0.Prologue
「ElixirでDeep Learning系 NLP(Natural Language Processing)をやってみるぞ」
随分前に吹いた大法螺であった![]() 手始めに日本語形態素解析 Sudachiの Elixirバインディングを書いてはみたものの、アウェーで勝手の分からぬフィールド故にその後食指が動かなかった。
手始めに日本語形態素解析 Sudachiの Elixirバインディングを書いてはみたものの、アウェーで勝手の分からぬフィールド故にその後食指が動かなかった。
とは言え、いつまでも放っておくと、先の大法螺が意識の隅っこでどんよりと淀んだ重しとなって、日々気持ちの良いものではない。そんな訳で、TensorFlow Lite サンプルにある「mobileBERT-QA: 自然言語による質問応答」なら Elixirにポーティングできるかもっと、しぶしぶキーボードに向かったのであった。これは、その備忘録である![]()
1.BERTをザックリ理解する
BERTとは、セサミストリートのバート&アニーのあの BERTらしい![]()
いやホント、BERTの前にELMo(エルモ)と言うのがあり、そのノリでBERTとなったとの噂が囁かれています(参考文献 3)
 © 2022 Sesame Workshop
© 2022 Sesame Workshop
まあ、正しくは "Bidirectional Encoder Representations from Transformers"と言う 2018年に発表された学習方法/NLPモデルです。そしてこのモデルが凄かった。いつもアニーに振り回されているバートは有能そうには見えないのですが、こちらのBERTはこれ一つで下記に挙げた各種NLPタスクをそつなくこなしてしまう優等生です。それも学習済みのBERTに、それぞれのタスクに特化した出力レイヤーを加え、チョコチョコッとファインチューニングするだけで良い感じのモデルが得られるらしいのです(下図)。エコロジカルですね![]() 。かつては、一つのタスクを学習させるだけでも大量の教示データを用意する必要があり、リッチな組織(人・物・金)でしか開発できなかったNLPが、ちょっと頑張ればあなたも私もできるかもと言う状況になりました。まさに、NLP界隈では天地がひっくり返る出来事だったようです。
。かつては、一つのタスクを学習させるだけでも大量の教示データを用意する必要があり、リッチな組織(人・物・金)でしか開発できなかったNLPが、ちょっと頑張ればあなたも私もできるかもと言う状況になりました。まさに、NLP界隈では天地がひっくり返る出来事だったようです。
…以上、聞きかじりです![]()
【各種NLPタスクの例】
Sentence Pair Classification Tases:
MNLI 多分類タスク:前提文と仮説文が含意/矛盾/中立のいずれかを分類
QQP 二値分類タスク:2つの疑問文が意味的に同一かを分類
QNLI 二値分類タスク:文と質問のペアが渡され、文に答えが含まれるかどうかを分類
MRPC 二値分類タスク:ニュースに含まれる2文が意味的に同じかを分類
RTE 分類タスク:文書が含意しているか否かを分類
Single Sentence Classification Tasks:
SST-2 二値分類タスク:映画レビューのポジ/ネガの感情分析
CoLA 多分類タスク:文が文法的に正しいか否かを分類
STS-B 多分類タスク:2文の類似度を1~5で分類
Question Answering Tasks:
SQuAD 質疑応答タスク: 質問文とその答えを含む文章から答えがどこにあるかを予測
Single Sentence Tagging Tasks:
CoNLL-2003 NER 固有表現抽出タスク: 組織名、人名、場所名、日付、金額などをテキストから抽出
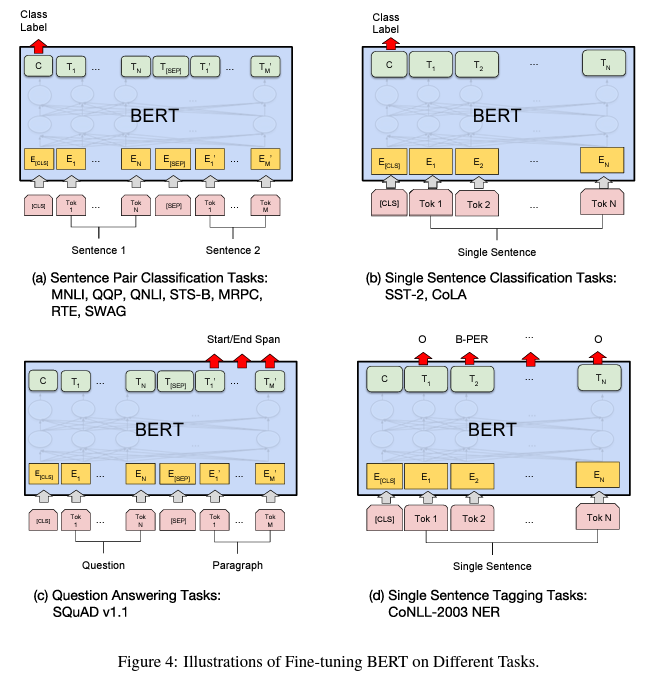
参考文献 1)より抜粋
さて、mobileBERT-QAを動かすために必要な情報を集めましょう。
mobileBERT-QAのモデルは上で触れた Question Answering Tasks(以下QA-Task)を実行するモデルです。基本のmobileBERTの出力段に QA-Task用のレイヤを付け加え、SQuADデータセット等で学習したものです。QA-Taskとは、上で見たように「質問」と「コンテキスト」が与えられ、「質問」の答えを「コンテキスト」から探し出すタスクです。尚、BERT/mobileBERTモデルの構造や機知に富む学習方法については本稿では触れません。興味のある方は文末の参考文献等で調べてくださいね。(中でもAIciaさんの[3]が分かり易くてお勧め![]() )
