はじめに
GANはDeepLearningの花形分野の一つではあるが、実際に学習させようとすると時間もかかる上に、学習失敗の危険性もあったりして、結構敷居の高い分野であると思う。このGAN学習の難易度を下げるブレイクスルーになりそうな手法としてProjectedGANが発表されているので、簡単な紹介と実装して学習させてみた結果を示す。
ProjectedGANとは
論文はこちら。
手法を簡単にまとめると以下の通り。
- 真偽判定のための画像は直接Discriminatorへの入力せず、ImageNetの画像で学習済みのCNNへ入力し、途中の特徴量を射影した値を使って判定する
- 特徴量から射影された値を使うのでProjectedと冠される
- Discriminator側だけの工夫なのでGeneratorの実装は何でもいい
- 論文内ではStyleGAN2とFastGANのGeneratorで実験している
- 既存のGANで5日かかった品質に3時間で到達した、と主張されている
論文内で学習の速さを示す以下の図が示されている。

高速で収束に向かい、FIDも小さくなって品質も向上しているという。
以下、内部構造について紹介する。
学習済みネットワークの選択
上述の通り既存のCNNを利用するのだが、論文内ではEfficientNet-lite1を使用している。
EfficientNet-liteは通常のEfficientNetより簡略化されたもの。

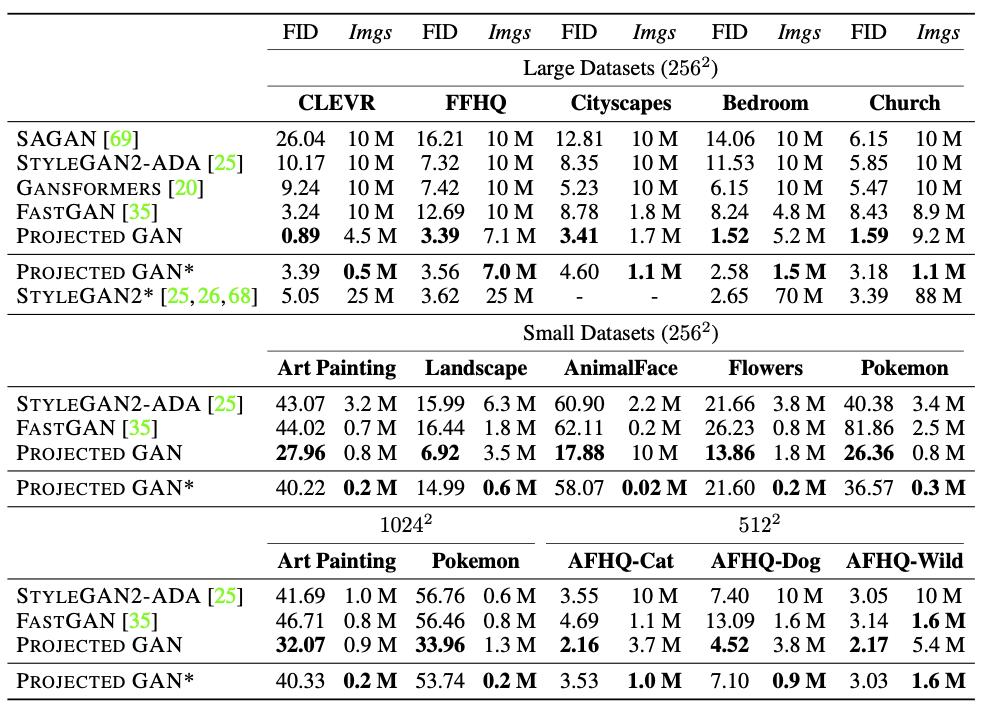
論文内に示された上の表からはlite1を使用する根拠が見て取れる。CNNの画像分類性能とGANに組み込んだ際のFIDの間には、明確な関連性が見られない。DeitとViTで大きな差があることは興味深く、コンパクトなネットワークの方がGANへの組み込みに適していることが示唆されているとも解釈できそうだ。
Multi-Scale Discriminators
CNNの特徴量は解像度の異なる4層から取り出される。
論文では$L_1=64^2$, $L_2=32^2$, $L_3=16^2$, $L_4 = 8^2$と各特徴量の解像度が示されており、CNNへの入力画像の解像度は$256^2$にしていると推測される。ただし、公式実装ではlite0を使い、入力が$224^2$で特徴量は$L_1=56^2$, $L_2=28^2$, $L_3=14^2$, $L_4=7^2$ になっているはずで、ここは齟齬があるように思われる。
各4層の特徴量は、それぞれ独立した単純なDiscriminatorに入力されて$4^2$のサイズまで縮小した出力となり、最終的に4つ分結合して64個の値で出力とする。
Random Projections
CNNの特徴量はそのまま使うのではなく、射影をしてからCNNに入力する。つまり前処理的なものが必要になるのだが、その際にRandom Projectionが使われる。Random Projectionは乱数で初期化された行列で射影することを指し、乱数で重みを初期化するのは普通のDeepLearningでも同様なのだが、それを学習で更新せずにそのまま使い続ける実装となる。
筆者は知らなかったのだが、以前から次元縮小の目的で使用されている手法のようだ。ただし、"a generalization of a permutation"と論文にあるので、ここでは少し違う役割として導入されていると思われる。
単純に1x1のConvolutionを通すことをCross-Channel Mixing(CCM)と呼んでいる。
さらに各スケール間でも特徴量をMixすると性能が上がるということで、こちらはCross-Scale Mixing(CSM)と呼んでいる。
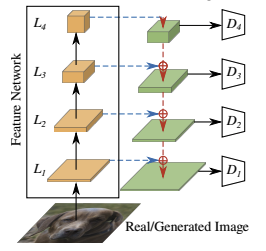
上図の青の波線がCCM、赤の波線がCSMを表しており、共にRandom Projectionで重みが更新されないConvolutionで構成される。
汎用性について
構成上、以下のような疑問が出てくる。
- ImageNetという現実にあるものの画像で学習したCNNを使うので、非現実の画像の生成に使えるのか?
- CNNへの入力サイズする際には$256^2$程度にリサイズしてしまうはずだが、高解像度($512^2$以上)の画像生成に使えるのか?
実験結果によれば、ArtPaintingやPokemonといった非現実な画像も生成できるし、高解像度でもFIDで上回っているという。
論文内では、非現実の画像でも有効なのでImageNetの学習だけで汎用的な学習ができているためと解釈しているが、より高解像度でも有効なことに関する理由については特に言及はないようだ。
課題
論文によれば、背景に浮き上がって顔だけが出てきたり、FIDは良くてもおかしなArtifactが出てきたりする現象が見られるようで、この辺が課題とされている。

