はじめに
こんにちは、株式会社ジールの@Suguru-Terouchiです。
さて、前回お正月明けで少しお茶を濁す形にしてしまいましたが、
今回からいよいよ実践に入っていきたいと思います。
これまで基礎的な知識要素について書いてきましたが、人によってはここから難易度が上がってきます。
どれくらい上がるかというとサルからチンパンジーくらいになりそうです。
さっきまで頭にバナナ乗っけて喜んでたヤツが道具を使いだすレベルです。

はい、冗談はさておき本題に入っていきます、実践編の第一弾としてなにやるか色々迷いましたが、
SageMakerのチュートリアルで実況と解説をやっていきたいと思います。
よろしくお願いいたします。
10分でできるチュートリアル
その噂のチュートリアルがこちらです。
・・・お分かり頂けただろうか、聡明な読者の皆様ならもうお気づきかも知れませんが、
対象者が「デベロッパー」になっています。きっとこんな人です(多分チガウ)。

そうです、このチュートリアルではプログラミング要素が出てきます。
概要
はい、では、まずタイトルからですね。
Amazon SageMaker を使用して機械学習モデルを構築、トレーニング、デプロイ

なんと、タイトルからして既にデベロッパー向けな香りがプンプンしますね。
慌てず騒がず落ち着いて、一つ一つ解説していきましょう。
Amazon SageMaker ・・・ AWSのサービスの一つで、こちらにある通り、今回の用途に最適なサービスです。
機械学習モデル ・・・ 一言でいうとプログラムです。今回はXGBoost ML アルゴリズムというものを使います。手法は「教師あり学習」になります。
トレーニング ・・・ ここは分かりますね、データをINPUTして学習することを指します!
デプロイ ・・・ これは簡単にいうと学習した機械学習モデルを使える状態にすることです。
なんとなくイメージ出来そうでしょうか?言葉だけでは動きのイメージが難しいので図解したものも添えておきます。
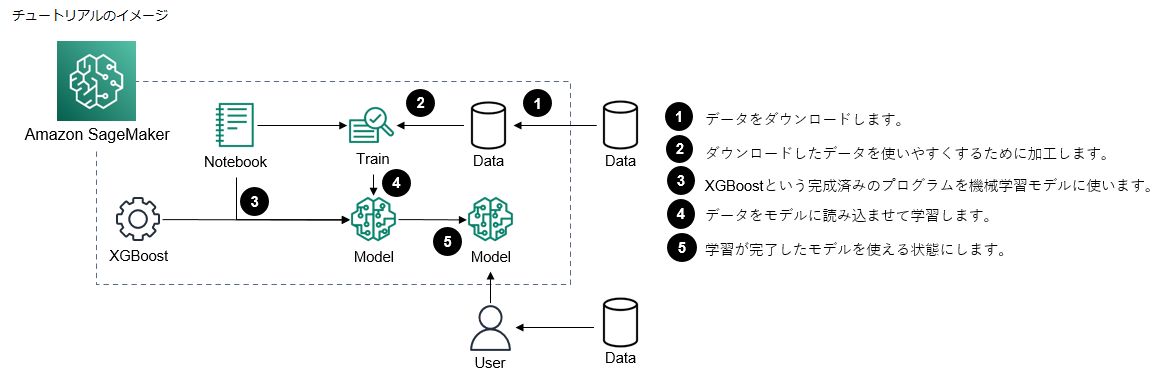
ストーリー
次にチュートリアルのストーリーですが、以下の通りになっています。
お客様は銀行で働く機械学習のデベロッパーという設定で進んでいきます。お客様は、顧客が預金証書 (CD) の申し込みを行うかどうかを予測するための機械学習モデルを開発するように求められました。
まず、預金証書 (CD) というのがイメージ沸かないですが、申し込みを行うかどうかを予測とあるので、
どのような人(性別?年齢?・・・etc)が申し込み(有/無)をするのかを予測しましょうということですかね。

手順
概要を押えたところでこれから行う手順について見ていきます。(画像はイメージです。)

では、こちらも1つ1つ見ていきましょう。
①環境作成
まず始めにチュートリアルを実行するためのマシンを起動します。
Notebookインスタンスというプログラムが動くパソコンと思って頂ければ良いかと思います。
設定も難しいことはなく、便宜上必要なマシン名(基本は好きな名前でOK)と
スペック(CPUやメモリといった性能)を選択すれば残りはデフォルト設定でOKです。
②データ準備
今回、使用するデータの準備として以下のことを行います。奇跡的にイメージ通りですね!(ドヤァ
・データのダウンロード
・データのシャッフル
・データの分割(トレーニング用データ、評価用データ)
ちなみに実際にダウンロードしたデータはこんな感じになっています。

=======
出典:[Moro et al., 2014] S. Moro, P. Cortez and P. Rita. 銀行テレマーケティングの成功を予測するためのデータ駆動型アプローチ。
意思決定支援システム、エルゼビア、62:22-31、2014 年 6 月
https://archive.ics.uci.edu/ml/datasets/bank+marketing
③モデル設定
こちらは概要でも説明したモデルの設定です。
事前に用意されたXGBoostアルゴリズムを使用するために必要な各種設定とハイパーパラメータ(※)なるものを設定します。
※機械学習アルゴリズムの挙動を設定する値のこと、これにより結果(予測精度)にも影響します。
④トレーニング
②データ準備の手順で作成したトレーニング用データを使ってモデルをトレーニングします。
具体的にはトレーニング用データをINPUTとしたトレーニングジョブというものを実行します。
⑤デプロイ&予測実行
先に予測実行の方ですが、こちらは②データ準備の手順で作成したテストデータを使って予測を行うことを指します。
またデプロイについてですが、こちらは中々に奥が深くて、用途や必要な実行頻度、コストなど様々な要素を考慮して決定する必要があります。
このチュートリアルでは「リアルタイム推論」というデプロイ方法が使われています。
こちらはまた別の機会に触れたいと思います。
⑥性能評価
こちらは簡単にいうとテストの採点ですね、予測した結果と実際のデータを比較して
予測結果がどれだけ正しかったのかを見ることでモデルの性能を確認する手順になります。
⑦後始末
こちらはチュートリアルで作成したマシン等を削除する手順です。
チュートリアルで作成するものはAWS無料利用枠という気軽にお試し可能なサービスになっていますが、
起動したまま放置しているといずれ無料利用枠を使い切り課金が発生してしまいますので、忘れずに行いましょう。
概要と手順の説明でかなりのボリュームになってしまったので、
チュートリアルを実施している様子は、また次回にさせてください。
おわりに
いかがでしたでしょうか。
これまで知識として学んできたことの実践に入ってきました。
難易度の高低差あり過ぎて耳がキーンとなっている方もいるかも知れないですが、
なるべくそうならないように順を追って説明していきますので、次回もよろしくお願いいたします!
データ活用をサクッと始めるなら!
株式会社ジールでは、「ITリテラシーがない」「初期費用がかけられない」「親切・丁寧な支援がほしい」「ノーコード・ローコードがよい」「運用・保守の手間をかけられない」などのお客様の声を受けて、オールインワン型データ活用プラットフォーム「ZEUSCloud」を月額利用料にてご提供しております。
ご興味がある方は是非下記のリンクをご覧ください: