はじめに
本記事は、TROCCO&COMETA Advent Calendar 2025の11日目の記事になります。
TROCCOでは、昨季(2024/11~2025/10)に転送元の大幅な拡充を進めてきました。これによってデータを取得できる対象は広がってきましたが、一方で従来からあるデータベース/ストレージやMA/SFAなどだけでなく、広告オーディエンスリスト連携といったデータによる業務の自動化を進めていくデータアクティベーションの領域にも対応を広げています。
その一環として、2025/12/11に独自の転送先コネクタを作成できる転送先カスタムコネクタ(*)がリリースされました。本記事では、転送先カスタムコネクタの概要からBacklogでの課題作成を事例としたその設定方法まで解説していきます。
これまで「Connector Builder」と呼ばれていたものが、「カスタムコネクタ」と名称が変更になり転送先の機能が追加されています。
こんな方におすすめ
- 転送先カスタムコネクタの概要を知りたい方
- 転送先カスタムコネクタを使うことによって何ができそうかを考えたい方
本記事でご紹介する機能は執筆時点のものであり、機能拡充に伴い仕様が変更される可能性があります。
カスタムコネクタとは
TROCCOはデータの転送/変換/ワークフロー管理といったデータ基盤の運用をAll in Oneで簡素化/自動化できるSaaSサービスですが、どれだけ多くのサービスからデータを転送できるかというコネクタの充実度は、こうしたサービスを選ぶ上では重要な観点です。
対応コネクタ一覧を見ていただくとかなりのサービスに対応していることが分かりますが、一方でSaaSの導入が広がっていくなかで、どうしても対応しきれないサービスというものは出てきてしまいます。そこで、ユーザー側で独自のコネクタを作成できるのがカスタムコネクタです。
以下のようなユースケースを想定しています。
- オープンデータを活用/併用した分析
- 各種SaaSとの連携/業務自動化
- 人事マスタSaaSを起点としたマスタデータ連携
- MA/SFA連携
- 広告データの取得/コンバージョンAPI
- メール/メッセージ配信
- ECプラットフォームとのデータ連携
- 自社サービスや限定公開しているITシステムとのデータ連携
- PaaS/FaaSで公開しているAPI
転送元カスタムコネクタについては、別途記事もあるのでそちらをご参考ください。
転送先カスタムコネクタとは
今回リリースされた転送先カスタムコネクタは、以前リリースされていた転送元カスタムコネクタの転送先版です。基本的な仕様は共通でありつつ、「転送先」コネクタとして利用できるのが違いです。
転送先カスタムコネクタとしては、以下のようなユースケースを想定しています。
- 様々な業務領域の各種SaaSへのデータ連携
- TROCCOがネイティブで対応していないMA/SFA/CRMへのデータ連携
- メールやメッセージサービスとの連携
いずれにせよ、DWHに集約したデータを統合しつつ、各種業務にデータを連携しながら自動化を進めていくような使い方をイメージしています。
利用にあたっては、以下のような流れで使っていきます。
- コネクタを作成する
- 基本情報を設定する
- 接続情報を作成する
- APIのエンドポイントへのリクエスト方法を指定する
- 転送先としてデータを連携するので、その際のデータの連携方法を指定する
- 接続確認をする
- 転送先としてカスタムコネクタを選択して転送設定を作成する
- 転送を実行する
細かい説明をしてもイメージがわきにくいと思うので、Backlogを例として具体例を通して紹介していきます。
Backlogで課題を起票する
開発部門はもちろん、ビジネス部門でもプロジェクト管理のためによく使われているツールとしてBacklogがあります。今回は、Backlogで課題を起票する方法を事例として取り上げます。
以下で取り上げるのはあくまで一例であり、何らかのデータに基づいて課題を起票し、対応を進めていくという観点では様々な用途を想像していただけるかと思います。
想定ケース
「BigQueryでスキャン量が最も多いクエリについて、その内容をまとめて課題に起票する」という事例を例にします。BigQueryはスキャン量に応じて費用がかかるため、お金を無駄に消費していないかをモニタリングするようなイメージです。

Backlogの仕様を確認する
Backlogの各種IDについては以前の記事でまとめてあるので、そちらをご確認ください。
Backlogと接続する準備をする
Backlogと接続する方法としては、APIキーとOAuth 2.0の2つの方法があります。BacklogではAPIキーをヘッダーではなくクエリパラメータで渡す形式になっているため、よりセキュアな方式としてOAuth 2.0での接続とします。
OAuth 2.0で接続するには、事前に接続用のアプリケーションを登録しておく必要があります。そこで、開発者向けのページからアプリケーション登録を進めます。



以下の項目を設定します。
- Redirect URI:https://trocco.io/connections/custom_connector/callback
- アプリケーション名:任意
- サイトURL:任意

