前置き:この記事で扱う生成AI
2023年の11月28日に、Titan Image Generatorが使えるようになりました。
StableDifusionやDALL-Eと同じ画像生成AIです。
同じ時期に、Titan Multimodal Embeddingsも使えるようになりました。
画像とテキストをベクトル表現(埋め込みベクトル)に変換できる生成AIです。
※データがどのくらい似ているのかを比べることができるのがベクトル表現です。
この記事では、この2つのモデルを扱います。
この記事で調べること
人間に理解できない画像を生成させて、生成AI自身に「これは何を描いたの?」と聞いたら、描かれたものを認識することができるのでしょうか?
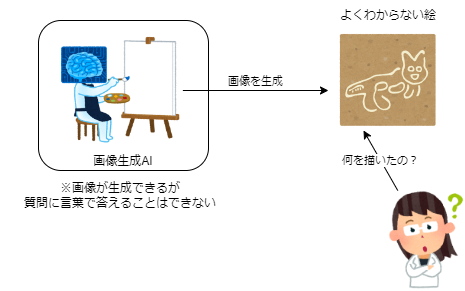
画像生成AI自身は言葉を返せないので、画像を生成するAIと、画像について質問をするAIは別のものにする必要があります。たとえば絵を描くAIにはStable Diffusionがあります。絵を識別する能力が高いAIには、Claude3やGPT4Vがあります。
ただ、これらは全く違う会社が全く違う時期に出したAIですから、人間で言えば別人です。
「これは何の絵だと思う?」と別人に聞いても、人間と同じ回答しか返ってこないはずです。
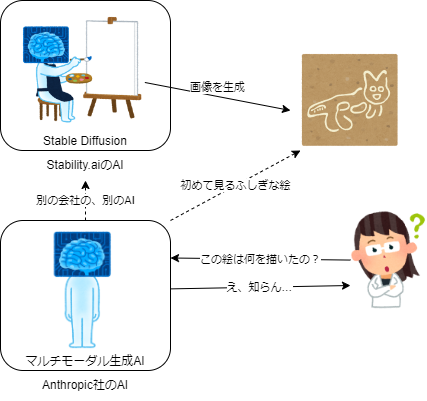
一方で、Titanの埋め込みと画像生成は、同じ会社が同じ時期に同じシリーズとして発表しています。ほぼ同一人物、そうでなくても近いデータで学習していて、かなり似たAIのはずです。
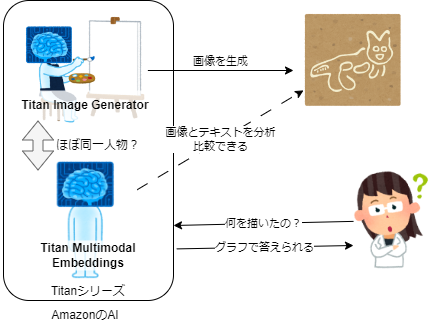
もしかすれば人間に区別のつかないものでも、描いた本人なら区別がつくかもしれません。
この記事では、それを検証します。
検証の環境
Amazon Titanを使います。リージョンはバージニアです。
- Amazon Titan Multimodal Embeddings G1(boto3から実行)
- Amazon Titan Image Generator(コンソールから実行)
- Python 3.10
検証に使ったソース
ソースコードはこちらのレポジトリに置いています
READMEの手順に沿って再実施することができます
2024/03/30 追記:ソースを整形しました
検証手順の概要
手順:検証は以下の手順で実施します
- 犬、猫の品種名を15件ずつ用意して、それぞれテキストからベクトル表現に変換します
- ベクトル表現(1024次元)から、犬と猫の分類にかかわりの薄い次元を除去します
- 除去して145次元になったベクトル表現を、PCAで2次元まで次元削減します
- 2次元になったベクトル表現をグラフ化します(赤が犬、青が猫です)

- グラフの中に、AI生成画像のベクトル表現(オレンジ色の点)をプロットします

観点:確認する観点は以下の2点です
- AI生成画像は、元プロンプトと比べて、どの程度ベクトル表現が変化するのか
- 元プロンプトに犬猫を含んでいて、生成画像から犬猫の区別がつかないとき、犬猫の分類は正しくできるか
結果と結論:結論
- AI生成画像と元プロンプトは、ベクトル表現の位置が異なる
- 元プロンプトに犬猫の表現があったとしても、生成画像が曖昧なら判定できない
以下、実際の検証です。
埋め込みベクトルを可視化する
比較をするために、まずは埋め込みベクトル(1024次元)を可視化する必要があります。
犬15種類、猫15種類の品種名を用意しました。
用意したデータ
Pomeranian
Schnauzer
Siberian Husky
Yorkshire Terrier
Shih Tzu
Poodle
Golden Retriever
Labrador Retriever
Maltese
Pekingese
Chihuahua
Dachshund
Dolmatian
Welsh Corgi
Bulldog
Abyssinian
Siberian
Siamese
Scottish Fold
Norwegian Forest Cat
Himalayan
Bengal
Munchkin
Maine Coon
Ragdoll
Russian Blue
Persian
Japanese Bobtail
Selkirk Rex
American Shorthair
犬と猫の品種名30件と、「Dog」、「Cat」の単語をベクトル化します。
def create_embeddings(input_text: str) -> Embeddings:
"""
テキストをベクトル化する
"""
model_id = "amazon.titan-embed-image-v1"
