はじめに
あなたは本番環境のデータパイプラインを誤って壊してしまった経験はありませんか?
TROCCOの新機能「環境管理」は、そんなリスクを減らし、安全かつ効率的にデータパイプラインを開発/運用するための仕組みです。データ活用を広げていく成長フェーズの組織はもちろん、安定した運用が求められるエンタープライズ企業まで、幅広いニーズに対応します。
本記事では、環境管理の概要から具体的な使い方・設計パターンまで、幅広く解説しています。環境管理が気になっている方、導入を検討している方はぜひご覧ください。
こんな方におすすめ
- 新機能「環境管理」の概要を知りたい方
- 環境管理を利用するにあたって、その使い方を理解したい方
あまりこうした運用に慣れていない方でもわかるように、環境管理の前提となる「環境分離」の説明からはじめています。そんなのもうわかっているよという方は、飛ばし飛ばし読んでいただければ!
前提知識の確認
環境管理について説明する前に、前提知識として環境管理によって実現される「環境分離」がどういうことかについて、おさえておきましょう。
環境分離とは
ソフトウェア開発では、開発環境で開発を行い、検証環境で開発内容の検証を行い、検証された内容を本番環境に反映するような開発フローを取ることがあります。
こうしたフローに即して開発を進めていくと、本番環境に予期せぬ影響を与えずに、安全/安心かつ効率的に検証済の改修内容を本番環境に適用していくことができます。
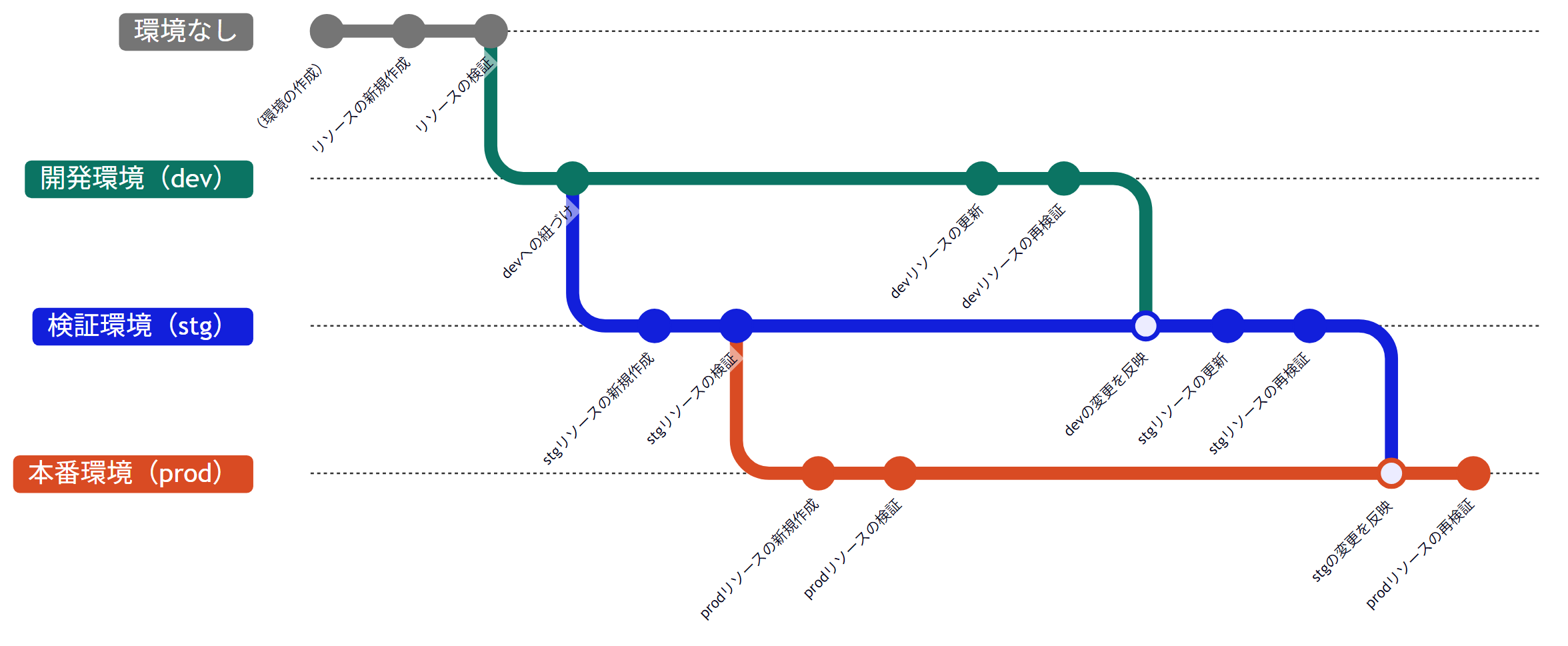
このとき、開発環境、検証環境、本番環境は相互に影響を与えないよう、切り離された環境に配置するようになっており、こうした手法を「環境分離」と呼びます。
今回リリースしたTROCCOの環境管理は、データパイプラインの環境分離を実現するための手段となっています。
手を動かして理解する「環境管理」とは
言葉だけではなかなか要点を掴みづらい方もいらっしゃるかもしれないので、手を動かしながらポイントを理解していきましょう。
環境管理の主な機能
まず、環境管理の主な機能をおさえておきます。環境管理でできることは、以下の4点になります。
- 1: 環境グループ/環境の作成
- 2: 既存リソースの環境への紐づけ/解除
- 3: ある環境に紐づいたリソースから別環境のリソースの新規作成
- 4: ある環境に紐づいたリソースの変更内容の、別環境に紐づいた既存リソースへの差分反映
これらについて、以下で詳細を見ていきます。
1: 環境グループ/環境の作成
