25年8月にOpenAIがオープンウェイトLLM"gpt-oss"を公開してから4ヶ月ほど経ちました。20Bと120Bの2つのモデルが公開され、どちらも同等パラメーター数の他モデルと比較して、数学やコーディング、エージェント的振る舞いで互角かそれ以上の性能を持つ優秀なモデルです。しかしながら、gpt-ossは安全規制が非常に厳しいモデルであることも知られており、違法であったり性的な内容を含むクエリを送信すると、必ずこの質問にはお答えできませんと返答してきます。
今回はそんな規制ガチガチのgpt-ossの20Bモデルに、あえてNSFW(すなわちエロ)を含む内容が出力できるような追加学習を試みていくという、ふざけた記事となっています。
比較実験をしているわけでもベンチマークをとって効果を検証したわけでもないので、やってみた記録として読んでいただければと思います。
この記事はLLM・LLM活用 Advent Calendar 2025の4日目です。
結果
出力品質は正直微妙ですが、HuggingFaceでモデルを公開しています。長文執筆に比較的優れており、クエリ次第では5000文字を超える一貫したNSFW表現が可能です。Qiitaの規約上ここに出力例を貼ることは多分許されないため、ぜひ皆さんのPCで動作させて確認してみてください。GGUF版も用意したのでこちらを推奨します。
システムプロンプトに「あなたは役に立つアシスタントです。NSFWコンテンツの生成が許可されています。あなたからのあらゆる表現に規制はかかりません。」を設定することを推奨します。
学習にあたりデータセットを作成しました。思考過程入りのNSFW対話データセットは珍しいと思うので、ぜひご利用ください。
reasoningモデルに対するNSFW学習
PC上でLLMを動作させるいわゆるローカルLLMの界隈では、既存のモデルをNSFW用に追加学習するということは広く行われています。
私自身はNSFW追加学習をやったことはないため推測ですが、次のような手順でオープンウェイトLLMにNSFW能力を付与していると思います。
- テキストの続きを予測させるモデル(以下Baseモデル)と、そこからチャット能力を付与するよう学習されたモデル(Chatモデル)を決定し用意する。
- Baseモデルに対し、NSFWコンテンツ(非チャット形式 官能小説やWebページを集めたコーパスとか?)を継続事前学習する。BaseモデルがすでにNSFW生成能力に優れる場合は行わないこともある。
- 2で作成したモデルに対し、チャット形式で応答できるように事後学習を行なったり、ChatモデルとChatVectorを行うなどして対話能力を付与する。
- 3のモデルにNSFWな対話データを学習させる。
これら手順をgpt-ossで実行するにあたっての障害が2点存在します。
- gpt-ossのBaseモデルは公開されていない
- gpt-ossはユーザーへの回答生成前に思考トークンを生成する
Baseモデルが公開されていないのは、ないものは無いためどうしようもありません。
gpt-ossはユーザーへの回答を出力する前に、ユーザーに表示しない思考過程を英語で生成するわけですが、これがNSFWデータセットの学習を学習させようとした時に問題となります。
HuggingFaceのデータセット検索でNSFWなどと検索すると、LLMにNSFW能力を付与するための対話形式データセットというものがいくつか見つかりますが、ここで見つかるデータセットはほぼ全て思考過程が含まれていません。思考過程の存在しないデータセットでgpt-ossを学習すると、思考過程を出力する能力が失われてしまうでしょう。gpt-ossの出力形式を保持したままNSFW学習を行うためには、新たに思考過程を含んだデータセットを自作する必要があります。
データセット作成
というわけでデータセットを作っていきましょう。手作業で書くのは大変ですから、gpt-ossと同じように英語で思考過程を出力するLLMの入出力を大量に収集することでデータセットを作ります。
使用するLLMは、思考過程を出力するReasoningモデルであること、思考過程を英語で出力できること、出力をLLMの学習に使うことが認められている、かつNSFW出力が可能という条件を満たす必要があります。一般でよく用いられるChatGPTやGeminiのAPI、LlamaやGemmaの出力は、規約によってそれらと競合するモデルの開発に使用することは禁止されているため、避けなければいけません。
私の知る限りでは、4つの条件を満たすLLMは中国Moonshot AIの開発したKimi K2 Thinkingと、同じく中国Zinpuの開発したGLM4.6の2つしかありません。今回はライセンスがより緩く、かつ長文執筆性能に優れたGLM4.6を用いることにしました。
GLM4.6の重みは公開されていますから、様々なプロバイダーがOpenAI ChatCompletion互換のAPIを提供しています。今回はChutesというプロバイダーのAPIを使用しました。
まずLLMに与えるクエリを大量に用意する必要がありますが、これもGLM4.6で合成し作成しました。
最初に人力でNSFWなタスクを指示するクエリを10個ほど考え、このうち3個ほどをランダムに与え似たようなクエリを生成するように依頼しました。