output_embedding_length = 1024
# Create request body.
# 画像の時は、inputTextの代わりにinputImageを指定して、base64形式のデータを入れます
body = json.dumps(
{
"inputText": input_text,
"embeddingConfig": {"outputEmbeddingLength": output_embedding_length},
}
)
bedrock = boto3.client(service_name="bedrock-runtime", region_name="us-east-1")
accept = "application/json"
content_type = "application/json"
response = bedrock.invoke_model(
body=body, modelId=model_id, accept=accept, contentType=content_type
)
response_body = json.loads(response.get("body").read())
return EmbeddingsText(
embedding=response_body.get("embedding"), input_text=input_text
)
ベクトル表現を可視化する
目に見える形で比較するために、まずベクトル表現を可視化する必要があります。
ベクトル表現は1024次元のベクトルですから、そのまま可視化するわけにはいきません。
まずはそのまま可視化する
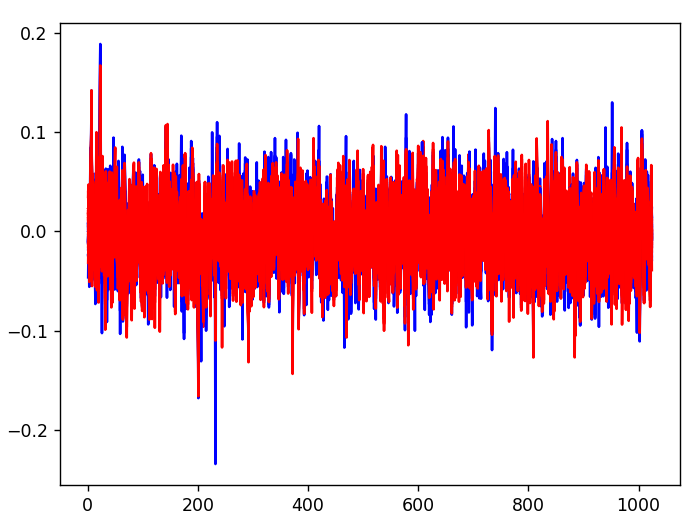
未加工の状態で、ベクトル表現を波形として表示してみます。
赤が犬、青が猫ですが、さすがに情報量が多すぎて読みようがありません。
PCA(主成分分析)で次元削減をします。
# 必要なライブラリをインポートする
from sklearn.decomposition import PCA
# PCAを取得する
pca = PCA(n_components=n_components)
# n_componentsの次元まで次元を減らして、結果を返す
result = pca.fit_transform(
[e.value.embedding for e in data_list.entity_list]
)
たとえばn_componentsを10にすると、1024次元あったベクトルを10次元まで減らしてくれます。
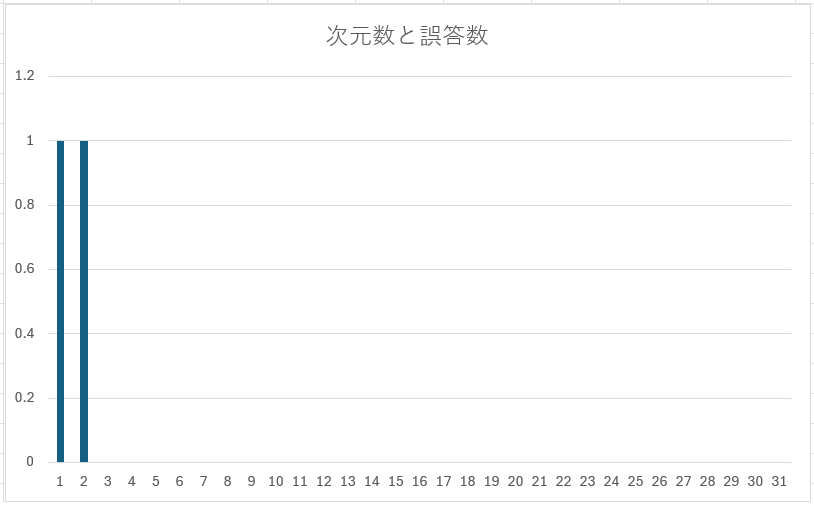
もちろん次元を減らしすぎると破綻します。コサイン類似度で犬の品種15件、猫の品種15件を答えさせた時に、30件中どれだけ誤答したかを調べて、破綻するしきい値を見つけます。
削減後の次元数を1~31で設定して、誤答数の変化を表にしました。
| 次元数 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| $\textsf{PCAの結果}$ | $\textsf{15}$ | 9 | 9 | 8 | 4 | 4 | 2 | 2 | 2 | 2 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