まず、環境管理は環境間のリソースの移行を支援するための機能であるため、ベースとなる環境の設定が必要になります。具体的には、環境のまとまりとして「環境グループ」というものが存在し、そのなかに個々の「環境」を作成することができます。
例えば、
- 環境グループ「3環境設定」: 環境「dev, stg, prod」
- 環境グループ「2環境設定」: 環境「dev, prod」
のような形に設定できます。
これらは左タブの「運用支援」 > 「環境管理」から作成が可能です。
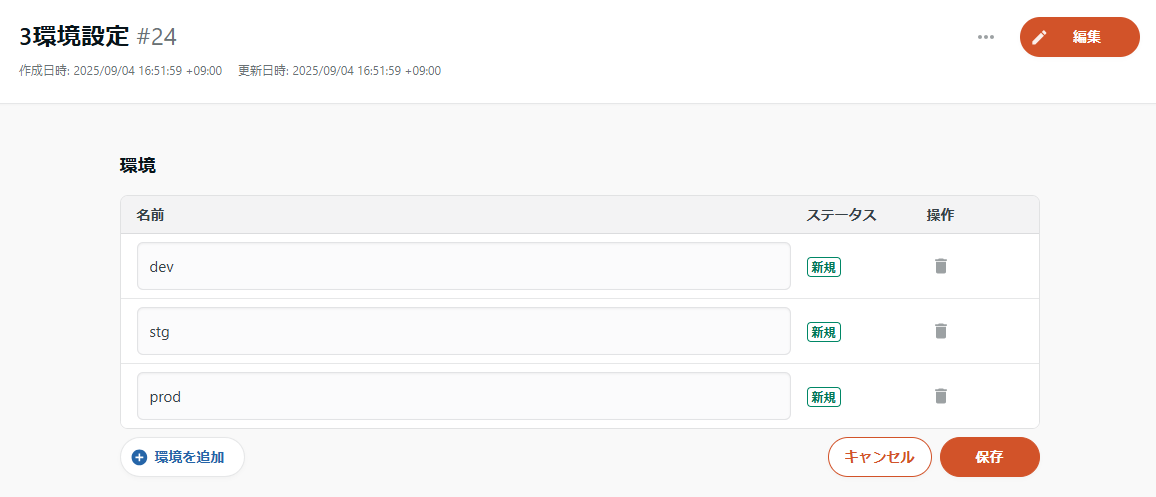

なお、環境グループ/環境の作成/編集については、アカウント特権管理者またはアカウント管理者の権限があるユーザーのみが可能です。
先ほどの図では分離する環境を開発、検証、本番の3環境としていますが、環境の数は目的と運用体制/運用コストを考慮したときに適切なものが定まってきます。
堅牢なプロセスを取りたい場合は3環境になるでしょうし、まだ環境分離の運用に慣れていない場合は、まずは開発と本番の2環境からはじめてみるとよいでしょう。
また、同一組織内でもビジネス部門は2環境、開発部門は3環境と運用を分けることもあるかもしれません。
2: 既存リソースの環境への紐づけ/解除(転送設定/データマート定義共通)
転送設定、データマート定義、ワークフローといったリソースは、そのリソースの作成時点では特定の環境に紐づけられていません。そこで、既存の設定を環境に紐づける/逆に解除することができます。
作成されたままの設定では、右側に環境が未設定であることが表示されています。
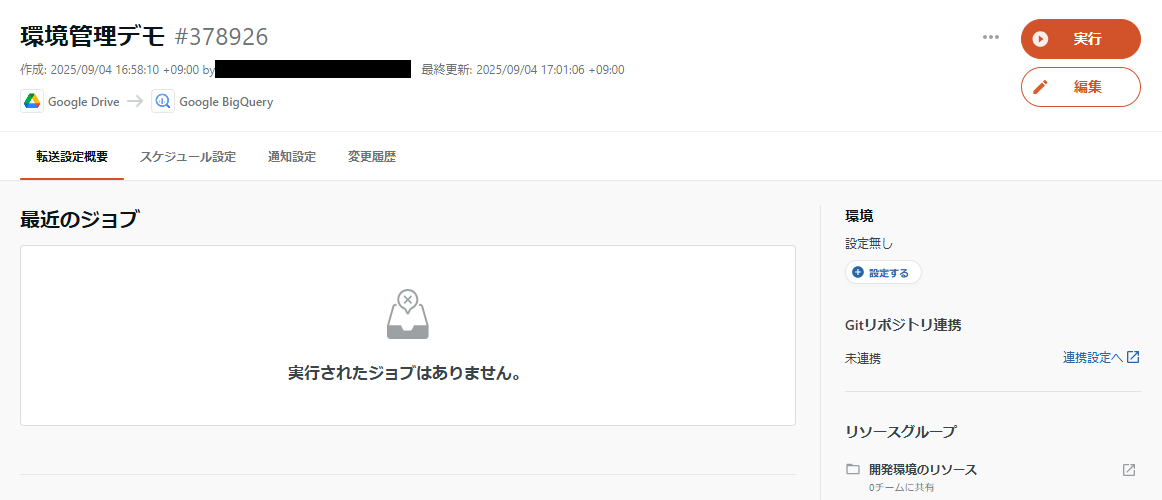
ここから環境を紐づけできます。
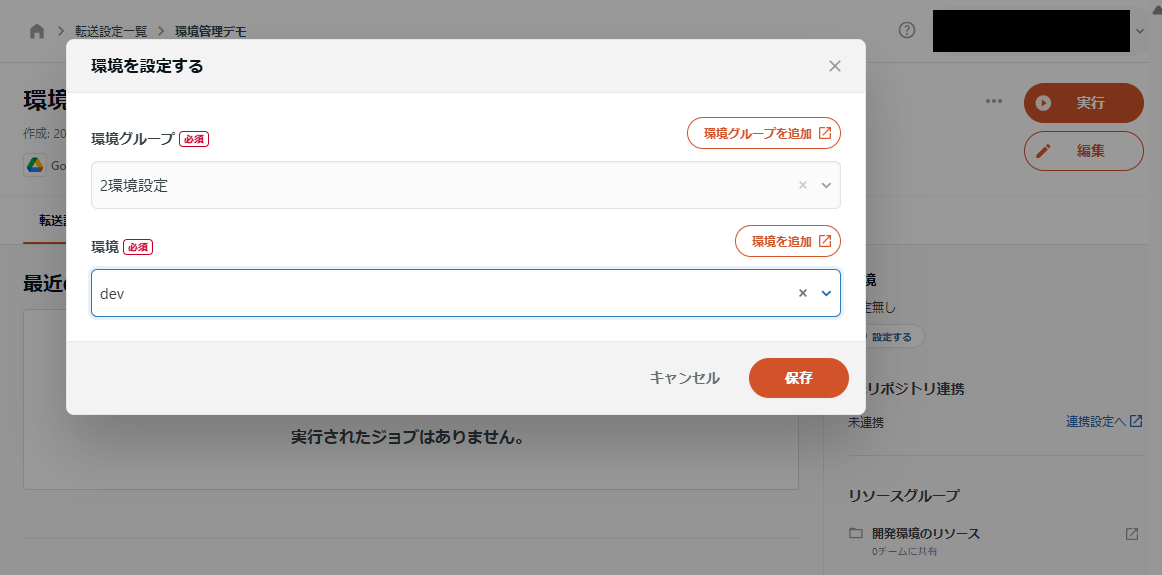
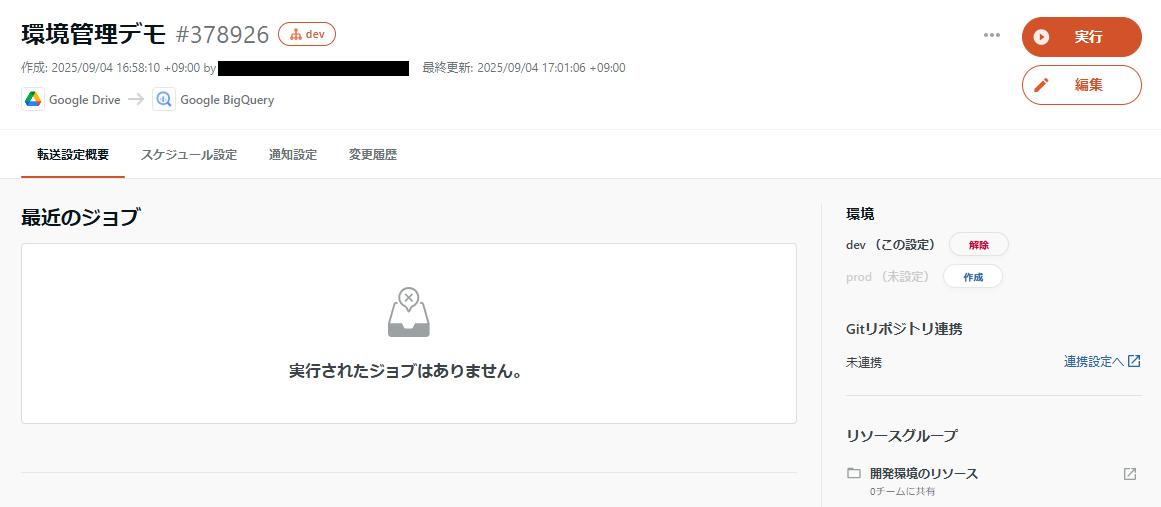
なお、ワークフローの場合、その内部のリソースに環境の異なるものが混在してしまうとおかしなことになるため、ワークフロー内のタスクとして複数環境のリソースが含まれている状態では、環境に紐づけることはできません。(詳細は後述します)
3: ある環境に紐づいたリソースから別環境のリソースの新規作成(転送設定/データマート定義共通)
例えばdev環境の転送設定Aがある場合、そこからprod環境の転送設定A'を新規作成できます。このとき、リソースグループ/接続情報/カスタム変数を環境間の差分として指定できます。
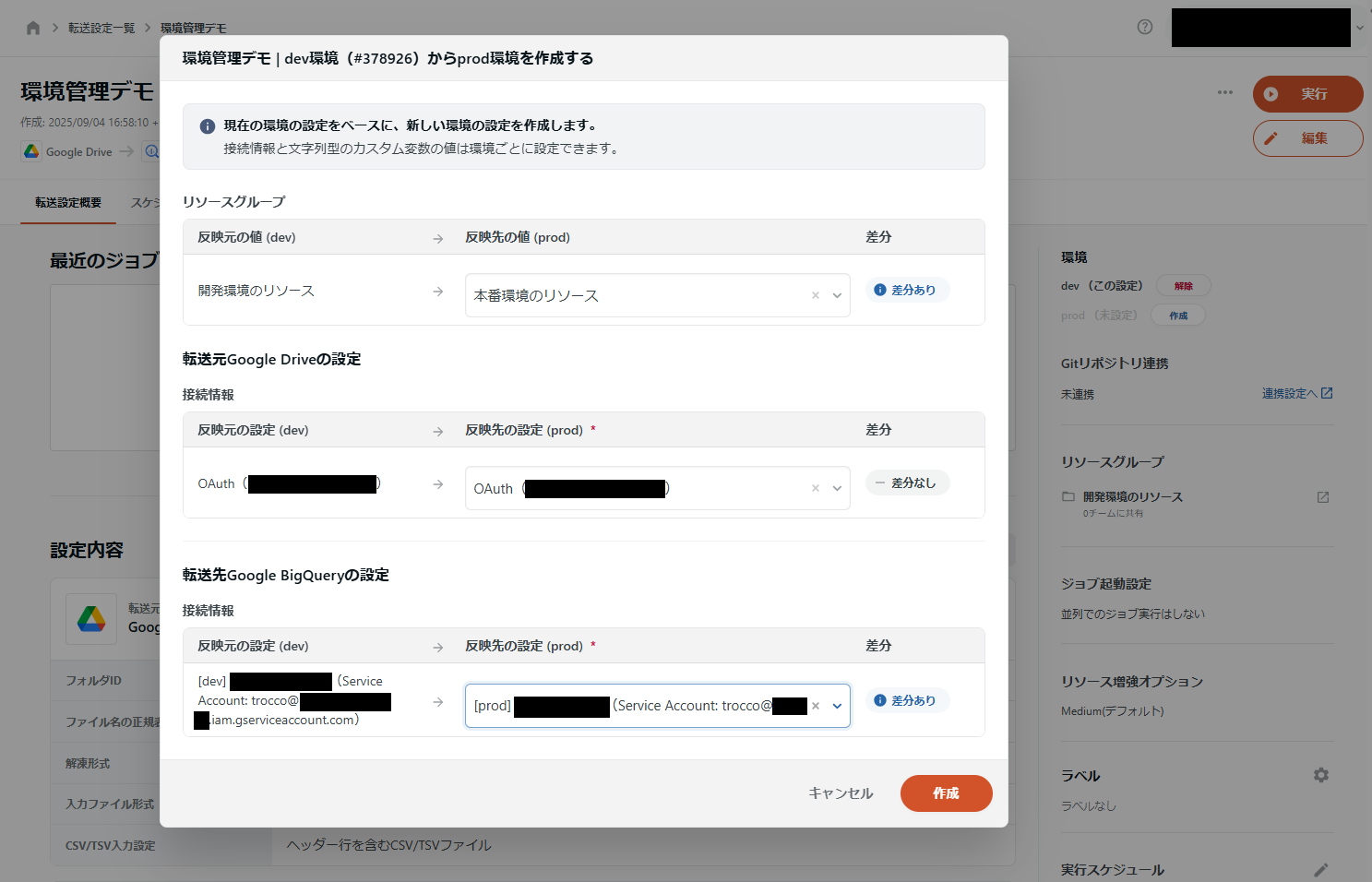
