DynamoDBを以前ほんの少しだけ触ったことがあるのですが、DynamoDBはデータに一貫性が無いとかいう記事を見て、「DynamoDBの何が良いんだろう。」とずっと疑問に思っていました。その疑問を解消しようとしてみた際のまとめです。
要旨
本投稿は、NoSQLについての理解を深めることを目的にしています。
- NoSQLとは
- Non-Relationalなデータモデル
- RDBMSのShardingの何が問題だったのか
- 分散システム
- CAP Theorem
- Scalabiilty (Replication / Sharding)
- DynamoDB
余談:Designing Data-Intensive Applicationsは名著だった。

【引用】Designing Data-Intensive Applications
名著オブ名著。もはや全アプリケーションエンジニア必読のレベルなのでは。データベースについて理解を深めようとするなら、絶対に読んだ方が良いと思います。日本語訳も出ているぽいので是非。
NoSQLの勃興
まずNoSQLとは何を指していて、何故生まれたのかについて見ていきます。
NoSQLとは

【引用】16 NoSQL, NewSQL Databases To Watch
NoSQLは、Not Only SQLの略です。Non-Relationalなデータモデルを採用することで脱SQLしたデータベースのことを指しています。NoSQLと一括りにされていますが、データモデルも様々なものがあり、それぞれ採用している技術が異なったりしています。本投稿では、基本的にDynamoDBを主軸に話を進めています。
NoSQLが何故生まれたのか
NoSQLの発端はAmazonの「Dynamo」とGoogleの「BigTable」の論文です。そこにサンフランシスコでのNoSQLのミートアップが続きました。
DynamoとNoSQLミートアップに注目することで、データベースの主流であったRDBMSでは何が不十分だったのかを見ていきたいと思います。
Dynamo
Dynamoの作成に至るモチベーションは、AWSのCTOのブログに綴られています。
A deep dive on how we were using our existing databases revealed that they were frequently not used for their relational capabilities. About 70 percent of operations were of the key-value kind, where only a primary key was used and a single row would be returned. About 20 percent would return a set of rows, but still operate on only a single table.
【引用】A Decade of Dynamo: Powering the next wave of high-performance, internet-scale applications
relationalにデータを管理しなくても良いケースが多く、単純なoperationが大半を占めていたことがDynamo作成に至るモチベーションだったようです。
San Francisco NoSQL Meet up
2009年にサンフランシスコで開催されたミートアップです。このミートアップでNoSQLという用語が生まれました。このミートアップのイントロダクションの資料では、NoSQLの前提/時代背景を紹介するスライドがあり、そこでは「data size」「reliability」「performance」の3つが挙げられています。
- data size:データサイズが増大し、一つのnodeにDBが収まりきらなくなったことからPartitionが必要となった。
- reliability:可用性のためにReplicationが可能、かつfault-tolerantである必要があった。
- performance:リアルタイム性のためにパフォーマンスが必要となった。
その時代の主流のデータベースであったRDBMSでこれらの要件を満たすことは難しかったと、スライドに記載されています。

【引用】Design Patterns for Distributed Non-Relational Databases
つまり
RDBMS+Shardingが罪であり、またrelationalに管理しなくてもよかったユースケースからNoSQLが生まれたようです。なのでNoSQLについて理解を深めるためには、以下の3つについて理解を深める必要があるでしょう。
- RDBMS+Shardingの問題点
- relationalなデータモデルに変わる新しいデータモデル
- 分散システム
ということで、上の3点についてこれから順に見ていきたいと思います。
ちなみに、Shardingという用語を使っていますが、これはPartitioningと同意のようです。
What we call a partition here is called a shard in MongoDB, Elasticsearch, and SolrCloud; it’s known as a region in HBase, a tablet in Bigtable, a vnode in Cassandra and Riak, and a vBucket in Couchbase. However, partitioning is the most established term, so we’ll stick with that.
【引用】Designing Data-Intensive Applications
RDBMS + Sharding(Parititioning)
Shardingとは
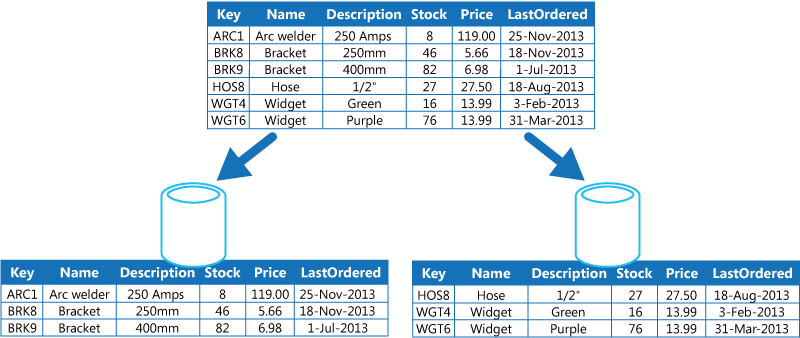
【引用】Data Partitioning Guidance
DBを分割し、分割されたDBを別々のnodeに持たせることを指します。(Shared-nothing)
データサイズの増加、writeリクエストの増加からShardingが求められました。Shardingを利用することで、データサイズを小さく管理することができ、またread・write共に負荷分散することができます。
RDBMS + Shardingの問題点
Shardingを導入しRDBMSを分散システムとして利用することも可能ですが、そうするとRDBの旨味を綺麗さっぱり消してしまうのです。もともとRDBMSは、1台のノードの中で単一のDBを保持するmonolithicな形式になっていて、複数ノードにDBを分散させることは想定されていません。
 【引用】[Amazon Aurora MySQL- Compatible Edition](https://aws-ref.s3.amazonaws.com/aurora/Amazon+Aurora.pdf)
【引用】[Amazon Aurora MySQL- Compatible Edition](https://aws-ref.s3.amazonaws.com/aurora/Amazon+Aurora.pdf)
RDBMS+Shardingに関してNoSQL Distilledで簡潔にまとめられていたので引用します。
Relational databases could also be run as separate servers for different sets of data, effectively sharding (“Sharding,” p. 38) the database. While this separates the load, all the sharding has to be controlled by the application which has to keep track of which database server to talk to for each bit of data. Also, we lose any querying, referential integrity, transactions, or consistency controls that cross shards. A phrase we often hear in this context from people who’ve done this is “unnatural acts.”
【引用】NoSQL Distilled
RDBMS+Shardingの問題点として上の記述で挙げられているのは、以下の4つです。
- クエリの一部を失う(本投稿ではJOINを取り上げます。)
- 参照整合性を失う
- Transactionを失う
- アプリケーション側のロジックの複雑化
順に見ていきます。
JOINを失う
RDBでは、データの正規化(normalization)が導入されています。そしてこの正規化という特徴を通してデータは複数のテーブルに跨って管理されています。この複数テーブルのデータを結合するためにJOINという機能が提供されています。
JOINは、単一nodeでRDBMSが動いていたからパフォーマンスを保って実行できました。RDBMSをPartitioningすると、テーブルが複数のnodeにまたがることになり、テーブルの結合がネットワーク越しとなってしまいパフォーマンスがだだ下がります。(transactionの問題は後に説明します。)
この問題点が、RDBMS+Shardingの問題点だとよく指摘されています。が、一方で、これは設計に注意することで回避することができる問題点です。
When choosing a partitioning key, try to pick something that lets you avoid cross-shard queries as much as possible, but also makes shards small enough that you won’t have problems with disproportionately large chunks of data. You want the shards to end up uniformly small, if possible, and if not, at least small enough that they’re easy to balance by grouping different numbers of shards together.
【引用】High Performance MySQL
要するに、ちゃんとpartitionの設計をして、関連するテーブルをsingle nodeに収めるように設計すれば、cross shardのqueryを実行する必要はなくなるわけです。この点が分かりやすい図がawsのドキュメントにあったので載せておきます。
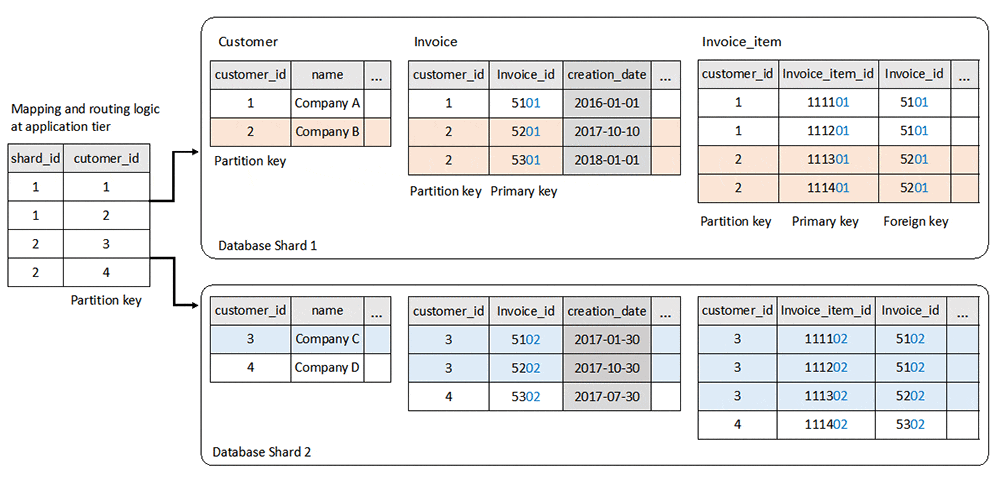
【引用】Amazon Relational Database Service を使用したシャーディング
Transactionを失う
「PartitioningをするとTransactionが不可能になる」という記述をよく見ますが、正確ではありません。その点はDesigning Data-Intensive Applicationsでも言及されています。
Many distributed datastores have abandoned multi-object transactions because they are difficult to implement across partitions, and they can get in the way in some scenarios where very high availability or performance is required. However, there is nothing that fundamentally prevents transactions in a distributed database, and we will discuss implementations of distributed transactions in Chapter 9.