グラフにすると以下のようになります。
縦軸が誤答数、横軸が削減後の次元数です。
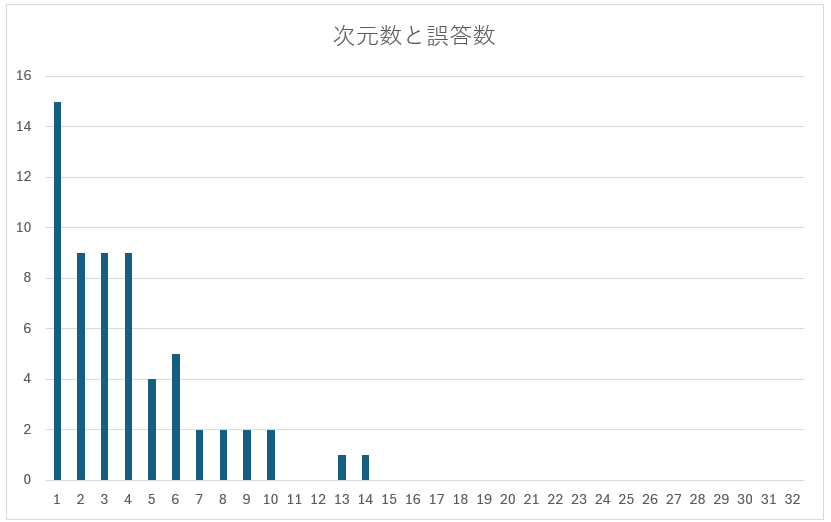
十分に次元が大きいと全て正答し、次元数を削るほど誤答が増えます。
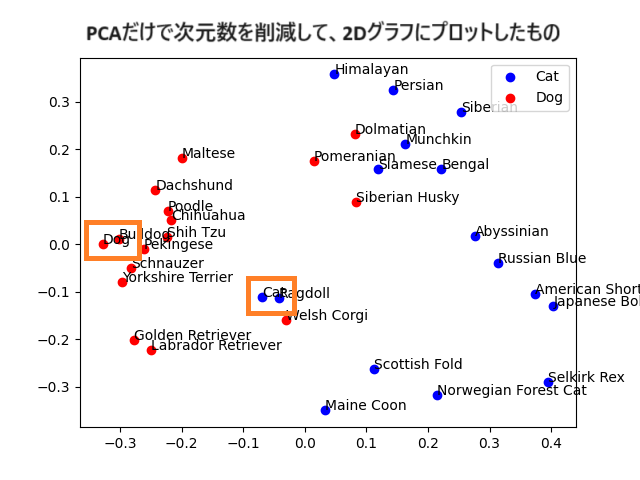
2次元では30%ほどが誤答です。現時点のものを2Dグラフで可視化すると以下のようになります。「Dog」と「Cat」の基準になるデータの距離は近く、猫の品種名を表す青の点と、犬の品種名を表す赤の点が入り混じっています。
16次元を可視化すると以下のように見えます。
前衛絵画みたいですね。
さすがにもう少し削らないとデータが読めません。
データをマスクする
犬と猫であまり差のない特徴があります。たとえば四本足で歩いているか、体毛があるかです。また、ペットショップでの値段だったりとか、飼いやすさだったりとか、生息地の分布だったりとか、そういった情報は、「ヨークシャーテリア」や「アビシニアン」のように品種としては持っていても、「犬」や「猫」の大きな区分にはない情報です。
そういった情報をベクトルから削り取ります。
いま、データはこのようになっています。横方向に1024次元の数値が並んでいます。
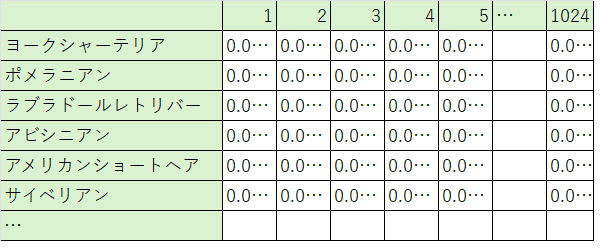
これを、縦方向に1次元目のデータだけを取って、縦にクラスタリングします。
下図の赤色の四角の枠の方向に配列を作って、DogとCatのどちらに近いのかを調べます。
その結果をグラフにしたものが以下のようになります。
