紹介したいこと
- ETLを使ってDummyの大量データを生成する方法を紹介します。
- ダミーデータを生成するGenerate random value, Fake data部品を紹介したい。
- HopでのETLの定義の雰囲気を伝えたい for Beginner
対象者
- Apache Hop (データ統合プラットフォーム) 、ETLを試してみたい方。
- 大量のDummyデータを準備したい人
- そのデータをデータソースに格納したい人(ファイル、RDB、MongDBなど)
前提環境
- Docker Desktopをインストールしている
- Apache Hopを準備している
- Hop GUIを操作できる
手順の流れ
- 大量データを作成するフローを作成する(1)
- 動作確認(1)
- 大量データを作成するフローを作成する(2)
- 動作確認(2)
大量データを作成するフローを作成する(1)
Generate random value
Hop GUIを起動して、以下のようなパイプラインを作成します。
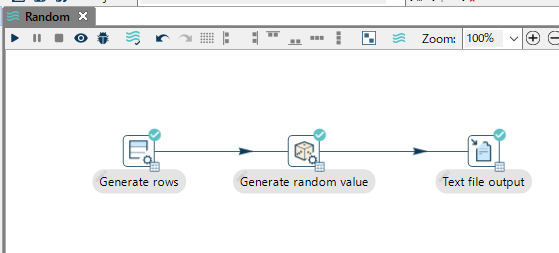
Generate rowsで行を生成します。何件分のデータの流れを作成するか定義します。
Generate random valueでランダムな値を生成します。
Text file outputでファイルに出力します。
この出力先を他のデータソースの部品に変更することで、他のデータソースに出力できます。
-
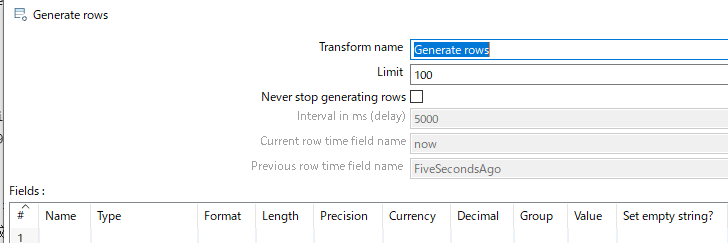
Generate rows
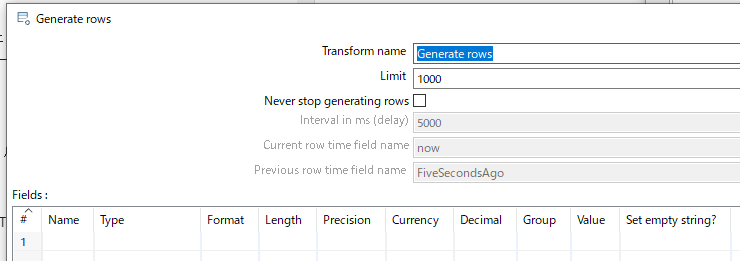
Limitのところ1000として、1000件の行を生成を指定。この件数を調整することで、大量データ生成できます。 -
Generate random value
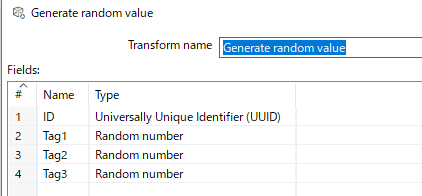
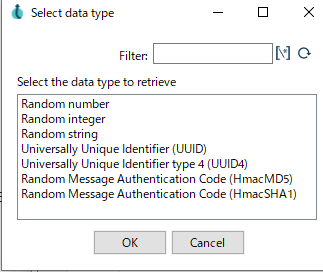
生成したい行のフィールド名、Typeを指定します。
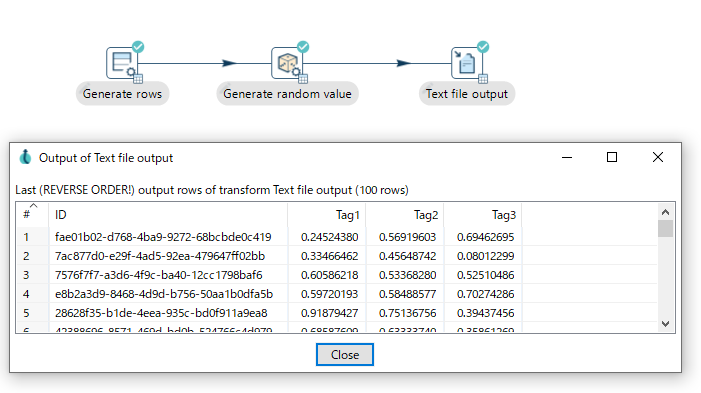
動作確認(1) : Generate random value
以下のようにデータを生成して、出力することができます。
大量データを作成するフローを作成する(2)
Fake data
