この記事は「【マイスター・ギルド】本物の Advent Calendar 2020」10日目の記事です。
こんにちは、マイスター・ギルド入社5か月のSwitchBladeです。
マイスター・ギルド アドカレの猫連載2日目になります。前の方の記事で保護猫に関して記載されていましたが、我が家の4匹は近所に落ちていたものを保護しました。
はじめに
独自の学習データを使ったyolov3-tinyによる物体検出の学習をしていきます。
物体検出の対象は我が家の4匹の猫です。柄は4匹とも違っています。
※なお。今回の作業にRaspberryPiは使用しません。
以下の順序で作業します。
- 学習用画像の準備
- アノテーションデータ作成
- アノテーションデータをYoLo形式に変換
- 学習
1.学習用画像の準備
デジカメ撮影で230枚用意しました。(多い方がいいことは分かっていましたが、2か月でこの辺りが限界でした。)
猫紹介
| なまえ | タグ | 写真 | 備考 |
|---|---|---|---|
| にゃー | mike |  |
三毛。他の3匹とは別部屋。 |
| ちゃちゃ | cha |  |
茶トラ(白)。さばの兄弟 |
| さば | saba |  |
キジトラ(白)。ちゃちゃの兄弟。 |
| ゆき | kiji |  |
キジトラ(ペルシャ風)。一人愚連隊。 |
2.アノテーションデータ作成
物体検出用の教師データを作成していきます。
具体的には、写真のここに何がありますという注釈(アノテーション)をつけていきます。
アノテーションツールはMicrosoft VoTTを使用しました。
2.1. VoTTインストール(Windows)
https://github.com/Microsoft/VoTT/releases からダウンロードして、インストールします。

2.2.新規プロジェクト
起動して、[新規プロジェクト]を選択します。
2.3.プロジェクト設定

- 表示名:任意
- セキュリティ トークン:設定不要
- ソース接続:画像フォルダ
- ターゲット接続:プロジェクトやエクスポートの保存先
- 説明:任意
- ビデオ設定:今回ビデオは使わないのでデフォルトのまま
- タグ:必要なタグを指定(今回は4つのタグを指定します)
2.4.エクスポート設定
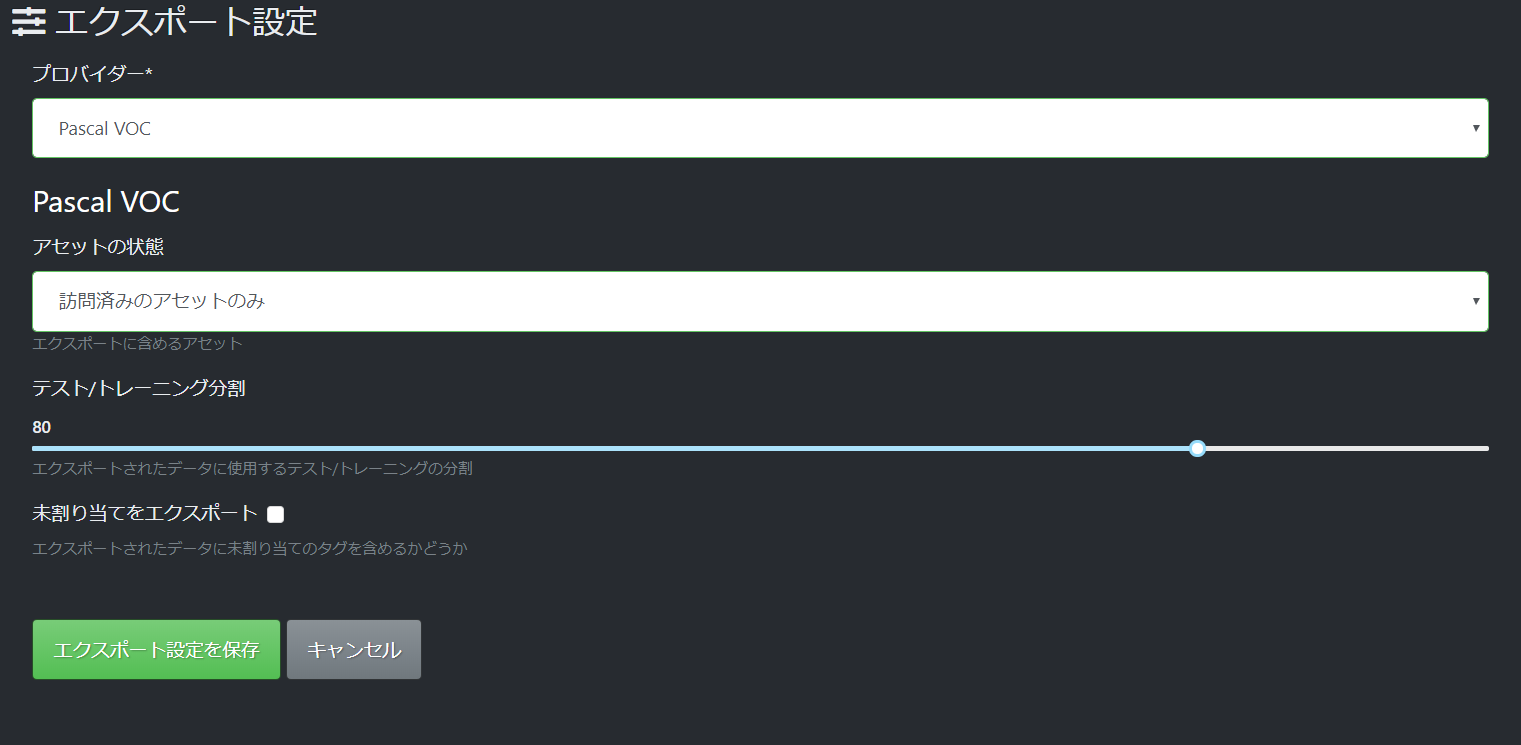
- プロバイダー:Pascal VOC (Yolo形式のエクスポートには対応していないので、一旦Pascal VOC形式にします)
- アセットの状態:訪問済みのアセットのみ
- テスト/トレーニング分割:キャプチャの状態で訓練データが80%、検証データが20%になります。
2.5.アクティブ ラーニング
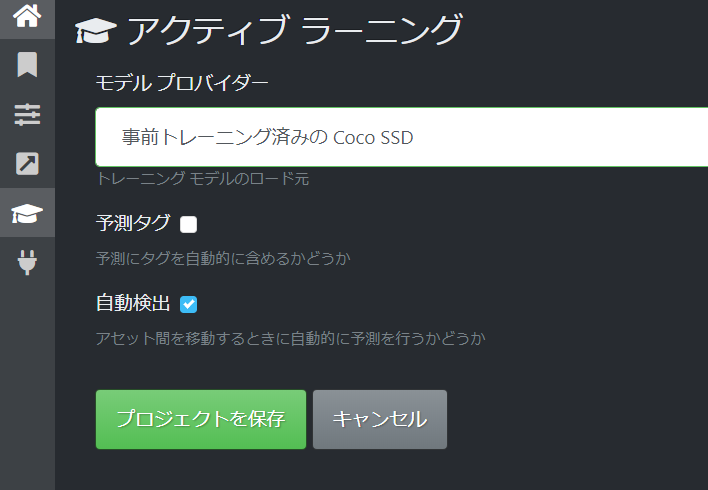
- モデル プロバイダー:「事前トレーニング済みのCoCo SSD」を選択すれば Microsoft CoCOデータセット に分類があるものは、物体がある場所を自動で範囲選択してくれるので、アノテーション作成にかかる時間を短縮できます。
- 予測タグ:ONにしておけば、Cocoデータセットと同じタグが自動で付与されます。今回はオリジナルのタグを付けるためOFFにしています。
上記の設定で、画像読み込み時にこのように自動で範囲選択されます。猫に関してはかなりの精度で検知してくれていました。
