本記事は「求ム!Pythonを使ってAzureで開発する時のTips!【PR】日本マイクロソフト Advent Calendar 2020」の17日目の記事です。空いていた枠に後日投稿しました。
Azure Machine Learning という機械学習周りの広い範囲をカバーするサービスがあります。Azure Machine Learning はデータセット管理からモデルの開発、実験の管理、モデルの管理、デプロイまで、機械学習モデルの開発に必要なほぼほぼ全ての工程をこなすことができるサービスですが、本記事ではAzure Machine Learning の機能の一部、実験管理とモデル管理部分をインターネットに接続可能な任意の Python 開発環境と組み合わせる方法を検証しつつ紹介します。
ただし、Azure Machine Learning の機能を素の状態では使用しません。最も広く使われてい実験管理ツールである MLflow のバックエンドとして Azure Machine Learning を使用していきます。
機械学習モデルの開発を本格的に始めると実験・モデルの管理に頭を悩ませることになるかと思うのですが、そのときに1つの例として参考にして頂ければ幸いです。
(2020/12/29追記)
モデルを API としてデプロイする手順を加えました。こちらは Azure Machine Learning に依存的です。
環境
これまで
機械学習用に作った GPU 搭載の Linux 機に JupyterLab 環境を用意し、メイン PC から接続して使っていました。
コード管理こそある程度Githubを活用していますが、恥ずかしながら、実験管理については面倒でやっておらず、結局ハイパラコメント&ノートブックコピー&ファイル名へのハイパラ挿入で実験管理をしておりました。できあがったモデルの管理も杜撰なもので、「model_adam_lr_0001_lstm_3_layer_e_512_h_1024.model」みたいなヤバい名前をつけておりました……。
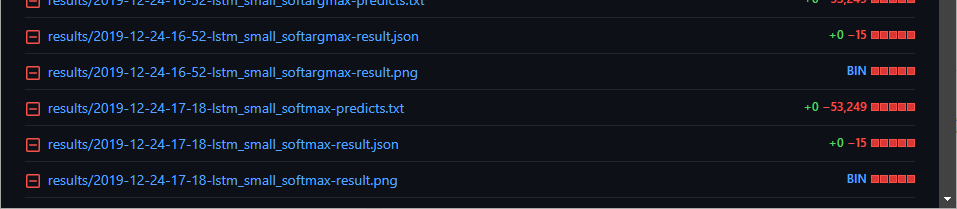
これは修論提出の直前、余裕が消失した大学院生の僕が雑な実験記録をした挙げ句何を思ったかファイルごと全部 GitHub に上げてしまい、その後全部削除したことを示す図です。
もう最終層に softmax 関数を使ってそうなことぐらいしかわからないですね……我ながらこれは酷い……。「model_adam_lr_0001_lstm_3_layer_e_512_h_1024.model」がマシに見えてきた……。
こんなやり方なので当然「あれ、あの時のハイパラどうだったっけ」とか「あ、間違えて既存のファイル上書きしちった」とか「出力した辞書なくした」とかポカが発生していました。
これから
既存の環境に実験管理、モデル管理を行えるツールを追加することでこれまでの杜撰な実験管理体制を改めたいと思います。なお検証自体は Jupyter 環境で行いますが、本記事の方法はインターネットにつながる Python 環境ならどこでも同じように使用できるはずです。
実験管理ツールとして広く使われているツールといえば MLflow です。
https://mlflow.org/
MLflow は開発環境側で使用するライブラリと、実験やモデルを記録するためのサーバーから成るようです。サーバーは REST API を提供し、ライブラリはこの API を使用するという関係です。MLflow のサーバーをローカルに建ててローカルから使用すると最も簡単に使用できますが、管理下の実験やモデルが開発環境と共倒れになるような状態は好ましくありません。別にサーバーを建てると共倒れは回避できますが、コンテナを使うとしても認証系の用意や MLflow サーバーのバックエンドとなる DB の管理、システム全体の管理が非常に面倒です。
マネージドサービスとしての MLflow があったらいいなぁと思って探していると、現状 Databricks がその一部として完璧な MLflow のマネージドサービスを提供してていることと、Azure Machine Learning が MLflow の API コールを受け入れられる互換機能を持っていることが分かりました。
https://databricks.com/jp/product/managed-mlflow
https://docs.microsoft.com/ja-jp/azure/machine-learning/how-to-use-mlflow
まずは実験管理とモデル管理ですが、最終的に API として機械学習モデルをデプロイしたり、あわよくば MLOps に繋げていきたいという下心もあるので、コンテナサービスとの連携が強力でプロダクションレベルのモデルデプロイができる Azure Machine Learning を MLflow のサーバーとして利用するスタイルを採用します。
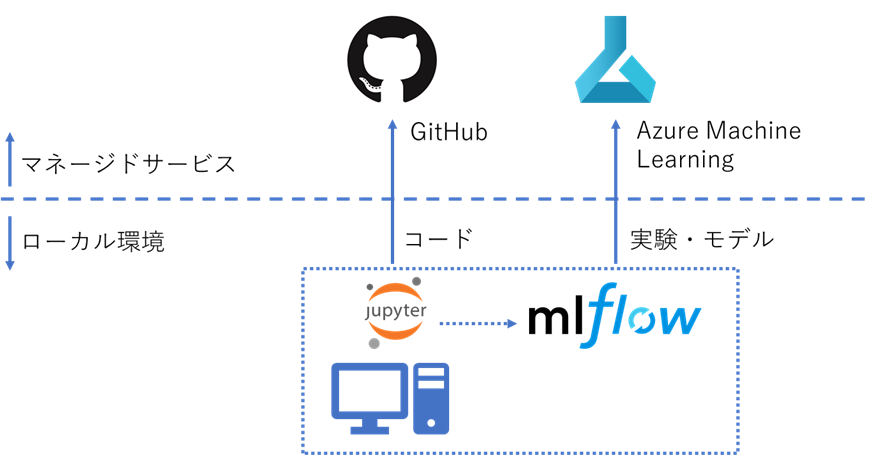
目指す姿はこんな感じです。
Azure Machine Learning は Python SDK を持っているので、それを使っても実験管理やモデル管理は実現できるでしょうが、あえて MLflow を使用します。MLflow は Azure Machine Learning やその他の実験管理ツールと比べると普及率が高く、ノウハウが豊富な印象です。ノウハウが豊富ということは問題発生時の解決や使い方で疑問が生じた場合に解決できる可能性が高まりますし、初めて実験管理ツールを導入する場合にはやはりこのネット上と先達に蓄積されたノウハウは大きな魅力となります。
サービス理解
Azure Machine Learning
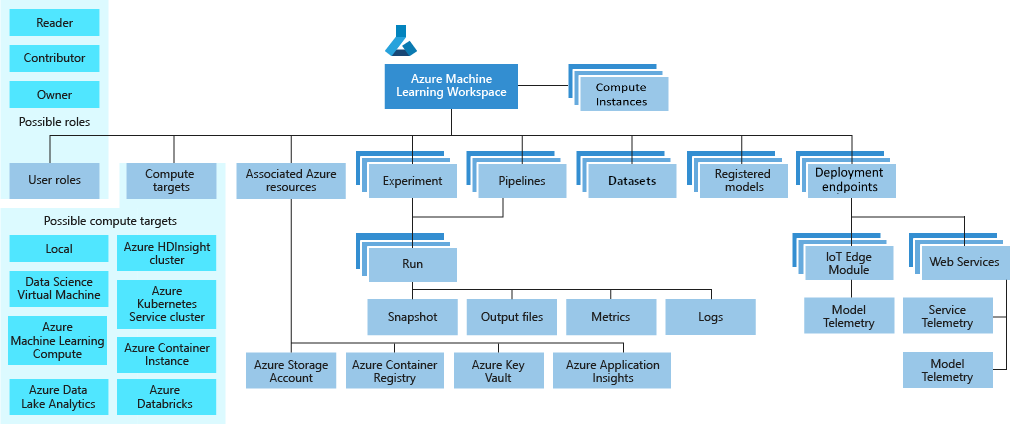
ドキュメント1にあったこの画像がわかりやすいのでこちらを起点に理解していきます。
最上位リソースとして Workspace が存在し、その配下に実験管理の Experiment 、モデル管理の Registerd models 、 デプロイの Deployment endpoints 等の各種コンポーネントが存在しているようです。
このうち Experiment が1つの実験を管理する単位で、Experiment の配下の Run は1回1回の実験の実行を管理する単位です。1つの Run のは以下にはさらに各種ファイルやメトリクス、ログなどをまとめたものです。
Pipelines というのは外部サービスと連携しての処理をこなすコンポーネントで、今回は使用しないので詳細は割愛します。
Datasets はデータソースから作ったデータセットを管理するコンポーネントで、こちらも今回は使用しませんが、再現性観点からはデータセットも記録した方が良いのでいつか組み入れたいものです。
Registerd models は読んで字の如く、モデルの管理コンポーネントです。
Azure Machine Learning Studio という GUI 環境があるので、これを使うことで GUI で管理下の実験やモデルを参照することができます。