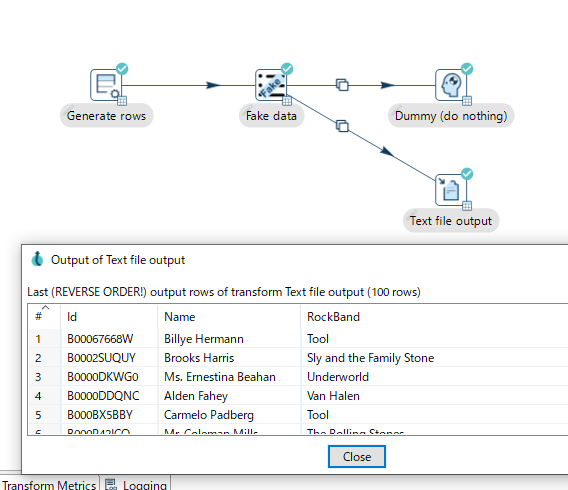
以下のようなパイプラインを作成します。
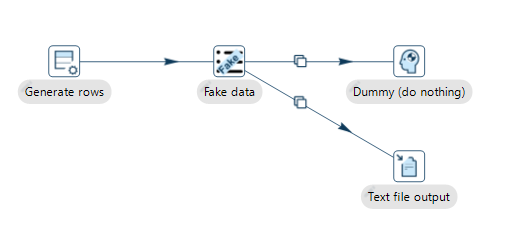
Generate rowsで行を生成します。何件分のデータの流れを作成するか定義します。
Fake dataでダミーのデータを生成します。
Text file outputでファイルに出力します。
Generate random valueとは違い、データの種類の設定のバリエーションが選べるところです。内部ではJava Faker libraryを使用してるとのことです。
-
Generate random value
-
Fake data
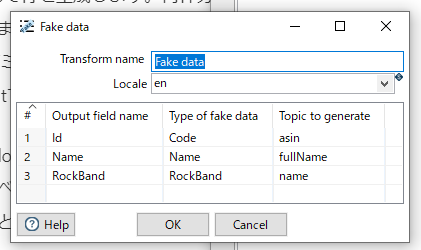
Locale: 言語を指定できる
Output filed name : 出力フィールド名
Type of fake data: フェイクデータの種類を指定
Topic to generate: フェイクデータのトピック
指定可能なTypeとTopicについては、Fake dataのヘルプを参照ください。
Localeにjaを指定してみたが、一部Type, Topicでは日本語は対応してないようでした。
動作確認(2) : Fake data
まとめ
- このようにGenerate random value, Fake dataを利用して、ダミーのデータを生成しました。
- 出力したデータをファイルに出力をしました。他のデータソースの部品を使えば、RDB、MongoDBなどに作成したデータを格納する流れも生成することができます。
- HopではETL処理によりデータの流れを作り出せることが理解していただけたのではないかと思います。
もしも、これをみて、活用できそうだ、応用できそうそうだと思ったら、ぜひとも試してみてください。
より応用的な使い方、拡張性としてストリーム処理のApaceh Beamと連携する機能もあるので、興味ありましたらそちらも。
注意事項
- 大量データを処理するときに、PCの負荷があがって操作しにくくなったりします。自己責任で気をつけて操作してください。処理の間にintervalなどいれるなど調整してください。
参考
連携可能なRDBの一覧
https://hop.apache.org/manual/latest/database/databases.html