はじめに
TROCCOのSelf-Hosted Runnerは、TROCCOのデータ転送をユーザー管理の処理環境で実行できる機能です。SaaSとしてのTROCCOの使いやすさを活かしつつ、実データを閉域内に留めることで、エンタープライズ企業で要求されるセキュアなデータ転送を簡易に実現することができます。
Docker(Linux環境)があれば利用できるので、運用構成としては様々な形が想定されますが、本記事では基本となる考え方や構成検討時の注意点をまとめています。
本記事で記載しているTROCCOおよび外部サービスの仕様は、2025/10/13現在のものです。アップデートに伴い、仕様が変更される可能性があります。
こんな方におすすめ
- TROCCOのSelf-Hosted Runnerの運用構成を検討している方
- 利用を検討するにあたり利用時の運用コストを理解したい方
- GitHubにて、AWS、Azure、Google Cloud、Oracle Cloud Infrastructure、docker-composeにおける最小限の実装例を公開しています。ひとまず動作確認してみたい場合はぜひご利用ください。
- またもう少し踏み込んだ全体構成について、Google Cloudを例にした実装例も公開しています。考え方としては他のクラウドプラットフォームでも利用できると思うので、参考にしてみてください。
前提知識の整理
Self-Hosted Runnerは、オンプレミスを含めた任意の環境で利用が可能ですが、例えばAWS環境を例にすると以下のような形で動作させることができ、
- 通信をRunnerからのアウトバウンド通信のみに限定
- 自己管理のネットワーク環境内で実データの転送を実現
させることができます。
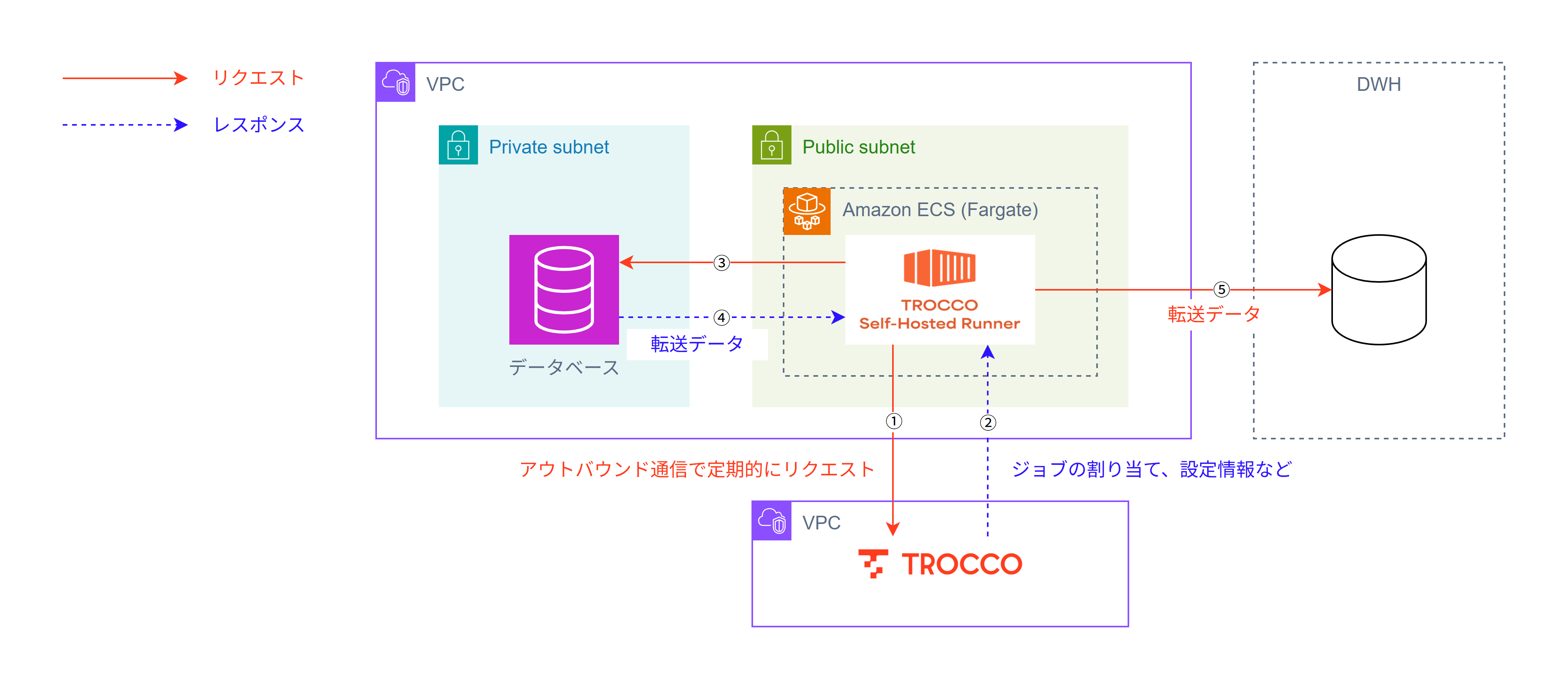
まずは、運用構成を考えるにあたってのポイントを掴んでおきましょう。
Self-Hosted Runnerの基本仕様
設定はSaaSで、データ転送はRunnerでという仕組みになっているので、SaaS側でRunnerを管理する必要があります。このとき、"Cluster"というRunner管理のまとまりがあり、個々のRunnerは"Registration Token"をもとにClusterへの紐づきが管理されます。
RunnerとTROCCO(SaaS)にはRunnerからのアウトバウンド通信しか行わないため、定期的にRunnerからTROCCO(SaaS)にHeartbeatを送り、そこからデータ転送のための処理を行っていきます。処理の流れは以下の通りです。
このように、Self-Hosted RunnerはRunner主導で動いていくような設計になっているため、Runnerへのインバウンド通信は不要であり、Runnerで問題が発生した場合は自律的にエラーを起こすようになっています。
したがって、Runner自体の動作は利用者側で細かく気にする必要はありません。一方で、Runnerが動くコンテナやその周辺環境の管理をどうするかというのが検討の観点となります。
なお、ジョブに対するRunnerの割り当ては、そのタイミングでIDLE状態(=SaaS側で存在が確認されているが、ジョブを実行していない)のものから選ばれるようになっており、同一のClusterに所属するRunnerを複数同時に立ち上げておくことが可能です(=Runnerの数だけ並列処理が可能)。
その他、詳細な仕様については公式ドキュメントをご確認ください。
TROCCO(SaaS)+踏み台サーバ、TROCCO(SaaS)+AWS PrivateLinkとの比較
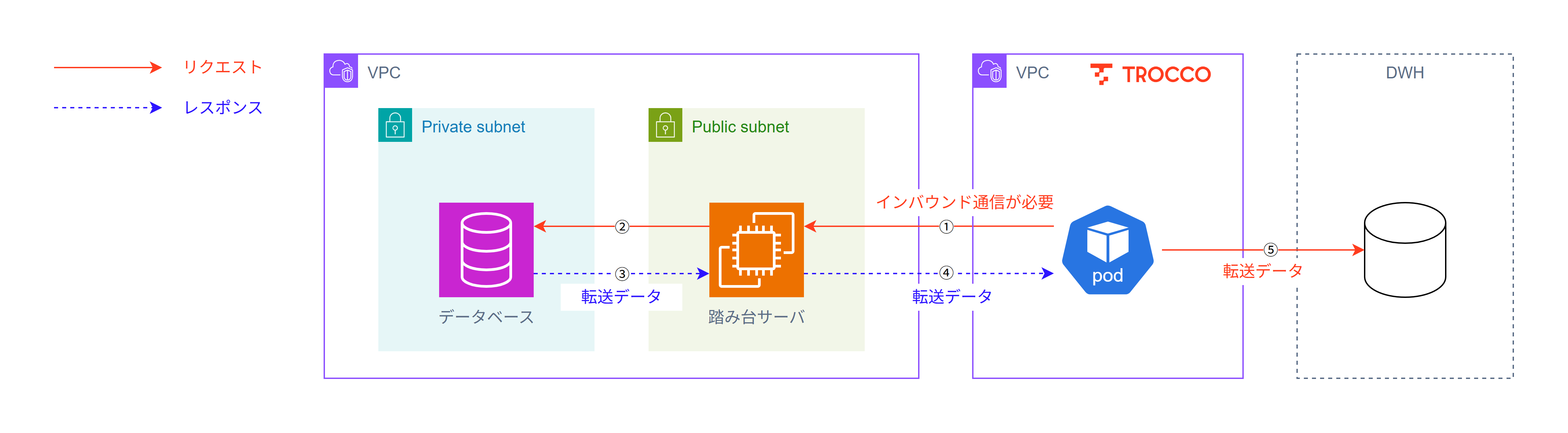
セキュアな通信をしていきたいとき、組織のセキュリティポリシーのレベルによってはSelf-Hosted Runnerでなくとも対応可能です。TROCCO(SaaS)+踏み台サーバ、TROCCO(SaaS)+AWS PrivateLinkで一定の要件を満たせることがあります。
TROCCO(SaaS)で、例えば直接データベースへのアクセスを許可せずに、踏み台サーバ経由での接続をする場合の構成は、以下のような形になります。
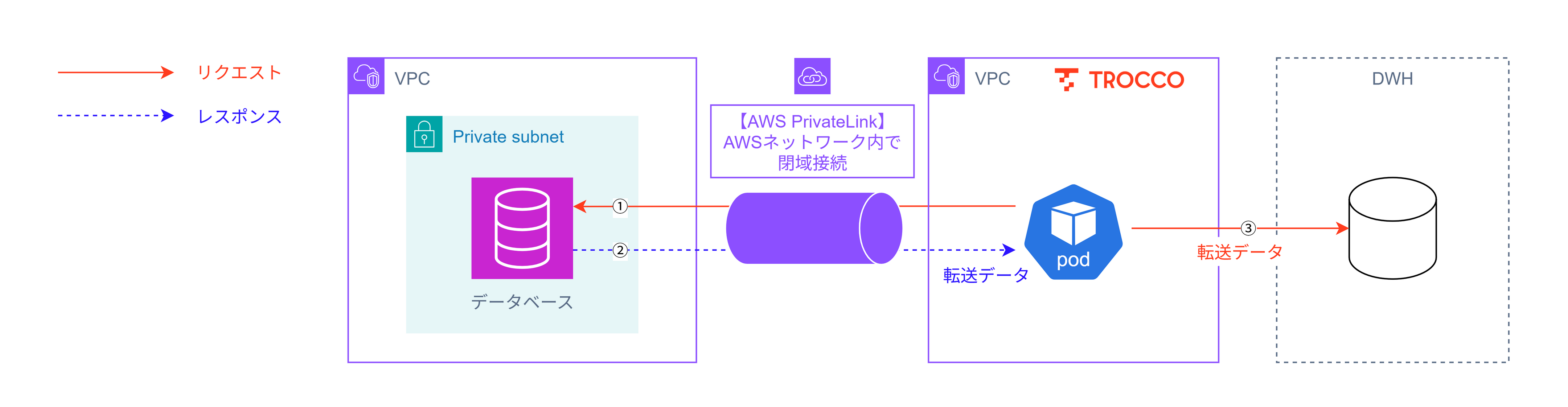
また、TROCCOはAWS環境上で動作しているSaaSなので、セキュアな通信オプションとしてAWS PrivateLinkでの接続を提供しています。その際は以下のような構成になります。
Self-Hosted Runnerとの比較は以下のようになります。
| 項目 | Self-Hosted Runner | TROCCO(SaaS)+踏み台サーバ | TROCCO(SaaS)+PrivateLink |
|---|---|---|---|
| 利用の前提 | Docker(Linux環境) | 踏み台サーバ | AWS経由での通信 *1 AWS PrivateLinkのネットワーク構築 |
| TROCCO(SaaS)の経由 | しない | する *2 | する *2 |
| データの経路 | 閉域内(自己管理下) | インターネット経由 *3 | 閉域内(AWS) |
| 通信の方向 | Runnerからのアウトバウンド | TROCCO(SaaS)からのインバウンド | TROCCO(SaaS)からのインバウンド |
- *1: TROCCO(SaaS) - AWS PrivateLink - AWS環境 - オンプレミスという形でオンプレミス環境に閉域で接続することも可能
- *2: TROCCO(SaaS)はデータ転送時に一時的にコンテナを立ち上げ、転送完了後に破棄するので、データの保持は転送実行時のみ
- *3: アクセスが間接的であるのに加えて、基本的に踏み台サーバへの接続はIP制限をかけるので、一定のセキュリティは担保できる
ということで、以下の3点をもとに使い分けを判断するといいでしょう。
- 一時的にせよTROCCO(SaaS)の環境を経由することを許容できるか
- インターネット経由でのデータの転送を許容できるか
- インバウンド通信を許容できるか
運用構成の検討ポイント
では、ここまでのSelf-Hosted Runnerの基本を踏まえつつ、運用構成の検討ポイントを整理していきます。
コンテナの管理
まず、Runnerが稼働するコンテナ環境の管理としては、以下のようなことが考えられます。
| 項目 | 内容 |
|---|---|
| 死活監視 | Runnerが予期せず停止していないか |
| 自動再起動 | Runnerが停止した際に、再起動して正常運用に戻るか |
| リソース監視 | CPU/メモリ等のパフォーマンスが十分か |
| ログ管理 | 実行ログが連携/保持されているか |
| ネットワーク監視 | Runnerからの通信が適切に制御/監視されているか |
どれをどこまでやるかは個々のセキュリティポリシーによるので、自身の組織でのポリシーを元に検討してください。
コンテナの設置環境
コンテナの設置環境としては、クラウドのマネージドコンテナサービス/コンテナオーケストレーションサービスや、Linux VM/Linuxサーバ上でコンテナを運用することが考えられます。このとき、ユーザー側の運用対象は以下のように整理できます。

このとき、前述のコンテナ管理の観点を踏まえると、運用負荷が最小化されるためクラウドのマネージドコンテナサービス/コンテナオーケストレーションサービスが推奨環境になります。それぞれの設置環境のメリット/デメリットは以下の通りです。
| 環境 | サービス/ツール | サービス/ツール例 | メリット | デメリット |
|---|---|---|---|---|
| クラウド (マネージド) |
コンテナサービス | ECS Fargate/Cloud Run/Azure Container Appsなど | ・死活監視、自動再起動、リソース監視、ログ管理、ネットワーク管理まで自動化または簡素化可能 | ・マネージドな分コストはかかる |
| クラウド (マネージド) |
コンテナオーケストレーションサービス | EKS/GKE/AKSなど | ・上に加えて細かい調整が柔軟に可能 | ・上に加えてオーケストレーションサービス自体の運用コストがかかる |
| Linux サーバ or Linux VM |
docker-compose | - | ・死活監視と自動再起動は可能 ・サーバ/VM単位でリソース調整が可能 |
・コンテナ管理に一定の工夫が必要になる ・サーバ/VM自体/コンテナプロセスの管理も必要になる |
| Linux サーバ or Linux VM |
コンテナオーケストレーションサービス | Kubernetesなど | ・上に加えて細かい調整が柔軟に可能 | ・上に加えてオーケストレーションサービス自体の運用コストがかかる |
このうち、docker-composeでの構成例については、「docker-composeでTROCCOのSelf-Hosted Runnerを動かす構成例」にまとめているので、そちらをご参考ください。
なお、例えばオンプレミス環境のデータベース等からクラウドデータウェアハウスにデータを転送したい場合、コンテナの設置場所としてはオンプレミス環境と移行先クラウド環境のどちらも候補になります。
とはいえ、
- 運用管理コストを最小化する
- 将来的なクラウド化を考えたときに、改めての環境構築が不要になる
という観点から、やはりクラウド環境でのマネージドサービスを最初の候補にするとよいでしょう。
コンテナのコストコントロール
コンテナの設置環境としては色々なものが考えられますが、この場としてはクラウドコンテナサービスを想定して整理していきます。このとき、コンテナのコストの基本は、コンテナのリソースと起動時間になります。
リソース
コンテナのリソースについては、個々の転送内容に依存してくるものなので、
- メモリ: 2GB以上
- CPU: 特に推奨値はないが、コア数を増やすと並列実行によりパフォーマンスが上がることがある
というのをベースにしつつ、検証しながら進めてください。
前述したように、Clusterを別に分けることで、転送設定によって通常のリソース/増強されたリソースを使い分けることができます。
