はじめに
こちらは MLOps アドベントカレンダーの20日目の記事です。
今回は Azure Machine Learning + Azure Databricks の組み合わせで以下2点を試したいと思います。
- Azure Databricks で機械学習を行い、Azure Machine Learning で機械学習実験の記録を取る
- Azure Databricks の Notebook を Azure Machine Learning Pipelines に組み込む
Azure Machine Learning と Azure Databricks
お気持ち表明
汎用機で構築した GPU マシンに JupyterHub やら CUDA やらをセットアップして機械学習していた大学院生時代、現在勤めている会社のインターンで Azure Databricks に触れて衝撃を受けました。
「GPU が乗ったクラスターがワンクリック3分で立ち上がった……!」
以来 Azure Databricks が好きです。
入社してから Azure Machine Learning という機械学習のプラットフォームサービスに出会い、衝撃を受けました。
「GPU が乗っていて JupyterLab が使える諸々プリセット済みのインスタンスとクラスターがワンクリック3分で立ち上がった……!」
以来 Azure Machine Learning も好使用する
「クソ寒いサーバールームからそこそこ重たいマシンを持ってきて環境構築を8時間ぐらい頑張ると何かしら機能を備えたサーバーができて嬉しい」という人生を送っていたので、環境を一瞬で構築できる PaaS 類が非常に好きです。加えて計算リソースがオートスケールしたり、未使用時には自動で停止したりするスケーラビリティを備えているとテンションが上がります。
Azure Machine Learning と Azure Databricks の2つのサービスですが、機械学習を行う立場から見れば機能的によく似ているように見えます。
どちらも機械学習を行うための計算リソースを簡単に立ち上げることができ、機械学習の実験記録を取るための機能を備えています。Auto ML の機能も両者備えていますし、モデルの管理とデプロイもできます。
「どう使い分ければいい?」という質問を受ける度に非常に悩ましい気持ちになっているのですが、それぞれ似たような機能を備えていても完成度が違ったりカバーできるワークロードの範囲が違ったりしているので、要件ごとに何が重要かに注目してどちらかに寄せるか、あるいはどう使い分けるかを考えています。
今回は最近改めて検証に取り組み始めた組み合わせ方の1つ、計算リソースは Azure Machine Learning でも Azure Databricks でもどちらを使っても良いが、実験記録やモデルの管理、パイプライン構築は Azure Machine Learning に寄せるというスタイルを実装し、手順を記載します。基礎的なことしか行っていないので今回の記事の中身から実用的な MLOps までは距離がありますが、実験記録とパイプラインは MLOps の第一歩ですから、まずはここから始めます。
Azure Machine Learning の概要
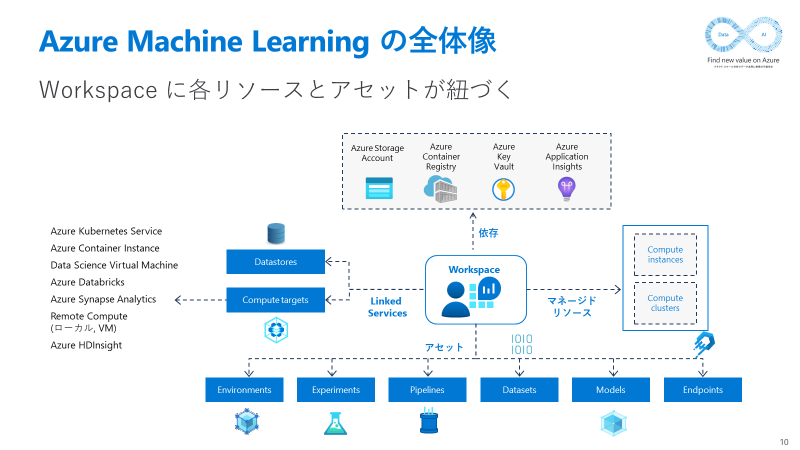
Azure Machine Learning のうち今回利用するコンポーネントは大きく分けて以下の3つです。
- Experiments
- Pipelines
- Compute targets
Experiments は機械学習実験を記録するコンポーネントです。個々の Experiment オブジェクトは配下に Run というオブジェクトを複数個持ち、さらに Run は配下に複数個の Child run を持つ (ことがある) 階層構造となっています。1つの Run が1回の機械学習実験に対応し、Experiment は一連の機械学習実験の試行錯誤をまとめたものと言えます。Child run はハイパーパラメーターチューニング等細かくたくさんの実験を行う場合に使用することがあります。