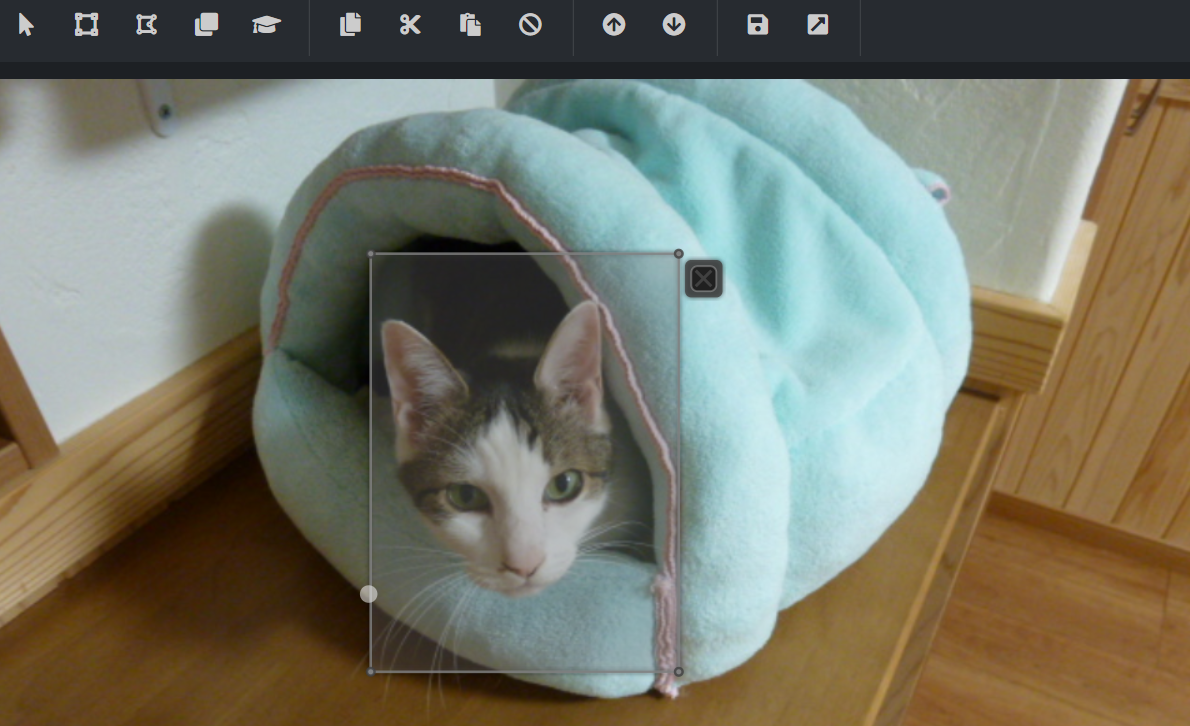
2.6.タグ付け
用意した画像分 地道にタグ付けをしていきます。。。230枚で1時間ほどかかりました。
2.7.エクスポート
タグを付け終わったら[プロジェクトをエクスポート]ボタンを押下して、エクスポートします
3.アノテーションデータをYoLo形式に変換
上に書いたようにVoTTはYoLo形式のエクスポートに対応していないので、Pascal VOC形式をYoLo形式に変換する必要があります。
VoTTでエクスポートしたPascal VOC形式のデータをYolo V3形式に変換 を参考にさせてもらいました。
一部ソースの修正が必要で、classes変数 をVoTTで作成したタグに書き換える必要があります
。その際、エクスポートされたpascal_label_map.pbtxtの順序で指定する必要があります。
classes = ["cha", "saba", "mike", "kiji"]
このPythonの実行は、Google Colaboratoryで作業しました。
実行すると、train.txt(訓練用の画像ファイルのセット)とval.txt(検証用の画像ファイルのセット)とexport/labelsの下に"画像のファイル名.txt"(YoLo形式のアノテーションファイル)ができます。
4.学習
学習は前回の記事でも使用したAlexeyAB/darknetをGoogle Colaboratory上で実行しました。Google ColaboratoryのランタイムのタイプはGPUを指定します。
4.1.インストール・ビルドなど
!apt install cuda-10-0 -y
import os
os.environ['PATH'] += ':/usr/local/cuda/bin'
os.environ['LD_LIBRARY_PATH'] += ':usr/local/cuda/lib64'
CUDAを使用するため、インストールします。バージョンは10.0以上です。
!git clone https://github.com/AlexeyAB/darknet
githubからcloneします。
%%bash
sed -i 's/GPU=0/GPU=1/g' Makefile
sed -i 's/CUDNN=0/CUDNN=1/g' Makefile
sed -i 's/OPENCV=1/OPENCV=0/g' Makefile
make
AlexeyABはC言語なので、Makefileを修正してmake(ビルド実行)します。Makefileの詳しい説明は、AlexeyABのgithubに書かれています。
-
%%bashは、Linuxコマンドを使うための、おまじないです。 - sedコマンド(Linuxの文字列置換コマンド)でMakefileを書き換えます。
-
GPU=1、CUDNN=1:GPUを使用できるようにします。 -
OPENCV=0:Google Colaboratory上ではOPENCVをOFFにしないと、学習の実行に失敗しました。
-
%%bash
./darknet partial yolov3-tiny_obj_train.cfg yolov3-tiny.weights yolov3-tiny.conv.15 15
一から学習すると時間がかかるため、学習済みの重みの前半のLayerを取り出して、そこから学習を始めます。
