はじめに
GPUを使うと計算が速くなる!という話はよく聞くけれど、実際に使ってみるとなると心理的なハードルが大きくてなかなか踏み出せない、という人は多いのではないでしょうか。私もそのような人間のひとりでしたが、Julia言語ではものすごく簡単にGPUを利用できるという実感を得たので、ここで紹介したいと思います。以下では、
- Juliaはインストール済み
- 使用するマシンにNVIDIA製のGPUが導入されている
ことを前提にします。検証を行った環境は
- OS: Windows10
- julia: 1.4.0
- GPU: Geforce GTX 970
です。
CUDA Toolkitのインストール
まず念の為、自分のGPUが対応していることを確認します。使用可能なGPUの一覧はここで確認できます。例えばGeforce GTX 970は、確かにこの一覧に含まれていることが分かります。
次にこちらのページからCUDA Toolkitをインストールします。OS等を選択していけば、自動的に適切なインストーラを提示してくれます。
CUDA.jlのインストール
CUDA.jlはJuliaからCUDAを使用するためのパッケージです。2020年6月17日にversion 1.0が公開されました。
通常のパッケージの導入手順と同じく、コンソールからjuliaを起動し
julia> using Pkg
julia> Pkg.add("CUDA")
で導入できます。完了したら
julia> using CUDA
julia> using Pkg
julia> Pkg.test("CUDA")
により、CUDA.jlのテストコードを走らせてみます。
すると、
[ Info: Testing using device GeForce GTX 970 (compute capability 5.2.0, 3.301 GiB available memory) on CUDA driver 10.2.0 and toolkit 10.2.0
のようにデバイスとドライバーの情報が表示された後、種々のテストが実行されます。これは結構時間がかかるのでのんびり待ちます。何事もなければ
Test Summary: | Pass Fail Error Broken Total
Overall | 8327 0 0 0 8327
(以下省略)
のように表示されるはずですが、自分の場合はFail 1, Error 1, Broken 1になりました。しかし、gpuarrays/linear algebraやgpuarrays/fftなどの大事そうな項目のテストはパスしたので、ここは見なかったことにして先に進みます。
JuliaでGPU計算
まずは公式ドキュメントのチュートリアルに載っているコードをそのままコピペして動かしてみると良いと思います。配列をGPUのメモリに乗せる方法はとてもシンプルで、juliaの配列をcu()で囲むだけでOKです。cu()で変換された配列は、CuArray型になります。CuArrayから通常の配列に戻すときはArray()かcollect()を使います。
using CUDA
N = 2^10
x = fill(1.0f0, N)
typeof(x) == Vector{Float32}
# CPU -> GPU
xcu = cu(x)
typeof(xcu) == CuArray{Float32,1,Nothing}
# GPU -> CPU
typeof(Array(xcu)) == Vector{Float32}
typeof(collect(xcu)) == Vector{Float32}
その他、配列を確保する方法として、
using CUDA
N = 2^10
CUDA.zeros(N, N)
CUDA.ones(N, N)
CUDA.fill(2.0, N, N)
CUDA.rand(N, N)
などが利用できます。
注意点としては、Float64の配列をGPUに渡すと、自動的にFloat32に変換されることでしょうか。
using CUDA
N = 2^10
y = fill(1.0, N)
ycu = cu(y)
typeof(y) == Vector{Float64}
typeof(ycu) == CuArray{Float32,1,Nothing}
ドキュメントによれば、
We used Float32 numbers in preparation for the switch to GPU computations: GPUs are faster (sometimes, much faster) when working with Float32 than with Float64.
なのだそうです。
基本的な使い方が分かったところで、GPUで本当に計算が速くなるのかどうかを実験してみたいと思います。そこで、$ N\times N $行列をCPU/GPU上に用意してそれを2乗する、という処理にかかる時間を比較してみます。以下はそのサンプルコードです。
using CUDA
using BenchmarkTools
using Statistics
function cumatmul(N)
A = CUDA.ones(N, N)
A*A
A=nothing
end
function matmul(N)
A = ones(Float32, N, N)
A*A
A=nothing
end
b = [@benchmark matmul(2^$n) for n in 1:11]