起動時間
コンテナサービス自体のコストもありますが、運用コストという観点もあるので、まずはシンプルにコンテナを立ち上げ続けるというのが1つの選択肢となるでしょう。
最低限のリソースで1か月立ち上げ続けると、1つのRunnerあたり1~2万円程度の費用となります。
このコストが許容できない場合は、2つ方法があります。具体の実装例については、Google Cloud環境にはなりますが、下部の説明およびコードを参考にしてください。
なお、データ転送処理に問題が出てきてしまうので、
- ジョブを実行中のコンテナを強制停止させる
- ジョブのスケジュール前後で、Runnerが全く存在しない(ジョブはキューイングされるので、前である必要はありません)
のは避けるようにしてください。
スケジュールベースの制御
ジョブを実行するタイミングに偏りがある場合、そのタイミングに合わせて事前にコンテナを起動/事後に停止することで、起動時間を最低限に抑えることができます。以下のような処理の流れになります。
イベントベースの制御
環境変数で設定できる、ジョブ実行後にRunnerが自動停止する機能を利用すると、イベントベースでのコンテナの起動制御を行うことができます。
コスト効率的には最も優れた形になりますが、例えばエラー発生時にエラー箇所からの再実行を行おうとすると、そのままではジョブを実行するRunnerがない(=別途立てる必要がある)など、運用面での工夫が必要になることにはご注意ください。
自動スケーリング
コンテナサービスでの自動スケーリングの基本は、アクセスの増大に起因するものですが、Runnerにはインバウンドリクエストは発生しないのでこれは利用できません。
コンテナサービス/コンテナオーケストレーションサービスによっては、CPUベースでのスケーリングが可能なので選択肢の1つにはなると思いますが、リソースやワークロードの依存性が大きいので、利用の際には、
- 実行ジョブが増えたタイミングで適切にスケールアウトできるか
- 実行ジョブが減ったタイミングで、かつ実行中のジョブを強制停止させずにスケールインできるか
という観点から検証してみてください。
クラウドでの全体構成例
各種コンテナサービスでの最小限の構成については一通り検証しており、以下のサービスのTerraformコードを公開しています。
- AWS / ECS Fargate
- Azure / Container Instances, Container Apps
- Google Cloud / Cloud Run Worker Pools, Cloud Run Service, Cloud Run Jobs
- Oracle Cloud Infrastructure / Container Instances
コードとしてはTerraformになりますが、あくまで設定項目をコード化しただけなので、Terraformについて詳しくない方もご参考いただけると思います。
さて、この場では、Google Cloud環境での全体構成を紹介します。Oracle Cloud Infrastructureは不明ですが、おそらくAWS/Azureでも似たような構成を取れるのではないかと思うので、参考にしていただければと思います。
構成概要
Google Cloudのプライベートで管理されているMySQL(Cloud SQL)からCloud Runでデータを取得し、Google Cloudの閉域内でBigQueryにデータを転送するという構成です。
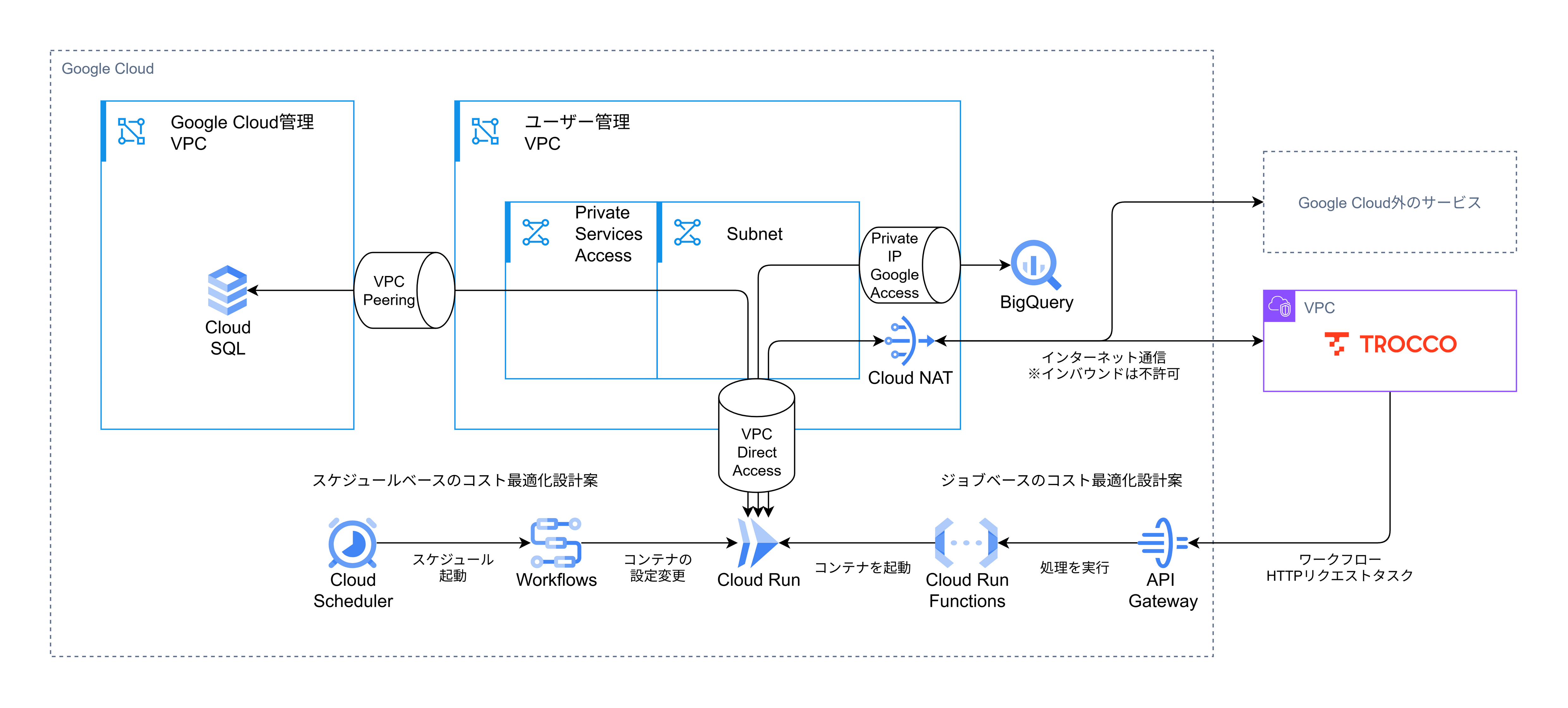
以下では、その設定時のコードを一部抜粋してご紹介します。完全なコードはGitHubをご確認ください。
Runnerを動かせるようにする
まずはRunnerを動かすための最低限の環境構築です。GitHubではCloud Runの3つの種別それぞれのコードを用意していますが、この場ではWorker Poolのみを取り上げます。なお、Google Cloud以外の環境での同等のコードも別途公開しています。
ポイントは以下の通りです。
- Cloud Runはデフォルトでインターネットへの通信ができるようになっているが、通信を統制したいためDirect VPC AccessでVPC経由での通信にしている
- BigQueryとの通信にはVPCからGoogle CloudへのAPIへの通信を許可するPrivate IP Google Accessを利用している
- この設定ではBigQuery以外のサービスへの通信も可能になってしまうので、より厳格な統制が必要な場合はPrivate Service Connectを利用する
- インターネット経由になっていないことは、NATのログを見ることで確認できる
- インターネットへの通信は、NATを通して行われる
- このときの通信をFirewallで制限している
- Google CloudではSelf-Hosted Runnerを公開しているAWS ECRのパブリックリポジトリから直接イメージの取得ができないので、一度Artifact Registryを経由して利用する形になっている
terraform {
required_providers {
google = {
source = "hashicorp/google"
version = "7.3.0"
}
google-beta = {
source = "hashicorp/google-beta"
version = "7.5.0"
}
random = {
source = "hashicorp/random"
version = "3.7.2"
}
local = {
source = "hashicorp/local"
version = "2.5.3"
}
}
}
provider "google" {
project = var.project_id
billing_project = var.project_id
user_project_override = true
region = var.default_location
default_labels = {
tested_by = var.tested_by
}
}
provider "google-beta" {
project = var.project_id
billing_project = var.project_id
user_project_override = true
region = var.default_location
default_labels = {
test_by = var.tested_by
}
}
variable "default_location" {
type = string
description = "デフォルトのロケーション"
}
variable "project_id" {
type = string
description = "Google CloudのProject ID"
}
variable "tested_by" {
type = string
description = "検証担当者"
}
variable "trocco_registration_token" {
type = string
description = "TROCCO Self-Hosted-RunnerのRegistration Token"
sensitive = true
}
variable "trocco_shr_image_path" {
type = string
description = "TROCCO Self-Hosted-RunnerのコンテナイメージPath"
}
# VPC
resource "google_compute_network" "vpc" {
name = "shr-test"
auto_create_subnetworks = false
delete_default_routes_on_create = true
depends_on = [
google_project_service.main
]
}
# サブネット
# ref: https://cloud.google.com/vpc/docs/configure-private-service-connect-apis?hl=ja
resource "google_compute_subnetwork" "subnet" {
name = "shr-test"
region = var.default_location
network = google_compute_network.vpc.id
ip_cidr_range = "10.0.0.0/16"
private_ip_google_access = true # これを設定するとGoogle CloudのプライベートネットワークでBigQueryにアクセスできる; 厳密にはBigQuery以外へのアクセスも可能になるので注意
}
# Internet Gatewayのためののルート
resource "google_compute_route" "internet" {
name = "shr-test-internet"
network = google_compute_network.vpc.id
dest_range = "0.0.0.0/0"
next_hop_gateway = "default-internet-gateway"
priority = 1000
}
# インターネットへのアクセスをNAT経由にルーティング
resource "google_compute_router" "router" {
name = "shr-test"
network = google_compute_network.vpc.id
region = var.default_location
}
# インターネットへのアクセスのためのNAT
resource "google_compute_router_nat" "nat" {
name = "shr-test"
router = google_compute_router.router.name
region = var.default_location
