はじめに
こんにちは、株式会社ジールの@Suguru-Terouchiです。
さて、前回で例のチュートリアルについて解説を行ってきましたので、
今回はいよいよAWSのサービスやプログラムを動かしていきたいと思います。
それなりのボリュームになってしまいましたが誰かのお役に立てれば幸いです。
軽く前回のおさらい
まず、チュートリアルのストーリーですが、預金証書 (CD)の申し込みを行うかどうかを予測を行います。

データはこんな感じになっています。
最後のQ列にある「y」という項目が「yes」か「no」かを予測します。

=======
出典:[Moro et al., 2014] S. Moro, P. Cortez and P. Rita. 銀行テレマーケティングの成功を予測するためのデータ駆動型アプローチ。
意思決定支援システム、エルゼビア、62:22-31、2014 年 6 月
https://archive.ics.uci.edu/ml/datasets/bank+marketing
で最後に今回実施する手順です。

その他、詳細を確認したい方はこちらを見て頂ければと思います。
え?今回手抜きじゃね?
そんなことないですよ、ここから本気出していくのでご安心ください。
チュートリアル実施
おさらいもしましたが、まずは手順通りにやっていきます。
①環境作成
ノートブックインスタンスの作成
まずはAWSのコンソールにログインします。

※チュートリアルでは黄色枠の部分について「米国西部 (オレゴン) リージョンを使用します。」とありますが、
料金単価が1時間に数円の違いがあるくらいで機能的な差はないので好きに選んでOKです。
チュートリアルにあるリンクもしくは↑のコンソールのホーム画面の検索やサービス一覧からAmazon SageMakerのコンソールを開いてください。(なにやらいっぱいメニューが出てきますが、気を確かに持ってください。)

画面左にあるメニューから「ノートブック」>「ノートブックインスタンス」とクリックして表示される「ノートブックインスタンスの作成」というオレンジ色のボタンをクリックしてください。

