はじめに
この記事では、Google製生成AI「Gemini」の新機能「response_schema」を使って、JSONデータを直接取得し、Pydanticで型安全に扱う方法を紹介します。
環境準備
本記事のコードはGoogle Colabで実行することを想定しています。まず必要なライブラリをインストールしましょう。
!pip install -q google-generativeai pydantic
実装の流れ
- APIキーの設定とクライアント初期化
- Pydanticによるスキーマ定義
- プロンプト作成と構造化出力の指定
- レスポンス取得と構造化データの利用
コード全体
まずは全体のコードを見てみましょう:
from google import genai
from pydantic import BaseModel
from typing import List
from google.colab import userdata
# Geminiクライアント初期化
client = genai.Client(api_key=userdata.get('GEMINI_API_KEY'))
# スキーマ定義:スパイス調合
class Spice(BaseModel):
name: str
amount: str
purpose: str
class CurrySpiceMix(BaseModel):
recipe_name: str
spices: List[Spice]
# プロンプト
prompt = (
"インド風カレーのスパイス調合を提案してください。"
"スパイスの名前、量、目的を含め、レシピ名とともにJSONで返してください。"
)
# コンテンツ生成リクエスト
response = client.models.generate_content(
model="gemini-2.0-flash",
contents=prompt,
config={
"response_mime_type": "application/json",
"response_schema": CurrySpiceMix,
},
)
# 生テキスト表示(JSON文字列)
print("=== JSON出力 ===")
print(response.text)
# オブジェクトとして利用可能(Pydanticモデル化)
parsed: CurrySpiceMix = response.parsed
print("\n=== 構造化出力 ===")
print(f"レシピ名: {parsed.recipe_name}")
for spice in parsed.spices:
print(f"- {spice.name}: {spice.amount}({spice.purpose})")
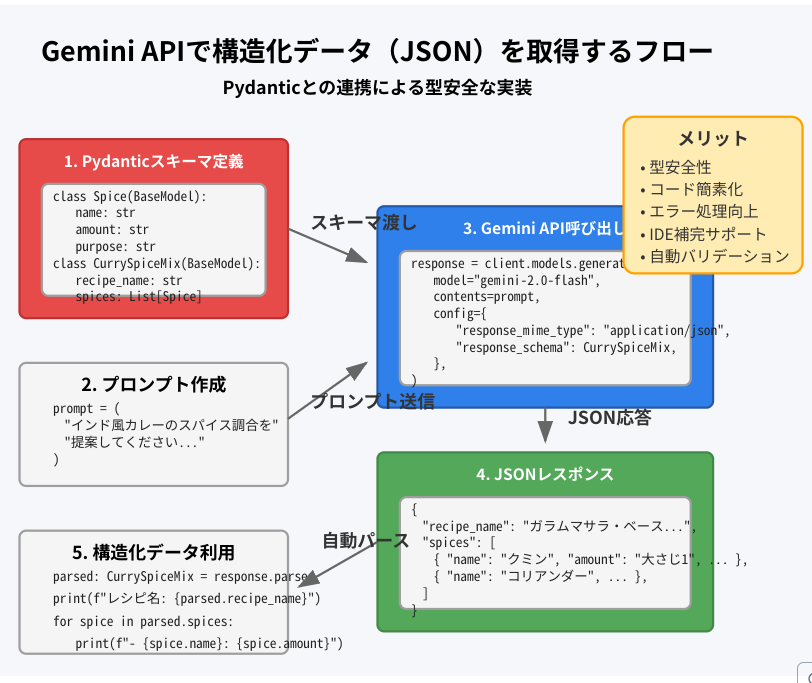
コードの詳細解説
1. APIキーとクライアント初期化
from google import genai
from google.colab import userdata
# Geminiクライアント初期化
client = genai.Client(api_key=userdata.get('GEMINI_API_KEY'))
Colabの環境変数に保存されたAPIキーを使ってGeminiのクライアントを初期化しています。
2. Pydanticによるスキーマ定義
from pydantic import BaseModel
from typing import List
# スキーマ定義:スパイス調合
class Spice(BaseModel):
name: str
amount: str
purpose: str
class CurrySpiceMix(BaseModel):
recipe_name: str
spices: List[Spice]
Pydanticを使って、APIから取得したいデータの型定義を行っています。この定義によって:
-
Spiceクラス:各スパイスの「名前」「量」「目的」の3つのプロパティを持つ -
CurrySpiceMixクラス:「レシピ名」と「スパイスのリスト」の2つのプロパティを持つ
この型定義により、取得するデータに対して静的型チェックが可能になります。
3. プロンプトと構造化出力の指定
# プロンプト
prompt = (
"インド風カレーのスパイス調合を提案してください。"
"スパイスの名前、量、目的を含め、レシピ名とともにJSONで返してください。"
)
# コンテンツ生成リクエスト
response = client.models.generate_content(
model="gemini-2.0-flash",
