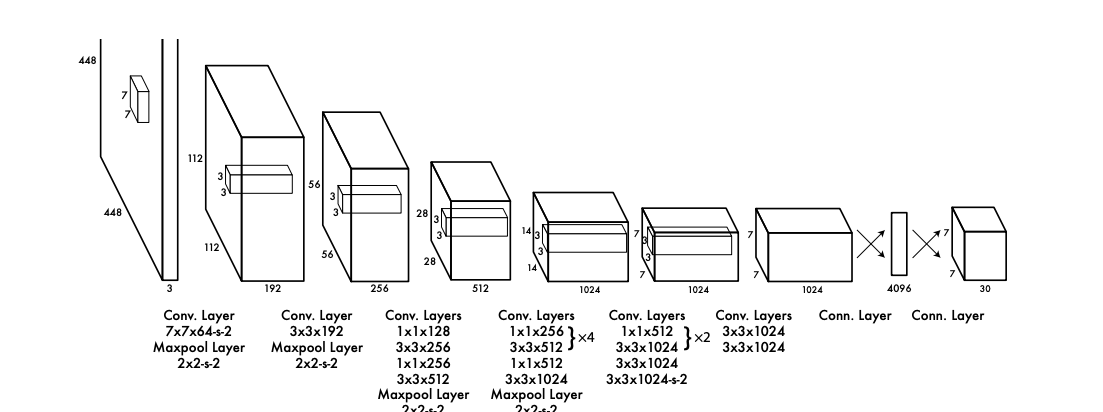
CNNにより実装されており、GoogLeNetのInception modulesを1×1のreduction layerに変更させたモデルを用いています。最初の20 convolutional layersのみImageNetで学習されたものを用い、その後、ランダムに初期化された4 convolutional layersと2 fully connected layersを付け加えます。
最適化のしやすさなどから、sum squared errorを用いますが、localization errorとclassification errorを同等に扱ってしまいます。また、物体を含まないセルが多く、信頼スコアをゼロのほうに追いやるので、物体を含むセルの勾配よりも物体を含まないセルの勾配の方が強くなってしまいます。そのため、Bounding Boxの座標予測の損失を増やし、物体を含まない信頼スコアの損失を減らす損失関数を利用します。$\lambda_{coord}$,$\lambda_{noobj}$の二つのパラメーターを用い、それぞれ5と0.5に設定します。
また、大きいboxのerrorを重視すべきなのに、sum squared errorは大きいboxと小さいboxのerrorを同等に扱ってしまうため、Bounding Boxの幅と高さは平方根にします。
一つの物体につき、一つのBounding Boxのみ必要なので、正解のboxとのIOUが一番高いBounding Boxを予測とします。
損失関数は以下のようになります。
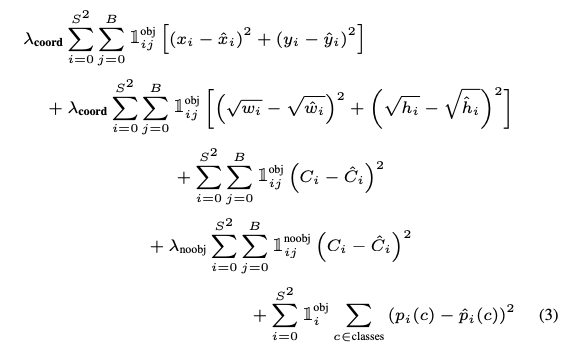
ここで、$x_i,y_i$はセルiの中心$w_i,h_i$は幅と高さを表します。$C_i$はセルiが物体を含む確率(信頼スコア)を表し、$p_i(c)$はセルiの物体がどのクラスに属するのかの確率分布となります。
- 推論
大きい物体や複数のセルの境界に位置する物体は複数のセルによって場所をよく特定できてしまうので、non-maximam supressionで修正します。
- 限界
1つのセルにつき、2つのBounding Boxと1つのクラスしか予測できないので、集団で出現する小さい物体の検出があまりできません。またデータからBounding Boxを予測できるようにしているので、初めて見る比率の物体の検出があまりできません。さらにdownsampleされた特徴をもとに予測しているので、粗い特徴量を使ってしまっています。
SSD
- モデル
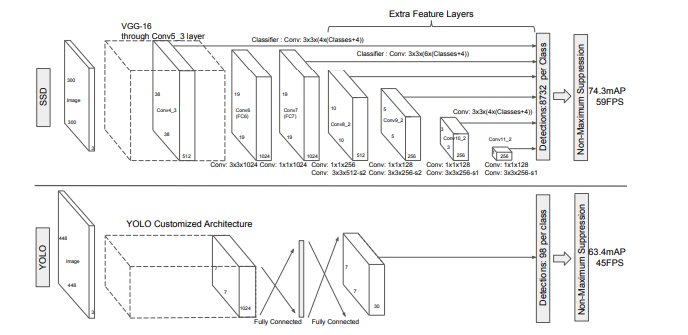
SSDはCNNからBounding Boxとクラスの確率を出力し、それにnon-maximum supressionが続くモデルになります。高画質の画像分類用のモデルから、分類を行うlayerより前の部分を切り出し、それをbase networkと呼びます。そのbase networkに、ある特徴を持つ補助構造を加えます。
