はじめに
オープンソースのQwen3-Coderが公開され、素人の私は「わんちゃんローカルLLM??」と胸を膨らませたもののあっさり打ち砕かれたのがこの記事。
最先端のバイブコーディングをしたいもの、あまりにも金欠すぎて毎月高額課金できない。
でもバイブコーディングしたい!そこそこのGPUリソースある!電気代定額なので使い放題!の恵まれた環境がそろっているのでこれはなにかしないともったいない。
ということで最新のQwen3-Coderよりも古いけどローカルで動かせそうなQwen2.5-Coderを使って、無課金ローカルバイブコーディングできる環境を整える手順をまとめました。LLMを稼働させているホストPCと同じネットワークに繋がったクライアントPCからもアクセスできるようする手順も書いてます。
ちなみにこのQwen2.5-Coderは2024年11月に公開されたものでGPT-4oと肩を並べる程度の性能があります。
実行環境
以下の環境で実行しています。
Windows PC (ホストPC)
| 項目 | 内容 |
|---|---|
| CPU | Intel Core i9-14900K |
| メモリ | DDR4 64GB |
| GPU | NVIDIA GeForce RTX 3090 (VRAM24GB) |
| OS | Windows 11 |
M4 Mac mini (クライアントPC)
| 項目 | 内容 |
|---|---|
| CPU | M4チップ |
| メモリ | 16GB |
| OS | macOS Sequoia |
参考になった記事
以下の記事を参考にしました。
Ollamaの導入
OllamaはいろんなLLMを簡単に実装できるLLM実行プラットフォームです。
入れるのはとても簡単。
リンクから好きなOS選んでダウンロードします。私はWindowsで入れました。
ダウンロードした実行ファイルを実行して、インストールが終わったら、ターミナルで
ollama --version
を実行してバージョンが表示されたらOKです。
Qwen2.5-Coderモデルのダウンロード
Ollamaに対応したモデルが公開されています。
いくつかのモデルがありますね。32bはこの中では最も性能が良いですが多くのVRAMを必要とするのに対し、0.5bは軽量版なのでVRAM必要量も少なく高速ですが、性能は落ちます。
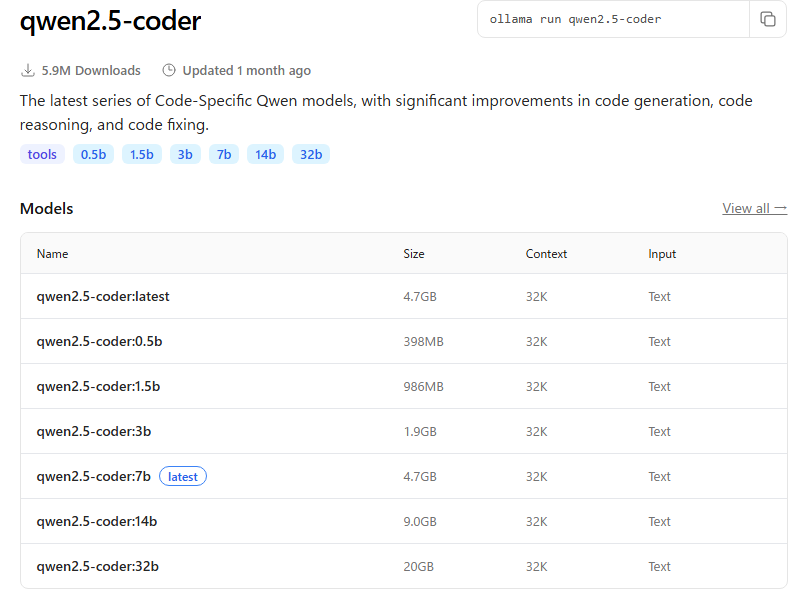
私はコーディングを目的としているので、なるべく性能がいいものを使いたい。このページではモデルを動作させるのに必要なシステム要件が書かれていないので実際に入れて試してみるしかないです。ここで書かれているSizeはファイルのサイズを意味しています。
32bモデルのテスト
私はVRAM24GBのRTX3090を使っているので、いったん一番大きな32bモデルを試してみます。
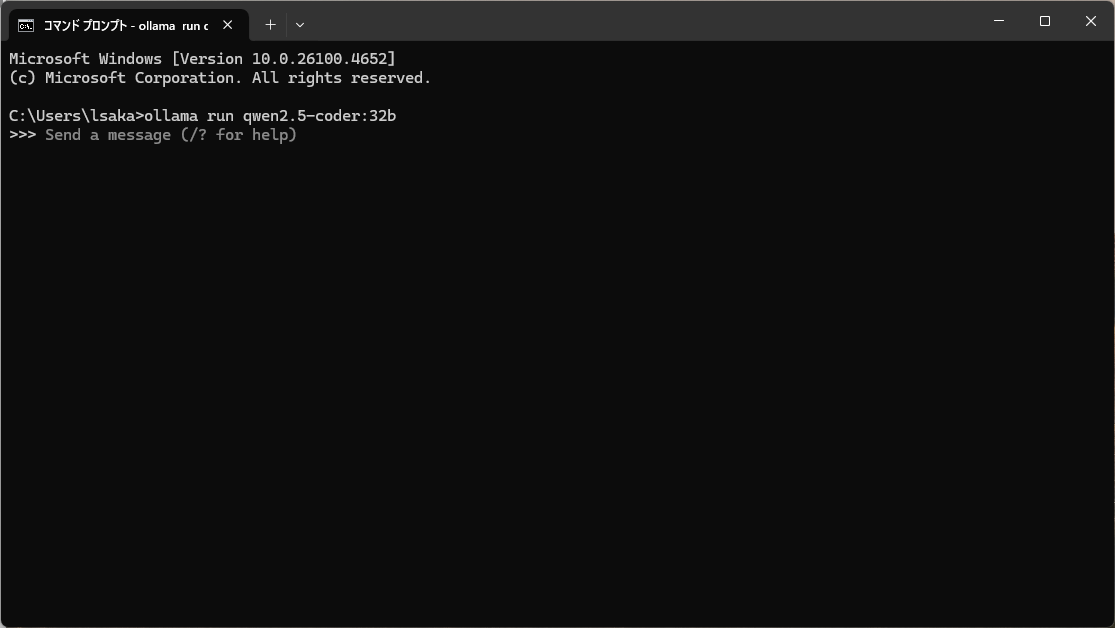
ターミナルで以下を実行すれば32bモデルをダウンロードしてそのまま実行してくれます。
ollama run qwen2.5-coder:32b
こんなかんじでSend a messageが出ればOKです。
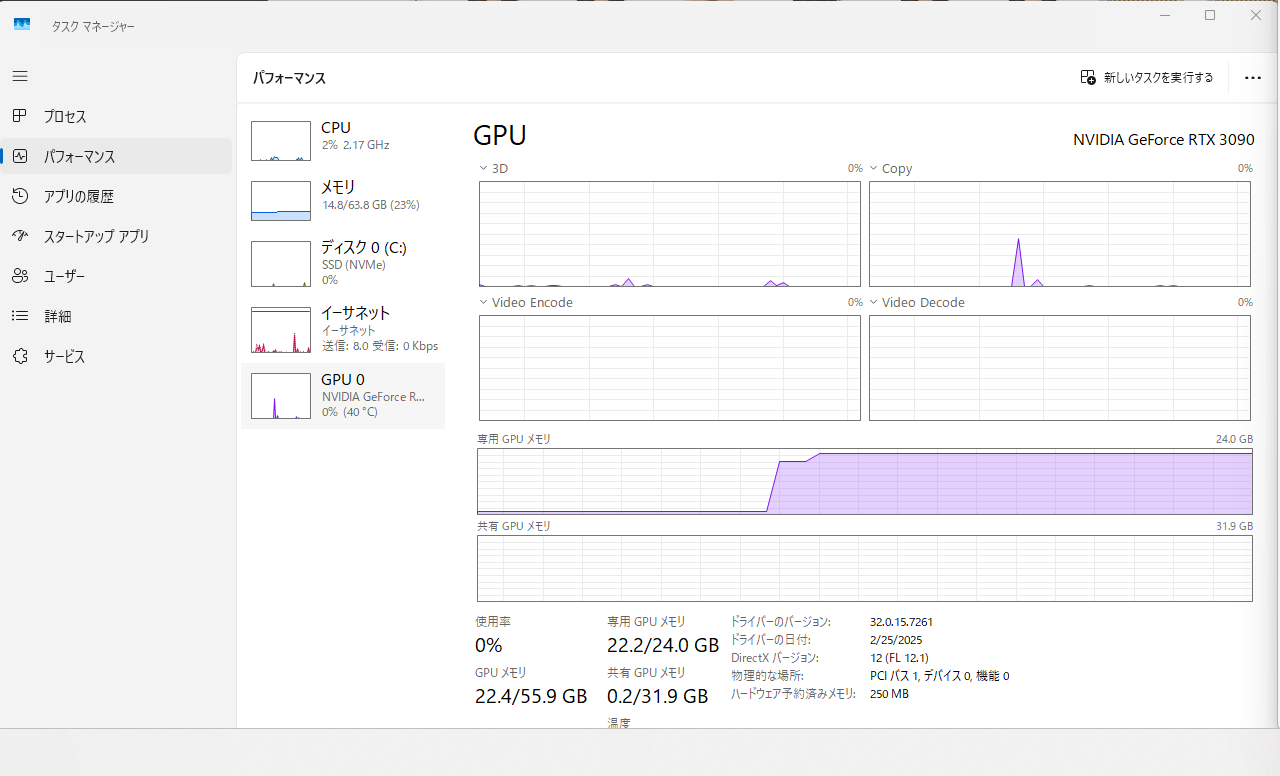
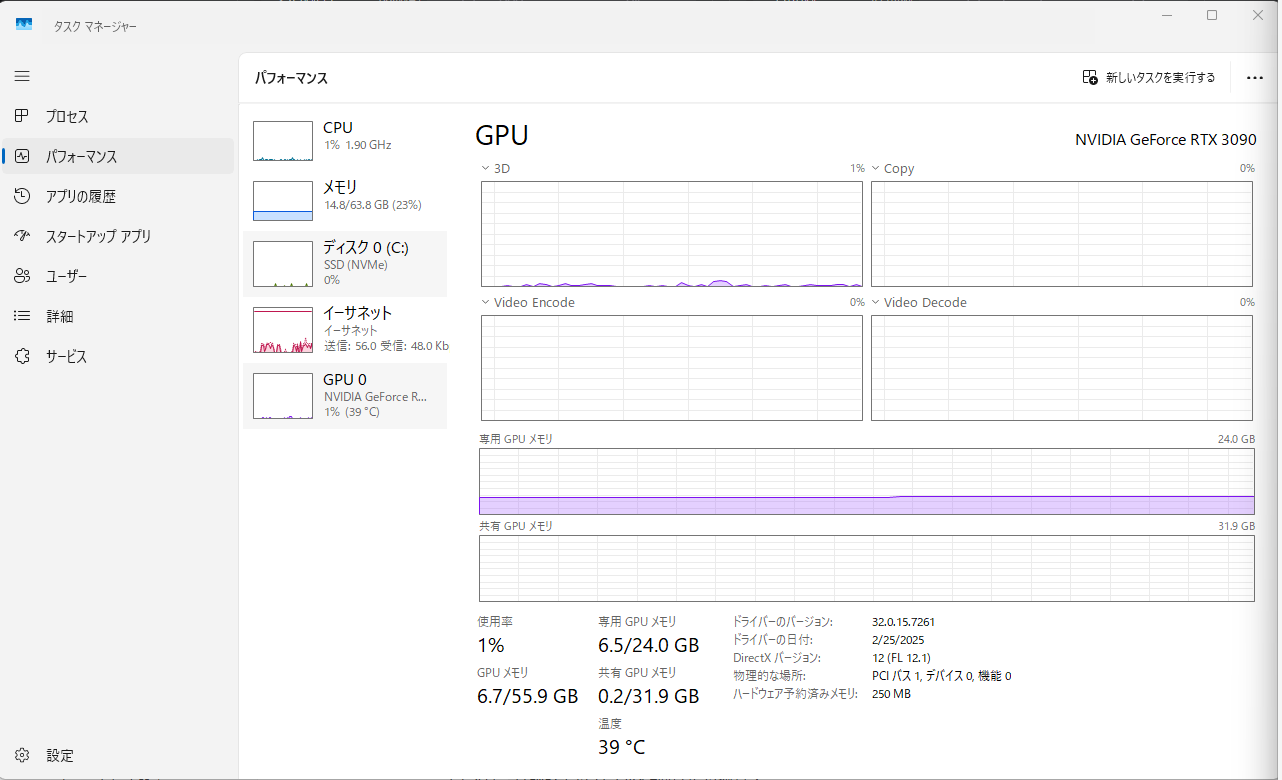
実行を開始したとたん、GPUメモリのほぼすべてが占有されましたw
これ足りてるのか??