Pipelines は一連の機械学習ワークフローをひとまとめにして実行できるようにするコンポーネントです。OSS で相当する立場の製品としては、Airflow や Kubeflow Pipelines あたりが該当します。
Compute targets は Azure Machine Learning に外部計算リソースを連携して内部で使用できるようにするためのコンポーネントです。今回は Azure Databricks を Compute targets として登録することで、Azure Machine Learning Pipelines から呼び出せるようにするために使います。
実装
リソース準備
Azure Machine Learning のデプロイ

Azure Machine Learning を探します。日本語環境の場合、上の検索窓に「機械学習」と打ち込むと一発で見つかるかと思います。
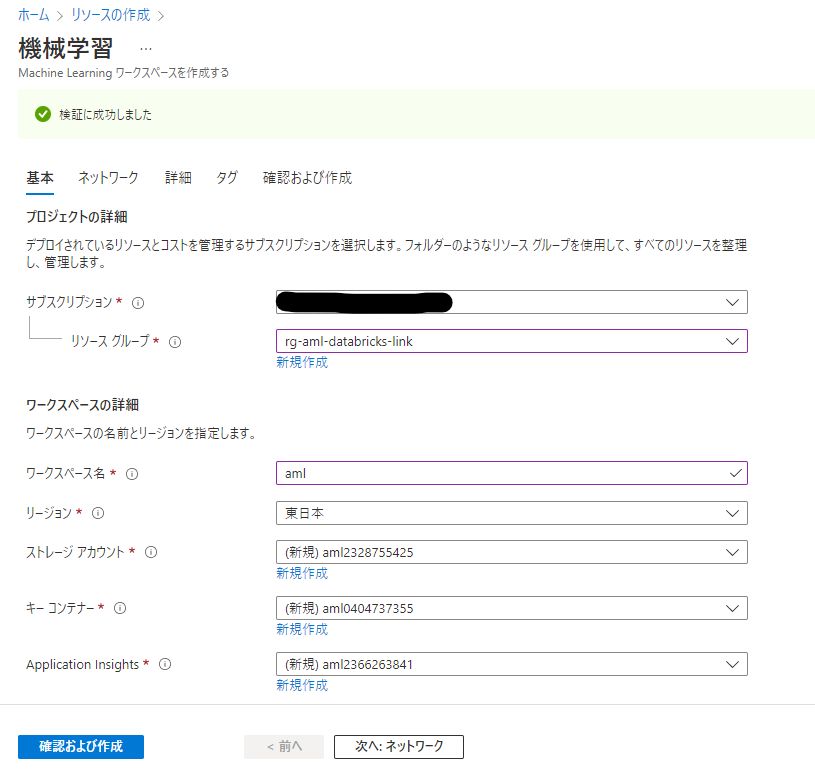
Machine Learning ワークスペースリソースとそのほか依存先のリソースを配置するリソースグループを選択し、ワークスペース名を入力します。リージョンは「東日本」にします。Azure Machine Learning は Blob Storage、Key Vault、Application Insights、Container Registery の4リソースに依存していて、作成時に依存先リソースも同時作成されます。(Container Registery だけは作成時に作らないようにすることも可能ですが、コンテナが必要となるような作業を実行すると自動的に作成されます)
デフォルト設定のままで問題ありません。「確認および作成」を押してリソースを作成します。
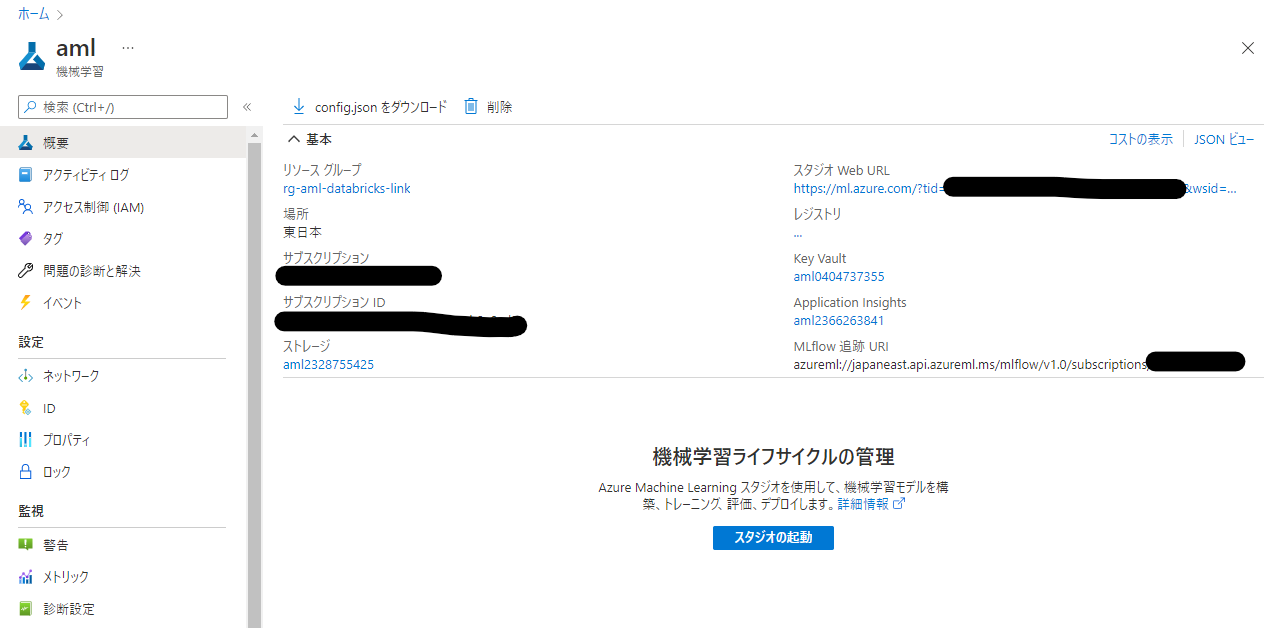
作成完了後リソースへ移動すると、管理画面が表示されます。
先ほどのリソース管理画面に「MLflow 追跡 URI」という項目が表示されていますが、これが Azure Machine Learning が備える MLflow の互換エンドポイントです。
去年の今頃、この互換エンドポイントを活用して Azure Machine Learning + MLflow で実験管理する記事を投稿しました。1年前の話ですので今も同じ手順が使えるかは不明ですが、参考程度にどうぞ。
「スタジオの起動」をクリックすれば Azure Machine Learning Studio へ接続し、GUI から Azure Machine Learning の機能に触れることができます。
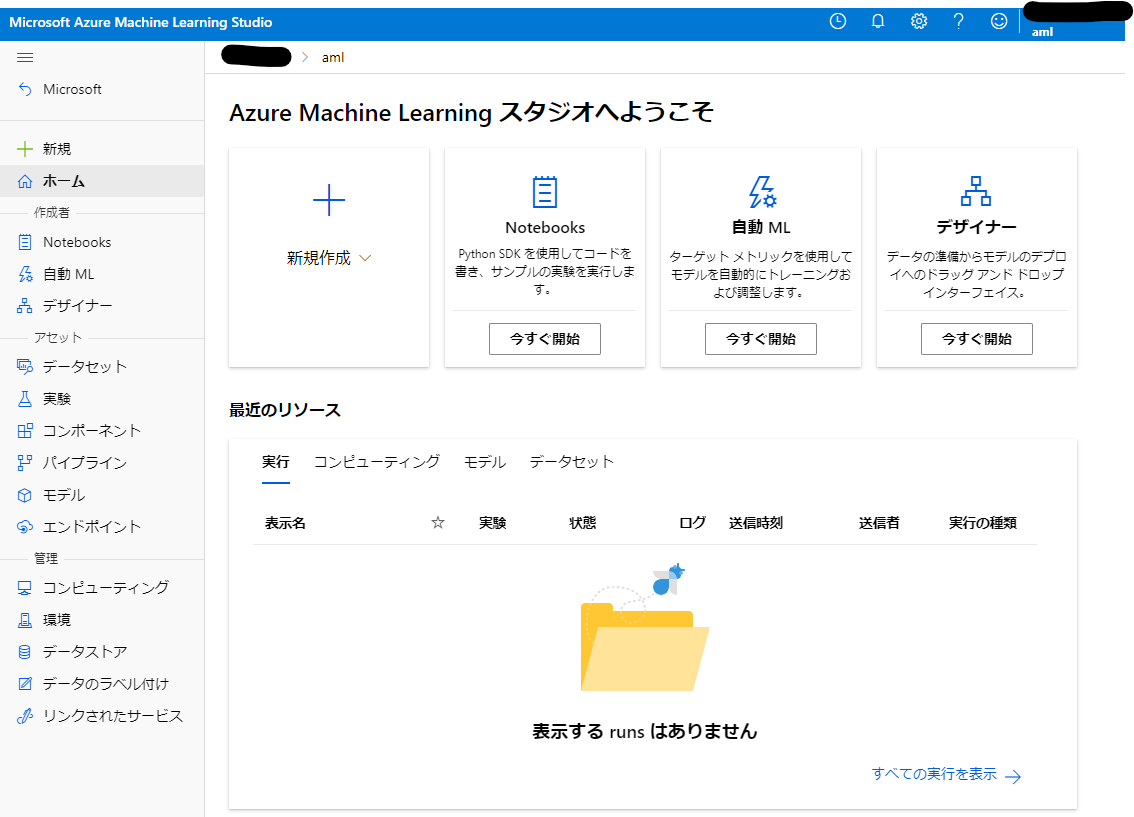
こちらが Azure Machine Learning Studio です。Jupyter 互換のノートブック環境や実験管理の画面等、全てここからアクセスることができます。
Azure Databricks のデプロイ
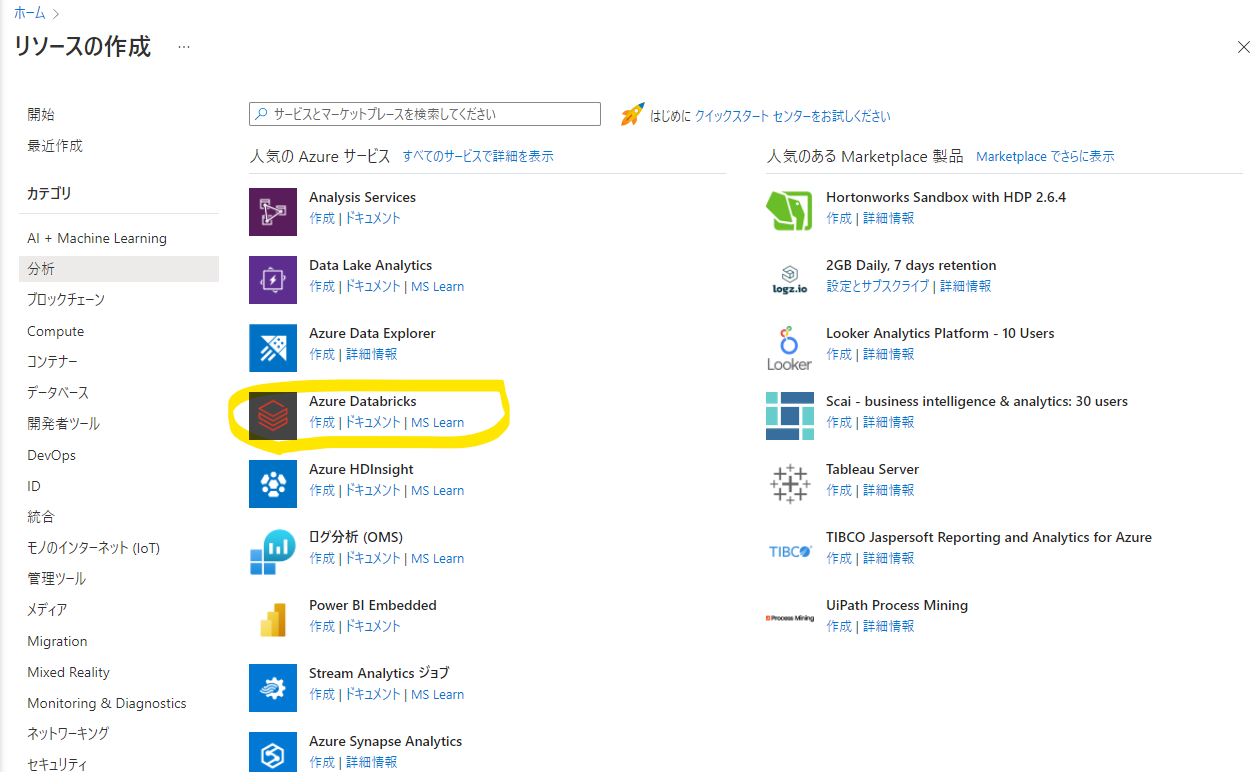
続いて同様の手順で Databricks を探し、リソースの作成を開始します。
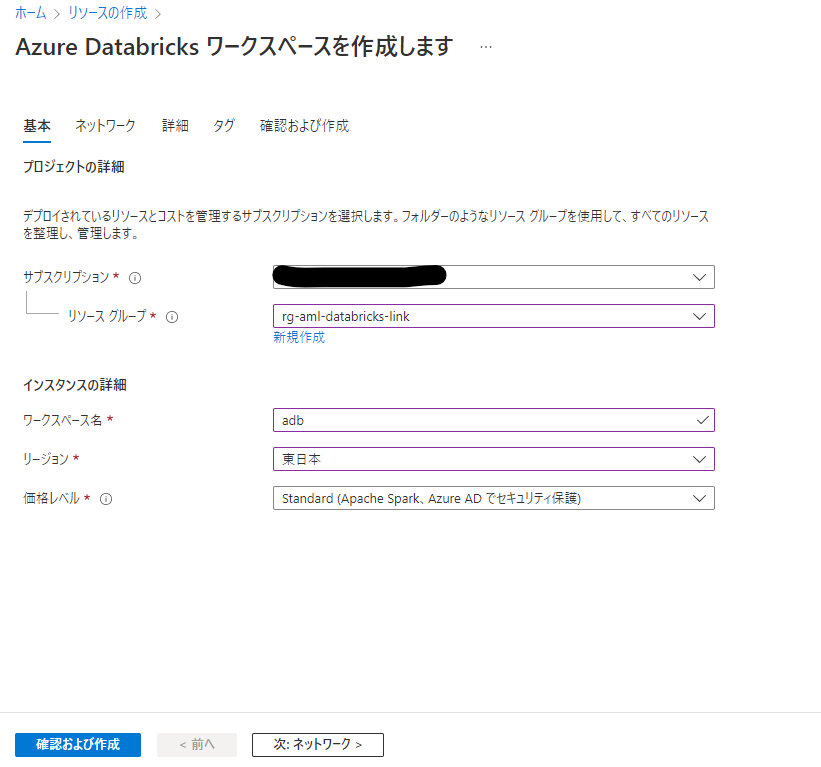
ワークスペース名を入力し、リージョンを「東日本」にします。価格レベルは今回は Standard としました。その他のオプションはデフォルトのままとし、「確認および作成」を押してリソースを作成します。
