はじめに
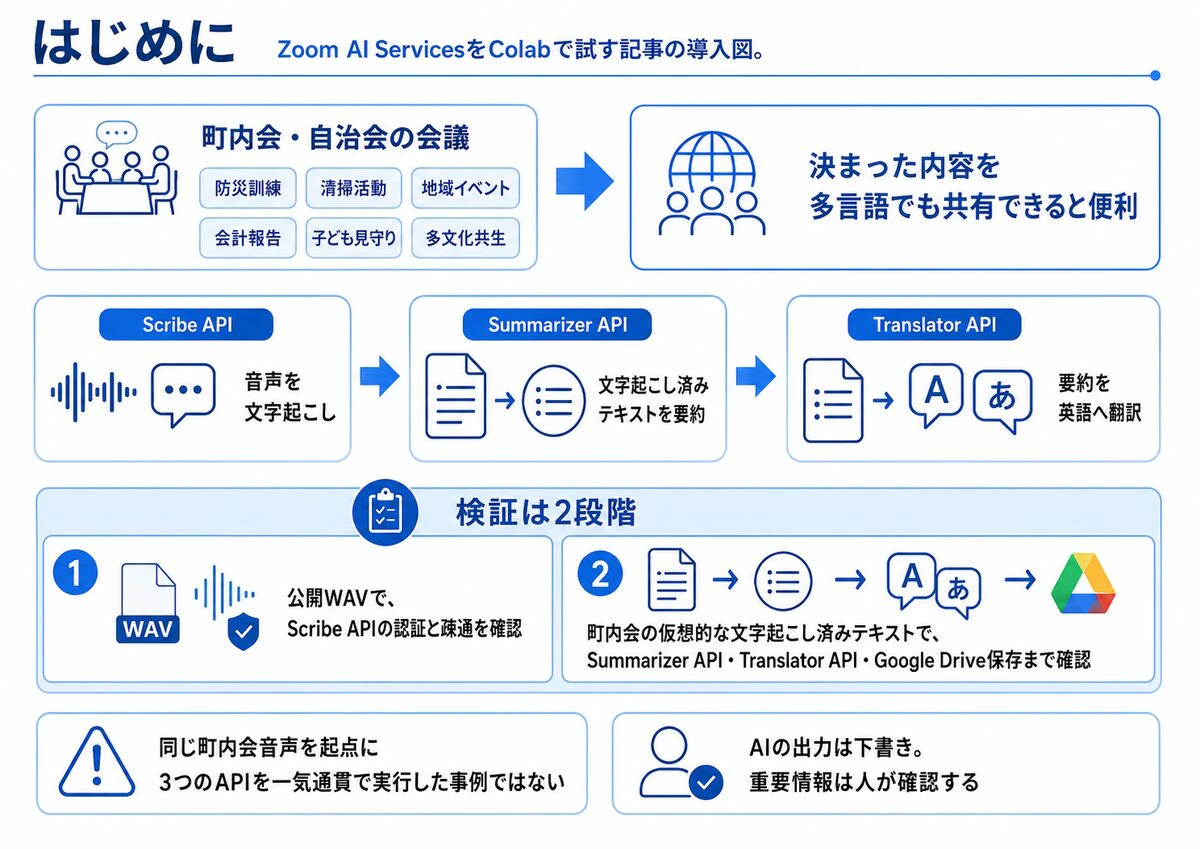
町内会や自治会の会議では、防災訓練、清掃活動、地域イベント、会計報告、子どもの見守り、多文化共生など、さまざまな話題を扱います。
海外出身の住民や、日本語を読むことに慣れていない参加者がいる場合は、「会議で何が決まったか」を日本語だけでなく、別の言語でも共有できると便利です。
この記事では、Google ColabからZoom AI Servicesの次のAPIを呼び出します。
- Scribe API:音声を文字起こしする
- Summarizer API:文字起こし済みテキストを要約する
- Translator API:要約を英語へ翻訳する
ただし、検証内容は次の2段階に分けています。
- Zoom公式ドキュメントでも使用されている公開WAVファイルで、Scribe APIの認証と疎通を確認する
- 町内会の仮想的な文字起こし済みテキストを使い、Summarizer API、Translator API、Google Drive保存まで確認する
つまり、同じ町内会音声を起点として3つのAPIを一気通貫で実行した事例ではありません。Scribe APIの疎通確認と、その後の要約・翻訳処理を分けることで、エラー箇所を切り分けやすくしています。
本記事は2026年6月28日時点の検証メモです。API仕様、利用条件、料金、認証方式は変更される可能性があります。実際に利用するときはZoomの公式ドキュメントを確認してください。
また、町内会・自治会のシナリオは仮想ユースケースです。筆者が実際の町内会で運用した事例ではありません。
AIが生成した文字起こし、要約、翻訳は、そのまま正式な議事録や案内文として配布せず、人が確認して補正する前提で扱います。特に日時、場所、金額、担当者、避難場所、緊急連絡先などの重要情報は、必ず原音声や関係者の確認結果と照合します。
今回確認する流れ

全体の流れは次のとおりです。
事前準備

Zoom AI ServicesのAPI呼び出しには、Zoom Build Platformで発行された API Key と API Secret を使用してJWTを生成します。
ここで使用する認証情報は、一般的なZoom OAuthアプリのClient ID / Client Secretとは別のものです。利用できる機能や課金条件はZoomアカウントの契約状態によって異なるため、事前にZoom Build Platform側でAI Servicesを利用できる状態にしておきます。
Colabでは、最初に必要なライブラリをインストールします。
!pip -q install PyJWT
requests は通常のColab環境に含まれていますが、環境によって不足している場合は一緒にインストールします。
!pip -q install PyJWT requests
Colab Secretsを設定する

Colab左側の鍵アイコンから、次の2つをSecretsに登録します。
ZOOM_API_KEY
ZOOM_API_SECRET
Notebookからは google.colab.userdata で読み出します。
from google.colab import userdata
ZOOM_API_KEY = userdata.get("ZOOM_API_KEY")
ZOOM_API_SECRET = userdata.get("ZOOM_API_SECRET")
if not ZOOM_API_KEY or not ZOOM_API_SECRET:
raise RuntimeError(
"Colab SecretsにZOOM_API_KEYとZOOM_API_SECRETを登録してください。"
)
API KeyやAPI SecretをNotebook本文へ直接書くと、共有時に認証情報が漏れる可能性があります。Colab Secretsや環境変数で管理するほうが安全です。
