要約
- この記事では、OKIのAIエッジコンピューター「AE2100」向けのプログラムの実装を説明します。
- 非同期処理を実装することで、前回の記事の実装(同期処理)よりも高いスループット(フレームレート)を引き出します。
はじめに
前回の記事では、物体検出プログラムの基礎的な実装について説明しました。
本記事では、非同期処理によって推論処理のスループットを改善するプログラムの実装について説明します。
なお本記事でのプログラム実装に取り組むにあたり、前回の記事に倣ってファイルの準備が済んでいることを前提としています。
同期処理・非同期処理
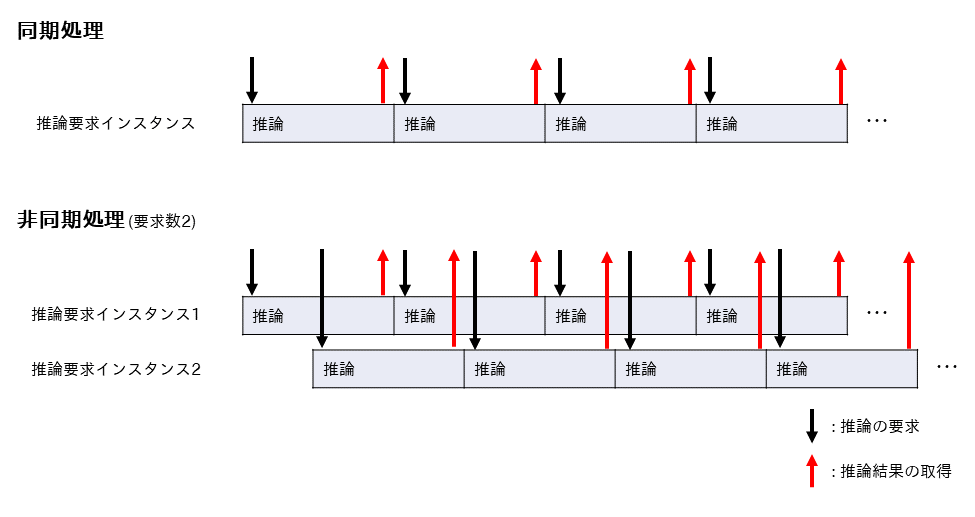
前回の記事で実装したプログラムでは、1つ前の推論が終了してから次の推論を開始しました。
このような処理方法を同期処理といいます。
これに対して1つ前の推論が終了するのを待たずに次の推論を開始し、多重に推論を実行するような処理方法を非同期処理といいます。
ここでは非同期処理で複数の推論を同時に実行することを考えます。
モデルに対して同時に要求できる推論の数を要求数と呼ぶことにします。
下図は同期処理と要求数を2とした場合の非同期処理を表しています。
AE2100に搭載されているMyriad Xは、非同期処理を行うことでスループットが向上します。
以下では、前回の記事で作成したプログラムを書き換えて非同期処理を実装し、スループットの向上を確認します。
なお学習済みモデル、動画ファイル、ラベルファイルは前回の記事のものを流用します。
非同期処理を利用した物体検出プログラム
非同期処理によって物体検出を行うプログラムを実装します。
下記をクリックしてPythonソースコードを開き、ディレクトリpractice直下にobject_detection_async.pyという名前のファイルを作成して書き込んでください。
ここをクリックしてソースコードを表示
import cv2
from openvino.inference_engine import IECore
import time
# ラベルファイルの読込
label = open('./labels.txt').readlines()
# IEコアオブジェクトを生成
ie = IECore()
# IRモデルファイルの読込
model_name = './ssd_mobilenet_v2_coco'
net = ie.read_network(model=model_name+'.xml', weights=model_name+'.bin')
# IEコアオブジェクトに読み込んだモデルを設定
exec_net = ie.load_network(network=net, device_name='HDDL', num_requests=2)
# 入力blob・出力blobの名前を取得
input_blob_name = list(net.inputs.keys())[0]
output_blob_name = list(net.outputs.keys())[0]
# 入力blobの形状を取得
batch, channel, height, width = net.inputs[input_blob_name].shape
def preprocess_input(img):
# 入力画像を入力blobの形状に変換
_img = cv2.resize(img, (width, height))
_img = _img.transpose((2, 0, 1))
_img = _img.reshape((1, channel, height, width))
return _img
def show_result(result, img):
# 推論結果を取り出す
_result = result[output_blob_name][0][0]
# 検出した物体ごとに結果を取り出す
for obj in _result:
index, label_id, score, x_min, y_min, x_max, y_max = obj
# scoreが一定の値を超えたら検出結果を描画
if score > 0.6:
# フレームの高さ・幅を取得
img_h, img_w, _ = img.shape
# 正規化された座標からフレーム上の座標を計算
x_min = int(x_min * img_w)
y_min = int(y_min * img_h)
x_max = int(x_max * img_w)
y_max = int(y_max * img_h)
# 検出枠の描画
cv2.rectangle(img, (x_min, y_min), (x_max, y_max),
(0, 255, 255), thickness=4)
# ラベルの描画
cv2.putText(img, label[int(label_id)][:-1], (x_min, y_min),
cv2.FONT_HERSHEY_PLAIN, fontScale=4,
color=(0, 255, 255), thickness=4)