ここからインスタンスの設定を行います。
設定項目はいっぱいありますが、まずはインスタンス名とタイプを選択してあげましょう。
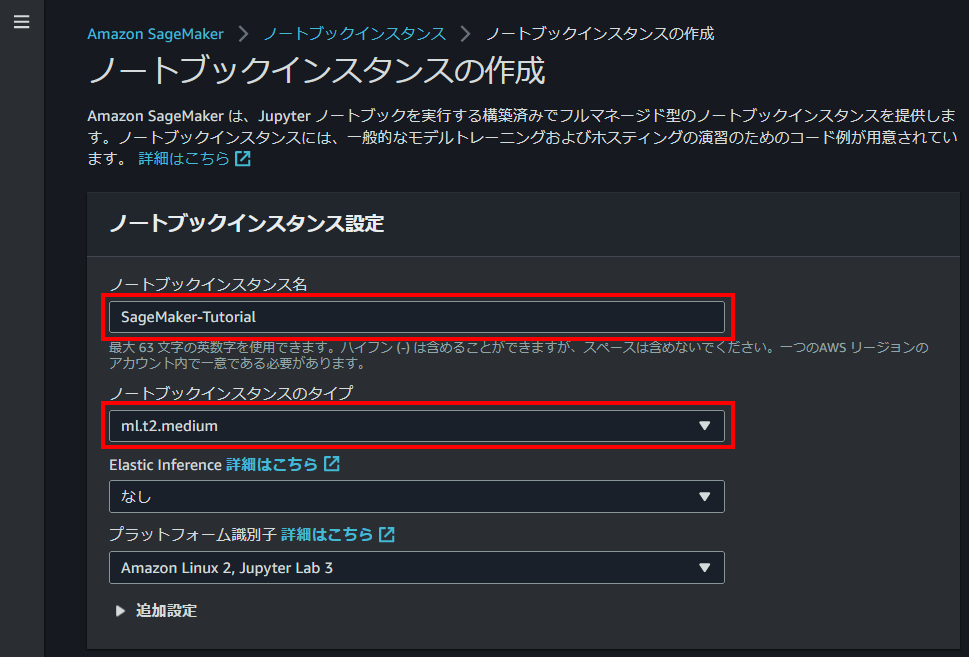
ノートブックインスタンス名はそのままですが、マシンの識別するための名前になります。
ぶっちゃけ同じ名前のものが存在しなければなんでも大丈夫です。従順な筆者は指示通り入力してます。
ノートブックインスタンスタイプはマシンの性能を決める設定になります。
チュートリアルでは「ml.t2.medium」が指定されていますが、初期設定されている「ml.t3.medium」でも問題ないです。
詳細は割愛しますが、「t2」とか「t3」はインスタンスの世代を表していて、執筆時点では互換性を保つために古い世代の「t2」が選択可能になっています。
次にアクセス許可設定を行います。
ここで言うアクセス許可とはこれから作成するマシンがどこにアクセスできるか?を設定します。
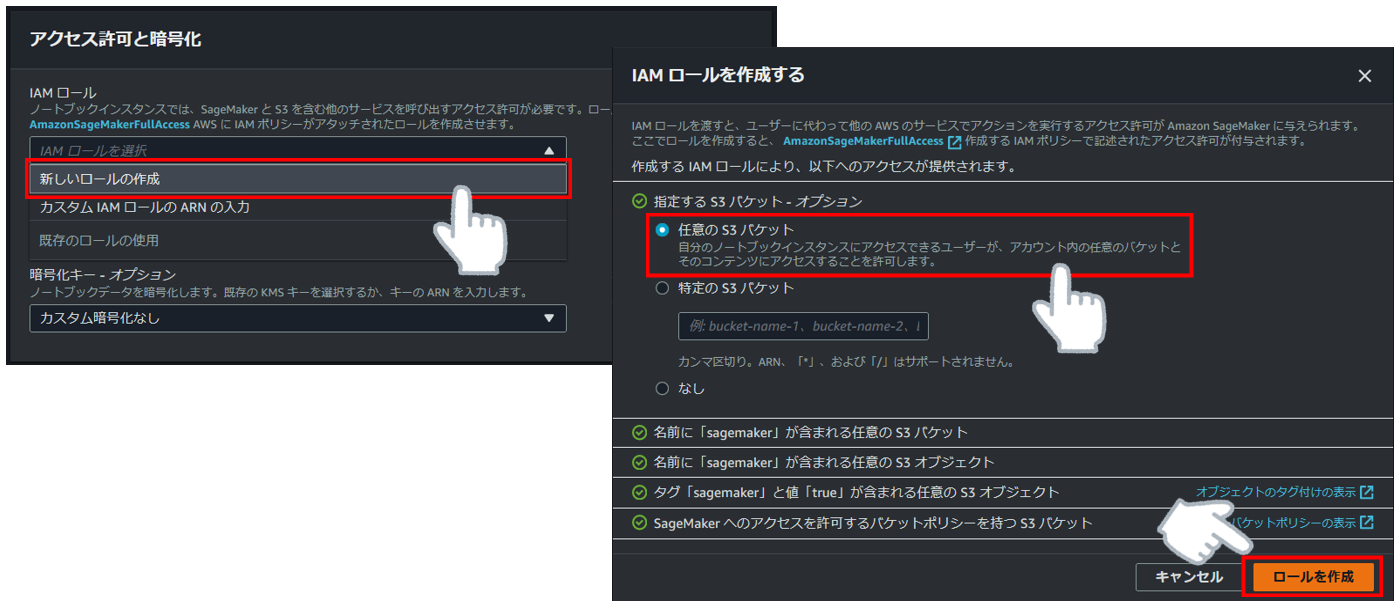
IAMロール作成に成功したことを確認したら勇気を出して「ノートブックインスタンスの作成」をクリックしてください。

すると画面が最初の画面に戻り、インスタンスの作成が始まります。

そのまま少し待っているとステータスが「Pending」から「InService」へ変わり、アクションのところにリンクが表示されたら環境作成は完了です。

②データ準備
この手順では①で作成した環境を使って今回使うデータの用意をします。
まずは先ほどの画面右側のアクションにある「Jupyter を開く」をクリックしてください。