MLflow
ドキュメント2によれば、 MLflow は以下4つのコンポーネントで構成されています。
- MLflow Tracking
- MLflow Projects
- MLflow Models
- MLflow Registry
Tracking はパラメーターやメトリックの記録や実行履歴の管理を担っているので、今回行いたい「実験管理」というのは Tracking の領分ということになります。
Tracking で管理する実験の1つ1つは experiment という単位で管理され、experiment は配下に run という単位を持っています。run には1回1回の実験実行で生じたファイルやログ、メトリック等が記録されます。このうちファイルは artifact と呼ばれています。僕の場合だとよくモデル本体以外にもログのバックアップやグラフを画像出力したものを作っているので、こういうものも管理できるのはありがたいです。
これまで MLflow のサーバーと呼んでいたコンポーネントは正しくは MLflow Tracking Server という名称で、API を提供する他 GUI による実験やモデルの参照・管理機能を提供しています。
Projcts が学習処理をどう行うかという環境情報を記録するもので、要するに実験の再現性を確保するために必要なものをひとまとめにしてどこでも実験を実行可能にするためのコンポーネントです。「機械学習の実験」というものを抽象化する機能とでも言えそうです。再現性確保の要になりそうです。
Models が学習済みモデルの管理を担当していて、このコンポーネントが「モデル管理」を担います。
Azure Machine Learning と MLflow の関係
Azure Machine Learning ワークスペースは MLflow 互換の REST API を提供しています。厳密には Azure Machine Learning が MLflow Tracking Server 互換の API コールを受け付けるエンドポイントを備えていて、MLflow のライブラリでこのエンドポイントにアクセスして記録を行うと、Azure Machine Learning の機能に対してマッピングされるという構造を取っています。記録の保存の仕方などは MLflow と全く同じというわけではないですが、Python を書いて機械学習モデルの開発を行う側が行う操作は純正 MLflow でも Azure Machine Learning でも原則同じです。
MLflow と全く同じ GUI が提供されるわけではなく、GUI で実験の様子管理したい場合は Azure Machine Learning Studio を使う必要があります。
Azure Machine Learning では Experiment が 実験管理を担当するコンポーネントですが、このコンポーネントが MLflow Tracking と対応しています。MLflow ではあるモデルの実験全体を表す Experiment という単位に、1回の実験実行に相当する Run を実験回数分収めてます。この構造は Azure Machine Learning でも同じで、対応が取れています。
MLflow Projects が担う環境情報の管理もAzure Machine Learning の Experiment の領分のようですが、Tracking とは異なり MLflow Projects で定義した1つのプロジェクトを構成する各種ファイルや設定がどこかに格納されるというわけではないようです。Azure Machine Learning では複数のコンピューティングリソースを管理下に入れることができ、実験をどのコンピューティングリソースで実行するか決めて実験を実行できる機能を備えていますが、このときどんな環境でも実験を行えるようスクリプトや依存関係などをひとまとめにしておく必要があり、この「ひとまとめにした実験」が MLflow Projects のプロジェクトと互換性を持っているということのようです。
プロジェクトの管理は GitHub でも良さそうな気配です。
MLflow Models が担うモデル管理は MLflow 互換のモデル定義に対応している Registerd models が担います。
試してみた
事前にやること
GPU 付きのインスタンスを使いたい場合、事前にサポートリクエストからクォータ (使用できるリソースの枠) 申請をしなければなりません。また、通常の仮想マシンと Azure Machine Learning 配下のインスタンスでは異なる枠が設定されているので、今回本記事では使用しませんが Azure Machine Learning で GPU インスタンスを使いたい場合はそちらのクォータ申請も必要です。
(Data Science VM のデプロイ)
使っている GPU 搭載機の調子が非常に悪く、いい機会なので Azure 上に GPU 付きの VM をデプロイしてそちらに一時的に移行しようと思います。オンプレ GPU マシンはロマンなので再構築したらまた戻ろうとは思っていますが、データを失うと本当に辛いので今回はクラウド上のJupyterLab環境を使っていきます。
Data Science Virtual Machine というデプロイ即 JupyterLab を使用できる VM イメージがあるのでこちらを使用します。典型的な Python 環境の構築にかかる手間が、わずか2クリック……。
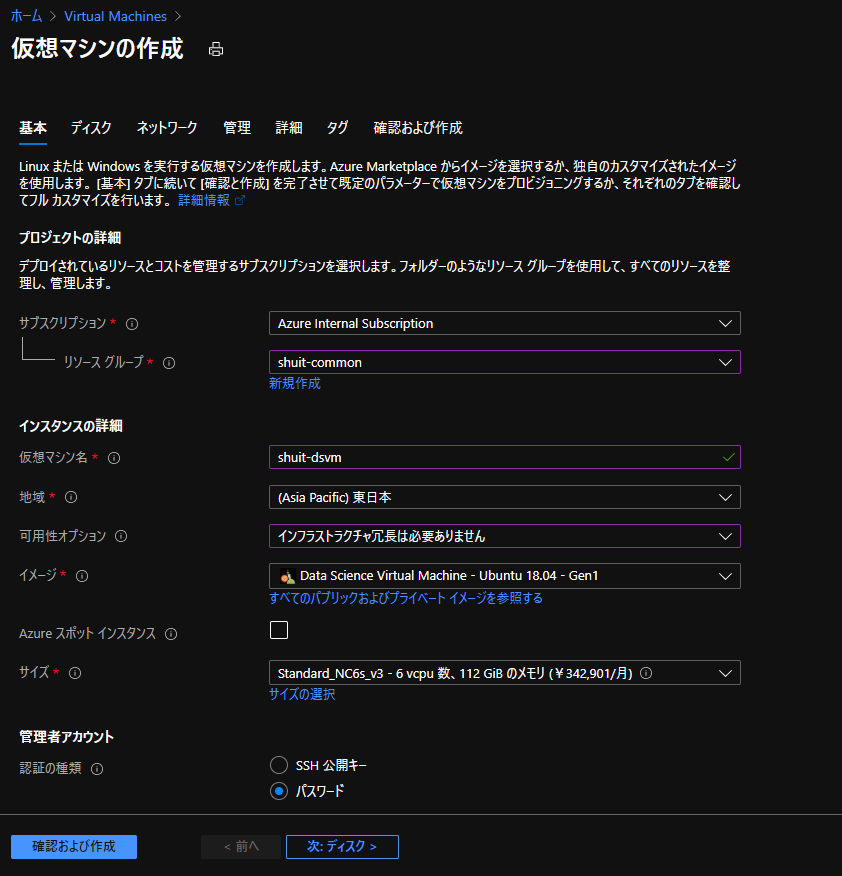
Tesla V100 を搭載している NC v3 系インスタンスを使用しています。140万円の GPU を1時間数百円で使えるなんていい時代ですね。
注意点として、可用性オプションがデフォルトではゾーン1に設定されていましたが、Data Science Virtual Machine は可用性オプションに対応してないようで、どのゾーンを指定してもエラーが出たので「インフラストラクチャ冗長は必要ありません」に変更しています。コードは GitHub に、実験記録やモデルについては Azure Machine Learning に任せる予定なので、計算環境は最悪死んでも構いません。
また、ログインに JupyterHub を使う関係上アカウントはユーザー名&パスワードの方が都合が良いので認証の種類を「パスワード」に変更しています。
ディスクやネットワークの設定はデフォルトのままでいきます。ディスク容量については扱うデータやモデルの規模次第では拡張する必要があるかもしれません。
間違って VM をつけっぱなしにすると非常に財布が辛いことになるので、自動シャットダウンは有効にしました。
https://<VM IP>:8000
で JupyterHub に接続できるので、オレオレ証明書特有のエラー画面を抜けて設定した管理者アカウントでログインすると見慣れた Jupyter Notebook 環境が表示されます。
https://<VM IP>:8000/user/<username>/tree?
