はじめに
GANが登場して数年経ち、生成画像の高画質化や応用範囲の広がりも著しいが、課題として大量の教師データが必要な点がある。この課題への対応としてのデータ拡張の手法が提案されているので、その効果確認をキルミーベイベーのデータセットを使って行った。
ADA (Adaptive Discriminator Augmentation)について
NVIDIAによって開発された、GANでのデータ拡張の手法。以下のページに概要や元論文へのリンクがある。
教師データが数千程度でも高画質の画像が生成できるとしている。以下引用。
高品質な GAN をトレーニングするには、通常は 5 万枚から 10 万枚のトレーニング用の画像が必要となります。しかし、多くの場合、研究者が数万枚または数十万枚のサンプル画像を自由に使えることはほとんどありえません。
トレーニング用の画像がわずか 2,000 枚程度の場合、多くの GANは実用的な成果を上げることができません。オーバーフィッティングと呼ばれるこの問題は、識別ネットワークがトレーニング用の画像を記憶するだけになり、生成ネットワークに有益なフィードバックを提供できないときに起こります。
画像識別のタスクでは、研究者はデータ拡張という手法を使ってオーバーフィッティングを回避しています。この手法は、回転、トリミングあるいは反転といった処理でランダムに改変した既存の画像のコピーを使って、小規模なデータセットを拡張し、モデルをより一般化させます。
しかし、GAN のトレーニング画像にデータ拡張を適用してきたこれまでの試みでは、生成ネットワークが真実味のある合成画像を作らずに、これらの改変を模倣するように学んでいました。
最後の一行についてだけ補足すると、GANでもデータ拡張した画像を単純に"現実の画像"であるかのように入力してしまうと、"データ拡張した後の画像”を模倣した画像を生成してしまう。つまり、回転した画像で学習すると水平がおかしくなったり、反転した画像で学習するとおかしな文字を生成したり、等々の問題が起きるということだろう。
NVIDIAの発表によれば、これを解決するような手法を開発したという。元論文から図を引用すると以下のような構造にする。
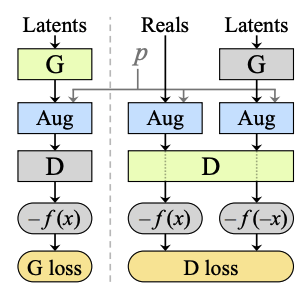
図内でのpはデータ拡張を適用する確率で、とにかくDiscriminatorに入力する前に一定の確率でデータに加工すればよい、ということでかなり単純な構造になっている。
ここで確率の数値が重要らしく、0.8あたりが限界。それ以下にすれば、データ拡張を適用して学習させても生成画像には問題ないという。(以下それを示す図)