Client Id/Client Secretは後ほど利用します。これで保存をすれば事前準備は完了です。
カスタムコネクタを作成する(基本情報)
TROCCOのカスタムコネクタの新規作成画面にいくと、転送元と転送先が選べるようになっています。
各種項目を設定していきます。
- ベースURL:
https://<spaceKey>.backlog.com - 認可URL:
https://<spaceKey>.backlog.com/OAuth2AccessRequest.action - アクセストークンURL:
https://<spaceKey>.backlog.com/api/v2/oauth2/token

この段階で一度保存し、次は接続情報を作成します。
接続情報を作成する
Backlogのアプリケーションにある、Client Id/Client Secretを利用します。

下部の認証をクリックすると、許諾を求める画面が表示されるので、「許可する」を選択すると認証が完了します。


カスタムコネクタを作成する(エンドポイント)
再度保存していたカスタムコネクタの編集画面に戻り、エンドポイントを追加します。今回は「課題の追加」のエンドポイントを利用するので、作成API/単一リクエストを選択します。
- 名前: 任意
- 操作種別: 作成API
- リクエストタイプ: 単一リクエスト
- パス: /api/v2/issues
- HTTPメソッド: POST
- リクエストテンプレート: ※下部で説明します
{
"projectId": {{ row.project_id }},
"summary": "{{ row.summary }}",
"description": "{{ row.description | replace: '
', '\r\n' | replace: '"', '\"' }}",
"issueTypeId": {{ row.issue_type_id }},
"priorityId": {{ row.priority_id }},
"assigneeId": {{ row.assignee_id }}
}
- HTTPヘッダ: Content-Type: application/json

リクエストテンプレートが何なのかですが、転送先としてデータを送る場合、受ける側のエンドポイントが指定している形でデータを送る必要があります。そこで、テーブルデータを求める形に整形してあげる必要があります。
転送先Connector Builderでは、Liquidテンプレートというものを利用してこの整形を行うことができます。テンプレートの{{ row.column_1 }}の部分にcolumn_1の値がマッピングされる形です。
LiquidのテンプレートはShopifyが開発したもので、Webアプリケーションとして様々な機能拡張がありますが、データ処理として利用するのは一部になるので、困ったらAIに教えてもらうと良さそうです。
なお、Backlogに投げ込むにあたって改行コードのエスケープ処理に苦労しまして、どのような設定が最適なのかはちょっとよくわからないです・・・(とりあえず動いたのでヨシとしました苦笑)
また、この例では単一リクエストの例になっていますが、一括リクエスト(1リクエストで複数レコードを処理する)方法もあり、別記事で例を取り上げています。
さて、下部には接続確認をするための設定があり、サンプルデータを追加してあげることで、curlリクエストの実行およびレスポンスの確認ができます。
当然ですが実際にレコードが作成されてしまうので、不用意に実行しないようにご注意ください。
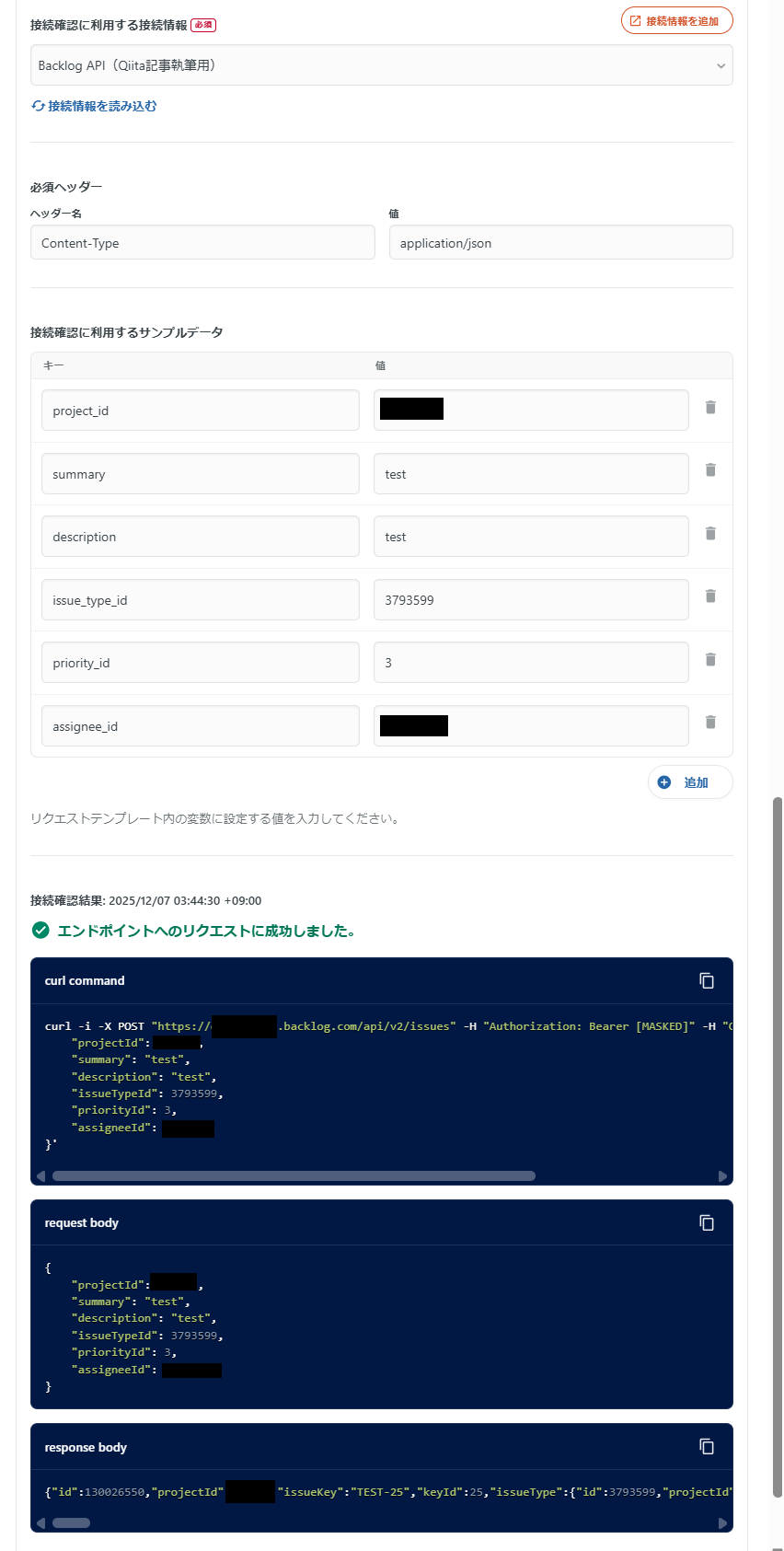
Backlogを確認すると、実際に課題が作成されています。