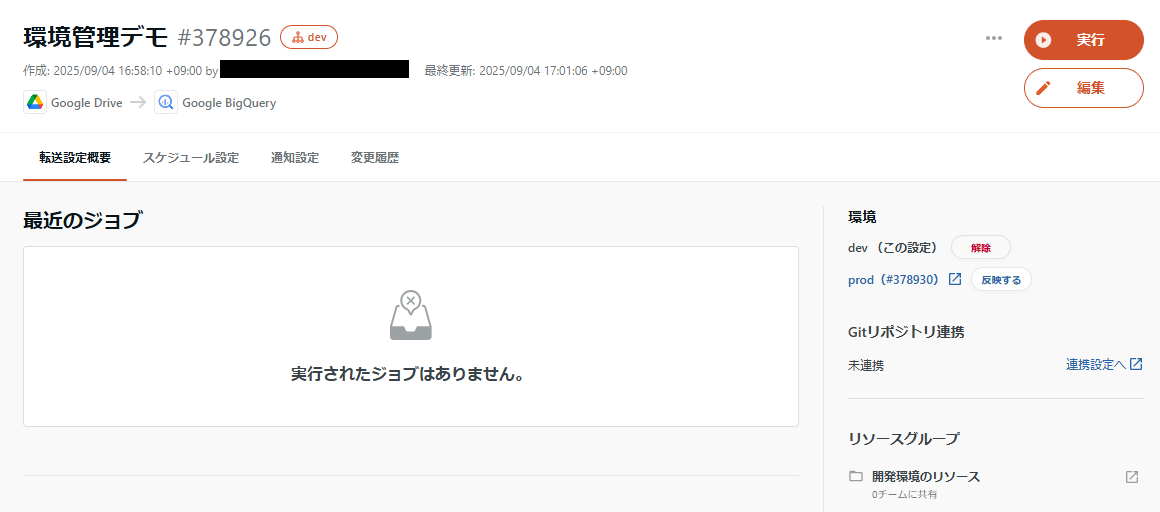
4: ある環境に紐づいたリソースへの変更内容の、別環境に紐づいた既存リソースへの差分反映(転送設定/データマート定義共通)
上記の流れで作業を進めていくと、別の環境に紐づいているが、指定している差分のみが違いとなっている設定が複数作成されています。そのうちの片方(例:dev)を変更した状態で、別の環境(例:prod)への「反映する」を選択すると、変更した内容を選択した環境の設定に反映できます。
ワークフロー定義と環境の関係
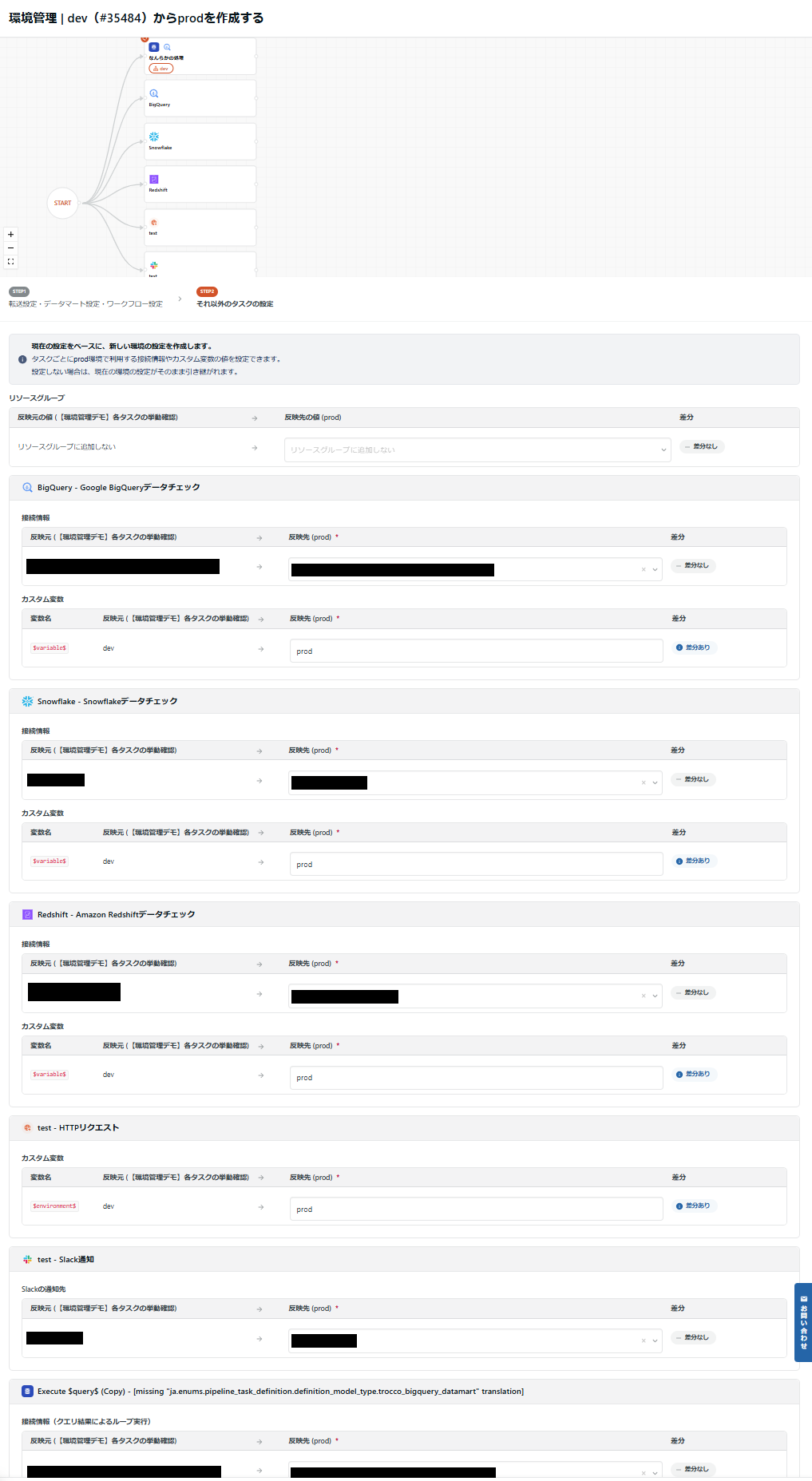
ワークフローでは、それに含まれるタスクとして環境なしのリソースまたは1種類のみの環境に紐づけられたタスクが設定可能です。以下のサンプルのようなイメージです。
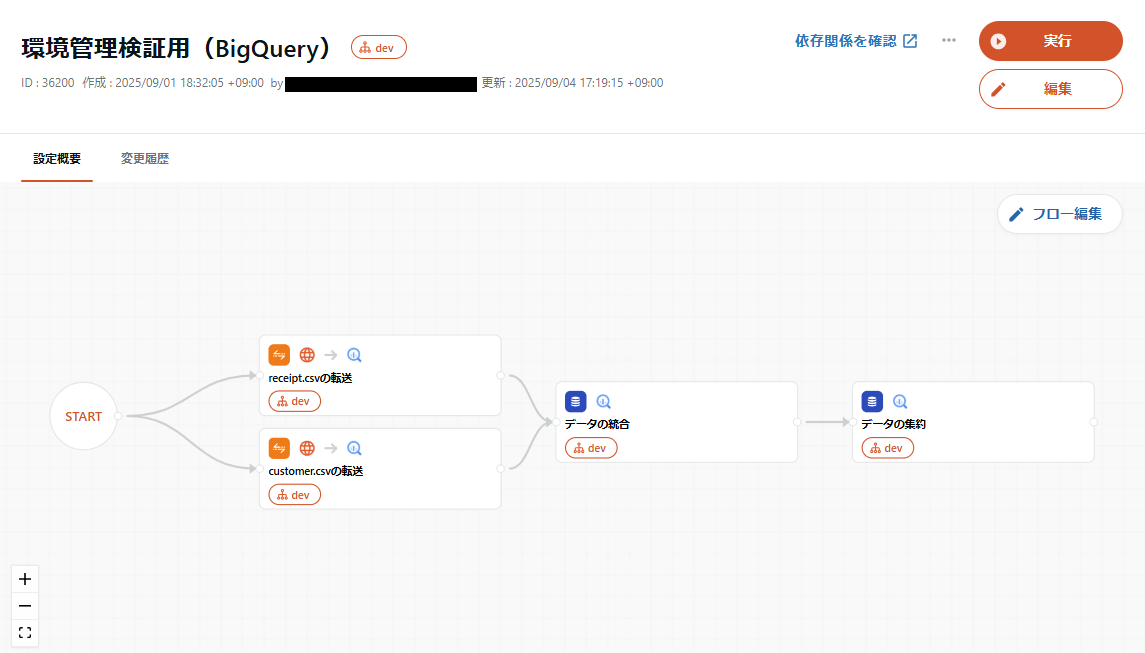
転送設定とデータマート定義については、それ自体がどの環境に紐づいているかというだけなのでシンプルですが、複数の構成要素を持つワークフロー定義では、環境の取扱いが変わってきます。
端的に言えば、「別の環境に紐づくものをまとめられない」ということですが、具体的には以下の通りです。
- フローを構成するタスクは、環境なし or 1種類のみ
- 例えば、紐づけなしまたはdevのみ
- 環境に紐づけられたタスクが存在する場合は、ワークフロー定義は同一の環境のみ可
- 例えば、devのタスクがある場合は、ワークフロー定義はdevのみ
- 別環境のワークフローを作成する場合、環境に紐づけられたタスクが存在する場合は、作成先の環境のタスクも必須
- devのタスクが存在するdevのワークフロー定義では、prodのワークフロー定義の作成時は、prodのタスクも必須
細かい条件はありますが、制約に反するものを作ろうとしてもエラーが発生してできないので、それほど慎重にならずとも大丈夫です。また反映先に対応するものがなければ移行処理のSTEP1で確認可能なので、それも気にしなくともよいです。
なお、ワークフローにはデータチェックなどワークフローのみにあるタスクもあり、それらにも対応しています。環境に紐づけたワークフローで新規作成/変更の反映をするとき、以下を差分として指定可能です。
- データチェックやクエリ結果でループの接続情報
- データチェックやHTTPリクエストタスクのカスタム変数
- Slack通知タスクのSlack通知先
サンプルは以下の通り(長いので開いて表示)
お掃除
ここまでで作った環境グループ/環境や紐づけたリソースが不要な方は、削除しておきましょう。環境に紐づけたリソースの一覧は、環境グループの詳細画面から確認できます。