のような URL が表示されていますが、ここで
https://<VM IP>:8000/user/<username>/lab
とすると JupyterLab 環境に移ります。デフォルトで JupyterLab を起動させる場合 JupyterHub の設定書き換えが必要と記憶していますが、面倒なので今回はこのままいきます。
Azure Machine Learning のデプロイ
Azure Machine Learning のワークスペースを用意します。
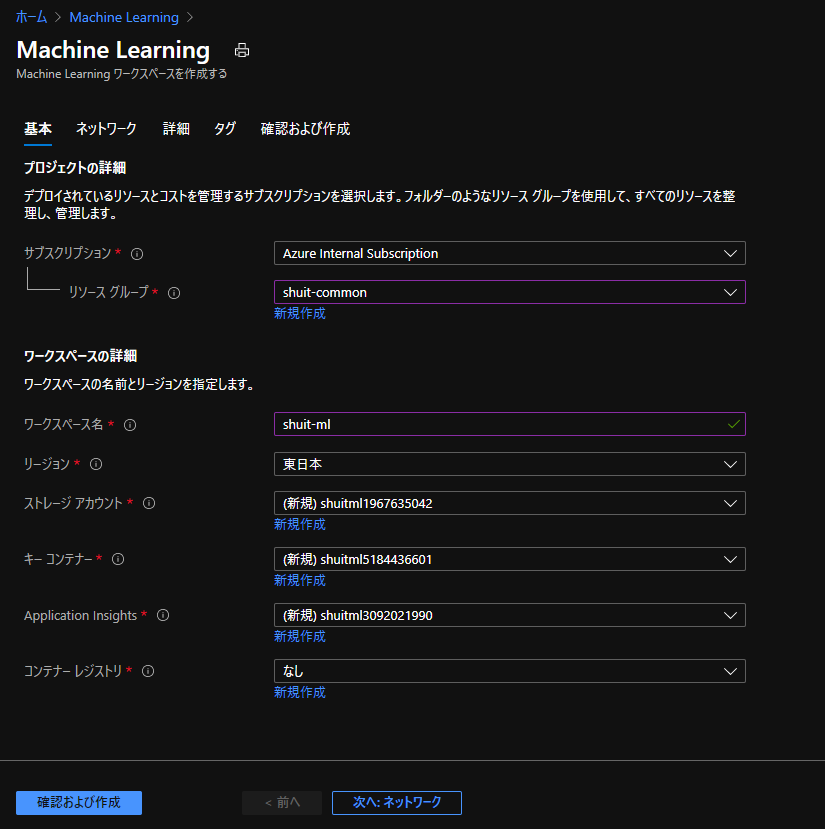
設定を変える必要は特になく、リソースグループとワークスペース名を決めたらそのまま作成に移ります。
デプロイが完了してリソースの画面へ移り、「config.json をダウンロード」をクリックします。これは SDK 越しに作ったAzure Machine Learning ワークスペースに接続するための情報が記載されたファイルです。中身はサブスクリプション ID とリソースグループ名、ワークスペース名です。手動入力でも十分対応できますが、今回はこちらを使用します。
「スタジオの起動」をクリックすると GUI である Azure Machine Learning Studio を使うことができます。
ここから色々と操作できるようです。(今回はデプロイを除いてほとんどコードで操作するのでもっぱら眺めるだけです)
サービスにきれいな UI があるとやる気が出るタイプなので俄然元気になってきました。
Azure Machine Learning Workspace への接続
Data Science Virtual Machine の JupyterLab 環境に移って、 azureml_py36_pytorch というカーネルを使用してノートブックを作ります。(自分で conda の仮想環境を作る場合、azureml と MLflow のインストールさえすれば特に問題はなさそうです)
まずはワークスペースへの接続を行います。先程ダウンロードした config.json をノートブックと同じディレクトリ内にアップロードする必要があります。
MLflow Tracking 互換のサーバーとして利用するので、 MLflow とワークスペースが提供する MLflow 互換エンドポイントの紐付けもついでに行います。
import mlflow
from azureml.core import Workspace
ws = Workspace.from_config()
mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())
認証しろと出ているので提示された URL から認証を済ませます。
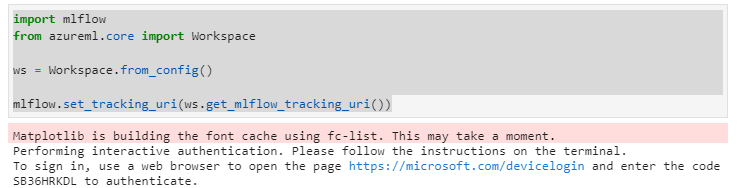
別ウィンドウでの認証を済ませて戻ってくるとセルの実行が完了して認証済みとなっていました。
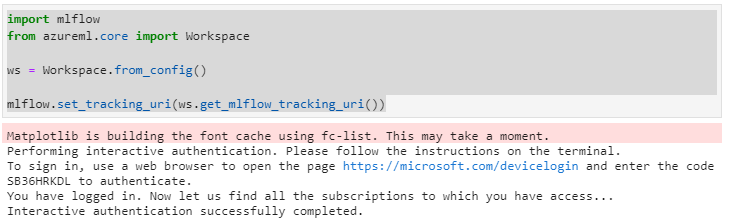
後は基本的に MLflow のライブラリを使っていくので、Azure Machine Learning 特有の部分は GUI で各手順の結果を確認しているところ以外にはほとんど出てこないはずです。既に MLflow に関する知見を持っている人はデプロイまで飛ばしてもいいかもしれませんね。
実験の用意
ボストンの住宅価格データセットを使用して、 PyTorch でニューラルネットワークを組んで価格を予測するモデルを用意してみました。
なお、今回なんとなく最適化手法として AdaBelief を使っています。使ってみたかっただけです。
conda activate azureml_py36_pytorch
pip install adabelief-pytorch==0.2.0
としてパッケージをインストールするか、パッケージインストールが面倒なら Optimizer の部分を
optimizer = torch.optim.Adam(nn_model.parameters(), lr=0.001)
とでもして Adam に置換すれば動きます。
import torch
from torch import nn
from torch.nn import functional as F
import numpy as np
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
import torch.utils.data as Data
from adabelief_pytorch import AdaBelief
import tqdm
from matplotlib import pyplot as plt
from sklearn.metrics import mean_squared_error
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# ハイパーパラメーター
hidden_1 = 64
hidden_2 = 16
batch_size = 16
n_epochs = 20
# データセット
boston = load_boston()
X_train, X_test = train_test_split(boston.data)
y_train, y_test = train_test_split(boston.target)
class BostonData(Data.Dataset):
def __init__(self, X, y):
self.targets = X.astype(np.float32)
self.labels = y.astype(np.float32)
def __getitem__(self, i):
return self.targets[i, :], self.labels[i]
def __len__(self):
return len(self.targets)
train_dataset = BostonData(X_train, y_train)
test_dataset = BostonData(X_test, y_test)
train_loaded = Data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loaded = Data.DataLoader(test_dataset, batch_size=batch_size, shuffle=True)
# モデル
class Model(nn.Module):
def __init__(self, n_features, hidden_1, hidden_2):
super(Model, self).__init__()
self.linear_1 = nn.Linear(n_features, hidden_1)
self.linear_2 = nn.Linear(hidden_1, hidden_2)
self.linear_3 = nn.Linear(hidden_2, 1)
def forward(self, x):
y = F.relu(self.linear_1(x))
y = F.relu(self.linear_2(y))
y = self.linear_3(y)
return y
n_features = X_train.shape[1]
nn_model = Model(n_features, hidden_1, hidden_2)
# 最適化手法と損失関数
criterion = nn.MSELoss(size_average=False)
optimizer = AdaBelief(
nn_model.parameters(),
lr=1e-3,
eps=1e-16,
betas=(0.9,0.999),
weight_decouple = True,
rectify = False,
print_change_log = False
)
# 学習
losses = []
for epoch in range(n_epochs):
progress_bar = tqdm.notebook.tqdm(train_loaded, leave=False)
losses = []
total = 0
for inputs, target in progress_bar:
inputs.to(device)
target.to(device)
optimizer.zero_grad()
y_pred = nn_model(inputs)
loss = criterion(y_pred, torch.unsqueeze(target,dim=1))
loss.backward()
optimizer.step()
losses.append(loss.item())
total += 1
epoch_loss = sum(losses) / total
losses.append(epoch_loss)
mess = f"Epoch #{epoch+1} Loss: {losses[-1]}"
tqdm.tqdm.write(mess)
plt.plot(losses)
MLflow Tracking + Azure Machine Learning による実験管理
MLFlow Tracking のサーバーとしてAzure Machine Learning の Experiment コンポーネントを使用しますが、 ここまで繰り返し述べている通り開発側は MLflow を使用します。
1つの実験を定義します。
experiment_name = 'boston_nn_experiment'
mlflow.set_experiment(experiment_name)
メトリックを追跡する場合、下記のようにwith mlflow.start_run():の内側でmlflow.log_metricを使って記録していきます。
with mlflow.start_run():
mlflow.log_metric('Loss', 0.03)
mlflow.log_metrics関数を使えば辞書型で一括で記録することもできます。
ハイパーパラメーターの記録はmlflow.log_paramかmlflow.log_paramsを使います。単数形だと1個ずつ、複数形だと辞書で一括なのはメトリックの記録と同様です。
params = {
"hidden_1":hidden_1,
"hidden_2":hidden_2,
"batch_size":batch_size,
"n_epochs":n_epochs
}
with mlflow.start_run():
mlflow.log_metrics(params)
実際に実験を実行して記録するときは先程までのコードの下に実行部分を書いていくか、mlflow.start_run()とmlflow.end_run()で実行部分を挟む必要があります。
この程度であれば既存コードも簡単に書き直せそうでいいですね。
生成したファイルの記録はmlflow.log_artifactで行います。今まではローカルのディレクトリに直接書き出していましたが、以後はファイルの管理もMLflow および Azure Machine Learning に任せるわけで、ローカルのファイルを残すと邪魔なので一時ディレクトリを生成してそこにファイルを書き出し、記録後に消えるようにしてみました。
fig = plt.figure()
plt.plot(losses)
with tempfile.TemporaryDirectory() as d:
filename = 'plot.png'
artifact_path = pathlib.Path(d) / filename
print(artifact_path)
fig.savefig(str(artifact_path))
mlflow.log_artifact(str(artifact_path))
学習したモデルの登録はmlflow.pytorch.log_modelを使用します。引数の artifact_path は Azure Machine Learning 側でモデルとその周辺ファイルを保存する先のディレクトリパスとなります。第1引数で指定しているのはモデルのオブジェクトで、自前で pickle やら torch.save をしなくても、勝手にバイナリ形式に変換してくれるみたいです。
mlflow.pytorch.log_model(nn_model,artifact_path="model")
関数名を見ると明白ですが、mlflow.pytorch.log_model以外にも色々とあります。3
log_model と log_artifact で記録したファイルは1まとめに管理されます。もし MLflow が対応していないライブラリを使う場合でも artifact として登録すればとりあえず記録はできます。
ここまでの mlflow の色々を組み込んで、学習部分のコードを下記のように書き換えました。
with mlflow.start_run():
mlflow.log_params(params)
losses = []
for epoch in range(n_epochs):
progress_bar = tqdm.notebook.tqdm(train_loaded, leave=False)
losses = []
total = 0
for inputs, target in progress_bar:
inputs.to(device)
target.to(device)
optimizer.zero_grad()
y_pred = nn_model(inputs)
loss = criterion(y_pred, torch.unsqueeze(target,dim=1))
loss.backward()
optimizer.step()
losses.append(loss.item())
total += 1
epoch_loss = sum(losses) / total
losses.append(epoch_loss)
mess = f"Epoch #{epoch+1} Loss: {losses[-1]}"
tqdm.tqdm.write(mess)
mlflow.log_metric("Loss",losses[-1])
mlflow.pytorch.log_model(nn_model,artifact_path="model")
fig = plt.figure()
plt.plot(losses)
with tempfile.TemporaryDirectory() as d:
filename = 'plot.png'
artifact_path = pathlib.Path(d) / filename
print(artifact_path)
fig.savefig(str(artifact_path))
mlflow.log_artifact(str(artifact_path))
Azure Machine Learning Studio から実験を開いてみると、確かに実験が記録されています。
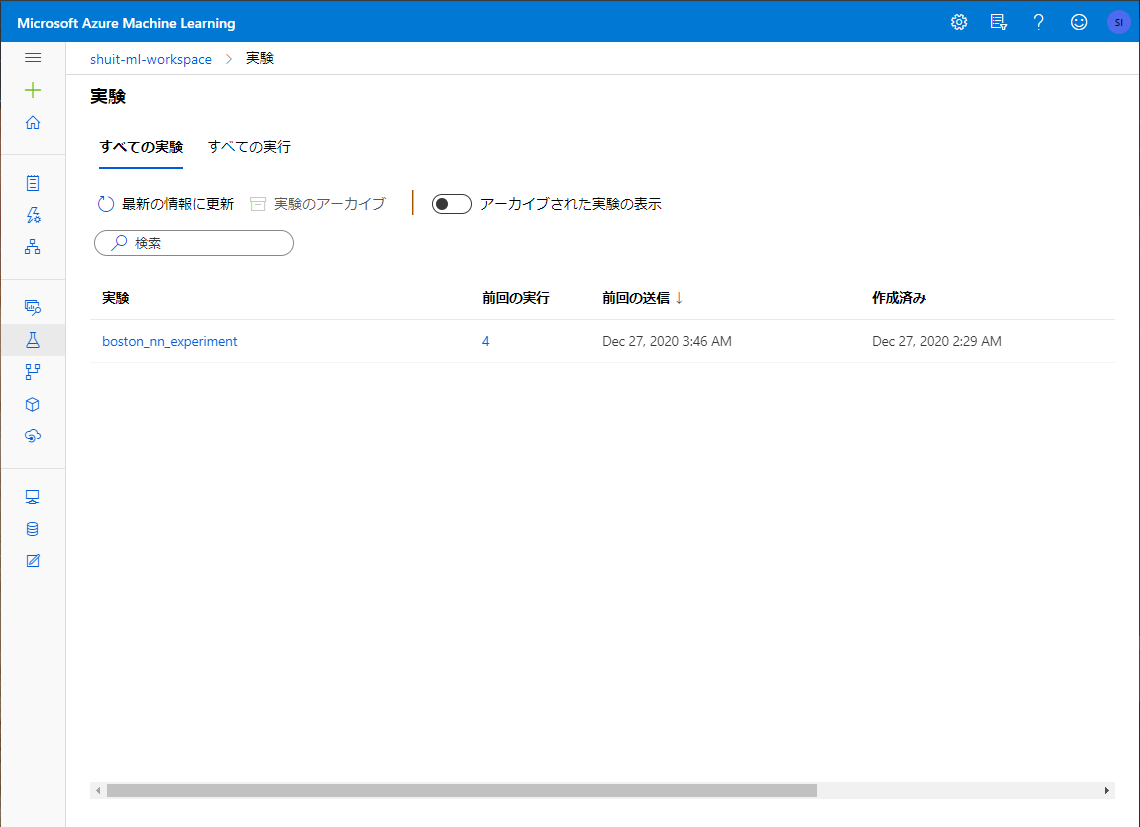
1回1回の Run も記録されています。
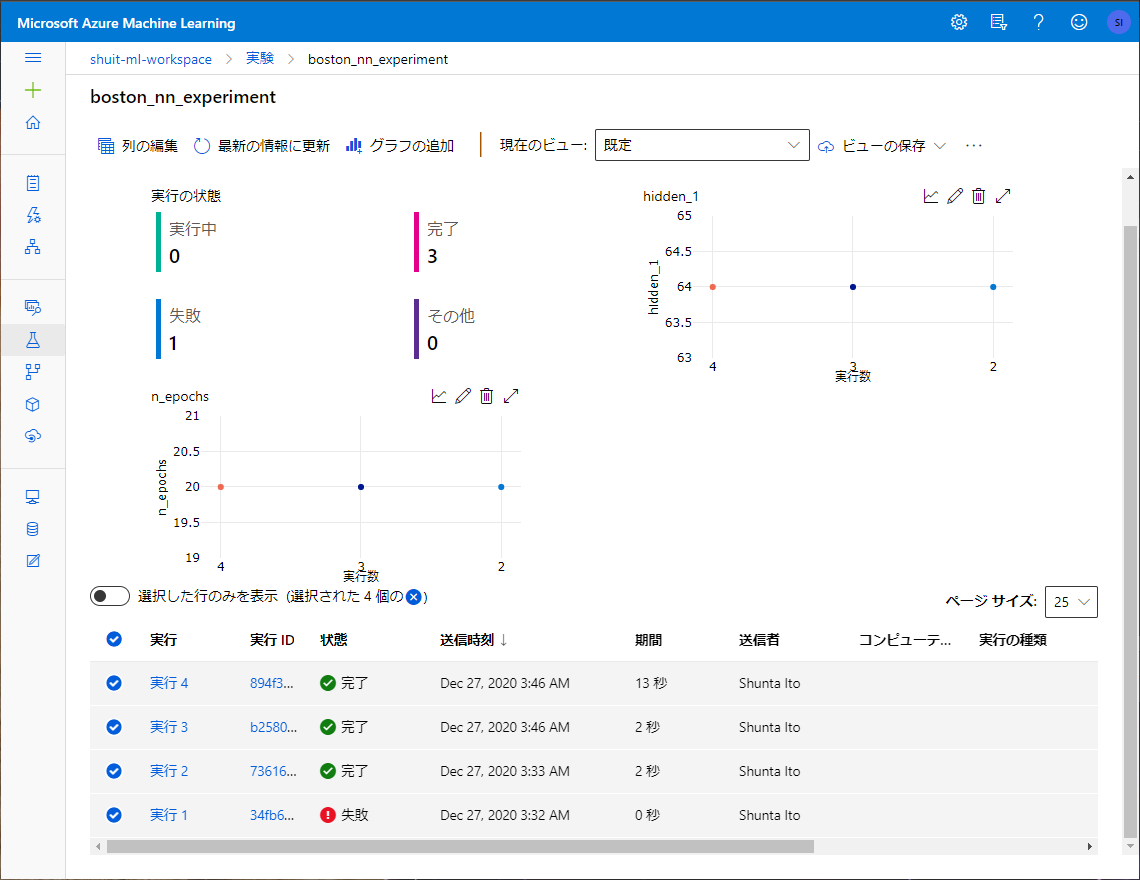
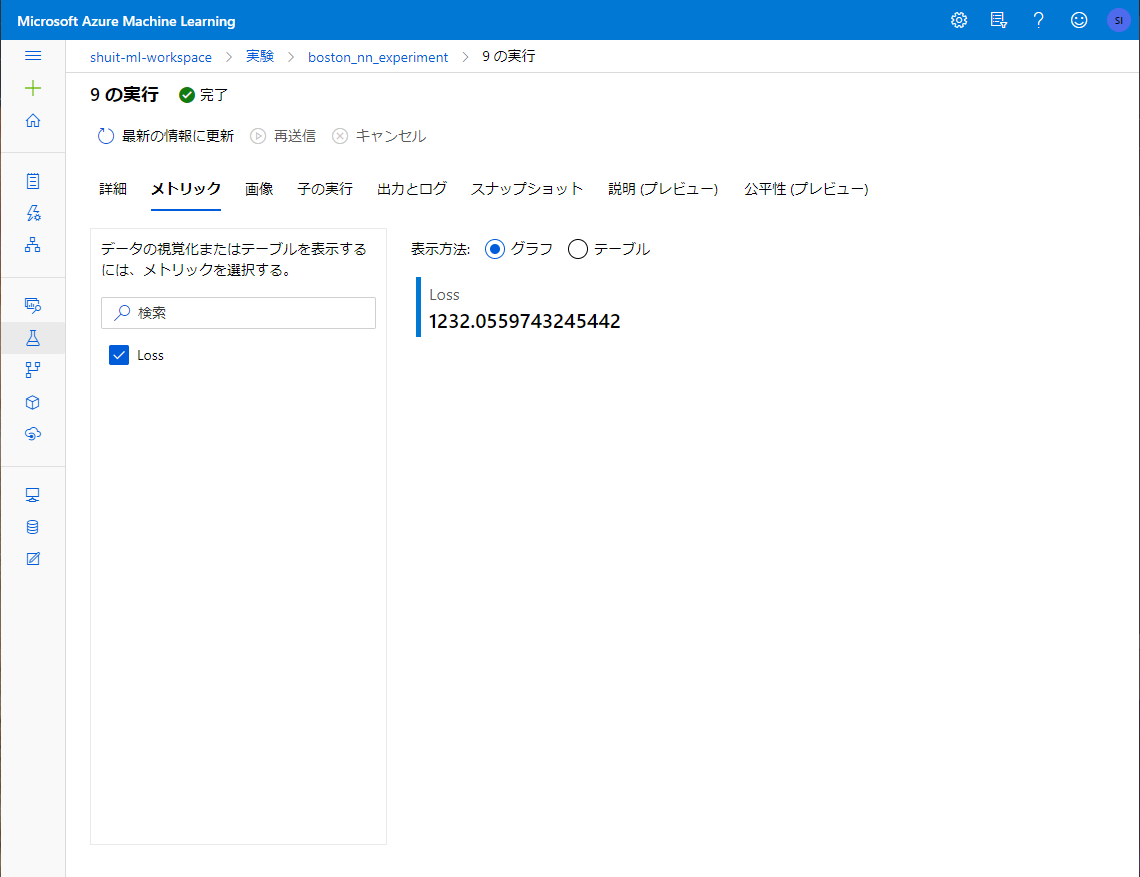
メトリックも記録されています。
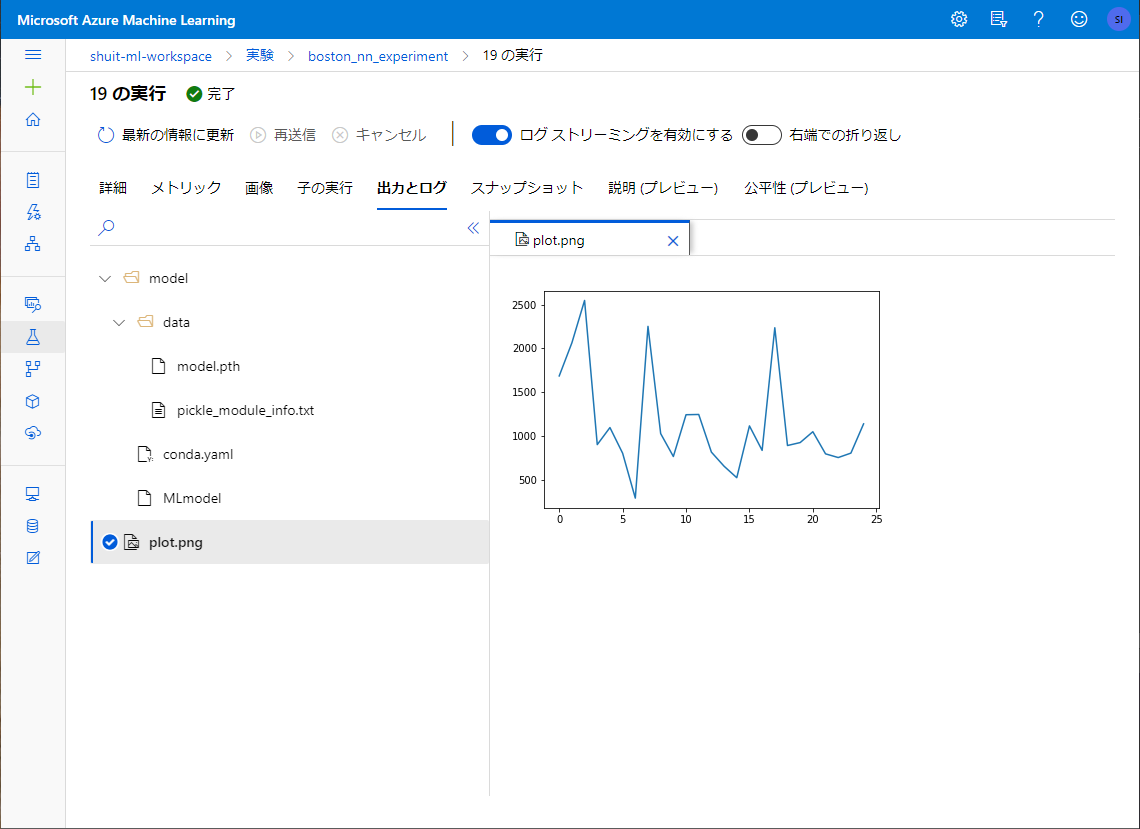
画像もきちんと記録されています。
パラメーターは Experiment の「ビュー」とやらには表示されていた一方 Run の中には見当たりませんが、生JSONを開くと中に記録されていました。この状態だと GUI からは見づらいですが、しかし MLflow の Python API から叩く分には特に問題がないのでよしとします。