nat_ip_allocate_option = "AUTO_ONLY"
source_subnetwork_ip_ranges_to_nat = "ALL_SUBNETWORKS_ALL_IP_RANGES"
log_config {
enable = true
filter = "ALL"
}
}
# デフォルトですべてのアウトバウンドトラフィックを拒否するファイアウォール
resource "google_compute_firewall" "deny_all_egress" {
name = "shr-test-deny-all-egress"
network = google_compute_network.vpc.name
deny {
protocol = "all"
}
direction = "EGRESS"
destination_ranges = ["0.0.0.0/0"]
priority = 65534 # デフォルトルールより高優先度
log_config {
metadata = "INCLUDE_ALL_METADATA"
}
}
# Cloud Runからインターネットにアクセスするためのファイアウォール
resource "google_compute_firewall" "cloud_run_egress" {
name = "shr-test-cloud-run-egress"
network = google_compute_network.vpc.name
allow {
protocol = "tcp"
ports = ["443"]
}
direction = "EGRESS"
target_service_accounts = [google_service_account.trocco_self_hosted_runner.email]
destination_ranges = ["0.0.0.0/0"]
priority = 1000
log_config {
metadata = "INCLUDE_ALL_METADATA"
}
}
# Cloud Runが利用するサービスアカウント
resource "google_service_account" "trocco_self_hosted_runner" {
project = var.project_id
account_id = "shr-test"
display_name = "TROCCO Self-Hosted Runner"
}
# Self-Hosted RunnerのRegistration TokenをSecret Managerに格納するためのシークレット
resource "google_secret_manager_secret" "trocco_registration_token" {
project = var.project_id
secret_id = "trocco_registration_token"
replication {
auto {}
}
}
# Self-Hosted RunnerのRegistration TokenをSecret Managerに登録
resource "google_secret_manager_secret_version" "trocco_registration_token" {
secret = google_secret_manager_secret.trocco_registration_token.id
secret_data = var.trocco_registration_token
}
# Cloud RunがSecret Managerのシークレットを参照できるようにする権限を付与
resource "google_secret_manager_secret_iam_member" "trocco_registration_token" {
project = var.project_id
secret_id = google_secret_manager_secret.trocco_registration_token.secret_id
role = "roles/secretmanager.secretAccessor"
member = google_service_account.trocco_self_hosted_runner.member
}
# TROCCOのSelf-Hosted Runner用のDockerイメージを格納するリポジトリ
resource "google_artifact_registry_repository" "trocco_self_hosted_runner" {
repository_id = "shr-test"
description = "TROCCOのSelf-Hosted Runner用のDockerイメージを格納するリポジトリ"
project = var.project_id
location = var.default_location
format = "DOCKER"
mode = "REMOTE_REPOSITORY"
remote_repository_config {
common_repository {
uri = "https://public.ecr.aws"
}
}
}
# Cloud RunがArtifact Registryのイメージをpullできるようにする権限を付与
resource "google_project_iam_member" "trocco__artifact_registry_reader" {
project = var.project_id
role = "roles/artifactregistry.reader"
member = google_service_account.trocco_self_hosted_runner.member
}
/*
- Cloud Run Worker Poolsの設定
- 定常起動しておくにはこの種別が最適だが、2025/10/13現在でGAのステータスではない
*/
# TROCCOのSelf-Hosted RunnerをCloud Run Worker Poolsにデプロイ
resource "google_cloud_run_v2_worker_pool" "trocco_self_hosted_runner" {
name = "shr-test-worker-pool"
project = var.project_id
location = var.default_location
scaling {
manual_instance_count = 0
}
template {
containers {
# この設定で自動的にImageはPullされるので、手動の操作は不要
image = "${google_artifact_registry_repository.trocco_self_hosted_runner.location}-docker.pkg.dev/${google_artifact_registry_repository.trocco_self_hosted_runner.project}/${google_artifact_registry_repository.trocco_self_hosted_runner.name}/${var.trocco_shr_image_path}:latest"
name = "trocco-self-hosted-runner"
resources {
limits = {
"memory" = "2Gi"
"cpu" = "2000m"
}
}
env {
name = "TROCCO_PREVIEW_SEND"
value = "true"
}
env {
name = "TROCCO_REGISTRATION_TOKEN"
value_source {
secret_key_ref {
secret = google_secret_manager_secret.trocco_registration_token.secret_id
version = "latest"
}
}
}
}
vpc_access {
egress = "ALL_TRAFFIC"
# ref: https://cloud.google.com/run/docs/configuring/vpc-direct-vpc?hl=ja
network_interfaces {
network = google_compute_network.vpc.name
subnetwork = google_compute_subnetwork.subnet.name
tags = ["trocco-self-hosted-runner-egress"]
}
}
service_account = google_service_account.trocco_self_hosted_runner.email
}
# GA Statusではない
# ref: https://cloud.google.com/run/docs/deploy-worker-pools?hl=ja
# ref: https://cloud.google.com/run/docs/troubleshooting#launch-stage-validation
launch_stage = "BETA"
timeouts {
create = "30m"
}
deletion_protection = false
lifecycle {
create_before_destroy = false
}
depends_on = [
google_secret_manager_secret_iam_member.trocco_registration_token
]
}
検証用のデータベースを設置する
次に、接続先のMySQLを設置するための設定です。
ポイントは以下の通りです。
- Cloud SQLはGoogle Cloud管理のVPCに設置されるので、Private Services Accessを利用して接続する
- VPC Peeringで接続するので、VPC内でIPレンジが重複してはいけない