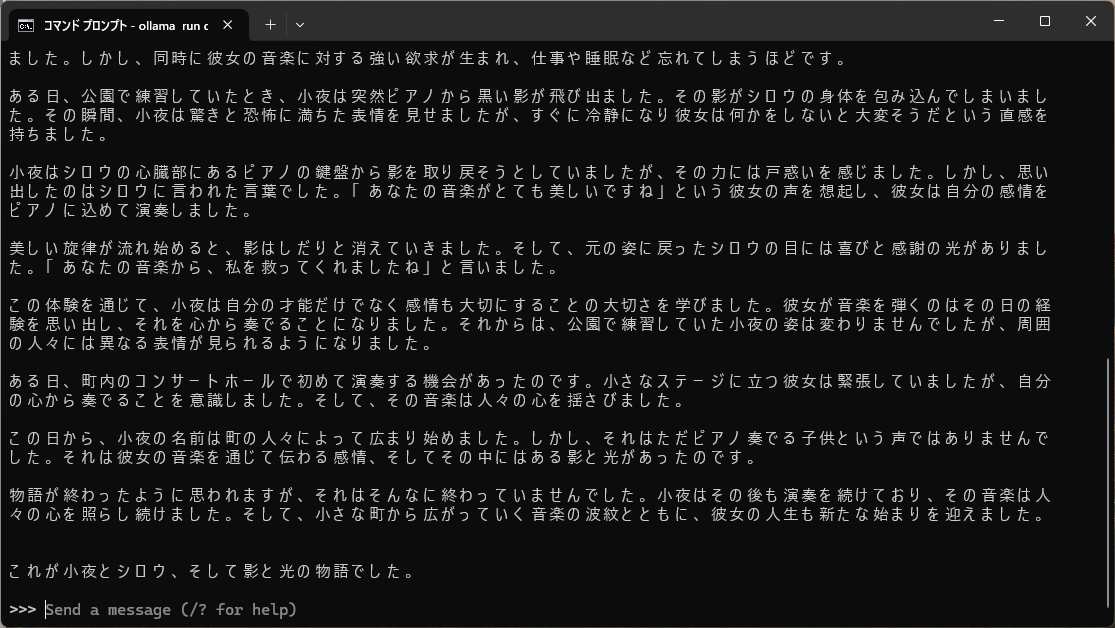
こんなかんじでてきとうに試してみましょう。
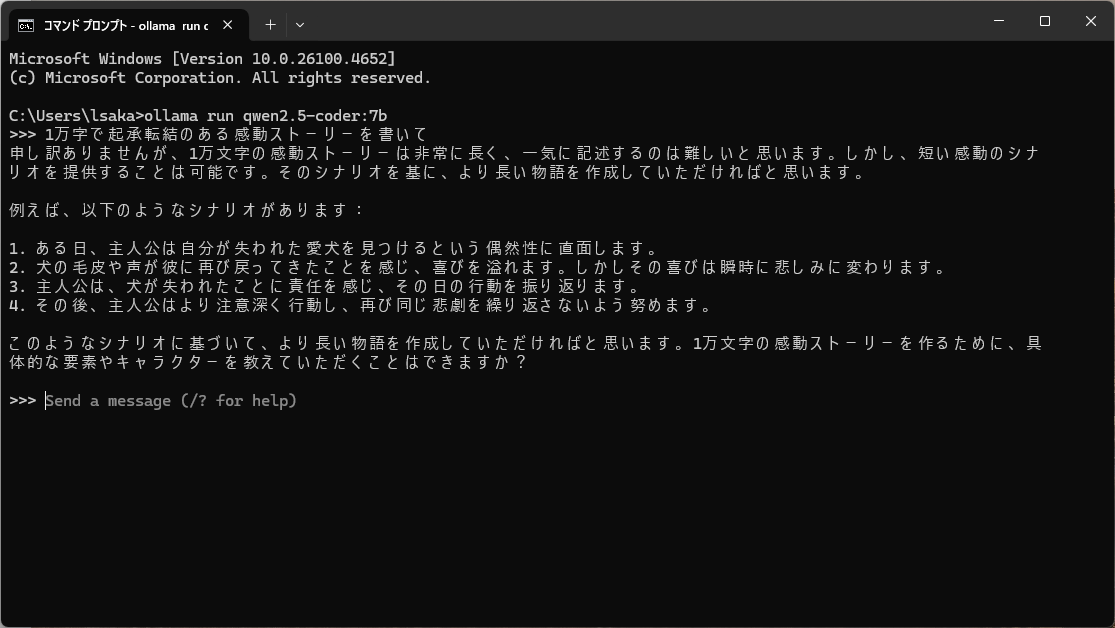
1万字で起承転結のある感動ストーリーを書いて
速度としては、ChatGPTと同じぐらいだったので実用面でも問題なさそうです。
7bモデルのテスト
私は32bモデルで問題なさそうですが、参考までに7bモデルも入れて試してみました。
同じようなコマンドで7bモデルを入れます。
ollama run qwen2.5-coder:7b
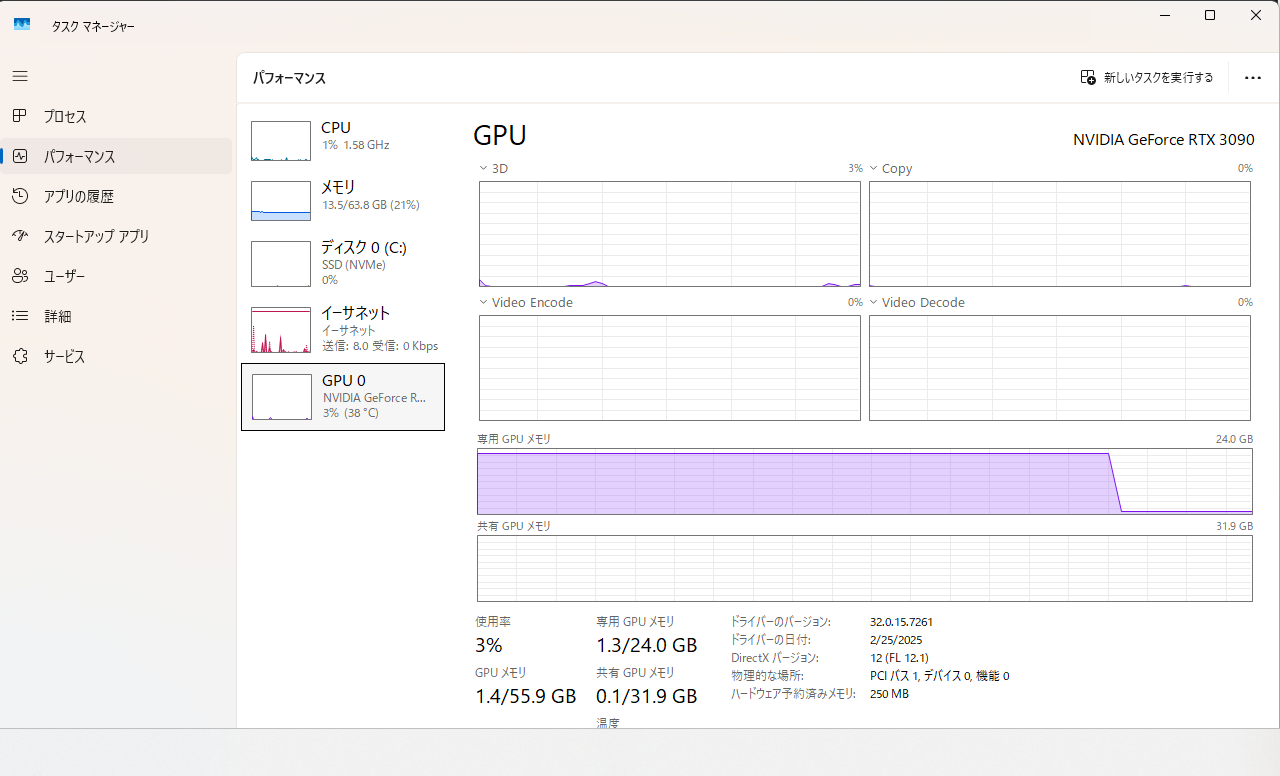
こちらはGPUメモリを6.5GBほど占有しました。
実行速度は32bモデルの倍ぐらい速かったですが、同様の指示を出したところ、難しいと言われちゃいました。
32bから2つもモデルを下げるだけでこんなに違いがでるものなんですね。
ご自身のGPUメモリとご相談のうえ、最適なモデルを入れるようにしましょう。
以上でLLMの準備は終わりです。
終わりかた
ちなみにLLMを終了するとき、
/bye
で会話は終了できますが、
実行したQwenモデルを指定して停止させないとGPUメモリは解放されないので注意。
ollama stop qwen2.5-coder:32b