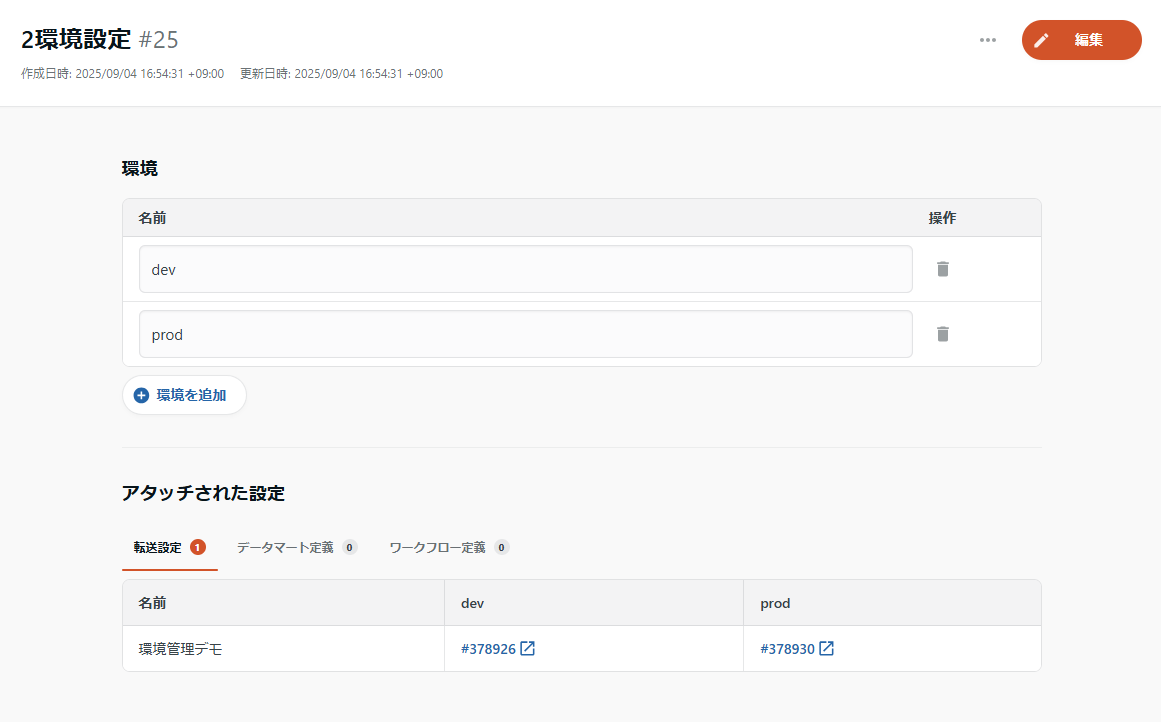
いきなり環境グループを削除することも可能ですが、その場合リソース自体は何の環境も紐づかないものとして残る(=削除されない)ようになっているので、個々のリソースが不要な場合はリソースを削除してから環境グループを削除してください。
そのほか、詳細な仕様を確認したい方は、公式ドキュメントをご確認ください。
設計パターンの整理(タスクレベル)
次に、どのような分離が可能なのか、転送設定/データマート定義の個別のタスクレベルで見ていきましょう。
分離のレイヤー
具体例に入る前に、簡単な前提知識をおさえておきます。一般に環境分離を実現する場合には、様々な分離のレイヤーが存在します。
例えば、AWSでアプリケーション開発をする場合、開発/検証/本番のそれぞれで、アカウントレベルで分離するのはよくあります。TROCCOもAWS環境で稼働していますが、サービス提供者視点では同様の構成になっています。
一方、ユーザーとして利用するTROCCOの環境管理では、同一のアカウントに含まれつつ、「データ処理の元データをどこから取得し、実行結果をどこに保管するか」という観点で、特定の差分だけを含む別々のリソース(=処理定義)を作成することによる分離になっていることが特徴です。
そこで、
- TROCCOのアカウントとしては1つになる
- データ処理の実行結果が分離されるように定義されたリソースを、特定の差分だけで環境ごとに作成する
- このときの差分の設定方法によって、分離のレイヤーが定義される
ことがポイントになります。
設計パターンの具体例
言葉だけではわかりにくいところがあると思うので、転送設定を例に代表的な具体例を見てみましょう。
接続元/先ごとまるごと分離したい
最もシンプルなのがこのパターンです。
| 環境 | 転送元接続情報 | 転送先接続情報 |
|---|---|---|
| 開発環境 | 開発環境用の転送元の接続情報 | 開発環境用の転送先DWHの接続情報 |
| 本番環境 | 本番環境用の転送元の接続情報 | 本番環境用の転送先DWHの接続情報 |
シンプルではありますが、転送元のサービスが環境分離されていることが前提です。例えば、自社サービスのDBであったり、設定変更前に事前検証をするような運用フローになっているSFAなどがこうした使い方の対象です。
接続先のみ分離したい
次に、以下のような場合には、接続先のみの分離(=接続元は共通)となります。