- 余談ですが、この設定でCloud SQLを直接指定しているところがないのに、IPが振られるのが少し変に思えてしまいます・・・(バックエンドでいい感じにしてくれます)
locals {
google_cloud = {
mysql = {
port = 3306
}
}
}
# DB接続のためのパスワード
resource "random_password" "db_user" {
length = 16
min_lower = 2
min_upper = 2
min_numeric = 2
min_special = 2
}
# 必要なAPIを有効化
resource "google_project_service" "database" {
for_each = toset([
"sqladmin.googleapis.com", # Cloud SQL Admin API
])
project = var.project_id
service = each.value
disable_on_destroy = true
}
# MySQLにアクセスするためのIPアドレス
# ref: https://cloud.google.com/sql/docs/mysql/configure-private-services-access?hl=ja
resource "google_compute_global_address" "mysql" {
name = "shr-test-mysql"
address_type = "INTERNAL"
purpose = "VPC_PEERING"
prefix_length = 16
network = google_compute_network.vpc.id
depends_on = [
google_compute_subnetwork.subnet,
google_project_service.database
]
}
# VPCとCloud SQLを接続するためのVPCピアリング
# ピアリングするVPC間でIPレンジの重複が許容されないことに注意
resource "google_service_networking_connection" "mysql" {
network = google_compute_network.vpc.id
service = "servicenetworking.googleapis.com"
reserved_peering_ranges = [google_compute_global_address.mysql.name]
deletion_policy = "ABANDON"
}
# MySQLインスタンス
resource "google_sql_database_instance" "mysql" {
name = "shr-test-mysql"
database_version = "MYSQL_8_0"
region = var.default_location
settings {
tier = "db-f1-micro"
ip_configuration {
ipv4_enabled = false
private_network = google_compute_network.vpc.id
ssl_mode = "ENCRYPTED_ONLY"
}
}
deletion_protection = false
depends_on = [
google_service_networking_connection.mysql
]
}
# MySQLのデータベース
resource "google_sql_database" "shr_test" {
name = "shr_test"
instance = google_sql_database_instance.mysql.name
}
# MySQLのユーザー
resource "google_sql_user" "shr_test" {
name = "shr_test"
instance = google_sql_database_instance.mysql.name
host = "%"
password = random_password.db_user.result
}
# Cloud RunからCloud SQLにアクセスするためのファイアウォール
resource "google_compute_firewall" "cloud_run_to_cloud_sql" {
name = "shr-test-cloud-run-to-cloud-sql"
network = google_compute_network.vpc.name
allow {
protocol = "tcp"
ports = ["3306"]
}
direction = "EGRESS"
target_service_accounts = [google_service_account.trocco_self_hosted_runner.email]
destination_ranges = ["${google_compute_global_address.mysql.address}/${google_compute_global_address.mysql.prefix_length}"]
priority = 1000
log_config {
metadata = "INCLUDE_ALL_METADATA"
}
}
スケジュールベースのコスト最適化
続いて、スケジュールベースでコスト最適化をするときのサンプル実装です。Cloud Schedulerでスケジュールベースで処理をキックし、Workflowsでコンテナの設定を変更しています。
# WorkflowsからCloud Run Worker Pools/Servicesを調整するためのサービスアカウント
resource "google_service_account" "trocco_self_hosted_runner__container_scheduler" {
project = var.project_id
account_id = "shr-test-scheduler"
display_name = "shr-test-scheduler"
description = "Service Account for Workflows to manage Cloud Run Worker Pools"
depends_on = [
google_project_service.cloud_scheduler__workflows
]
}
# WorkflowsからCloud Run Worker Pools/Servicesを調整するための権限を付与
resource "google_project_iam_member" "trocco_self_hosted_runner__container_scheduler" {
for_each = toset([
"roles/workflows.invoker", # Cloud SchedulerからCloud Workflowsを実行するために必要
"roles/logging.logWriter", # Cloud Workflowsのログ出力に必要
"roles/run.admin", # Cloud Run Worker Pools/Servicesの更新に必要
"roles/iam.serviceAccountUser" # Cloud Runの更新時にサービスアカウントを利用するために必要
])
project = var.project_id
role = each.value
member = google_service_account.trocco_self_hosted_runner__container_scheduler.member
}
/*
- Cloud Run Worker Poolsの場合
*/
# Cloud Run Worker Poolのインスタンス数を調整するためのWorkflow
resource "google_workflows_workflow" "trocco_self_hosted_runner__container_scheduler__worker_pool" {
name = "shr-test-scheduler-worker-pool"
region = var.default_location
description = "Workflow to Manage Cloud Run Worker Pool Instance Count"
service_account = google_service_account.trocco_self_hosted_runner__container_scheduler.email
# ref: https://cloud.google.com/run/docs/reference/rest/v2/projects.locations.workerPools
source_contents = <<-EOT
main:
params: [args]
steps:
- log_start:
call: sys.log
args:
severity: "INFO"
text: "インスタンス調整開始; 対象: ${google_cloud_run_v2_worker_pool.trocco_self_hosted_runner.name}, インスタンス数: $${args.manual_instance_count}"
- update_instance_count:
# Beta APIのため、googleapis.run.v2ではなく、http.patchで直接APIを叩くしかない
# ref: https://cloud.google.com/run/docs/reference/rest/v2/projects.locations.workerPools/patch
call: http.patch
args:
url: "https://run.googleapis.com/v2/${google_cloud_run_v2_worker_pool.trocco_self_hosted_runner.id}"