ローカルネットワークで使えるようにする
私の目論見としては、windows PCでこのQwen2.5-Coderを常時稼働させて、同じネットワークに接続されたMacから呼び出して使えるようにする、というものです。
Ollamaは稼働時にhttp://localhost:11434でAPIを受け付けるようですが、これはあくまでホストPCのみなので、同じネットワークにつながった別PCからはアクセスできません。なので設定が必要です。
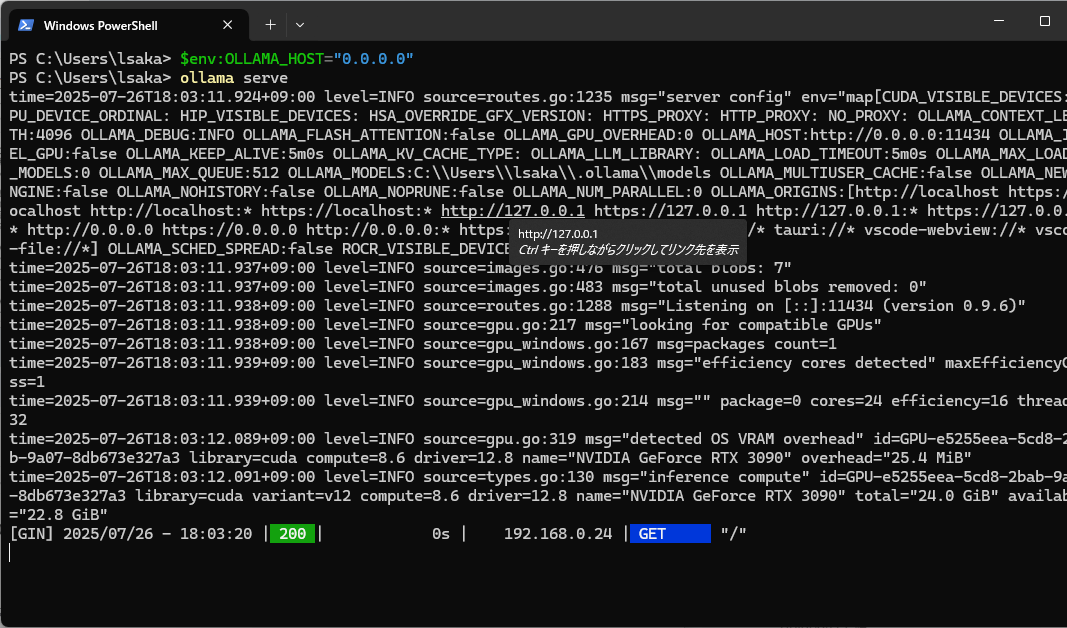
Windows PCのパワーシェルを開いて、以下を実行します。
$env:OLLAMA_HOST="0.0.0.0"
ollama serve
※OllamaでQwen2.5-Corderを稼働したままの状態にしておいてください。
これで解放されました。Macでもなんでもいいので、以下のアドレスにアクセスするとOllama is runningが確認できます。
http://<Ollama稼働させているPCのIPアドレス>:11434
これは同じネットワークに繋がっているMacから接続した様子。
もちろん、同じネットワークであればiPhoneからでも接続できます。
リクエストの送信(これはやらなくてもOK)
OllamaはAPIを用意してくれているので、接続できたアドレスに対してAPIのリクエストを送ればLLMを動かせるというわけです。
