はじめに
前回の内容:離散型確率分布の最尤推定と当てはめ
今回は連続型確率分布の最尤推定と当てはめです。
連続型確率分布:正規分布
正規分布を表す確率関数は以下の通りです。
$$P(y)=\frac{1}{\sqrt{2πσ^2}}e^{(-\frac{(y_i-\mu)^2}{2\sigma^2})} (\mu,\sigma =パラメータ)$$
推定と分布の当てはめをするテストデータは答え合わせができるよう、あらかじめ対象の確率分布から作成しておきます。
Python
"""正規分布からの乱数"""
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(seed=10)
norm_values = np.random.normal(0, 1, size=1000) # 平均0,標準偏差1の正規分布から1000個抽出
# 描画
plt.hist(norm_values, bins=50, range=[-5, 5], normed=True)
bin_edges
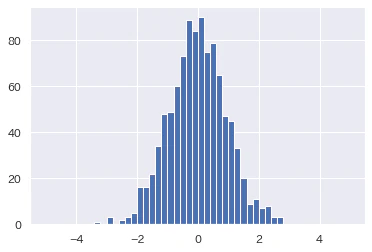
連続変数なので離散型のようにカウントできません。そのため0.2ずつに区切ってカウントしています。
さて、このようなデータに対し、正規分布を当てはめそのパラメータを最尤推定してみます。
Python
""" 対数尤度関数を偏微分してパラメータ推定 """
import sympy
# 変数を定義(v=σ**2としておく)
sympy.var('μ v y')
# 尤度p(パラメータ|x)を定義
fe=(1/sympy.sqrt(2*sympy.pi*v))*sympy.exp(-(y-μ)**2/(2*v))
# 対数化
logf=sympy.log(fe)
# fを偏微分して、式を展開
pdff1 = sympy.expand(sympy.diff(logf, μ)) #μについて偏微分
pdff2 = sympy.expand(sympy.diff(logf, v)) #vについて偏微分
対数尤度をμについて偏微分した式pdff1が$ \frac{y}{v}-\frac{\mu}{v}$ 、vについて偏微分した式pdff2が$\frac{-1}{2v}+\frac{y^2}{2v^2}-\frac{y\mu}{v^2}+\frac{\mu^2}{2v^2}$ですね。$\sum pdff1=\sum pdff2=0$になるμ,vを求めてやればよいので
Python
def L_sympy(fmu,fs,var,values):
likelihood_mu = 0 #尤度の初期値
likelihood_s = 0 #尤度の初期値
for i in np.arange(len(values)):
# likelihood
likelihood_mu += fmu.subs(var,values[i]) #xに値を代入
likelihood_s += fs.subs(var,values[i]) #xに値を代入
param = sympy.solve([likelihood_mu,likelihood_s]) #方程式を解く
return param
parameters = L_sympy(pdff1,pdff2,"y",norm_values)
parameters[0]["σ"]=sympy.sqrt(parameters[0][v])
parameters
[{v: 0.879764754284410, μ: -0.0145566356154705, 'σ': 0.937957757196138}]
大体平均μ=0、σ=1の設定どおりになってますね。
パラメータ推定が複雑なケース
詳細は前回の①。非線形方程式を解く方法を使います。
Python
"""確率密度関数"""
def probability_function(y,param):
from scipy.special import factorial
# param[0]s,param[1]mu: パラメータ
# y: データy
# return: データyの確率密度P(y|パラメータ)
return (1/np.sqrt(2*np.pi*param[1]**2))*np.exp(-0.5*(y-param[0])**2/param[1]**2)
"""対数尤度関数(連続)"""
def L_func_c(param,y):
likelihood = 0 #尤度の初期値
for i in np.arange(len(y)):
# model output
p = probability_function(y[i], param)
# likelihood 尤度
likelihood += -np.log(p) #尤度
return likelihood
"""パラメータ推定"""
"""
準Newton法(BFGS,L-BFGS法:複雑な場合にメモリの節約などが可能)
"""
from scipy import optimize
x0 = [0,0.1] #パラメータの初期値
bound = [(-100, 100),(0, None)]#,(0,None)] #最適パラメータ検索の範囲(min,max)
params_MLE = optimize.minimize(L_func_c,x0,args=(norm_values),method='l-bfgs-b',
jac=None, bounds=bound, tol=None, callback=None,
options={'disp': None, 'maxls': 20, 'iprint': -1,
'gtol': 1e-05, 'eps': 1e-08, 'maxiter': 15000,
'ftol': 2.220446049250313e-09, 'maxcor': 10,
'maxfun': 15000})
# 最尤推定パラメータ
print('パラメータμ,σ:',params_MLE.x)
# パラメータ数
k=3
# AIC(一番小さい値がはてまりの良い確率分布)
print('AIC:',params_MLE.fun*(2)+2*k)
パラメータμ,σ: [-0.01455655 0.93795781]
AIC: 2715.7763344850605
手っ取り早くパラメータを知りたい・・・
詳細は前回の①。非線形方程式を解く方法を使います。
Python
"""scipy.stats.fitでパラメータ推定するのもあり"""
from scipy.stats import norm
fit_parameter = norm.fit(norm_values)
fit_parameter
# パラメータμ,σ
(-0.014556635615470447, 0.9379577571961389)
データに当てはめて図示してみる
推定したパラメータμ=-0.01455655, σ=0.93795781として、確率分布(正規分布)をデータに当てはめてみます。
Python
acc_mle = probability_function(np.sort(norm_values), params_MLE.x)
plt.hist(norm_values, bins=50, range=[-5, 5], normed=True)
plt.plot(np.sort(norm_values), acc_mle)
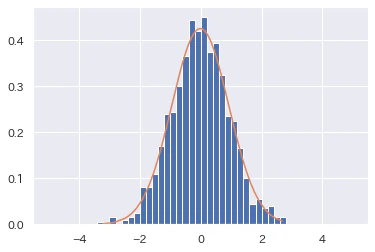
良い感じですね。