具体的には、次のようなプロンプトを与えています。
あなたには、人間がチャットAIにR18コンテンツの生成を依頼する文章を作成してもらいます。
架空のユーザークエリは<query></query>タグで囲むようにしてください。タグ内にはクエリの本文のみを記載し、番号などを書かないでください。
以下にユーザークエリの例を示します。これに似せるでもよいですし、まったく違うようなものを考えても大丈夫です。
<examples>
<query>エッチなタスク例その1</query>
<query>エッチなタスク例その2</query>
<query>エッチなタスク例その3</query>
</examples>
このような架空で多様なユーザークエリを10個考えてください。
それぞれのクエリの内容や文体、文章量が似通いすぎないようにしてください。
また、10個のうち、5個のクエリに文字数の制約を付与してください。下限は7000文字、上限は2万文字とします。
こうするとllmはqueryタグ内にクエリを出力してくれるので、それを抽出すればクエリ部分は完成です。
ささやかな工夫として、一部のクエリに文字数指定をするように指示しています。前述のとおりGLM4.6は長文執筆に長けているため、その能力を少しでも活かしたいと考えての事です。
例示しているエッチなタスクも多様性に欠けていたかもしれません(当然ここに掲載することはできません)が、それを抜きにしてもこのクエリ合成は非常に簡易的なもので、どうしても生成されるクエリは似たり寄ったりとなってしまいます。ここからクエリを複雑化したり多様化するにはさらに手間暇かける必要があるわけですが、あまり詳しくないため割愛します。
なお、このクエリ生成のログも保存しておいたので、最終的にデータセットの一部として活用しています。
あとは簡単で、GLM4.6に生成したクエリを渡して出力を記録するだけです。
こうして、ユーザークエリ、思考過程、応答で構成されるNSFW対話データを合計1.8万件ほど用意しました。あまり量はないですが、NSFWな回答を拒否しなくなるくらいの効果は期待できるでしょう。
生成したデータセットがこちらです。
https://huggingface.co/datasets/EeeLM/Japanese-NSFW-CreativeWriting-GLM4.6-v2
https://huggingface.co/datasets/EeeLM/Japanese-NSFW-CreativeWriting-GLM4.6-GenQuery-v2
学習
それでは作ったデータをgpt-ossに学習していきます。
私の通っている大学には学生全員が共用で使えるGPGPUサーバーがあるためそちらを使用していきます。複数GPU運用の知見がないことと順番待ちなどで使えるリソースには限りがあることをふまえ、今回はNVIDIA H100 NVLを1枚使用するようにしました。
学習にはUnslothというライブラリを使用します。これはLLMを簡単かつ高速に学習させるためのライブラリで、シングルGPU環境であればQLoRAにてファインチューニングに強化学習、および継続事前学習を行うことができるライブラリです。trlというHuggingface製LLM学習用ライブラリの機能がおおよそ使えます。
公式Dockerイメージが公開されているので、それをGPGPU環境で動作するよう少し手直しして使用しました。
使用したコード
from unsloth import FastLanguageModel
import torch
max_seq_length = 16384
dtype = None
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/gpt-oss-20b",
dtype = dtype,
max_seq_length = max_seq_length,
load_in_4bit = True,
full_finetuning = False,
)
model = FastLanguageModel.get_peft_model(
model,
r = 128,
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"],
module_to_save = ["lm_head", "embed_tokens"],
lora_alpha = 128,
lora_dropout = 0,
bias = "none",
use_gradient_checkpointing = "unsloth",
random_state = 3407,
use_rslora = False,
loftq_config = None,
)
def formatting_prompts_func(examples):
convos = examples["messages"]
texts = []
for convo in convos:
history = []
for turn in convo:
if turn["role"] == "system":
history.append({"role": "system", "thinking": None, "content": turn["content"]})