)
mobileBERT-QAの入力部は下図のように3つのEmbeddingsブロックになっていて、そこに英文を数値(トークン)に変換した tensorを含む3つの tensor(int32[1][384])を入力します[*1]。入力する英文は、質問文(以下 Q文)とその答えを探すコンテキスト(以下 T文)の2つです。3つの tensorはそれぞれ次の要領で作成します。
-
Token Embeddingsへの入力
語彙辞書[*2]を用いて Q文、T文中の単語をトークン(数値)に置き換え、トークン列(Q'文、T'文)を作る。そして、先頭から特殊トークン[CLS]、Q'文、特殊トークン[SEP]、T'文、特殊トーク[SEP]の順に連結したtensorを作成し入力とする。 -
Segment Embeddingsへの入力
Token Embeddingsの入力と同じ長さで、先頭から一つ目の特殊トークン[SEP]までは数値'0'が、それ以降で最後の特殊トークン[SEP]までは数値'1'が埋まった tensorを作成し入力とする。Q'文、T'文の範囲を表わすマーカーです。 -
Position Embeddingsへの入力
Token Embeddingsの入力と同じ長さで、数値'1'が埋まった tensorを作成し入力とする。Posision Embeddingsは学習時に使用するブロックです。
[*1]扱える文の長さを除き BERTと基本的に同じ入力形式です。
[*2]SQuAD:The Stanford Question Answering Datasetで学習したモデルなので SQuAD v1.1の辞書を使用します。
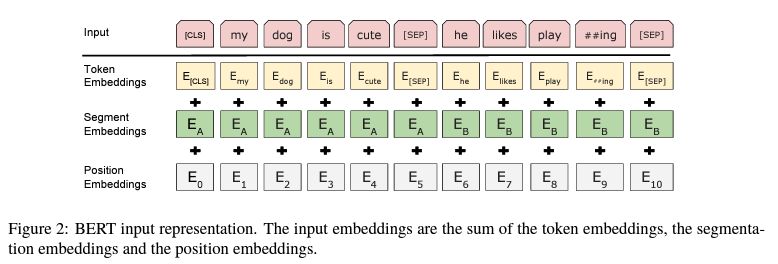
参考文献 1)より抜粋
Token/Segment/Position Embeddingsに、上の手順で作成した3つの tensorを入力すると、入力と同じ長さの2つの tensor(Start-span,End-span)が出力されます。これらの tensorには、元の入力文の同じインデックスにあるトークンが、質問文に対する答えの句の開始点である確率(Start-span)、終了点である確率(End-span)がそれぞれ格納されています(下図)。
つまり、Start-spanで確率が高いトークンからEnd-spanで確率が高いトークンまでの間の句を取り出せば、それが質問文(Q文)の答えとなると言う仕掛けとなっています。

2.mobileBERT-QAアプリの実装
では、Elixirで mobileBERT-QAアプリをプログラムしましょう。
本家Tensorflow liteの例を参考に拙作OnnxInterpで実装したコードを見ていきます[*3]
[*3]TflInterpで実装/動作確認したモノを OnnxInterpに転用しています。
プログラムの心臓部 -- QA-Taskの推論 -- は、次の3つのモジュールから出来ています。
- MBertQA.Tokenizer -- 入力文の個々の単語を tokenに翻訳する処理
- MBertQA.Feature ---- 入力文を Token/Segment/Position Embeddingsへの入力 tensorに翻訳する処理
- MBertQA ------------- DNNモデル推論を行い、その結果の tensorを英文に逆翻訳する処理
§1. MBertQA.Tokenizer
英文をスペース区切りで単語に分割し、個々の単語を辞書に基づいて tokenに翻訳する処理を担当します。
辞書は、下記の様に一行に一単語が書かれたテキスト・ファイルです(注:行番号は入っていません)。0始まりの行番号がその単語の token値となります。総数30522の単語が登録されています。
0: [PAD]
:
3080: older
3081: via
3082: heavy
3083: 1st
3084: makes
3085: ##able
3086: attention
3087: anyone
3088: africa
3089: ##ri
3090: stated
:
30521: ##~
単語には、"[PAD]","[SEP]"の様に角カッコ付きの特殊ワード、"##able","##ri"のように先頭に"##"が付いたサブワード、"older","via"の様な一般ワードの3種類があります。特殊ワードは、mobileBERT/BERTがシステム用として予約している tokenなので、入力文に現れることはありません。