ひとまずこれで実験管理と、部分的ではありますがモデル管理ができるようになりました。
MLflow Projects + MLflow Tracking + Azure Machine Learning による再現性を確保した実験管理
上記実験管理の一連の工程は全てノートブック上での実験を前提としています。デバッグ等を済ませたら train.py のようなスクリプトファイルにまとめることになるかと思いますが、こうなると MLflow Projects の出番です。
MLflow Projects を使用することでローカルでの実行のみならずリモート (クラウド上の他の強力なリソース等) での実行すら可能になります。僕個人であればオンプレ GPU マシンに戻るときなどに重宝しそうですが、チームで開発を行っている場合には他人の実験の再現性を確保できるようになることが重要そうです。
雰囲気としてはソースコードとビルドの設定ファイルを使ってビルドを行うことに似ています。
先程使ったコードと実験の記録時に artifact として出力された conda.yaml と公式サンプル4を参考に Project に必要な3つのファイル
- train.py
- conda.yaml
- MLproject
を作成します。
先程のビルドの例に例えると、train.py がソースコード、conda.yaml が依存関係を記述したファイル、MLproject がビルドの細かい設定を示したファイルといったところでしょうか。
import torch
from torch import nn
from torch.nn import functional as F
import numpy as np
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
import torch.utils.data as Data
from adabelief_pytorch import AdaBelief
import tqdm
from matplotlib import pyplot as plt
from sklearn.metrics import mean_squared_error
import tempfile
import pathlib
import sys
import mlflow
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# ハイパーパラメーター
hidden_1 = int(sys.argv[1]) if len(sys.argv) > 1 else 64
hidden_2 = int(sys.argv[2]) if len(sys.argv) > 1 else 16
batch_size = int(sys.argv[3]) if len(sys.argv) > 1 else 16
n_epochs = int(sys.argv[4]) if len(sys.argv) > 1 else 20
params = {
"hidden_1":hidden_1,
"hidden_2":hidden_2,
"batch_size":batch_size,
"n_epochs":n_epochs
}
# データセット
boston = load_boston()
X_train, X_test = train_test_split(boston.data)
y_train, y_test = train_test_split(boston.target)
class BostonData(Data.Dataset):
def __init__(self, X, y):
self.targets = X.astype(np.float32)
self.labels = y.astype(np.float32)
def __getitem__(self, i):
return self.targets[i, :], self.labels[i]
def __len__(self):
return len(self.targets)
train_dataset = BostonData(X_train, y_train)
test_dataset = BostonData(X_test, y_test)
train_loaded = Data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loaded = Data.DataLoader(test_dataset, batch_size=batch_size, shuffle=True)
# モデル
class Model(nn.Module):
def __init__(self, n_features, hidden_1, hidden_2):
super(Model, self).__init__()
self.linear_1 = nn.Linear(n_features, hidden_1)
self.linear_2 = nn.Linear(hidden_1, hidden_2)
self.linear_3 = nn.Linear(hidden_2, 1)
def forward(self, x):
y = F.relu(self.linear_1(x))
y = F.relu(self.linear_2(y))
y = self.linear_3(y)
return y
n_features = X_train.shape[1]
nn_model = Model(n_features, hidden_1, hidden_2)
# 最適化手法と損失関数
criterion = nn.MSELoss(size_average=False)
optimizer = AdaBelief(
nn_model.parameters(),
lr=1e-3,
eps=1e-16,
betas=(0.9,0.999),
weight_decouple = True,
rectify = False,
print_change_log = False
)
# 学習
with mlflow.start_run():
mlflow.log_params(params)
losses = []
for epoch in tqdm.tqdm(range(n_epochs)):
losses = []
total = 0
for inputs, target in train_loaded:
inputs.to(device)
target.to(device)
optimizer.zero_grad()
y_pred = nn_model(inputs)
loss = criterion(y_pred, torch.unsqueeze(target,dim=1))
loss.backward()
optimizer.step()
losses.append(loss.item())
total += 1
epoch_loss = sum(losses) / total
losses.append(epoch_loss)
mess = f"Epoch #{epoch+1} Loss: {losses[-1]}"
mlflow.log_metric("Loss",losses[-1])
mlflow.pytorch.log_model(nn_model,artifact_path="model")
fig = plt.figure()
plt.plot(losses)
with tempfile.TemporaryDirectory() as d:
filename = 'plot.png'
artifact_path = pathlib.Path(d) / filename
print(artifact_path)
fig.savefig(str(artifact_path))
mlflow.log_artifact(str(artifact_path))