動作テストとして、以下のcurlコマンドをjson形式でリクエストを送ります。
curl http://<Ollama稼働させているPCのIPアドレス>:11434/api/generate \
-H "Content-Type: application/json" \
-d '{"model": "qwen2.5-coder:32b", "prompt": "こんにちは。自己紹介してください", "stream": false}'
回答が返ってくればOKです。 ここまでやってもまだ「それChatGPTでよくね?」なので、VScodeに統合します。
VScodeへのローカルLLM統合設定(ホストPC側)
まずはOllamaを稼働させているホストPCで設定してみます。クライアント側でしか使わないよって人は飛ばしてOKです。
VScodeでContinueという拡張機能を入れます。これはAIアシスタントをVScodeに統合するための拡張機能です。
インストールすると左側に新しく追加されます。グレー色のボタンの下にあるOr, configure your own modelsを押します。
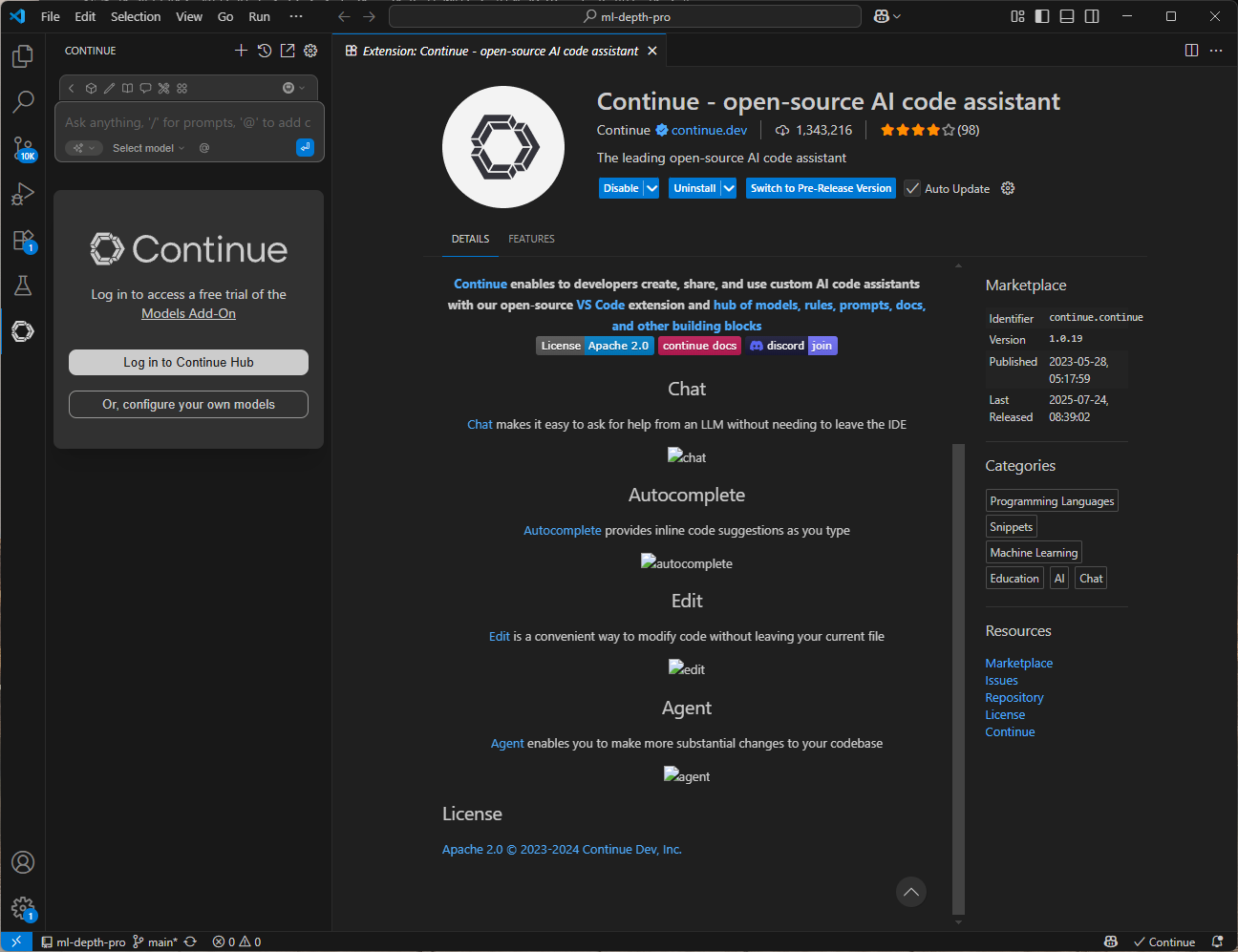
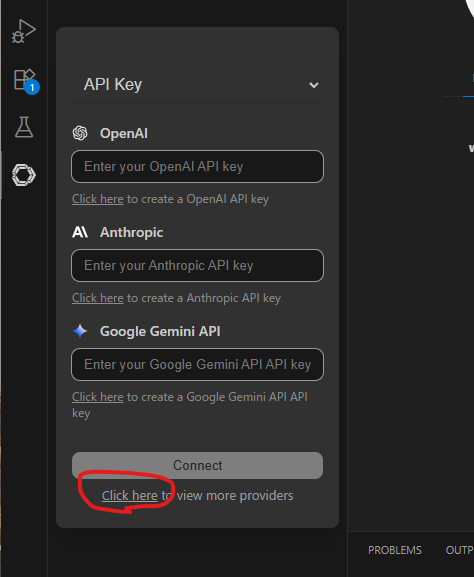