学習済みの重みはpjreddie/darknetからダウンロードできます。
上のコマンドでは15Layerを取り出しています。
4.2.画像ファイル・アノテーションファイル等の配置
画像ファイルとYoLo形式のアノテーションファイルをdarknetフォルダの下に移動します。今回はdata/imagesフォルダとします。
同じくYoLo形式のアノテーションファイル作成時に出力されるtrain.txtとval.txtをdarknetフォルダの下に移動します。今回はdataフォルダとします。train.txtとval.txtには画像のパスが書かれていますが、darknet実行ファイルからの相対パスに変更します。今回の場合だと、data/images/XXXX.jpgに変更します。
以下の2ファイルを作成します。
cha
saba
mike
kiji
タグ名称をpascal_label_map.pbtxtの順序で記載します。
classes= 4
train = data/train.txt
valid = data/test.txt
names = data/obj.names
backup = backup/
classes:タグの数を指定
train:訓練用の画像ファイルセットが記載されたファイル
valid:検証用の画像ファイルセットが記載されたファイル
names:タグ名称が記載されたファイル
backup:学習結果の重みが格納されるパス
4.3.configファイル修正
configファイルをpjreddie/darknetからダウンロードして、学習したい内容に合わせて修正します。
# Testing
# batch=1
# subdivisions=1
# Training
batch=32
subdivisions=8
・・・
max_batches = 8000
・・・
steps=6400,7200
学習用に設定を変更します。
- batch:学習時のバッチサイズ。大きくすると時間がかかります。
- subdivisions:バッチを何分割するか。小さいと
Out of memoryが発生する可能性があります。 - max_batches:バッチの繰り返し回数。タグ数×2000が目安。
- steps: max_batchesの80%と90%を指定します。
[convolutional]
size=1
stride=1
pad=1
filters=27 ★
activation=linear
[yolo]
mask = 3,4,5
anchors = 10,14, 23,27, 37,58, 81,82, 135,169, 344,319
classes=4 ★
num=6
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1
★の位置を修正します。
- classes:[yolo]レイヤーのclassesをタグ数に変えます。
- filters:[yolo]レイヤーの前の[convolutional]レイヤーのfiltersを(タグ数 + 5)x3 に変えます。
yolov3-tiny.cfgにはそれぞれ2か所あります。
4.4.学習実行
%%bash
chmod u+x darknet
./darknet detector train data/obj.data yolov3-tiny_train.cfg yolov3-tiny.conv.15
