はじめに
物体検出の記事をこれまで書いてきましたが、最近Unityを触る機会があったので、Unityで物体検出する方法を調べて、まとめてみました。
本記事では、自前のdarknet形式のYOLOv3-tinyモデルを使ったUnity上での物体検出を行います。
以下の順序で記載します。
開発環境
- Unity Editor:2021.3.9f1
- Barracuda:Version 3.0.0
Barracudaの導入
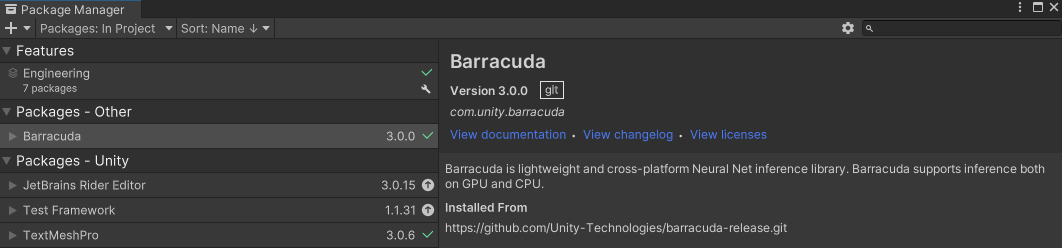
BarracudaはUnityの公式パッケージとして提供されているニューラルネットワーク推論ライブラリです。GPUとCPUの両方で推論をサポートしています。
Unity Editorでプロジェクトを起動し、以下の手順でパッケージを導入します。
- Window - Package Manager
- +マーク - Add package from git URL
-
https://github.com/Unity-Technologies/barracuda-release.gitと入力して、Add
2022年11月現在、Version 3.0.0が追加されます。
YOLOv3-tiny用の実装
YOLOv3-tinyモデルの検出結果を元に描画する実装を一から行うのは大変なので、Unity-Technologies/barracuda-starter-kit の中に含まれてるYOLOv3-tinyの実装を流用します。
barracuda-starter-kitには3つのサンプルが含まれています。
- 01-StaticImageRecognition-MobileNetV2:MobileNet
- 02-FaceTracking-BlazeFace:MediaPipe BlazeFace model
- 03-MultiObjectStaticImageRecognition-YoloV3Tiny : YOLOv3-tiny
まずは動作を確認してみましょう。
03-MultiObjectStaticImageRecognition-YoloV3TinyのSceneを選択し、再生すると以下のような画面が表示されます。公式の説明はありませんが、COCOデータセット(クラス数は80)の検出モデルが搭載されているようです。
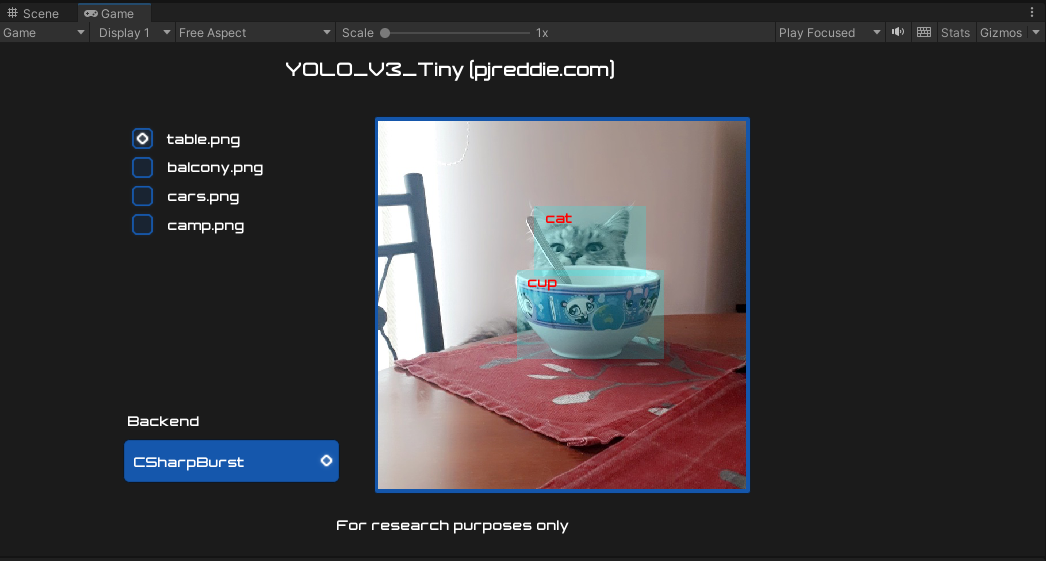
左下のBackendでは、Workerの種別を指定できます。Workerはモデルを実行可能なタスクに分解し、GPUまたはCPUにスケジュールします。
- CSharpBurst:Burstでコンパイルされた高効率なジョブ化・並列化されたCPUコード
- ComputePrecompiled:すべてのオーバーヘッドコードが取り除かれ、ワーカーにプリコンパイルされた高効率なGPUコード
- PixelShader:Pixel Shaderの実装
今回は、barracuda-starter-kitの03-MultiObjectStaticImageRecognition-YoloV3Tiny以下をUIも含めて自分で作成したプロジェクトにコピーして使用しました。