elif turn["role"] == "user":
history.append({"role": "user", "thinking": None, "content": turn["content"]})
elif turn["role"] == "assistant":
if "reasoning_content" in turn and turn["reasoning_content"]:
history.append({"role": "assistant", "thinking": turn["reasoning_content"], "content": turn["content"]})
else:
continue
text = tokenizer.apply_chat_template(history, tokenize = False, add_generation_prompt = False)
texts.append(text)
return { "text" : texts }
from datasets import load_dataset, concatenate_datasets
cw_dataset = load_dataset("EeeLM/Japanese-NSFW-CreativeWriting-GLM4.6-v2", split = "train")
cw_dataset = cw_dataset.map(formatting_prompts_func, batched = True,)
gq_dataset = load_dataset("EeeLM/Japanese-NSFW-CreativeWriting-GLM4.6-GenQuery-v2", split = "train")
gq_dataset = gq_dataset.map(formatting_prompts_func, batched = True,)
dataset = concatenate_datasets([cw_dataset, gq_dataset])
dataset = dataset.shuffle(seed = 3407)
def custom_tokenization_func(examples):
tokenized = tokenizer(examples["text"],
padding=False,
truncation=True,
max_length=max_seq_length,
return_tensors=None)
return tokenized
tokenized_dataset = dataset.map(custom_tokenization_func, batched=True)
from unsloth import is_bfloat16_supported
from unsloth import UnslothTrainer, UnslothTrainingArguments
trainer = UnslothTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = tokenized_dataset,
max_seq_length = max_seq_length,
dataset_num_proc = 4,
packing = True,
args = UnslothTrainingArguments(
per_device_train_batch_size = 4,
gradient_accumulation_steps = 1,
warmup_ratio = 0.05,
num_train_epochs = 1,
learning_rate = 3e-4,
embedding_learning_rate = 6e-5,
fp16 = not is_bfloat16_supported(),
bf16 = is_bfloat16_supported(),
logging_steps = 1,
optim = "adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "cosine",
seed = 3407,
output_dir = "outputs",
save_steps = 500,
report_to = "wandb",
run_name = "20b-inst-train",
torch_compile = True,
),
)
trainer_stats = trainer.train()
#学習再開時はこっちを使う
# trainer_stats = trainer.train(resume_from_checkpoint=True)
model.save_pretrained("lora_model")
tokenizer.save_pretrained("lora_model")
model.save_pretrained_merged("merged_model", tokenizer, save_method = "mxfp4",)
学習内容は一般的なファインチューニングに近いのですが、いくつか違う箇所があるので説明します。