タブからAPI Keyを選択して、
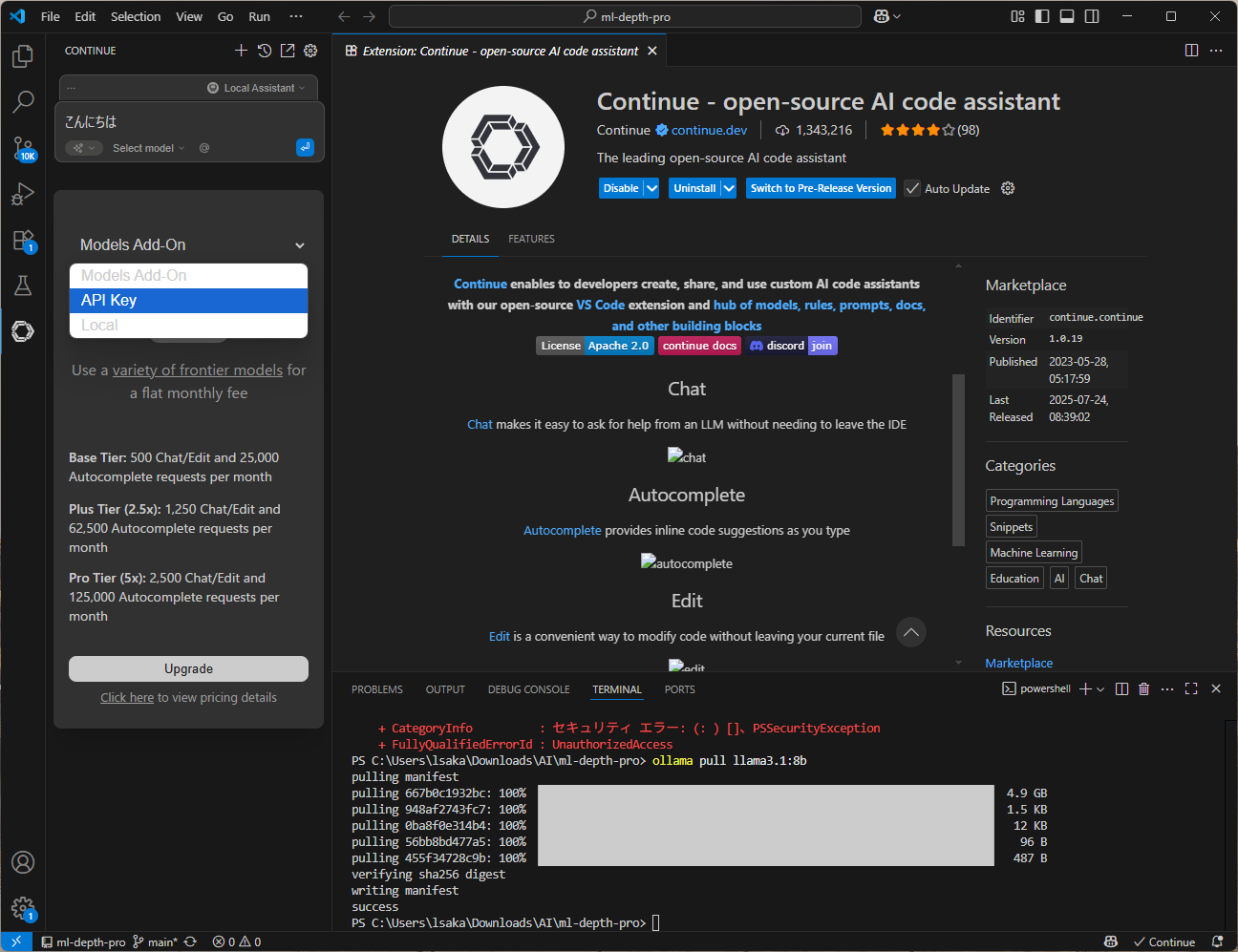
Click hereをクリック
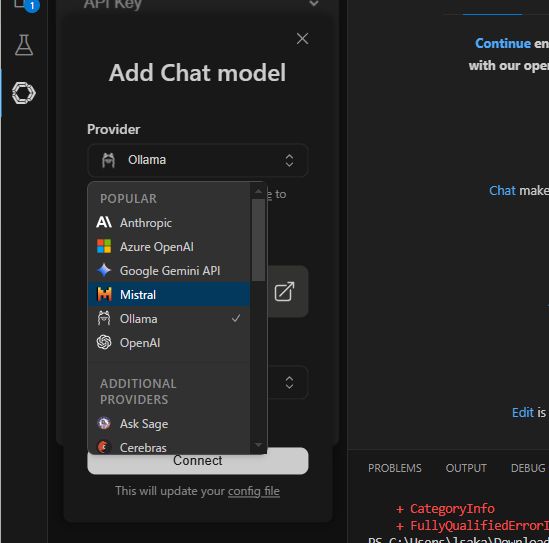
ProviderでOllamaを選択。
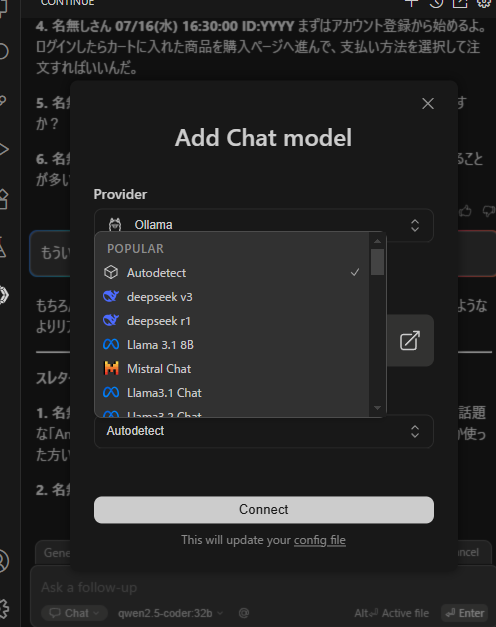
一番上にあるAutodetectを押してConnectするとOllamaの中にあるすべてのモデルを自動で追加してくれます。
これでOK。
使い方
Ctrl + Shift + L(Lは大文字)のショートカットでContinueの画面を出したり、コードを範囲選択した状態で押すとチャット欄に入れることができますので覚えておきましょう。
入力欄の左下にある部分がChatになっていることを確認しておきましょう。これがAgentになってるとjson形式のよくわからない返答になってします。
テストとして、以下の指示で確認してましょう。ちなみに@を使ってファイルなどいろんな媒体を与えることもできます。
pythonでユーザーとじゃんけんするスクリプト書いて
生成が終わったら、赤丸のところにあるInsert Codeボタンを押すと生成したコードがエディターに挿入されます。
これが、、、バイブコーディング、、、なのか???