リソースの作成が完了すると Azure Databricks のリソース管理画面に移動できるので、「ワークスペースの起動」をクリックして Azure Databricks を開きます。
おしゃれな UI ですね
人は最初に出会ったマネージド機械学習基盤サービスを親だと思ってついていくので、僕の目にはバイアスがかかりまくっています。
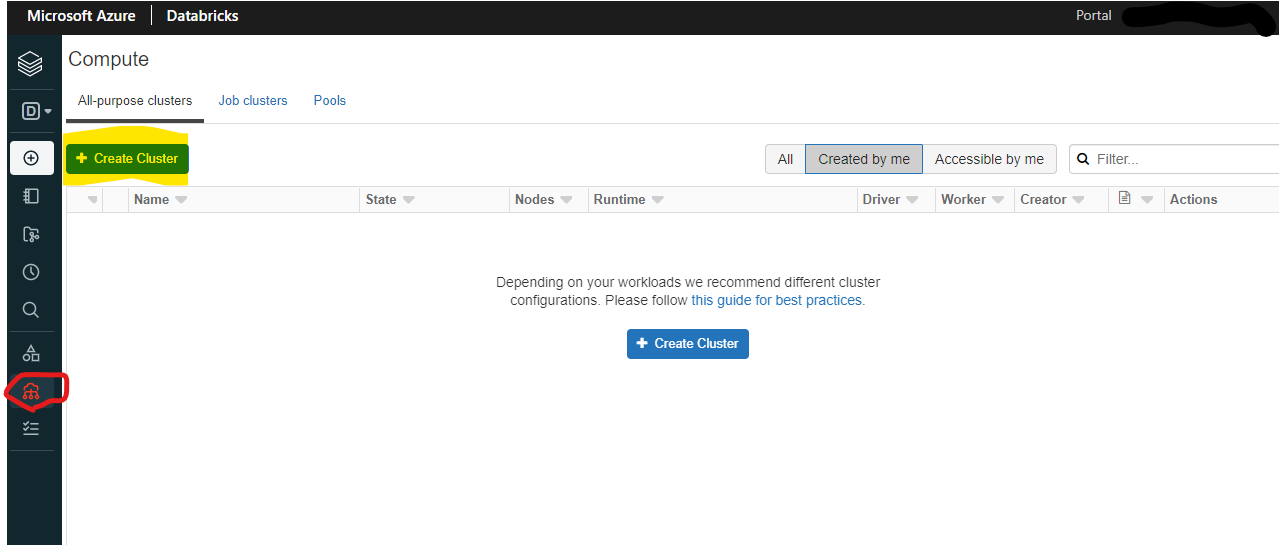
クラスターの作成を行います。左のメニューから「Compute」を選択し、「Create Cluster」をクリックします。
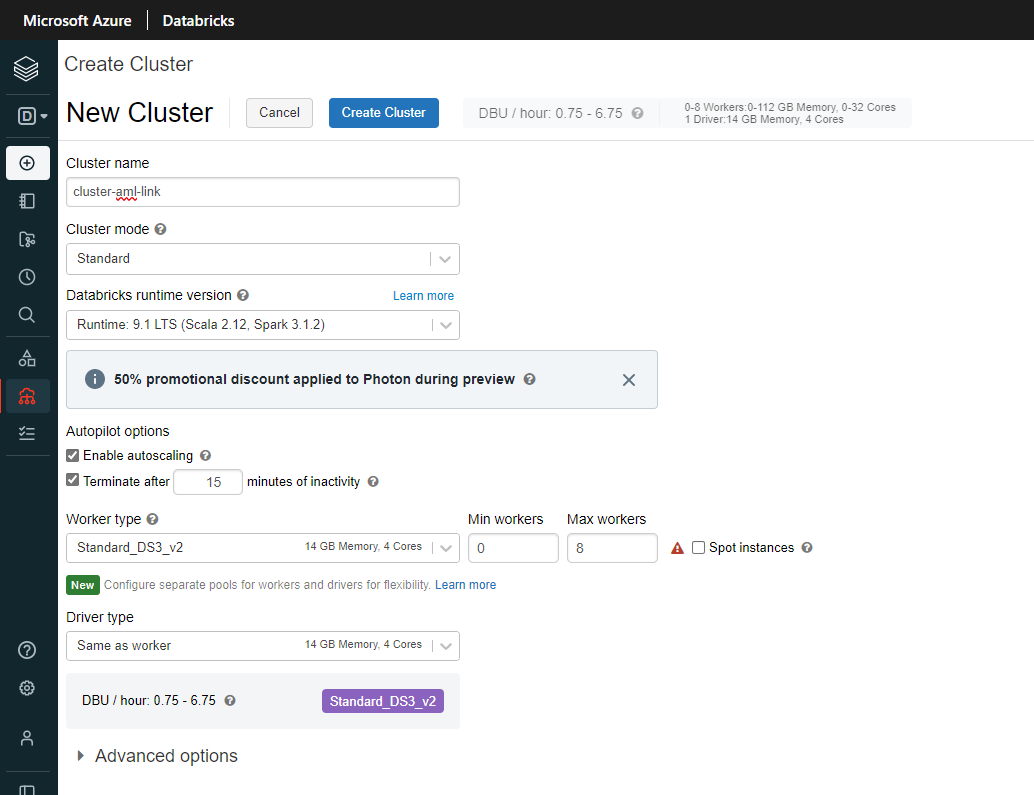
Cluster name に好きな名前を入力します。Databricks runtime version は何でも良いのですが、今回は Standard の 9.1 LTS にしました。
ポイントは「Enable autoscaling」にチェックを入れること、「Terminate afret nn miniutes of inactivity」にチェックを入れること、Min workers を 0 にすることです。画像の設定では、15分間何もしなければクラスターが停止して課金も止まります。
クラスターの作成が完了したら、次は Azure Machine Learning との接続に必要なパッケージをインストールしましょう。
クラスターの「Libraries」から「Install new」をクリックすると、パッケージのインストール画面が開きます。
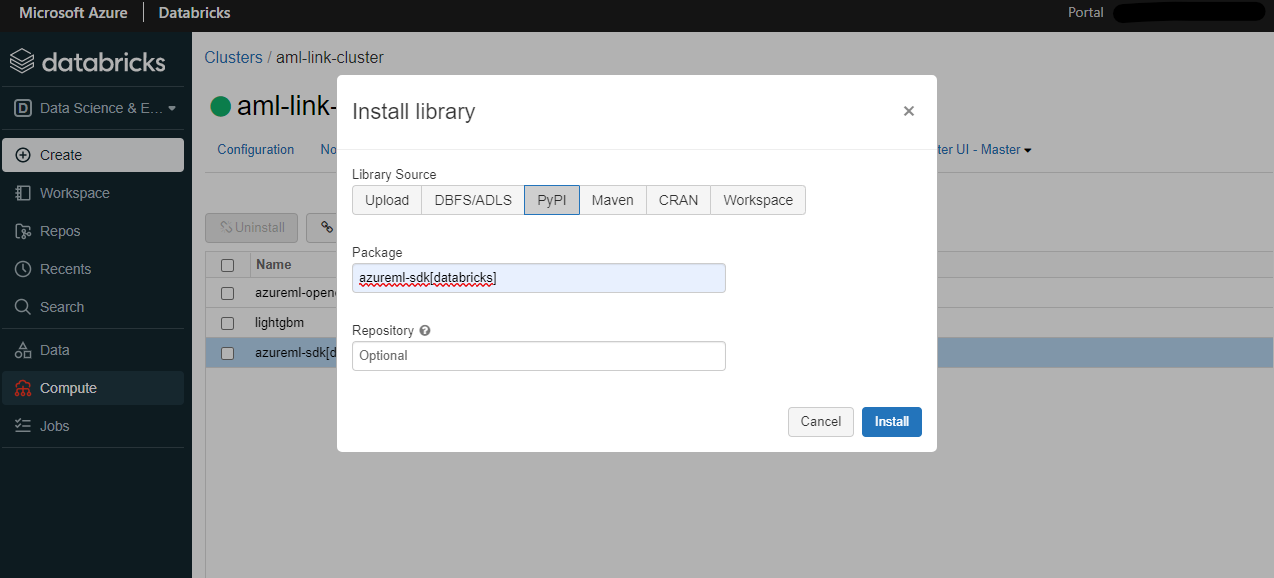
PyPI を選択し、Package 欄に「azureml-sdk[databricks]」と入力し、「Install」をクリックします。
同じ手順で以下パッケージもインストールします。
- azureml-opendatasets
- lightgbm
クラスターの準備は以上で完了です。
続いて Azure Machine Learning Pipelines での使用に向けて、Azure Databricks のアクセストークンを取得します。
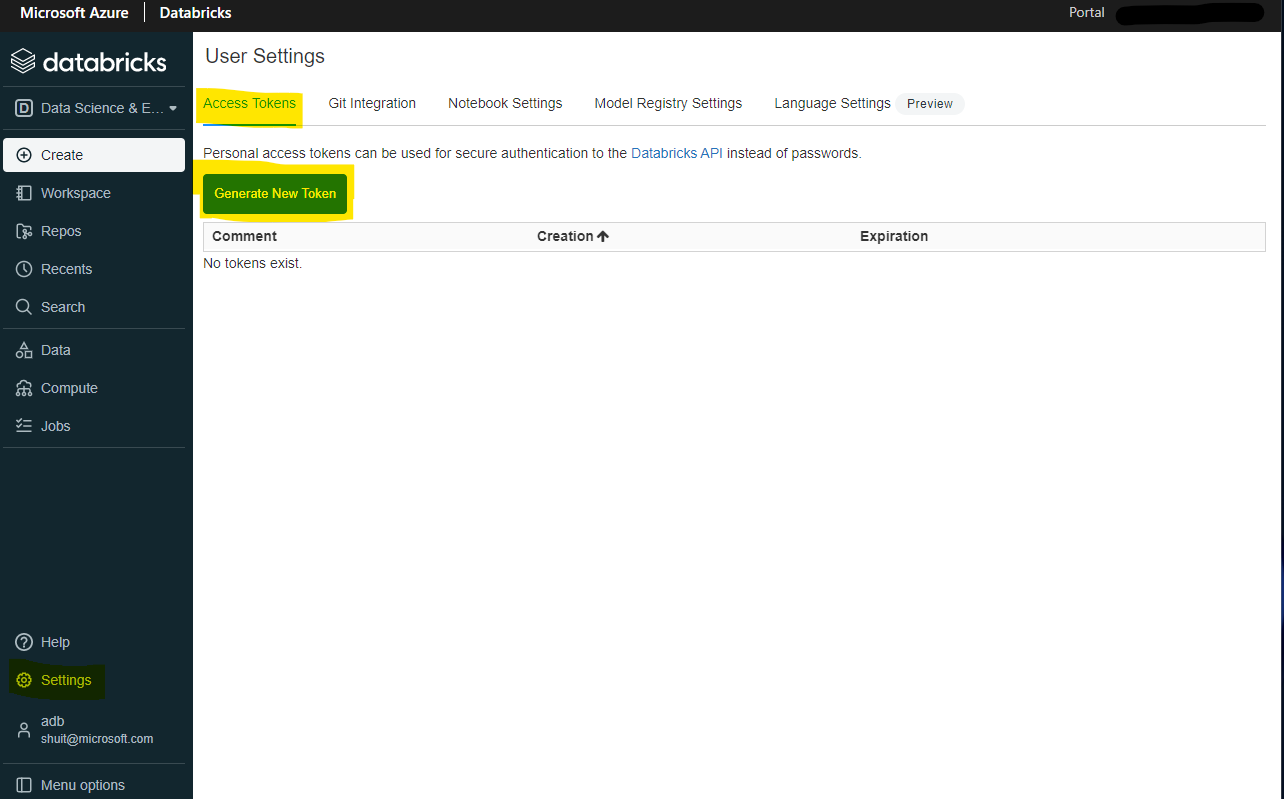
左メニューの「Settings」から「Access Tokens」→「Generate New Token」をクリックします。
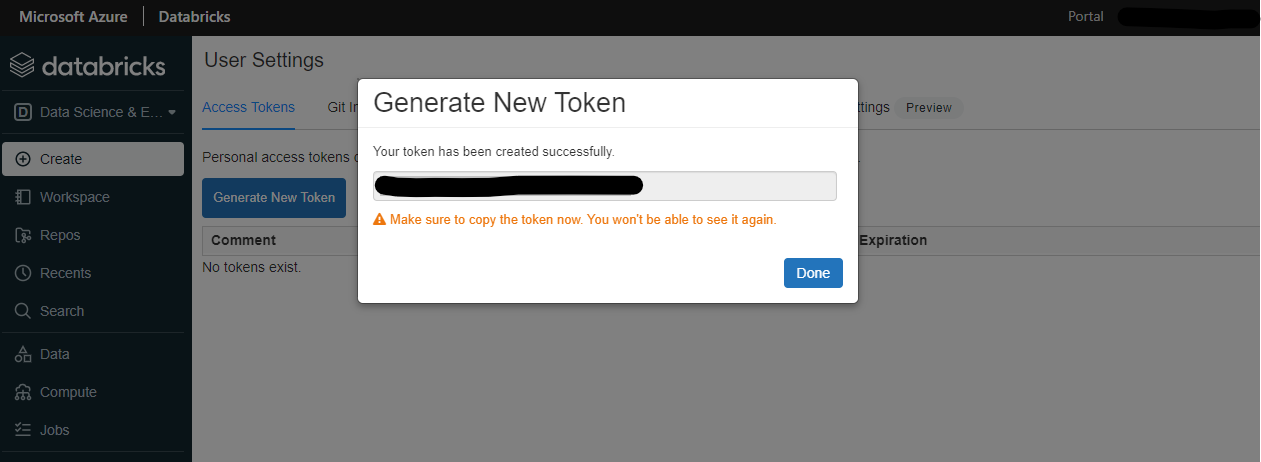
適当なトークン名をつけて、life spanを設定するとトークンを取得できます。life span は何も設定しないと無期限になるようです。一度作ると再生成できないので、どこかにメモっておきます。流出すると大惨事なので管理には十分に注意を払いましょう。
Compute targets の登録
Azure Machine Learning Pipelines の前準備として、 Compute targets に Azure Databricks を登録しておきます。
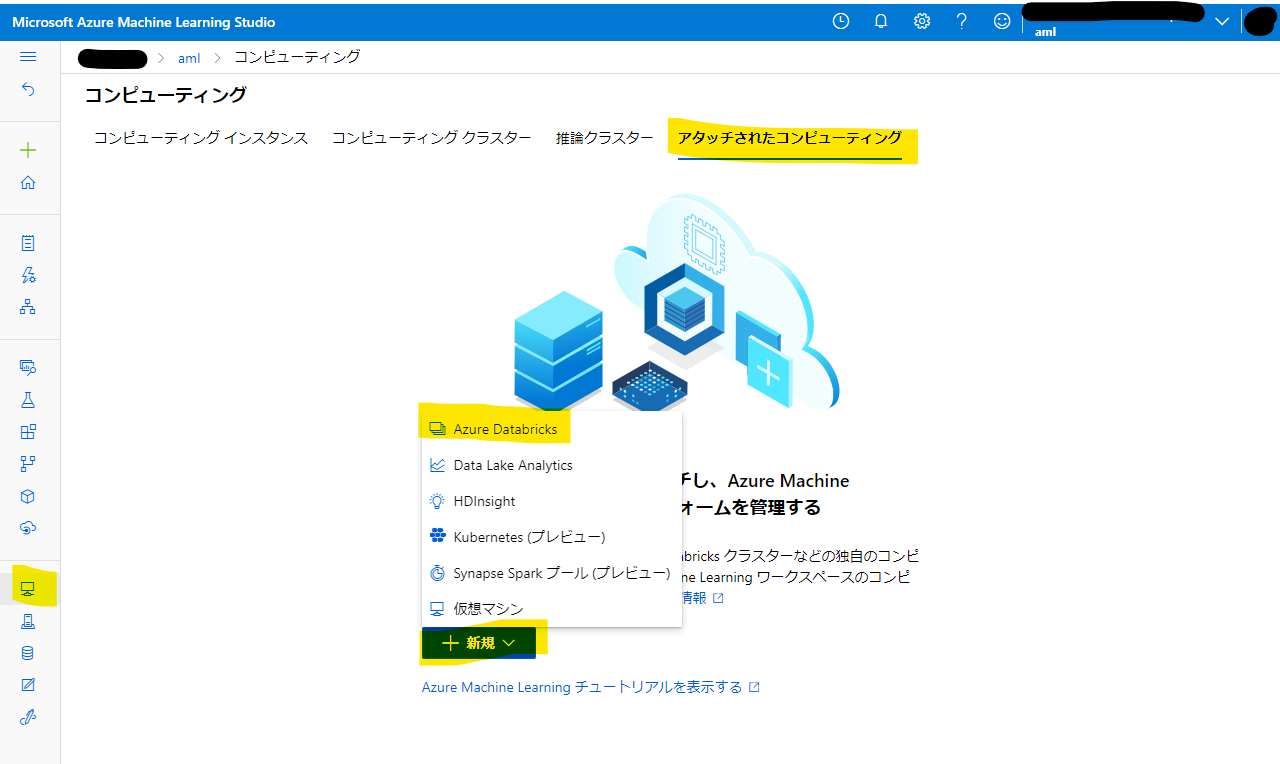
Azure Machine Learning Studio 左メニューの Compute targets →「アタッチされたコンピューティング」→「新規」→「Azure Databricks」とたどり、登録を開始します。
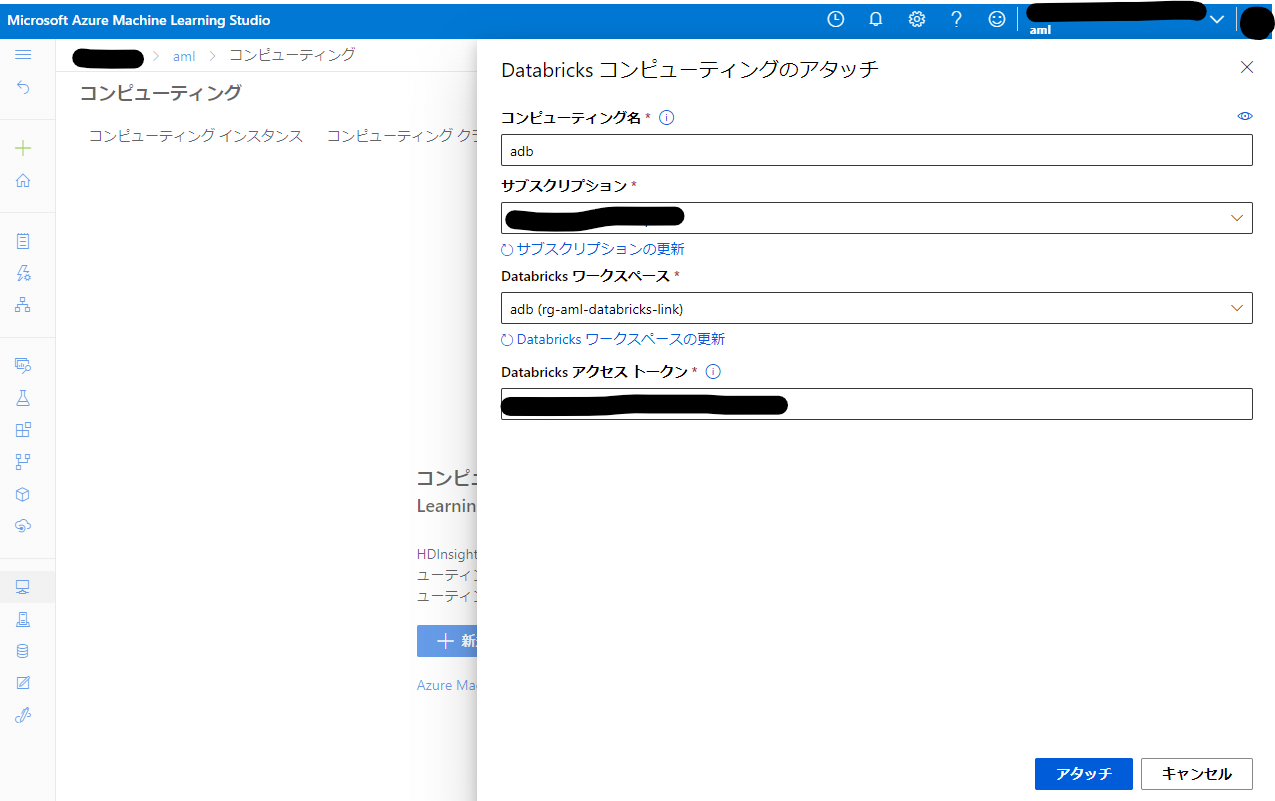
適当な名称をつけて Azure Databricks ワークスペースを選択したら、先ほど作成した Azure Databricks のアクセストークンを入力して「アタッチ」をクリックします。
余談: セキュリティ
Azure Machine Learning は素の状態でも Azure Active Directory による RABC で権限管理ができますが、さらに Private Endpoint を使用して特定の仮想ネットワーク内のリソースにアクセスを限定することでセキュリティを高めることができます。