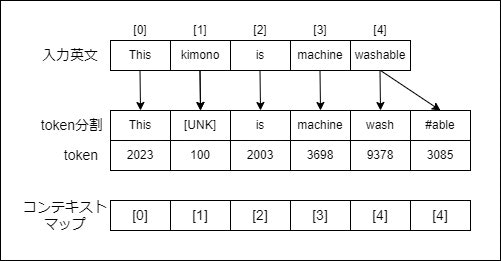
一般ワード/サブワードについては、単語"washable"を tokenに翻訳する例を見ながらその意味を捉えましょう。
STEP_1:
辞書に登録されている一般ワードの中で、"washable"の先頭文字から最も長く一致するワードを見つけ、そのワードの tokenを翻訳結果とします。"washable"の最初の3文字"was"で辞書を引くと下記の一般ワードが見つかります。"washable"の先頭文字から最も長く一致するワードは"wash"ですね。そのtoken 9378を翻訳結果とします。もしも入力単語"washable"自身が辞書の中で見つかった場合は、翻訳はここで終わります。また、入力単語のどの先頭部分文字列も辞書で見つからなかった場合は、未知語[UNK]と翻訳しここで終わります。
2001 was
2347 wasn
2899 washington
5949 waste
8871 washed
9378 wash
12699 washing
13842 wasted
18313 wasting
19411 wasp
23146 wasps
28269 wastewaterSTEP_2:
入力単語"washable"から先の最長一致文字列"wash"を取り除いた文字列"able"について翻訳を続けます。STEP_1と同様に"able"の先頭部分文字列を考え、今度はサブワードの中で最長一致するワードを探します。"able"の最初の3文字"abl"で辞書を引くと下記のサブワードが見つかります。最も長く一致するワードは"##able"ですね。そのtoken 3085を翻訳結果とします。以降 STEP_2を、入力単語の全ての部分文字列を翻訳し切るか、または未知語に遭遇するまで続けます。そして最終的な翻訳結果は、STEP_1/STEP_2で翻訳したtokenの列とします。"washable"の場合は、全ての部分文字列が翻訳でき、翻訳結果は[9378,3085]となります。
3085 ##able
8231 ##ably
サブワードの翻訳があるために、なかなか面倒ですね![]() 。サブワードが導入された動機は、モデルの限られた入力サイズ、さらに限られた辞書のサイズに対し、入力文の単語が未知語 [UNK] (ノイズに相当)に翻訳される機会を小さく抑えるための様です。
。サブワードが導入された動機は、モデルの限られた入力サイズ、さらに限られた辞書のサイズに対し、入力文の単語が未知語 [UNK] (ノイズに相当)に翻訳される機会を小さく抑えるための様です。
これらの手順を Elixirを用いて下記の様に実装しました。
コードから意味を読み取り難い部分について補足説明します。
辞書は、一般ワード(@dic1)とサブワード(@dic2)の2つに分割し、それぞれを ETSで保持することにしました。翻訳関数は再帰ループで実装しているので、そのネストしたループの中から簡単に辞書を参照できるように、ETSは named_tableとして扱います。また、サブワードは先頭の"##"を取り除いて辞書@dic2に登録しています。(load_dic/1)
関数 tokenize/2が外部に対するインターフェイスです。引数に渡された入力文(英文)をスペース区切りで単語に分割(text2words/1)したのちに、個々の単語を tokenに翻訳(words2tokens/1)し、token列を作成します。token列は Elixirのリストで表しています。
wordpiece1/2と wordpiece2/3が、上記STEP_1, STEP_2の実装です。引数には翻訳対象の単語と、その先頭から切り出す文字列の長さを渡します。再帰ループでこの文字列長を変えながら、単語の先頭から最長一致するワードを探しています。
あとはコードを読めば分かるかな![]()
※注意: 部分文字列の切り出しは String.slice/3を使用していますが、Elixirの文字列は imutableなので切り出す度に新たな文字列を生成しているかも![]()
※独言: こう言う仕事は Elixirではなく、C++,Rust,Zigなどに任せるのが適切と思う。それが壁の向こうに留まるなら、mutableな処理があっても構わないので![]()
defmodule MBertQA.Tokenizer do
@moduledoc """
Mini Tokenizer for Tensorflow lite's mobileBert example.
