必要な情報をすべて見つけ出し、より多くの利益を得る方法があるかどうか、疑問に思ったことはありませんか? Web Crawler(ウェブクローラー)は、そのような素晴らしいツールです。 インターネット上の膨大なデータを体系的に閲覧し、クロールできるだけでなく、無限のビジネスチャンスをもたらします。eコマースウェブサイトにおける価格情報のリアルタイムアクセスや競合他社の動向のモニタリングなど、ウェブクローラーはお客様のデータ収集効率を大幅に改善し、競合他社に対する優位性を獲得するお手伝いをいたします。
クローラとは何ですか?何ができるのですか?
ウェブクローラ(ウェブスパイダー、ウェブロボット、自動インデクサとも呼ばれる)は、インターネット上のウェブページを体系的に閲覧し、ウェブスクレイピングを行う自動スクリプトまたはプログラムです。
簡単に言えば、ウェブクローラーはロボットのようなものです。一連のルールを設定するだけで、そのルールに従ってウェブページを自動的に閲覧し、必要なあらゆるデータを収集できるため、人件費を大幅に削減できます。
ウェブクローラーは、ユーザーが最も安い航空券を見つけられるよう、すべての航空会社のウェブサイトを巡回することができます。また、電子商取引、医療、不動産などの分野でも、データをリアルタイムで巡回することができます。ウェブスクレイピングに加えて、ウェブクローラーは、ユーザーがチケットを予約したり、さまざまなプラットフォームにログインしたりするのを助けるためにデータを送信することができます。また、世間で話題になっているホットなトピックを分析したり、投資判断を助けるために株式市場のデータを収集したりすることもできます。これらの業界の市場価値は数十億ドルに達しています。
検索エンジンの重要な一部として、クローラーの主な機能はウェブデータをクロールすることです。現在、市場で人気の高い収集ソフトウェアは、ウェブクローラーの原理や機能を利用しています。
多くの企業がウェブクローラ技術を利用することで、データ収集の効率化だけでなく、ユーザーに高品質な情報サービスを提供することで、大きなビジネス上の利益を実現しています。では、この技術をどのようにプロジェクトに適用すればよいのでしょうか?
クローラで収益を得るにはどうすればよいのでしょうか?
クローラの価値は、まさにデータの価値です。まず、数百の競合他社と競争しなければならない再販業者やeコマース販売業者を想像してみてください。価格と在庫は、主な競争優位性となります。リアルタイムの情報にアクセスし、競合他社が価格を引き下げたり在庫切れを起こした場合に価格を調整できれば、大幅な利益につながります。しかし、ほとんどの企業は情報へのアクセスを禁止しており、APIが提供されている場合でも、レート制限、時代遅れのデータ、その他の問題により、システムの関連性が損なわれる可能性があります。そのため、ウェブクローラーを構築して、代わりに処理する必要があります。
また、爬虫類は次の業界でも収益をもたらす可能性があります。
爬虫類のアウトソーシングの仕事を探す
ウェブスクレイピングで収入を得る最も一般的な方法は、ウェブサイトのアウトソーシング、小規模および中規模のクロールプロジェクトの実施、A 当事者へのウェブスクレイピング、データ構造化、データクリーニングなどのサービスの提供です。 新しいプログラマーのほとんどは、まずこの方向性を試み、直接的に技術的手段に頼って収入を得ようとしますが、技術者にとっても最善の方法ですが、あまりにも多くの競合相手がいるため、価格はそれほど高くはないかもしれません。
ウェブサイトのデータ収集
Pythonクローラーでデータをクロールしてウェブサイトを作成し、収入を得ることができます。収入はあまり客観的ではありませんが、作成後はあまりメンテナンスを必要としないため、不労所得を得られるとも考えられます。
社会人学生
あなたが社会人学生、数学やコンピュータ関連の専門家であれば、プログラミング能力は大丈夫です。クローラライブラリ、HTMLの解析、コンテンツの保存など、少しプログラミングの知識があれば、複雑なURLのランキング、ログインのシミュレーション、CAPTCHAの識別、マルチスレッドなどの理解も必要です。この部分の エンジニアリング経験は比較的少ないですが、クローラで稼ぎたいのであれば、少数のデータキャプチャを探すことができます。クローラで稼ぎたいのであれば、少量のデータキャプチャプロジェクト、少しの経験を見つけることができます。いくつかの監視プロジェクトや大規模なキャプチャプロジェクトに挑戦することができます。
現職者
ご自身でPythonのウェブクローラーの作業に従事している場合、お金を稼ぐのは非常に簡単です。現職者はプロジェクト開発プロセスに精通しており、エンジニアリングの経験も豊富で、タスクの難易度、時間、費用を合理的に評価できるため、大規模なクロールタスク、監視タスク、モバイルシミュレーションログインおよびクロールタスクなどを見つけ、収益を上げることができます。
実際にウェブクローラーを運用するにはどうすればよいのでしょうか?