【引用】Designing Data-Intensive Applications
実際、MySQLでは分散システム版のTransactionとして、XA Transactionを使うことができます。storage engine内で完結していたTransactionを、strage engineを超えてネットワーク越しに利用されるのが、このXA Transactionです。
MySQLのドキュメントにもあるように、このXA Transactionではtwo-phase commitが用いられています。
The process for executing a global transaction uses two-phase commit (2PC). This takes place after the actions performed by the branches of the global transaction have been executed.
【引用】13.3.8 XA Transactions
分散システムでTransactionを実現しようとすると、各storage engineが実行するtransactionを一斉に実行する必要があるわけですが、その際に用いられる仕組みがtwo-phase commitです。
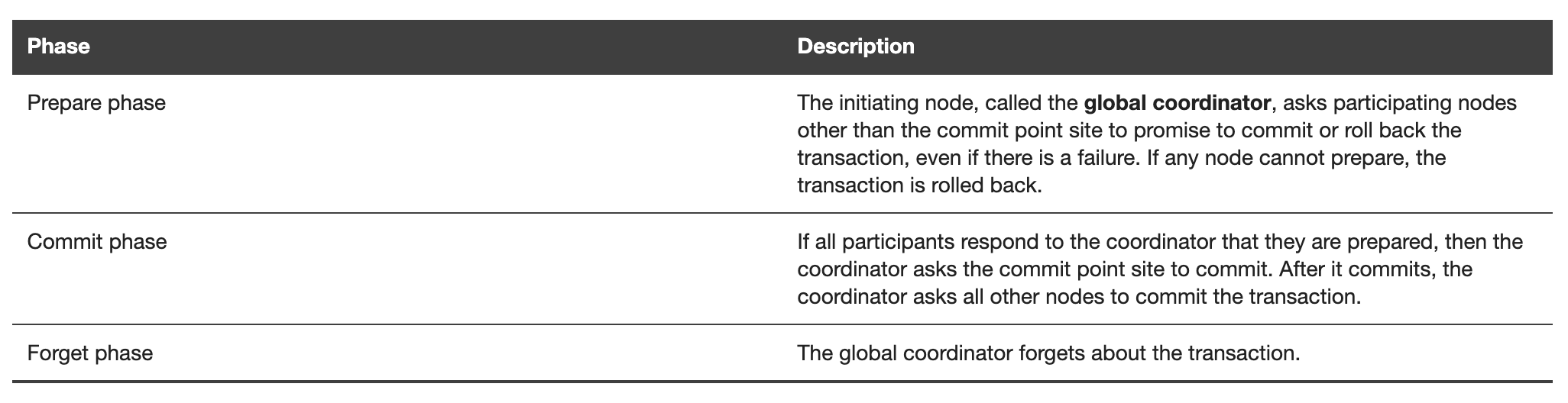 【引用】[Two-Phase Commit Mechanism](https://docs.oracle.com/cd/B28359_01/server.111/b28310/ds_txns003.htm#ADMIN12223)
【引用】[Two-Phase Commit Mechanism](https://docs.oracle.com/cd/B28359_01/server.111/b28310/ds_txns003.htm#ADMIN12223)
各nodeでのtransactionを実行するか放棄するかなどの決断を下したり管理するTransaction Managerが必要になります。が、このTransaction Managerの役割はMySQLではなくアプリケーション側に任されているのです。
For “external XA,” a MySQL server acts as a Resource Manager and client programs act as Transaction Managers.
【引用】13.3.8.3 Restrictions on XA Transactions
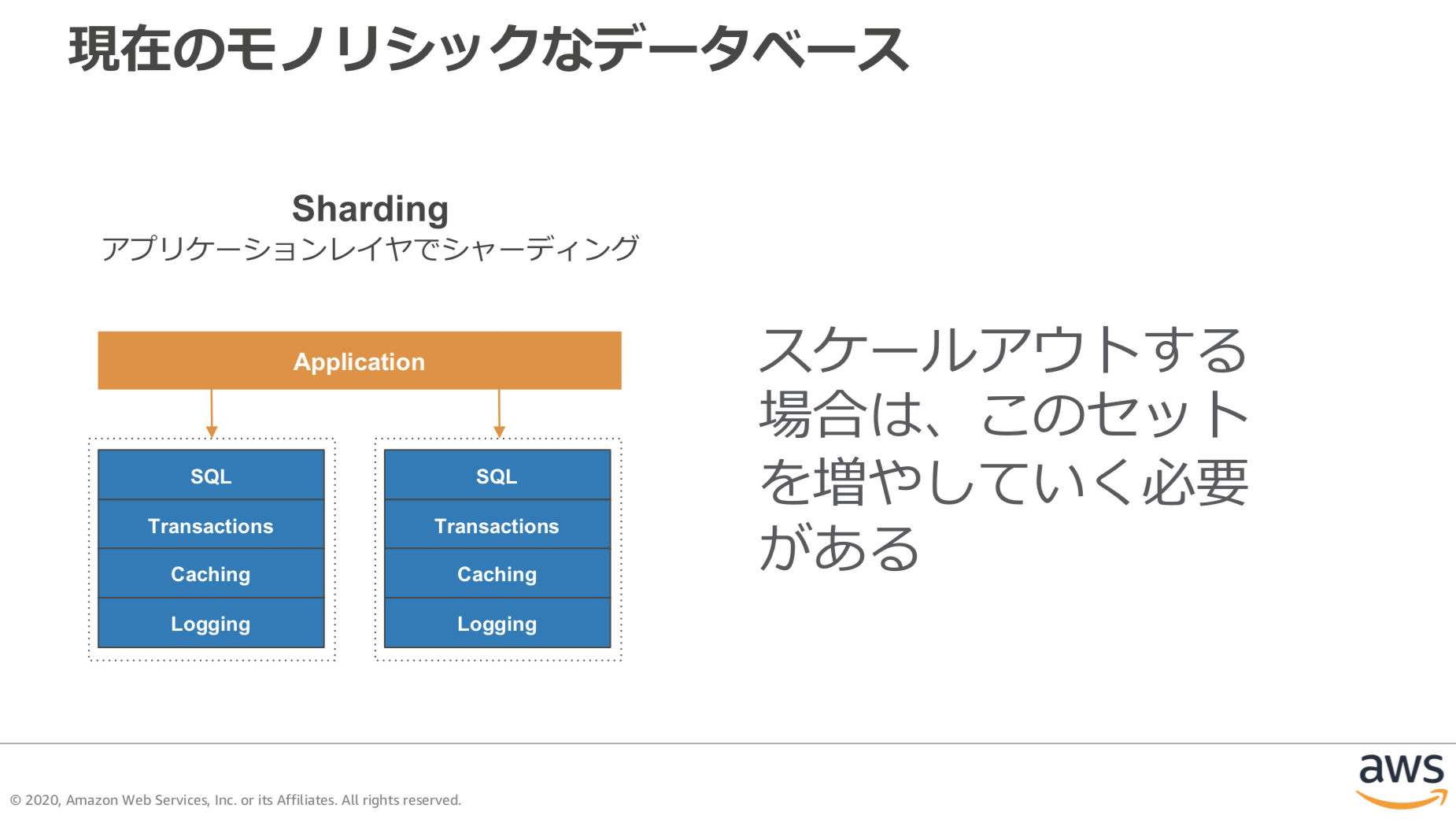 【引用】[Amazon Relational Database Service を使用したシャーディング](https://aws.amazon.com/jp/blogs/news/sharding-with-amazon-relational-database-service/)
【引用】[Amazon Relational Database Service を使用したシャーディング](https://aws.amazon.com/jp/blogs/news/sharding-with-amazon-relational-database-service/)
上の図を見ると分かりやすいですが、RDBMSは下のブロックを提供するものであり、それらを管理する要素は提供していません。つまり、MySQLは自分のstorage engine内でのtransactionを保証することはできますが、複数nodeにまたがるtransactionを保証するのはアプリケーション側の責務になってくることに注意が必要です。
また、このdistributed transactionはパフォーマンスが非常に悪いため基本的には使わない方が良いそうです。
Some implementations of distributed transactions carry a heavy performance penalty —for example, distributed transactions in MySQL are reported to be over 10 times slower than single-node transactions [87], so it is not surprising when people advise against using them. Much of the performance cost inherent in two-phase commit is due to the additional disk forcing (fsync) that is required for crash recovery [88], and the additional network round-trips.