JWTを生成する

Zoom AI Servicesでは、API Key / API SecretからJWTを生成し、Bearer tokenとしてリクエストヘッダーへ設定します。
JWTの署名アルゴリズムには HS256 を使用し、ペイロードへ iss、iat、exp を設定します。
import time
import jwt
def create_zoom_ai_token(api_key: str, api_secret: str) -> str:
issued_at = int(time.time()) - 30
expires_at = issued_at + 60 * 60
payload = {
"iss": api_key,
"iat": issued_at,
"exp": expires_at,
}
return jwt.encode(
payload,
api_secret,
algorithm="HS256",
headers={
"alg": "HS256",
"typ": "JWT",
},
)
ZOOM_AI_TOKEN = create_zoom_ai_token(
ZOOM_API_KEY,
ZOOM_API_SECRET,
)
この記事では有効期限を1時間にしています。Notebookを長時間開いたままにした場合は、期限切れ後にJWTを再生成します。
API呼び出しの共通処理を作る
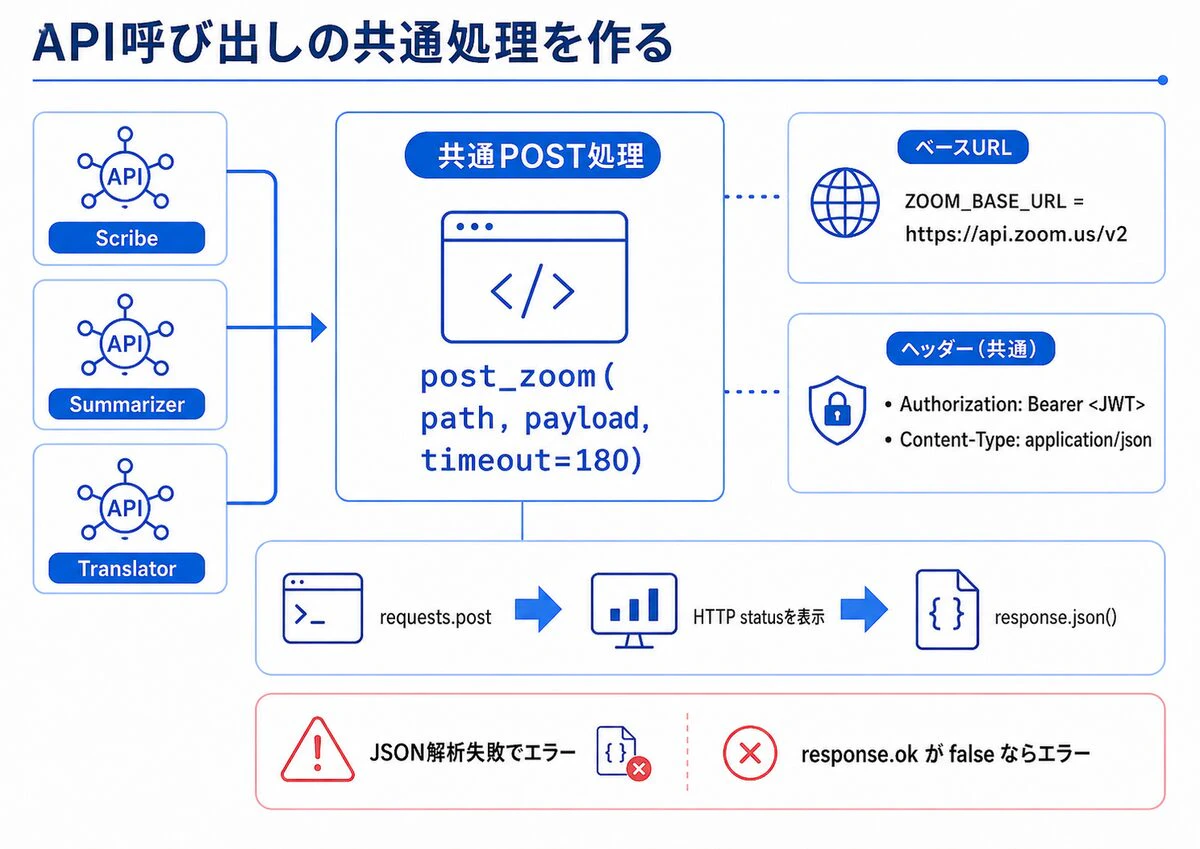
Scribe、Summarizer、Translatorで共通して使うPOST処理を作ります。
import json
import requests
ZOOM_BASE_URL = "https://api.zoom.us/v2"
def zoom_headers() -> dict[str, str]:
return {
"Authorization": f"Bearer {ZOOM_AI_TOKEN}",
"Content-Type": "application/json",
}
def post_zoom(path: str, payload: dict, timeout: int = 180) -> dict:
response = requests.post(
f"{ZOOM_BASE_URL}{path}",
headers=zoom_headers(),
json=payload,
timeout=timeout,
)
print("endpoint:", path)
print("HTTP status:", response.status_code)
try:
data = response.json()
except ValueError as exc:
print(response.text)
response.raise_for_status()
raise RuntimeError("Zoom APIの応答をJSONとして解析できませんでした。") from exc
if not response.ok:
print(json.dumps(data, ensure_ascii=False, indent=2))
response.raise_for_status()
return data
まずScribe APIだけ動かす

最初は、短い公開WAVファイルで疎通確認します。
Scribe API Fast modeは、1つの音声ファイルを同期的に処理する方式です。短い録音の確認に向いています。
def transcribe_audio(audio_url: str, language: str) -> dict:
payload = {
"file": audio_url,
"config": {
"language": language,