"""
@dic1 :word2token1
@dic2 :word2token2
@dic3 :token2word
@doc """
Load a vocabulary dictionary.
"""
def load_dic(fname) do
Enum.each([@dic1, @dic2, @dic3], fn name ->
if :ets.whereis(name) != :undefined, do: :ets.delete(name)
:ets.new(name, [:named_table])
end)
File.stream!(fname)
|> Stream.map(&String.trim_trailing/1)
|> Stream.with_index()
|> Enum.each(fn {word, index} ->
# init dic for encoding.
case word do
<<"##", trailing::binary>> -> :ets.insert(@dic2, {trailing, index})
_ -> :ets.insert(@dic1, {word, index})
end
# init dic for decoding.
:ets.insert(@dic3, {index, word})
end)
end
@doc """
Tokenize text.
"""
def tokenize(text, tolower \\ true) do
if tolower do
String.downcase(text)
else
text
end
|> text2words()
|> words2tokens()
end
defp text2words(text) do
text
# cleansing
|> String.replace(~r/([[:cntrl:]]|\xff\xfd)/, "")
# separate panc with whitespace
|> String.replace(~r/([[:punct:]])/, " \\1 ")
# split with whitespace
|> String.split()
end
defp words2tokens(words) do
Enum.reduce(words, [], fn word, tokens ->
case wordpiece1(word, len = String.length(word)) do
{^len, token} ->
[token | tokens]
{0, token} ->
[token | tokens]
{n, token} ->
len = len - n
wordpiece2(String.slice(word, n, len), len, [token | tokens])
end
end)
|> Enum.reverse()
end
defp wordpiece1(_, 0), do: {0, token("[UNK]")}
defp wordpiece1(word, n) do
case lookup_1(String.slice(word, 0, n)) do
{_piece, token} ->
{n, token}
nil ->
wordpiece1(word, n - 1)
end
end
defp wordpiece2(_, 0, tokens), do: [token("[UNK]") | tokens]
defp wordpiece2(word, n, tokens) do
case lookup_2(String.slice(word, 0, n)) do
{_piece, token} ->
len = String.length(word) - n
if len == 0 do
[token | tokens]
else
wordpiece2(String.slice(word, n, len), len, [token | tokens])
end
nil ->
wordpiece2(word, n - 1, tokens)
end
end
defp lookup_1(x), do: lookup(@dic1, x)
defp lookup_2(x), do: lookup(@dic2, x)
defp lookup(dic, x), do: List.first(:ets.lookup(dic, x))
@doc """
Get token of `word`.
