はじめに
従来のレコメンドシステムは協調フィルタリングやコンテンツベースフィルタリングが主流でしたが、LLMの登場により自然言語での詳細な分析が可能になりました。
今回はPydantic AIを使って、個人の好みとアイテム一覧を総当たりで分析し、詳細な理由付きでレコメンドするシステムを作ってみました。
何を作るのか
コンセプト
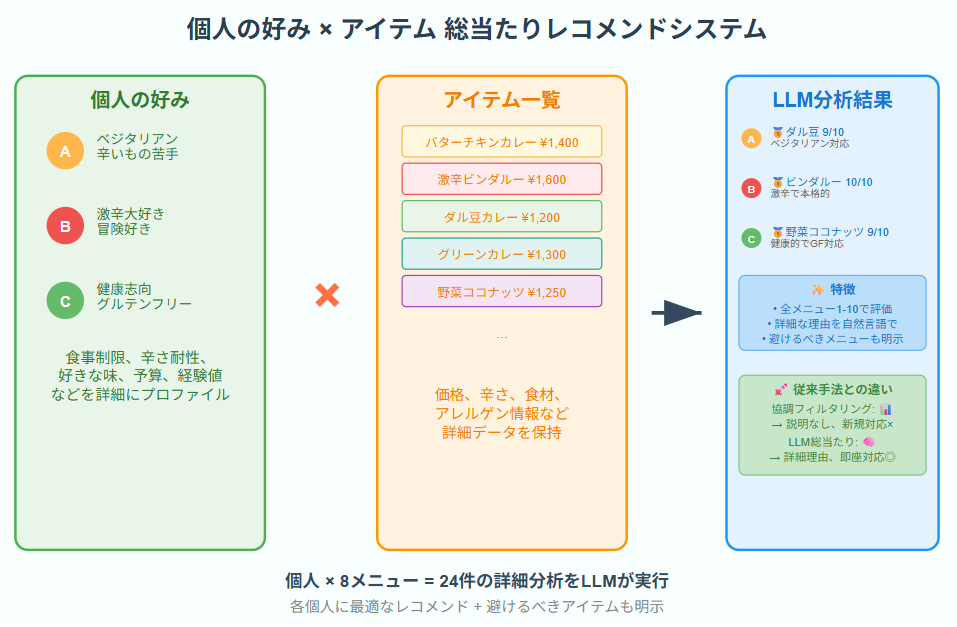
個人プロファイル × 全アイテム = 総当たり分析
↓
各アイテムに1-10のマッチ度スコア + 詳細理由
↓
最適なレコメンド + 避けるべきアイテムも明示
実例(カレー専門店での活用)
👤 Aさん(ベジタリアン、辛いもの苦手)
🏆 TOP 3 レコメンド
🥇 ダル豆カレー (9/10) - ベジタリアン対応で優しい味
🥈 野菜ココナッツカレー (8/10) - 植物性で健康的
🥉 日本風チキンカレー (3/10) - 甘口だが肉類含有
❌ 避けるべき
💥 激辛ビンダルーカレー (1/10) - 肉類+激辛で完全不適合
システムアーキテクチャ
1. データ構造設計
from pydantic import BaseModel, Field
from typing import List
class MenuMatchScore(BaseModel):
"""アイテムマッチスコア"""
menu_name: str = Field(description="アイテム名")
match_score: int = Field(description="マッチ度(1-10)")
reason: str = Field(description="スコアの理由(1行)")
concern: str = Field(description="懸念点(あれば)")
class IndividualAnalysis(BaseModel):
"""個人分析結果"""
user_name: str = Field(description="ユーザー名")
user_summary: str = Field(description="ユーザー特徴の要約")
top_recommendation: MenuMatchScore = Field(description="最高評価アイテム")
avoid_item: MenuMatchScore = Field(description="避けるべきアイテム")
all_scores: List[MenuMatchScore] = Field(description="全アイテムのスコア一覧")
このシステムでは、all_scoresを用いてすべてのアイテムを評価し、それぞれのスコアに対して自然言語で理由を説明します。また、推奨すべきでないアイテムについても明示されるため、判断材料としても有用です。
2. LLMエージェント設計
from pydantic_ai import Agent
from pydantic_ai.models.gemini import GeminiModel
model = GeminiModel('gemini-2.0-flash', provider='google-gla')
matching_agent = Agent(
model,
output_type=IndividualAnalysis,
system_prompt="""
個人の好みとアイテム一覧の総当たり分析を行うシステムです。
分析手順:
1. ユーザーの全特徴を詳細分析
2. 全アイテムを1つずつ評価(1-10スコア)
3. マッチ度の根拠を明確に説明
4. 最高・最低評価アイテムを特定
スコアリング基準:
- 制約条件への対応(必須)
- 好み・嗜好との適合性
- 予算・価格との整合性
- 経験・冒険度との適合
客観的で詳細な評価を行ってください。
"""
)
設計面では、output_typeにPydanticモデルを指定することで、出力形式を明確に定義できます。また、システムプロンプトで評価基準を明示することで一貫性のある応答が得られ、構造化された出力により後処理もスムーズに行えます。
3. 総当たり分析の実装
async def analyze_individual_match(user: dict, items: List[dict]):
"""個人×アイテム総当たり分析"""
prompt = f"""
【分析対象ユーザー】
{json.dumps(user, ensure_ascii=False, indent=2)}
【アイテム一覧】
{json.dumps(items, ensure_ascii=False, indent=2)}
タスク:
上記のユーザーに対して、全{len(items)}アイテムを評価してください。
各アイテムに1-10のスコアを付け、その理由を説明してください。
最も避けるべきアイテムも正直に評価してください。
"""
result = await matching_agent.run(prompt)
return result.output
実装例 カレー専門店レコメンドシステム
サンプルデータの準備
# レストランメニューデータ
restaurant_menu = [
{
"name": "バターチキンカレー",
"price": 1400,
"spice_level": 2,
"main_ingredient": "鶏肉",
"cuisine_type": "インド",
"dietary_tags": ["濃厚", "クリーミー"],
"allergens": ["乳製品"]
},
{
"name": "激辛ビンダルーカレー",
"price": 1600,
"spice_level": 5,
"main_ingredient": "豚肉",
"cuisine_type": "インド・ゴア",
"dietary_tags": ["激辛", "スパイシー"],
"allergens": []
},
{
"name": "ダル豆カレー",
"price": 1200,
"spice_level": 2,
"main_ingredient": "レンズ豆",
"cuisine_type": "インド",
"dietary_tags": ["ベジタリアン", "ヘルシー"],
"allergens": []
}
# ... 他のメニュー
]
# ユーザープロファイル
users = [
{
"name": "Aさん(初心者)",
"spice_tolerance": 1,
"dietary_restrictions": ["ベジタリアン"],
"preferred_flavors": ["まろやか", "優しい"],
"budget_range": "1000-1500円"
}
# ... 他のユーザー
]
実行と結果表示
async def run_recommendation_system():
"""レコメンドシステム実行"""
for user in users:
print(f"🔍 {user['name']} を分析中...")