すると新しいタブが開き、以下のような画面が表示されるので、「New」>「conda_python3」とクリックしてください。

そうするとまた新しいタブが開きます。ここでプログラムを書いたり実行したりすることができます。
初期設定
手順にある初期設定用のプログラムを張り付け、「▶Run」をクリックしてください。
# import libraries
import boto3, re, sys, math, json, os, sagemaker, urllib.request
from sagemaker import get_execution_role
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from IPython.display import Image
from IPython.display import display
from time import gmtime, strftime
from sagemaker.predictor import csv_serializer
# Define IAM role
role = get_execution_role()
prefix = 'sagemaker/DEMO-xgboost-dm'
my_region = boto3.session.Session().region_name # set the region of the instance
# this line automatically looks for the XGBoost image URI and builds an XGBoost container.
xgboost_container = sagemaker.image_uris.retrieve("xgboost", my_region, "latest")
print("Success - the MySageMakerInstance is in the " + my_region + " region. You will use the " + xgboost_container + " container for your SageMaker endpoint.")
おや、、実行してみたら、なにやらエラーになりました。。

いろいろ調べてみるとインストールされているソフトウェアが古いようなのでアップデートを試みます。(もし空のセルがなければ画面左上にある「+」で追加してください。
%pip install --upgrade awscli
%pip install --upgrade boto3
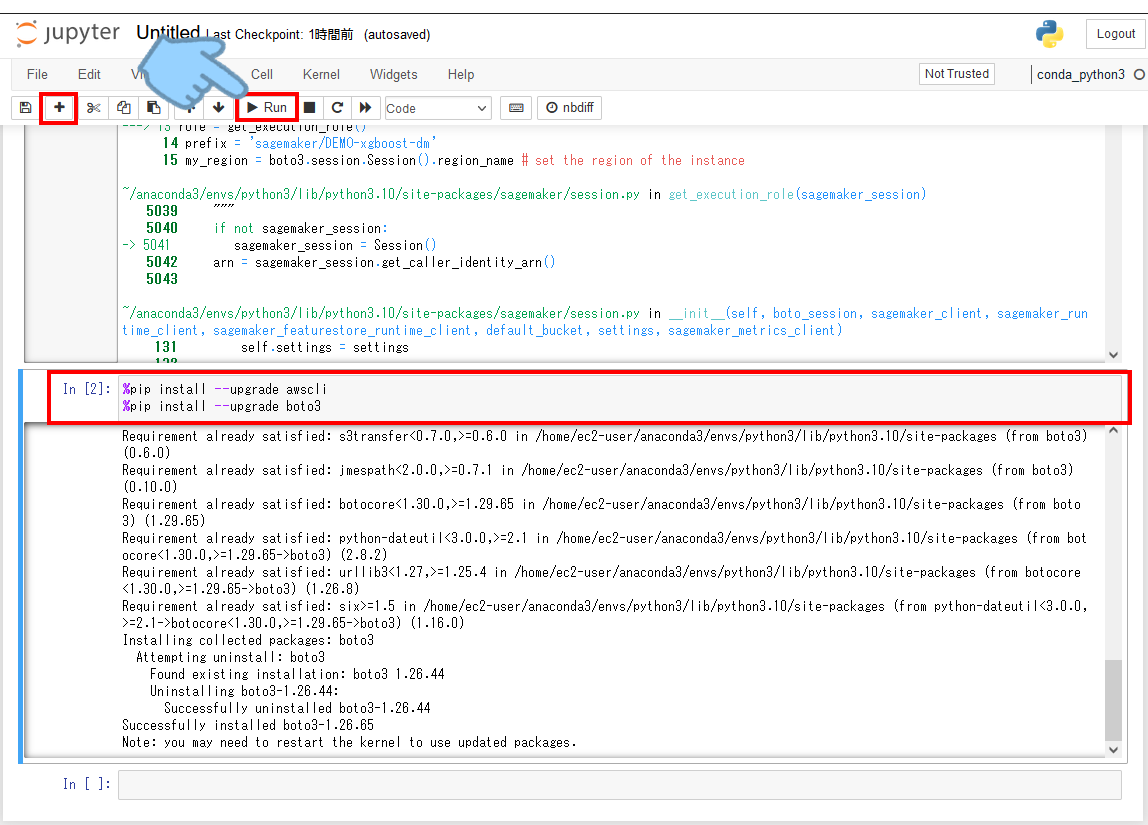
なんか「ERROR」という文字が見えた気がしますが、気にしない、、気にしない。。。
次にカーネルの再起動が必要なようなので以下のどちらかの方法で再起動します。