Azure Machine Learning は複数のリソースに依存している都合上、構成にあたっては注意点がたくさんあります。いつかその辺りも記事にしたいところです。
Azure Databricks も Azure Active Directory による RBAC による権限管理に加え、隠蔽されている諸々のリソースを特定の VNet に展開する機能と、計算リソースに Public IP を付与しないにようにする機能の2つでさらにセキュリティを高めることができます。
扱うデータや要件、プロジェクトの段階にもよりますが、多層防御の観点からはこうした仮想ネットワークを活用したセキュリティ対策 (閉域化と呼んでいます) が必要になることもあります。
現時点では完全には検証が済んでいないのですが、閉域化状態であっても以下の手順はそのまま使えそうです。
LightGBM による回帰と実験記録
Azure Databricks の左側メニューから「Create」→「Notebook」とクリックしていき、ノートブックを作成します。
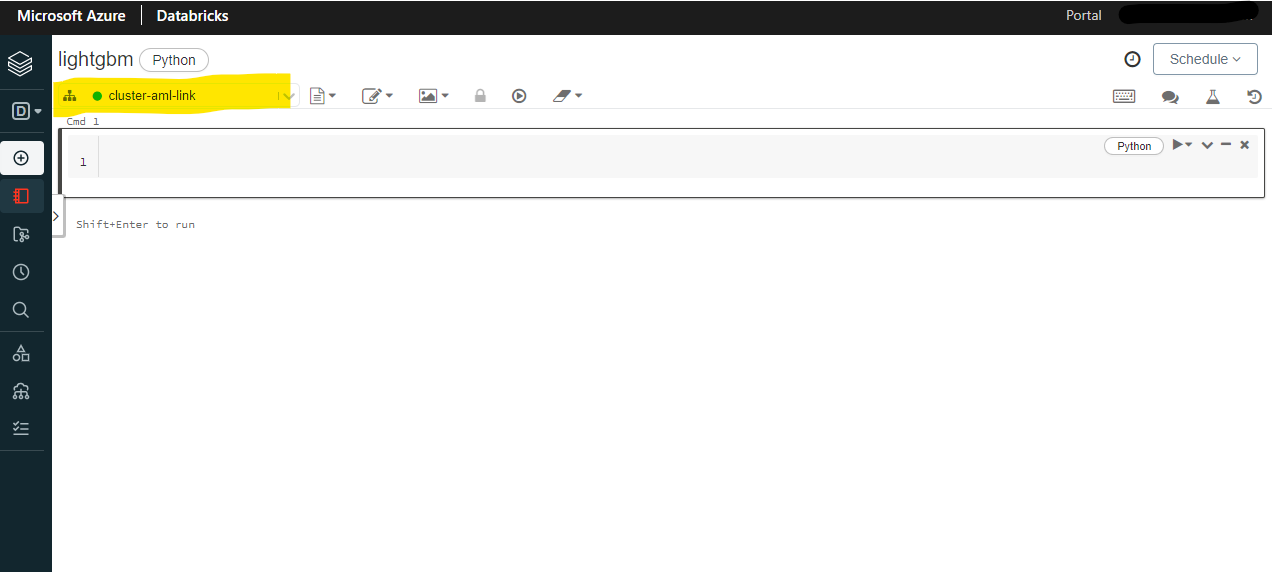
Jupyter Notebook によく似た画面ですね。左上にノートブックがアタッチされているクラスターが表示されています。きちんとクラスターがアタッチされているか見ておきましょう。当たり前ですが、ちゃんと起動している (緑色の丸) クラスターをアタッチしておかないと何もできません。
これで一通りの準備は終わりました。ここからはコードを書いていきます。
LightGBM を使用して回帰モデルを作成します。
まずはこれから使う依存パッケージの類を import します。
import lightgbm as lgb
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score
from sklearn.metrics import mean_squared_error
import numpy as np
import pandas as pd
from azureml.core import Workspace, Dataset, Experiment, Run
from azureml.opendatasets import NycTlcGreen
import time
import cloudpickle
import copy
from datetime import datetime
from dateutil.relativedelta import relativedelta
続いて Azure Machine Learning ワークスペースに接続します。
subscription_id = 'subscription_id'
resource_group = 'resource_group_name'
workspace_name = 'workspace_name'
ws = Workspace.get(name=workspace_name,
subscription_id=subscription_id,
resource_group=resource_group)
実行すると
Performing interactive authentication. Please follow the instructions on the terminal.
To sign in, use a web browser to open the page https://microsoft.com/devicelogin and enter the code ABCDEFGHI to authenticate.