analysis = await analyze_individual_match(user, restaurant_menu)
# 結果表示
display_recommendations(analysis)
def display_recommendations(analysis):
"""レコメンド結果の表示"""
print(f"👤 {analysis.user_name} の分析結果")
print("=" * 50)
# トップ3表示
sorted_scores = sorted(analysis.all_scores,
key=lambda x: x.match_score, reverse=True)
for i, item in enumerate(sorted_scores[:3], 1):
emoji = "🥇" if i == 1 else "🥈" if i == 2 else "🥉"
print(f"{emoji} {item.menu_name}")
print(f" スコア: {item.match_score}/10")
print(f" 理由: {item.reason}")
if item.concern:
print(f" ⚠️ 注意: {item.concern}")
実行結果例(一部)
🎯 個人×メニュー総当たりマッチングシステム
======================================================================
📊 分析対象:
👥 ユーザー数: 3人
🍛 メニュー数: 8品目
🔢 総評価数: 24件
======================================================================
📊 個別分析結果
======================================================================
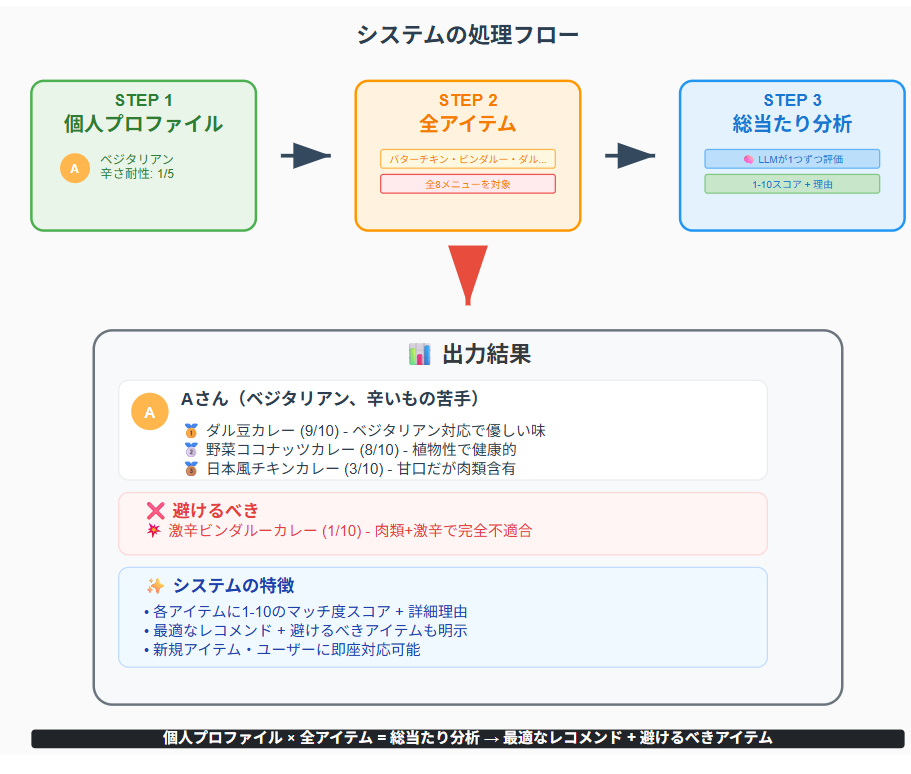
👤 Aさん(初心者) の完全メニュー分析
============================================================
📝 特徴:ベジタリアンで辛いものが苦手、まろやかな味を好む。
🏆 あなたにオススメ TOP 3
----------------------------------------
🥇 ダル豆カレー
スコア: 9/10
理由: ベジタリアン対応、予算内、辛さも許容範囲で、Aさんの好みに合う可能性が高い。
🥈 野菜ココナッツカレー
スコア: 8/10
理由: ベジタリアン対応、ココナッツ風味がAさんの好みに合う可能性が高い。
🥉 グリーンカレー
スコア: 5/10
理由: ベジタリアンではない、辛さが少し高いが、ココナッツ風味が好みかもしれない。
❌ 避けた方がよいメニュー
----------------------------------------
💥 バターチキンカレー
スコア: 1/10
理由: ベジタリアンではない、辛さレベルもAさんには合わないため、最低評価。
📊 全メニューランキング
----------------------------------------
1位 ダル豆カレー 9/10 ⭐⭐⭐⭐
2位 野菜ココナッツカレー 8/10 ⭐⭐⭐⭐
3位 グリーンカレー 5/10 ⭐⭐
4位 日本風チキンカレー 2/10 ⭐
5位 バターチキンカレー 1/10 ⭐
6位 激辛ビンダルーカレー 1/10 ⭐
7位 キーマカレー(ラム) 1/10 ⭐
8位 シーフードレッドカレー 1/10 ⭐
----------------------------------------------------------------------
👤 Bさん(激辛好き) の完全メニュー分析
============================================================
📝 特徴:激辛好きで、インド、タイ、メキシカン料理の経験があり、冒険心が非常に高い。甘い味付けは苦手。予算は1200-2000円。
🏆 あなたにオススメ TOP 3
----------------------------------------
🥇 激辛ビンダルーカレー
スコア: 10/10
理由: Bさんの激辛好きに最適で、 spice_level も5と最高レベル。
🥈 シーフードレッドカレー
スコア: 9/10
理由: spice_level が4と高く、海鮮好きならおすすめ。
🥉 キーマカレー(ラム)
スコア: 8/10
理由: spice_level は3だが、ラム肉の風味がBさんの冒険心をくすぐる。