まず、base networkにconvolution feature layersを付け加えます。これらのlayerはfeature mapのサイズを次第に小さくし、様々なスケールの物体検出を可能にします。
その次は、その付け加えられたfeature layer各層で3×3×pの小さなkernelを基本要素としてスライドさせ、カテゴリーのスコアと座標を出力します。そして、そのそれぞれのfeature mapのセル(3×3×p)とdefault boxを結びつけます。つまり、それぞれのfeature mapのセルでdefault boxの座標やカテゴリーのスコアを予測します。これは各feature layerで行われるので、Faster R-CNNと違い様々な解像度でanchor boxesを適用していると考えることができます。
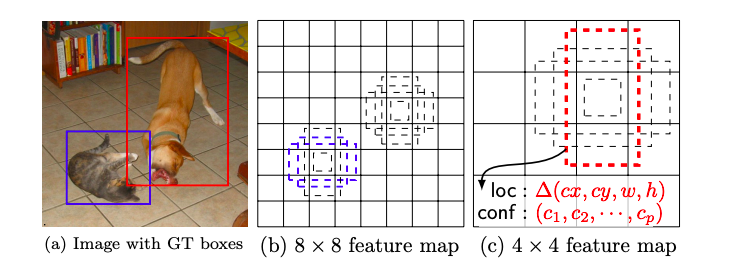
- Training
正解のboxとのjaccard overlap(IOU)が0.5以上のdefault boxだけを今後の訓練に用います。損失関数は
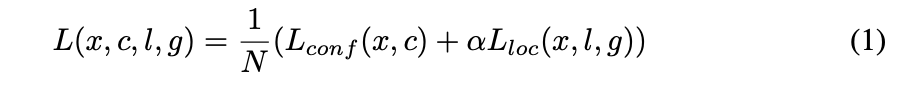
が用いられます。Nは上で選ばれたdefault boxの数です。$\alpha$は1と設定しています。Faster R-CNNの時と同様、localization lossにはsmooth L1 lossが用いられ、以下のように計算されます。$x_{ij}^p$とはi番目のdefault boxがカテゴリーpのj番目の正解boxとマッチしていれば1でそれ以外は0になります。lは推測されたboxの座標、高さ、幅でgは正解boxのの座標、高さ、幅です。
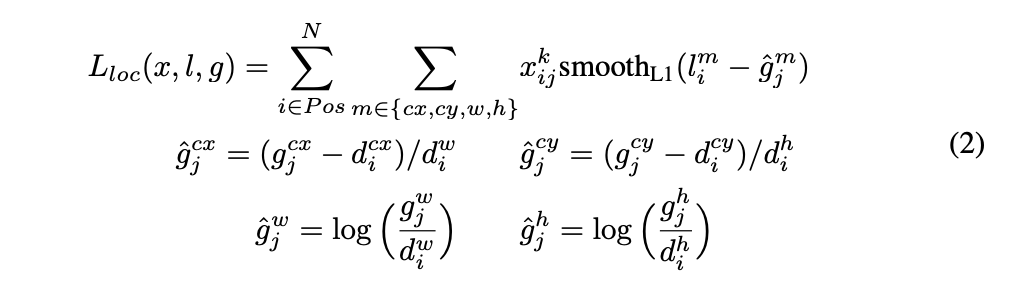
また、confidence lossはsoftmax lossで以下のように計算されます。
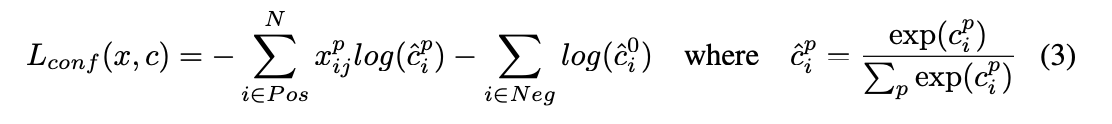
ここで$C_i^p$はカテゴリpの信頼スコアになります。
様々なサイズの画像で処理し結果をまとめる手法もありますが、このモデルだと様々な層のfeature mapを利用することで同じ効果を得ながら、全ての物体の様々なスケールに対してパラメーターを共有することが可能です。
CNNの下層にあるfeature mapは物体のより詳細な情報を捉えることができるので、semantic segmentationの性能をよくするという研究があります。また、feature mapからpoolされたglobal contextを加えることでsemantic segmentationをより滑らかにすることができます。これらに動機付けされ下層と上層のfeature mapを両方用いてました。
m個のfeature mapを使いたいと仮定したとき、各層のfeature mapでのdefault boxのスケールは以下のように計算されます。
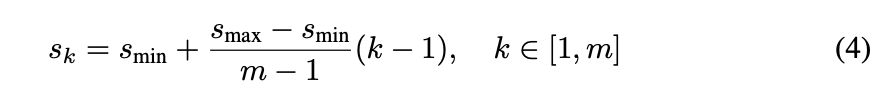
ここで、$s_{min}$は最下層のスケールの0.2、$s_{max}$は最上層のスケール0.9を用います。また、比率は$a_r\in {1,2,3,1/2,1/3}$を用い、$w_k^a=s_k\sqrt{a_r}$、$h_k^a=s_k/\sqrt{a_r}$です。また、$a_r=1$のときは$s_k^{'}=\sqrt{s_ks_{k+1}}$もdefault boxに加えます。各Default Boxの中心は($\frac{i+0.5}{|f_k|},\frac{j+0.5}{|f_k|}$)となります。ここで、|$f_k$|はk番目のfeature mapのサイズになります。i,jは$i,j\in[0,|f_k|)$です。
SDDではnegativeなdefault boxが非常に多くなるため、それらを全て使うのではなく、confidence lossが高いものから順に使い、negativeとpositiveの割合が多くとも3:1になるようにします。(Hard negative mining)
R-FCN
- Overview
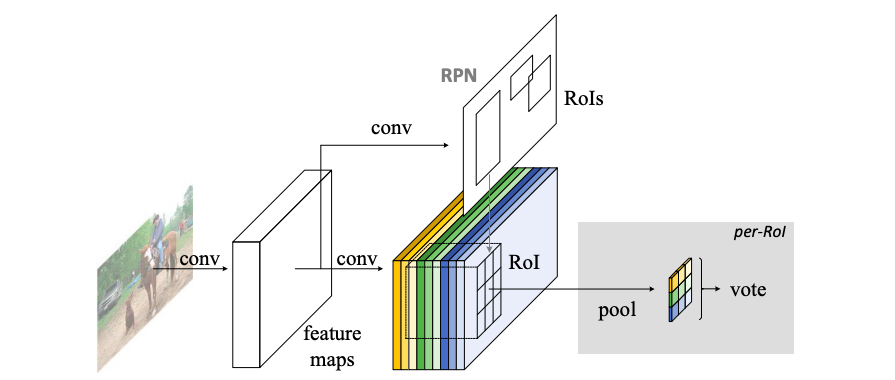
R-CNNのようにこのモデルはtwo stage:(i) region proposal (ii) region classificationのモデルです。Faster R-CNNのように、RPNとFast R-CNNで特徴を共有しているモデルになります。
Proposal regions(RoIs)が与えられると、R-FCNはRoIsを各カテゴリーあるいは背景に分類します。最後のconvolution layerは$k^2$個のpositive sensitive score mapsを生み出し、各position sensitive score mapsにつきC+1カテゴリー分のchannelsがあります。つまりpositive sensitive score mapsは合計で$k^2(C+1)$channelになります。この$k^2$のscore mapはk×kのspatial gridに対応しており、例えば3×3=9個のscore mapsはそれぞれ、{左上、真ん中上、右上、・・、左右}に対応しています。下図を参照してください。
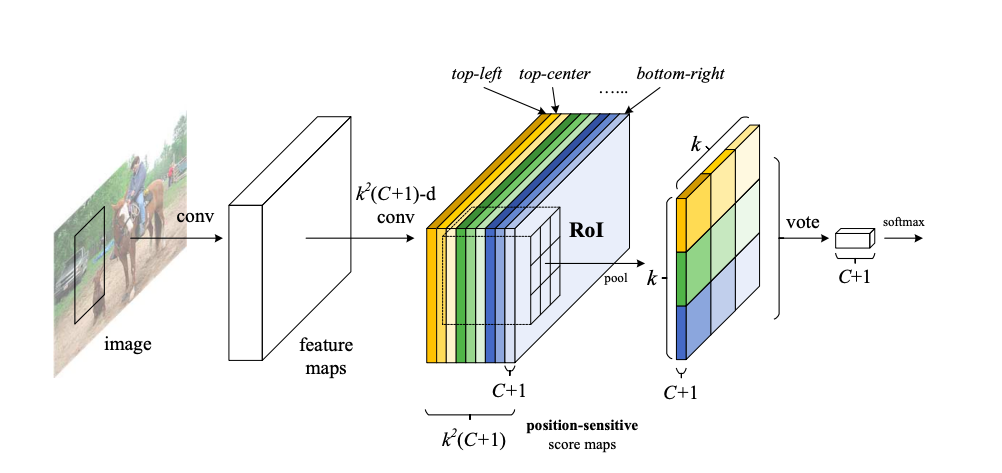
モデルはその後position-sensitive RoI pooling layerが続きます。そこでposition-sensitive score mapsのRoIに対応する箇所のk×k×(C+1)のスコアを生成します。ここでのpoolingはselective poolingで、poolingされたC+1 channelのk×kのbin一つ一つが、一つのscore mapからの情報を集約しているものになります。
- BackBone Architecture
最後のaverage poolingとfully connected layerを取り除いてResNet101を使います。それに1024-d 1×1のconvolutional layerと$k^2(C+1)$ channelのconvolutional layerを付け加えます。
- Positive-sensitive score maps & Position-sensitive RoI pooling
長方形のRoIをk×kのbinに分割し、一つあたりのbinのサイズは$\frac{w}{k}\times\frac{h}{k}$とします。一つ一つのbinを(i,j) ($0\leq i,j\leq k-1$)とすると、Positive-sensitive RoI pooling は以下のように表せます。
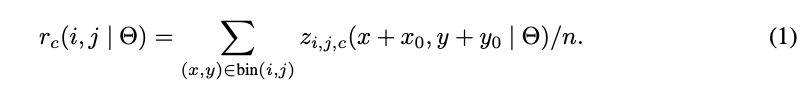
ここで、$r_c(i,j)$はカテゴリーcの(i,j)番目のbinに対応するものです。$z_{i,j,c}$は$k^2(C+1)$個あるスコアマップのうち一つです。($x_0,y_0$)はRoIの左上の座標です。nはbinの中のpixelsの数になります。また$i\frac{w}{k} \leq x \leq (i+1)\frac{w}{k}$、$j\frac{h}{k} \leq y \leq (j+1)\frac{h}{k}$です。
その後、"Vote"という作業を行います。
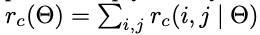
により、C+1のベクトルを出力します。そして
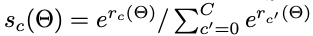
で各カテゴリの確率を求め、これを使いcross entrophy lossを計算します。
Bounding box regressionに関しては$k^2(C+1)$-dのconvolutional layerではなく、$4k^2$-dのconvolutional layerを使いposition-sensitive RoI poolingが4$k^2$個のmapに適用され$4k^2$-dのベクトルを出力します。そしてそれはvoteで4-dのベクトルに集約されます。
- Training
RPNがすでに計算されていれば、R-FCNはend-to-endで学習ができます。損失関数は
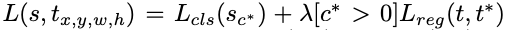
となり、$L_{cls}(s_c^*)$はcross cross-entropy lossで$L_{reg}$:regression lossはFast R-CNNのと同じものを利用しています。IOUが0.5以上をpositive,それ以外をnegativeとして学習を行なっています。
このモデルはonline hard example mining(OHEM)が適用しやすいです。まず提案された領域N個全てののlossを調べ、その中で上位B個を選んで利用します。backpropagationではそのB個の例を用いて訓練が行われます。RPNとR-FCNで特徴を共有するために、Faster R-CNNと同様に4 step alternating trainingを利用します。