カーネルというのは、プログラムのチェックや実行をやってくれるソフトウェアです。
カーネルの再起動が完了したら再度、「▶Run」をクリックします。
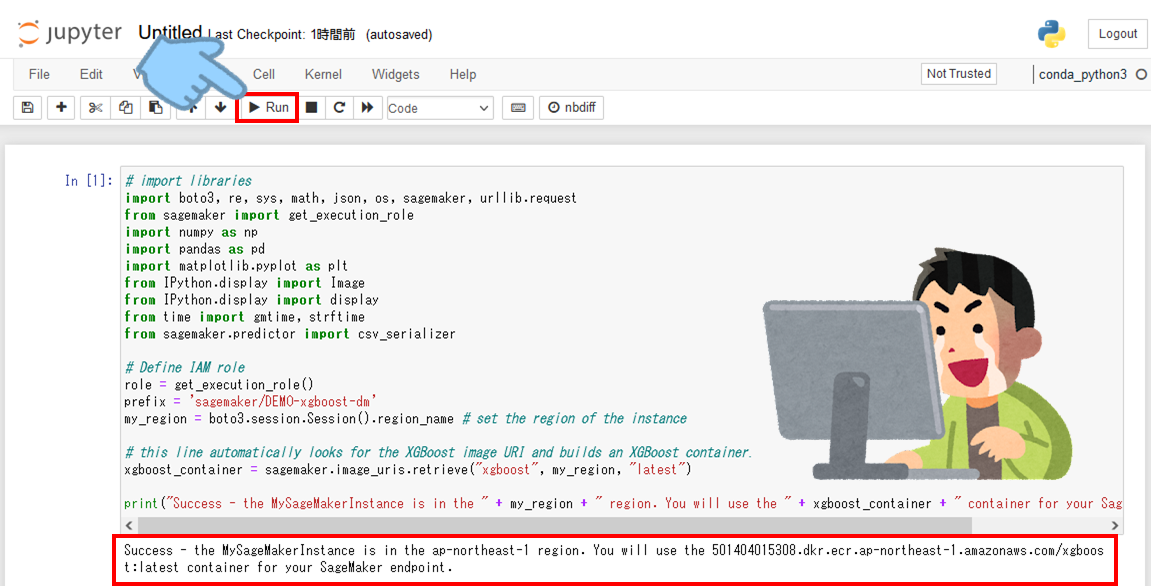
おおっ、やっと出会えました「Success」の文字!!良かった~!危うくもう少しで連載終了に追い込まれるところでした。
S3バケットの作成
では次にデータの置き場になるS3バケット作成を行います。
チュートリアルでも書いてありますが、1行目の「your-s3-bucket-name」の部分を 一意 のS3バケット名に置き換えしてください。
しれっと書いていますが、この「一意」というのが少しくせ者で全世界で重複してはいけないので、自身のフルネームだけでなく、所属や年月日なども組合せた名前にするのがおすすめです。
このプログラムを張り付け、「▶Run」をクリックしてください。
bucket_name = 'your-s3-bucket-name' # <--- CHANGE THIS VARIABLE TO A UNIQUE NAME FOR YOUR BUCKET
s3 = boto3.resource('s3')
try:
if my_region == 'us-east-1':
s3.create_bucket(Bucket=bucket_name)
else:
s3.create_bucket(Bucket=bucket_name, CreateBucketConfiguration={ 'LocationConstraint': my_region })
print('S3 bucket created successfully')
except Exception as e:
print('S3 error: ',e)