【引用】Designing Data-Intensive Applications
まとめると、分散システムとしてMySQLを用いる場合、Transactionが不可能なわけではありませんが、基本的にそれを回避する姿勢が求められます。そしてそれはつまり、ACID特性が失われることを意味します。
参照整合性(Referential Integrity)を失う
Parititioningを利用した場合、外部制約キーはサポートされないと、MySQLのドキュメントに記されています。そして外部制約キーが利用できないのであれば参照整合性を担保することはできません。
Foreign keys not supported for partitioned InnoDB tables
【引用】23.6 Restrictions and Limitations on Partitioning
外部制約キーの一貫性の担保はstorage engineが裏側で行ってくれているためエンジニアが意識することはあまりありません。裏側では、まず変更対象のrowにロックをかけ、そして外部制約キーによって参照されている別のテーブルのrowを確認しロックをかけ、そして変更対象のrowを変更しtransactionを完了させた上でロックを解除しています。
つまり参照整合性は複数テーブルにまたがるtransactionによって成立しているのです。そしてPartitioningを利用した場合transactionを実現することが難しいことは先に述べました。
つまりPartitioningを利用すると、参照整合性を担保することはできないのです。一方で、参照整合性を保つことが「不可能である」と言っているわけではありません。アプリケーション側で参照整合性が保たれていることを保証するコードを書くことで参照整合性を保持することができます。
Querying across shards isn’t the only thing that’s harder with sharding. Maintaining data consistency is also difficult. Foreign keys won’t work across shards, so the normal solution is to check referential integrity as needed in the application, or use foreign keys within a shard, because internal consistency within a shard might be the most important thing. It’s possible to use XA transactions, but this is uncommon in practice because of the overhead.
【引用】High Performance MySQL
アプリケーション側のコードの複雑化
ここまででも分かりますが、single nodeで動く想定で作成されたMySQLでPartitioningを利用すると、アプリケーション側のコードが複雑化します。
MySQLは自分のstorage engineが管理しているDBのみを担当するのであって、複数のstorage engineを管理する機能は提供されていません。つまり、Partitioningを利用すると、Partitionを管理する機能を全てアプリケーション側で実装する必要が出てくるわけです。
まず、どのクエリをどのPartitionに送るかというルーティングロジックを実装する必要が出てきます。さらにPartition自体の管理も必要になってきます。もしも特定のnodeにアクセスが偏ってしまうhot spotが生まれてしまった場合、Partitionの分け方を変える必要が出てきます。もしかしたらnodeを新しく追加するのかもしれません。Partitionを新しく追加/削除する場合はデータのMigrationを実行する必要も出てきます。
また、transactionを管理する機能もアプリケーション側で実装する必要が出てきます。もしもXA transactionを利用するのであれば、two-phase commitが使われているようなので、Partition Tolerantな設計にしなければ同期処理が完了せず処理がストップするという事態に陥ることもあるのかもしれません。
さらに参照整合性もアプリケーション側で担保する必要があります。また、もとよりMySQLはsingle nodeで管理するのがデフォルトであり、そのように管理してきたコードを分散システムへと移行させるのは非常に多くの工数を要するでしょう。
Non Relationalなデータモデル
Relationalにデータを保持しなくても良いケースが多かったことから、Non-Relationalなデータモデルが取り入れられました。ここではNon Relationalなデータモデルの特徴について見ていきます。
Aggregate
RDBの場合、正規化を通してrelationalにデータを管理します。一方でNoSQL(DynamoDB)では、一緒に使うような関連するデータをまとめて保持するデータモデルが採用されています。
NoSQL Distilledでは、このことをlocalizationと表現していました。(日本語でいう「参照の局所性」ぽいです。)
20 年前のルーティングテーブルの最適化に関する研究では、関連するデータをまとめて 1 つの場所にまとめておく「参照の局所性」が、応答時間を短縮する上で最も重要な要素であることが分かりました。これは、今日の NoSQL システムにも同様に当てはまります。関連するデータを近くに置くことはコストとパフォーマンスに大きな影響を与えます。関連するデータ項目を複数のテーブルに分散するのではなく、NoSQL システム内の関連項目を可能な限り近くにまとめる必要があります。
【引用】DynamoDB に合わせた NoSQL 設計
複数テーブルを結合する必要もなく、関連するデータを一括で引っ張ってこれます。(もちろんAggregateが別れている場合はJOIN的な処理が必要になります。そのためNoSQLでは設計(データモデリング)が非常に重要になってきます。)
Scheme Less
RDBではスキーマ定義を事前に行いますが、NoSQLのデータモデルはスキーマレスであり、事前にスキーマを定義する必要はありません。
 【引用】DynamoDBのテーブル作成画面
【引用】DynamoDBのテーブル作成画面
DynamoDBではテーブル名とプライマリキー、ソートキーを指定するのみでテーブルが作成できます。後の項目はスキーマ定義関係なしに、後からじゃんじゃん投入することができます。
このスキーマレスという特徴は、すごくフレキシブルな印象を与えます。が、実際はscheme-on-read、つまりアプリケーション側でデータを読み込む時に、データ構造を特定しなければならないことに注意が必要です。
従来のRDBでは、スキーマ定義はDB側の責務であり、事前に定義されたスキーマを基にアプリケーションロジックを組むものでした。が、スキーマレスなデータモデルでは、スキーマ定義がアプリケーション側の責務になっているのです。
アプリケーション側でロジックを組むのは良いのですが、その際に項目名などスキーマについて事前に知っておかないとロジックが組めないのです。そして厄介なのが、その「前提としているスキーマ」はアプリケーションコード全体に散らばってしまうということです。この点を指してMartinはSchemaless Data Structuresでスキーマレスを「hidden scheme」と呼称し、これによって開発が難しくなってしまうと述べています。
ちなみにMongoDBのドキュメントでは、その点について以下のように述べています。
MongoDB is a document database that focuses on developer needs. (Notice a common theme yet?) There’s no need for an army of database administrators to maintain a MongoDB cluster and the database’s flexibility allows for application developers to define and manipulate a schema themselves instead of relying on a separate team of dedicated engineers.
【引用】Ruby, Rails, MongoDB and the Object-Relational Mismatch
スキーマレスであることによって、データベースのチームと組まなくてもアプリケーション側のチームが自由にスキーマを変更したりできるからメリットだと述べています。

【引用】Schemaless Data Structures
スキーマレスという点のみに絞ると、もしもcustom fieldを用いる場合であったり、non-uniformなデータを管理するだけのテーブルなのであれば、スキーマレスであるメリットはありますが、そうでない場合は、デメリットも考慮した上でNon-Relationalなデータモデルを取り入れるべきでしょう。
スキーマレスといえど、事前にアクセスパターンに基づいて入念に設計をすることが求められます。また、最初はNon-Relationalなデータモデルが適しているように見えるアプリケーションであっても、時が経つとRelationalに管理する必要が出てくる場合があることにも注意が必要です。
分散システムの設計
NoSQLを理解するためには、分散システムの設計について理解を深める必要があると思います。ここでは「CAP Theorem」そして「Scalability」について順に見ていきたいと思います。
CAP Theorem
CAP Theoremは、分散システムの設計を考える上で考慮すべき3つの性質間のトレードオフについて言及した定理です。
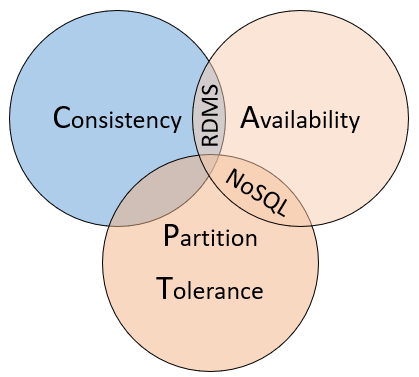
注意が必要なのですが、この定理は、誤解を生む表現などが使われていたり、考慮していない点が多いなどの理由から、結構批判を受けているようで、Designing Data-Intensive Applicationsでも、こっぴどくdisられていました。
A widely misunderstood theoretical result that is not useful in practice.