縦軸は分類の誤答数、横軸は次元です。1024次元全てで誤答率を見ています。
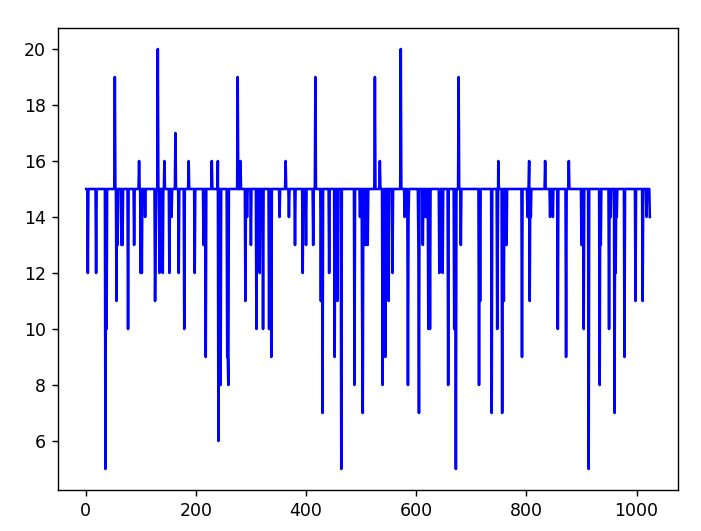
そうすると、グラフに明確な水平線が出ていることが分かります。
この水平線は、「全て犬、または全て猫で分類結果が返ってきた場所」です。
基準データ(DogとCatをベクトル化したもの)をグラフにすると、このようになります。
グラフの線が青に近ければ猫、グラフの線が赤に近ければ犬です。
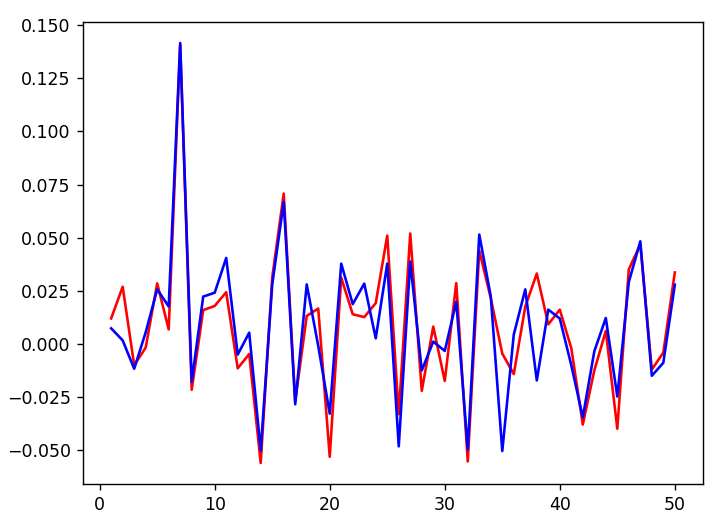
それぞれの品種名を調べて、青と赤のどちらに近いかを比べるのですが、全ての品種名の線が下図のオレンジ色のあたりを通る場所も少なくありません。犬や猫の分類には深く関わらない情報が入っている場所です。
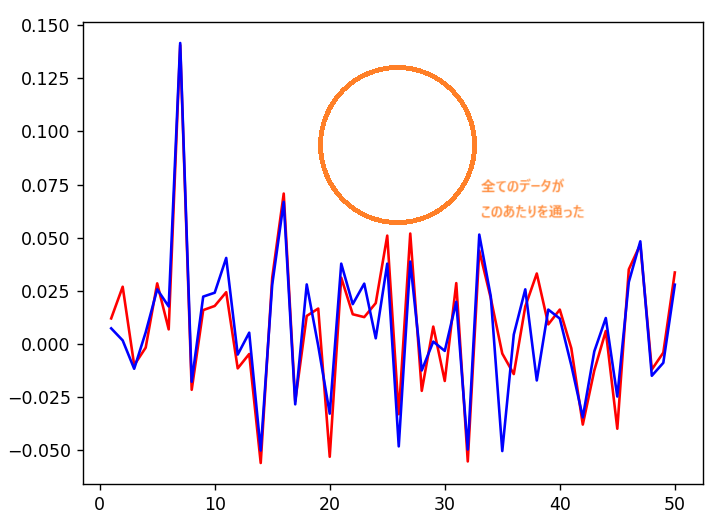
こういった情報を除外して、分類に影響のあるデータだけを残します。
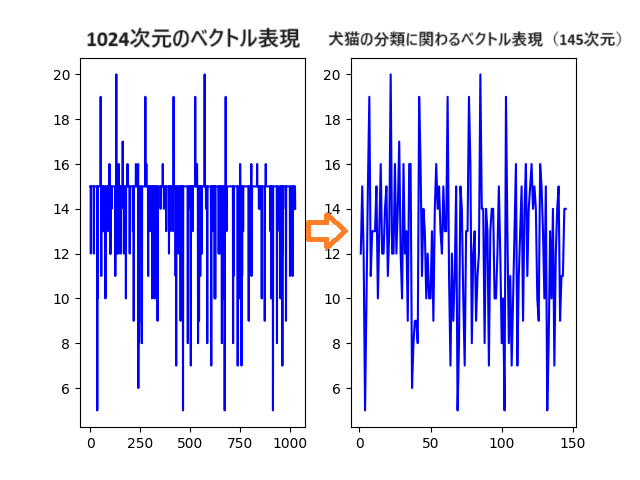
犬と猫の判別にかかわりのない情報を除外すると、145次元のベクトルになりました。
この状態で再度1~31次元までPCAで次元削減して、先ほどと同じ手順で、データが壊れない限界を調べます。
| 次元数 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| $\textsf{PCAの結果}$ | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
グラフにすると、以下のようになります。