- 例えば広告データなど、わざわざ検証用のデータを用意することがないため、転送元に本番環境のみしかない場合
- そもそも目的として本番データを利用したデータパイプラインを作れればいいので、転送元は本番環境だけでいい場合
接続情報レベルでの分離
接続先のみの分離の1つの方法として、接続情報レベルでの分離があります。
| 環境 | 転送元接続情報(=共通) | 転送先接続情報 |
|---|---|---|
| 開発環境 | 本番環境用の転送元の接続情報 | 開発環境用の転送先DWHの接続情報 |
| 本番環境 | 本番環境用の転送元の接続情報 | 本番環境用の転送先DWHの接続情報 |
これもよくある分離のパターンになるでしょう。
スキーマレベルでの分離
接続先のみの分離の別の方法として、スキーマレベルの分離も可能です。この場合は、カスタム変数(*)を活用して分離を行います。
(*)このときのカスタム変数は、環境管理以外で利用するカスタム変数と容易に判別できるように、特定のプレフィックス(この例ではenv_var__)をつけておくとよいです。
| 環境 | 転送元接続情報(=共通) | 転送先接続情報(=共通) | カスタム変数 |
|---|---|---|---|
| 開発環境 | 本番環境用の転送元の接続情報 | 本番環境用の転送先DWHの接続情報 | $env_var__schema_id$ = sample_dev |
| 本番環境 | 本番環境用の転送元の接続情報 | 本番環境用の転送先DWHの接続情報 | $env_var__schema_id$ = sample_prod |
なお、Snowflakeの場合はカスタム変数でウェアハウスを指定することで、開発と本番で使うウェアハウスを切り替えられるようになります。
分離のレイヤーの補足
転送元からDWHへのデータ転送の転送先では、考え方としてはテーブルレベルでの分離もあり得ます。とはいえ、設計的にシンプルになるので、DWHはデータベースレベルでの分離にしてしまうのがよいでしょう。
また、データマート定義については、処理的にはDWH内のテーブルを参照してDWH内にテーブルを作成するのが基本になるので、これも考え方としては転送設定と同様に、上記のようなパターンになります。
設計パターンの整理(ワークフローレベル)
続いて、ワークフローレベルまで拡張していきます。タスクレベルと異なるのは、複数のタスクが依存関係を持って処理されるため、その依存関係を考慮しながら利用を進めていく必要があるということです。
初級:本番ソースからの2環境分離
最もシンプルな形が、本番環境の転送元からデータを取得し、後続の処理を分離する方法です。これには2つ方法があり、1つ目が転送設定からまるごと分離してしまう方法です。
※図を作成しているツールの仕様上、devの転送設定がprodのワークフロー定義に含まれているように見えますが、devに含まれていると読み替えてください
2つ目はDWHに取り込んだデータ以降で分離する方法です。なお、これで転送設定を分けているのは、取込部分で開発をする場合に事前検証をする目的です。
※図を作成しているツールの仕様上、devの転送設定、1つ目のdevのデータマート定義がprodのワークフロー定義に含まれているように見えますが、devに含まれていると読み替えてください
いずれも設計としてはシンプルになるので、初心者はまずこの形から利用してみましょう。
ただし、個々のタスクの処理方法によっては本番環境と開発環境でデータに齟齬が発生しやすいのが課題になります。全部が洗い替え処理であれば全く問題ありません(そしてデータ量の少ない初期フェーズではそうするのが望ましい)が、例えば差分更新などが入ってくると整合性を保つのがやや難しくなってきます。
中級:初級&テーブルクローンの活用
初級の設計パターンではデータの不整合が課題になるという話をしましたが、その解決方法の1つとして、データのコピーがあります。基本的に初級をベースにしつつ、開発に取り掛かる前に本番環境のデータを開発環境に持ってくることで不整合を解消するのがこのパターンです。
なお、データをコピーするとき、BigQueryやSnowflakeでは既存のテーブルのデータを効率的に利用できる「クローン」という機能があります。
BigQueryの場合は、
create table `{dest_project_id}.{dest_dataset_id}.{dest_table_id}`
clone `{source_project_id}.{source_dataset_id}.{source_table_id}`
Snowflakeの場合も、
create table {dest_project_id}.{dest_dataset_id}.{dest_table_id}
clone {source_project_id}.{source_dataset_id}.{source_table_id}
の形式のSQLを実行することでテーブルをクローンできます。
実際に運用する際にはこれを自動化したいですが、その場合はTROCCOのクエリ結果でループを利用するとよいです。例えばBigQueryでは、以下のクエリでクローンを行うクエリをまとめて生成できます。これをDWHで実行すると、テーブルをまとめてクローンできます。
select
string_agg(
'create or replace table `' || {dest_project_id} || '.' || table_schema || '.' || table_name || '`\n' ||
'clone `' || table_catalog || '.' || table_schema || '.' || table_name || '`;\n',
'\n' order by table_name
)
from
`{source_project_id}`.`region-asia-northeast1`.INFORMATION_SCHEMA.TABLES
where
table_type = 'BASE TABLE'
上級:本番データの動的参照
中級のようにクローンを活用することでデータ不整合の問題は解消できますが、いちいちその処理を行うのがめんどくさい大変という課題があります。そこで、不整合が問題なら本番データを参照してしまえばいいのでは?という案が出てきます。
ワークフロー全体でいい感じにやるのは難しいのでそれは別として、少なくともタスクレベルの開発では接続情報とカスタム変数を使い分けることで実現できます。
BigQueryを例にすると、
- devの接続情報:devのプロジェクトの編集権限+prodのプロジェクトの閲覧権限
- prodの接続情報:prodのプロジェクトの編集権限
を作っておきます。
データマート定義では以下のような設定にします。
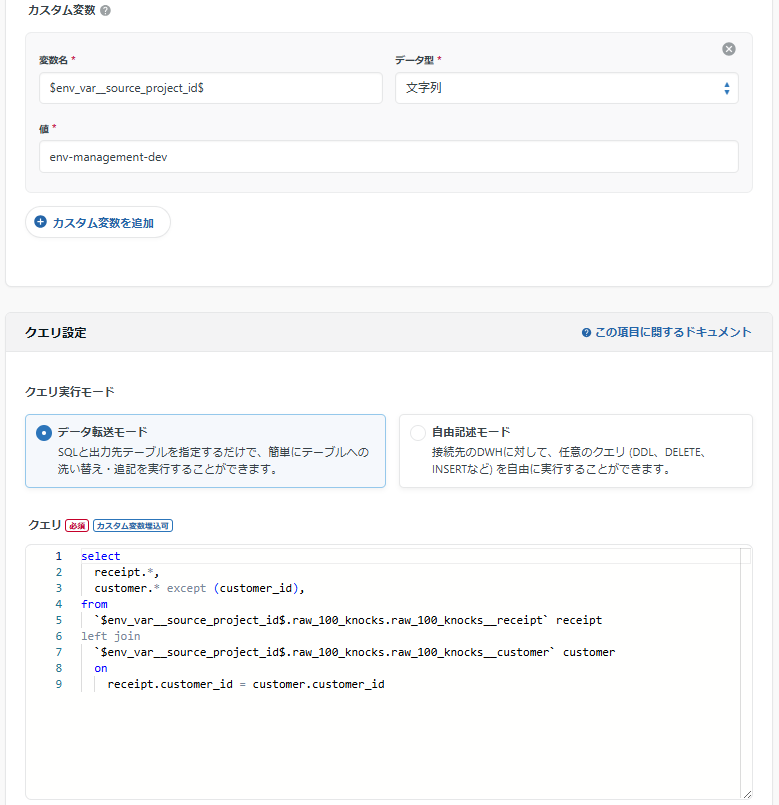
すると、実行時のカスタム変数の指定によって、以下のような処理をさせることができます。
| 環境(カスタム変数指定) | 接続情報(=マートの作成プロジェクト) | カスタム変数(=参照元テーブルのプロジェクト) | 処理 |
|---|---|---|---|
| 開発環境(なし) | env-management-devプロジェクト | env-management-dev | 開発環境のデータを参照して開発環境にマートを作成 |
| 本番環境(なし) | env-management-prodプロジェクト | env-management-prod | 本番環境のデータを参照して本番環境にマートを作成 |
| 開発環境(env-management-prod) | env-management-devプロジェクト | env-management-dev →env-management-prodでオーバーライド |
本番環境のデータを参照して開発環境にマートを作成 |
ここまで3つのパターンを紹介してきましたが、適した設計のあり方は実現したいことや組織体制によって変わってきます。上記の内容を参考にしつつ、自組織にあった設計方法を考えてみてください。
Tips
特定の環境のみで実行するタスクを設定したい
例えばTableauデータ抽出のタスクが本番環境でしか動かしようがないなど、特定の環境のみでしか実行しないというタスクがあることもあるでしょう。
このケースでは、直近で拡充されたのワークフロー条件分岐の条件「環境」を利用してください。
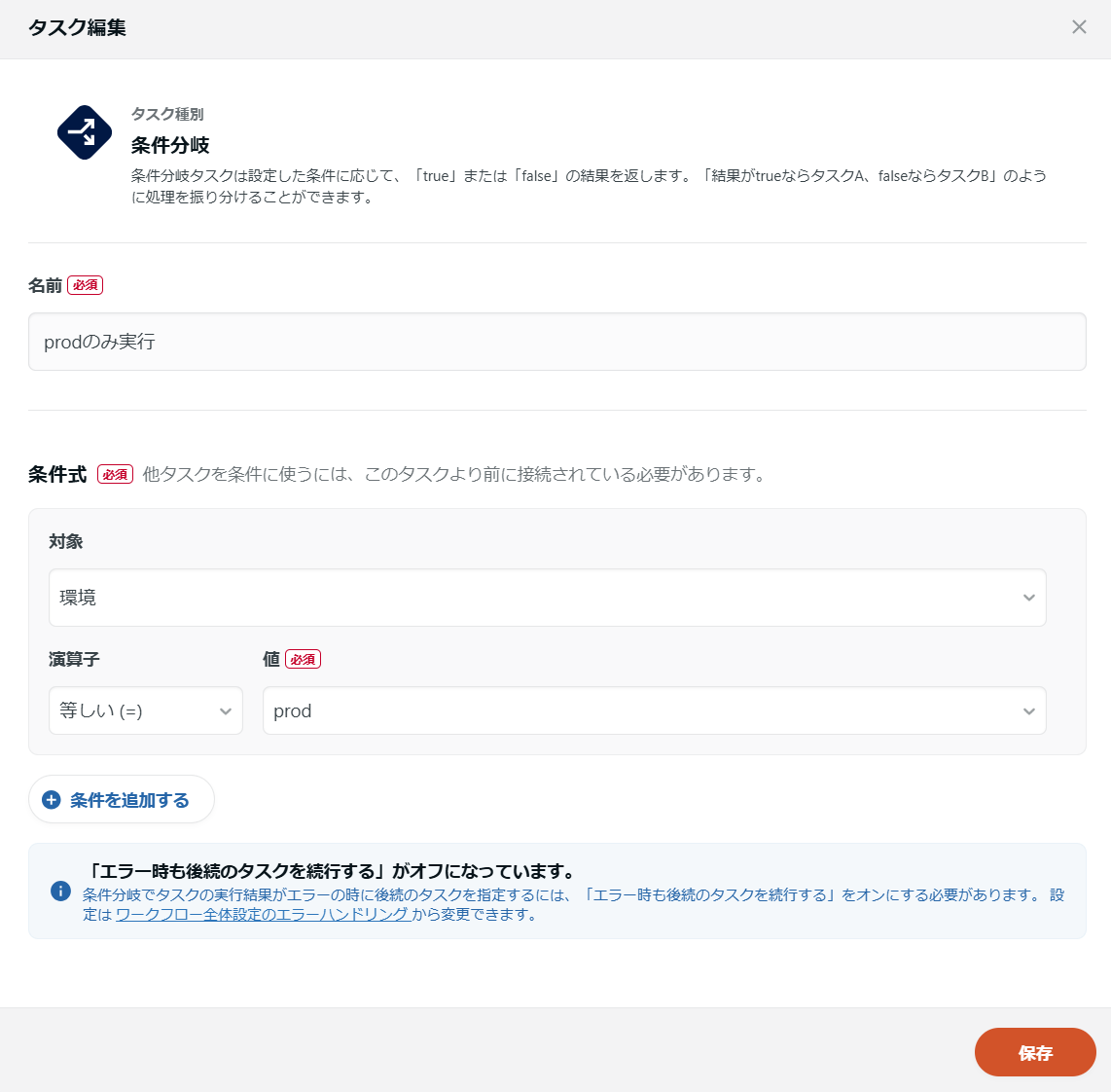
ワークフロー条件分岐の詳細については、「TROCCOのワークフローがさらに便利に!条件分岐で実現する、より柔軟なデータ活用」をご確認ください。
利用上の注意
既にTROCCOをご利用いただいている方には、リソースの複製をして形式上の環境分離を実現している方がいらっしゃいます。その場合の注意点を付記しておきます。
TROCCOの環境管理では、あくまで環境を付与されたリソースから別環境のリソースを移行して作るため、既存の開発/本番環境のリソースを合わせて環境管理に載せ替えることはできません。
そこで、本番のものにprodを付与して、そこからstg, dev等を作る形で進めてください。その際、リソースの作り方(特にカスタム変数の使い方)を、環境管理に適した形に作り変えていただく必要があるかもしれません。
おわりに
もう少し詳しく解説した方がよさそうなところがありつつ、結構な分量になってきたのでひとまずこちらで留めておきます。改めてのポイントとしては、
- TROCCOの環境管理では、同一アカウント内で接続元/先に応じた環境分離を行う
- 分離の方法としては、接続元を開発/本番など分けるかというところから、DWHではアカウントレベル/データベースレベル/スキーマレベル/テーブルレベルなどの階層がある
- 1つのタスクレベルでどう分離するかに加えて、ワークフロー単位で運用しやすいように設計しておくのがよい
- 分離の際は接続情報とカスタム変数を上手く使い分ける
といったところでしょうか。
これまで使ってこなかった方には、なかなか理解が難しいことやどうするのが最適か迷うところもあるかもしれませんが、この記事では不足していることがあればぜひお気軽にご指摘ください。
設計/運用していく難しさもありつつ、でもやっぱり「本番環境を壊さなくてすむ安心感」はかけがえのないものですので、上手くご利用いただけると嬉しいです!