実装
公式ではPyTorchの実装。
筆者はGoogleColabのTPUを使いたいので、TensorFlow/Kerasで実装した。TensorFlowのバージョンは2.8.0。
Projector
Projector部分のみ貼り付けておく。
論文ではEfficientNet-liteなのだが、この実装ではImageNet学習済みのEfficientNetB0を作成して使用する。
画像は$224^2$にリサイズしてからCNNに入力し、4つのレイヤーから出力を取り出す。
そこから上述のCCMやCSMといった手法がRandom Projectionを構成する。つまりパラメータは更新しない。
def cnn(input_shape,name=None):
efnet = tf.keras.applications.efficientnet.EfficientNetB0(
include_top=False, weights='imagenet', input_tensor=None,
input_shape=(224,224,3), pooling=None)
efnet.trainable = False
selected_layers = ['block2b_add','block3b_add','block5c_add','block7a_project_bn']
outputs = [efnet.get_layer(l).output for l in selected_layers]
net = tf.keras.Model(efnet.input, outputs, name='EfNet')
x = input = layers.Input(input_shape)
x = (x+1.0)*127.5
if input_shape != (224,224,3):
x = layers.Resizing(224,224, name='Resizing')(x)
cnn = tf.keras.Model(input, net(x), name=name)
return cnn
def make_projector( input_shape, name=None ):
inputs = layers.Input(input_shape, name='Input')
x0, x1, x2, x3 = cnn(input_shape,name='CNN')(inputs)
# CCM
x0 = layers.Conv2D(64 , 1, name='CCM_L1_Conv')(x0)
x1 = layers.Conv2D(64*2, 1, name='CCM_L2_Conv')(x1)
x2 = layers.Conv2D(64*4, 1, name='CCM_L3_Conv')(x2)
x3 = layers.Conv2D(64*8, 1, name='CCM_L4_Conv')(x3)
# CSM
x3 = layers.Resizing(x2.shape[1], x2.shape[2], name='CSM_L4_Resize')(x3)
x3 = layers.Conv2D(x2.shape[3], 1, name='CSM_L4_Conv')(x3)
x2 = layers.Add()([x3,x2])
x2 = layers.Resizing(x1.shape[1], x1.shape[2], name='CSM_L3_Resize')(x2)
x2 = layers.Conv2D(x1.shape[3], 1, name='CSM_L3_Conv')(x2)
x1 = layers.Add()([x2,x1])
x1 = layers.Resizing(x0.shape[1], x0.shape[2], name='CSM_L2_Resize')(x1)
x1 = layers.Conv2D(x0.shape[3], 1, name='CSM_L2_Conv')(x1)
x0 = layers.Add()([x1,x0])
x0 = layers.Resizing(x0.shape[1]*2, x0.shape[2]*2, name='CSM_L1_Resize')(x0)
x0 = layers.Conv2D(x0.shape[3], 1, name='CSM_L1_Conv')(x0)
model = tf.keras.Model( inputs, [x0, x1, x2, x3], name=name )
model.trainable = False # Freeze
return model
論文との今回の実装の違い
GeneratorはFastGANの構造だが、ProjectedGANの公式実装で採用されているliteな実装になっている。
FastGANについては以下の記事を参考にした。
また、論文ではExponential Moving Averageを使っているが、こちらの実装は使用していない。
学習結果
以下、学習させてみた結果を示す。
本来は従来のDiscriminatorでの学習結果と比較したいところなのだが、従来型ではうまく学習できなかったので比較はしない。従来のGANでは$64^2$から$128^2$サイズの間で難易度が一気に上がる、というのが筆者の経験からの印象なのだが、ProjectedGANは学習は非常に安定しているように感じられた。(もちろん失敗する場合もあるが)
時間的に速いかどうかは、上述の通りうまく比較できなかったので判断はしないことにする。
論文ではDifferentiable Augmentationを使用しているが、AugmentationにはADA(Adaptive Discriminator Augmentation)を使用している。以前筆者は記事にしているが、その記事の実装よりも簡略化して高速化したりしているのでかなり違いがあり、よくあるDifferentiable Augmentationに近い実装に変わっている。平行移動と左右反転は常に実行されるが、それ以外の色変更やカットアウトはAdaptiveにして確率を制御するようにしてある点で違いがある。Adaptiveの制御はFakeとRealのロスの値が同じ値になるように誘導している。
関連記事:
キルミーベイベー
前記した記事でも使用したキルミーベイベーデータセットを使って$128^2$の画像を生成した。元のデータセットのままでは流石に難しすぎると判断して、顔がしっかり写っているものだけ選別し約300枚の画像で学習させた。
以下、1エポックを2500ステップとし、30エポック学習させた際のグラフ。(破線はFID)
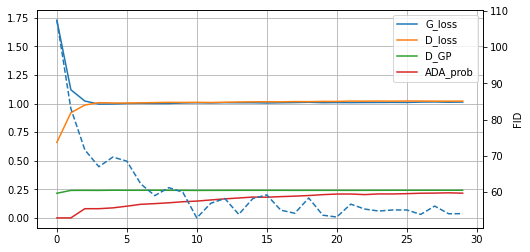
FID的には大体収束してこれ以上向上の余地がないように見える。
GeneratorとDiscriminatorのLoss値がフラットになって学習が進んでいる。これはADAの制御で誘導している側面もあるし、パラメータ選択によってはこのようにならないこともある。偶然かもしれないが、筆者は従来型のGANでここまで安定したものは経験がないので、ProjectedGANの特性に関係あるのかもしれない。
以下は30エポック学習後の生成画像をアニメーションにしたもの。

頭部以外の部分はだいぶ怪しいが、かなりの高品質だと思う。
Exponential Moving Averageは使用していないので、採用すれば品質はもう少し向上する可能性がある。
一般的にGANでは背景部分が怪しくなる傾向があるようだが、ProjectedGANではより抽象化された背景になっているように感じる。
実は前回のGANの記事では$64^2$で妥協しており、その時は$128^2$では満足するものができなくて断念していた。ProjectedGANを知って再開したのがこの記事になっているのだが、このレベルの画像生成が実際に自分でできるとは思っていなかったので、筆者的には驚きの結果となった。
美少女イラスト
FastGANのgithubからたどれるリンクで提供されているデータセットを使って、美少女イラスト画像の生成もしてみた。
このデータセットはGANで生成された画像で、100枚程度。元は$512^2$だがここでは$256^2$で生成させている。
以下、1エポックを5000ステップとし、30エポック学習させた際のグラフ。
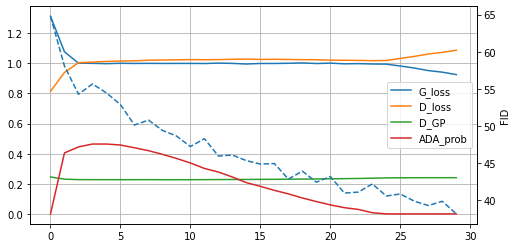
ADAで調整できている間はGeneratorとDiscriminatorはフラットになっているが、ADAの確率が0になるあたりでGeneratorが強くなってきている。FID値はエポック数を伸ばせばもう少し向上できそう。
以下は30エポック学習後の生成画像をアニメーションにしたもの。

猫
上と同じデータセット内にある猫の顔画像100枚から$256^2$の画像生成。こちらはアニメーションのみ添付。

まとめ
ProjectedGANの論文を紹介し、Tensorflowでの実装例を示した。
実験結果はかなり良好で、安定して高画質の画像が学習&生成できた。今後定番の手法になる可能性もあるように思う。
筆者同様にGANの難しさに挫折していた方は、試してみる価値はあるのではないか。