【引用】Designing Data-Intensive Applications
批判を受けているものの、分散システムの設計を考える上で、この3つの性質を理解しておくことは重要だと思うので、これから各性質について見ていきます。
- Consistency
- Availability
- Partition-tolerance
Consistency
CAP TheoremにおけるConsistencyは、Linearizabilityによる強整合性のことを指ししています。
This is equivalent to requiring requests of the distributed shared memory to act as if they were executing on a single node, responding to operations one at a time. One important property of an atomic read/write shared memory is that any read operation that begins after a write operation completes must return that value, or the result of a later write operation.
【引用】Brewer’s Conjecture and the Feasibility of Consistent, Available, Partition-Tolerant Web Services
強整合性の元では、あるwriteの後のreadは、必ずそのwriteによって書き込まれた最新のデータを取得します。
Avaiability
For a distributed system to be continuously available, every request received by a non-failing node in the system must result in a response.4 That is, any algorithm used by the service must eventually terminate.
【引用】Brewer’s Conjecture and the Feasibility of Consistent, Available, Partition-Tolerant Web Services
いつ如何なる時でも、生きているnodeにリクエストが来たなら待たせることなくレスポンスを返すんやで、って言っています。
Partition Tolerance
even if every other node in the network fails (i.e. the node is in its own unique component of the partition), a valid (atomic) response must be generated. No set of failures less than total network failure is allowed to cause the system to respond incorrectly.5
【引用】Brewer’s Conjecture and the Feasibility of Consistent, Available, Partition-Tolerant Web Services
たとえそのnode以外の全てのnodeがfailしていても、サービスが動くようにしとくんやで、って言っています。つまり単一障害点を持ってはいけないわけです。
CAP Theoremについて
どうやら原論文では、分散システムでは、この3つの性質のうち2つしか得ることはできないよ、的なことを述べているようなのですが、実際はそうではありません。
分散システムではネットワークの分割は遅かれ早かれ必ず起きてしまうものであり、それ故にPartition Toleranceを放棄するわけにはいかないのです。つまりCAP Theoremとは、「3つのうちから2つを選べ」ではなく、「ネットワーク分割が起きている時にConsistencyを優先するのかAvailablityを優先するのかを選ぶ」必要があるということを考えなければならないのです。
そしてこのConsistencyとAvailabilityは、どちらか一方の性質しか得ることができないというわけではなく、そのバランスを調整することが重要であることにも注意が必要です。
また、分散システムで考えられるfaultはネットワーク分割のみではない点や、システムをfault-tolerantにするためではなくPerformanceを得るためにConsistency(Linearazability)を緩和するケースも多い点にも注意が必要です。
Scalability
分散システムを考慮する上で、Scale Outの方法について把握しておくことは非常に重要でしょう。基本的にScale Outの手法は2つ、ReplicationとPartitioningがあるので、それらを見ていきます。
Replication
同じデータをコピーして複数のnodeに持たせます。single nodeで単一コピーを保持しいている場合と異なり、冗長性を持たせることができ、またreadのスケーラビリティを得ることができます。またnodeを地理的に分散させることで、地理的な利も得ることができます。
保持しているDBには、writeリクエストを通して変更が加えられていくわけですが、どのnodeに対してwriteリクエストを送るのかで、Replicationの仕組みが異なってきます。
writeが行われるnodeを一つだけ持っておくSingle Leader ( Master-Slave )、複数のnodeに対してwriteを許可するMulti Leader、Leaderを持たないLeader Lessの3つに大きく分けられるかと思います。
ここではMySQL、DynamoDBで利用されているSingle Leaderについて見ていきます。
ちなみにMulti Leaderは、Leaderの冗長性を高めることができる一方で、writeできるnodeが複数になることによってconcurrency issuesが発生するようになるというデメリットの方が大きいため、あまり使われないようです。
Single Leader
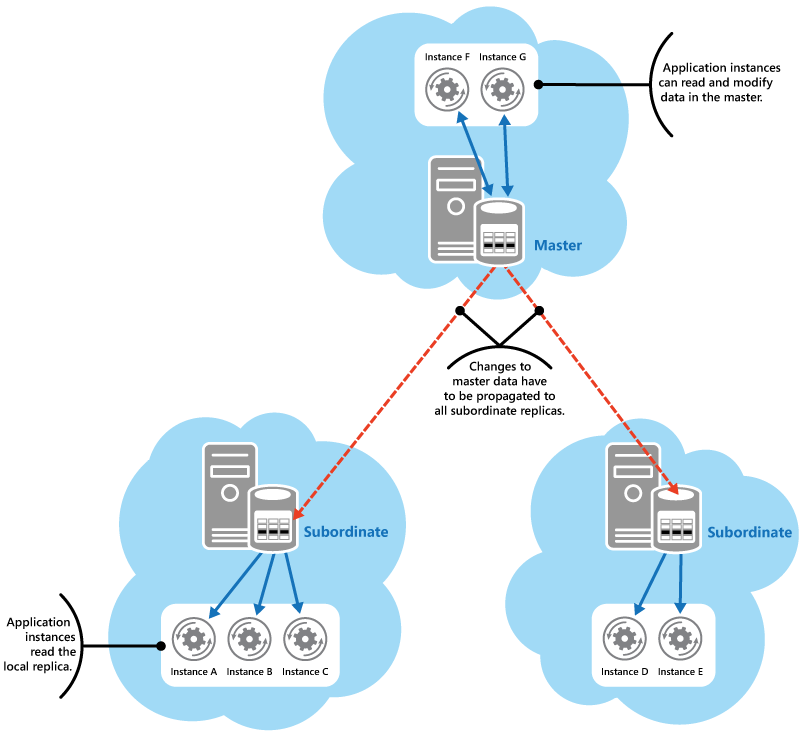
【引用】Data Replication and Synchronization Guidance
Leaderが1つであるため冗長性はなく、単一障害点になり得ます。LeaderからReplicaに対するwriteの波及方法として、同期レプリケーションと非同期レプリケーションがあります。
同期レプリケーションの場合、writeに対する冗長性を得られるというメリットがある一方で、相手のnodeがfailしたりネットワーク分割が起きた場合などに、Leaderに対するwriteの処理を実行・完了できなくなるなどのデメリットがあります。
非同期レプリケーションの場合、他のnodeやネットワークに関係なくデータの更新を実行・完了することができる一方で、Leaderに対してwrite操作が完了してもその後、他のnodeにログを共有する前にLeaderがfailすると、更新したデータを失ってしまうというデメリットがあります。
それ故に準同期レプリケーション(semi-syncronous)、つまりFollowerのうちの1つにだけデータを同期レプリケーションし、他のnodeに対しては非同期にレプリケーションするという手法が用いられます。後に見ますが、DynamoDBでもこの手法が用いられています。
非同期のレプリケーションが絡んでくると、Consistencyについても考える必要が出てきます。なぜなら非同期レプリケーションでは、Replication Lagが存在し、いつFollowerが最新のデータに更新されるのかが分からないからです。この点を指して、非同期レプリケーションにおけるConsistencyを「結果整合性(Eventual Consistency)」と呼びます。
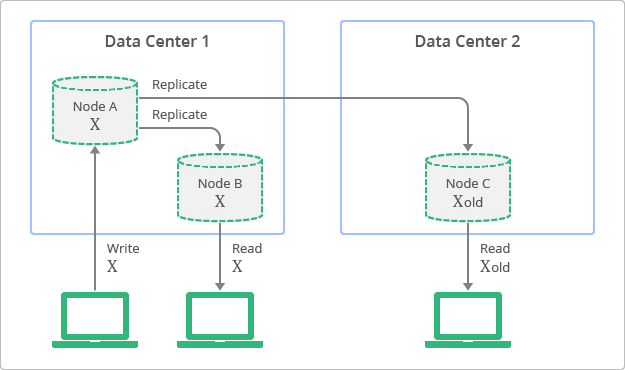
【引用】Datastore での強整合性と結果整合性のバランス
一方で同期レプリケーションの場合は、Followerのnodeにレプリケーションが完了するまではwriteを完了させないため、writeの完了はレプリケーションの完了を指します。この時Replicaに対するreadをブロックすることで、どのnodeでも最新のDBを保持しているという状態になります。この点を指して「強整合性(Strong Consistency)」と呼ばれます。
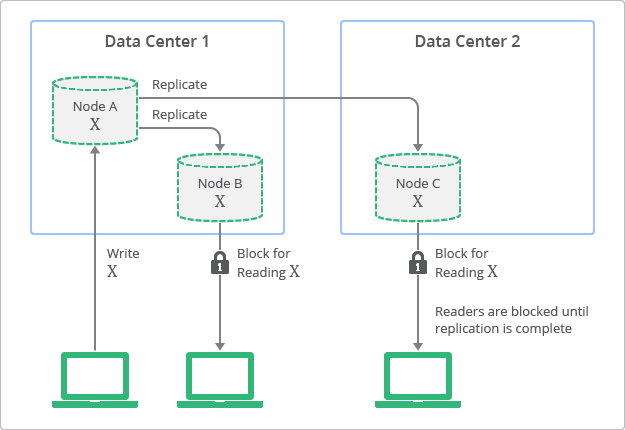
【引用】Datastore での強整合性と結果整合性のバランス
MongoDBのドキュメントによれば、MongoDBではstrong consistencyがデフォルトに設定されています。MongoDBもSingle Leaderなのですが、readリクエストはReplicaに対して行われるのではなく、Leaderに対してリクエストがいく設計になっています。そのためReplication Lagに関係なく、いつでも最新の状態を取得することができるというわけです。Replicaは、Leaderがfailした場合のバックアップとして機能しています。
この時、強整合性を得るために同期レプリケーションを利用していないことに注意してください。先にも述べましたが、同期レプリケーションにすると、1つのnodeがfailしただけでwriteが困難になりavailabilityが失われてしまったり、ネットワーク遅延によってwriteのパフォーマンスが下がるなどのデメリットがあるので利用されていません。
Eventual Consistencyに話を戻します。Replication Lagによって強整合性ではなく結果整合性になってしまっているわけですが、これは普通は問題にならないようです。Replication Lagが微々たるものだからです。
When working with a database that provides only weak guarantees, you need to be constantly aware of its limitations and not accidentally assume too much. Bugs are often subtle and hard to find by testing, because the application may work well most of the time. The edge cases of eventual consistency only become apparent when there is a fault in the system (e.g., a network interruption) or at high concurrency.