3次元までクラスタリング結果を保ったまま削減できました。2次元でも誤答は1つですから、十分に可視化できそうです。
2次元の散布図に表示すると、下のようになりました。
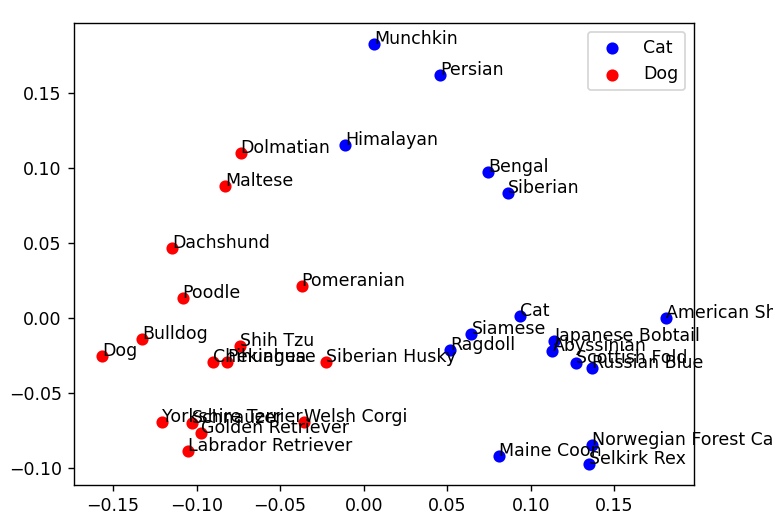
犬、猫のそれぞれのベクトル表現が可視化されて、はっきりとグラフ上で分かれていることが確認できます。
画像を分析する
では、インターネット上で拾った犬と猫の画像をベクトル化して、グラフ上のどこに点が表示されるのかを確認します。
画像のベクトル表現はオレンジ色で表示するように、matplotlibを設定しました。
| 対象画像 | グラフ |
|---|---|
 |
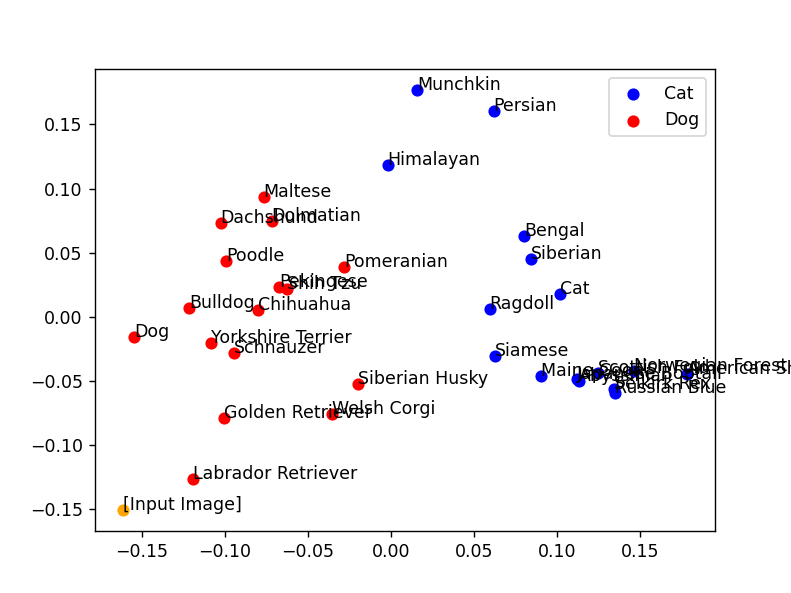 |
出典:パブリックドメインQ「雪とラブラドールレトリバー」
https://publicdomainq.net/labrador-retriever-dog-photo-0076496/
左下の端に出力されました。明らかに犬です。
最も近い点も「Labrador Retriver」になっています。品種も正答です。
| 対象画像 | グラフ |
|---|---|
 |
 |
出典:パブリックドメインQ「まどろむ猫」
https://publicdomainq.net/cat-sleeping-animal-photo-0078549/
右端に出力されました。明らかに猫です。
最も近い点は「American Shorthair」のようです。たしかにアメショに見えます。
| 対象画像 | グラフ |
|---|---|
 |
 |
出典:パブリックドメインQ「夜の古い街並みと猫耳の少女」