というメッセージが出るので、Azure Machine Learning ワークスペースにログイン可能なアカウントでログインを行います。
続いてデータを用意します。
今回は Azure Open Datasets に収録されている NYC タクシー&リムジン協会 - グリーンタクシー運行記録データセット1の2015年1月から3月までの各月のデータからランダムに2000件ずつ、合計6000件のデータを使用します。
raw_df = pd.DataFrame([])
start = datetime.strptime("1/1/2015","%m/%d/%Y")
end = datetime.strptime("1/31/2015","%m/%d/%Y")
for sample_month in range(3):
temp_df_green = NycTlcGreen(start + relativedelta(months=sample_month), end + relativedelta(months=sample_month)) \
.to_pandas_dataframe()
raw_df = raw_df.append(temp_df_green.sample(2000))
raw_df.head(10)
今回の目的変数はtotalAmountです。
続いて生データに対して前処理を施していきます。
df = copy.deepcopy(raw_df)
columns_to_remove = ["lpepDropoffDatetime", "puLocationId", "doLocationId", "extra", "mtaTax",
"improvementSurcharge", "tollsAmount", "ehailFee", "tripType", "rateCodeID",
"storeAndFwdFlag", "paymentType", "fareAmount", "tipAmount"
]
for col in columns_to_remove:
df.pop(col)
df = df.query("pickupLatitude>=40.53 and pickupLatitude<=40.88")
df = df.query("pickupLongitude>=-74.09 and pickupLongitude<=-73.72")
df = df.query("tripDistance>=0.25 and tripDistance<31")
df = df.query("passengerCount>0 and totalAmount>0")
df["lpepPickupDatetime"] = df["lpepPickupDatetime"].map(lambda x: x.timestamp())
df.head(5)
不要なカラムの除去、外れ値の除去、日付の UNIX タイムスタンプへの変換を行っています。
続いて学習データとテストデータの分割と、説明変数を収めたデータフレームと目的変数を収めたデータフレームへの分割を行います。
train, test = train_test_split(df, test_size=0.2, random_state=1234)
x_train = train[train.columns[train.columns != 'totalAmount']]
y_train = train['totalAmount']
x_test = test[test.columns[test.columns != 'totalAmount']]
y_test = test['totalAmount']
最後に LightGBM に入力するための専用形式に変換します。
lgb_train = lgb.Dataset(x_train, y_train)
lgb_eval = lgb.Dataset(x_test, y_test, reference=lgb_train)
これでデータの準備は完了です。
ここからいよいよ実験記録をしつつ学習を実行していきます。まずは Experiment を作成します。
experiment = Experiment(ws, "nyc_taxi_lightgbm_regression")
続いて Experiment 配下の Run を作成します。
名前は何でも良いですが、今回は好みでタイムスタンプを入れています。
run = experiment.start_logging(display_name=f'lightgbm_run_{int(time.time())}')
続いて LightGBM のハイパーパラメーターを決めます。値は適当です。
定義した辞書オブジェクトをそのままrun.add_propertiesで Run に登録します。
params = {
'task': 'train',
'boosting_type': 'gbdt',
'objective': 'regression',
'metric': 'rmse',
'learning_rate': 0.1,
'num_leaves': 10,
'min_data_in_leaf': 1,
'num_iteration': 100,
'verbose': 0
}
run.add_properties(params)
学習を実行します。
gbm = lgb.train(
params,
lgb_train,
num_boost_round=50,
valid_sets=lgb_eval,
early_stopping_rounds=10
)
モデルを保存します。
model_path = 'model.pickle'
with open(model_path, mode='wb') as f:
cloudpickle.dump(gbm, f)
推論結果と評価指標を得て、それぞれ Run に保存します。(既に学習の過程で得ているものもありますが、単に2件以上適当な評価指標が欲しかっただけなのでご容赦を)
y_pred = gbm.predict(x_test, num_iteration=gbm.best_iteration)
pred = {
"schema_type": "predictions",
"schema_version": "1.0.0",
"data": {
"prediction": list(y_pred)
}
}
run.log_predictions('test', pred)
test_score = r2_score(y_test, y_pred)