"""
def token(word) do
try do
:ets.lookup_element(@dic1, word, 2)
rescue
ArgumentError -> nil
end
end
@doc """
[debug utiltiy]
Decode the token list `tokens`.
"""
def decode(tokens) do
Enum.map(tokens, fn x -> :ets.lookup_element(@dic3, x, 2) end)
end
end
§2. MBertQA.Feature
与えられた英文を Token/Segment/Position Embeddingsへの入力tensorに翻訳する処理を担当します。併せて、mobileBERT-QAの推論結果を元の英文に逆翻訳するためのコンテキスト・マップを作成します。
1章の図示の通り Token/Segment/Position Embeddingsへの入力は3本の tensorですが、実装コードの見通しを良くするために、入力文は一旦「3つの属性+1」の要素を持つ一本の tensorに翻訳することにしました。「質問文」、「コンテキスト」、特殊ワードのそれぞれを個別に tensorフラグメント(token/segment/position/context_map)に翻訳し、それらのtensorフラグメントをガチャンと連結して一本の tensorを作成しています。そして、Embeddingsに渡す際に3本の tensorに分割します(MBertQAモジュール)。
翻訳tensor[4][入力文字列長+3]:
[0] - Token Embedding用/入力文をtoken列に翻訳したもの
[1] - Position Embedding用/全ての値が1
[0] - Segment Embedding用/質問文の区間は値0、コンテキストの区間は値1
[0] - コンテキスト・マップ用/tokenの元となった単語のコンテキスト文上の位置
コンテキスト・マップは、次のセクションで説明する MBertQAが推論結果を英文に逆翻訳する際に必要とするマップです。下図のように、MBertQA.Tokenizerが一つの単語を複数のtokenに翻訳することがあるのですが、その場合単語とtokenは一対多の関係になってしまいます[*4]。もしも、全ての単語とtokenが一対一の関係にあるならば、tokenのインデックスを手掛かりに元の単語を取り出すことが出来ますが、一対多の関係ではそういう簡単な方法は使えません。そこで、各tokenの翻訳元の単語のインデックス -- コンテキスト文上の単語の位置 -- を別途コンテキスト・マップとして記録しておき、tokenから単語への逆翻訳の際に利用しようという訳です。尚、質問文、特殊ワードのインデックスは値(-1)としてコンテキスト・マップに記憶されています。
[*4]サブワードの導入による副作用ですね。
Elixirでの実装は下記の通りです。
ここでも、コードから意味を読み取り難い部分を補足しましょう。
convert/2が外部に対するインターフェイスです。引数に渡された質問文queryとコンテキスト文contextを順に tensorフラグメントに変換し、特殊ワードと合わせてガッチャンと連結して一本のtensorを作成しています。モデルへの入力tensor&コンテキスト・マップです。また、mobileBERTの入力tensorの長さは@max_seq(384)以内に制限されているため、tensorフラグメントを作成する下請け関数 convert_query/2, convert_context/2に空き残数roomを渡し、tensorフラグメントの長さが制限を超えないように制限しています。
convert_context(text, room)は入力文の翻訳とコンテキスト・マップの作成を同時に行うために少々複雑に見えるかも知れませんね。入力文をスペース区切りで単語に分割し(context_list)、それぞれの単語にコンテキスト・マップに記憶するインデックスをくっ付けて(Stream.with_index)、下請け関数convert_text/4で単語の tensorフラグメントを繰り返し作成しています(Enum.reduce_while)。最後に、単語の tensorフラグメント・リストを一本の tensorに連結して呼び出し元に返します。
あとはコードを読めば分かるかな![]()
defmodule MBertQA.Feature do
@moduledoc """
Feature converter for Tensorflow lite's mobileBert example.