c = [@benchmark cumatmul(2^$n) for n in 1:11]
bt = [mean(bn.times)/1e9 for bn in b]
ct = [mean(cn.times)/1e9 for cn in c]
@benchmark hoge()とすると、hoge()を複数回実行して、かかった時間や確保したメモリの量などの情報を教えてくれます。時間はナノ秒単位で出力されるのですが、最後のところでは秒に換算するため$ 10^9 $で割っています。縦軸を時間、横軸を行列のサイズにとってプロットすると、以下のようになりました。
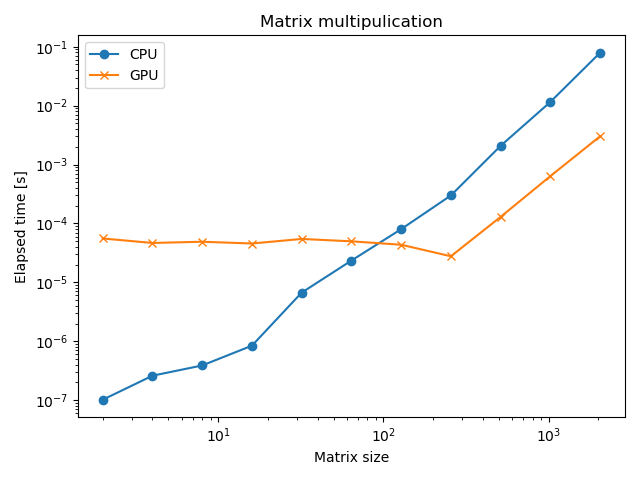
行列のサイズが256を越えたあたりから、GPUで計算した方がCPUの場合より約10倍高速になることが分かります。劇的ですね。もし自分の行っている数値計算の中で、巨大な行列の掛け算を何度も反復するような処理があり、さらにそれが全体のボトルネックになっているような場合は、ソースコードにちょっとcu()と書いてやるだけで高速化することが望めます。この他、行列の和、差、スカラー倍、element-wise operation (sin.(A)とか)も高速です。
同じ調子で、高速フーリエ変換も比較してみましょう。
using CUDA
using BenchmarkTools
using Statistics
using FFTW
function gpu_fft(N)
a = CUDA.ones(2^20)
CUFFT.fft(a)
a = nothing
end
function cpu_fft(N)
a = ones(Float32, 2^20)
fft(a)
a = nothing
end
b = [@benchmark cpu_fft(2^$n) for n in 10:20]
c = [@benchmark gpu_fft(2^$n) for n in 10:20]
bt = [mean(bn.times)/1e9 for bn in fftb]
ct = [mean(cn.times)/1e9 for cn in fftc]
結果は以下のようになりました。
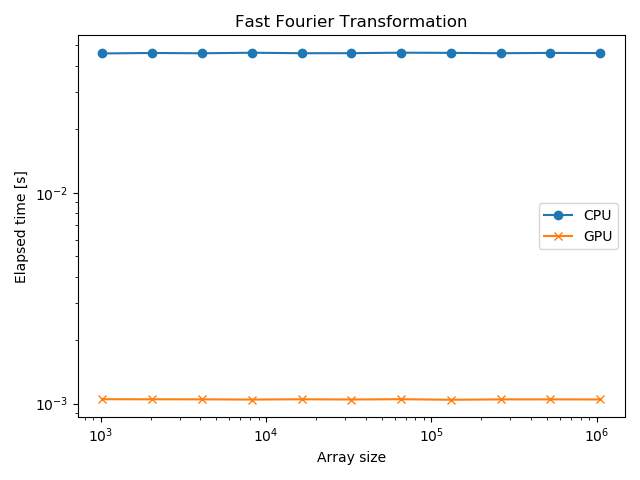
GPUの方が40倍以上高速です。これはこれで感動的ですが、むしろFFTのアルゴリズム自体の優秀さを実感します。
GPUが苦手な処理
とはいえ、GPUも万能ではありません。公式ドキュメントでも解説されていますが、下手に配列の要素にアクセスしてしまうと、パフォーマンスが急激に悪化します。例えば、
function element(N)
A = zeros(N)
for i in 1:N
A[i] = i
end
A = nothing
end
function element_cu(N)
A = CUDA.zeros(N)
for i in 1:N
A[i] = i
end
A = nothing
end
を考えましょう。これらの実行時間を計測すると、例えば
julia> @time element(2^14)
0.000033 seconds (2 allocations: 128.078 KiB)
julia> @time element_cu(2^14)
0.533071 seconds (49.18 k allocations: 2.001 MiB)
のようになり、GPUの方が桁違いに遅くなります。このような場合、CUDA.jlは
Warning: Performing scalar operations on GPU arrays: This is very slow, consider disallowing these operations with `allowscalar(false)
という警告を出してくれるので、参考にすると良いでしょう。これに関連して、GPUの処理が遅くなる例としては、行列のトレース
julia> using LinearAlgebra
julia> using CUDA
julia> A = ones(2^9,2^9)
julia> cuA = CUDA.ones(2^9,2^9)
julia> @time tr(A)
0.000011 seconds (1 allocation: 16 bytes)
julia> @time tr(cuA)
0.000816 seconds (289 allocations: 9.734 KiB)
やクロネッカー積
julia> using LinearAlgebra
julia> using CUDA
julia> A = ones(2^4,2^4)
julia> cuA = CUDA.ones(2^4,2^4)
julia> @time kron(A, A)
0.000142 seconds (2 allocations: 512.078 KiB)
julia> @time kron(cuA, cuA)
3.957541 seconds (208.91 k allocations: 8.750 MiB)
などがあります。ちなみに、CuArrayにdet()やinv()を使うとエラーになります。
まとめ
juliaでGPUを利用する方法を概観し、巨大な行列の演算や高速フーリエ変換が高速に行えることを確認しました。特に、低レベルの処理を一切気にせず、cu()するだけで十分な効果が期待できる場合があることが分かりました。GPUの利用は、相当ハードルが下がったと言えるのではないでしょうか。