contents=prompt,
config={
"response_mime_type": "application/json",
"response_schema": CurrySpiceMix,
},
)
ここがこの実装の最も重要なポイントです:
-
response_mime_type: レスポンスの形式をJSONに指定 -
response_schema: 先ほど定義したPydanticクラスを指定
これにより、Gemini APIは指定されたスキーマに従ったJSONを生成してくれます。
4. レスポンスの利用
# 生テキスト表示(JSON文字列)
print("=== JSON出力 ===")
print(response.text)
# オブジェクトとして利用可能(Pydanticモデル化)
parsed: CurrySpiceMix = response.parsed
print("\n=== 構造化出力 ===")
print(f"レシピ名: {parsed.recipe_name}")
for spice in parsed.spices:
print(f"- {spice.name}: {spice.amount}({spice.purpose})")
レスポンスは2つの形式で利用できます:
-
response.text:生のJSON文字列 -
response.parsed:Pydanticモデルにパース済みのオブジェクト
.parsedプロパティを使うことで、すでにPydanticモデルとしてパースされたオブジェクトにアクセスできるため、追加のパース処理は不要です。
実行結果例
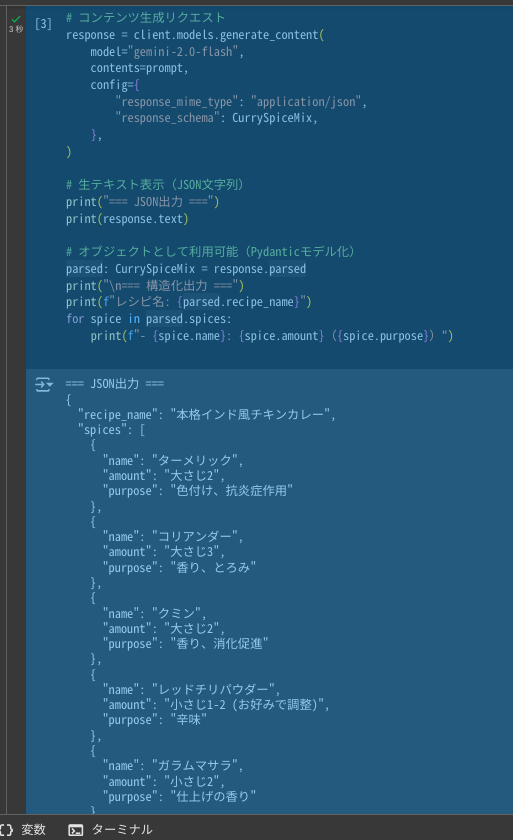
=== JSON出力 ===
{
"recipe_name": "本格インド風チキンカレー",
"spices": [
{
"name": "ターメリック",
"amount": "大さじ2",
"purpose": "色付け、抗炎症作用"
},
{
"name": "コリアンダー",
"amount": "大さじ3",
"purpose": "香り、とろみ"
},
{
"name": "クミン",
"amount": "大さじ2",
"purpose": "香り、消化促進"
},
{
"name": "レッドチリパウダー",
"amount": "小さじ1-2 (お好みで調整)",
"purpose": "辛味"
},
{
"name": "ガラムマサラ",
"amount": "小さじ2",
"purpose": "仕上げの香り"
},
{
"name": "ジンジャーパウダー",
"amount": "小さじ1",
"purpose": "風味、消化促進"
},
{
"name": "ガーリックパウダー",
"amount": "小さじ1",
"purpose": "風味"
}
]
}
=== 構造化出力 ===
レシピ名: 本格インド風チキンカレー
- ターメリック: 大さじ2(色付け、抗炎症作用)
- コリアンダー: 大さじ3(香り、とろみ)
- クミン: 大さじ2(香り、消化促進)
- レッドチリパウダー: 小さじ1-2 (お好みで調整)(辛味)
- ガラムマサラ: 小さじ2(仕上げの香り)
- ジンジャーパウダー: 小さじ1(風味、消化促進)
- ガーリックパウダー: 小さじ1(風味)
この実装のメリット
Pydanticを使うことで、データの型安全性が確保され、手動でJSONを解析する必要がなくなります。スキーマに合わないデータがあった場合には、明確なエラーメッセージが表示されるため、エラー処理も容易です。また、構造化されたオブジェクトに対してIDEの補完が効くため、開発効率が向上します。さらに、Pydanticの自動バリデーション機能により、入力データの整合性を確実に保つことができます。
活用例
この実装パターンは以下のようなケースで特に有効です:
- チャットボットから構造化データを取得したい場合
- 生成AIによるデータエントリーの自動化
- 既存のデータモデルとの連携
- 複雑なJSON構造のハンドリング
注意点
- モデルによってはスキーマ通りの出力を生成できない場合があります
- 複雑すぎるスキーマは失敗しやすいため、シンプルな構造を心がけましょう
- APIキーの管理には十分注意してください
まとめ
Google GeminiのAPI + Pydanticによる構造化データ取得は、生成AIを実践的なアプリケーション開発に組み込む際の強力なパターンです。特に、生成AIの出力を他のシステムと連携させる場合に非常に有効です。
是非、みなさんも自分のユースケースに合わせて試してみてください!