ノートブックで実行していたときとの違いはハイパーパラメーターをスクリプトの外から与えられるようになったことです。
channels:
- defaults
- conda-forge
- pytorch
dependencies:
- python=3.6.9
- pytorch=1.4.0
- torchvision=0.5.0
- pip
- pip:
- mlflow
- cloudpickle==1.6.0
name: mlflow-env
こちらは Azure Machine Learning の Experiment に自動で生成されていたファイルを持ってきています。今回は一揃い依存パッケージが入っているローカル環境で動かしてたので特にエラーは出なかったのですが、リモート実行するならadabelief-pytorch==0.2.0とかも要りそうです。conda.yml の自動生成は完璧ではなさそうな気配がします。
name: mlflow-env
conda_env: conda.yaml
entry_points:
main:
parameters:
hidden_1: {type: int, default: 64}
hidden_2: {type: int, default: 16}
batch_size: {type: int, default: 16}
n_epochs: {type: int, default: 20}
command: "python train.py {hidden_1} {hidden_2} {batch_size} {n_epochs}"
MLproject にはパラメーターを渡すためのブロックを追加しています。
entory_points は実行が複数段階、例えば前処理、学習1、学習2のように分かれる場合などに使いますが、今回は複数段階の実行はないので main だけです。
以上のファイルを同一ディレクトリ内に収めます。
実験を行う際には以下のように Azure Machine Learning のワークスペースへの接続、実験名の定義、パラメーターの定義、ちょっとした設定を書くだけで実験が実行可能になります。
import mlflow
from azureml.core import Workspace
import os
ws = Workspace.from_config()
mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())
experiment_name = "pytorch-boston-project"
mlflow.set_experiment(experiment_name)
backend_config={"USE_CONDA": False}
params = {
"hidden_1":32,
"hidden_2":8,
"batch_size":16,
"n_epochs": 10
}
local_env_run = mlflow.projects.run(uri=os.getcwd(),
parameters=params,
backend = "azureml",
use_conda=False,
backend_config = backend_config)
backend_config は実験をリモートのコンピューティングリソースで実行する際に変更します。
例えば Azure Machine Learning 配下にある cpu-cluster という名称のクラスターで実行する場合、下記のように変更します。5
backend_config = {"COMPUTE": "cpu-cluster", "USE_CONDA": False}
モデル管理
既に現時点でモデルの記録はできていますが、あくまでも artifact の1つとしての記録です。モデルは Azure Machine Learning における実験の管理コンポーネントである Experiment とは別に Registerd models でも記録が可能で、こちらにモデルを記録しているとコンテナ化してデプロイまでが容易になります。実験の度 Registerd models にモデルを登録することもできますが、モデルのバージョン管理機能もあるので、実験がうまく行ってプロダクション環境に投入するモデルができた場合に登録するといった運用もできそうです。
Registerd models へのモデルの記録はmlflow.register_model で可能です。
with mlflow.start_run() as run:
mlflow.log_params(params)
## 中略
mlflow.log_metric("Loss",losses[-1])
mlflow.pytorch.log_model(nn_model,artifact_path="model")
model_uri = "runs:/{}/model".format(run.info.run_id)
mlflow.register_model(model_uri, "PyTorchModel")
ですが、このやり方だと Azure Machine Learning 上では実験の記録との関連付けが切れていてあまり気持ちよくありません。そこで、azureml.mlflow の register_model を使用します。
import azureml.mlflow
with mlflow.start_run() as run:
mlflow.log_params(params)
## 中略
mlflow.log_metric("Loss",losses[-1])
mlflow.pytorch.log_model(nn_model,artifact_path="model")
#model_uri = "runs:/{}/model".format(run.info.run_id)
#mlflow.register_model(model_uri, "PyTorchModel")
azureml.mlflow.register_model(run, name="PyTorchModel", path="model")
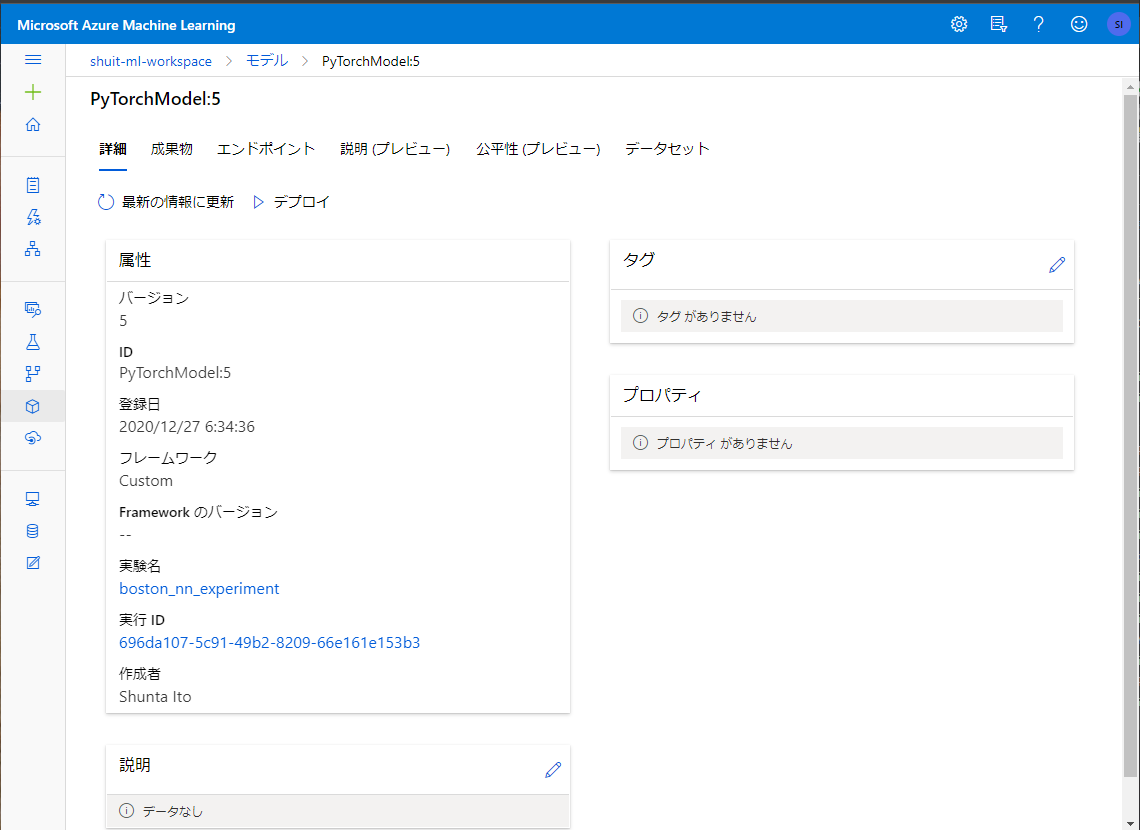
実験の記録 (実験名や実行ID) とも関連付けられた状態でモデルの登録でできている様子が確認できます。
デプロイ
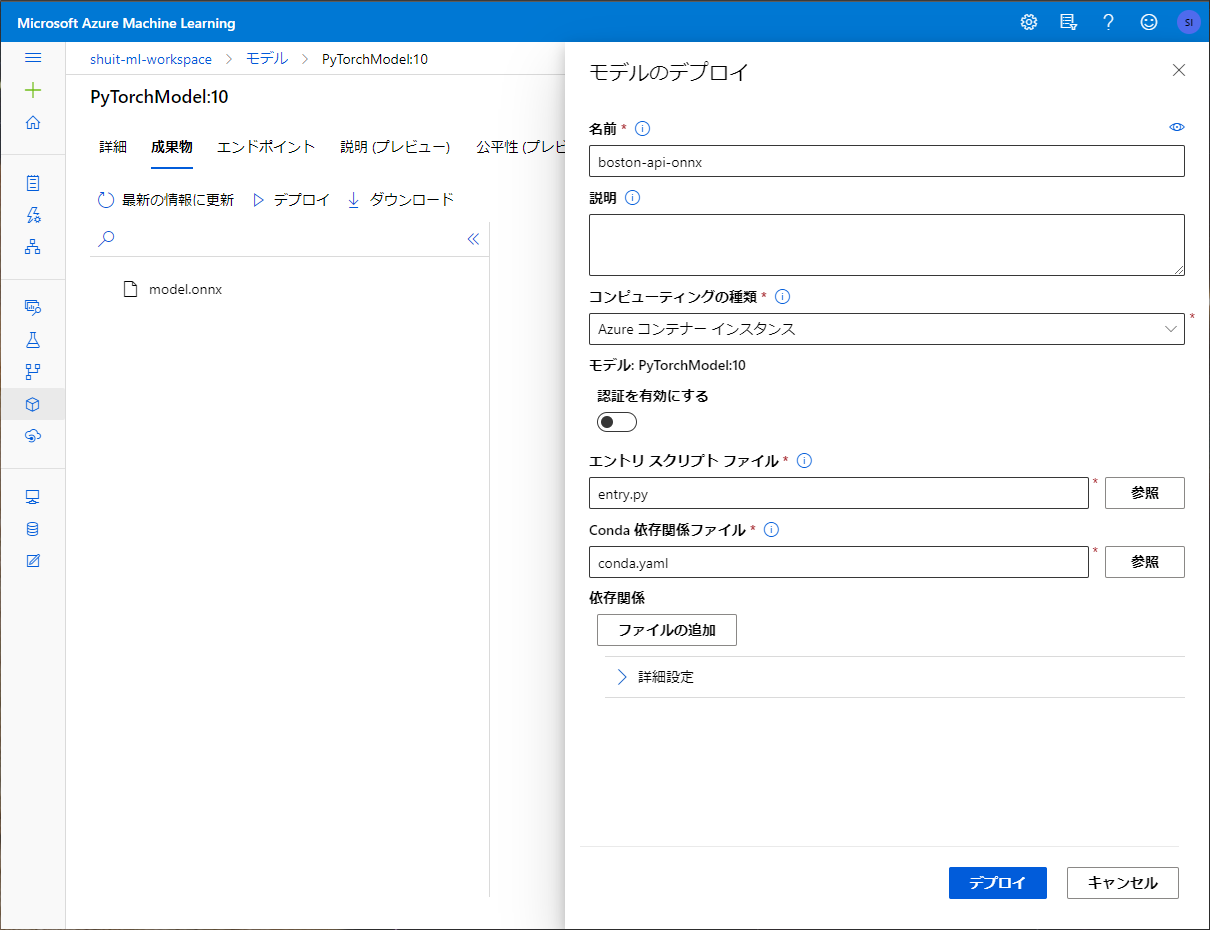
せっかくなのでAPIデプロイまでやってみようとおもいます。
作った機械学習モデルをデプロイする場合はモデル登録からさらにもう1手間必要で、エントリースクリプトと呼ばれるモデルのロードと予測値の出力を行うためのスクリプトを書く必要があります。6
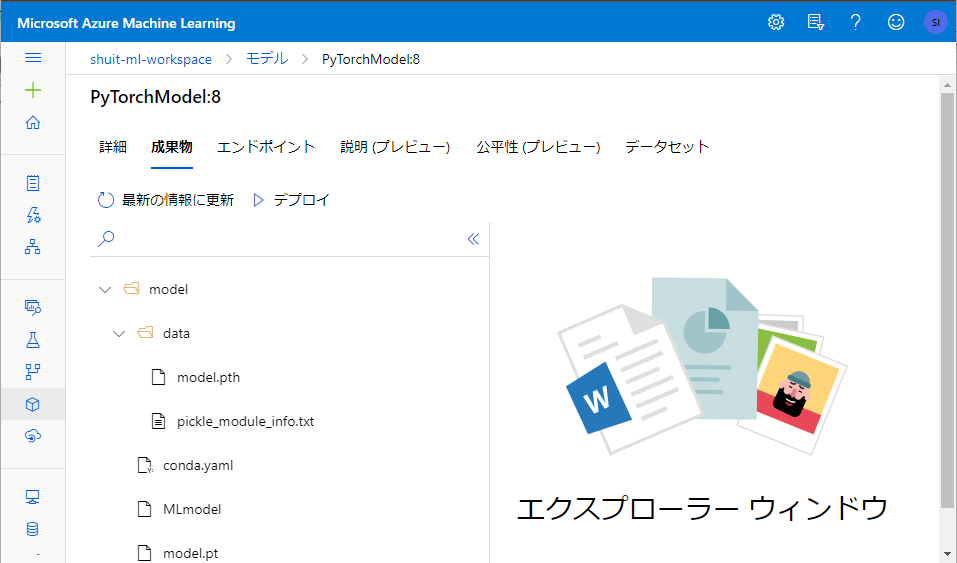
APIデプロイは Registerd model に登録されたモデルの「デプロイ」から行うことができ、コンテナとして Azure Kubernetes Service か Azure Container Instance にデプロイされます。
コンテナにはエントリースクリプトの他に登録されたモデルの「成果物」が全て収められる様子で、"AZURE_MODEL_DIR"という環境変数として成果物までのパスが登録されます。
発生した問題
デプロイの部分については初稿の投稿 (2020/12/27) に間に合わなかったのですが、なぜ間に合わなかったかというとエントリスクリプトというデプロイに必要なスクリプトのデバッグに非常に手間取ったためです。(どうやってログ見ればいいか分からなかった……)
経過は省きますが、mlflow.pytorch.load_modelによるモデルのローディングをエントリスクリプト内で行おうとしていたのですが、これがうまく動きませんでした。
