Hive-BigQuery Connector とは
Google CloudにDataprocというHadoopのマネージド・サービスがあります。数クリックでHadoopクラスタがすぐに構築でき、SparkやHiveなどのジョブを動かせます。Dataprocを利用する場合、データはHDFS(Hadoop Distributed File System)ではなく、Google Cloud Storageを利用するのが一般的です。そこにParquetなどのファイルを置いて、HiveテーブルにしてHiveクエリを投げたり、Sparkジョブでデータ処理したりできます。
一方、BigQueryのストレージを保存先にすることもできます。そのデータは、もちろんBigQueryでクエリすることもできますし、DataprocからHiveやSparkを使ってアクセスすることもできます。
今回はHiveからBigQueryのデータにアクセスするための、Hive-BigQuery Connectorを試してみます。
Dataprocへのインストール
DataprocでHadoopクラスタを構築した場合、デフォルトでHive-BigQuery Connectorはインストールされません。Dataprocには、init actionと呼ばれるクラスタ構築時に自動的に実行されるスクリプトを設定する機能があります。今回のコネクターをインストールする初期スクリプト自体もGoogle Cloudからこちら
で提供されています。
以下のコマンドでHive-BigQuery ConnectorがインストールされたHadoopクラスタが出来上がります。リージョンは適宜変えてください。
REGION=us-central1
CLUSTER_NAME=test-hive-bigquery-connector
gcloud dataproc clusters create ${CLUSTER_NAME} \
--region ${REGION} \
--initialization-actions gs://goog-dataproc-initialization-actions-${REGION}/connectors/connectors.sh \
--metadata hive-bigquery-connector-version=2.0.3
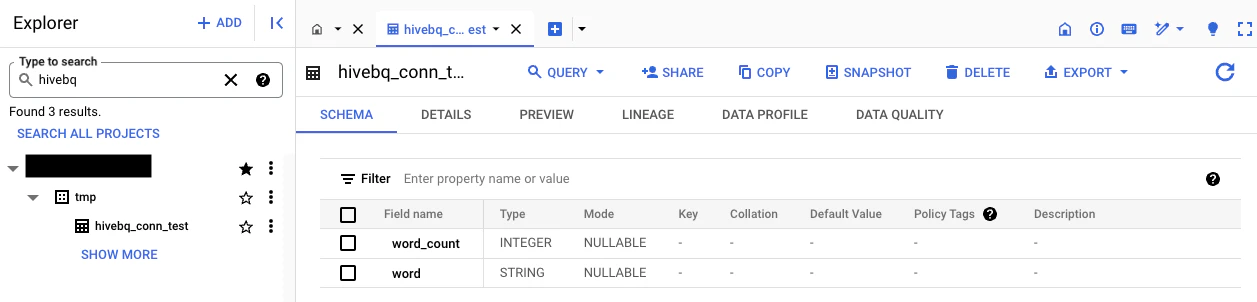
テーブルを作ってみる
BigQueryのテーブルを作成するHiveクエリを投げてみます。
gcloud dataproc jobs submit hive \
--cluster=test-hive-bigquery-connector \
-e="CREATE TABLE mytable (word_count BIGINT, word STRING)
STORED BY 'com.google.cloud.hive.bigquery.connector.BigQueryStorageHandler'
TBLPROPERTIES (
'bq.table'='myproject.mydataset.mytable'
);"
クエリの部分だけ抜き出すとこんな感じ。
CREATE TABLE mytable (word_count BIGINT, word STRING)
STORED BY 'com.google.cloud.hive.bigquery.connector.BigQueryStorageHandler'
TBLPROPERTIES (
'bq.table'='myproject.mydataset.mytable'
);
できました。
データ挿入してみる
次のコマンドを実行してHiveQLでBigQueryのテーブルにデータ挿入してみます。
gcloud dataproc jobs submit hive \
--cluster=test-hive-bigquery-connector \
-e="INSERT INTO TABLE mytable VALUES
(20, 'is'),