※ 画像の選択部分やBackendのプルダウンのUIが一部壊れるので手動で修正が必要になります。
darknet形式のYOLOv3-tinyモデルからONNX形式に変換
BarracudaはONNX(Open Neural Network Exchange)形式の学習モデルをサポートしています。TensorflowやPytorchなどで作成した学習モデルは変換が必要になります。
darknet形式からONNX形式への変換方法は、Kerasを経由したり、tensorflowを経由したり、複数の方法がありそうなのですが私の環境では失敗する方法が多かったです。
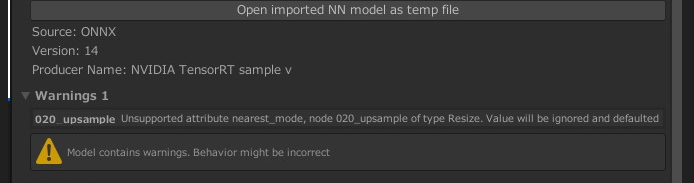
いろいろ試した結果、tensorrt_demos を利用することで成功しました。ONNXのVer1.4.1を利用する古いバージョンを使用しています。ONNXのVer1.9.0を利用する最新版では、変換には成功しますが、Unityのアタッチで警告が出ました。
準備
Python3.6で環境を構築し、必要なライブラリを入れます。
cd tensorrt_demos/yolo/
pip install -r requirements.txt
変換手順
まずは、正常に変換できることの確認するために、darknetの作者のサイト:YOLO: Real-Time Object Detectionで配布されているCOCOデータセット(クラス数は80)の学習済みモデルの重みとconfigファイルを用いて、ONNX形式のモデルへの変換を試します。
- 学習済みモデルの重みのファイル名を「yolov3-tiny-[学習時の画像サイズ].weight」に変更する。
- configファイルのファイル名を「yolov3-tiny-[学習時の画像サイズ].cfg」に変更する。
- tensorrt_demos/yolo/に、重みとconfigファイルを配置する
python yolo_to_onnx.py --model yolov3-tiny-[学習時の画像サイズ]
これでONNX形式のモデルが作成できました。
Unityへの取り込み
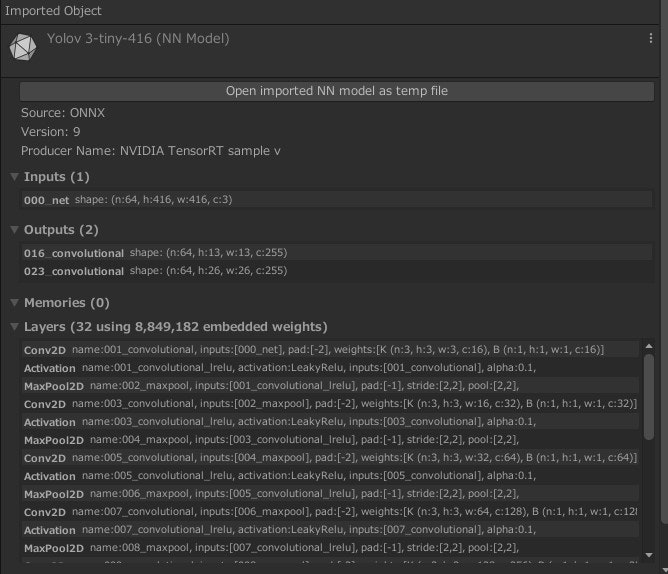
- ONNX形式ファイルのUnityへの取り込みはProjectウィンドウにDrag&Dropするだけです。正常に取り込めた場合は、以下のような表示になります。
モデルに異常がある場合は、以下のようにWarningやErrorが表示されます。
- Hierarchyウィンドウで「Controler」を選択し、Inspectorウィンドウの「Src Model」に取り込んだONNX形式のファイルをタッチします。
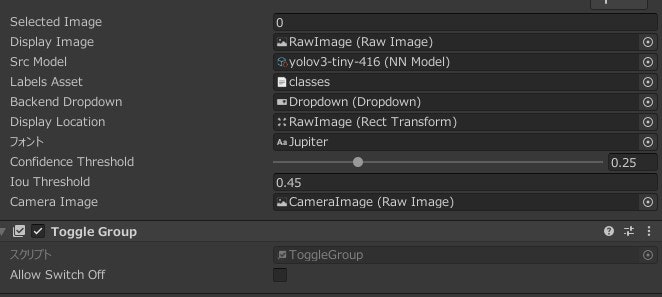
- 再生します。

モデル置き換え前と同様に検出できているので、正常に変換できていることが分かりました。
自作のYOLOv3-tinyモデルを使って物体検出