これだと出力される文字が英語なので読みづらいですね。日本語に変えるように指示しましょう。再び生成されたコードに対して、Applyを押すと前回生成していたコードを1行ずつ精査して差分を表示してくれます。
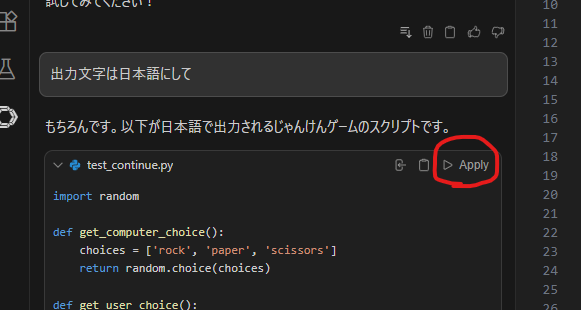
変更がよければAcceptを押して確定しましょう。そして実行して確かめてみます。
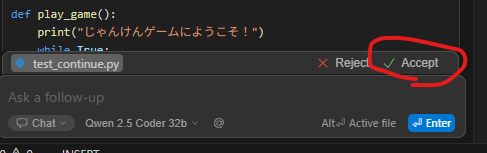
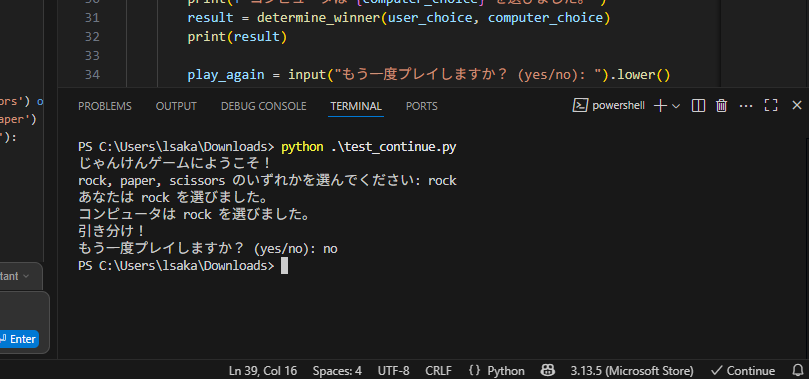
無事遊べましたね。
別PCからでもバイブコーディングできるようにする
今度はさっきやった内容をローカルネットワーク接続しているほかのPCでもできるように設定します。
これContinueの仕様変更のせいでかなり苦戦したのですが、なんとかできました。それをまとめた記事がこちら↓
手順はさっきやったこととほぼ一緒です。
VScodeにContinueを入れて、LLMのモデルを選択するのですが、このモデル選択が先ほどとちょっと違います。
まず一度Add Chat modelを押して
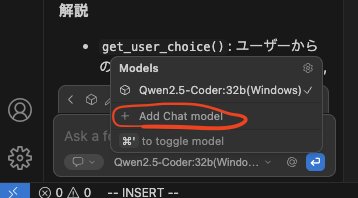
OllamaのAutodetectでいったんConnect押します。
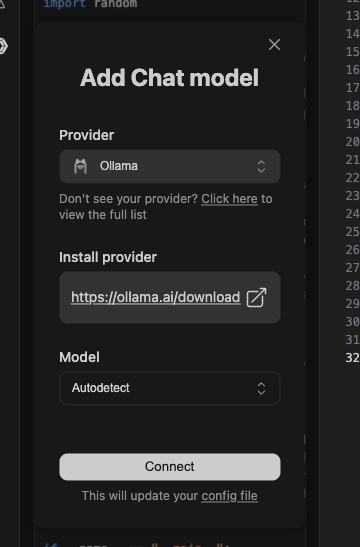
すると多分config.yamlファイルが開くと思います。これが設定ファイルなのでここに呼び出したいモデルの詳細設定を書けばいいわけです。赤丸の部分はさきほどてきとうにConnectしたものなのでここを変更しましょう。
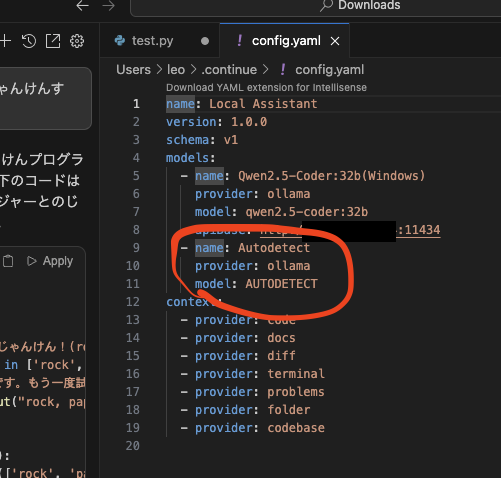
models:の中身をこんなかんじに書けばOK。
name: Local Assistant
version: 1.0.0
schema: v1
models:
- name: Qwen2.5-Coder:32b(Windows)
provider: ollama
model: qwen2.5-coder:32b
apiBase: http://<LLM稼働させているPCのIPアドレス>:11434
context:
- provider: code
- provider: docs
- provider: diff