print(test_score)
run.log('r2', test_score)
test_RMSE_score = np.sqrt(mean_squared_error(y_test, y_pred))
print(test_RMSE_score)
run.log('rmse', test_RMSE_score)
run.log_predictionsが推論結果の保存、run.log が評価指標の保存です。
最後に Run を終了させ、モデルの保存を実行します。
run.complete()
run.register_model(model_name='nyc_taxi_regression_lightgbm', model_path='outputs/model.pickle')
run.complete() を実行した時点で実行ディレクトリのスナップショットが作成され、丸ごと Run 配下にコピーされます。その後run.register_model()を実行していますが、これは引数のmodel_pathがスナップショット内のパスを要求しているので、明示的にモデルを Run に送信するか run 終了後 (≒スナップショットが取られてモデルファイルも送信されるタイミング) に実行する必要があるためです。model_pathがmodel.pickleではなくoutputs/model.pickleである理由ですが、出力したファイルはこのディレクトリに入るためです。
スナップショットが取られるディレクトリは通常はコードを実行したディレクトリになるはずですが、 Databricks の場合はどこなんだかよく分からないディレクトリが保存されているので、ここはもうちょっとうまいやり方がありそうです。
コードの管理については Databricks 側でも Git リポジトリと連携する機能があるので、そちらを使うのがワークアラウンドになりそうです。
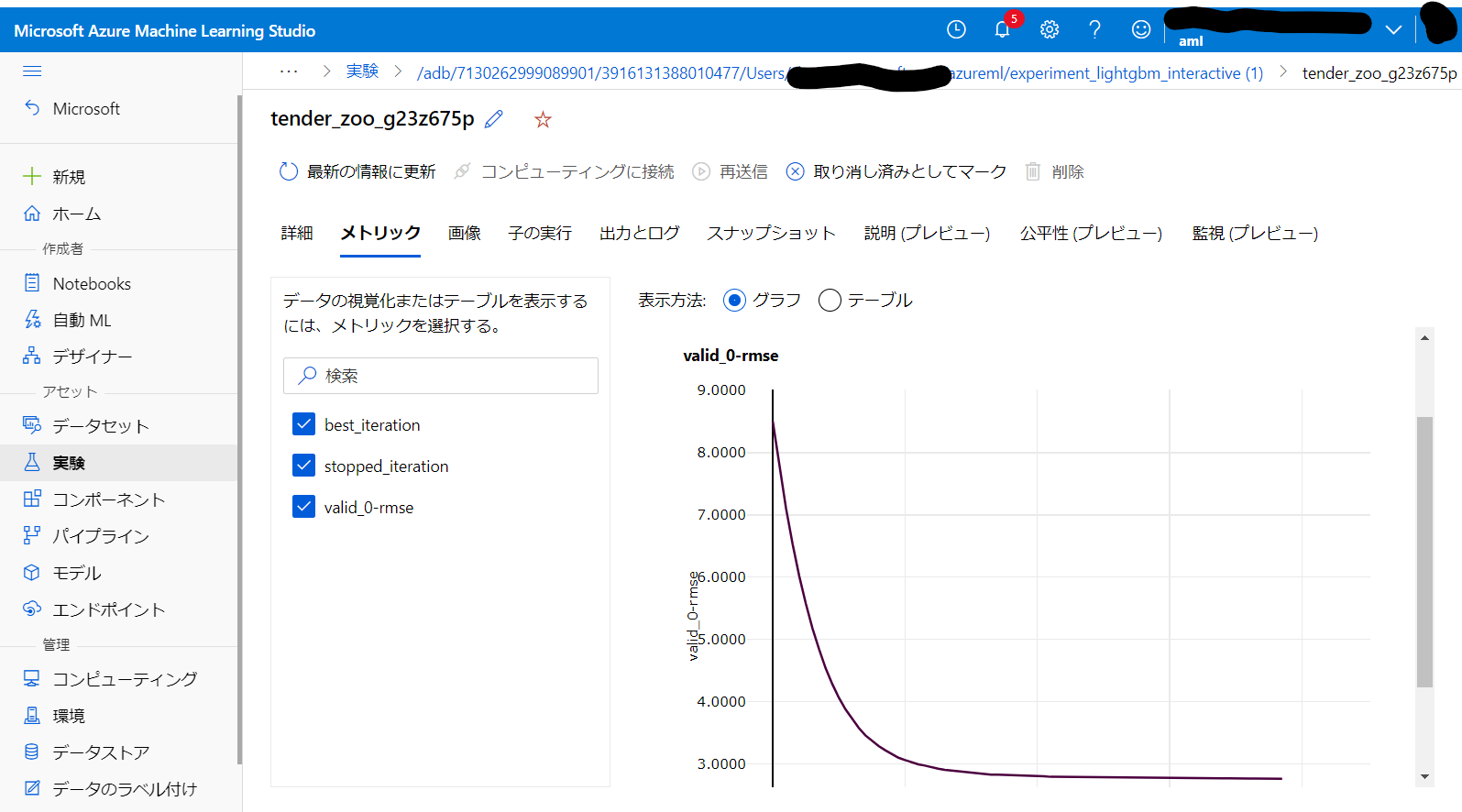
実験はここまでです。きちんと記録が取れているか確認してみます。
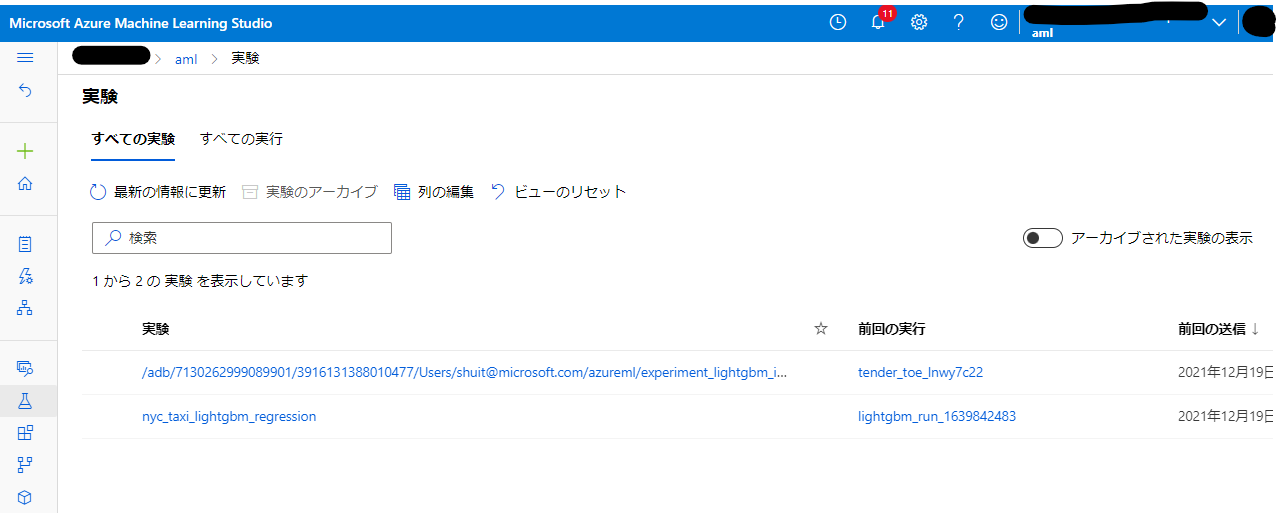
きちんと指定した名称の Experiment ができています。(もう2つの実験の方はあとの方に載せた「Azure Databricks と Azure Machine Learning をリンクして実験記録を取る話」で取得した実験記録です)
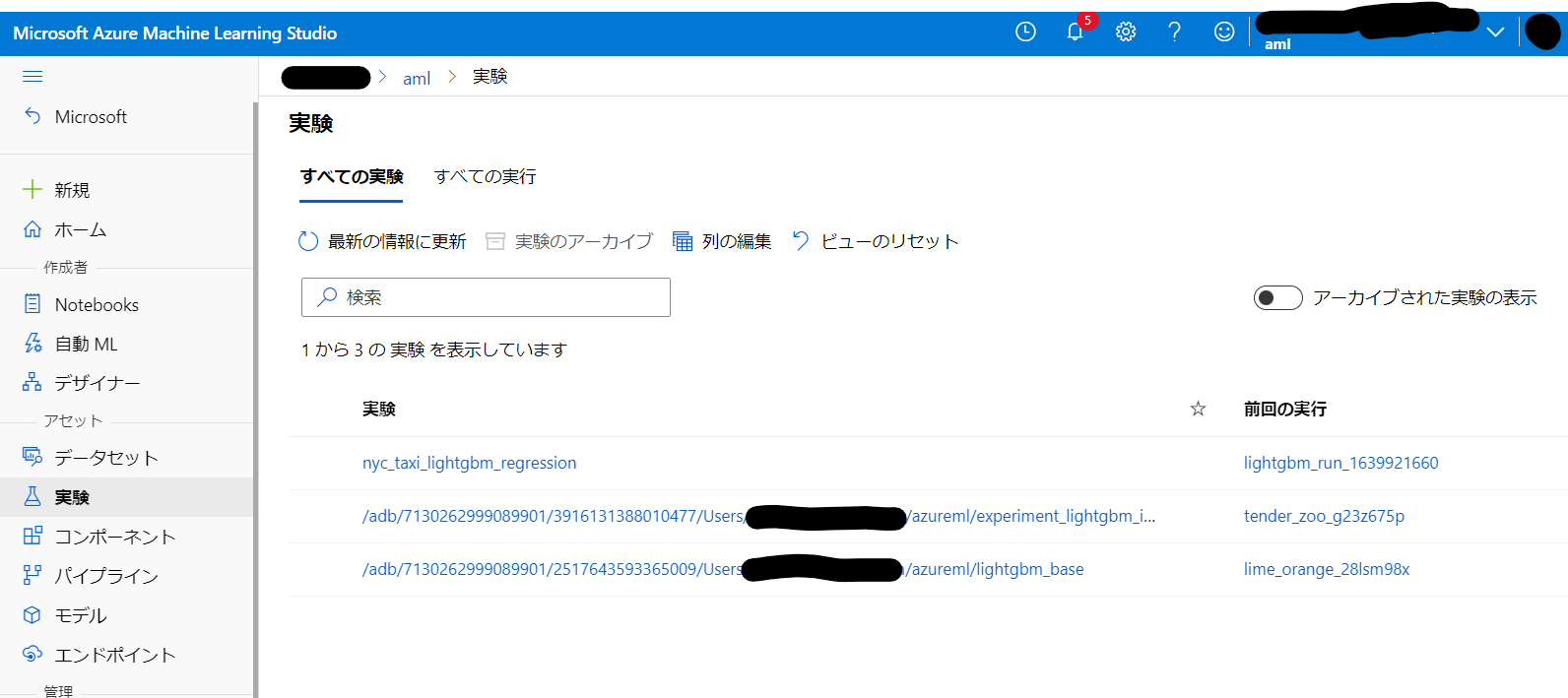
Run も問題なく作成されています。
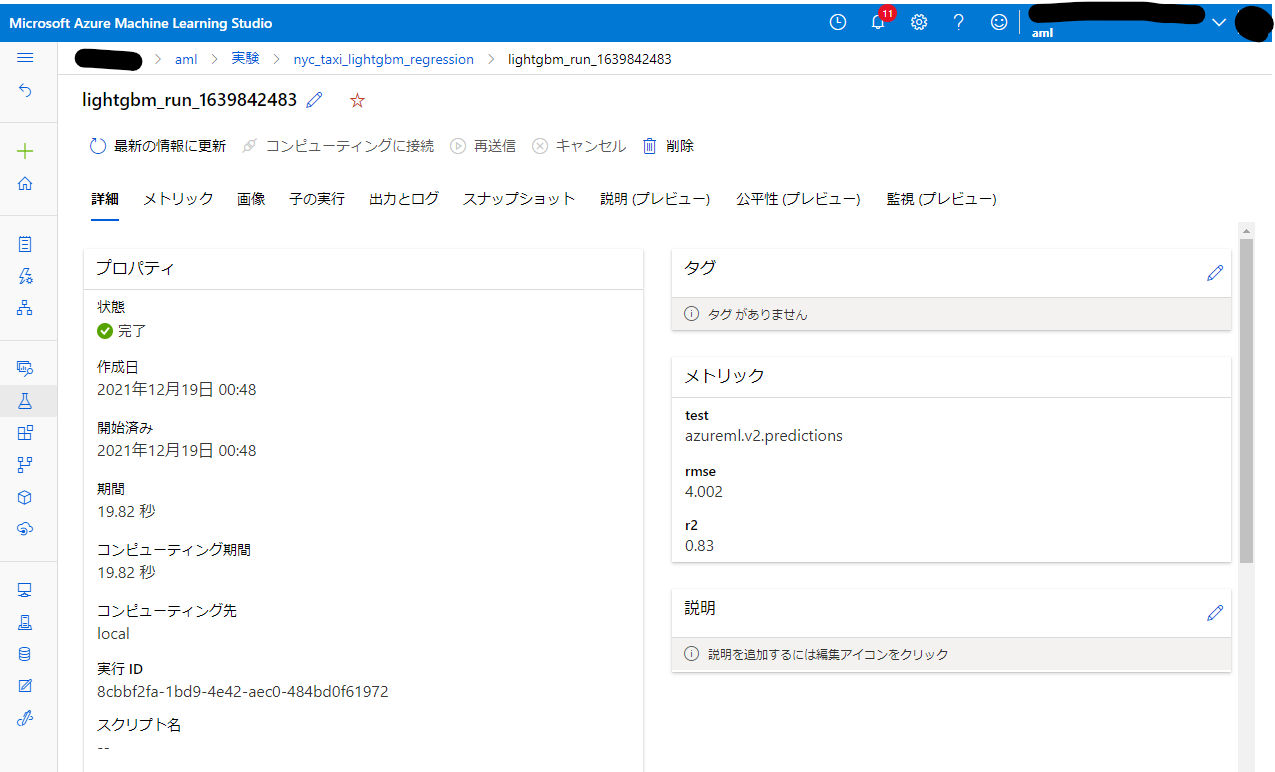
評価指標も記録できています。
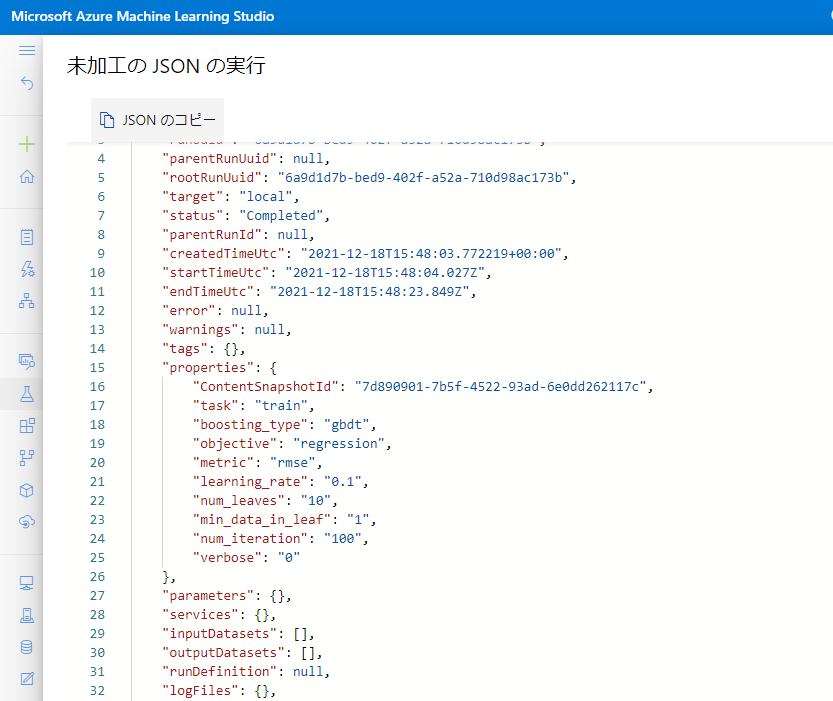
パラメーターは「生 JSON」に格納されていました。翻訳……。
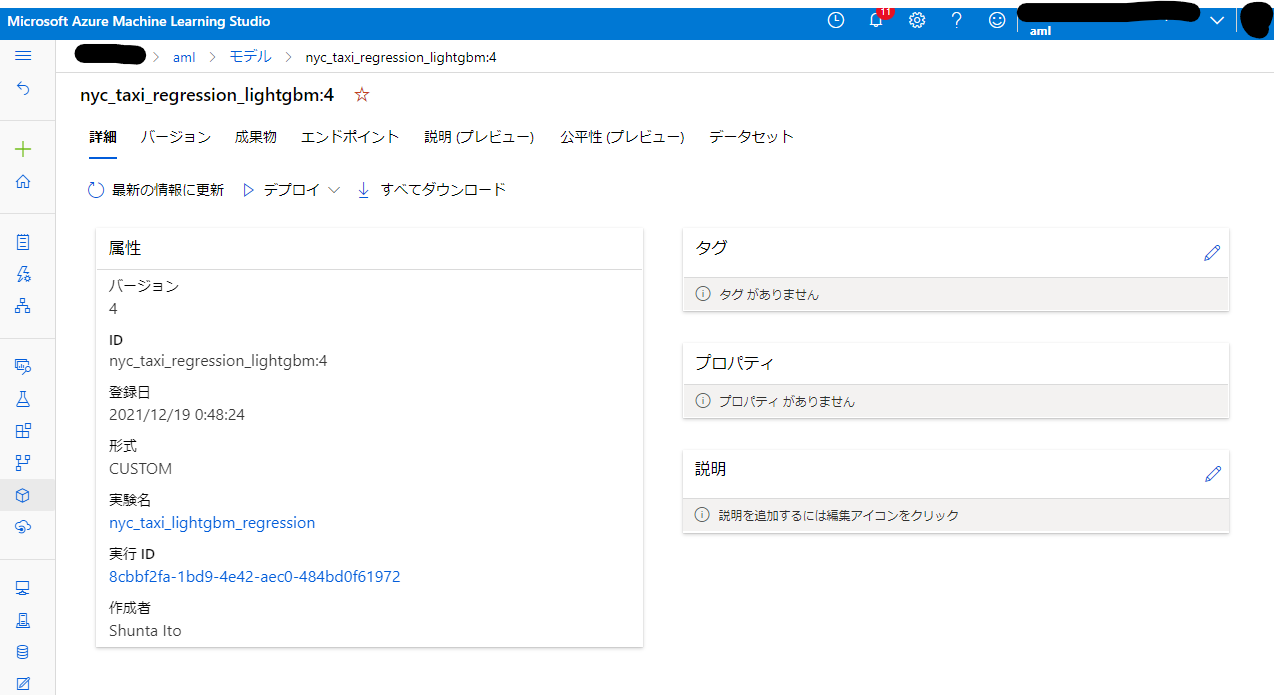
モデルの登録もできていますね。
最低限度ではありますが、一通り実験記録を取得できていることが確認できました。
Azure Databricks ノートブックを使用したパイプラインの構築
先ほど作成した LightGBM の実験を行うノートブックを使用したパイプラインを構築し、Azure Machine Learning Pipeline として登録します。
本当はデータの入出力とか前処理とか一連のフローとして定義すると格好いいのですが、今回はアドベントカレンダーの担当日まで時間が無いので割愛します。
例によって必要なライブラリを import します。
from azureml.core import Workspace
from azureml.core import Experiment, Run
from azureml.core.compute import DatabricksCompute
from azureml.core.compute import ComputeTarget
from azureml.core.databricks import PyPiLibrary
from azureml.pipeline.core import Pipeline, PipelineData
from azureml.pipeline.steps import DatabricksStep
import os
Azure Machine Learning ワークスペースに接続します。ここは LightGBM 実験と同じです。
subscription_id = 'subscription_id'
resource_group = 'resource_group_name'
workspace_name = 'workspace_name'
ws = Workspace.get(name=workspace_name,
subscription_id=subscription_id,
resource_group=resource_group)
Azure Machine Learning に登録した Azure Databricks の Compute targets オブジェクトを取得します。
databricks_compute = ComputeTarget(workspace = ws, name = 'adb')
パイプライン中で実行したノートブックのパスと、必要なライブラリを指定して、Azure Machine Learning Pipeline の DatabricksStep を構成します。先ほど作成した LightGBM の実験ノートブックを想定しています。
data_prep_path = os.getenv("DATABRICKS_PYTHON_SCRIPT_PATH", "/Users/<username>/<notebook-name>")
pypi_libraries = [PyPiLibrary(package = 'lightgbm'), PyPiLibrary(package = 'azureml-opendatasets')]
adb_step = DatabricksStep(name = "lightgbm",
run_name = 'lightgbm',
existing_cluster_id = '<cluster-id>',
notebook_path = data_prep_path,
pypi_libraries = pypi_libraries,
compute_target = databricks_compute,