ここでpは各データ拡張に個別(例えば色0.8、回転0.8、左右反転0.8など)に適用されるので、複数の手法を用いた場合はほぼ100%に近い形で何らか改変が適用されるが、それでも生成画像に悪影響が出ない、としている。
Adaptiveにする方法
ここまでだとAdaptive(適応的)な要素がないのだが、データセットが大きければ過学習の心配も減るので、pは0.8よりもっと下げて良いし、そのほうが処理時間も減らせる。このpを学習に応じて変化させる処理を入れるとAdapive Discriminator Augmentationとなるようだ。(p=1.0で固定すると、Differentiable Augmentationと同じ動作になると思われる)
Adaptiveにする方法は、「過学習している兆候があればpを増やし、逆なら減らす」ということで、論文には二種類の例が提案されていて、公式コードでもその両方と固定確率が実装されている。
論文の実験では、以下のような手法で更新しているようだ。
- pの初期値は0
- 過学習の判定は、256個のRealデータに対する「Discriminatorの出力の正負の符号のみの平均」を指標として、所定の値(0.6)を超えるかどうかで判定
- ここでは、Realデータの場合は正、Fakeデータの場合は負の値、が出力されるようなDiscriminatorを前提としている
- 更新幅は最短で500k個のデータで0から1に持っていける程度
Kerasの実装例もあるが、こちらはLoss関数が別なので制御方法が異なり、Accuracyを直接利用している。
この部分はGANの設計に依存しているため、決まった方法は無く自由に実装して良いと思われる。
なぜキルミーベイベーなのか
Qiitaは技術系サイトなので、キルミーベイベーという作品については詳しく述べないでおく。
下記の記事におけるキルミーベイベーデータセットを使用させていただいた。
このうち主要登場人物の3人についてデータとして用い、キャラクターごとのConditionalGANの学習データとした。
| やすな | ソーニャ | あぎり |
|---|---|---|
 |
 |
 |
| 341枚 | 175枚 | 44枚 |
全部で540枚の超小規模データセットで、ADAの効果確認には適していると考えられる。
また、キャラクターごと枚数に大きな偏りがあるほか、デフォルメした表現や特殊なアングルも結構あり、GANとしてはかなり難しいタスクのはずで、論文内での実験より厳しい条件になっていると思われる。
以下、特殊な画像例。
 |
 |
 |
 |
 |
 |
実装
論文の実験結果を見る限り、データ数が2000枚以下の場合は確率は0.8固定で問題なさそうなので、以下の実装&実験はAdaptive要素無しとなっている。
環境はGoogle Colab TPU 上で行い、Tensorflow(2.7.0)+Kerasを使用した。
キャラクタごとにラベル(3つ)をつけたConditionalなGANとなっている。
ADA
構造自体は簡単なので、普通は実装もそんなに問題ないのだが、TPU上で動作させようとすると工夫が必要になる。具体的には、Tensorflowに用意されているRandomFlipやRandomRotation等のレイヤーをTPUの学習時に使うとエラーが出るので、それを回避するように自前で実装しなければならなかった。
この処理はこちらに投稿されているコードを大改造した。
今回はLayerとして実装したので、GANのDiscrimintorの入力直後にレイヤーとして挿入すれば使える。
入力データは-1.0から1.0に正規化されていることが前提の処理になっている。
def make_coord(size):
coord1_vec = tf.tile(tf.range(size), [size])
coord2_vec = tf.reshape(coord1_vec, [size, size])
coord2_vec = tf.transpose(coord2_vec, [1, 0])
coord2_vec = tf.reshape(coord2_vec, [-1])
image_center = size/2
coord = tf.transpose(tf.stack([coord2_vec, coord1_vec]), [1, 0])
return tf.cast(coord, tf.float32) - image_center
def image_transform_fn(image, coord, angle_range, zoom_range, skew_range, shift_range, flip_h,flip_v):
angle = tf.random.uniform(shape=[], minval=-angle_range, maxval=angle_range)*3.141519/180
skew_x = tf.random.uniform(shape=[], minval=-skew_range, maxval=skew_range)
skew_y = tf.random.uniform(shape=[], minval=-skew_range, maxval=skew_range)
zoom_x = tf.random.uniform(shape=[], minval=(1.0-zoom_range), maxval=(1.0+zoom_range))
zoom_y = tf.random.uniform(shape=[], minval=(1.0-zoom_range), maxval=(1.0+zoom_range))
mirror_x = tf.cond( flip_h, lambda:tf.sign(tf.random.uniform([],-1,1)), lambda:tf.constant(1.0))
mirror_y = tf.cond( flip_v, lambda:tf.sign(tf.random.uniform([],-1,1)), lambda:tf.constant(1.0))
shift_x = tf.random.uniform(shape=[], minval=-shift_range, maxval=shift_range)
shift_y = tf.random.uniform(shape=[], minval=-shift_range, maxval=shift_range)
sinval = tf.sin(angle)
cosval = tf.cos(angle)
mat = tf.convert_to_tensor([[cosval, -sinval]*mirror_y, [sinval, cosval]*mirror_x])
skew_mat = tf.convert_to_tensor([[zoom_y, skew_x*zoom_x], [skew_y*zoom_y, zoom_x]])
mat = tf.matmul(mat, skew_mat)
size = image.get_shape()[0]
image_center = size/2
coord_transformed = tf.matmul(coord, mat) + (image_center*(1.0+shift_y), image_center * (1.0+shift_x))
coord_transformed = tf.cast(tf.round(coord_transformed), tf.int32)
coord_transformed = tf.clip_by_value(coord_transformed, 0, size-1)
image_new = tf.gather_nd(image, coord_transformed)
image_new = tf.reshape(image_new, image.shape)
return image_new
def random_color_jitter_fn(x, shift):
return x + tf.random.uniform([3,], -shift, shift)
def random_contrast_fn(x, contrast_range):
return x * tf.random.uniform([], 1.0-contrast_range, 1.0+contrast_range)
class AugImage(tf.keras.layers.Layer):
def __init__(self,image_shape, p=0.8, color_shift_range=0.2, contrast_range=0.5,
rotation_range=90.0, zoom_range=0.2,shift_range=0.2,skew_range=0.2,
flip_h=True, flip_v=False,
**kwargs):
super().__init__(**kwargs)
self.p = p
self.color_shift_range = color_shift_range
self.contrast_range = contrast_range
self.coord = make_coord(image_shape[0])
self.rotation_range = rotation_range
self.zoom_range = zoom_range
self.shift_range = shift_range
self.skew_range = skew_range
self.flip_v = flip_v
self.flip_h = flip_h
def _augmentation(self, image):
def pred():
return tf.less_equal(tf.random.uniform([]), self.p)
# random shift color
image = tf.cond(pred(),
lambda: random_color_jitter_fn(image,self.color_shift_range), lambda: image )
# random contrast
image = tf.cond(pred(),
lambda: random_contrast_fn(image,self.contrast_range), lambda: image )
image = tf.clip_by_value(image, -1.0,1.0)
# Transform
coord = self.coord
if coord is not None:
angle = tf.cond(pred(), lambda:self.rotation_range, lambda:0.0)
zoom = tf.cond(pred(), lambda:self.zoom_range, lambda:0.0)
skew = tf.cond(pred(), lambda:self.skew_range, lambda:0.0)
shift = tf.cond(pred(), lambda:self.shift_range, lambda:0.0)
flip_h = pred() if self.flip_h else tf.constant(False)
flip_v = pred() if self.flip_v else tf.constant(False)
image = image_transform_fn(image, coord, angle, zoom, skew, shift, flip_h, flip_v)
return image
def call(self, inputs, training=None):
if training is None:
training = tf.keras.backend.learning_phase()
if training:
return tf.map_fn( lambda img: self._augmentation(img), inputs)
return inputs
適用するとこんな感じの画像になる。