ここまでできればカスタムコネクタの作成は完了です。
転送設定を作成する
続いて、転送設定を作成し転送ジョブを実行します。転送元BigQuery→転送先カスタムコネクタとして転送設定を作成します。

SQLは以下の通りです。
select
<your_backlog_project_id> as project_id,
3793599 as issue_type_id,
3 as priority_id,
<your_backlog_assignee_id> as assignee_id,
'$yesterday$のスキャン量が最も多いクエリ(' || total_bytes_billed / 1024 / 1024 / 1024 || 'GB)' as summary,
concat(
'- Job URL:\n - ' || 'https://console.cloud.google.com/bigquery?hl=ja&project=' || project_id || '&ws=!1m5!1m4!1m3!1s' || project_id || '!2s' || job_id || '!3s$location$' || '\n',
'- Principal Subject:\n - `' || principal_subject || '`\n',
'- Total Gibibytes Billed:\n - ' || total_bytes_billed / 1024 / 1024 / 1024 || '\n',
'- Project ID:\n - ' || project_id || '\n',
'- Job Type:\n - ' || job_type || '\n',
'- Referenced Tables:' || (
select
string_agg('\n - ' || referenced_table.project_id || '.' || referenced_table.dataset_id || '.' || referenced_table.table_id, '')
from
unnest(referenced_tables) referenced_table
) || '\n',
coalesce(
'- Destination Table:\n - ' || destination_table.project_id || '.' || destination_table.dataset_id || '.' || destination_table.table_id || '\n',
''
),
coalesce(
'- Labels: ' || (
select
string_agg(label.key || '- ' || label.value, ', ')
from
unnest(labels) label
) || '\n',
''
),
'- Query: ' || '\n```\n' || query || '\n```\n'
).replace('\r', '') as description,
from
`$project_id$`.`region-$location$`.INFORMATION_SCHEMA.JOBS
where
date(creation_time, 'Asia/Tokyo') = '$yesterday$'
order by
total_bytes_billed desc
limit
1



モードには「追記(INSERT)」のほか「UPSERT」がありますが、これは別記事で取り上げています。
プレビューに進むと、カスタムコネクタで設定したテンプレートの通りにリクエストで送られるデータが表示されます。