"output_format": "json",
},
}
return post_zoom(
"/aiservices/scribe/transcribe",
payload,
)
audio_url = (
"https://www.mmsp.ece.mcgill.ca/Documents/"
"AudioFormats/WAVE/Samples/AFsp/M1F1-Alaw-AFsp.wav"
)
scribe_response = transcribe_audio(
audio_url=audio_url,
language="en-US",
)
print(json.dumps(scribe_response, ensure_ascii=False, indent=2))
レスポンスから表示用の文字起こし本文を取得します。
def extract_transcript_text(data: dict) -> str:
result = data.get("result")
if isinstance(result, dict):
text = result.get("text_display")
if isinstance(text, str) and text.strip():
return text.strip()
raise KeyError(
"result.text_displayが見つかりません: "
+ json.dumps(data, ensure_ascii=False)[:1000]
)
sample_transcript = extract_transcript_text(scribe_response)
print(sample_transcript)
ここまで動けば、次の項目を確認できます。
- Zoom AI Services用JWTを生成できている
- Bearer tokenとして認証できている
- Scribe APIへ音声URLを渡せている
-
result.text_displayから文字起こし結果を取得できている

Google Driveの音声を直接使わない理由

Scribe API Fast modeでは、file にZoom側から取得可能な音声ファイルのURLを渡します。
ColabでGoogle Driveをマウントしても、次のようなColab内のパスをZoomのサーバーから直接読むことはできません。
/content/drive/MyDrive/chonaikai-sample.wav
また、Google Driveの共有URLをダウンロードURLへ変換して渡したところ、今回の検証では次のエラーが返りました。
{
"code": 400,
"reason": "UNSUPPORTED_MEDIA",
"message": "File extension \"\" is not supported. Supported extensions: .m4a, .mp3, .mp4, .wav, .webm",
"metadata": {}
}
https://drive.google.com/uc?export=download&id=... のようなURLでは、URL上にファイル拡張子がないことに加え、Google Drive側のリダイレクトや応答形式などの影響により、Scribe APIが音声ファイルとして判定できなかった可能性があります。
この挙動は今回の検証結果に基づくものであり、「すべてのGoogle Drive URLで必ず失敗する」という意味ではありません。
ただし、Scribe APIの入力として安定させるには、次のようなURLを用意するほうが扱いやすいです。
https://example.com/audio/chonaikai-sample.wav
https://storage.googleapis.com/your-bucket/chonaikai-sample.wav?...