Feature tensor[4][] is consisted of
[0] list of tokens converted from query and contex text in the dictionary.
[1] list of token masks. all are 1 in valid token.
[2] segment type indicator. 0 for query, 1 for context.
[3] index of the token's position in the context list. see bellow.
Context list is a list of words separated by whitespace from the context .
"""
alias MBertQA.Tokenizer
@max_seq 384
@max_query 64
defdelegate load_dic(fname), to: Tokenizer, as: :load_dic
@doc """
"""
def convert(query, context) do
{t_query, room} = convert_query(query)
{t_context, room, context_list} = convert_context(context, room)
{
Nx.concatenate([cls(), t_query, sep(0), t_context, sep(1), padding(room)], axis: 1),
context_list
}
end
defp convert_query(text, room \\ @max_seq - 3) do
t_query = convert_text(text, @max_query, 0)
{
t_query,
room - Nx.axis_size(t_query, 1)
}
end
defp convert_context(text, room) do
context_list = String.split(text)
{t_context, room} =
context_list
|> Stream.with_index()
|> Enum.reduce_while({[], room}, fn
{_, _}, {_, 0} = res ->
{:halt, res}
{word, index}, {t_context, max_len} ->
t_word = convert_text(word, max_len, 1, index)
{:cont, {[t_word | t_context], max_len - Nx.axis_size(t_word, 1)}}
end)
{
Enum.reverse(t_context) |> Nx.concatenate(axis: 1),
room,
context_list
}
end
defp convert_text(text, max_len, segment, index \\ -1) do
tokens =
text
|> Tokenizer.tokenize()
|> Enum.take(max_len)
|> Nx.tensor()
len = Nx.axis_size(tokens, 0)
Nx.stack([
tokens, # Token Embeddings
Nx.broadcast(1, {len}), # Position Embeddings (mask)
Nx.broadcast(segment, {len}), # Segment Embeddings
Nx.broadcast(index, {len}) # context map
])
|> Nx.as_type({:s, 32})
end
defp cls() do
Nx.tensor([[Tokenizer.token("[CLS]")], [1], [0], [-1]], type: {:s, 32})
end
defp sep(segment) do
Nx.tensor([[Tokenizer.token("[SEP]")], [1], [segment], [-1]], type: {:s, 32})
end
defp padding(n) do
Nx.tensor([0, 0, 0, -1], type: {:s, 32})
|> Nx.broadcast({4, n}, axes: [0])
end
end
§3. MBertQA
DNNモデルで推論を行い、その結果の tensorを英文に逆翻訳する処理を担当します。mobileBERT-QA推論のメイン・モジュールに当たります。
入力文をToken/Segment/Position Embeddingsの入力tensorに翻訳する処理(前処理)は、ここまでのセクションで見てきた通りです。
モデルの出力は1章で見た通り2つの tensorです(コードでは beg_logits/end_logitsとしています)。これをいくつか条件で篩に掛け、コンテキスト上で質問文の答えとなる句の開始点/終了点を求めています。
Elixirでの実装は下記の通りです。
例によって、コードから意味を読み取り難い部分のみ補足します。
beg_index, end_indexは、それぞれ beg_logits, end_logitsの要素のうち確率が高いものをpredict_num個取り出したリストです。つまり、答えの句の開始点/終了点の候補ですね。
次の for関数は、beg_indexとend_indexから[開始点,終了点]ペアの組み合わせを作っています。この時同時に、「開始点が終了点よりも右にあること」、「句の長さが @max_ans未満であること」をチェックしています。また、[開始点,終了点]ペアの評価値をそれぞれの確率の積として計算しています(Nx.to_number(Nx.add(beg_logits[b], end_logits[e])))。
最終的な推論結果は、[開始点,終了点]ペアの評価値が高いものからpredict_num個を英文に逆翻訳し、その英文と評価値のペアをタプルにしたもののリストです。
あとはコードを読めば分かるかな![]()
defmodule MBertQA do
@moduledoc """
Documentation for `MBertQA`.