その他
ADA以外の実装に関して、標準的ではなさそうな箇所について簡単に説明しておく。
GANの構成
標準的なGANの実装では、上記の図のように一回ステップでGeneratorを2回とDiscriminatorを3回通す形になるが、今回はAugmentationの処理をできるだけ減らしたいので、Generator1回とDiscriminator2回で済ます形にしてある。教科書的ではないが、これでも学習できる。
Minibatch standard deviationの使用
DiscriminatorにはPGGANで提案されているMinibatch standard deviationの処理を挿入した。これがあると生成画像に多様性が出るようだ。
Discriminator Projectionの使用
Conditionalなのでモデルに対してラベルも入力しているが、Discriminator側ではDiscriminator Projectionに準じた形で処理している。若干論文とは違う気がするが、学習できるので良しとする。こちらの方が入力画像にラベルを結合する形よりも学習が速いようだ。
GeneratorのActivationにGLUを使用
たまたまOT-GANのコードを見ていたらGLU(Gated Linear Unit)を使用する形のDCGANが実装されていて、試したら結構良かったので採用。
Spectral Normalization
これはGANでは有名な手法だが、TensorFlowの実装は割と怪しいものが多いようだ。こちらの記事の実装が最も信頼できそうだったので、改造してDiscriminator内で使用している。
実験結果
元のデータは128x128だが、ここでは64x64にリサイズして実施している。入力バッチサイズは512になっているので、一つのバッチにほぼ全てのデータが収まることになっている。データ拡張の適用確率は論文通り0.8とし、上記のコードのデフォルト値でShift/Rotation/Zoom/Skew/RandomHorizontalFlip/RandomColorJitter/RandomContrastのデータ拡張処理を行った。その他の細かい設定はコード参照のこと。
一エポック(1000ステップ)にかかる時間はADAなしで約70秒、ADAありで約140秒だった。
ADAなしは割とすぐにDiscriminatorのLossが0付近に張り付くので、約180エポック程度で打ち切った。ADAありは約240エポックまで学習させている。
ランダム生成
キャラクター(ラベル)ごとにランダムに画像を生成し、学習の過程を比較した。
(注:ランダム生成の画像はAnimation PNGなのだが、静止画として表示されてしまう場合は、画像をクリックして単体で表示させると動画として閲覧できるはず。)
ADAなし