allow_reuse = False
)
steps = [adb_step]
1行目のノートブックパスですが、ここは Users 個別のディレクトリにノートブックを作成した場合を想定しています。Shared に保存した場合は Shared から始めてください。
<username>は Azure Databrciks のユーザー名です。多くの場合 Azure Active Directory のアカウント名 (メールアドレス形式) を取るかと思います。
<cluster-id>のところは Azure Databricks の Compute から実行したいクラスターを選び、「Configuration」→「Advance options」→「Tags」と辿っていくと確認できます。
今回は DatabricksStep に1つきりですが、実際にはデータの保存や入出力等を定義して、Step 連なったワークフローとして定義します。
きちんと連続する Step を複数定義している良い記事を見つけました。参考にどうぞ。
最後にパイプラインを実行します。
pipeline = Pipeline(workspace = ws, steps = [steps])
pipeline.validate()
experiment = Experiment(ws, 'pipeline_nyc_taxi_lightgbm_regression')
pipeline_run = experiment.submit(pipeline)
pipeline_run.wait_for_completion(show_output = False)
Experiment の中に Pipeline 実行を含める形になっていますね。
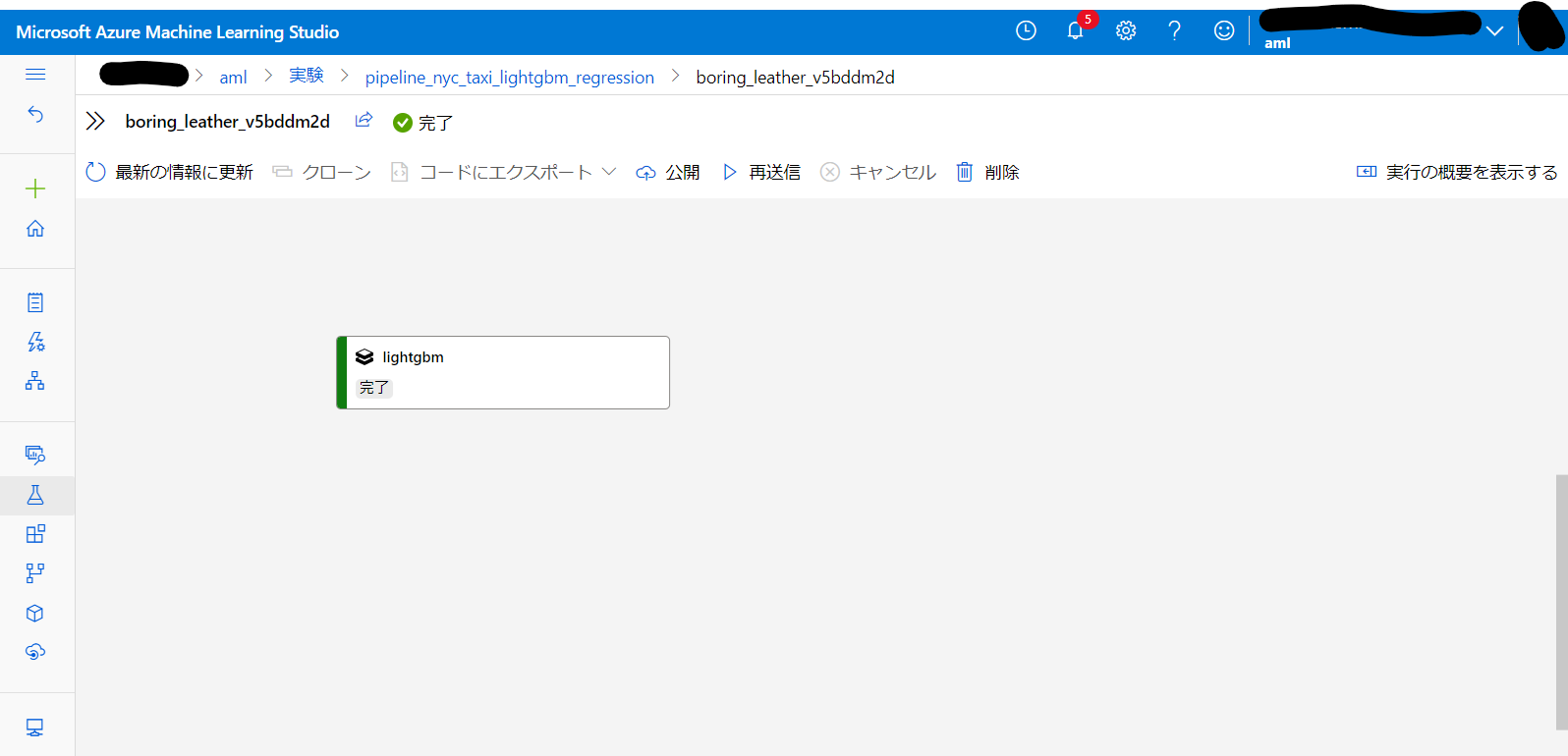
該当 Experiment を確認するとパイプラインの模式図が表示されています。(Step が1つしかないのでこれだけだと何のことやらという感じですが……)
完了となっていて、きちんと実行成功しているようです。これでパイプラインの作成と実行は完了です。
なお、今回はノートブック内に実験記録を含むコードを実行したのでそちらの記録も別に作成されています。
認証回りが怪しいまま実行して普通に通ってしまっている点が気になっています。今回は既に何度か Azure Machine Learning に対する認証を実行したクラスターでパイプラインを実行させたので認証できるのは分からなくもないのですが、これって例えば停止しているクラスターを起こして始めて実行する場合とかだとどうなるんでしょうか。Workspace.get()の実行で「ログインしろ」となってそのまま停止するのか、それとも Pipeline 側から何かしらのコンテキストが与えられて認証通るのか、どちらなんでしょう。
もし前者であればサービスプリンシパルと Key Vault 等の安全にシークレットを取り扱う仕組みが必要そうです。以下関連するサンプルノートブックやドキュメントの記事です。この辺りは年明けに検証してみようと思います。
おわりに
Azure Databricks で実験を実行して Azure Machine Learning で実験記録を取れることを確認し、さらにできあがったノートブック Azure Machine Learning Pipeline の一部として組み込みパイプラインとして実行できることが確認できました。
おまけに記載したやり方が実行できるとなおよしですが、このあたりは年明けの課題とします。
皆さま1年お疲れさまでした。良いお年を。
おまけ
Azure Databricks と Azure Machine Learning をリンクして実験記録を取る話 (失敗)
先に言っておくと、こちらの手順は 2021/12/18 現時点では動作せず失敗に終わった手順となります。以下ドキュメント通りだと思うのですが、何がダメだったのか……。
もしこのやり方で連携ができると Azure Databricks に統合されたマネージド MLflow で Azure Machine Learning に実験記録を取れるようになる& mlflow.*.autolog() で一部フレームワークについてはもはや実験記録用のコードすら不要ということでとても期待していたのですが、完全には動作しませんでした。
折角書いた記事下書きの供養といつか動くようになることを期待する意味で、こちらに残しておきます。
Azure Machine Learning と Azure Databricks のリンク
リソースのデプロイが完了すると、リソースグループ内に以下のように5個 (Azure Machine Learning ワークスペース作成時に明示的に Container Registry を作成した場合は6個) のリソースが展開された状態になるかと思います。
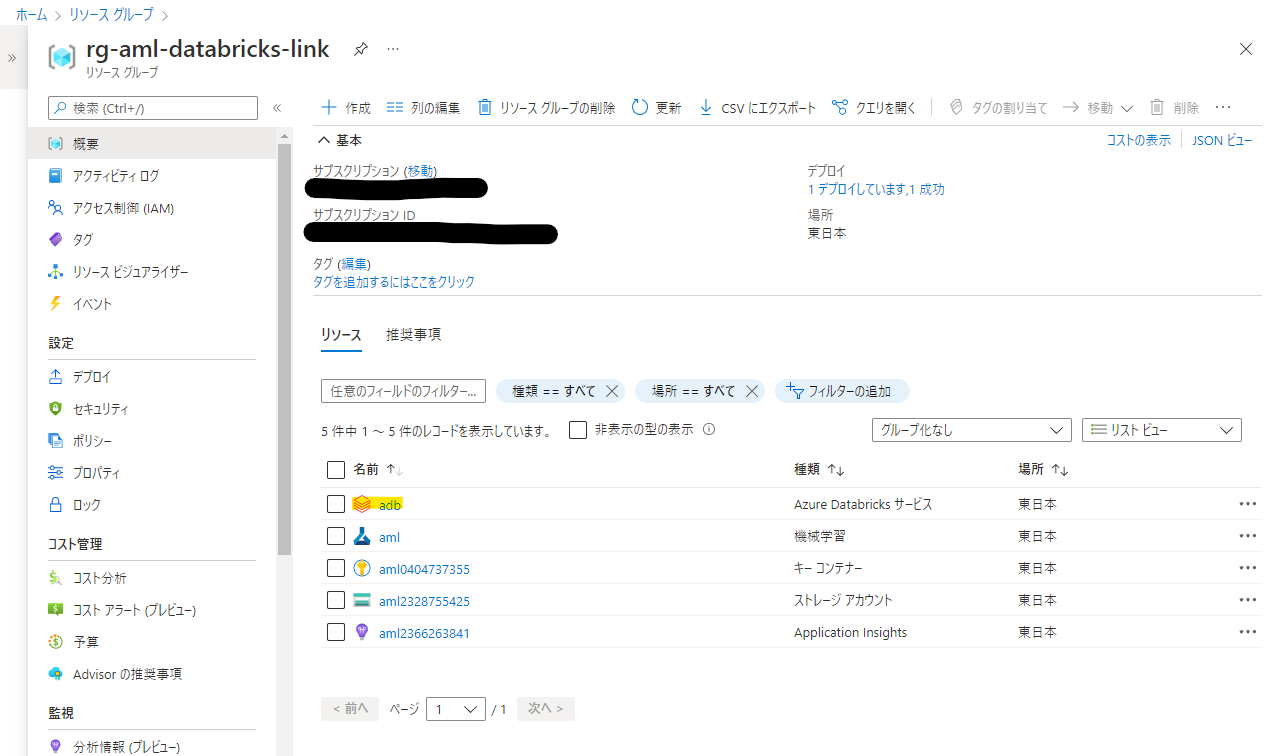
Azure Databricks のリソースをクリックして、管理画面に入ります。
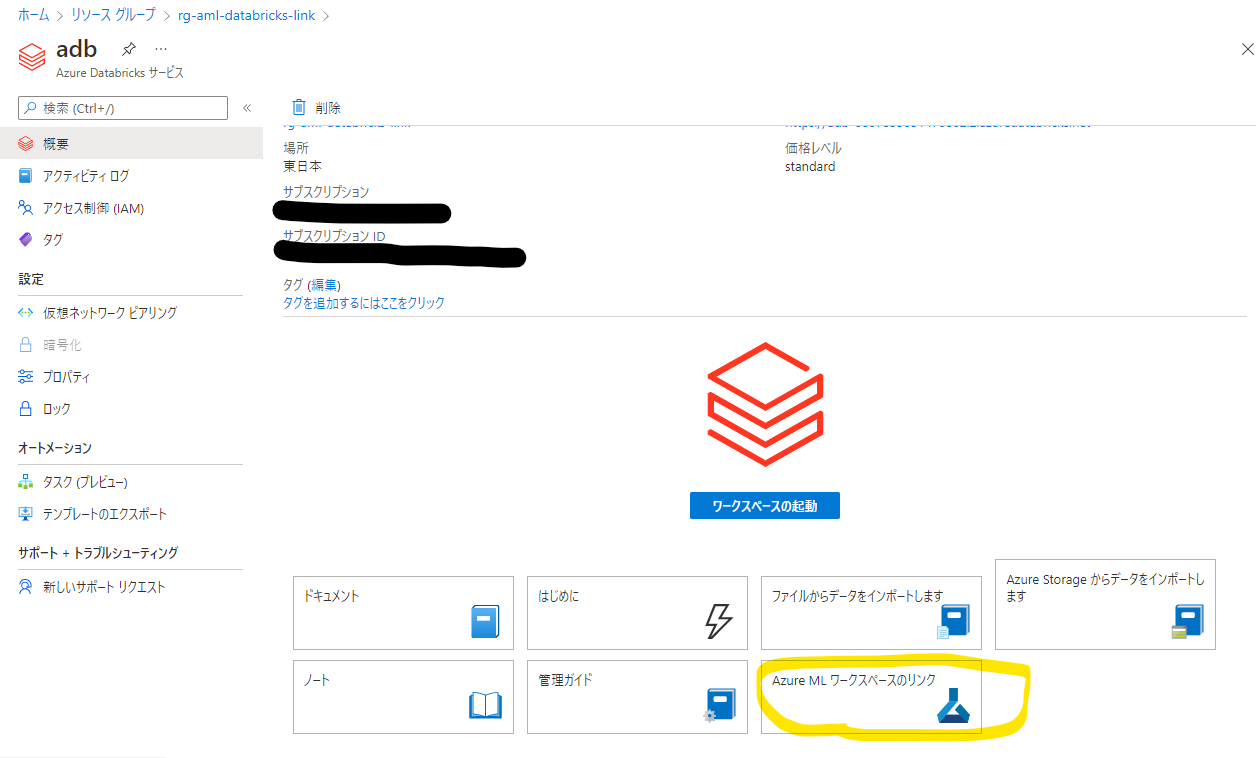
「Azure ML ワークスペースのリンク」という項目があるので、こちらをクリックします。
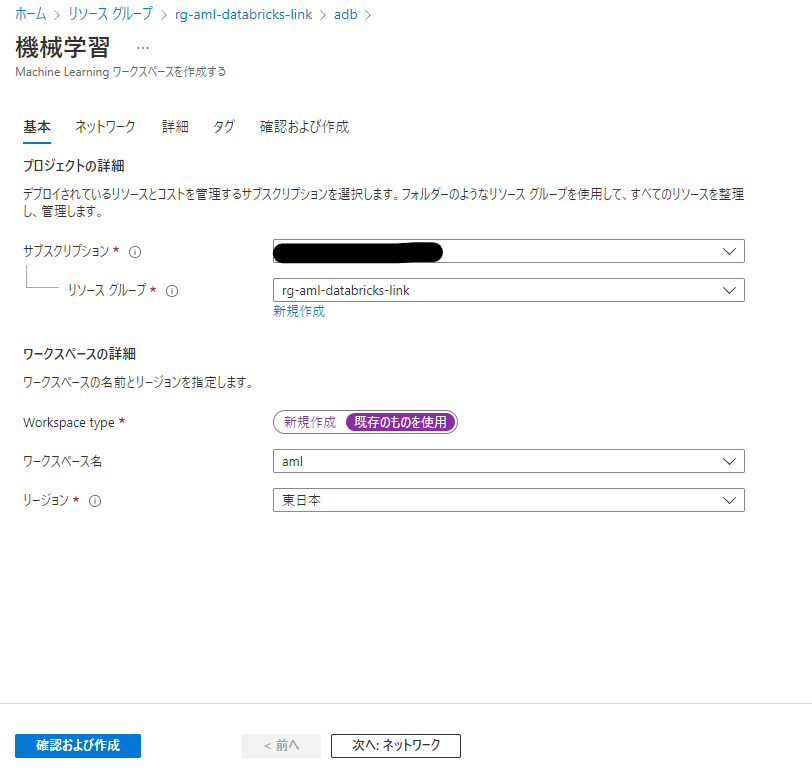
「既存のものを使用」を選択し、作成した Azure Machine Learning ワークスペースを選択します。あとはデフォルトで問題ありません。「確認および作成」をクリックして、リンクを作成します。
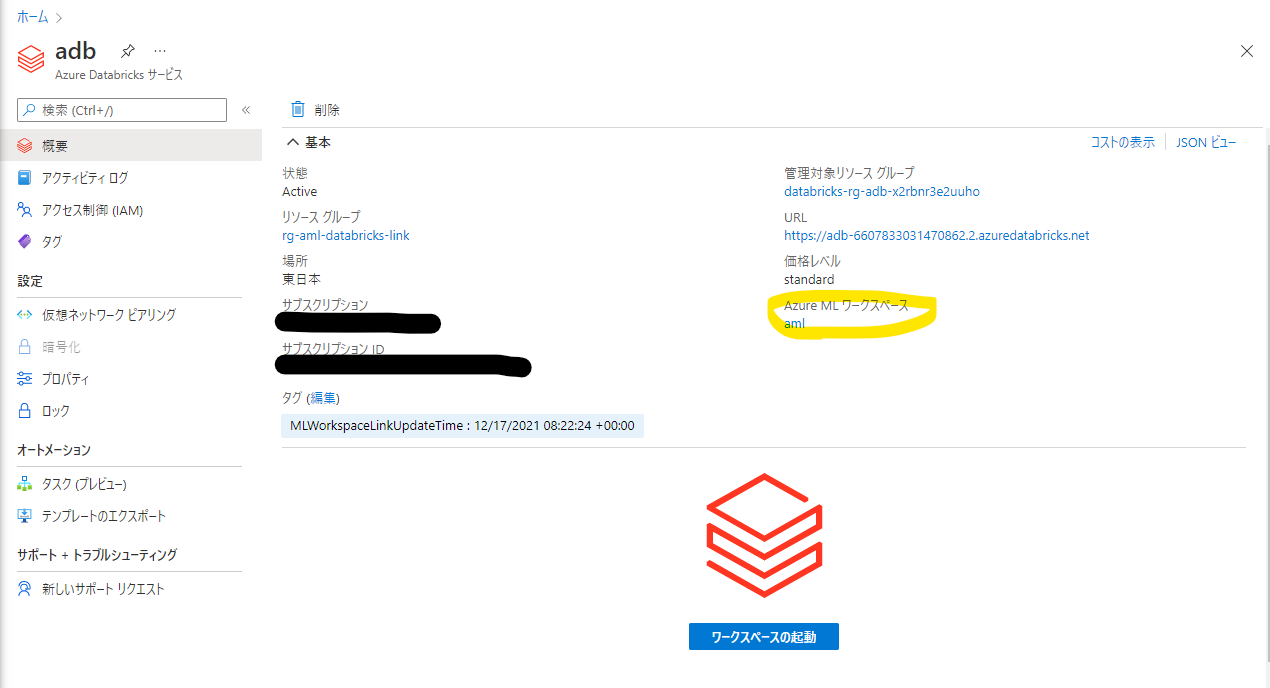
リンクの作成が完了すると、Azure Databricks の管理画面にリンクした Azure Machine Learning ワークスペースの名称が表示されるようになります。
コードと結果
コードの全文を記載します。基本的には同じことをしていますが、実験記録に MLflow を使用している点と、 autolog で一部自動的に実験記録が取れている点が異なります。
import mlflow
import mlflow.azureml
import azureml.mlflow
import azureml.core
from azureml.core import Workspace
from azureml.opendatasets import NycTlcGreen
from datetime import datetime