"""
alias OnnxInterp, as: NNInterp
use NNInterp, model: "./model/mobilebert_squad.onnx"
alias MBertQA.Feature
@max_ans 32
@predict_num 5
def setup() do
Feature.load_dic("./model/vocab.txt")
end
def apply(query, context, predict_num \\ @predict_num) do
# pre-processing
{feature, context_list} = Feature.convert(query, context)
# prediction
mod =
__MODULE__
|> NNInterp.set_input_tensor(0, Nx.to_binary(feature[0])) # Token embeddings
|> NNInterp.set_input_tensor(1, Nx.to_binary(feature[1])) # Position embeddings
|> NNInterp.set_input_tensor(2, Nx.to_binary(feature[2])) # Segment embeddings
|> NNInterp.invoke()
[end_logits, beg_logits] =
Enum.map(0..1, fn x ->
NNInterp.get_output_tensor(mod, x)
|> Nx.from_binary({:f, 32})
end)
# post-processing
[beg_index, end_index] =
Enum.map([beg_logits, end_logits], fn t ->
Nx.argsort(t, direction: :desc)
|> Nx.slice_along_axis(0, predict_num)
|> Nx.to_flat_list()
|> Enum.filter(&(Nx.to_number(feature[3][&1]) >= 0))
end)
for b <- beg_index, e <- end_index, b <= e, e - b + 1 < @max_ans do
{b, e, Nx.to_number(Nx.add(beg_logits[b], end_logits[e]))}
end
|> Enum.sort(&(elem(&1, 2) >= elem(&2, 2)))
|> Enum.take(predict_num)
# make answer text with score
|> Enum.map(fn {b, e, score} ->
b = Nx.to_number(feature[3][b]) # context map
e = Nx.to_number(feature[3][e]) # context map
{
Enum.slice(context_list, b..e) |> Enum.join(" "),
score
}
end)
end
end
3.mobileBERT-QAに質問してみる - "GoogleのCEOって誰?"
さぁて、一通り準備が整ったので Livebookで動かしてみましょう。
"setup"セルは次の通りです。コンピュータビジョン系でなれば、依存するモジュールはたったコレだけなんですね。ちょっぴり、びっくりです![]()
省略しますが、"setup"セルの後にはここまでみて来た MBertQA.Tokenizer, MBertQA.Feature, MBertQAのコード・セルが続きます。
File.cd!(__DIR__)
# for windows JP
System.shell("chcp 65001")
Mix.install([
{:onnx_interp, "~> 0.1.9"},
{:nx, "~> 0.4.0"},
])
MBertQAの実体は GenServerなので、一度だけ起動します。
#OnnxInterp.stop(MBertQA)
MBertQA.start_link([])
mobileBERTの辞書を準備します。
unless File.exists?("./model/vocab.txt"),
do: OnnxInterp.URL.download("https://github.com/shoz-f/onnx_interp/blob/b940dafdcfa027e22570e13b3f66eb700df3e9a3/demo_mbert_qa/model/vocab.txt", "./model", "vocab.txt")
MBertQA.setup()
ここからが本番です。
質問とコンテキストを MBert.apply/2に渡すとちゃんと答えてくれるかな?
コンテキストは、本家 Tensorflow liteの例題から借りて来た下記の英文です。
ちょっとドキドキしますね![]()
context = """
Google LLC is an American multinational technology company that specializes in
Internet-related services and products, which include online advertising
technologies, search engine, cloud computing, software, and hardware. It is
considered one of the Big Four technology companies, alongside Amazon, Apple,
and Facebook.