無事に成功しましたね!この状態でS3のコンソールを確認するとちゃんとバケットが作成されていました。

データのダウンロード
では次にこのデータをノートブックインスタンスにダウンロードしてプログラムで扱えるようにデータフレームという箱に入れます。
このプログラムを張り付け、「▶Run」をクリックしてください。
try:
urllib.request.urlretrieve ("https://d1.awsstatic.com/tmt/build-train-deploy-machine-learning-model-sagemaker/bank_clean.27f01fbbdf43271788427f3682996ae29ceca05d.csv", "bank_clean.csv")
print('Success: downloaded bank_clean.csv.')
except Exception as e:
print('Data load error: ',e)
try:
model_data = pd.read_csv('./bank_clean.csv',index_col=0)
print('Success: Data loaded into dataframe.')
except Exception as e:
print('Data load error: ',e)

無事に成功しましたね!調子アガって来たのでこのままいきます。
データの加工
最後にデータの準備としてデータのシャッフルを行い、トレーニング用データとテストデータに分割します。
このプログラムを張り付け、「▶Run」をクリックしてください。
train_data, test_data = np.split(model_data.sample(frac=1, random_state=1729), [int(0.7 * len(model_data))])
print(train_data.shape, test_data.shape)

少し分かりにくいですが、左がトレーニング用のデータ件数、右がテスト用のデータ件数になります。ちなみに61というのは項目(列の)数です。
これで無事にデータの準備が完了しました。

③モデル設定
この手順では初期設定とモデル設定を行っていきます。
初期設定
XGBoostアルゴリズムを利用するためにトレーニングデータの予測項目を設定します。
このプログラムを張り付け、「▶Run」をクリックしてください。
pd.concat([train_data['y_yes'], train_data.drop(['y_no', 'y_yes'], axis=1)], axis=1).to_csv('train.csv', index=False, header=False)
boto3.Session().resource('s3').Bucket(bucket_name).Object(os.path.join(prefix, 'train/train.csv')).upload_file('train.csv')
s3_input_train = sagemaker.inputs.TrainingInput(s3_data='s3://{}/{}/train'.format(bucket_name, prefix), content_type='csv')

こちらもエラー(というかなにも)出ていないので次の手順に行きます。
強いて言えば青枠のところが「*」(処理中)でないことを確認してください。
モデル設定
いよいよモデル設定です。ここではモデルとしてインスタンスとハイパーパラメータの設定を行います。
え、またインスタンス作るの?と思ったそこのアナタ!良いセンスしてますね。
実はこのチュートリアルではインスタンスは3種類出てきます。最後にまとめたいと思うので、一旦先に進めていきましょう。
では、このプログラムを張り付け、「▶Run」をクリックしてください。
sess = sagemaker.Session()
xgb = sagemaker.estimator.Estimator(xgboost_container,role, instance_count=1, instance_type='ml.m4.xlarge',output_path='s3://{}/{}/output'.format(bucket_name, prefix),sagemaker_session=sess)
xgb.set_hyperparameters(max_depth=5,eta=0.2,gamma=4,min_child_weight=6,subsample=0.8,silent=0,objective='binary:logistic',num_round=100)

ここも設定だけなので素早くかつ迅速に終わると思います。
これでモデルの設定が完了しました。

④トレーニング
この手順ではモデルのトレーニングを行っていきます。
トレーニングジョブの実行
トレーニングジョブの実行をしますが、ここまでで必要な準備は全て終わっているので、たった1行のプログラムだけです。
でも実行して頂くと分かると思いますが、この1行の実行で数分かかります、筆者ではだいたい3分ちょっとかかりました。
では、このプログラムを張り付け、「▶Run」をクリックしてください。
xgb.fit({'train': s3_input_train})