from dateutil.relativedelta import relativedelta
import numpy as np
import pandas as pd
import lightgbm
import mlflow.lightgbm
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score
from sklearn.metrics import mean_squared_error
import cloudpickle
import copy
subscription_id = 'subscription_id'
resource_group = 'resource_group_name'
workspace_name = 'workspace_name'
ws = Workspace.get(name=workspace_name,
subscription_id=subscription_id,
resource_group=resource_group)
experimentName = "/Users/shuit@microsoft.com/azureml/lightgbm"
mlflow.set_experiment(experimentName)
raw_df = pd.DataFrame([])
start = datetime.strptime("1/1/2015","%m/%d/%Y")
end = datetime.strptime("1/31/2015","%m/%d/%Y")
for sample_month in range(3):
temp_df_green = NycTlcGreen(start + relativedelta(months=sample_month), end + relativedelta(months=sample_month)) \
.to_pandas_dataframe()
raw_df = raw_df.append(temp_df_green.sample(2000))
columns_to_remove = ["lpepDropoffDatetime", "puLocationId", "doLocationId", "extra", "mtaTax",
"improvementSurcharge", "tollsAmount", "ehailFee", "tripType", "rateCodeID",
"storeAndFwdFlag", "paymentType", "fareAmount", "tipAmount"
]
df = copy.deepcopy(raw_df)
for col in columns_to_remove:
df.pop(col)
df = df.query("pickupLatitude>=40.53 and pickupLatitude<=40.88")
df = df.query("pickupLongitude>=-74.09 and pickupLongitude<=-73.72")
df = df.query("tripDistance>=0.25 and tripDistance<31")
df = df.query("passengerCount>0 and totalAmount>0")
df["lpepPickupDatetime"] = df["lpepPickupDatetime"].map(lambda x: x.timestamp())
columns_to_remove_for_training = ["pickupLongitude", "pickupLatitude", "dropoffLongitude", "dropoffLatitude"]
for col in columns_to_remove_for_training:
df.pop(col)
df.head(5)
train, test = train_test_split(df, test_size=0.2, random_state=1234)
x_train = train[train.columns[train.columns != 'totalAmount']]
y_train = train['totalAmount']
x_test = test[test.columns[test.columns != 'totalAmount']]
y_test = test['totalAmount']
lgb_train = lightgbm.Dataset(x_train, y_train)
lgb_eval = lightgbm.Dataset(x_test, y_test, reference=lgb_train)
mlflow.lightgbm.autolog(log_models=True)
with mlflow.start_run() as run:
gbm = lightgbm.train(params, lgb_train, num_boost_round=50, valid_sets=lgb_eval)
y_pred = gbm.predict(x_test, num_iteration=gbm.best_iteration)
test_score = r2_score(y_test, y_pred)
print(test_score)
test_RMSE_score = np.sqrt(mean_squared_error(y_test, y_pred))
print(test_RMSE_score)
mlflow.log_metric('R2', test_score)
mlflow.log_metric('RMSE', test_RMSE_score)
このコードを実行すると Run を終わらせようとしたタイミングで Azure Machine Learning 側起因で Bad request エラーになってしまいます。with から始めて該当処理が終了した時点でも、明示的に Run を終了させた場合でも同様です。様子を見ていると Experiment と Run を作成した時点では Azure Databricks と Azure Machine Learning 双方にきちんと該当のオブジェクトが作成されるのですが、Azure Machine Learning 側の Run はステータスが未開始になっています。未開始だから終了ができずエラーになってるんですかね。詳細はまた年明けに確認します。
ただ実験の記録自体は送信できています。