ADAなしでもそれなりに画像は生成しているように見えるが、画像にノイズが多ように見える。また、同じような画像を生成している場合が多く、モード崩壊が発生していると思われる。
ADAあり

回転や反転、色変動を加えていても、生成画像としては概ね問題ない。ただしキルミーベイベーのロゴが左下にくる画像を生成している場合があり、このような画像は入力データには存在しないので、左右反転された画像を学習して生成していると思われる。もっと確率を低くすれば防止できたかもしれない。
ADAを入れない場合に比べて、生成画像にノイズ感があまりなくなるようだ。また、一エポックあたりの画像のバリエーションも多い。
モーフィング
ラベルを固定して2つのノイズ入力間で補間したものと、ノイズ入力を固定してラベルを補間したもので比較する。
ノイズ間補正では画像の右端と左端で別のノイズ入力で、中間はそれを補間した物になり、上下に隣接する画像ではラベルだけが違いノイズは共通している。
ラベル間補正では全画像で全てノイズ入力は同じで、ラベルを「やすな→ソーニャ→あぎり→やすな」と補間しながら循環させている。この場合は訓練では必ずOneHotで入力されていたラベルが、生成時だけ中間のベクトルを入力することになる。
どちらの補間もSlerpで行った。
ADAなし
ノイズ間補間

ラベル間補間

左右に隣接する画像とはできるだけ類似していて欲しいのだが、ノイズ間補間では急激に画像が変わる。上下に隣接するものでは同じノイズ入力なので似たような画像になって欲しいところだが、この関連性もあまり感じられない。
ラベル間での補間は事実上機能していない。
ADAあり
ノイズ間補間(その1)

ノイズ間補間(その2)

ラベル間補間

ノイズ間補間はそれなりにうまくいっているように見える。隣接する上下の画像が似たような構図になりやすいことも二番目の画像で示した。ただし、共通性が少ないキャラクター固有の画像が元になると補間は流石に厳しい。
ラベル間補間もなんとか中間の画像を出そうをしているように見える。
総じて超小型データセットとしてはかなりうまくいっている方ではないかと思う。
まとめ
キルミーベイベーデータセットを用いて、ADAの効果を確認した。約500百枚程度のデータセットでもそれなりに学習できたように思うので、かなり効果があるのではないかと感じた。
記事のタイトル通りにキルミーベイベーが復活したとまでは流石に言えないが、筆者はつい最近GANに入門したGAN初心者なので、もっとスキルがある方が挑戦すればさらに良い結果が得られるかもしれない。
参考記事
GANについて概念から実装まで ~DCGANによるキルミーベイベー生成~
FastGAN(LightweightGAN)を試してみる
TensorFlow2.0 + 無料のColab TPUでDCGANを実装した
TensorFlowでカスタム訓練ループをfitに組み込むための便利な書き方