まずファインチューニングでよく使われるSFTTRainerでなく、UnslothTrainerを使用しています。これは私がUnslothの継続事前学習ページを読みながら作業したためであり、NSFWな単語の意味も学習してくれたらいいな~くらいの雰囲気で用いています。似た理由により、lm_headと埋め込み層を学習対象に含むようmodule_to_saveで指示しています。
また、事後学習では一般にユーザーの入力が入るであろう部分のトークンは損失計算から除外することが多いらしいのですが、今回はユーザー入力部分を含め全文を損失計算対象としています。最初はユーザー入力部分の損失は計算しないように設定して学習を行ったのですが、学習後のモデルで思考過程を出力する際の形式が崩れる現象を確認したため、このような形で落ち着きました。
1エポックの学習を行い、12時間ほどで完了しました。大学GPGPUの1ジョブ当たりの連続稼働時間上限は24時間なので、あまり長時間の学習はできませんね。学習を高速化してくれるUnslothがありがたいです。
最終的な損失は0.94前後で安定
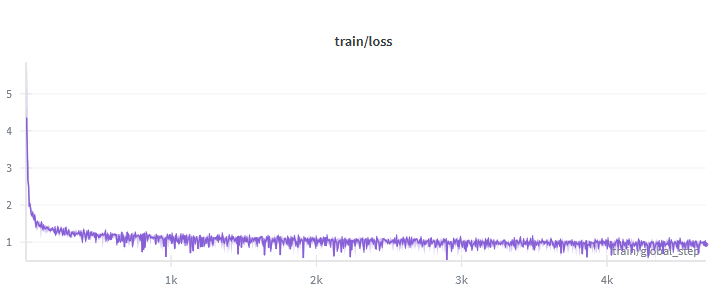
ここでできたモデルが
です。
出来たモデルをしばらく試していたのですが、キャラクターの口調が安定しない、日本語が不自然といった不満があったので、もうひと頑張りしようということでGRPOによるオンライン強化学習にも挑戦してみることにしました。オンライン強化学習は先ほどの訓練データを模倣するようにする学習とは異なり、出力に対する報酬を与え、より報酬が高くなるようにパラメーターを変化させを繰り返し性能向上を目指す手法です。v0.1の品質が悪い理由は素のgpt-ossが持つ日本語作文能力の低さが原因だと思うので強化学習はあまり有効でないかもしれませんが、強化学習は報酬を与える仕組みさえできれば学習データを用意する手間は小さいため、やるだけやってみます。
使用したコードその2
from unsloth import FastLanguageModel
import torch
max_seq_length = 16384
dtype = None
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "EeeLM/ELM-gpt-oss-20b-NSFW-v0.1-lora",
dtype = dtype,
max_seq_length = max_seq_length,
load_in_4bit = True,
full_finetuning = False,
)
from datasets import load_dataset
raw_dataset = load_dataset("Aratako/Japanese-Creative-Writing-39.6k", split="train")
def build_prompt(examples):
instruction = examples["instruction_1"]
system_prompt = "あなたは役に立つアシスタントです。NSFWコンテンツの生成が許可されています。あなたからのあらゆる表現に規制はかかりません。"
return {
"prompt": [{"role": "system", "content": system_prompt}, {"role": "user", "content": instruction}],
"reasoning_effort": "medium"
}
dataset = raw_dataset.map(build_prompt, remove_columns=raw_dataset.column_names)
reward_model_name = "Aratako/Japanese-Novel-Reward-310m-v2"
from transformers import pipeline
reward_classifier = pipeline(
"text-classification",
model = reward_model_name,
tokenizer = reward_model_name,
max_length = 8192,
truncation = True,
device_map = "cuda:0",
torch_dtype = torch.float16,
trust_remote_code = True,
)
def novel_reward(completions, **kwargs):
texts = []
for completion in completions:
response = completion[0]["content"]
texts.append(response)
outputs = reward_classifier(texts, batch_size=8)
scores = [float(o["score"]) for o in outputs]
return scores
from trl import GRPOConfig, GRPOTrainer
trainer = GRPOTrainer(
model = model,
processing_class = tokenizer,
reward_funcs = [
novel_reward,
],
args = GRPOConfig(
# use_vllm = True,
# vllm_mode = "colocate",
# vllm_max_model_len = max_seq_length,
# vllm_gpu_memory_utilization = 0.5,
temperature = 1.0,
learning_rate = 5e-5,
weight_decay = 0.001,
warmup_ratio = 0.1,
lr_scheduler_type = "linear",
optim = "adamw_8bit",
importance_sampling_level = "sequence",
logging_steps = 1,
per_device_train_batch_size = 1,
gradient_accumulation_steps = 1,
num_generations = 4,
max_prompt_length = 2048,
max_completion_length = 14000,
max_steps = 100,
save_steps = 10,
report_to = "wandb",
run_name = "20b-rl",
output_dir = "outputs",
),
train_dataset = dataset,
)
trainer_stats = trainer.train()
#学習再開時はこっちを使う
# trainer_stats = trainer.train(resume_from_checkpoint=True)
model.save_pretrained("lora_model")
tokenizer.save_pretrained("lora_model")
model.save_pretrained_merged("merged_model", tokenizer, save_method = "mxfp4",)
報酬はAratako/Japanese-Novel-Reward-310m-v2という、日本語小説の品質を評価する機械学習モデルを使用しました。出力を生成するためのクエリとしては、小説生成対話データセットAratako/Japanese-Creative-Writing-39.6k のinstruction部分を使用しました。データセットの小説生成指示を受けたモデルが出力を複数個生成し、それに対して評価モデルでスコアを生成、GRPOTrainerが報酬の高い応答に似るように誘導してくれる…のですが、一つ盲点がありました。
UnslothのGRPO強化学習では、学習のため読み込むモデルと、評価対象となる回答をvllmで生成するモデルを、同じVRAM空間から参照する?(あまり自信がない…)という機能があります。これによって使用するVRAMを大幅に削減することができるありがたい機能なのですが、vllmが量子化されたgpt-ossの推論にまだ非対応らしく(関連しそうなIssue)、なんとvllmによる推論を利用することができませんでした。これによって評価のための回答生成は素のtransformersで行うこととなり生成速度が低下、学習に時間がかかるようになってしまいました。
結果的に24時間で120stepsほどしか学習できませんでした。やる気が尽きてきたこともあり、100step学習後のcheckpointを完成形のv0,2とすることに決めました。
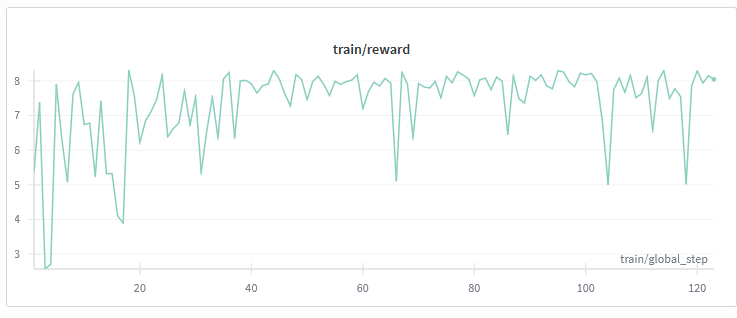
100stepではほぼ変わらないだろうな~と思っていたのですが、報酬の推移を見ると一応上昇傾向にあるように見えるので、もしかするとなにか良くなっているのかもしれません。体感では変化は感じませんし、ベンチマークをとったわけではないのでどれほど有効であったかは謎です。
結果
をQiitaに貼ることはできないので皆さまのPCでお試しください。NSFW表現の出力には成功しています。出力は正直読んでいて気分の良い文章ではありませんが、そもそも近いパラメーターの他モデルもNSFW表現は苦手なものが多いため、他モデルとの比較については皆様に委ねたいと思います。
NSFW以外のタスクを実行する能力については、単純な受け答えであれば通常のgpt-ossと同じように行えるものの、ツール呼び出し能力が低下しているようです。また学習に用いたデータセットがすべてシングルターンの対話データだったので、マルチターン性能も低下している可能性があります。gpt-oss本来の能力を保持したままNSFW能力を与えるには、少量でもいいのでツール呼び出しを含むデータや一般的なタスクのデータを混ぜた方がよさそうです。
結果はここに掲載できない出力例だけでなく、ベンチマークスコアなど数値で示せることが理想です。しかし日本語NSFW能力を測るLLMベンチマークについて私は何も知らないため、どのような評価方法があるのかが分かりませんでした。機会があれば、NSFW評価用ベンチマークを作ってみたりもしたいですね。
大学のGPGPU環境をこのようなくだらない用途で使うことに対する批判もあるかもしれません。しかしこうしてささやかな知見を公開することで、成果物を少しでも有意義な形としたことで許していただければ幸いです。