【引用】Designing Data-Intensive Applications
ただしネットワークの分割や遅延などの事象が発生した場合、結果整合性は問題となってきます。Replication Lagが大きくなってしまうからです。Leaderが持つ最新のデータをReplicaに反映できなくなる、もしくは反映が遅れることで、そのReplicaに対してreadリクエストを送ったユーザーは古い値を読み込んでしまう可能性が出てきます。(同じデータに対する並行アクセスが多い場合も同じく問題となってきます。)
これが先に述べたCAP Theoremの言わんとしているところです。「ネットワーク分割が起きた場合、Replicaから読み取ると、古い値が返ってくるかもしれないですけど、それでも読み込んでいいですよー。」として availabilityを優先するのか。それとも「そういう時にはReplicaからの読み込みを禁止しますよー。」としてConsistency(linearizability:一貫して最新の値を返す)を優先するのか、というトレードオフです。
古い値を読み込んでしまっても問題がない場合に結果整合性のシステムを採用しているとは思います。が、もしもそうではない場合、つまり必ず最新の値を返すという一貫性が求められる状況で結果整合性のシステムを利用している場合は、Replication Lagを考慮したデータアクセスを心がける必要があります。
さて、結果整合性と強整合性について見てきましたが、このどちらが良いとかいうことではなくて、使い分けが重要であることに注意が必要です。もしも強整合性が必要なユースケースなのであれば、強整合性を利用し、強整合性が不要な場合は、スケーラビリティとパフォーマンスのために結果整合性を極力利用しましょう、ということです。
Sharding / Partitioning
Shardingの手法
アプリケーションの設計を考える上で重要なのが、どのようにしてデータをShardに分け、格納するnodeを決めるのかということです。Shardingの方法にも色々あるようですが、ハッシュ戦略と範囲戦略を理解しておけば問題ないように思います。
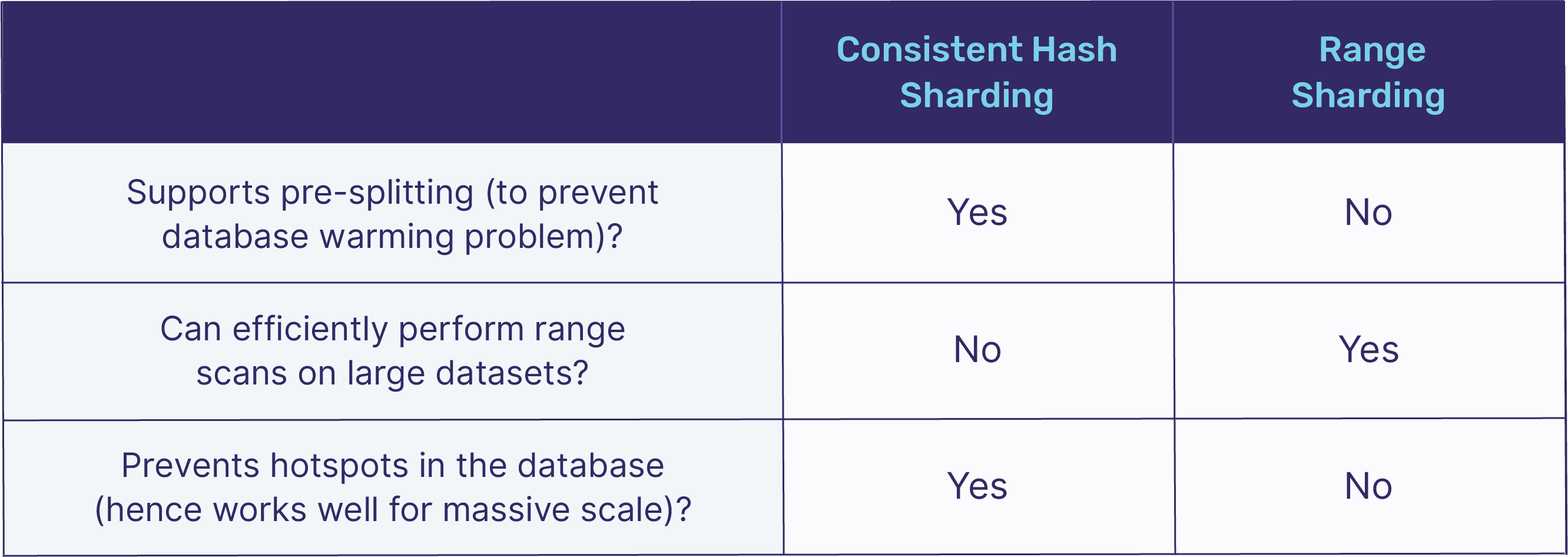
【引用】Four Data Sharding Strategies We Analyzed in Building a Distributed SQL Database
DynamoDBやCassandraはConsistent Hash Shardingをデフォルトに、Google SpannerやApache HBaseはRange Shardingをデフォルトにしているようです。
Range Shardingは、partition keyの値の範囲ごとにShardが決まります。一方でConsistent Hash Shardingは、partition keyの値をハッシュ化して、Consistent Hashingを用いて値に応じたShardにデータを格納します。Consistent Hashingによって、Incremental Scalabilityが可能になります。
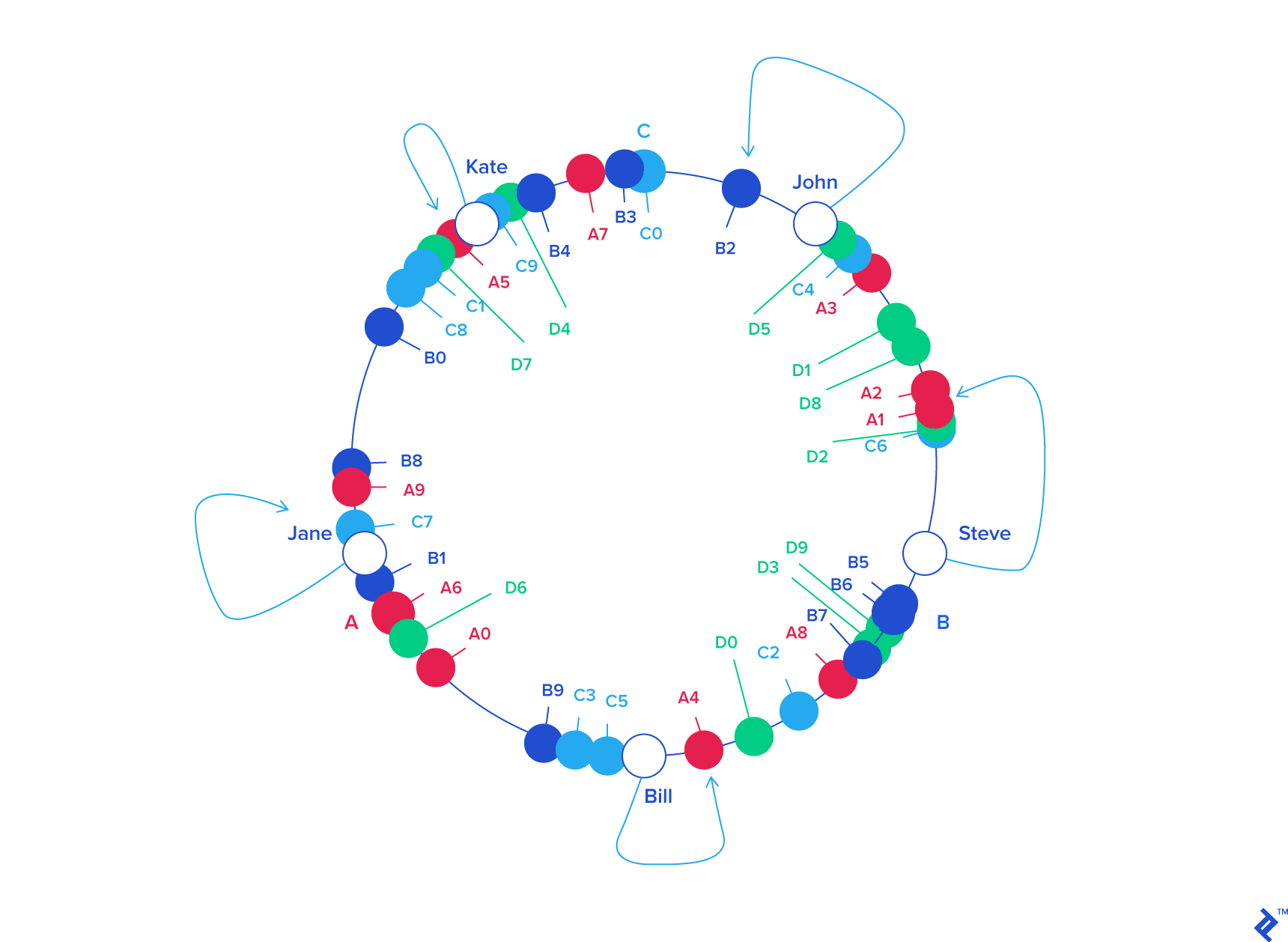
【引用】A Guide to Consistent Hashing
Consistent Hashingについて、上のブログで非常に丁寧に解説されています。すごく雑に簡単に説明してみますが、詳しく丁寧に知りたい方は上のブログを参照してください。
ハッシュの上限値と下限値を繋いで円形にし、データだけではなくnodeもランダムにハッシュ化することで、どのデータがどのnodeに属するかを決めます。こうすることで一つのnodeを取り除いたとしても、そのnodeに属していたデータを隣接するnodeに割り当てるだけで済み、他のnodeとデータを再度割り当て直す必要がありません。nodeを新しく追加した場合も同様で、隣接するnodeとデータには影響を与えますが、それ以外には影響を与えずに済みます。nodeの追加・削除時にもサービスを停止しないようにしたいわけで、そのためにはnodeを移動させるデータを最小限に止めることが求められるのですが、Consistent Hashingによってre-shardingの際に最小限のデータの移行のみで済みます。
Range ShardingとConsistent Hashing Shardingの、どちらの手法を取るかはケースバイケースです。もしもpartition keyによる範囲検索が必要であるならばRange Shardingにすることでパフォーマンスを保つことができるでしょう。一方で、partition keyによりけりですがhot spotが生まれやすいということは考慮すべきです。
Consistent Hash Shardingの場合、ハッシュ化した値に応じてShardが決まるのでhot spotが生まれにくいですが、ハッシュ関数にかけるというオーバーヘッドが追加されます。DynamoのWhite Paperでは、Partitioningのハッシュ化関数としてMD5を用いていると記載されています。node数に応じたハッシュ化関数ではないので、nodeの追加/削除を容易に行えます。
