はじめに
TensorFlow/Kerasで最適化アルゴリズムを自作したくなる場面はまず無いが、興味のある人もそれなりにいるだろう、と思い記事を作成。
環境
- TensorFlow(2.3.0)
- Google Colab(GPU/TPU)で動作確認済み
基本
tensorflow.python.keras.optimizer_v2.optimizer_v2.OptimizerV2を継承して作る。
VanillaSGDを実装すると以下の通りになる。
from tensorflow.python.keras.optimizer_v2.optimizer_v2 import OptimizerV2
class VanillaSGD(OptimizerV2):
def __init__(self, learning_rate=0.01, name='VanillaSGD', **kwargs):
super().__init__(name, **kwargs)
self._set_hyper("learning_rate", kwargs.get("lr", learning_rate))
def get_config(self):
config = super(VanillaSGD, self).get_config()
config.update({
"learning_rate": self._serialize_hyperparameter("learning_rate"),
})
return config
def _resource_apply_dense(self, grad, var, apply_state=None):
var_device, var_dtype = var.device, var.dtype.base_dtype
lr_t = self._get_hyper("learning_rate", var_dtype)
return var.assign(var - lr_t * grad)
def _resource_apply_sparse(self, grad, var, indices):
raise NotImplementedError("not implemented")
-
__init__()は各種初期化処理を実装する。 - 主にハイパーパラメーターの登録を
_set_hyper()を使用して行う - この例の場合はlearning_rateを登録しているが、
kwargs.get("lr", learning_rate)というのは"lr="と指定しても扱えるようにするため。 -
get_config()はシリアライズのための処理を入れる。 - ModelのSave時に呼ばれる。
- ハイパーパラメーターは全てここで
configに追加する。 - 値の取得には
_serialize_hyperparameter()を使う。 -
_resource_apply_dense()で変数の更新処理を行う。 - gradは勾配のテンソル
- varは変数(つまり重み)のテンソル。gradと同じShape。
- apply_stateはハイパーパラメーター等が格納されている辞書
- ハイパーパラメーターの取得には
_get_hyper()を使う - 戻り値は「変数を更新するOperater」が要請されているので、varをassign系の関数で更新したものを返す必要がある。この例では、重みから勾配に学習率を掛けたものを引いて新しい重みとする。
-
_resource_apply_sparse()はSparseなネットワークを更新する場合に使用される。通常は実装しなくても問題ない。
保存したモデルからLoadを実行する際には、下記のようにcustom_objectsとして追加しておく。
tf.keras.models.load_model('model.h5', custom_objects={'VanillaSGD': VanillaSGD})
decay対応
基本的にOptimizerV2を継承しているOptimizerはdecayパラメータにも対応している。
先に作成したVanillaSGDも対応させると、下記のようになる。
class VanillaSGD2(OptimizerV2):
def __init__(self, learning_rate=0.01, name='CustomOptimizer', **kwargs):
super().__init__(name, **kwargs)
self._set_hyper("learning_rate", kwargs.get("lr", learning_rate))
self._set_hyper('decay', self._initial_decay)
def get_config(self):
config = super(VanillaSGD, self).get_config()
config.update({
"learning_rate": self._serialize_hyperparameter("learning_rate"),
"decay": self._serialize_hyperparameter("decay"),
})
return config
def _resource_apply_dense(self, grad, var, apply_state=None):
var_device, var_dtype = var.device, var.dtype.base_dtype
lr_t = self._decayed_lr(var_dtype)
return var.assign(var - lr_t * grad)
def _resource_apply_sparse(self, grad, var, indices):
raise NotImplementedError("not implemented")
-
__init__()でハイパーパラメーターとして'decay'を登録するが、super().__init__でself._initial_decayがすでに定義済みなので、それを利用する。 -
_resource_apply_dense()内では、学習率を取得する際に定義済みの_decayed_lr()を使用する。自動的にdecayが効いた学習率が返ってくる。
変数の追加
実用的な最適化アルゴリズムでは、各重みに付随した変数を保持して計算に利用する必要がある。
このような例としてMomentumSGDを実装すると下記のようになる。
class MomentumSGD(OptimizerV2):
def __init__(self, learning_rate=0.01, momentum=0.0, name='MomentumSGD', **kwargs):
super().__init__(name, **kwargs)
self._set_hyper("learning_rate", kwargs.get("lr", learning_rate))
self._set_hyper('decay', self._initial_decay)
self._set_hyper('momentum', momentum)
def get_config(self):
config = super(MomentumSGD, self).get_config()
config.update({
"learning_rate": self._serialize_hyperparameter("learning_rate"),
"decay": self._serialize_hyperparameter("decay"),
"momentum": self._serialize_hyperparameter("momentum"),