# 画面に表示
cv2.imshow('Object Detection', img)
cv2.waitKey(1)
# インスタンス毎に推論状況・入力画像を管理
input_idx = 0
output_idx = 1
max_infer = len(exec_net.requests)
images = [None for i in range(max_infer)]
# フレーム番号
frame_index = 0
# 動画を開く
video = cv2.VideoCapture('./face-demographics-walking.mp4')
if not video.isOpened():
exit()
# 1枚目のフレーム読込
ret, img = video.read()
# 開始時間の取得
start = time.perf_counter()
# 推論ループ
while True:
# 推論を要求 --- (1)
if ret:
req = exec_net.requests[input_idx]
# フレームごとに前処理
in_img = preprocess_input(img)
# 推論要求(非同期)
res = req.async_infer(inputs={input_blob_name: in_img})
# フレームを入力済みとする
images[input_idx] = img
# 次のフレームを読み込む
ret, img = video.read()
# 推論結果を取得 --- (2)
if images[output_idx] is not None:
req = exec_net.requests[output_idx]
# 推論終了を待機
status = req.wait(-1)
# 推論結果の取得
result = req.outputs
out_img = images[output_idx]
# 表示の間引き処理
if frame_index % 4 == 0:
# 画面表示
show_result(result, out_img)
frame_index += 1
# 入力済みフレームを解放
images[output_idx] = None
# インスタンス番号の更新 --- (3)
input_idx += 1
if input_idx >= max_infer:
input_idx = 0
output_idx += 1
if output_idx >= max_infer:
output_idx = 0
# 推論ループの終了を判定 --- (4)
# インスタンスがすべて空であればループを終了
if all(i is None for i in images):
break
elapsed_time = time.perf_counter() - start
video.release()
# 処理時間・フレームレートの表示
print('Async')
print(' Num\t: %d' % max_infer)
print(' Frames\t: %d' % frame_index)
print(' Elapse\t: %f [s]' % elapsed_time)
print(' Speed\t: %f [fps]' % (frame_index/elapsed_time))
以下ではソースコードについて解説します。
前回の記事からの主な変更を説明します。
まずIEコアオブジェクトへモデルを設定する際、推論の要求数num_requestsを指定します。
これにより要求数分の推論要求インスタンスが用意されます。
下記コードでは要求数2を指定しています。
exec_net = ie.load_network(network=net, device_name='HDDL', num_requests=2)
推論結果の表示は、動画の先頭フレームから順番に行います。
そのため推論要求先のインスタンスと推論結果取得先のインスタンスを番号で管理し、推論の順番を保持します。
ここでは推論要求先のインスタンス番号をinput_idx、推論結果取得先のインスタンス番号をoutput_idxとします。
input_idxは初期値を0、output_idxは初期値を1とし、どちらも最大値を要求数-1として循環させ、推論の要求と推論結果の取得を行います。
また、推論要求時にモデルへ入力したフレームの元画像を、リストimages[]で保持します。
images[i]にフレームの元画像が格納されていればi番目のインスタンスは推論を要求済みであること、Noneが格納されていればi番目のインスタンスは空き状態であることを表します。
input_idx = 0
output_idx = 1
max_infer = len(exec_net.requests)
images = [None for i in range(max_infer)]
非同期処理の推論ループを記述します。
推論ループ内の処理は、大きく分けて(1)推論を要求する処理部分、(2)推論結果を取得する処理部分、(3)インスタンス番号を更新する処理部分、(4)推論ループの終了を判定する処理部分の4つがあります。