Dynamo treats both the key and the object supplied by the caller as an opaque array of bytes. It applies a MD5 hash on the key to generate a 128-bit identifier, which is used to determine the storage nodes that are responsible for serving the key.
DynamoDB

【引用】Amazon DynamoDB
DynamoDBとは
Amazon DynamoDB は、フルマネージド型の NoSQL データベースサービスで、高速で予測可能なパフォーマンスとシームレスなスケーラビリティを特長としています。DynamoDB を使用すると、分散データベースの運用とスケーリングに伴う管理作業をまかせることができるため、ハードウェアのプロビジョニング、設定と構成、レプリケーション、ソフトウェアのパッチ適用、クラスタースケーリングなどを自分で行う必要はなくなります。
【引用】Amazon DynamoDB とは
もともとNoSQLの先駆けとなったDynamoとDynamoDBを混同してしまいがちですが、DynamoDBとDynamoは仕組みが異なります。
DynamoDBは、SimpleDBというAmazonのNoSQLと、Dynamoとを組み合わせたサービスです。
We concluded that an ideal solution would combine the best parts of the original Dynamo design (incremental scalability, predictable high performance) with the best parts of SimpleDB (ease of administration of a cloud service, consistency, and a table-based data model that is richer than a pure key-value store). These architectural discussions culminated in Amazon DynamoDB, a new NoSQL service that we are excited to release today.
【引用】Amazon DynamoDB – a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications
DynamoDBはNoSQLであり、求めるのは「スケーラビリティ」だと思うので、その点について見ていきたいと思います。まずReplicationとShardingについて見た後、Auto Scalingについて見ていきます。
ReplicationとSharding
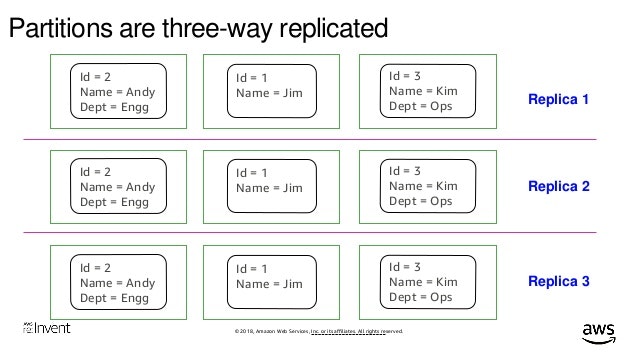
【引用】Amazon DynamoDB Deep Dive Advanced Design Patterns for DynamoDB (DAT401) - AWS reInvent 2018.pdf
各Partition(Shard)は、3箇所のAZに自動でレプリケーションされます。DynamoではLeader less Replicationであるquorumが用いられていたためDynamoDBでもそうだと勘違いしそうになるのですが、DynamoDBではSingle Leader Replicationが用いられています。
Dynamo is not available to users outside of Amazon. Confusingly, AWS offers a hosted database product called DynamoDB, which uses a completely different architecture: it is based on single-leader replication.
【引用】Designing Data-Intensive Applications
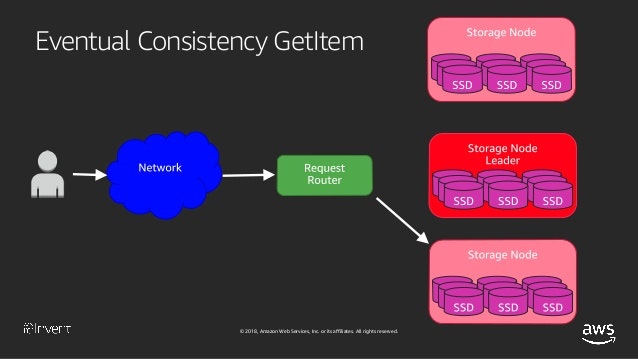
【引用】Amazon DynamoDB Under the Hood: How We Built a Hyper-Scale Database (DAT321) - AWS re:Invent 2018
nodeの前段にあるRequest Routerが、ランダムに選んだnodeに対してread requestを投げます。writeは3つのうち2つのnodeで完了しているのが分かっているので、1/3で更新されなかったnodeを選ぶ可能性があるということです。そしてもしもそのnodeにおいてvalueが更新されていなければ古い値を読み込むことになります。
DynamoDBのドキュメントにも記載されていますが、デフォルトではEventual Consistent Readsであり、Consistent Readオプションを使うことでStrongly Consistent Readsに変えることもできる仕様になっています。(この場合、ランダムにnodeを選ぶのではなくLeaderからデータが読み込まれるようです。)
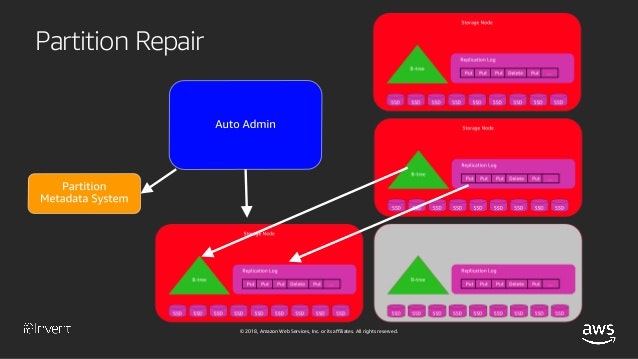
【引用】Amazon DynamoDB Under the Hood: How We Built a Hyper-Scale Database (DAT321) - AWS re:Invent 2018
Partition Metadataというコンポーネントが、どのnodeがLeaderなのかを管理しています。また、Leaderがfailした場合、新しいLeaderをFollowerの中から選ばなければならないわけですが、その場合に合意が取れていないとsplit brainになってしまいます。Leaderの選出についてはPaxosという合意形成アルゴリズムが採用されています。このLeaderの選出や、nodeがfailした時の対応などは、Auto Adminが受け持ってくれているようです。
Sharding
DynamoDBではShardingがサポートされていて、それ故にテーブルサイズに制限がありません。
テーブルのサイズ
テーブルのサイズには実用的な制限はありません。テーブルは項目数やバイト数について制限がありません。
【引用】Amazon DynamoDB のサービス、アカウント、およびテーブル制限
DynamoDBではテーブル作成時にPartition keyとSort keyを指定します。Partition keyの値をハッシュ化した値によって、そのaggregateがどのPartitionに格納されるのかが決まります。またSort keyを設定することで、そのPartition内でrange検索が可能になります。
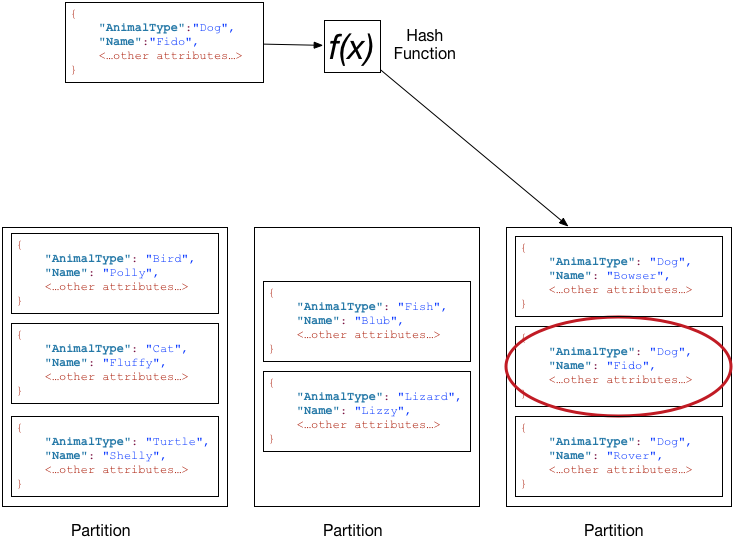
【引用】パーティションとデータ分散
先にも述べましたが、DynamoDBではConsistent Hashingを用いたShardingが行われています。hash化でPartitioningするとデータアクセス量は分散しやすいものの、やはり幾つかのデータに対するアクセスが膨大な場合、hot spotが生じます。DynamoDBでは、後に紹介するAdaptive Capacityにより、hot spotを自動で解決してくれます。
Auto Scaling
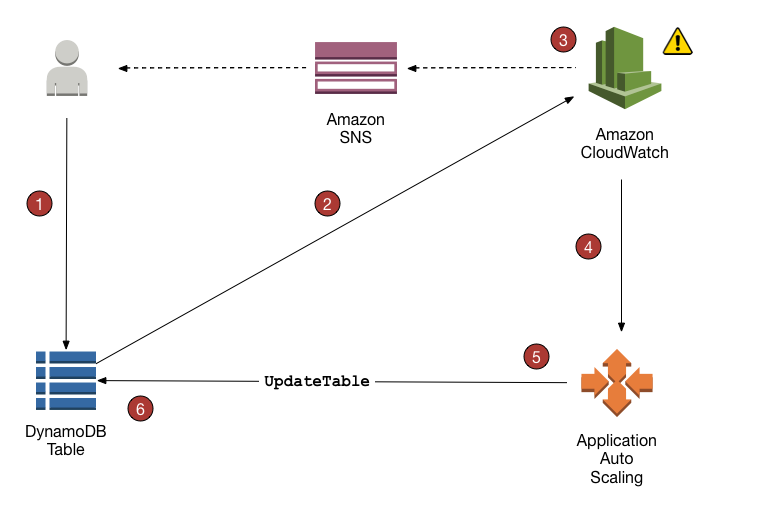
【引用】DynamoDB Auto Scaling によるスループットキャパシティーの自動管理
事前にApplication Auto Scaling ポリシーを作成しておけば、CloudWatchが監視し、トラフィックに応じてテーブルを操作するクエリを投げてくれます。Application Auto Scaling ポリシーはテーブル作成時にも指定することができます。どのくらいの読み込み/書き込みが予想されるのか、どこまでのスケーリングを許容するのかを指定します。
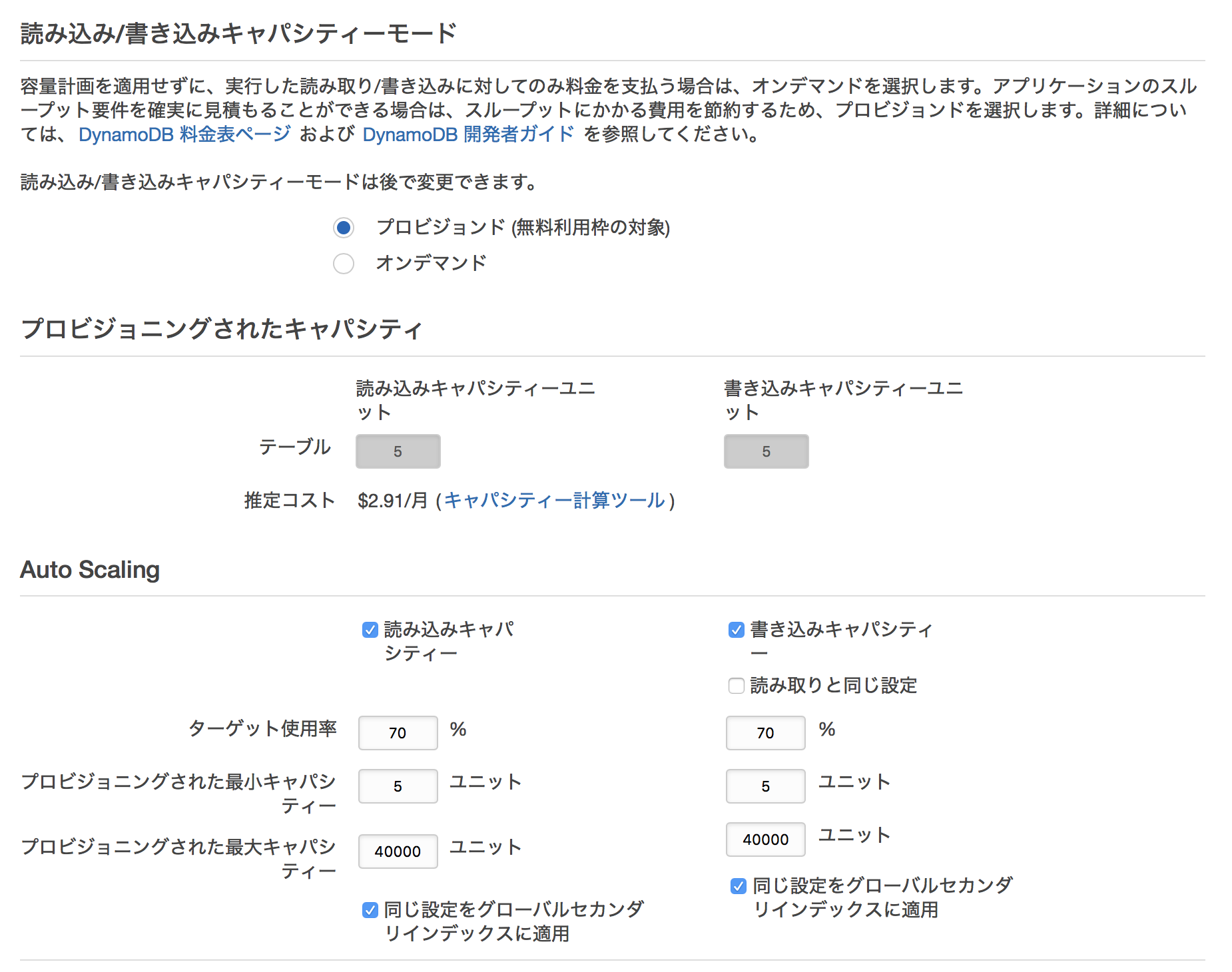 【引用】DynamoDBの管理画面
【引用】DynamoDBの管理画面
ホットパーティションに対してはアダプティブキャパシティという仕組みで対応してくれます。
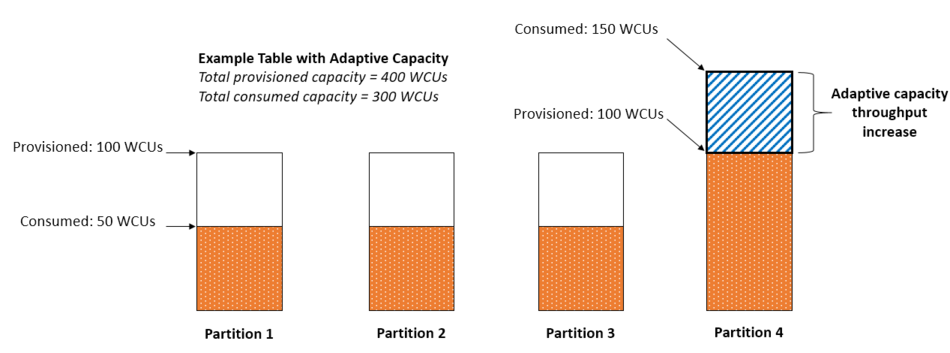 【引用】[パーティションキーを効率的に設計し、使用するためのベストプラクティス](https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/bp-partition-key-design.html#bp-partition-key-partitions-adaptive)
【引用】[パーティションキーを効率的に設計し、使用するためのベストプラクティス](https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/bp-partition-key-design.html#bp-partition-key-partitions-adaptive)
Adaptive Capacity –DynamoDB intelligently adapts to your table's unique storage needs, by scaling your table storage up by horizontally partitioning them across many servers, or down with Time To Live (TTL) that deletes items that you marked to expire. DynamoDB provides Auto Scaling, which automatically adapts your table throughput up or down in response to actual traffic to your tables and indexes. Auto Scaling is on by default for all new tables and indexes.