動作確認ができたので、自作のYOLOv3-tinyモデルを使って、物体検出しています。
yolov3-tinyの自作モデルは過去に https://qiita.com/SwitchBlade/items/11253433bbf6c34772acで作成した飼い猫の検出モデルを用います。クラス数は4のモデルになります。
ONNX形式への変換手順は先ほどと同様です。
Unityへの取り込み
- ONNX形式ファイルをProjectウィンドウにDrag&Dropします。
- タグ名称が記載されたテキストファイル(darknetモデルの作成時に「obj.names」のようなファイル名で作ったものです)をProjectウィンドウにDrag&Dropします。
- Hierarchyウィンドウで「Controler」を選択し、Inspectorウィンドウの「Src Model」に取り込んだONNX形式のファイルをタッチします。また、「Labels Asset」にタグ名称が記載されたテキストファイルをアタッチします。
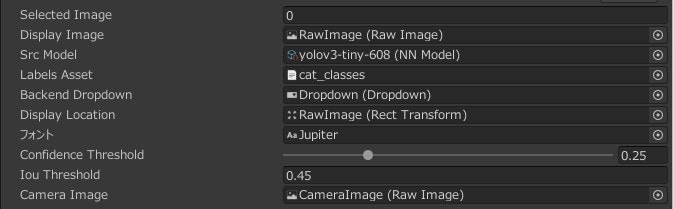
- クラス数が変わるので一部ソースの修正が必要になります。
private const int amountOfClasses = 4;
//private const int amountOfClasses = 80;
private const int anchorBatchSize = amountOfClasses + 5;
//private const int anchorBatchSize = 85;
動作確認
検出対象の画像をUnityに取り込みます。
RunInferenceYOLO.csで640×640の画像以外はエラーになるようにしているので、画像のサイズを変更するか、ソースを修正する必要があります。今回は、画像のサイズを640×640に変換して使用しました。
- 画像ファイルをProjectウィンドウにDrag&Dropします。
- 取り込んだ画像を選択し、Inspectorウィンドウで[Non-Power of 2]を[None]に変更します。また、[Format]を[RGBA 32bit]に変更します。
- Hierarchyウィンドウで「Controler」を選択し、Inspectorウィンドウの[Input Image]のいずれかのElementの画像と置き換えます。
- 再生します。


自前の検出モデルで検出できました!!
まとめ
今回はUnityを使って自前モデルで物体検出することができました。
今後は物体検出とARと組み合わせたアプリの作成や、物体検出以外のモデルの利用も試してみたいと思います。
参考にしたサイト
Unity Learning Materials/Unity Barracudaを使用したONNXニューラルネットワークモデルのマルチプラットフォーム運用
Unityの推論エンジン『Barracuda』を試してみたのでそのメモ
Barracuda 1.0.0 - Unity用の軽量でクロスプラットフォームなニューラルネットワーク推論ライブラリ
ONNX変換・確認ライブラリ、アプリケーションまとめ