(1)では動画からフレームが読み込めているかどうかをretで判断し、推論要求を行います。
推論要求後は次のフレームを動画から読み込みます。
読み込むフレームがなくなったらretにはFalseが格納されるため、以後推論ループ内で推論要求を行ないません。
(2)ではoutput_idx番目のインスタンスへ推論要求済みであれば推論結果を取得します。
(3)ではinput_idxとoutput_idxの値が0から要求数-1で循環するようにインスタンス番号を更新します。
(4)では推論要求インスタンスがすべて空となった状態を推論ループの終了条件とし、ループを抜けます。
# 推論ループ
while True:
# 推論を要求 --- (1)
if ret:
req = exec_net.requests[input_idx]
# フレームごとに前処理
in_img = preprocess_input(img)
# 推論要求(非同期)
res = req.async_infer(inputs={input_blob_name: in_img})
# フレームを入力済みとする
images[input_idx] = img
# 次のフレームを読み込む
ret, img = video.read()
# 推論結果を取得 --- (2)
if images[output_idx] is not None:
req = exec_net.requests[output_idx]
# 推論終了を待機
status = req.wait(-1)
# 推論結果の取得
result = req.outputs
out_img = images[output_idx]
# 表示の間引き処理
if frame_index % 4 == 0:
# 画面表示
show_result(result, out_img)
frame_index += 1
# 入力済みフレームを解放
images[output_idx] = None
# インスタンス番号の更新 --- (3)
input_idx += 1
if input_idx >= max_infer:
input_idx = 0
output_idx += 1
if output_idx >= max_infer:
output_idx = 0
# 推論ループの終了を判定 --- (4)
# インスタンスがすべて空であればループを終了
if all(i is None for i in images):
break
object_detection_async.pyへ書き込むソースコードの説明は以上となります。
AE2100での実行
上記の手順で用意した物体検出プログラムを、AE2100上で実行します。
実行環境のディレクトリpracticeの中身が下記の通りとなっていることを確認してください。
# cd
# ls practice
face-demographics-walking.mp4 object_detection.py ssd_mobilenet_v2_coco.bin ssd_mobilenet_v2_coco.xml
labels.txt object_detection_async.py ssd_mobilenet_v2_coco.mapping
環境変数の設定、検出結果の画面表示先の指定を行います。
# source /opt/intel/openvino/bin/setupvars.sh
# export DISPLAY=192.168.100.101:0.0
今回実装した非同期処理のプログラムを、下記のコマンドで実行します。
# python3 object_detection_async.py
検出結果が開発環境の画面に表示されます。
推論結果は前回の記事のプログラムと同様ですが、画面の更新が前回の記事のプログラムよりも速くなりました。
同期処理と非同期処理の比較
前回の記事で実装した同期処理のプログラムobject_detection.pyと、上記の非同期実行のプログラムobject_detection_async.pyをAE2100上で動作させ、スループットを比較します。
非同期処理については要求数を増やして比較します。
要求数を変更するには、IEコアオブジェクトへモデルを設定するie.load_network(...)の引数であるnum_requestsの値を書き換えてください。
下図に計測したスループットを示します。
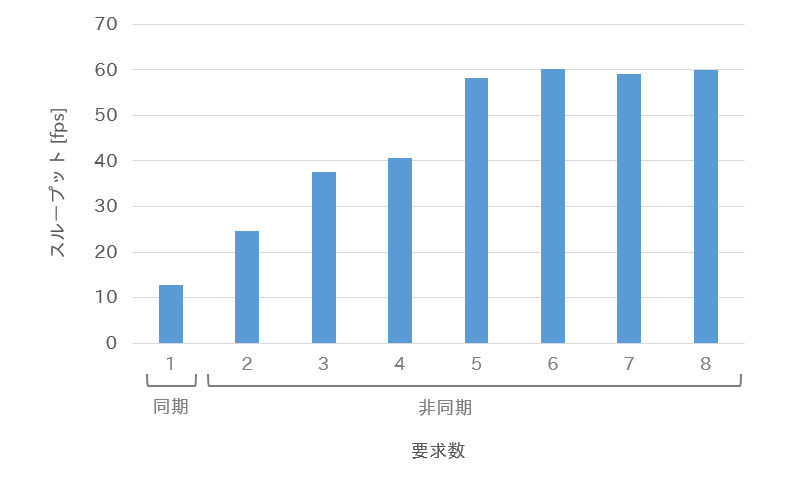
非同期処理の要求数を6まで増やすと、スループットは約60fpsになりました。
同期処理のスループットは約13fpsですから、非同期処理の実装によって5倍までスループットが向上したといえます。
まとめ
今回はAE2100上で物体検出を行うプログラムに非同期処理を実装しました。
非同期処理を実装することにより、プログラムのスループットが向上しました。
AE2100で推論処理をする際には、非同期処理の実装をおすすめします。