【引用】A Decade of Dynamo: Powering the next wave of high-performance, internet-scale applications
この機能により、トラフィックの最大値でプロビジョンしなくても済むようになります。
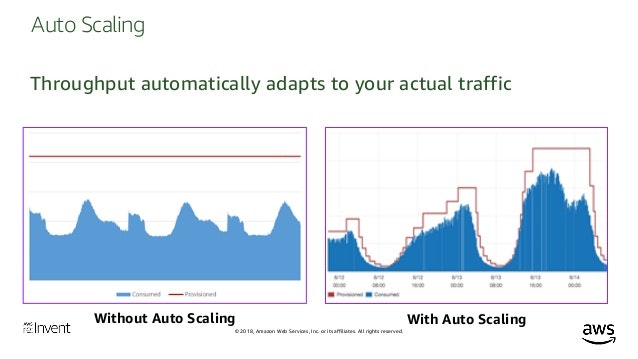
【引用】Amazon DynamoDB Deep Dive Advanced Design Patterns for DynamoDB (DAT401) - AWS reInvent 2018.pdf
Transaction
DynamoDBでは、DynamoDB Transactionの記事にあるように、transactionが新機能として追加されました。Transactionの実装によって、複数のパーティショニングとテーブル間でトランザクションが可能になったと記載されています。
以下の文言を見るに、two-phase commitを用いてTransactionが実現されているようです。リクエスト数の増加を招くため料金も上がってしまうことに注意が必要でしょう。
すべてのリクエストに対して最後の書き込みが常に利用可能であることを必須とするトランザクションアプリケーションについては、トランザクション API が最も良い選択です。トランザクションをサポートし、「オールオアナッシング」のテーブル変更を行う開発者経験をシンプルにするため、DynamoDB はトランザクションの全アイテムの、2 つの基本的な読み込みと書き込みを行います。そのひとつはトランザクションを準備するためのもので、もうひとつはトランザクションをコミットするためのものです。それぞれの読み込みと書き込みのコストは同じですが、どのトランザクション変更についても読み込みと書き込みの合計回数を増加させるため、最も高額なテーブル更新オプションと読み込み整合性モデルになります。
【引用】Amazon DynamoDB がニーズに合うかどうかを判断し、移行を計画する方法
最後に
この流れで各種NewSQLについても見ていきたかったのですが、疲れたのでまた次の機会にします。MySQLのInnoDBをNDBに変えて分散システムを実現しているMySQL Clusterがあったり。従来のRDBを再定義しSOAを導入、そしてredo Logを中心に据え置くことでパフォーマンスの向上を図ったAWS Auroraがあったり。他にもTrue Timeを導入したGoogle Spannerなど、様々なスケーラブルRDBMSが存在します。NewSQLを理解することでNoSQLについて違う視点で見れるようになると思います。
本投稿で間違っている点があれば、ご指摘いただけると嬉しいです🙇♂️
参考
Books
-
Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems
https://www.amazon.co.jp/dp/B06XPJML5D/ref=dp-kindle-redirect?_encoding=UTF8&btkr=1 -
High Performance MySQL: Optimization, Backups, and Replication
https://www.amazon.co.jp/dp/B007I8S1TY/ref=dp-kindle-redirect?_encoding=UTF8&btkr=1 -
NoSQL Distilled: A Brief Guide to the Emerging World of Polyglot Persistence
https://www.amazon.co.jp/dp/B0090J3SYW/ref=dp-kindle-redirect?_encoding=UTF8&btkr=1
Partition / Sharding
-
データの水平的、垂直的、および機能的パーティション分割
https://docs.microsoft.com/ja-jp/azure/architecture/best-practices/data-partitioning -
How Data Sharding Works in a Distributed SQL Database
https://blog.yugabyte.com/how-data-sharding-works-in-a-distributed-sql-database -
How Sharding Works
https://medium.com/@jeeyoungk/how-sharding-works-b4dec46b3f6 -
Amazon Relational Database Service を使用したシャーディング
https://aws.amazon.com/jp/blogs/news/sharding-with-amazon-relational-database-service/ -
シャーディング パターン
https://docs.microsoft.com/ja-jp/azure/architecture/patterns/sharding -
Four Data Sharding Strategies We Analyzed in Building a Distributed SQL Database
https://blog.yugabyte.com/four-data-sharding-strategies-we-analyzed-in-building-a-distributed-sql-database/
Consistency
-
なぜ「共有データの整合性」が重要なのか? ゲームにおけるサーバーサイド設計のいろは
https://logmi.jp/tech/articles/321472 -
Data Consistency Primer
https://docs.microsoft.com/ja-jp/previous-versions/msp-n-p/dn589800(v=pandp.10)?redirectedfrom=MSDN -
Cloud Datastore での強整合性と結果整合性のバランス
https://cloud.google.com/datastore/docs/articles/balancing-strong-and-eventual-consistency-with-google-cloud-datastore?hl=ja
CAP Theorem
-
CAP 定理
https://cloud.ibm.com/docs/Cloudant?topic=Cloudant-cap-theorem&locale=ja -
CAP Theorem
https://www.ibm.com/cloud/learn/cap-theorem -
Brewer’s Conjecture and the Feasibility of Consistent, Available, Partition-Tolerant Web Services
http://lpd.epfl.ch/sgilbert/pubs/BrewersConjecture-SigAct.pdf -
12年後のCAP定理: "法則"はどのように変わったか
https://www.infoq.com/jp/articles/cap-twelve-years-later-how-the-rules-have-changed/ -
Cloud Spanner と CAP 定理
https://cloud.google.com/blog/ja/products/gcp/inside-cloud-spanner-and-the-cap-theorem
NoSQL全般
-
Building Scalable Databases: Pros and Cons of Various Database Sharding Schemes
http://www.25hoursaday.com/weblog/2009/01/16/BuildingScalableDatabasesProsAndConsOfVariousDatabaseShardingSchemes.aspx -
Schemaless Data Structures
https://martinfowler.com/articles/schemaless/ -
After MongoDB support ACID, will we see the end of the era of RDBMS?
https://www.quora.com/After-MongoDB-support-ACID-will-we-see-the-end-of-the-era-of-RDBMS -
リレーショナル データ ソースとNoSQL データ
https://docs.microsoft.com/ja-jp/dotnet/architecture/cloud-native/relational-vs-nosql-data -
新しいデータベースの世界を 読み解くガイドブック
https://www.ibm.com/downloads/cas/3BAWY9RW
NoSQL Meet Up
-
Design Patterns for Distributed Non-Relational Databases
http://static.last.fm/johan/nosql-20090611/intro_nosql.pdf -
NOSQL debrief
https://blog.oskarsson.nu/2009/06/nosql-debrief.html
Dynamo / DynamoDB
-
A Decade of Dynamo: Powering the next wave of high-performance, internet-scale applications
https://www.allthingsdistributed.com/2017/10/a-decade-of-dynamo.html -
Amazon DynamoDB Under the Hood: How We Built a Hyper-Scale Database (DAT321) - AWS re:Invent 2018
https://www.slideshare.net/AmazonWebServices/amazon-dynamodb-under-the-hood-how-we-built-a-hyperscale-database-dat321-aws-reinvent-2018 -
Amazon's Dynamo
https://www.allthingsdistributed.com/2007/10/amazons_dynamo.html -
Amazon DynamoDB – a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications
https://www.allthingsdistributed.com/2012/01/amazon-dynamodb.html -
パーティションキーを効率的に設計し、使用するためのベストプラクティス
https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/bp-partition-key-design.html -
DynamoDB Auto Scaling によるスループットキャパシティーの自動管理
https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/AutoScaling.html -
New – Auto Scaling for Amazon DynamoDB
https://aws.amazon.com/jp/blogs/aws/new-auto-scaling-for-amazon-dynamodb/