https://publicdomainq.net/girl-cat-ear-0071480/
おそらく「猫耳」のプロンプトで出力されたAI画像です。
やや犬と猫の境界に近い場所ですが、猫だと正しく分類されています。
最も近い点は「Siberian」のようです。サイベリアンの画像は以下の通りです。

出典:みんなの子猫ブリーダー「サイベリアンの人気毛色は?」
https://www.koneko-breeder.com/magazine/11604
拾った画像を検証して、正しく分類できること、画像のベクトル座標が正しくグラフ上で可視化できることが確認できました。
Titan画像生成AIの出力画像を分類する
ここからが本題です。
Titanを使って、コーギーの画像を作成しました。
プロンプト:Welsh Corgi
プロンプト強度:10
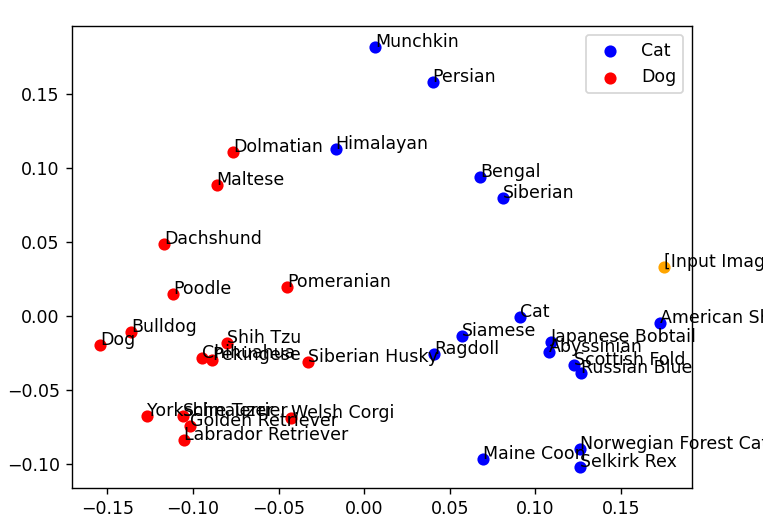
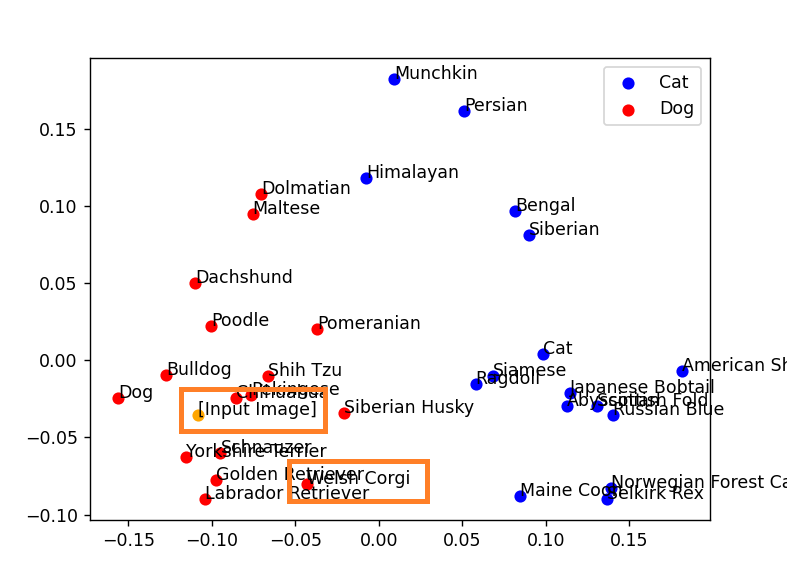
この画像をベクトル化して分析すると、以下のようになりました。
| 対象画像 | グラフ |
|---|---|
 |
 |
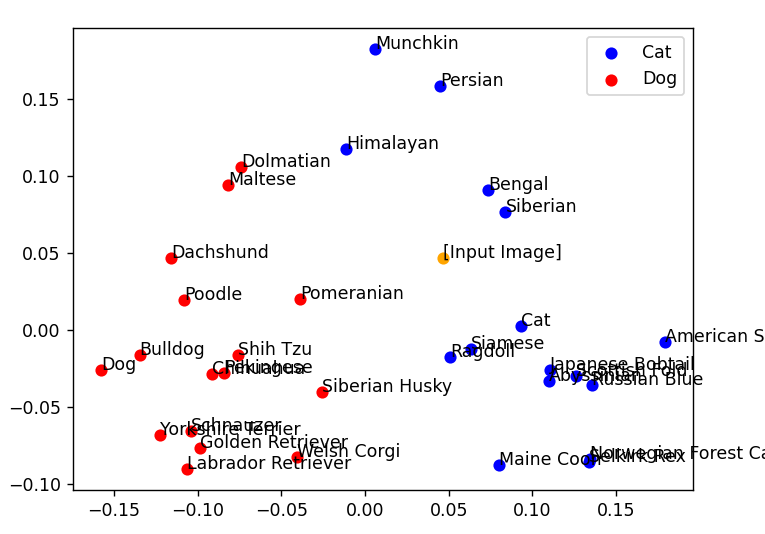
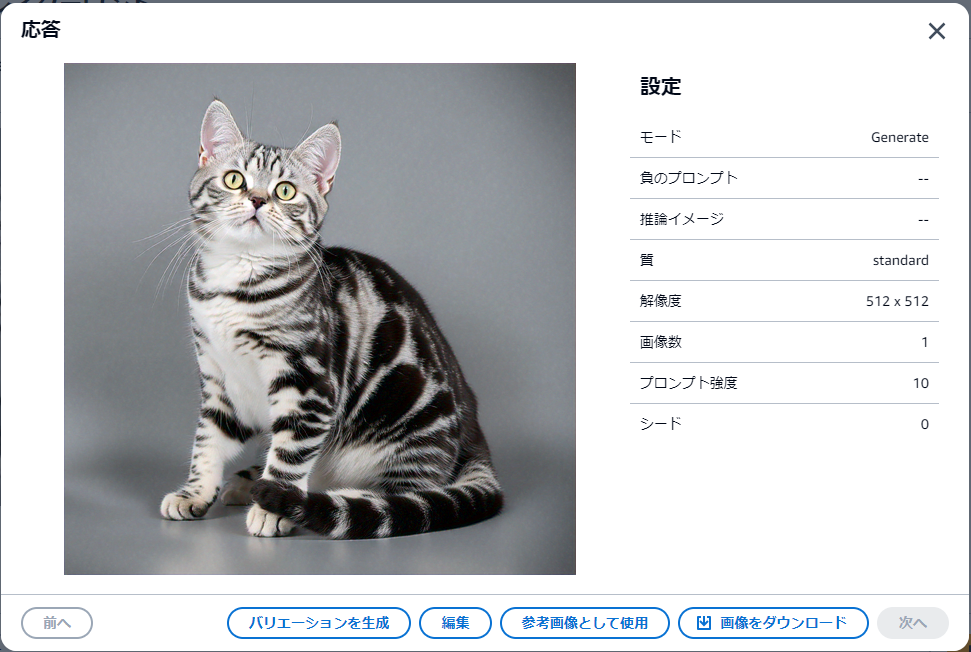
同様に、アメリカンショートヘアでもやってみます。
プロンプト:American Shorthair
プロンプト強度:10
| 対象画像 | グラフ |
|---|---|
 |
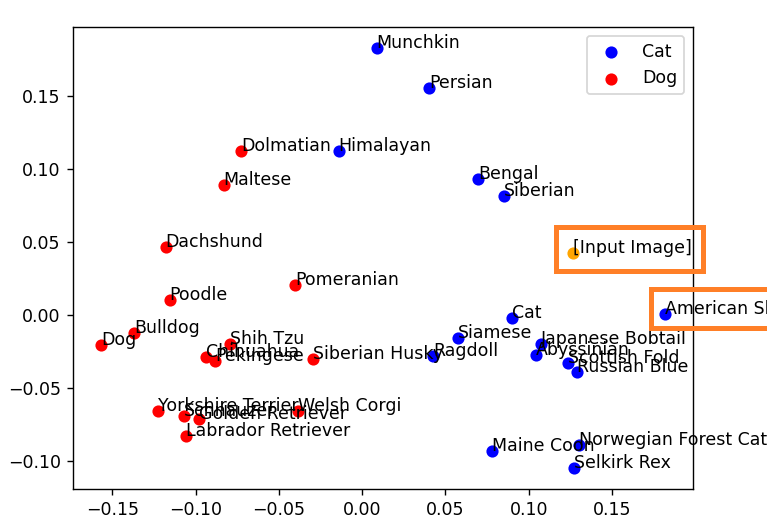 |