学習時間はColaboratoryのGPUガチャにもよりますが、Tesla P100で60分程度かかりました。
学習結果の確認
学習結果の確認もColaboratoryで行います。
%%bash
sed -i 's/GPU=0/GPU=1/g' Makefile
sed -i 's/CUDNN=0/CUDNN=1/g' Makefile
sed -i 's/OPENCV=0/OPENCV=1/g' Makefile
make
Makefileを書き換えてmakeし直します。OPENCVを有効にします。
# Testing
batch=1
subdivisions=1
# Training
# batch=32
# subdivisions=8
yolov3-tiny_train.cfg をファイルコピーして上の部分を修正します。
%%bash
chmod u+x darknet
./darknet detector test data/obj.data yolov3-tiny_test.cfg backup/yolov3-tiny_train_final.weights data_test/XXXXXX.JPG -ext_output -thresh 0.01 -dont_show
- -ext_output :結果画像が
predictions.jpgで出力されます。 - -thresh XXX :検出する確度の閾値
- -dont_show : 実行時の結果画像表示を抑止する。Colaboratory上では付けないとエラーになります。
何枚か結果を載せます。判定の枠にタグ名と判定確度が出力されます。


この辺りはうまく検出できています!特に1枚目は高い確度になっていますが、ほぼ同じ構図の写真を学習に使用していた影響と思います。


この辺りは閾値を0.01にしているためぎりぎり検出できていますが、確度も低いですし誤判定もあります。全般的に「ちゃちゃ」はうまく検出できてない傾向が多かったです。学習用の画像が230枚とかなり少なかったこともありますが、見る角度によっては白の割合が多いため「にゃー」や「さば」と混同して学習されている可能性があります。
メモ
役に立つか分かりませんが、気づいたことをメモしておきます。
- 学習時のloss(損失)が0.2程度まで下がっていない場合は、収束していない可能性が高いです。訓練データを用いて学習結果の確認を行っても、検出できません。
- VoTTの訓練データ、検証データの振り分けはVoTTで読み込んだファイル順である程度連続して振り分けるっぽいです。自分で撮った写真を使う場合は似た写真が連続するため、訓練データ、検証データの偏りが大きいです。収束しない場合は、
train.txtとval.txtのファイル名をランダムに入れ替えるとうまくいくかもしれません。 - 学習時は1000ステップごとにバックアップファイルが作成されます。もし、Colaboratoryの時間切れなどで途中で学習が途切れた場合は、学習実行コマンドの
yolov3-tiny.conv.15をバックアップファイルに変えることで学習を途中から再開することができます。
今後の方向性
【物体検出】vol.3 :YOLOv3の独自モデル学習の勘所 によると、学習データは1タグにつき1000枚程度が必要ということなので学習用の写真を増やして検出の精度を上げる方法を試しつつ、RaspberryPiで検出できるようにしていきます。