初めに
- 大学の課題で勉強する必要があったので備忘録
- PytorchでCNN(畳み込みニューラルネットワーク)を構築してMNISTを学習させました
<対象>
- 機械学習初心者(細かい内容についての解説はしません)
- PyTorch触り始めた方
- アバウトな解説でも耐えられる方
<非対象> - Pytorch詳しい方
- 精度向上したい方
[環境]
Google Colaboratory
(Python 3.6.9)
(torch 1.5.1)
(torchvision 0.6.1)
解説
import
import torch
import torch.nn as nn
import torch.nn.functional as f
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
<インストール方法>
torch -> PyTorchのこと。
https://pytorch.org/
に飛んでOS,パッケージなど適切なものを選択して出てきたコマンドを打つだけ。
matplotlibは皆さん使ってると思うんで割愛。
ネットワーク構造
class MyNet(nn.Module):
def __init__(self):
super(MyNet,self).__init__()
self.conv1 = nn.Conv2d(1,32,3,1)
self.conv2 = nn.Conv2d(32,64,3,1)
self.pool = nn.MaxPool2d(2,2)
self.dropout1 = nn.Dropout2d(0.25)
self.dropout2 = nn.Dropout2d(0.5)
self.fc1 = nn.Linear(12*12*64,128)
self.fc2 = nn.Linear(128,10)
def forward(self,x):
x = self.conv1(x)
x = f.relu(x)
x = self.conv2(x)
x = f.relu(x)
x = self.pool(x)
x = self.dropout1(x)
x = x.view(-1,12*12*64)
x = self.fc1(x)
x = f.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
return f.log_softmax(x, dim=1)
入力は28×28のグレースケール画像とした。
各層に名前を付けることによりそれぞれの段階での出力を得やすいため,自分でネットワーク構造を考えるときの途中経過の抽出がしやすいらしい。
今回のネットワーク構造,途中の出力サイズは以下のように確認できる。
(torchsummaryっていうライブラリを使います)
from torchsummary import summary
model = MyNet()
print(model)
print(summary(model, (1, 28, 28)))
結果
MyNet(
(conv1): Conv2d(1, 32, kernel_size=(3, 3), stride=(1, 1))
(conv2): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1))
(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(dropout1): Dropout2d(p=0.25, inplace=False)
(dropout2): Dropout2d(p=0.5, inplace=False)
(fc1): Linear(in_features=9216, out_features=128, bias=True)
(fc2): Linear(in_features=128, out_features=10, bias=True)
)
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 32, 26, 26] 320
Conv2d-2 [-1, 64, 24, 24] 18,496
MaxPool2d-3 [-1, 64, 12, 12] 0
Dropout2d-4 [-1, 64, 12, 12] 0
Linear-5 [-1, 128] 1,179,776
Dropout2d-6 [-1, 128] 0
Linear-7 [-1, 10] 1,290
================================================================
Total params: 1,199,882
Trainable params: 1,199,882
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.59
Params size (MB): 4.58
Estimated Total Size (MB): 5.17
----------------------------------------------------------------
層が多すぎる気はしますがまぁいいでしょう。
Dropout層を入れることによって過学習を防いでいます。
入力は[N×1×28×28],出力は[N,10]となるようにパラメータを調整します。(Nはバッジサイズ)
データのロード
def load_MNIST(batch=128):
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))])
train_set = torchvision.datasets.MNIST(root="./data",
train=True,
download=True,
transform=transform)
train_loader = torch.utils.data.DataLoader(train_set,
batch_size=batch,
shuffle=True,
num_workers=2)
val_set = torchvision.datasets.MNIST(root="./data",
train=False,
download=True,
transform=transform)
val_loader =torch.utils.data.DataLoader(val_set,
batch_size=batch,
shuffle=True,
num_workers=2)
return {"train":train_loader, "validation":val_loader}
PyTorchのtorchvisionというライブラリからMNISTデータセットを読み込めるのでそこから読み込みます。
PyTorchはtorch.tensorというデータ型でデータを扱う。[Batch size,C,H,W]の4次元構造。
自前のテストデータを使うときには自分でtorch.tensor型に変更しないといけない。
今回のプログラムではデータセットを0.1307を平均、0.3081を標準偏差に正規化している。
メイン部分(前半・学習前)
# エポック数,バッジサイズ
epoch = 20
batch_size = 64
# 学習結果の保存
history = {
"train_loss": [],
"validation_loss": [],
"validation_acc": []
}
# データのロード
data_loder = load_MNIST(batch=batch_size)
# GPUが使えるときは使う
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
# ネットワーク構造の構築
net = MyNet().to(device)
print(net)
# 最適化方法の設定
optimizer = torch.optim.Adam(params=net.parameters(), lr=0.001)
学習前の準備段階。
GPUが使用可能な環境なら使用し,使えないなら自動でCPUで演算を行うように設定。
ネットワーク構築の際やデータを学習する際に~.to(device)が必要。
最適化方法はAdamを使用。optim.SGD(model.parameters(), lr=0.01)もよく見かける。
メイン部分(後半・学習部分)
for e in range(epoch):
""" 学習部分 """
loss = None
train_loss = 0.0
net.train() #学習モード
print("\nTrain start")
for i,(data,target) in enumerate(data_loder["train"]):
data,target = data.to(device),target.to(device)
#勾配の初期化
optimizer.zero_grad()
#順伝搬 -> 逆伝搬 -> 最適化
output = net(data)
loss = f.nll_loss(output,target)
train_loss += loss.item()
loss.backward()
optimizer.step()
if i % 100 == 99:
print("Training: {} epoch. {} iteration. Loss:{}".format(e+1,i+1,loss.item()))
train_loss /= len(data_loder["train"])
print("Training loss (ave.): {}".format(train_loss))
history["train_loss"].append(train_loss)
"""検証部分"""
print("\nValidation start")
net.eval() #検証モード(Validation)
val_loss = 0.0
accuracy = 0.0
with torch.no_grad():
for data,target in data_loder["validation"]:
data,target = data.to(device),target.to(device)
#順伝搬の計算
output = net(data)
loss = f.nll_loss(output,target).item()
val_loss += f.nll_loss(output,target,reduction='sum').item()
predict = output.argmax(dim=1,keepdim=True)
accuracy += predict.eq(target.view_as(predict)).sum().item()
val_loss /= len(data_loder["validation"].dataset)
accuracy /= len(data_loder["validation"].dataset)
print("Validation loss: {}, Accuracy: {}\n".format(val_loss,accuracy))
history["validation_loss"].append(val_loss)
history["validation_acc"].append(accuracy)
学習時(train)
学習の開始の合図はnet.train(),絶対必要。
大まかな流れは以下の通り
- 勾配初期化
optimizer.zero_grad() - 順伝搬
output = net(data) - ロス計算
loss = f.nll_loss(output,target) - 逆伝搬
loss.backward() - 最適化
optimizer.step()
その中に途中経過を保存するための変数が挟んである。
検証時(validation)
検証の開始はnet.eval(),絶対必要。
with torch.no_grad()とすることで勾配計算を行わないで進めることができる。(メモリ節約)
- 順伝搬
output = net(data) - ロス計算
loss = f.nll_loss(output,target).item() - 推測
predict = output.argmax(dim=1,keepdim=True)
最後にいろいろ計算してLossとAccuracyを出力する。
モデルの保存
PATH = "./my_mnist_model.pt"
torch.save(net.state_dict(), PATH)
torch.save()の引数をnet.state_dect()にすることによりネットワーク構造や各レイヤの引数を省いて保存する。これにより保存したモデルの容量を削減することができる。
結果
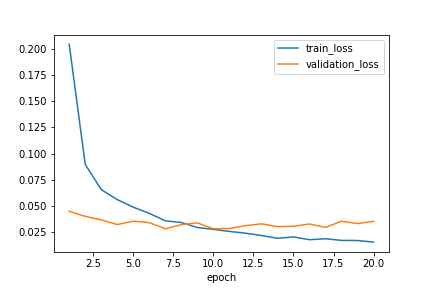

(自分なりの)考察
- Train Lossは良い感じに減少している
- Validation Lossは初めから低い
- (いろいろ調べた結果)問題なさそう
- Dropout層の影響でTrain時とValidation時で挙動が変わるのが原因
- Train時には過学習を防ぐためにニューロンが一部利用されない
- Validation時には全てののニューロンを利用してLossを計算する
- Accuracyもいい感じに上がってる
- 最初から98%なのはいかがなものか...
Source Code
import torch
import torch.nn as nn
import torch.nn.functional as f
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
# ネットワーク構造の定義
class MyNet(nn.Module):
def __init__(self):
super(MyNet,self).__init__()
self.conv1 = nn.Conv2d(1,32,3,1)
self.conv2 = nn.Conv2d(32,64,3,1)
self.pool = nn.MaxPool2d(2,2)
self.dropout1 = nn.Dropout2d(0.25)
self.dropout2 = nn.Dropout2d(0.5)
self.fc1 = nn.Linear(12*12*64,128)
self.fc2 = nn.Linear(128,10)
def forward(self,x):
x = self.conv1(x)
x = f.relu(x)
x = self.conv2(x)
x = f.relu(x)
x = self.pool(x)
x = self.dropout1(x)
x = x.view(-1,12*12*64)
x = self.fc1(x)
x = f.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
return f.log_softmax(x, dim=1)
# MNISTデータセットのロード
def load_MNIST(batch=128):
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))])
train_set = torchvision.datasets.MNIST(root="./data",
train=True,
download=True,
transform=transform)
train_loader = torch.utils.data.DataLoader(train_set,
batch_size=batch,
shuffle=True,
num_workers=2)
val_set = torchvision.datasets.MNIST(root="./data",
train=False,
download=True,
transform=transform)
val_loader =torch.utils.data.DataLoader(val_set,
batch_size=batch,
shuffle=True,
num_workers=2)
return {"train":train_loader, "validation":val_loader}
def main():
#エポック数
epoch = 20
batch_size = 64
#学習結果の保存
history = {
"train_loss": [],
"validation_loss": [],
"validation_acc": []
}
#データのロード
data_loder = load_MNIST(batch=batch_size)
#GPUが使えるときは使う
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
#ネットワーク構造の構築
net = MyNet().to(device)
print(net)
#最適化方法の設定
optimizer = torch.optim.Adam(params=net.parameters(), lr=0.001)
for e in range(epoch):
""" 学習部分 """
loss = None
train_loss = 0.0
net.train() #学習モード
print("\nTrain start")
for i,(data,target) in enumerate(data_loder["train"]):
data,target = data.to(device),target.to(device)
#勾配の初期化
optimizer.zero_grad()
#順伝搬 -> 逆伝搬 -> 最適化
output = net(data)
loss = f.nll_loss(output,target)
train_loss += loss.item()
loss.backward()
optimizer.step()
if i % 100 == 99:
print("Training: {} epoch. {} iteration. Loss: {}".format(e+1,i+1,loss.item()))
train_loss /= len(data_loder["train"])
print("Training loss (ave.): {}".format(train_loss))
history["train_loss"].append(train_loss)
"""検証部分"""
print("\nValidation start")
net.eval() #検証モード(Validation)
val_loss = 0.0
accuracy = 0.0
with torch.no_grad():
for data,target in data_loder["validation"]:
data,target = data.to(device),target.to(device)
#順伝搬の計算
output = net(data)
loss = f.nll_loss(output,target).item()
val_loss += f.nll_loss(output,target,reduction='sum').item()
predict = output.argmax(dim=1,keepdim=True)
accuracy += predict.eq(target.view_as(predict)).sum().item()
val_loss /= len(data_loder["validation"].dataset)
accuracy /= len(data_loder["validation"].dataset)
print("Validation loss: {}, Accuracy: {}\n".format(val_loss,accuracy))
history["validation_loss"].append(val_loss)
history["validation_acc"].append(accuracy)
PATH = "./my_mnist_model.pt"
torch.save(net.state_dict(), PATH)
#結果
print(history)
plt.figure()
plt.plot(range(1, epoch+1), history["train_loss"], label="train_loss")
plt.plot(range(1, epoch+1), history["validation_loss"], label="validation_loss")
plt.xlabel("epoch")
plt.legend()
plt.savefig("loss.png")
plt.figure()
plt.plot(range(1, epoch+1), history["validation_acc"])
plt.title("test accuracy")
plt.xlabel("epoch")
plt.savefig("test_acc.png")
if __name__ == "__main__":
main()