(3, 'Bob'),
(1, 'kind');"
入った。
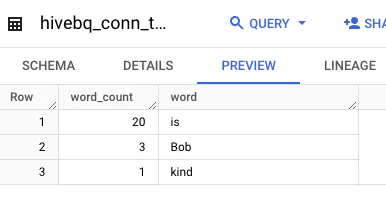
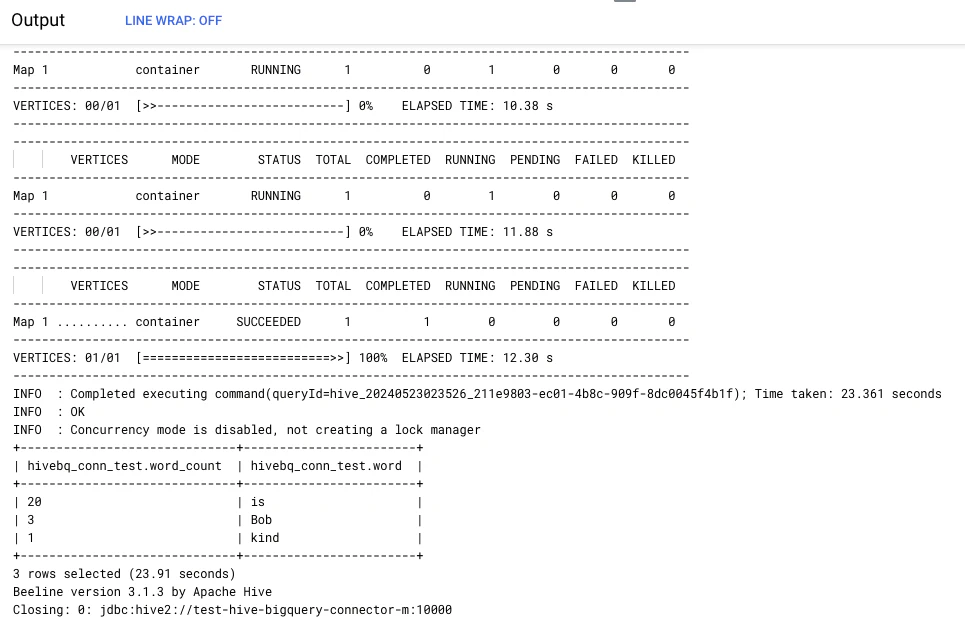
データ読んでみる
最後にデータを読んでみます。
gcloud dataproc jobs submit hive \
--cluster=test-hive-bigquery-connector \
-e="SELECT * FROM mytable;"
こんな感じのアウトプット。
もう少しまともなクエリをBigQueryのパブリックテーブルに投げてみます。BigQueryが持つパブリックデータセット bigquery-public-data.austin_bikeshare.bikeshare_trips にクエリを投げてみます。すでにあるテーブルをHiveでクエリするためには次のように外部テーブルとして認識させます。
gcloud dataproc jobs submit hive \
--cluster=test-hive-bigquery-connector \
-e="CREATE EXTERNAL TABLE bikeshare_trips (trip_id STRING, subscriber_type STRING, bike_id STRING, bike_type STRING, start_time TIMESTAMPLOCALTZ, start_station_id BIGINT, start_station_name STRING, end_station_id STRING, end_station_name STRING, duration_minutes BIGINT)
STORED BY 'com.google.cloud.hive.bigquery.connector.BigQueryStorageHandler'
TBLPROPERTIES (
'bq.table'='bigquery-public-data.austin_bikeshare.bikeshare_trips'
);"
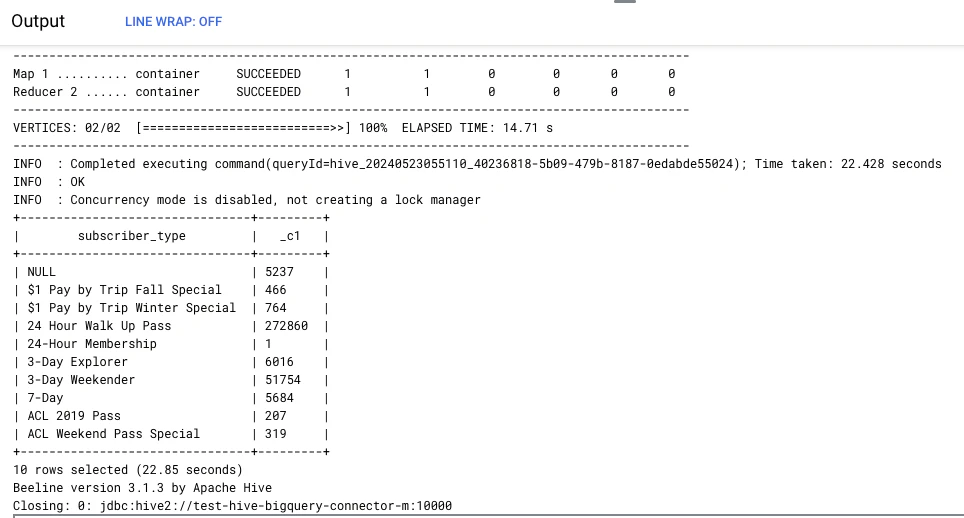
で、クエリしてみる。
gcloud dataproc jobs submit hive \
--cluster=test-hive-bigquery-connector \
-e="SELECT subscriber_type, COUNT(1)
FROM bikeshare_trips
GROUP BY subscriber_type
LIMIT 10;"
その他README読んで気になったこと
- パーティションやクラスタを適用したテーブルも作れる
- ちゃんとパーティションとクラスタのプルーニングも効く
- Predicate pushdownによって、一部のクエリはBigQuery Storage Read APIが使われる(つまりHiveの処理が減る)
- 書き込みはデフォルトでBigQuery Storage Write APIが使われるが、パラメーターでLoadを利用するindirect writeも選択できる。
- ビューやマテビューを読む場合、Strorage Read APIが直接使えないため、一時テーブルにマテリアライズするということをしている、そのため性能は劣化するしコストもかかる
- ビューの読み取りはデフォルト不可。オプションで有効化できる
- テーブルスナップショットは通常のテーブル同様利用できる
- BigLakeテーブルも読める
- デフォルトではクラスターのサービスアカウントでBigQueryのデータにアクセスするので、その権限付与が必要
- DMLはサポートされていない
- CTAS/CTLTはサポートされていない
まとめ
ぶっちゃけ同じSQLならBigQuery SQLに変換してBigQueryで処理させたほうがコストパフォーマンスはかなりいいと思いますが、クエリの書き換えなど移行が困難なものがあれば今回のコネクターを使うものありですね。