私は、Eコマースのマーケットプレイスで商品をスキャンし、価格の変動を自動的に追跡し、機会を最大限に活用するために調整を行うようアラートを出す自動ウェブクローラーを見つけました。DrissionPageのような人気の高いフレームワークを使用して、ウェブサイトを訪問し、商品をスキャンし、HTMLを解析し、価格を取得してデータベースに保存し、価格が変更されているかどうかを確認します。
時間間隔を設定して、毎日、毎時間、または必要に応じて毎分ごとに自動的にスキャナーを実行するようにしています。ご覧の通り、私はEコマースの価格を分析し、毎日Amazonで自動的に商品を入手する商品検索ツールを持っています。商品の追跡を有効または無効にしたり、新しい商品を追加したり、価格を表示したりすることができます。
この自動ウェブクローラーを PyCharm で操作するのはとても簡単です。まず、PyCharm をダウンロードし、新しいプロジェクトを作成して、新しいプロファイルを作成するように選択してください。
次に、PyCharmのターミナルで仮想プロファイルを有効化し、必要なパッケージをインストールするために、pip install DrissionPagetoを実行します。次に、プロジェクトディレクトリを右クリックし、新規 > Python ファイルを選択して、新しいPythonファイル(例:main.py)を作成し、そのファイルに上記のコードをコピー&ペーストします。最後に、main.pyファイルを右クリックして「Run 'main'」を選択するか、ショートカットキーのShift + F10を使用してスクリプトを実行し、ターミナルに表示される結果を確認し、プロジェクトディレクトリに生成されたdata.jsonファイルとscraper.logログファイルを見つけます。
import time
from DrissionPage import ChromiumOptions
from DrissionPage import WebPage
import json
import logging
# Configure logging
logging.basicConfig(filename='scraper.log', level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
try:
co = ChromiumOptions()
co.headless()
page = WebPage(chromium_options=co)
page.get("https://www.amazon.com/")
page.ele("#twotabsearchtextbox").click()
keyword = input("Please enter a keyword and press Enter: ")
page.ele("#twotabsearchtextbox").input(keyword)
page.ele("#nav-search-submit-button").click()
goods_eles = page.eles('xpath://*[@id="search"]/div[1]/div[1]/div/span[1]/div[1]/div')
logging.info("Starting data scraping...")