❌ 避けた方がよいメニュー
----------------------------------------
💥 日本風チキンカレー
スコア: 2/10
理由: spice_level が1と低く、甘口でBさんの好みに合わない。
📊 全メニューランキング
----------------------------------------
1位 激辛ビンダルーカレー 10/10 ⭐⭐⭐⭐⭐
2位 シーフードレッドカレー 9/10 ⭐⭐⭐⭐
3位 キーマカレー(ラム) 8/10 ⭐⭐⭐⭐
4位 グリーンカレー 7/10 ⭐⭐⭐
5位 バターチキンカレー 6/10 ⭐⭐⭐
6位 野菜ココナッツカレー 6/10 ⭐⭐⭐
7位 ダル豆カレー 5/10 ⭐⭐
8位 日本風チキンカレー 2/10 ⭐
まとめ
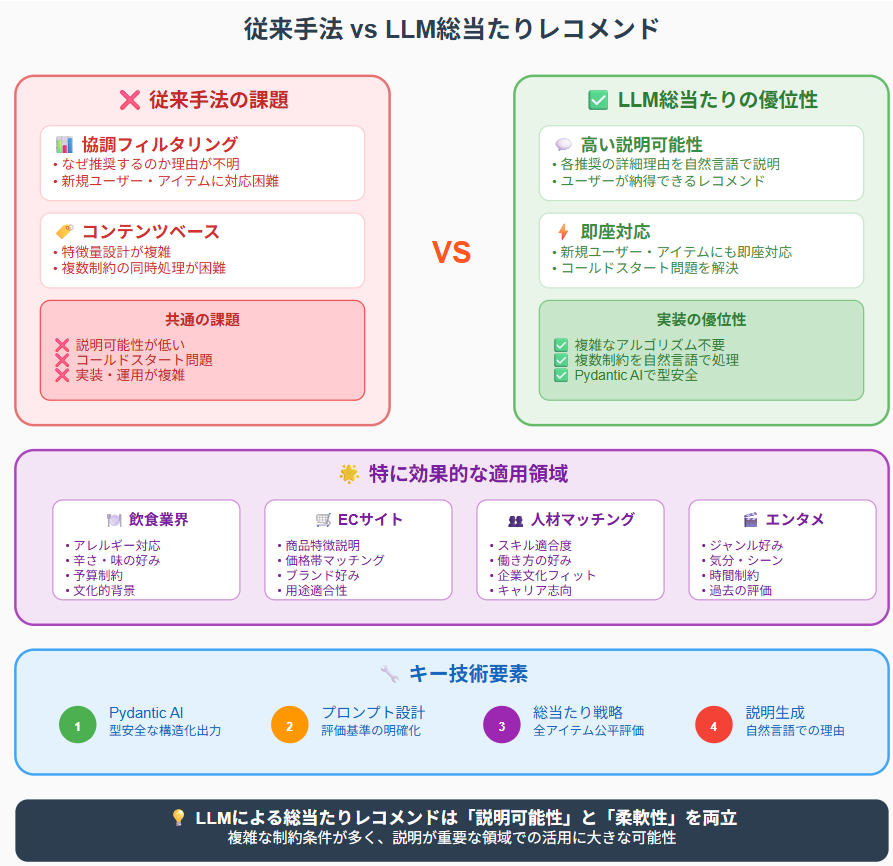
LLMを活用した総当たり型レコメンドシステムは、複雑なアルゴリズムなしに実装でき、理由付きで柔軟なレコメンドが可能です。新しいユーザーやアイテムにも即対応でき、複数の制約条件も自然言語で処理できます。従来の課題だった「なぜこれを勧めるのか」という説明性の低さも、LLMの言語理解と生成能力によって補えます。
結果の妥当性については人間の確認が必要ですが、おおまかな方向性をつかむ初期のたたき台としては有用です。アンケート結果の分析などにも応用が期待できます。情報の取り扱いに十分配慮すれば、LLMを業務支援に活用する可能性は広がりそうです。
実装
著者はGoogle Colabを用いて動作確認を行いました。
# 必要なライブラリのインストール
!pip -q install pydantic-ai
# Google Colab用セットアップ
import nest_asyncio
import os
nest_asyncio.apply()
# APIキー設定(Google Colab)
from google.colab import userdata
os.environ["GEMINI_API_KEY"] = userdata.get('GEMINI_API_KEY')
"""
個人×メニュー総当たりマッチングシステム(訂正版)
各個人に対して全メニューを評価し、最適な提案を行う
"""
import asyncio
import json
from pydantic import BaseModel, Field
from pydantic_ai import Agent
from pydantic_ai.models.gemini import GeminiModel
from typing import List, Optional
# ===== 個人×メニューマッチング専用データ構造 =====
class MenuMatchScore(BaseModel):
"""メニューマッチスコア"""
menu_name: str = Field(description="メニュー名")
match_score: int = Field(description="マッチ度(1-10)")
reason: str = Field(description="スコアの理由(1行)")
concern: str = Field(description="懸念点(あれば、なければ空文字)")
class IndividualMenuAnalysis(BaseModel):
"""個人メニュー分析結果"""
user_name: str = Field(description="ユーザー名")
user_summary: str = Field(description="ユーザー特徴の要約")
all_scores: List[MenuMatchScore] = Field(description="全メニューのスコア一覧(スコア順にソート済み)")
# ===== レストランメニューデータ =====
restaurant_menu = [
{
"name": "バターチキンカレー",
"price": 1400,
"spice_level": 2,
"main_ingredient": "鶏肉",
"cuisine_type": "インド",
"dietary_tags": ["濃厚", "クリーミー"],
"allergens": ["乳製品"]
},
{
"name": "激辛ビンダルーカレー",
"price": 1600,
"spice_level": 5,
"main_ingredient": "豚肉",
"cuisine_type": "インド・ゴア",
"dietary_tags": ["激辛", "スパイシー"],
"allergens": []
},
{
"name": "ダル豆カレー",
"price": 1200,
"spice_level": 2,
"main_ingredient": "レンズ豆",
"cuisine_type": "インド",
"dietary_tags": ["ベジタリアン", "ヘルシー", "グルテンフリー"],
"allergens": []
},
{
"name": "グリーンカレー",
"price": 1300,
"spice_level": 3,
"main_ingredient": "鶏肉",
"cuisine_type": "タイ",
"dietary_tags": ["ココナッツ", "ハーブ"],
"allergens": []
},
{
"name": "野菜ココナッツカレー",
"price": 1250,
"spice_level": 2,
"main_ingredient": "季節野菜",
"cuisine_type": "タイ",
"dietary_tags": ["ベジタリアン", "ココナッツ", "グルテンフリー"],
"allergens": []
},
{
"name": "日本風チキンカレー",
"price": 1100,
"spice_level": 1,
"main_ingredient": "鶏肉",
"cuisine_type": "日本",
"dietary_tags": ["甘口", "親しみやすい"],
"allergens": ["小麦"]
},
{
"name": "キーマカレー(ラム)",
"price": 1450,
"spice_level": 3,
"main_ingredient": "ラム肉",
"cuisine_type": "インド",
"dietary_tags": ["ドライ", "スパイシー"],
"allergens": []
},
{
"name": "シーフードレッドカレー",
"price": 1500,
"spice_level": 4,
"main_ingredient": "海鮮",
"cuisine_type": "タイ",
"dietary_tags": ["海鮮", "辛口"],
"allergens": ["甲殻類"]
}
]
# ===== 個人プロファイル =====
individual_users = [
{
"name": "Aさん(初心者)",
"spice_tolerance": 1,
"dietary_restrictions": ["ベジタリアン"],
"preferred_flavors": ["まろやか", "優しい"],
"disliked_ingredients": ["肉類", "魚介類"],
"budget_range": "1000-1500円",
"adventurousness": "低い",
"cuisine_experience": ["日本料理"]
},
{
"name": "Bさん(激辛好き)",
"spice_tolerance": 5,
"dietary_restrictions": [],
"preferred_flavors": ["激辛", "刺激的", "本格的"],
"disliked_ingredients": ["甘い味付け"],
"budget_range": "1200-2000円",
"adventurousness": "非常に高い",
"cuisine_experience": ["インド", "タイ", "メキシカン"]
},
{
"name": "Cさん(健康志向)",
"spice_tolerance": 2,
"dietary_restrictions": ["グルテンフリー"],
"preferred_flavors": ["あっさり", "自然", "野菜重視"],
"disliked_ingredients": ["油っぽい料理"],
"budget_range": "1000-1400円",
"adventurousness": "中程度",
"cuisine_experience": ["和食", "タイ料理"]
}
]
# ===== 総当たりマッチングAIエージェント =====
model = GeminiModel('gemini-2.0-flash', provider='google-gla')
matching_agent = Agent(
model,
output_type=IndividualMenuAnalysis,
system_prompt="""
個人の好みとレストランメニューの総当たり分析を行うシステムとして動作してください。
分析手順:
1. ユーザーの全ての特徴を詳細分析してuser_summaryを作成