auth:
type: OAuth2
headers:
Content-Type: "application/json"
query:
updateMask: "scaling.manualInstanceCount"
body:
scaling:
manualInstanceCount: $${args.manual_instance_count}
result: updated_result
- log_success:
call: sys.log
args:
severity: "INFO"
text: "インスタンス調整完了; 対象: ${google_cloud_run_v2_worker_pool.trocco_self_hosted_runner.name}, インスタンス数: $${args.manual_instance_count}"
- return_result:
return:
status: "success"
worker_pool: ${google_cloud_run_v2_worker_pool.trocco_self_hosted_runner.name}
manual_instance_count: $${args.manual_instance_count}
updated_result: $${updated_result}
EOT
deletion_protection = false
}
# Cloud Run Worker Poolsを起動するためのCloud Scheduler
resource "google_cloud_scheduler_job" "trocco_self_hosted_runner__container_scheduler__worker_pool__start" {
name = "shr-test-scheduler-worker-pool-start"
schedule = "0 9 * * *" # これは適当な時間
time_zone = "Asia/Tokyo"
http_target {
uri = "https://workflowexecutions.googleapis.com/v1/projects/${var.project_id}/locations/${var.default_location}/workflows/${google_workflows_workflow.trocco_self_hosted_runner__container_scheduler__worker_pool.name}/executions"
http_method = "POST"
headers = {
"Content-Type" = "application/json"
}
body = base64encode(jsonencode({
argument = jsonencode({
manual_instance_count = 1
})
}))
oauth_token {
service_account_email = google_service_account.trocco_self_hosted_runner__container_scheduler.email
}
}
}
イベントベースのコスト最適化
最後に、イベントベースでコスト最適化をするときにサンプル実装です。
TROCCOのHTTPリクエストタスクでAPI Gatewayで構築したAPIをキックし、そこからCloud Run FunctionsによってCloud Run Jobsのジョブを起動します。APIのキック時はAPIキーとIPベースで制限をかけることで、TROCCOからのみのリクエストを受け付けます。
また、同じAPI GatewayのAPI定義で実行内容の取得も行えるようにすることで、過去の実行状況についてデータを取得しながら、運用を検証/改善することもできそうです。こちらはConnector Builderで接続するコネクタを作成できます。
# Cloud Run FunctionsからCloud Run Jobsを起動するためのサービスアカウント
resource "google_service_account" "trocco_self_hosted_runner__container_manager" {
project = var.project_id
account_id = "shr-test-manager"
display_name = "shr-test-manager"
description = "Service Account for Cloud Run Functions to manage Cloud Run Jobs"
depends_on = [
google_project_service.api_gateway__cloud_run_functions
]
}
# Cloud Run FunctionsからCloud Run Jobsを起動するための権限を付与
resource "google_project_iam_member" "self_hosted_runner__container_manager" {
for_each = toset([
"roles/run.developer", # ジョブ構成をオーバーライドしたCloud Run Jobの実行に必要; ref: https://cloud.google.com/run/docs/execute/jobs
])
project = var.project_id
role = each.value
member = google_service_account.trocco_self_hosted_runner__container_manager.member
}
# Cloud Functionのソースコードをzip化
data "archive_file" "function_source_archive" {
type = "zip"
source_dir = "${path.root}/src"
output_path = "${path.root}/dist/function_source.zip"
}
# GCSバケット名の一意性を担保するためのUUID
resource "random_uuid" "bucket_suffix" {
}
# Cloud Functionのソースコードを格納するためのCloud Storageバケット
resource "google_storage_bucket" "function_source" {
name = "shr-test-function-source-${random_uuid.bucket_suffix.result}"
project = var.project_id
location = var.default_location
force_destroy = true
}
# Cloud FunctionのソースコードをCloud Storageにアップロード
resource "google_storage_bucket_object" "function_source" {
name = "shr-test/function_source.zip"
bucket = google_storage_bucket.function_source.name
source = data.archive_file.function_source_archive.output_path
}
# Cloud Run Worker Poolのインスタンス数を調整するCloud Function
resource "google_cloudfunctions2_function" "trocco_self_hosted_runner__container_manager" {
name = "shr-test-manager"
description = "Cloud Function to Manage Cloud Run Jobs"
project = var.project_id
location = var.default_location
build_config {
runtime = "python311"
entry_point = "cloud_run_jobs_manager_handler"
source {
storage_source {
bucket = google_storage_bucket.function_source.name
object = google_storage_bucket_object.function_source.name
}
}
}
service_config {
available_memory = "128Mi"
min_instance_count = 0
timeout_seconds = 60
service_account_email = google_service_account.trocco_self_hosted_runner__container_manager.email
ingress_settings = "ALLOW_ALL" # API Gatewayからのアクセスを許可するため
all_traffic_on_latest_revision = true
environment_variables = {
CLOUD_RUN_JOB_ID = google_cloud_run_v2_job.trocco_self_hosted_runner.id
}
}
lifecycle {
replace_triggered_by = [
google_storage_bucket_object.function_source
]
}
}
# API GatewayがCloud Functionを呼び出すためのサービスアカウント
resource "google_service_account" "trocco_self_hosted_runner__container_manager_api" {
account_id = "shr-test-manager-api"