data = []
for goods_ele in goods_eles:
if not goods_ele.attrs['data-asin']:
continue
goods_name = goods_ele.ele('xpath://h2/a/span').text
goods_href = goods_ele.ele('xpath://h2/a').link
goods_price_ele = goods_ele.eles('xpath:/div/div/span/div/div/div[2]/div/div/span[2]')
if len(goods_price_ele) == 1:
goods_price = goods_price_ele[0].text
elif len(goods_price_ele) > 1:
goods_price = goods_price_ele[1].text
else:
continue
if '$' not in goods_price:
continue
logging.info(f"Product Name: {goods_name}")
logging.info(f"Product Price: {goods_price}")
logging.info(f"Product Link: {goods_href}")
logging.info('=' * 30)
data.append({
"name": goods_name,
"price": goods_price,
"link": goods_href
})
logging.info('Data scraping completed')
Save data to file
with open("data.json", "w", encoding="utf-8") as f:
json.dump(data, f, ensure_ascii=False, indent=4)
logging.info("Data has been saved to data.json")
except Exception as e:
logging.error("An error occurred:", exc_info=True)
PyCharmが「実行」をクリックした後。 *キーワードを入力:検索するキーワードを入力します。 *データ収集:スクリプトがAmazon.com上のキーワードに関連する製品情報を検索し、収集します。 *データ保存:収集したデータはdata.jsonファイルに保存され、ログ情報はscraper.logファイルに保存されます。
Amazonのブレスレットをクロールする例を以下に示します。
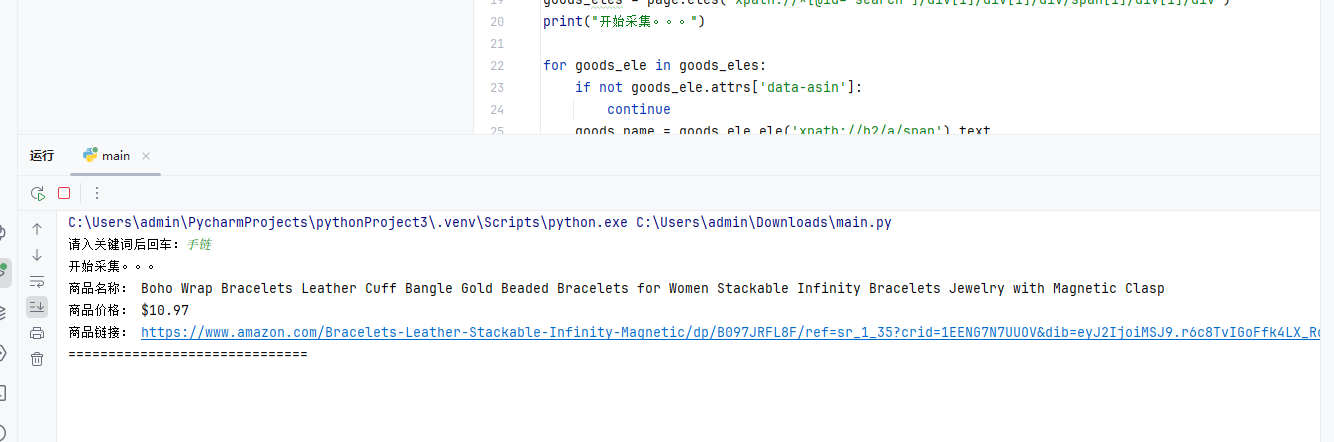
画像をクリックすると、商品の詳細をご覧いただけます。
しかし、クローラーを実行していると、サイトにブロックされてしまうことがよくあります。どうすればよいでしょうか?
ウェブクローラーの課題と対策:ブロックされないクロール方法とは?
試すたびに、多くのサイトはボットを検知するのに十分なほど賢く、CAPTCHAを設置してデータのクロールを阻止しています。IPブロックやCAPTCHAなど、クロール防止策を講じているサイトも多く、こうした「障壁」はクロールの効率や収益性に影響を与えます。何度も試した結果、サイトがブロックされてしまいます。この問題の解決策は何でしょうか?
今回は、Residential Proxies(住宅用プロキシ)を利用して操作することができます。プロキシの原理は非常にシンプルです。サーバーに送信するリクエストがある場合に、私たちはサイトをクロールします。直接アクセスすると、サーバーは私たちのIPアドレスを知ることになります。訪問回数が多すぎると、アクセス禁止になりますが、私たちはまずProxy Service(プロキシサービス)に送信し、プロキシサービスがリクエストの送信を支援します。そうすれば、クロールされるサイトに私たちのIPが知られることはありません。
ここで私が推奨するのは、私が長年利用しているPROXY.CCです。このプロキシには3つのタイプがあります。ローテーション・レジデンシャル・プロキシ、無制限トラフィック用プロキシ:
ローテーティング・レジデンシャル・プロキシは、各レジデンシャルIPが選択可能な国と都市であるローテーティング・プロキシです。これにより、ユーザーは正確な地理位置情報と情報へのアクセスを効率的かつ安全に行うことができます。 スタティック・レジデンシャル・プロキシは固定された実際のレジデンシャルIPを提供し、ユーザーが同じIPを長期間使用することを保証し、アクセス安定性とセキュリティを向上させ、ユーザーの実際のIPを隠します。
無制限トラフィックプロキシは、効率的かつ安全なプロキシによる情報へのアクセスを保証し、ユーザーの実際のIPアドレスを隠すために、住宅用プロキシに無制限のトラフィックを提供します。大量のトラフィックを必要とする作業に最適です。大規模なデータクロールや自動テストを行う必要があり、国や都市の所在地に要件がない場合は、このパッケージを強くお勧めします。フローごとの課金コストを大幅に削減できます。
自動的にウェブサイトをアンロックし、プロキシに接続し、IPアドレスをローテーションし、CAPTCHAを解読し、手間のかからないウェブクローラーを実現します。PROXY Web Scraping。
また、無制限の同時セッションも可能で、つまり、数百のクローラーインスタンスを同時に実行でき、単一またはローカルマシンの処理に限定されません。PROXY.CCについてさらに詳しく知りたい方は、リンクをクリックしてPROXY.CCの強力な機能をご確認ください。また、カスタマーサービスに連絡することで、初回登録時に500MBの無料トラフィックを入手できます。PROXY.CC 住宅用プロキシチュートリアル
私はここでResidential Proxiesを購入しました。生成されたプロキシの内容をこの場所に追加するだけです。私はAPI抽出を使用しており、抽出結果は[5.78.24.25:23300]と想定されます。
オリジナルコード:
try:
co = ChromiumOptions()
co.headless()
page = WebPage(chromium_options=co)
page.get("https://www.amazon.com/")
page.ele("twotabsearchtextbox").click()
keyword = input("Please enter a keyword and press Enter: ")
page.ele("twotabsearchtextbox").input(keyword)
page.ele("nav-search-submit-button").click()
goods_eles = page.eles('xpath://*[@id="search"]/div[1]/div[1]/div/span[1]/div[1]/div')
logging.info("Starting data scraping...")
co = ChromiumOptions()
co.headless()
# co.set_proxy("http://5.78.24.25:23300")
page = WebPage(chromium_options=co)
# page.get("https://api.ip.cc/")
page.get("https://www.amazon.com/")
# time.sleep(5)
# page.get("https://www.amazon.com/s?k=fender+guitar")
# print(page.html)
page.ele("#twotabsearchtextbox").click()
keyword = input("Please enter a keyword and press Enter: ")
page.ele("#twotabsearchtextbox").input(keyword)
page.ele("#nav-search-submit-button").click()
goods_eles = page.eles('xpath://*[@id="search"]/div[1]/div[1]/div/span[1]/div[1]/div')
print("Starting data scraping...")
 結論
実際には、ウェブクローラー技術は多くの企業や個人がデータ収集を自動化し、作業効率を向上させ、多くの時間とコストを節約するのに役立っています。しかし、クローラーは、IPブロックやCAPTCHA認証など、ウェブサイトの反クローリング対策にしばしば遭遇します。この時点で、PROXY.CCなどのResidential Proxiesを使用して、これらの問題を解決することができます。プロキシサービスを利用することで、クローラはIPアドレスを隠してブロックを回避し、スムーズにデータ収集を行うことができます。PROXY.CCでは、ローテーティング・レジデンシャル・プロキシ、スタティック・レジデンシャル・プロキシ、アンリミテッド・トラフィック・プロキシなど、さまざまなプロキシモードを提供しており、ユーザーのニーズに合わせて選択できます。特に大規模なデータを収集する必要があるユーザーにとっては、トラフィック無制限のプロキシを利用することで、コストを大幅に削減することができます。
結論
実際には、ウェブクローラー技術は多くの企業や個人がデータ収集を自動化し、作業効率を向上させ、多くの時間とコストを節約するのに役立っています。しかし、クローラーは、IPブロックやCAPTCHA認証など、ウェブサイトの反クローリング対策にしばしば遭遇します。この時点で、PROXY.CCなどのResidential Proxiesを使用して、これらの問題を解決することができます。プロキシサービスを利用することで、クローラはIPアドレスを隠してブロックを回避し、スムーズにデータ収集を行うことができます。PROXY.CCでは、ローテーティング・レジデンシャル・プロキシ、スタティック・レジデンシャル・プロキシ、アンリミテッド・トラフィック・プロキシなど、さまざまなプロキシモードを提供しており、ユーザーのニーズに合わせて選択できます。特に大規模なデータを収集する必要があるユーザーにとっては、トラフィック無制限のプロキシを利用することで、コストを大幅に削減することができます。