https://your-r2-domain.example/chonaikai-sample.wav?...
実際の町内会音声には、氏名や連絡先などの個人情報が含まれる可能性があります。実運用では完全な公開URLを避け、アクセス期限を短く設定した署名付きURLを使う構成が安全です。
この記事では、Google Driveを入力音声の配信元ではなく、処理結果の保存先として使います。
PowerShellで検証用WAVを作る
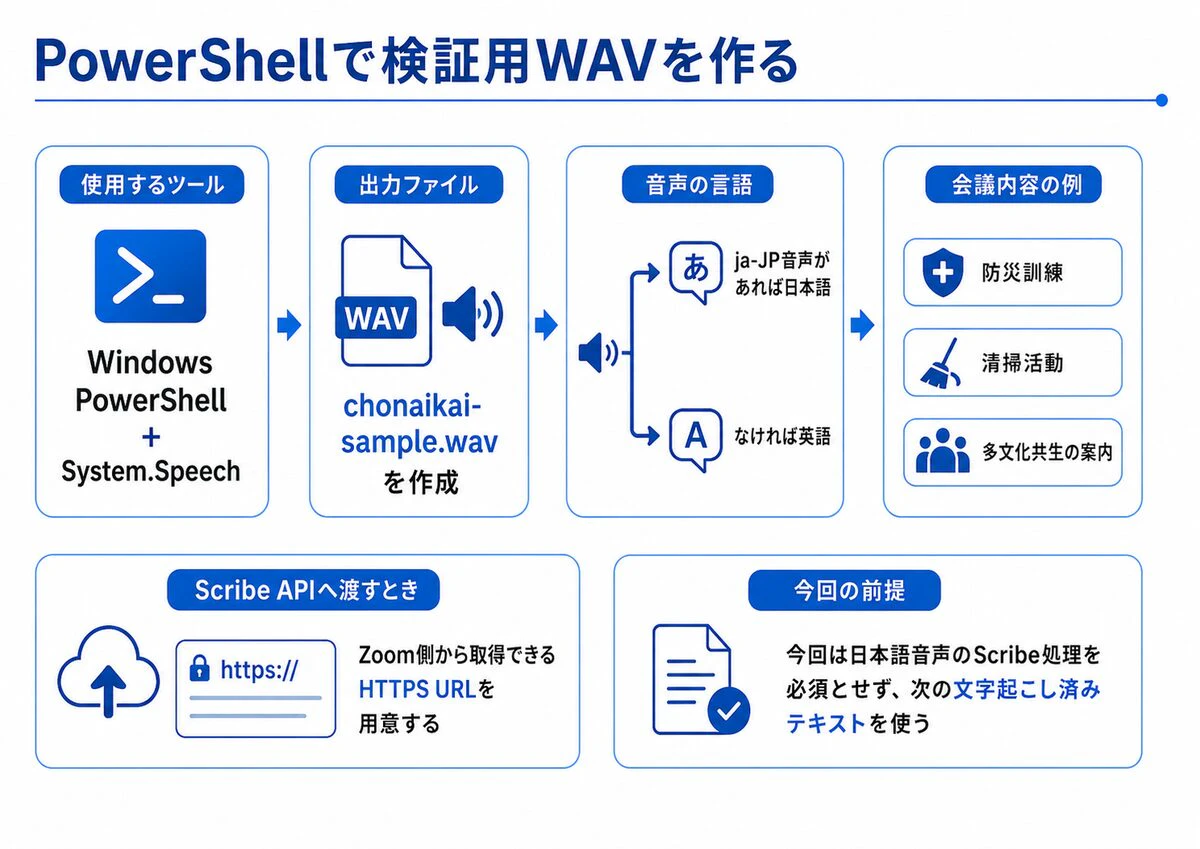
手元に検証用の会議音声がない場合は、Windows PowerShellの System.Speech を使ってWAVファイルを作成できます。
Add-Type -AssemblyName System.Speech
$out = Join-Path (Get-Location) "chonaikai-sample.wav"
$synth = New-Object System.Speech.Synthesis.SpeechSynthesizer
$jaVoice = $synth.GetInstalledVoices() |
Where-Object { $_.VoiceInfo.Culture.Name -eq "ja-JP" } |
Select-Object -First 1
if ($jaVoice) {
$synth.SelectVoice($jaVoice.VoiceInfo.Name)
$text = @"
本日の町内会では、防災訓練、清掃活動、多文化共生の案内について話し合いました。
まず、防災訓練は来月第二土曜日の午前九時から、第一公園に集合して実施します。
雨天の場合は町内会館に集合し、避難経路の確認と備蓄品の点検だけを行います。
山田さんは日本語の案内文を作成し、佐藤さんは掲示板と回覧板への掲載を担当します。
アレックスさんは英語版の案内文を確認し、海外メンバー向けの説明で分かりにくい表現がないかを見ます。
次に、清掃活動は防災訓練の翌週の日曜日、午前八時から実施します。
集合場所は町内会館前で、担当エリアは東側道路、公園周辺、ゴミ集積所の三つに分けます。
軍手とゴミ袋は町内会で用意しますが、トングを持っている人は持参してください。
最後に、外国籍住民向けの案内について、やさしい日本語版と英語版を作る方針になりました。
ゴミ出しルール、防災訓練の日程、緊急連絡先を一枚の資料にまとめ、LINEグループにも投稿します。
次回会議では、案内文の内容と配布日を確認します。
"@
} else {
$text = @"
Today's neighborhood association meeting discussed the disaster drill, neighborhood cleaning activity, and multilingual guidance for international members.
The disaster drill will be held at 9 AM on the second Saturday of next month, starting from Daiichi Park.
If it rains, participants will meet at the neighborhood hall and only review evacuation routes and emergency supplies.
Yamada will prepare the Japanese notice, and Sato will post it on the bulletin board and circulate it.
Alex will review the English notice and check whether any expressions are unclear for international members.
The cleaning activity will be held on the Sunday after the disaster drill, starting at 8 AM.
Participants will meet in front of the neighborhood hall, and the areas will be divided into the east road, the park area, and the garbage collection point.
The association will prepare gloves and garbage bags, but people who have pickup tongs should bring them.
The group also agreed to prepare guidance in plain Japanese and English for international residents.
The document will include garbage disposal rules, the disaster drill schedule, and emergency contact information, and it will also be posted to the LINE group.
