BigQuery Data Transfer Serviceを使用してS3からBigqueryへのデータロードを行います。
BigQuery Data Transfer Serviceの概要
あらかじめ設定されたスケジュールに基づき、BigQueryへのデータの移動を自動化するマネージドサービスです。
今回は S3からBigqueryへデータロードするため、BigQuery Data Transfer Service for Amazon S3を使用して、S3から BigQueryへの定期的な読み込みジョブを自動的にスケジュールし、管理します。
なお、BigQuery Data Transfer Serviceのジョブ実行自体には料金はかからず、S3からの上り(AWS)、BigQueryのストレージとクエリの標準料金のみ適用されます。
- アクセス方法は以下です。
- Cloud Console
- bq コマンドライン ツール
- BigQuery Data Transfer Service API
制約事項
-
BigQuery Data Transfer Service for S3では、以下の形式のデータの読み込みをサポートしています。
-
カンマ区切り値(CSV)
-
JSON(改行区切り)
-
Avro
-
Parquet
-
ORC
- データソースのS3のURIは最上位のバケット名のみが必須となり、配下のフォルダ名は任意で指定可能です。
例えば
最上位のバケット名 s3://load-bigquery を指定した場合、配下にあるファイルは全て転送対象となります。
s3://load-bigquery/folder1 を指定した場合、folder1 配下のファイルのみ転送対象となります。
- URIにはワイルドカードを使用出来ます。
例えば s3://load-bigquery/folder1/*.csv を転送対象と指定した場合、s3://load-bigquery/folder1/test.csv および、s3://load-bigquery/folder1/folder2/prod.csv は転送対象となります。
-
BigQuery Data Transfer Serviceでは、BigQueryの読み込みジョブに対して以下の上限事項があります。
-
読み込みジョブの転送実行ごとの最大サイズ 15 TB
-
Amazon S3 URIに 0~1 個のワイルドカードを使用する場合の転送実行ごとの最大ファイル数 10,000,000 ファイル
-
Amazon S3 URIに複数のワイルドカードを使用する場合の転送実行ごとの最大ファイル数 10,000 ファイル
-
URI と宛先テーブルはどちらも
run_time/run_dateというパラメータの利用が可能です。
例えば、日付毎に格納されたバケットからデータを読み込めます。
URI内のcsvは、今日の日付で分割されたテーブルに転送されます。
更新転送では、この構成によって、最後の読み込み以降に追加されたファイルが転送対象になり特定のパーティションに追加されます。
| 利用箇所 | 値 |
|---|---|
| 抽出元 URI | s3://load-bigquery/*.csv |
| パラメータ化された宛先テーブル名 | table${run_time | "%Y%m%d"} |
| 評価された宛先テーブル名 | table$20211007 |
使用順序のまとめ
S3
-
S3側は以下の準備が必要です。
-
対象バケットから転送を呼び出しを行う際に使用する IAMアクセスキーIDの準備
-
対象バケットから転送を呼び出しを行う際に使用する シークレットアクセスキーの準備
-
対象のIAMから対象バケットに対して少なくとも AWS管理ポリシー AmazonS3ReadOnlyAccessの設定
-
転送するS3バケットURIの用意
-
AWS側に特段要件が無い場合、以下のようにバケットポリシー上で特定のIAMユーザーのみの操作を許可する事でアクセス権限を最小限に抑える事が可能です。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal":{
"AWS": "arn:aws:iam::account-id:user/xxx"
},
"Action":"s3:*",
"Resource": [
"arn:aws:s3:::account-id-bucket",
"arn:aws:s3:::account-id-bucket/*"
]
},
{
"Effect": "Deny",
"Principal": "*",
"Action": "s3:*",
"Resource": [
"arn:aws:s3:::account-id-bucket/*"
],
"Condition": {
"StringNotEquals": {
"aws:username": "xxxx"
}
}
}
]
}
BigQuery Data Transfer Service
- BigQuery Data Transfer APIを有効化する必要があります。
Google ConsoleからBigqueryを選択いただき、有効化を選択します。
- 転送するユーザー(Google Cloud側)に
bigquery.admin権限が必要です。必要に応じて権限を持つユーザーの追加、変更をします。
作業
BigQueryのデータセット、テーブル作成を行います。
今回は bq コマンドラインから実施します。
データセットの作成
bq --location=us mk --dataset test_dataset_s3
テーブルの作成 (今回はインラインでスキーマを定義します)
bq --location=us mk --table test_dataset_s3.test_table date:string,randomvalue:string
BigQuery Data Transfer Serviceの転送ジョブを作成します。
ここでアクセスキーID / シークレットキー/ 転送対象の URI が必要となります
bq mk \
--transfer_config \
--data_source=amazon_s3 \
--display_name=load_from_s3 \
--target_dataset=test_dataset_s3 \
--params='{
"data_path":"s3://xxx-test01",
"destination_table_name_template":"test_table",
"access_key_id":"xxxxxxxxxxxxx",
"secret_access_key":"xxxxxxxxxxxxxx",
"file_format":"CSV",
"max_bad_records":"0",
"ignore_unknown_values":"true",
"field_delimiter":",",
"skip_leading_rows":"0",
"allow_quoted_newlines":"true"
}'
BigQuery Data Transfer Service を使用する bq コマンドのオプションは以下に記載があります。
https://cloud.google.com/bigquery-transfer/docs/s3-transfer
- 実行後に URLが発効されるため、ブラウザから認証コードを取得してコマンドラインに貼り付けます。
Enter your version_info here:
認証が完了すると、ジョブの実行が開始されます。
今回はテスト用の CSV のため数秒で実行が完了しました。
ロードしたデータの確認
ジョブが完了すると、bq コマンドライン ツールからロードしたテーブルにクエリを実行して、データが格納されているかを確認します。
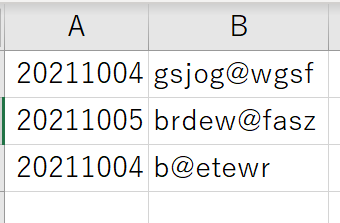
bq query --nouse_legacy_sql 'SELECT * FROM test_dataset_s3.test_table'
+----------+-------------+
| date | randomvalue |
+----------+-------------+
| 20211004 | gsjog@wgsf |
| 20211004 | b@etewr |
| 20211005 | brdew@fasz |
+----------+-------------+
以下は S3 の CSV のデータソースです。ロードは問題なく完了しているようです。