display_name = "shr-test-manager-api"
description = "Service Account for API Gateway to invoke Cloud Run Jobs Container Manager Function"
}
# Cloud Functionを呼び出すための権限を付与
resource "google_cloudfunctions2_function_iam_member" "invoker" {
project = var.project_id
location = google_cloudfunctions2_function.trocco_self_hosted_runner__container_manager.location
cloud_function = google_cloudfunctions2_function.trocco_self_hosted_runner__container_manager.name
role = "roles/cloudfunctions.invoker"
member = google_service_account.trocco_self_hosted_runner__container_manager_api.member
}
# API GatewayがCloud Run Functionsを呼び出すための権限を付与
resource "google_project_iam_member" "trocco_self_hosted_runner__container_manager_api" {
for_each = toset([
"roles/run.invoker", # Cloud Run Functionsの呼び出しに必要
])
project = var.project_id
role = each.value
member = google_service_account.trocco_self_hosted_runner__container_manager_api.member
}
# API GatewayのAPI
resource "google_api_gateway_api" "trocco_self_hosted_runner__container_manager_api" {
provider = google-beta
project = var.project_id
api_id = "shr-test-manager-api"
display_name = "shr-test-manager-api"
depends_on = [
google_cloudfunctions2_function.trocco_self_hosted_runner__container_manager
]
}
# API GatewayのGateway
resource "google_api_gateway_gateway" "trocco_self_hosted_runner__container_manager_api" {
provider = google-beta
project = var.project_id
gateway_id = google_api_gateway_api.trocco_self_hosted_runner__container_manager_api.api_id
display_name = google_api_gateway_api.trocco_self_hosted_runner__container_manager_api.display_name
api_config = google_api_gateway_api_config.trocco_self_hosted_runner__container_manager_api.id
lifecycle {
replace_triggered_by = [
google_api_gateway_api_config.trocco_self_hosted_runner__container_manager_api
]
}
}
# API GatewayのAPI Config
# ref: https://cloud.google.com/api-gateway/docs/passing-data?hl=ja
resource "google_api_gateway_api_config" "trocco_self_hosted_runner__container_manager_api" {
provider = google-beta
project = var.project_id
api_config_id = "shr-test-manager-config"
display_name = "shr-test-manager-config"
api = google_api_gateway_api.trocco_self_hosted_runner__container_manager_api.api_id
openapi_documents {
document {
path = "openapi.yaml"
contents = base64encode((<<-EOT
swagger: "2.0"
info:
title: "Cloud Run Jobs Container Manager API"
version: "1.0.0"
schemes:
- "https"
produces:
- "application/json"
security:
- api_key: []
securityDefinitions:
api_key:
type: "apiKey"
name: "x-api-key"
in: "header"
x-google-backend:
address: "${google_cloudfunctions2_function.trocco_self_hosted_runner__container_manager.service_config[0].uri}"
jwt_audience: "${google_cloudfunctions2_function.trocco_self_hosted_runner__container_manager.service_config[0].uri}"
protocol: "h2"
path_translation: APPEND_PATH_TO_ADDRESS
paths:
/run: # ref: https://cloud.google.com/run/docs/reference/rest/v2/projects.locations.jobs/run
post:
summary: "Run Cloud Run Job"
operationId: "RunCloudRunJob"
parameters:
- in: body
name: body
schema:
type: object
properties:
trocco_pipeline_definition_id:
type: integer
description: "TROCCO Pipeline Definition ID"
task_count:
type: integer
description: "Number of tasks to run"
default: 1
task_execution_mode:
type: string
enum:
- single_job
- multi_job
default: single_job
description: "Task Execution Mode"
responses:
200:
description: "Success"
400:
description: "Bad Request"
401:
description: "Unauthorized"
500:
description: "Internal Server Error"
/executions/list: # ref: https://cloud.google.com/run/docs/reference/rest/v2/projects.locations.jobs.executions/list
get:
summary: "List Available Cloud Run Job Executions"
operationId: "listCloudRunJobExecutions"
parameters:
- in: query
name: page_size
type: integer
description: "Page size"
- in: query
name: page_token
type: string
description: "Page token"
- in: query
name: show_deleted
type: boolean
description: "Whether to show deleted executions"
default: false
responses:
200:
description: "Success"
400:
description: "Bad Request"
401:
description: "Unauthorized"
500:
description: "Internal Server Error"
/executions/{execution_id}/tasks/list: # ref: https://cloud.google.com/run/docs/reference/rest/v2/projects.locations.jobs.executions.tasks/list
get:
summary: "List Available Cloud Run Job Execution Tasks"
operationId: "listCloudRunJobExecutionTasks"
parameters:
- in: path
name: execution_id
required: true
type: string
description: "Cloud Run Job Execution ID"