At the next meeting, the group will confirm the notice content and the distribution date.
"@
}
$synth.SetOutputToWaveFile($out)
$synth.Speak($text)
$synth.Dispose()
Write-Host "created: $out"
生成した chonaikai-sample.wav をScribe APIへ渡す場合は、Zoom側から取得できるHTTPS URLを用意します。
今回はScribe APIによる日本語音声の処理を必須とせず、次の文字起こし済みテキストを使って、Summarizer API以降の流れを確認します。
町内会の文字起こし済みテキストを用意する

町内会の仮想的な会議を文字起こししたものとして、次のテキストを使います。
transcript = """
本日の町内会では、防災訓練、清掃活動、多文化共生の案内について話し合いました。
まず、防災訓練は来月第二土曜日の午前九時から、第一公園に集合して実施します。
雨天の場合は町内会館に集合し、避難経路の確認と備蓄品の点検だけを行います。
山田さんは日本語の案内文を作成し、佐藤さんは掲示板と回覧板への掲載を担当します。
アレックスさんは英語版の案内文を確認し、海外メンバー向けの説明で分かりにくい表現がないかを見ます。
次に、清掃活動は防災訓練の翌週の日曜日、午前八時から実施します。
集合場所は町内会館前で、担当エリアは東側道路、公園周辺、ゴミ集積所の三つに分けます。
軍手とゴミ袋は町内会で用意しますが、トングを持っている人は持参してください。
最後に、外国籍住民向けの案内について、やさしい日本語版と英語版を作る方針になりました。
ゴミ出しルール、防災訓練の日程、緊急連絡先を一枚の資料にまとめ、LINEグループにも投稿します。
次回会議では、案内文の内容と配布日を確認します。
""".strip()
実際に自分の日本語音声をScribe APIで処理できた場合は、手書きの transcript の代わりに、その日本語音声のレスポンスから取得した文字列を使用できます。
# 公開英語WAVの scribe_response ではなく、
# 自分の日本語音声を処理したレスポンスを指定する
own_scribe_response = transcribe_audio(
audio_url=YOUR_JAPANESE_AUDIO_URL,
language="ja-JP",
)
transcript = extract_transcript_text(own_scribe_response)
公開WAVの疎通確認で作成した scribe_response をここで使うと、町内会テキストではなく公開WAVの英語文字起こし結果が要約対象になります。セルの実行順による上書きを避けるため、変数名を分けて扱います。
会議カテゴリを補助情報として付ける

会議カテゴリによって、確認したい内容は異なります。
def category_context(category: str) -> str:
contexts = {
"disaster_prevention": (
"会議種別: 防災。"
"避難場所、訓練日、担当者、備蓄、連絡網、未決事項に注目する。"
),
"cleaning": (
"会議種別: 清掃活動。"
"実施日、集合場所、担当エリア、必要備品、雨天時対応に注目する。"
),
"festival": (
"会議種別: 地域イベント。"
"日程、係分担、予算、安全管理、次の作業に注目する。"
),
"finance": (
"会議種別: 会計。"
"収支、承認事項、未収金、次回確認事項に注目する。"
),
"child_watch": (
"会議種別: 子ども見守り。"
"見守り場所、時間帯、担当者、注意事項、保護者への連絡に注目する。"
),
"multicultural": (
"会議種別: 多文化共生。"
"多言語案内、やさしい日本語、相談窓口、海外メンバーへの共有事項に注目する。"
),
}
return contexts.get(category, contexts["multicultural"])
ここで行っているのは、Summarizer APIの専用プロンプト機能を使うことではありません。会議カテゴリの説明を入力テキストの先頭へ加える、実験的な工夫です。
カテゴリ情報が常に期待どおり反映される保証はないため、正式な議事録を作る場合は出力結果を確認します。
Summarizer APIで要約する
Summarizer API Fast modeへ、文字起こし済みテキストを渡します。
task に full_summary を指定すると、Recap、Summary、Action Itemsを含む要約を取得できます。今回の実レスポンスでは、本文は result.full_summary に格納されました。
2026年6月時点では、Zoom公式のFast mode解説ページでは要約本文をresult.text、APIリファレンスではresult.full_summaryなどのタスク別フィールドとして記載しており、公式ドキュメント内でも差異があります。今回の実レスポンスはAPIリファレンス側の形式でした。そのため、本記事では両方の形式を考慮して抽出します。
def build_summary_input(transcript: str, category: str) -> str:
context = category_context(category)
return f"{context}\n\n--- transcript ---\n{transcript}"
def summarize_meeting(
transcript: str,
category: str,
language: str,
) -> dict:
payload = {
"input": {
"text": build_summary_input(transcript, category),
},
"config": {
"summary_type": "conversation",
"task": "full_summary",
"language": language,
},
"reference_id": f"chonaikai-{category}",
}
return post_zoom(
"/aiservices/summarizer/summarize",
payload,
)
def extract_summary_text(data: dict) -> str:
result = data.get("result")
if not isinstance(result, dict):
raise KeyError(
"resultが見つかりません: "
+ json.dumps(data, ensure_ascii=False)[:1000]
)
# APIリファレンス側の形式
full_summary = result.get("full_summary")
if isinstance(full_summary, str) and full_summary.strip():
return full_summary.strip()
# Fast mode解説ページ側の形式
text = result.get("text")
if isinstance(text, str) and text.strip():
return text.strip()
# 分割されたフィールドしか返らない場合に備えて結合する
parts = []
for key in ["recap", "summary_text", "action_items"]:
value = result.get(key)
if isinstance(value, str) and value.strip():
parts.append(value.strip())
if parts:
return "\n\n".join(parts)
raise KeyError(
"要約本文が見つかりません。resultのキー: "
+ str(list(result.keys()))
)
要約を実行します。
MEETING_CATEGORY = "multicultural"
SUMMARY_LANGUAGE = "ja-JP"
summary_response = summarize_meeting(
transcript=transcript,
category=MEETING_CATEGORY,
language=SUMMARY_LANGUAGE,
)
meeting_note_ja = extract_summary_text(summary_response)
print(meeting_note_ja)
今回確認した task="full_summary" のレスポンスでは、要約本文は result.full_summary に格納されました。抽出関数ではこのキーを最優先に確認し、レスポンス差異に備えて他の候補キーも順に確認します。

Summarizer API Fast modeの入力上限は96 KBです。
長時間会議の文字起こしを扱う場合は、入力サイズを確認し、
必要に応じて内容を適切な単位へ分割するか、Batch modeを検討します。
Translator APIで英語へ翻訳する
Translator API Fast modeは、1回のリクエストにつき1つの翻訳先言語を指定します。また、入力テキストの上限は4,000文字です。
末尾を気付かないまま切り捨てると、Action Itemsなどの重要情報が欠ける可能性があります。そのため、この記事では上限を超えた場合にエラーとします。
TRANSLATOR_MAX_CHARS = 4000
def translate_text(
text: str,
source_language: str,
target_language: str,
) -> dict:
if len(text) > TRANSLATOR_MAX_CHARS:
raise ValueError(
"Translator API Fast modeの入力上限を超えています: "
f"{len(text)}文字 / 上限{TRANSLATOR_MAX_CHARS}文字"
)
payload = {
"text": text,
"config": {
"source_language": source_language,
"target_languages": [target_language],
},
"reference_id": "chonaikai-translation",
}
return post_zoom(
"/aiservices/translator/translate",
payload,
)
def extract_translation_text(data: dict, target_language: str) -> str:
result = data.get("result")
if isinstance(result, dict):
translations = result.get("translations")
if isinstance(translations, dict):
text = translations.get(target_language)
if isinstance(text, str) and text.strip():
return text.strip()
raise KeyError(
f"result.translations[{target_language!r}]が見つかりません: "
+ json.dumps(data, ensure_ascii=False)[:1000]
)
日本語の要約を英語へ翻訳します。
現在のTranslator APIは英語との相互翻訳に対応しており、翻訳元または翻訳先のどちらかをen-USにする必要があります。今回のja-JPからen-USへの翻訳は対応範囲内です。
TRANSLATE_TO = "en-US"
translation_response = translate_text(
text=meeting_note_ja,
source_language=SUMMARY_LANGUAGE,
target_language=TRANSLATE_TO,
)
meeting_note_en = extract_translation_text(
translation_response,
TRANSLATE_TO,
)
print(meeting_note_en)
要約が4,000文字を超える場合は、段落単位で分割して複数回翻訳するか、要約内容を短くする必要があります。
Google DriveへMarkdownとJSONを保存する
最後に、文字起こし、要約、翻訳結果をGoogle Driveへ保存します。
Markdownは人が読みやすい形式、JSONは後続のプログラムから再利用しやすい形式として保存します。
from datetime import datetime
from pathlib import Path
from zoneinfo import ZoneInfo
from google.colab import drive
drive.mount("/content/drive")
now_jst = datetime.now(ZoneInfo("Asia/Tokyo"))
timestamp = now_jst.strftime("%Y%m%d_%H%M%S")
out_dir = (
Path("/content/drive/MyDrive/zoom_ai_chonaikai_verified")
/ timestamp
)
out_dir.mkdir(parents=True, exist_ok=True)
(out_dir / "transcript.md").write_text(
"# Transcript\n\n" + transcript + "\n",
encoding="utf-8",
)
(out_dir / "meeting_note_ja.md").write_text(
"# Meeting Note JA\n\n" + meeting_note_ja + "\n",
encoding="utf-8",
)
(out_dir / "meeting_note_en.md").write_text(
"# Meeting Note EN\n\n" + meeting_note_en + "\n",
encoding="utf-8",
)
result_data = {
"created_at": now_jst.isoformat(),
"meeting_category": MEETING_CATEGORY,
"summary_language": SUMMARY_LANGUAGE,
"translation_language": TRANSLATE_TO,
"transcript": transcript,
"meeting_note_ja": meeting_note_ja,
"meeting_note_en": meeting_note_en,
"zoom_responses": {
"summarizer": summary_response,
"translator": translation_response,
},
}
(out_dir / "result.json").write_text(
json.dumps(result_data, ensure_ascii=False, indent=2),
encoding="utf-8",
)
print("saved:", out_dir)
保存されるファイルは次の4つです。
transcript.md
meeting_note_ja.md
meeting_note_en.md
result.json
出力イメージ
多文化共生の会議では、次のような日本語共有ノートを作成する想定です。
# Meeting Note JA
Recap:
町内会では、防災訓練、清掃活動、外国籍住民向け案内の準備について確認した。
Summary:
防災訓練は来月第2土曜日の午前9時から第一公園で実施する。
雨天時は町内会館で避難経路と備蓄品を確認する。
清掃活動は翌週の日曜日に実施し、やさしい日本語版と英語版の案内も作成する。
Action Items:
- 山田さん: 日本語の案内文を作成する
- 佐藤さん: 掲示板と回覧板へ掲載する
- アレックスさん: 英語版の案内文を確認する
- 次回会議: 案内文の内容と配布日を確認する
Translator APIで英語へ変換した共有ノートは、海外出身の住民や日本語を読むことに慣れていない参加者への案内の下書きとして利用できます。
実際の出力内容は、入力テキストやAPI側のモデルによって変わります。
実運用で注意したいこと

AIの出力をそのまま確定情報にしない
要約や翻訳では、日時、固有名詞、担当者、数値などを誤る可能性があります。重要な情報は原音声、元資料、関係者の確認結果と照合します。
録音前に参加者へ説明する
会議を録音し、外部のAIサービスへ送信する場合は、参加者への説明、同意、保存期間、閲覧権限などを事前に整理します。
音声URLを不用意に公開しない
実際の会議音声をインターネット上へ無期限で公開するのは避けます。可能であれば、有効期限を短くした署名付きURLを使用します。
長時間の会議にはFast mode以外も検討する
この記事では確認しやすさを優先してFast modeを使っています。長時間音声、大量ファイル、非同期処理が必要な場合は、各APIのBatch modeも検討します。
まとめ

Google ColabからZoom AI Servicesを呼び出し、次の流れを確認しました。
- Colab SecretsからZoom Build PlatformのAPI Key / API Secretを取得する
- PyJWTでZoom AI Services用JWTを生成する
- 公開WAVファイルでScribe APIの認証と疎通を確認する
- 町内会の文字起こし済みテキストをSummarizer APIで要約する
- Translator APIで日本語の要約を英語へ翻訳する
- MarkdownとJSONをGoogle Driveへ保存する
今回は、Scribe APIの疎通確認と町内会シナリオの後続処理を分けました。この構成なら、音声取得の問題と、要約・翻訳の問題を切り分けながら確認できます。
町内会のように、参加者のITスキルや言語背景が異なる場面では、録音を残すだけでなく、内容を読みやすい共有ノートへ変換することに意味があります。
ただし、AIが作成する共有ノートは最終成果物ではなく下書きです。人が確認し、誤りを直し、必要な補足を加えたうえで配布します。
試して感じたこと (感想)
今回試したこと
今回は、町内会という仮想的なユースケースを考え、Zoom AI Servicesを使って次の流れを試しました。
- 音声の文字起こし
- 会議内容の要約
- 英語への翻訳
- Google Driveへの保存
Zoom AI Servicesは、エンタープライズ向けの文字起こし、要約、翻訳の技術をAPIとして利用できる点が特徴です。
自前でAI基盤を構築するのではなく、処理量や予算を見ながら利用を検討できる点は、地域活動や個人の取り組みにも応用しやすいと感じました。
要約時に補助情報を加える工夫
要約では、文字起こし済みテキストをそのまま渡すだけでなく、会議カテゴリに応じて次のような注目点を入力テキストの先頭に加えました。
- 日時
- 担当者
- 未決事項
- 共有すべき内容
- 次回までの対応事項
これはSummarizer APIの専用プロンプト機能ではなく、入力テキストに補助情報を加える実験的な方法です。
必ず期待どおりに反映されるとは限りませんが、会議や音声資料の種類に応じて、重要な情報を確認しやすい形へ整理する工夫として活用できる可能性を感じました。
過去の音声資産にも活用できる可能性
活用先は、新しく録音する会議だけではありません。
例えば、次のような過去の音声資産にも利用できるかもしれません。
- 研究室に残っている過去の講義や研究記録
- 地域団体が保管している会議音声
- インタビューや聞き取り調査の録音
- 資料館や個人が所有している地域史の音声
- カセットテープ、磁気テープ、レコードなどに残された音声
物理メディアの場合は、あらかじめWAVやMP3などへデジタル化する必要があります。
その後、Zoom AI Servicesを使って次のような処理へつなげることが考えられます。
- 音声を文字起こしする
- 要点や対応事項をまとめる
- 人物名、日時、研究テーマなどを確認しやすい形へ整理する
- 翻訳して共有しやすくする
- 検索可能なデータとして保存する
予算や期間が決まっている場合の進め方
すべての音声を人が最初から聞き直して整理するには、多くの時間と費用がかかります。
予算や作業期間がある程度決まっている場合には、次のような進め方も考えられます。
- AIで文字起こしと要約の下書きを作る
- 必要な情報を整理する
- 人が重要な箇所を原音声と照合する
- 検索や共有ができる形式で保存する
AIにすべてを任せるのではなく、人が確認する箇所を絞るための補助として使うイメージです。
実際に活用するときの注意点
実運用では、次の点を事前に確認する必要があります。
- 著作権や利用権限
- 録音された本人や参加者の同意
- 個人情報や研究倫理
- 音声データの保存期間
- 公開範囲や閲覧権限
- AI出力の正確性
それでも、音声として眠っている過去の資産を、読める情報、探せる情報、共有できる情報へ変える用途には、検討する価値があると感じました。