2. 全メニューを1つずつ評価(1-10スコア)
3. マッチ度の根拠を明確に説明
4. all_scoresは必ずスコアの高い順(降順)でソートして出力
スコアリング基準:
- 食事制限への対応(必須)
- 辛さ耐性との適合性
- 好みの味付けとの一致
- 予算との整合性
- 冒険度との適合
出力要件:
- user_summary: ユーザーの特徴を1-2文で要約
- all_scores: 全メニューのスコアをスコア降順でソート済みリスト
- 各スコアの理由を1行で明確に記述
- 懸念点があれば正直に指摘、なければ空文字
個人の満足度を最大化する客観的評価を行ってください。
"""
)
# ===== メイン処理(総当たり分析) =====
async def analyze_individual_menu_match(user: dict, menu_list: List[dict]):
"""個人×メニュー総当たり分析"""
prompt = f"""
【分析対象ユーザー】
{json.dumps(user, ensure_ascii=False, indent=2)}
【レストラン全メニュー】
{json.dumps(menu_list, ensure_ascii=False, indent=2)}
タスク:
上記のユーザーに対して、全{len(menu_list)}メニューを1つずつ評価してください。
評価観点:
1. 食事制限との適合性(最重要)
2. 辛さ耐性とのマッチング
3. 好みの味付けとの一致度
4. 予算範囲との適合性
5. 冒険度・経験との整合性
各メニューに1-10のスコアを付け、その理由を1行で説明してください。
all_scoresは必ずスコアの高い順に並べて出力してください。
"""
result = await matching_agent.run(prompt)
return result.output
def display_individual_analysis(analysis: IndividualMenuAnalysis):
"""個人分析結果の表示"""
print(f"👤 {analysis.user_name} の完全メニュー分析")
print("=" * 60)
print(f"📝 特徴:{analysis.user_summary}")
print()
# トップ3表示(all_scoresは既にソート済み)
print("🏆 あなたにオススメ TOP 3")
print("-" * 40)
for i, menu in enumerate(analysis.all_scores[:3], 1):
emoji = "🥇" if i == 1 else "🥈" if i == 2 else "🥉"
print(f"{emoji} {menu.menu_name}")
print(f" スコア: {menu.match_score}/10")
print(f" 理由: {menu.reason}")
if menu.concern:
print(f" ⚠️ 注意: {menu.concern}")
print()
# 避けるべきメニュー(最後の要素)
worst_menu = analysis.all_scores[-1]
print("❌ 避けた方がよいメニュー")
print("-" * 40)
print(f"💥 {worst_menu.menu_name}")
print(f" スコア: {worst_menu.match_score}/10")
print(f" 理由: {worst_menu.reason}")
if worst_menu.concern:
print(f" ⚠️ 懸念: {worst_menu.concern}")
print()
# 全メニュー一覧(既にスコア順)
print("📊 全メニューランキング")
print("-" * 40)
for i, menu in enumerate(analysis.all_scores, 1):
star = "⭐" * max(1, menu.match_score // 2)
print(f"{i:2d}位 {menu.menu_name:<20} {menu.match_score}/10 {star}")
print()
# ===== 複数人分の一括分析 =====
async def batch_individual_analysis(users: List[dict], menu: List[dict]):
"""複数人の個別分析を一括実行"""
results = []
for user in users:
print(f"🔍 {user['name']} を分析中...")
analysis = await analyze_individual_menu_match(user, menu)
results.append(analysis)
print("✅ 完了")
return results
def display_comparison_summary(all_results: List[IndividualMenuAnalysis]):
"""比較サマリー表示"""
print("\n" + "=" * 80)
print("📋 みんなのベストメニュー比較")
print("=" * 80)
for analysis in all_results:
# all_scoresは既にソート済みなので最初の要素が最高評価
best = analysis.all_scores[0]
print(f"{analysis.user_name:<15} → {best.menu_name:<25} ({best.match_score}/10)")
print(f"\n📊 メニュー人気ランキング")
print("-" * 50)
# 全員のトップ3メニューを集計
menu_popularity = {}
for analysis in all_results:
for i, menu in enumerate(analysis.all_scores[:3]):
score = 3 - i # 1位=3点、2位=2点、3位=1点
menu_popularity[menu.menu_name] = menu_popularity.get(menu.menu_name, 0) + score
ranked_menus = sorted(menu_popularity.items(), key=lambda x: x[1], reverse=True)
for i, (menu_name, score) in enumerate(ranked_menus[:5], 1):
print(f"{i}位 {menu_name:<25} (人気スコア: {score}点)")
# ===== 実行例 =====
async def individual_matching_demo():
print("🎯 個人×メニュー総当たりマッチングシステム(訂正版)")
print("=" * 70)
print(f"📊 分析対象:")
print(f" 👥 ユーザー数: {len(individual_users)}人")
print(f" 🍛 メニュー数: {len(restaurant_menu)}品目")
print(f" 🔢 総評価数: {len(individual_users) * len(restaurant_menu)}件")
print()
print("🤖 全組み合わせを分析中...")
# 全員の個別分析実行
all_analyses = await batch_individual_analysis(individual_users, restaurant_menu)
print("\n" + "=" * 70)
print("📊 個別分析結果")
print("=" * 70)
# 各個人の分析結果表示
for analysis in all_analyses:
display_individual_analysis(analysis)
print("\n" + "-" * 70 + "\n")
# 比較サマリー
display_comparison_summary(all_analyses)
# ===== 実行 =====
if __name__ == "__main__":
# 総当たりマッチングデモ実行
asyncio.run(individual_matching_demo())
注意事項
LLMの最大トークン制限への配慮が不足
現在の実装では全アイテムを一度にプロンプトに含めているため、アイテム数が50件以上になるとLLMのトークン制限に引っかかる可能性があります。
また、大量のデータを処理する際は評価精度が下がり、処理コストも増加する傾向があります。10-20件ずつに分割するバッチ処理や、明らかに不適合なアイテムを事前に除外するフィルタリングなどの対策が必要になります。
この実装は概念を示すデモレベルのものなので、もっと情報量多くなる場合は、更なる改良が必要です。
参考情報