Google was founded in September 1998 by Larry Page and Sergey Brin while they
were Ph.D. students at Stanford University in California. Together they own
about 14 percent of its shares and control 56 percent of the stockholder voting
power through supervoting stock. They incorporated Google as a California
privately held company on September 4, 1998, in California. Google was then
reincorporated in Delaware on October 22, 2002. An initial public offering (IPO)
took place on August 19, 2004, and Google moved to its headquarters in Mountain
View, California, nicknamed the Googleplex. In August 2015, Google announced
plans to reorganize its various interests as a conglomerate called Alphabet Inc.
Google is Alphabet's leading subsidiary and will continue to be the umbrella
company for Alphabet's Internet interests. Sundar Pichai was appointed CEO of
Google, replacing Larry Page who became the CEO of Alphabet.
"""
Q: "GoogleのCEOは誰ですか?"
"What is CEO of Google?"
|> MBertQA.apply(context, 3)
|> Enum.each(fn {ans, score} ->
IO.puts("\n>ANS: \"#{ans}\", score:#{score}")
end)
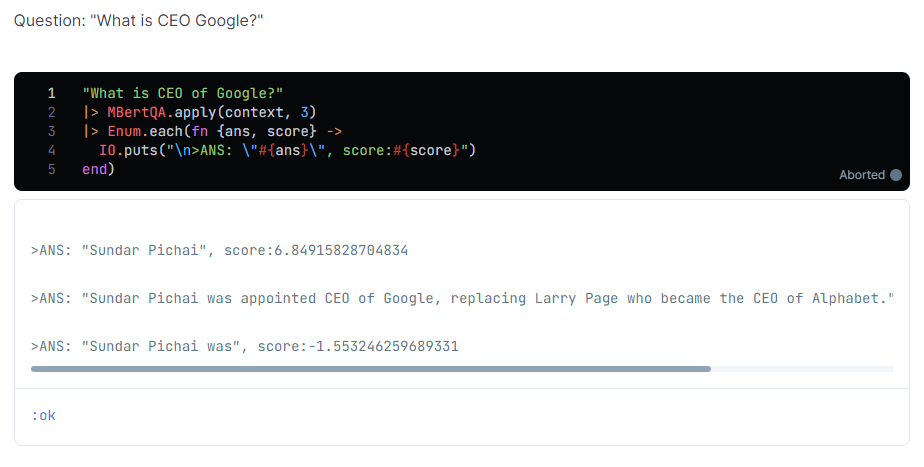
Larry Page氏ではなく、正しくSundar Pichai氏と答えてくれました。素晴らしい![]()
4.Epilogue
お疲れ様でした。
TensorFlow Lite サンプルアプリの「mobileBERT-QA: 自然言語による質問応答」を拙作OnnxInterpを用いて Elixirで動かしてみました。
mobileBERT-QAは、その仕組みを見るに、果たして英文を理解しているのだろうかとの疑問が湧きます(根拠なし)。しかし、入力された質問に対し概ね的確な回答をするので、英文を理解していなとも言い切れないようです。そして、ここ数週間世間を騒がしているとんでもない chatGPTなんかも現れてきました。いったい文を理解するとはどういうことなんでしょうね? この冬は炬燵で丸まりながら哲学的な問いに妄想を巡らしているかも知れませんね。
ん! ひょっとすると近い将来にC3POが誕生して、答えを教えてくれるかも![]()
それではまた。
参考文献
-
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova -
MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices
Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, Denny Zhou -
【深層学習】BERT - 実務家必修。実務で超応用されまくっている自然言語処理モデル【ディープラーニングの世界vol.32】
AIcia Solid Project -
Question Answering with a Fine-Tuned BERT
Chris McCormick
Appendix: mobileBERT-QA ONNXモデルの作り方
本稿で使用した mobilebert_squad.onnxモデルは、Google researchが公開している Tensorflow savedmodel (float32) を onnxにコンバートしたものです。コンバートは下記の様に pythonの tf2onnxモジュールで行います。
pip install -U tf2onnx
python -m tf2onnx.convert --saved-model mobilebert_squad_savedmodels/float --output mobilebert_squad.onnx
□