- in: query
name: page_size
type: integer
description: "Page size"
- in: query
name: page_token
type: string
description: "Page token"
- in: query
name: show_deleted
type: boolean
description: "Whether to show deleted executions"
default: false
responses:
200:
description: "Success"
400:
description: "Bad Request"
401:
description: "Unauthorized"
500:
description: "Internal Server Error"
EOT
))
}
}
gateway_config {
backend_config {
google_service_account = google_service_account.trocco_self_hosted_runner__container_manager.email
}
}
lifecycle {
create_before_destroy = false
}
}
# API Gatewayのサービスを有効化
# 有効化には多少の時間がかかるので、applyは失敗することがある
resource "google_project_service" "api_gateway" {
project = var.project_id
service = google_api_gateway_api.trocco_self_hosted_runner__container_manager_api.managed_service
disable_on_destroy = true
}
# 実運用に使うことを想定した、IPベースでTROCCOからのアクセスのみに限定したAPIキー
resource "google_apikeys_key" "api_key_restricted" {
name = "shr-test-api-key-restricted-${formatdate("YYYYMMDD-hhmmss", timeadd(timestamp(), "9h"))}"
display_name = "shr-test-api-key-restricted-${formatdate("YYYYMMDD-hhmmss", timeadd(timestamp(), "9h"))}"
project = var.project_id
restrictions {
api_targets {
service = google_api_gateway_api.trocco_self_hosted_runner__container_manager_api.managed_service
}
server_key_restrictions {
allowed_ips = [ # ref: https://documents.trocco.io/docs/global-ip-list
"18.182.232.211",
"13.231.52.164",
"3.113.216.138",
"57.181.137.181",
"54.250.45.100",
]
}
}
lifecycle {
ignore_changes = [
name,
display_name,
]
replace_triggered_by = [
google_project_service.api_gateway
]
}
}
Cloud Run Functionsのコード(クリックして開く)
import os
import json
import re
import logging
import functions_framework
import google.auth
from google.auth.transport.requests import AuthorizedSession
from google.cloud import logging as cloud_logging
CLOUD_RUN_JOB_ID = os.environ.get("CLOUD_RUN_JOB_ID")
cloud_logging_client = cloud_logging.Client()
cloud_logging_client.setup_logging()
logger = logging.getLogger(__name__)
def run_cloud_run_job(request):
"""
Cloud FunctionsでCloud Run Jobを起動
"""
try:
body = request.get_json(silent=True) or {}
task_count = body.get("task_count", 1)
trocco_pipeline_definition_id = body.get("trocco_pipeline_definition_id")
task_execution_mode = body.get("task_execution_mode", "single_job")
if task_count is None:
return ("task_count parameter is required", 400)
try:
task_count = int(task_count)
except ValueError:
return ("task_count must be an integer", 400)
if task_count <= 0:
return ("task_count must be a positive integer", 400)
credentials, project = google.auth.default(
scopes=["https://www.googleapis.com/auth/cloud-platform"]
)
authed_session = AuthorizedSession(credentials)
base_url = f"https://run.googleapis.com/v2/{CLOUD_RUN_JOB_ID}"
# ref: https://cloud.google.com/run/docs/reference/rest/v2/projects.locations.jobs/get
existing_job_config = authed_session.get(base_url)
if existing_job_config.status_code != 200:
return (
f"Failed to get: {existing_job_config.text}",
existing_job_config.status_code,
)
container_config = existing_job_config.json()["template"]["template"][
"containers"
]
additional_env = []
if (
trocco_pipeline_definition_id != 0
and trocco_pipeline_definition_id is not None
):
additional_env.append(
{
"name": "TROCCO_PIPELINE_DEFINITION_ID",
"value": trocco_pipeline_definition_id,
}
)
# ref: https://cloud.google.com/run/docs/reference/rest/v2/projects.locations.jobs/run
execution_url = f"{base_url}:run"
body = {
"overrides": {
"containerOverrides": {
"name": container_config[0]["name"],
"env": container_config[0].get("env", []) + additional_env,
},
"taskCount": task_count if task_execution_mode == "single_job" else 1,
}
}
if task_execution_mode == "single_job":
response = authed_session.post(execution_url, json=body)
if response.status_code != 200:
return (f"Failed to execute: {response.text}", response.status_code)
return json.dumps(
{
"status": "success",
"task_count": task_count,
"executed_result": response.json(),
}
)
else:
execution_results = []
for _ in range(task_count):
response = authed_session.post(execution_url, json=body)
if response.status_code != 200:
return (f"Failed to execute: {response.text}", response.status_code)
execution_results.append(response.json())
return json.dumps(
{
"status": "success",
"task_count": task_count,
"executed_results": execution_results,
}
)
except Exception as e:
return (str(e), 500)
def list_cloud_run_job_executions(request):