手元で同じような環境を作って検証したところどうも何かしらのファイルが足りていないというようなエラーが出ていたのですが (スクショ忘れました) 、めんどくさそうなのでとっとと諦めて PyTorch が備えるモデルのセーブとロードでなんとかする方向に舵を切りました。
ところがこちらのやり方も推論環境におけるモデル読み込みに使うとなると問題が生じることが分かりました。
torch.save(model, "model/model.pth")
というような形でモデルのセーブを行うことができるので、これをmlflow.log_artifactで保存すればそれで済みそう……そんなふうに考えていた時期が俺にもありました……。
ロードの段階でシンプルに
model = torch.load("model/model.pth")
とすると、モデルを学習した環境と推論環境が異なる場合に問題が生じます。これは環境依存的な情報を含んだ形でモデルを保存しているために生じる問題です。
ではどうするかというと、
model = ModelClass(<model_parameters>)
model.load_state_dict(torch.load("model/model.pth"))
というように一度モデルを定義するクラスからからのモデルを作って、そこに学習済みモデルのパラメーターを上書きするという形を取ります。
この問題について良い解説記事がありました。詳しく知りたい場合はこちらをどうぞ。
https://qiita.com/jyori112/items/aad5703c1537c0139edb
このやり方だとモデルを定義したクラスとモデルのクラスからインスタンスを作るためにハイパーパラメーターを記述したファイルも一緒にRegisterd models に登録しないといけないということになりますが、それは正直イヤです。ハイパーパラメーターをテキストで吐き出すならわざわざ MLflow を使って記録する意味が薄れてしまいます。
ONNX
そういうわけで ONNX を使うことにしました。
ONNX は機械学習モデルを保存するためのフォーマットです。モデル構造を含む形式であるため上記問題を解決できることに加え、今回デプロイする API に限らず色んな所で利用しやすくなりますし、PyTorch 以外に例えば XGBoost とか scikit-learn とかを使った場合でも同じ手順を踏襲できて一石三鳥なのでこちらを採用することに決めました。
「API に限らず色んな所で利用しやすくなります」の一例ですが、個人的には分析基盤の SQL 文中で ONNX 形式のモデルを読みこんで推論できる機能が面白そうだと思いました。
https://docs.microsoft.com/ja-jp/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-predict
まず学習を行う部分を下記のように書き換えて、ONNX 形式で出力したモデルを登録するようにします。
# 学習
with mlflow.start_run() as run:
mlflow.log_params(params)
#中略
mlflow.log_metric("Loss",losses[-1])
with tempfile.TemporaryDirectory() as d:
filename = 'model.onnx'
artifact_path = pathlib.Path(d) / filename
# 入力サンプル
valid_input = torch.randn(1, 13, requires_grad=True)
# ONNX
torch.onnx.export(model=nn_model,
args=valid_input,
f=str(artifact_path),
export_params=True,
opset_version=11,
input_names = ['input'],
output_names = ['output'],
dynamic_axes={'input' : {0 : 'batch_size'}, 'output' : {0 : 'batch_size'}})
mlflow.log_artifact(str(artifact_path),artifact_path="model/"+filename)
mlflow.pytorch.log_model(nn_model,artifact_path="model")
azureml.mlflow.register_model(run, name="PyTorchModel", path="model/model.onnx")
fig = plt.figure()
plt.plot(losses)
with tempfile.TemporaryDirectory() as d:
filename = 'plot.png'
artifact_path = pathlib.Path(d) / filename
print(artifact_path)
fig.savefig(str(artifact_path))
mlflow.log_artifact(str(artifact_path))
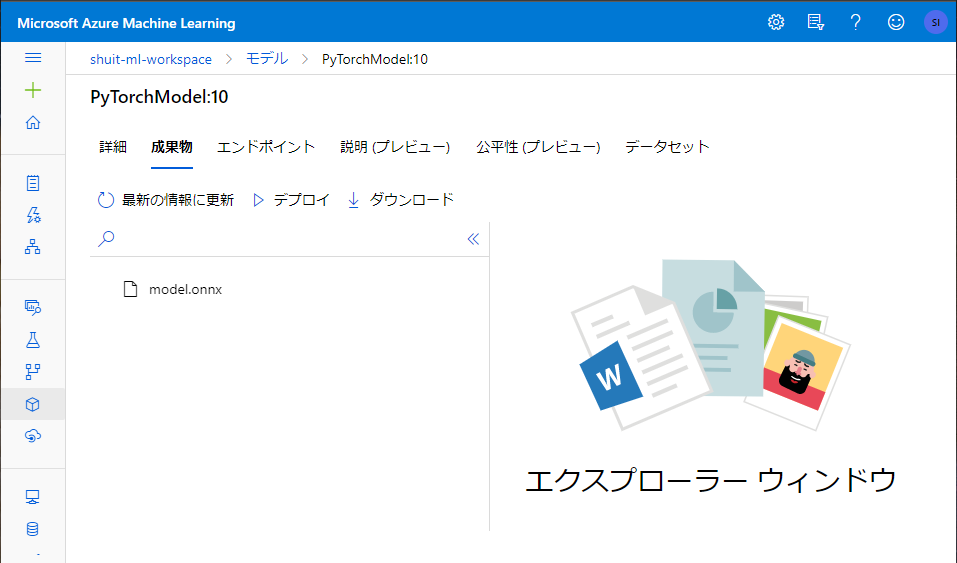
実行してみると、確かに onnx のモデルが登録されています。
続いてエントリスクリプトを用意します。
エントリスクリプトにはモデルのロードを行うinit関数と API にリクエストが来たときに実際に行う処理を記述したrun関数が必要です。
詳細はドキュメントを参照してください。
https://docs.microsoft.com/ja-jp/azure/machine-learning/how-to-deploy-advanced-entry-script
onnx 形式のモデルを使って推論を行う場合は onnxruntime を使用します。
余談ですが、onnxruntime は Microsoft が開発して OSS 化したものらしいです。知らなかったです。
https://japan.zdnet.com/article/35129632/
https://github.com/microsoft/onnxruntime
import json
import os
import numpy as np
import onnxruntime
def init():
global model
model_path = os.path.join(os.getenv('AZUREML_MODEL_DIR'), 'model.onnx')
model = onnxruntime.InferenceSession(model_path)
def run(data):
try:
data= json.loads(data)
data_array = [[data['CRIM'], data['ZN'], data['INDUS'], data['CHAS'], data['NOX'], data['RM'], data['AGE'], data['DIS'], data['RAD'], data['TAX'], data['PTRATIO'], data['B'], data['LSTAT']]]
input_array = np.array(data_array, dtype=float).tolist()
pred = model.run(output_names=["output"], input_feed={"input": input_array})
return {"prediction": float(pred[0])}
except Exception as e:
error = str(e)
return {"error": error}
ONNX 側はまとめてたくさんの入力が来た場合でもよしなにやれるように入出力を定義しているのですが、このエントリスクリプトだと1度のリクエストで1組の入力しか受け付けません。(デバッグで力尽きて面倒になってしまいました)