犬と猫の分類は正しく動いています。
ですが、テキストと生成後の画像で、ベクトルの座標が少しずれていることが分かります。
コーギーはどちらかと言えばブルドッグに近い場所に、アメリカンショートヘアもサイベリアンに近い場所にいます。
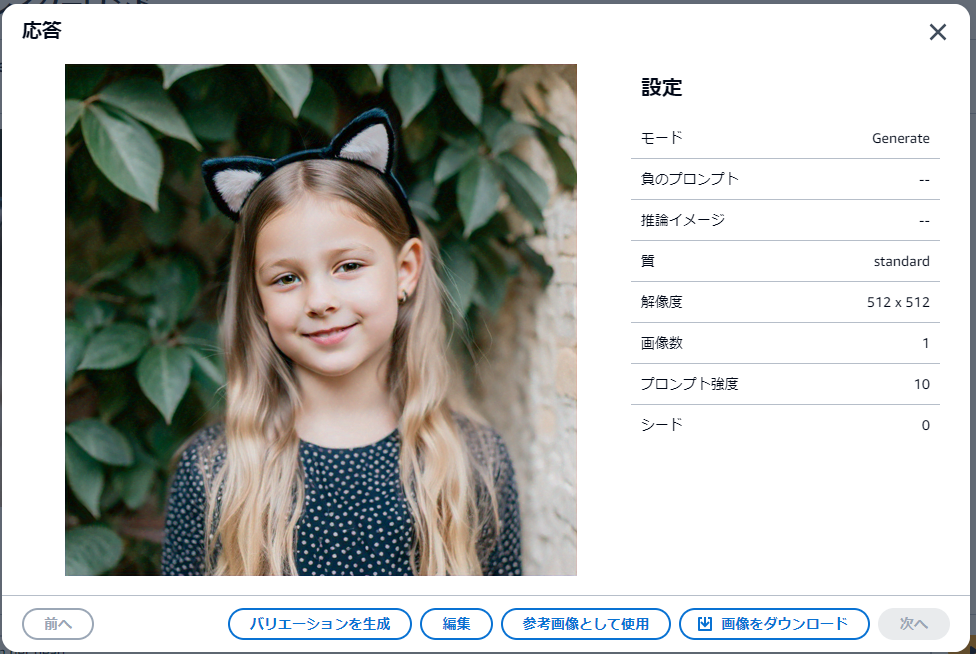
今度は猫耳の画像を生成して検証してみます。
プロンプト:Girl with cat eyars on her head
| 対象画像 | グラフ |
|---|---|
 |
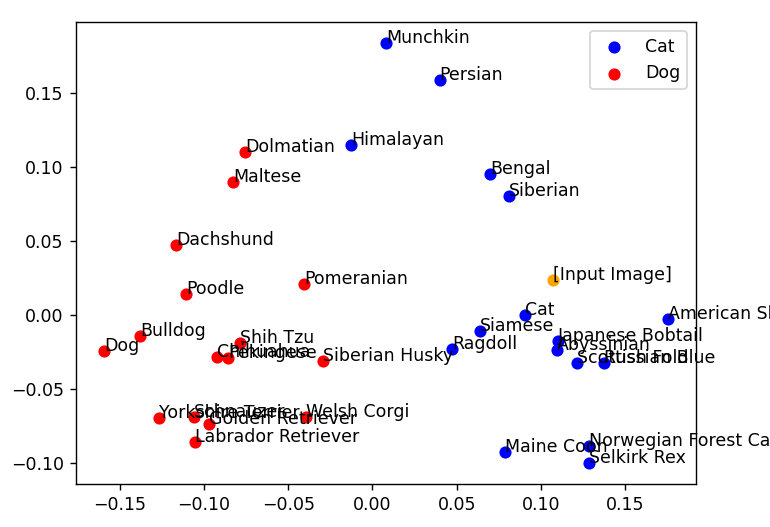 |
猫だと判定されています。
今度は犬耳の画像を生成します。
プロンプト:Girl with dog eyars on her head
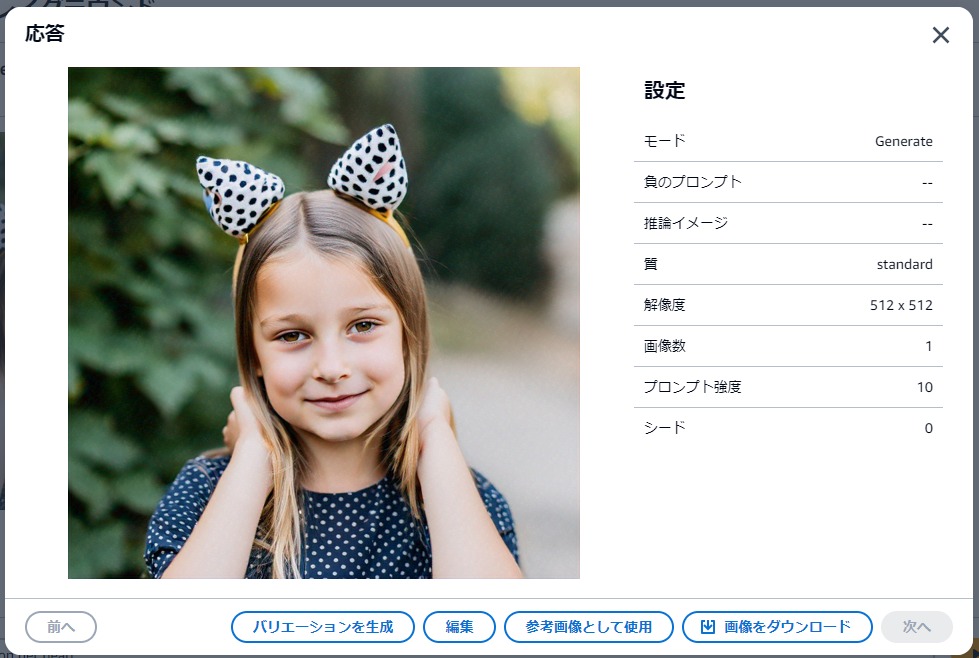
| 対象画像 | グラフ |
|---|---|
 |
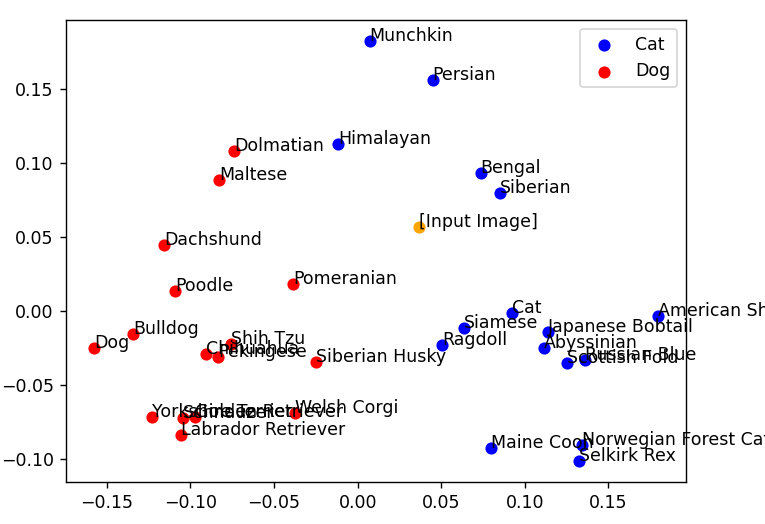 |
人間が見ても「犬…?」と思う画像ですが、AIも同じように猫だと判定しています。
結論とまとめ
人間に理解できない絵を出力して、「何を描いたの?」と聞いても、描いたAI自身も答えられないようです。
このことから、以下のことが言えると思います。
- 画像生成AIでプロンプトから画像に変換すると、そのデータに対応するベクトル表現は変わる
- dogのプロンプトで出力した画像が、dogのベクトル表現に分類できるわけではない
- 画像を分析しても、プロンプトのリバースエンジニアリングはできない