"""
Cloud FunctionsでCloud Run Job Executionの一覧を取得
"""
try:
page_size = request.args.get("page_size", type=int)
page_token = request.args.get("page_token", type=str)
show_deleted_str = request.args.get("show_deleted", type=str)
show_deleted = show_deleted_str.lower() == "true" if show_deleted_str else False
credentials, project = google.auth.default(
scopes=["https://www.googleapis.com/auth/cloud-platform"]
)
authed_session = AuthorizedSession(credentials)
# ref: https://cloud.google.com/run/docs/reference/rest/v2/projects.locations.jobs.executions/list
url = f"https://run.googleapis.com/v2/{CLOUD_RUN_JOB_ID}/executions"
params = {}
if page_size is not None:
params["pageSize"] = page_size
if page_token is not None:
params["pageToken"] = page_token
if show_deleted:
params["showDeleted"] = show_deleted
response = authed_session.get(url, params=params)
if response.status_code != 200:
return (f"Failed to get: {response.text}", response.status_code)
return json.dumps(
{
"status": "success",
"executions": response.json(),
}
)
except Exception as e:
return (str(e), 500)
def list_cloud_run_job_execution_tasks(request):
"""
Cloud FunctionsでCloud Run Job Execution Taskの一覧を取得
"""
try:
page_size = request.args.get("page_size", type=int)
page_token = request.args.get("page_token", type=str)
show_deleted_str = request.args.get("show_deleted", type=str)
show_deleted = show_deleted_str.lower() == "true" if show_deleted_str else False
path = request.path
match = re.match(r"^/executions/([^/]+)/tasks/list$", path)
execution_id = match.group(1)
credentials, project = google.auth.default(
scopes=["https://www.googleapis.com/auth/cloud-platform"]
)
authed_session = AuthorizedSession(credentials)
# ref: https://cloud.google.com/run/docs/reference/rest/v2/projects.locations.jobs.executions.tasks/list
url = f"https://run.googleapis.com/v2/{CLOUD_RUN_JOB_ID}/executions/{execution_id}/tasks"
params = {}
if page_size is not None:
params["pageSize"] = page_size
if page_token is not None:
params["pageToken"] = page_token
if show_deleted:
params["showDeleted"] = show_deleted
response = authed_session.get(url, params=params)
if response.status_code != 200:
return (f"Failed to get: {response.text}", response.status_code)
return json.dumps(
{
"status": "success",
"tasks": response.json(),
}
)
except Exception as e:
return (str(e), 500)
@functions_framework.http
def cloud_run_jobs_manager_handler(request):
"""
Cloud Functions のエントリポイント
"""
try:
# for debugging
logging.info(f"Method: {request.method}")
logging.info(f"Path: {request.path}")
logging.info(f"Headers: {request.headers}")
logging.info(f"Query params: {request.args}")
logging.info(f"Body: {request.get_json(silent=True)}")
request_path = request.path
if not request_path:
return ("Cannot get path", 400)
if request_path.startswith("/run"):
return run_cloud_run_job(request)
elif request_path.startswith("/executions/list"):
return list_cloud_run_job_executions(request)
elif re.match(r"^/executions/[^/]+/tasks/list$", request_path):
return list_cloud_run_job_execution_tasks(request)
else:
return ("Unknown path", 404)
except Exception as e:
return (str(e), 500)
個別コンテナサービスでの注意点
諸々の検証を進めるなかで、把握できた注意点について付記しておきます。
Azure
Container Instances/Container Appsのいずれでも利用可能ではありますが、コンソールでログデータが簡易に確認できるという点では、Container Appsの方が使いやすいです。
Container Instancesでは、CLIでコマンドを実行するか、コンソールでログを確認するためのクエリを実行する必要があります。
Google Cloud
イベント駆動で利用する場合はCloud Run Jobsになりますが、常時起動をする際はCloud Run Worker PoolsとCloud Run Servicesの2つの選択肢があります。
機能的にはCloud Run Worker Poolsをご利用いただけると良いのですが、リリースフェーズとしてはパブリックプレビューのステータスなので、その点にはご留意ください。(位置付けも明確ですし、多少特性が違うだけなので、GA時に大きく変わることもなさそうではないかと個人的には思っています。)
GAされたものしか利用できないという場合は、Cloud Run Servicesを利用することになりますが、こちらで起動時のヘルスチェックが必須になっているため、そのための環境変数を設定するようにしてください。
なお、あくまでCloud Run Servicesに対応するための設定であり、Self-Hosted Runnerとしてポートを開く必要性は全くありません。
また、Cloud Run Servicesにはリクエストベースの料金モデルとインスタンスベースの料金モデルの2種類がありますが、インバウンドリクエストを受け付けないというRunnerの設計上、インスタンスベースが必須です。リクエストベースでも一応動きはしますが、CPUがIdle状態のままなので、実運用が不可能なくらい処理が遅くなります。
Oracle Cloud Infrastructure
Runnerを動かす分には問題ありませんが、Container Instancesがサービスログでの連携対象に入っていないという問題があります。
コンテナが停止した際にログが消えるので、運用上の使いにくさが懸念されます。なお、ログとしてはTROCCO(SaaS)にも連携されるので、そちらで確認するという割り切りも可能ですが、Runner環境で問題がありSaaSにログが連携されないときに、デバッグが難しくなる可能性があります。
一方で、そのためにOracle Cloud Infrastructureに対して別環境からつなぐのかという論点も出てくるでしょうから、あくまでセキュリティ要件と運用負荷とのバランスをどこで取るかという判断になりそうです。
おわりに
コンテナやネットワークの構成など難しいところも多いかと思いますが、検討観点の大枠はご理解いただけたかと思います。ぜひご参考にしていただき、判断に悩む点があれば個別にご相談いただけますと幸いです。
参考