})
return config
def _create_slots(self, var_list):
for var in var_list:
self.add_slot(var, 'm')
def _resource_apply_dense(self, grad, var, apply_state=None):
var_device, var_dtype = var.device, var.dtype.base_dtype
lr_t = self._decayed_lr(var_dtype)
momentum = self._get_hyper("momentum", var_dtype)
m = self.get_slot(var, 'm')
m_t = m.assign( momentum*m + (1.0-momentum)*grad)
var_update = var.assign(var - lr_t*m_t)
updates = [var_update, m_t]
return tf.group(*updates)
def _resource_apply_sparse(self, grad, var, indices):
raise NotImplementedError("not implemented")
-
_create_slots()で、追加したい変数を登録する。 - 慣性項のために、
add_slot()を使用して各varごとに'm'という名前で追加。 - 追加した変数は、
get_slot()で取り出す。 -
_resource_apply_denseの戻りとしては、更新する変数のOperationをtf.group()を使ってまとめて返す。今回の場合はvar_updateとm_tが対象。
ちなみに今回作成したMomentumSGDは、tf.kerasのSGDを使ったものとは学習率の解釈が違うので、同じ学習率でも結果が違う。
こちらの学習率に(1-momentum)を掛けると、tf.kerasのSGDと同じ結果になる。例えばMomenutumSGD(0.01,momentum=0.9)はSGD(0.001,momentum=0.9)と同じ。
ステップ数に応じて処理を変える
実行回数に応じて係数を調整したりする処理が必要な場合がある。
そのような場合はすでに定義済みのself.iterationsが利用できる。
MomentumSGDの慣性項は初期値の0.0に引っ張られてしまうバイアスが存在するが、それを補正する処理を入れてみたものが以下の例。(Adamでも同様の補正をしている)
とりあえず"Centered Momentum SGD"と名付けておく。
class CMomentumSGD(OptimizerV2):
def __init__(self, learning_rate=0.01, momentum=0.0, centered=True, name='CMomentumSGD', **kwargs):
super().__init__(name, **kwargs)
self._set_hyper("learning_rate", kwargs.get("lr", learning_rate))
self._set_hyper('decay', self._initial_decay)
self._set_hyper('momentum', momentum)
self.centered = centered if momentum!=0.0 else False
def get_config(self):
config = super(CMomentumSGD, self).get_config()
config.update({
"learning_rate": self._serialize_hyperparameter("learning_rate"),
"decay": self._serialize_hyperparameter("decay"),
"momentum": self._serialize_hyperparameter("momentum"),
'centered': self.centered,
})
return config
def _create_slots(self, var_list):
for var in var_list:
self.add_slot(var, 'm')
def _resource_apply_dense(self, grad, var, apply_state=None):
var_device, var_dtype = var.device, var.dtype.base_dtype
lr_t = self._decayed_lr(var_dtype)
momentum = self._get_hyper("momentum", var_dtype)
m = self.get_slot(var, 'm')
m_t = m.assign( momentum*m + (1.0-momentum)*grad)
if self.centered:
local_step = tf.cast(self.iterations+1, var_dtype)
m_t_hat = m_t * 1.0 / (1.0-tf.pow(momentum, local_step))
var_update = var.assign(var - lr_t*m_t_hat)
else:
var_update = var.assign(var - lr_t*m_t)
updates = [var_update, m_t]
return tf.group(*updates)
def _resource_apply_sparse(self, grad, var, indices):
raise NotImplementedError("not implemented")
- centeredが真の場合に、補正を入れる。ここでself.iterationsを使用している
- centeredはハイパーパラメーターではあるが、途中で変更すこともないので、
_set_hyper()等は使用していない。
せっかく作ったので、各最適化アルゴリズムの比較をしてみる。
比較方法は、この記事に準じている
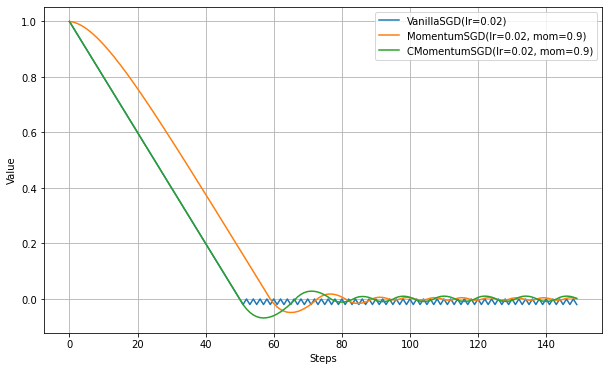
- MomentumSGDとVanillaSGDの比較
- MomentumSGDのほうが立ち上がりが遅い(角度がつくまで時間がかかる)。慣性があるため、初期値の0から動き出すのに時間がかかっていると解釈できる。
- VanillaSGDと同じ角度になってからは、全く同じ角度で推移する。
- 最適値(0.0)をやや大きく通りすぎるのは慣性項の効果。
- VanillaSGDでは最適値付近で細かく振動するが、MomentumSGDではゆるく振動する。これも慣性項の効果。
- CenteredMomentumSGDとMomentumSGDの比較
- 初期値バイアスの補正の結果、立ち上がりの遅さが改善されて、VanillaSGDと全く同じ軌道をとるようになった。
- 最適値を通りすぎた後は、MomentumSGD特有の動きとなる。
繰り返しになるが、ここで実装したMomentumSGDはKeras等で通常実装されているものとは若干処理が異なるので注意。(こちらのほうが慣性項の真の効果がわかりやすくて、個人的には良いと思うが)
参考
TensorFlowの実装
https://github.com/tensorflow/tensorflow/tree/master/tensorflow/python/keras/optimizer_v2
Optimizerの実装方法
第6回 カスタマイズするための、TensorFlow 2.0最新の書き方入門