問題なければこれで保存します。
データを転送する
保存した転送設定を実行します。無事成功です!
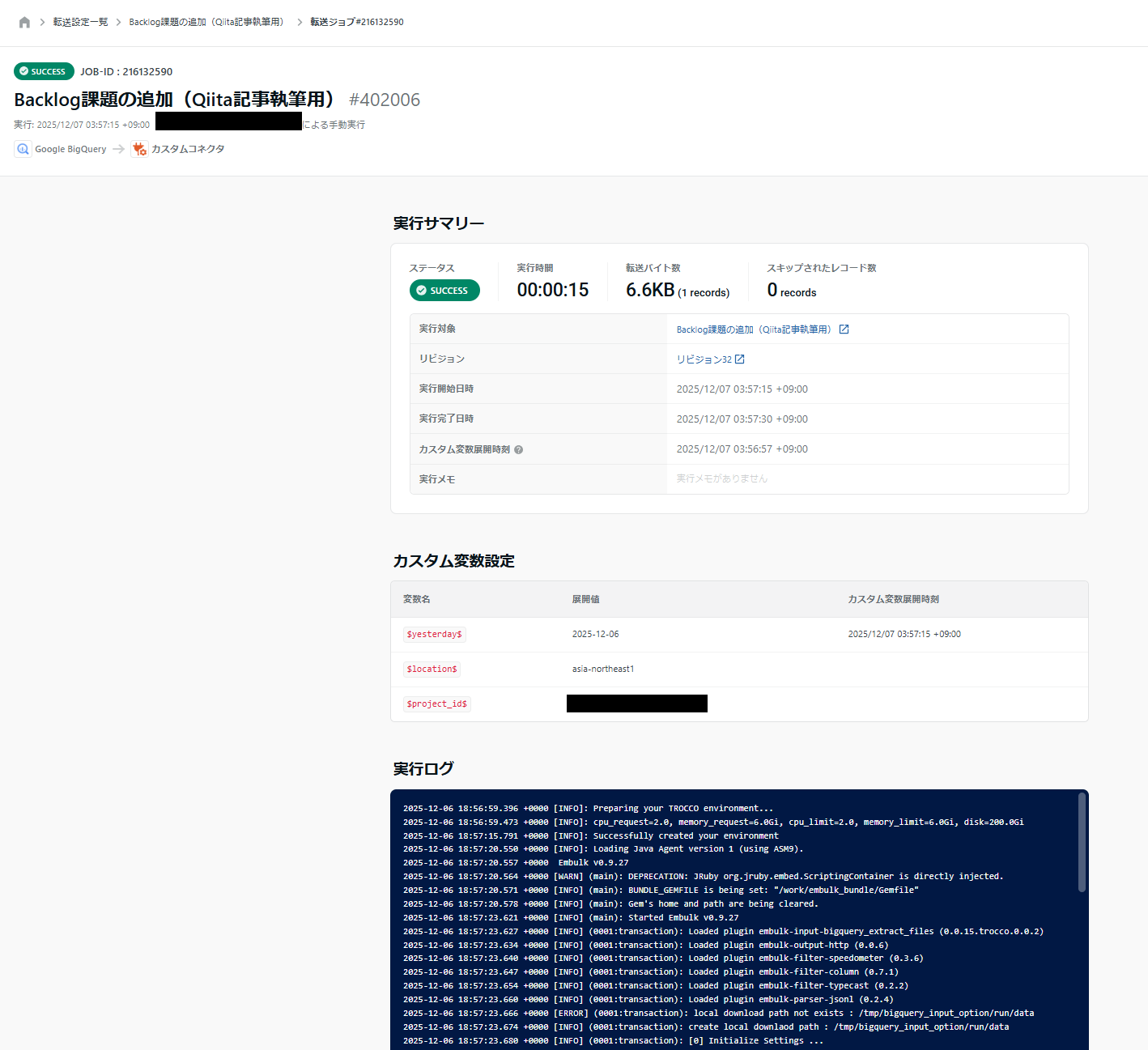
Backlogを確認すると、確かに課題が作成されています!
概要としての説明は以上になります。
一般的な留意点
接続先のAPI仕様に合わせてリクエストを送るという仕組みになっているため、
- 認証の仕様が特殊で対応できない
- ペイロード形式が特殊で対応できない
- APIの仕様上パフォーマンスが高められない
といった可能性があります。そういった場合は、プロダクトとして機能拡充や運用方法の検討などを一緒にしていければと思うので、ぜひご相談くださいませ。
また、TROCCOおよび転送先カスタムコネクタはバッチベースの仕組みであるので、iPaaS(Zapierなど)のようなイベントドリブンな仕組みとは、以下の観点で上手く使い分けをするとよいでしょう。
- TROCCO
- 即時性が不要なもの
- コストを抑えたいもの
- データを横断的に統合して使いたいもの
- iPaaS
- 即時性が必要なもの
その他、詳細な情報については公式ドキュメントをご確認ください。
おわりに
転送先カスタムコネクタの概要について紹介しました。個人的には、転送先として利用できることで、あれができるかも/これができるかもと様々な妄想が膨らむ機能です。
みなさんもぜひ色々新たな活用方法を開拓してもらえると嬉しいです!