これでモデルのトレーニングが完了しました。

⑤デプロイ&予測実行
この手順ではトレーニングしたモデルのデプロイといよいよテストデータを使った予測やっていきます。
モデルのデプロイ
トレーニングしたモデルを実際に予測に利用できるようにデプロイします、具体的には別にインスタンスを設定していきます。
このプログラムを張り付け、「▶Run」をクリックしてください。
xgb_predictor = xgb.deploy(initial_instance_count=1,instance_type='ml.m4.xlarge')

こちらも地味に3分程かかりますが、冷静に完了を待ちましょう。
予測実行
さて、いよいよデプロイしたモデルを使って実際に予測を行っていきます。
ここではあとで結果確認の時に削る前のデータとモデルが予測したデータで比較に利用するために
3行目の「test_data_array = ~~~」の部分でテストデータから答えの列を削ってからモデルに入力しています。
このプログラムを張り付け、「▶Run」をクリックしてください。
from sagemaker.serializers import CSVSerializer
test_data_array = test_data.drop(['y_no', 'y_yes'], axis=1).values #load the data into an array
xgb_predictor.serializer = CSVSerializer() # set the serializer type
predictions = xgb_predictor.predict(test_data_array).decode('utf-8') # predict!
predictions_array = np.fromstring(predictions[1:], sep=',') # and turn the prediction into an array
print(predictions_array.shape)

「いよいよ」なんて書いたのに一瞬で処理が完了しました。優秀ですね。(たぶんチガウ
これで予測実行まで完了しました。

⑥性能評価
チュートリアルも大詰めです、前の手順で予測した結果の性能評価を行います。
性能評価と言われるとなんだか難しく思うかも知れませんが、予測結果と実際の結果を突き合わせて答え合わせしていきます。
性能評価の実行
具体的な答え合わせのやり方ですが、「混同行列」という指標を使います。
「混同行列」ってなにという人も多いかも知れませんが、簡単にいうと「yes」、「no」のように2択の予測を「2値分類」と言って、
「yes」のデータをどれだけ、「yes」と予測できたか、また「no」のデータをどれだけ、「no」と予測できたかを表します。
図解するとこんな感じ。

もっと詳しく!という方は先人の知恵をご参照ください。
さて、なんとなくご理解頂いたところで実際にやってみましょう!
このプログラムを張り付け、「▶Run」をクリックしてください。
cm = pd.crosstab(index=test_data['y_yes'], columns=np.round(predictions_array), rownames=['Observed'], colnames=['Predicted'])
tn = cm.iloc[0,0]; fn = cm.iloc[1,0]; tp = cm.iloc[1,1]; fp = cm.iloc[0,1]; p = (tp+tn)/(tp+tn+fp+fn)*100
print("\n{0:<20}{1:<4.1f}%\n".format("Overall Classification Rate: ", p))
print("{0:<15}{1:<15}{2:>8}".format("Predicted", "No Purchase", "Purchase"))
print("Observed")
print("{0:<15}{1:<2.0f}% ({2:<}){3:>6.0f}% ({4:<})".format("No Purchase", tn/(tn+fn)*100,tn, fp/(tp+fp)*100, fp))
print("{0:<16}{1:<1.0f}% ({2:<}){3:>7.0f}% ({4:<}) \n".format("Purchase", fn/(tn+fn)*100,fn, tp/(tp+fp)*100, tp))
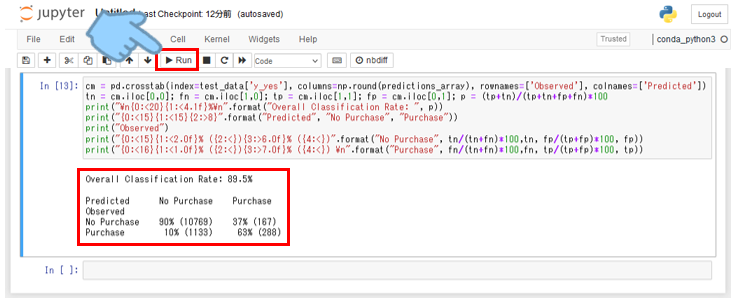