- provider: terminal
- provider: problems
- provider: folder
- provider: codebase
保存したら変更を認識した旨の通知がきます。

こうなれば、さきほどWindowsでやったように別PCでもバイブコーディングできるようになります。
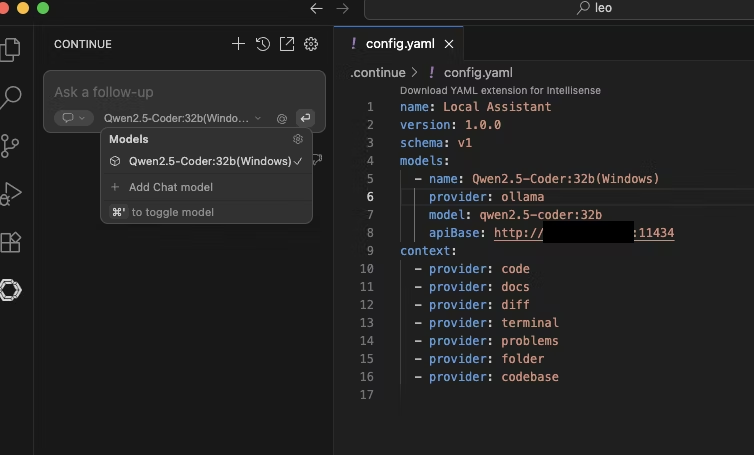
【おまけ】Continue経由だとGPUをフル活用してくれない問題
VScodeのContinue経由で生成を開始したとき、GPUの使用率が20%程度止まりになって100%にならない問題がありました。このせいで生成速度がかなり遅くなってしまい、作業に支障が出てしまいます。
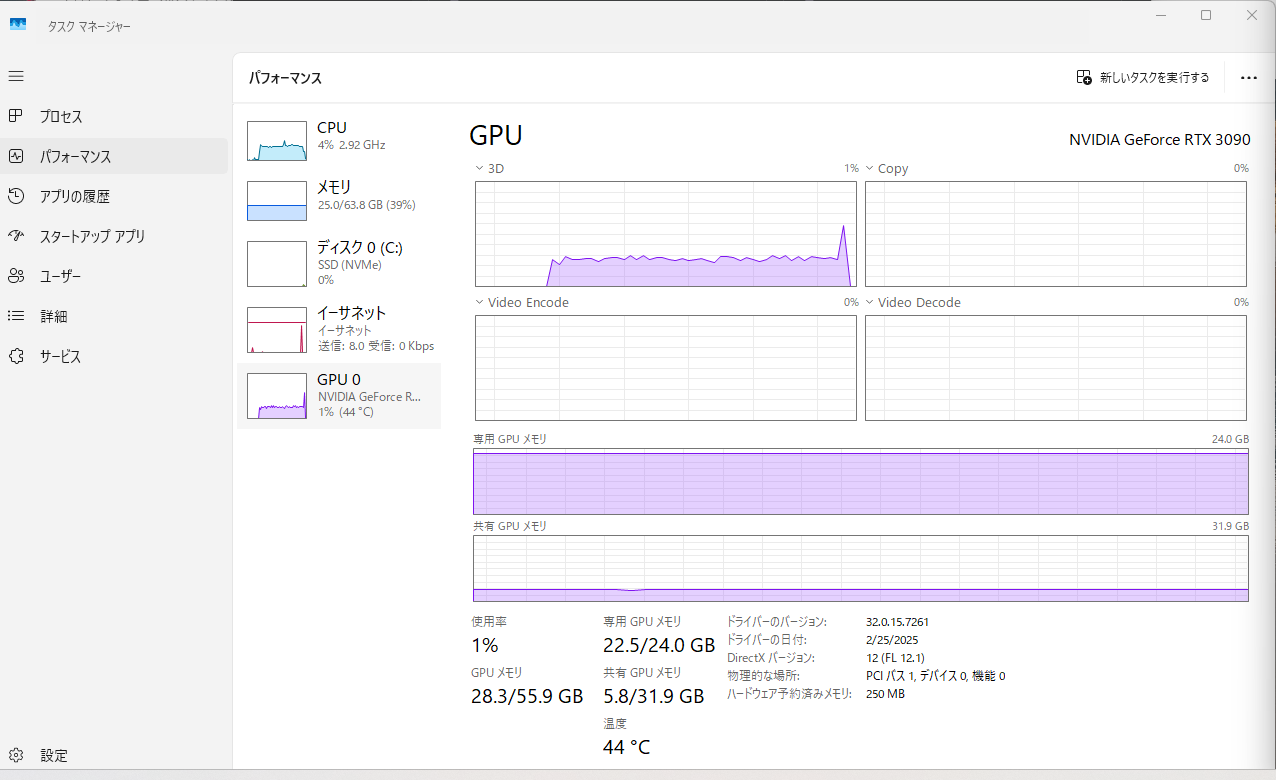
現状としては以下です。
- VRAMはちゃんとフルで確保している
- でも使用率は20%止まり
- なぜかCPUの使用率が上がる
おかしいのは、コマンドラインで直接OllamaでQwen2.5-Coderを動かしたときは問題なくGPUを100%フルで使ってくれていたし、CPUはまったく使っていなかったんですよね。
ネットで検索してもそれっぽい解決策はなく、ChatGPTは以下の理由でそうなると言ってます。
- ターミナル経由だとプロンプト全文を一括で送信してるからGPUはまとめて対処できる
- Continue経由だと、Continueが独自加工するから入力が分割されてストリーミングされるためGPUがまとめて対処できない
- VScodeに同期して表示する処理もあるからCPU処理が発生する
→ストリーミングオプションをfalseにするといいですよ
と言われたからこんなかんじでやってみたけど、速度は変わらず、全部生成し終わってから結果を出力するようになったから気持ち的にはより遅く感じる。
models:
- name: Qwen2.5-Coder:32b(Windows)
provider: ollama
model: qwen2.5-coder:32b
apiBase: http://<ホストPCのアドレス>:11434
defaultCompletionOptions:
stream: false
こちらでも議論されていて、特に解決策はないみたい。
う~ん、動きはするからとりあえずこれで運用するしかないのかなぁ。