onnxruntime.InferenceSession(model_path)でモデルを読み込み、pred = model.run(output_names=["output"], input_feed={"input": input_array})で推論を行っています。
このエントリスクリプトの依存を解決するための conda.yaml を用意します。
channels:
- defaults
- conda-forge
- pytorch
dependencies:
- python=3.6.9
- pip
- numpy
- pip:
- onnxruntime
- azureml-defaults
- azureml-sdk
name: boston-api
いよいよデプロイです。
コマンドから行いたい場合はmlflow.azureml.deployを使用するとできそうです。
公式ドキュメントにも記載があります。エントリスクリプトとかどうなってるんだろ……。
https://docs.microsoft.com/ja-jp/azure/machine-learning/how-to-use-mlflow#deploy-and-register-mlflow-models
https://www.mlflow.org/docs/latest/python_api/mlflow.azureml.html
定期的にデータセットを更新してモデル及び API を更新するような用途ならコマンドの方が何かと都合が良いかもしれません。GitHub Actions の定期実行とリモートの計算リソースを使う機能を組み合わせると継続的なモデル更新ができそうと今思い付きました。そのうち検証してみます。
デプロイが完了するとエンドポイントのページに表示されます。

実際に叩いてみます。
import requests
import json
data = {
"CRIM":1.00245,
"ZN":0,
"INDUS":8.12,
"CHAS":0,
"NOX":0.538,
"RM":6.674,
"AGE":87.3,
"DIS":4.239,
"RAD":4,
"TAX":307,
"PTRATIO":21,
"B":380.23,
"LSTAT":11.98
}
data = json.dumps(data)
res = requests.post(url='http://1c055c7b-8f78-4dc4-a2ba-543e094a37b6.japaneast.azurecontainer.io/score', data=data, headers={'Content-Type': 'application/json'})
res.json()
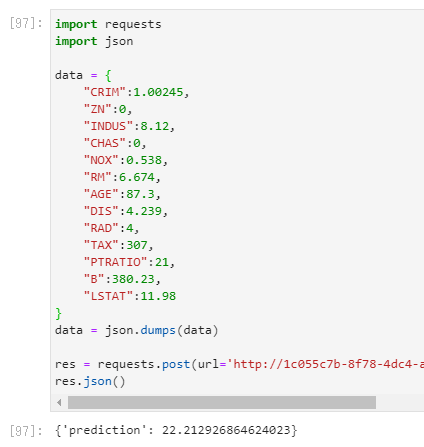
ちゃんと返ってきてますね。大勝利。
なお課金されたくないので API は既に削除済みです。
ここまでほぼほぼ MLflow の使い方といった趣で Azure Machine Learning は影を潜めていましたが、デプロイまで至ると Azure Machine Learning の良さが出てきますね。
終わりに
Azure Machine Learning を MLflow のバックエンドとして使用することで、Python の機械学習開発環境に実験管理とモデル管理の仕組みを組み込むことができました。ついでにモデルを API としてデプロイすることもできました。
これでもう「model_adam_lr_0001_lstm_3_layer_e_512_h_1024.model」とはおさらばです。間違えてファイルを上書きしてしまって学習やり直しになったり、パラメーター設定を記録し忘れて真顔になったりしなくてよくなりました。
密度濃く機械学習をしていた大学院時代にこれを知っていればなぁ……。
参考文献
Azure Machine Learning と MLflow の連携について (さらっと) 書かれたドキュメントです。
https://docs.microsoft.com/ja-jp/azure/machine-learning/how-to-use-mlflow, 2020/12/27閲覧
実装及び概念の理解に際して下記公式ドキュメントを参照しました。
https://www.mlflow.org/docs/latest/python_api/index.html, 2020/12/27閲覧
https://pytorch.org/docs/stable/index.html, 2020/12/27閲覧
https://docs.microsoft.com/ja-jp/python/api/overview/azure/ml/?view=azure-ml-py, 2020/12/27閲覧
ONNX によるモデル登録に際して、公式のコンテンツと PyTorch のチュートリアル、BASE の斎藤氏の記事を参照しました。
https://onnx.ai/get-started.html, 2020/12/29閲覧
https://pytorch.org/tutorials/advanced/super_resolution_with_onnxruntime.html, 2020/12/29閲覧
https://devblog.thebase.in/entry/2019/12/15/110000, 2020/12/29閲覧
一時ディレクトリを使って artifact を生成する部分は momijiame 氏の下記ブログ記事を参考にさせて頂きました。
https://blog.amedama.jp/entry/mlflow-tracking, 2020/12/27閲覧
AdaBelief を使う部分は Juntang Zhuang 氏らの公式実装リポジトリを参照にさせて頂きました。
https://github.com/juntang-zhuang/Adabelief-Optimizer, 2020/12/27閲覧
AdaBelief ってなんやねんという方は下記論文をどうぞ。NeurIPS 2020 の Sportlight に選ばれたそうです。めちゃくちゃすごいですね。
https://arxiv.org/abs/2010.07468, 2020/12/27閲覧
その他に下記ドキュメントを参照しました。
-
https://docs.microsoft.com/ja-jp/azure/machine-learning/concept-workspace, 2020/12/27閲覧 ↩
-
https://mlflow.org/docs/latest/concepts.html#mlflow-components, 2020/12/27閲覧 ↩
-
https://www.mlflow.org/docs/latest/python_api/index.html, 2020/12/27閲覧 ↩
-
https://github.com/Azure/MachineLearningNotebooks/tree/master/how-to-use-azureml/track-and-monitor-experiments/using-mlflow/train-projects-local, 2020/12/27閲覧 ↩
-
https://github.com/Azure/MachineLearningNotebooks/blob/master/how-to-use-azureml/track-and-monitor-experiments/using-mlflow/train-projects-remote/train-projects-remote.ipynb, 2020/12/27閲覧 ↩
-
https://docs.microsoft.com/ja-jp/azure/machine-learning/how-to-deploy-and-where?tabs=azcli#define-an-entry-script, 2020/12/27閲覧 ↩