今回の予測モデルの性能としては89.5点ということですね。
チュートリアルと比べて、細かい件数などの違いはあれど、もう少し結果に違いが出ると思っていたので個人的には少し意外でした。
兎にも角にもこれで性能評価まで終わりました。

⑦後始末
無事に予測を体験できたところで、名残惜しいですが、これまで作成してきたものの削除を行っていきます。
デプロイモデルの削除
このプログラムを張り付け、「▶Run」をクリックしてください。
xgb_predictor.delete_endpoint(delete_endpoint_config=True)

トレーニングモデルとS3バケットの削除
このプログラムを張り付け、「▶Run」をクリックしてください。
bucket_to_delete = boto3.resource('s3').Bucket(bucket_name)
bucket_to_delete.objects.all().delete()
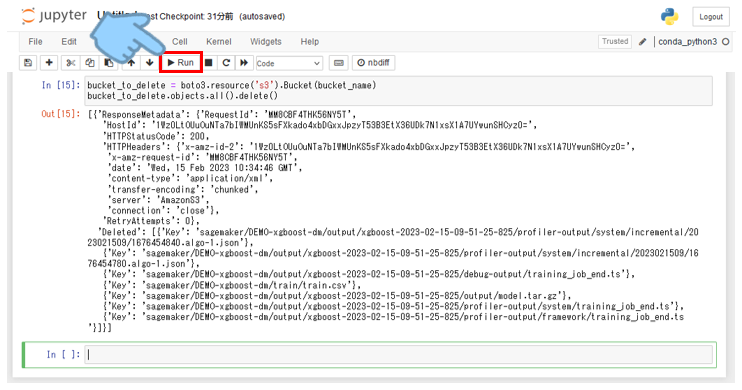

少し補足ですが、このコマンドだけでは作成したフォルダやファイルは削除されますが、バケット本体は削除されません。
※S3は使用したデータサイズに対して課金されるのでバケットが残っていても害はありません。
ノートブックインスタンスの削除
最後にこれまでお世話になったノートブックインスタンスを削除していきます。
インスタスが起動(黄色枠のステータスが「InService」)中だと削除することが出来ないので、
画面左側の丸ポッチをクリックしてから「アクション」>「停止」とクリックしてください。

しばらくすると「Stopping」から「Stopped」に変わったら先ほどと同じように丸ポッチからの「アクション」をクリックして、今度は「削除」をクリックしてください。

途中、脅しが入りますが、気にせずに「削除」をクリックしてください。
はい、これでリストからも削除され無事にインスタンスの削除が完了しました。

ここまででチュートリアルは完了となります。

おまけ
途中でインスタンスが複数出てくるという話をしたかと思いますが、
振り返ってみると以下がインスタンスとして登場してきます。
・ノートブックインスタンス
・トレーニングジョブ実行
・モデルデプロイ
ではこの3つがどのような関係なのかを整理しておきたいと思います。

・・・なんだか図解する必要あるのか・・・?という感じになってしまいましたが、
ノートブックインスタンスは指示する監督のような役割で
色々な状況を想定したトレーニングを実行する選手、監督のお眼鏡にかなって試合に采配され試合で活躍する選手といった感じでしょうか。
え?分かりにくい?すみません、、、今後にご期待ください。。
こちらのデプロイ方法については活用シーンに応じて色々なデプロイ方法があるのでまた別の機会に学んでいきたいと思います。
おわりに
ここまでお読みいただきありがとうございました。
いかがでしたでしょうか。
なるべく嚙み砕いて書いたつもりですが、プログラムなどに触れたことがない方にはまだまだ難易度が高いかも知れません。
次なにやるかまだ悩み中ですが、次回もよろしくお願いいたします!
データ活用をサクッと始めるなら!
株式会社ジールでは、「ITリテラシーがない」「初期費用がかけられない」「親切・丁寧な支援がほしい」「ノーコード・ローコードがよい」「運用・保守の手間をかけられない」などのお客様の声を受けて、オールインワン型データ活用プラットフォーム「ZEUSCloud」を月額利用料にてご提供しております。
ご興味がある方は是非下記のリンクをご覧ください: