業務でキャッシュに関わる部分を見る機会があり、せっかくなのでキャッシュについて理解を深めてみました。そのまとめです。
Redisとは
Redisは「REmote DIctionary Server」の略です。githubのリポジトリ→redisのリポジトリ
(最近開発者がRedisの開発から退く意向を示す投稿をしていました。そのため、Redisのリポジトリが作者の個人リポジトリからredis-ioリポジトリに移っています。)
Redisはin-memory databaseであるが故に高速アクセスが可能であり、client/serverモデルを採用しているが故に複数のクライアントからアクセスすることが可能です。またreplicationがサポートされているなどscalableであるという特徴も持っています。
本投稿では以下の2点を見ていきます。
- in-memory database
- remote (client / server)
in-memory database
in-memory databaseでは、HDDやSSDなどDiskを利用せずにメインメモリにデータを保持します。非常に時間のかかるDisk I/Oがなくなることで、パフォーマンスの改善が得られます。

【引用】Latency numbers every programmer should know
Redisはよく「in-memory databaseであり、高速である」と言われます。実際RedisはMySQLなどと比べて高速なアクセスが可能です。ここで注意が必要なのですが、MySQLと比べて、Disk I/Oがなくメモリアクセスのみでデータ取得が可能だから高速なのではありません。そうであれば、MySQLでもpage cache (buffer pool)でin-memoryにデータをキャッシュしているため、もし十分なメモリ量を持たせればDisk-basedなRDBであっても高速なアクセスが可能になるはずです。
正確には、「Diskの制約が取り除かれる」ことによって、in-memory databaseは高速なのです。Diskには様々な制約が存在します。HDDを例にとると、データの読み書きを行うためには磁気ヘッドを回す必要があります。そのため、RAMとは異なり、random I/Oではなくsequential I/Oを前提としたデータ構造でデータを扱わなければ、最適化ができません。(例えば、最適化のためにB tree indexなどが利用されます。)
つまり、Diskの制約があることによって、memoryで利用されていたデータ構造をDisk最適化されたデータ構造にencode/decodeしているのです。そのoverheadがなくなることこそが、in-memory databaseを高速アクセス可能にするのです。
使用できる最大メモリ量については、redis.confにてmaxmemoryで指定可能です。そこで指定した限界値を超えた場合のためにEviction Policyが用意されています。そのうちの1つにLRU(Least Recently Used)があります。Redisは、LRUを使うことによってメモリをあまり使いすぎないように考慮されていたりします。

【引用】Using Redis as an LRU cache
また、メモリにデータを保持しているためDurabilityは失われます。ただし、キャッシュを目的として作成されたmemcachedとは異なり、Redisでは、AOF logもしくはRDB snapshotを通して、バックアップを取ることができます。注意が必要なのが、最後にバックアップが取られてからのデータの書き込みに関しては失われてしまうことです。そのため、重要なデータについては、キャッシュDBであるRedisに対しての書き込みで済ませることは危険です。あくまで一時的なデータストアとして考えるべきであり、セッションなど失っても大丈夫なデータに限るのが得策です。
ちなみになんですが、個人的にin-memory databaseと聞くとRedisとMemcachedを思い浮かべます。ただ、List of in-memory databasesによると他にも様々なデータベースがin-memory databaseであるようです。例えばSQLiteも、in-memory databaseとして記載されています。SQLiteの公式ドキュメント(In-Memory Databases)によると、設定によってin-memory databaseとして使うことができるようです。
Client/Server Model
Redisではclient/serverモデルが採用されています。アプリケーション側でRedis client libraryを利用し、TCP/IPを通して、リクエストをRedis serverに送ります。Redis serverではRAMに保持されているデータを取得し、それをResponseとしてアプリケーションに返します。
MySQLなどもこのClient Serverモデルを採用しています。一方でSQLiteは、このClient Serverモデルと対になる構造を取っていて、SQLiteのDocumentではserverlessと呼ばれています。
以下の画像がそれらの違いを端的に表しています。SQliteは、networkを介さずにDatabaseにアクセスする手段を提供しているのです。
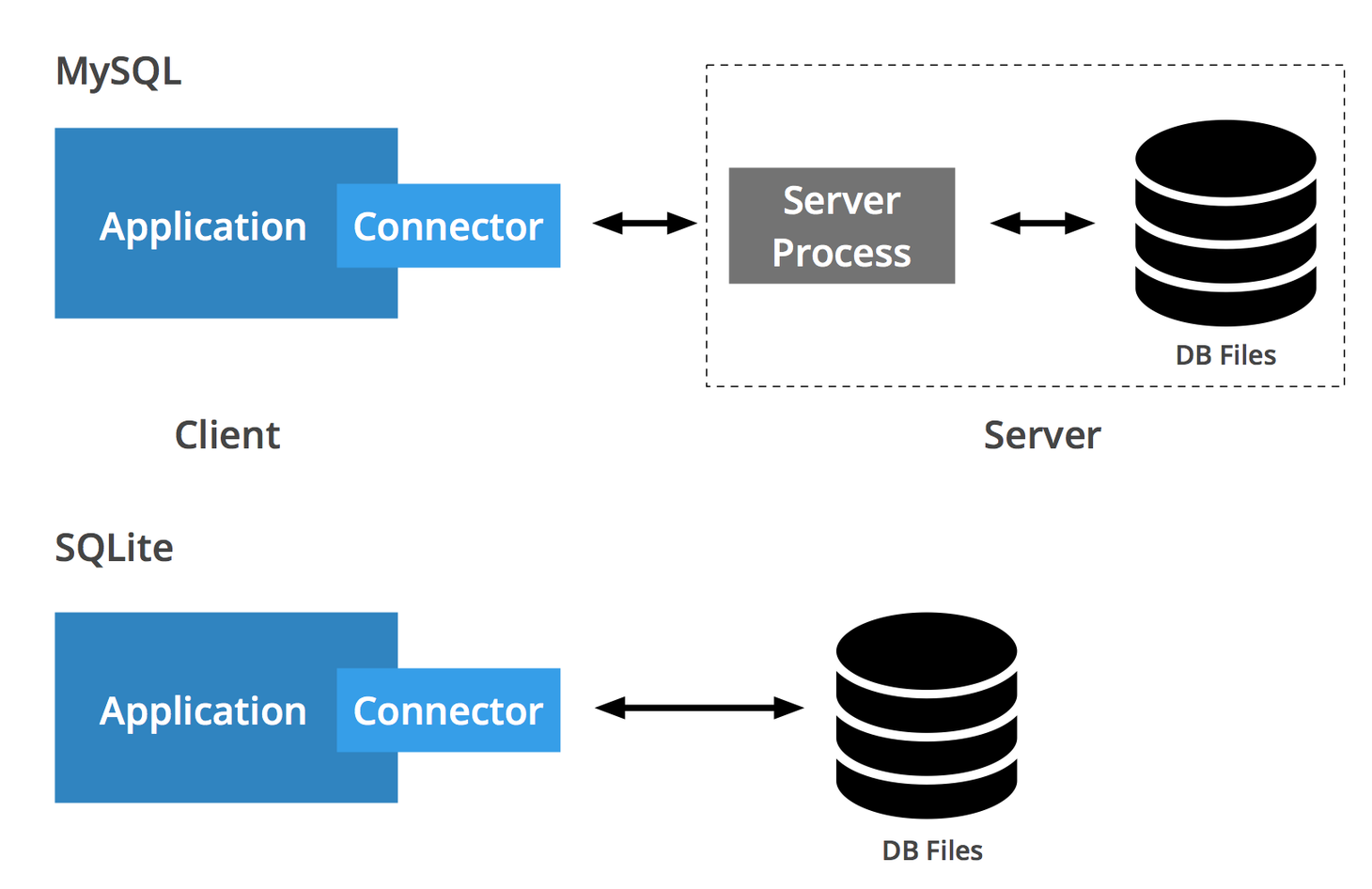
【引用】SQLite vs MySQL - Comparing 2 Popular Databases
Appropriate Uses For SQLiteでも述べられていますが、serverlessは、local cacheなどlocal data storageとして利用するのに適している一方で、scalabilityを求めるのであればclient-serverモデルを採用すべきでしょう。
Thread Model
client/serverモデルを採用するのであれば、clientからのconnectionに対してどのように対応するのかを決める必要があります。clientからのconnectionに対して、Redisはsingle thread architectureを採用しています。

Node.jsやnginxと同じくEvent Loopを利用していて、内部ではIO多重化、Thread Poolが存在します。Nginxがこのモデルを採用した理由はc10k問題に対応するためでしたが、Redisがsingle thread architectureを採用した理由はSimplicityです。RedisのMANIFESTOの6番目に「We're against complexity.」とあるように、Redisはsimplicityを重視しています。
もしもmulti thread architectureを採用するのであれば、Threadはメモリを共有するので、共有データに対するrace conditionを排除する必要が出てきます。処理の並列化を扱うと、コードは複雑になってしまうのです。
Single Threadにすることで、あるタイミングでは1つの処理しか実行されていないことになり、race conditionは発生しません。一方でSingle Threadであるため、CPU intensiveであれI/O intensiveであれ、Blockingなoperationを実行する場合には注意を払う必要があります。
Single Thread Modelでは、マルチコアを活用できなくなるというデメリットがあります。Redis is single threaded. How can I exploit multiple CPU / cores?で述べられていますが、通常Redisにおいて、CPUがボトルネックになることは無いようなので、Scalabilityを求める際にマルチコア + multi threadにするのではなく、Redis instanceを複数作成することによるRedis ClusterもしくはRedis Proxyを利用することが推奨されています。(MANIFESTOの7番目)
multi thread
memcachedはmulti thread architectureを採用しています。ただしConfiguringServerでも述べられていますが、apacheのようなモデルとは異なり、どちらかというとnginxのようなモデルを採用しています。つまり、Redisと同じくイベントループを回しているのです。
デフォルトでは4つのthreadが割り当てられていて、libeventというライブラリを使ってイベントループを回しています。そのためmulti threadといえど、c10k問題に直面するわけではありません。
一方でmulti threadモデルを採用することでrace conditionが発生することは避けられません。Memcachedではrace conditionを避けるために、optimisticなconcurrency controlであるcasコマンドが提供されていたりします。
Check And Set (or Compare And Swap). An operation that stores data, but only if no one else has updated the data since you read it last. Useful for resolving race conditions on updating cache data.
【引用】Commands
Memcachedはデータアクセスからthreadに分散させるのに対して、RedisはI/Oのみthreadに分散させているのです。
KeyDB
Redisがsingle thread modelを採用していることは賛否両論のようです。Multi-Thread版のRedis ForkであるKeyDBというデータベースも存在します。→KeyDB
KeyDB works by running the normal Redis event loop on multiple threads. Network IO, and query parsing are done concurrently. Each connection is assigned a thread on accept(). Access to the core hash table is guarded by spinlock. Because the hashtable access is extremely fast this lock has low contention. Transactions hold the lock for the duration of the EXEC command. Modules work in concert with the GIL which is only acquired when all server threads are paused. This maintains the atomicity guarantees modules expect.
【引用】A Multithreaded Fork of Redis That’s 5X Faster Than Redis
KeyDBはMulti Threadを採用しているのでrace conditionが発生します。Hash Tableのアクセスに関してspin lockを用いることで相互排他を保っているようです。KeyDB-Proでは、MVCCを導入することでsnapshot isolationを実現しているようです。
キャッシュ
キャッシュは、time-consumingな処理を一度だけ実行し、結果をメモリに保持することを指します。例えばCPU-intensiveな処理の場合、CPUを駆使してその処理を何回も繰り返したりするのは効率的ではないので、RAMに処理結果を保存してそれを使い回すようにしましょうよ、っていう感じです。
RedisやMemcachedのような、キャッシュによく使われるデータベースは、パフォーマンスを得ることを主目的として導入されることもあれば、DBに対するreadの負荷分散を主目的として導入されることもあります。
以下の画像が示すように、キャッシュは様々なレイヤで利用することができます。
 【引用】[キャッシュの概要](https://aws.amazon.com/jp/caching/)
【引用】[キャッシュの概要](https://aws.amazon.com/jp/caching/)
本投稿では、Database Cachingでの命名を参考に、以下の2つを見ていきます。
- Local Caches (client-side caching / application cache)
- Remote Caches
local caches
Redisではclient-side cacheとして紹介されています。client-sideとは、Redisにとってのclientであり、application serverであることに注意してください。
+-------------+ +----------+
| | | |
| Application | ( No chat needed ) | Database |
| | | |
+-------------+ +----------+
| Local cache |
| |
| user:1234 = |
| username |
| Alice |
+-------------+
【引用】Redis server-assisted client side caching
client-sideにキャッシュすることで、Networkを通さず、またDisk I/Oを省いた高速なデータアクセスが可能になります。
一方で、application serverと同じメモリにキャッシュを載せてしまうlocal cachesには注意が必要です。application serverを複数インスタンスにして負荷分散した際に、スケーリングに応じてapplication serverのキャッシュ間でデータの不整合が発生してしまう場合があるからです。
キャッシュがアプリケーションやキャッシュを使用しているシステムと同じノードにある場合、スケーリングがキャッシュの整合性に影響を与える場合があります。また、ローカルキャッシュを使用する場合、データを消費するローカルアプリケーションのみがローカルキャッシュを活用できます。分散キャッシュ環境では、データが複数のキャッシュサーバーにまたがる場合があるため、データのコンシューマーすべてに活用されるように、一元的な場所に保存されます。
【引用】キャッシュの概要
remote caches
Application Cacheに対して、ApplicationとDatabaseから独立したCacheを設ける方法があります。
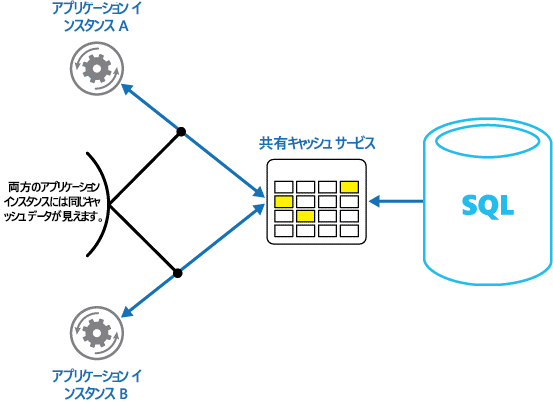
【引用】キャッシュ
Networkを通すのでデータアクセスが遅くはなるものの、Application Server複数インスタンスから同じキャッシュサーバを参照できるため、local cacheで見られるようなデータの不整合が起きません。
キャッシュ戦略
キャッシュの利用を検討するのであれば、データベースに対する書き込みの頻度は高すぎないか、また読み取りなどでキャッシュが使われる頻度は高いのかなど、様々なことを考慮する必要があります。このような「本質的にキャッシュを使うべきなのかどうか」については、ここでは置いておきます。キャッシュを使うことを前提とします。
local cacheを利用するにせよremote cacheを利用するにせよ、データベースとキャッシュデータベースとの整合性を考慮する必要があります。また、キャッシュミスによってパフォーマンスが落ちることを防ぐためには、どのデータをどのタイミングでキャッシュに保存するのか、そしていつまでキャッシュにそのデータを置くのかといったことを考慮する必要があります。そういった背景から、キャッシュを導入する際にはキャッシュ戦略、つまりキャッシュとデータベース間のシステム設計が重要になります。
ここからは代表的なキャッシュ戦略を2つ見ていきます。
Read Through / lazy caching / Cache Aside (reactive approach)

【引用】memcached を使用してサイトのパフォーマンスを高める
上の図において、キャッシュにデータが存在した場合に「Process / Format data」の過程が存在しないことにも注意したいところです。事前にprocess/formatしておいたdataをキャッシュに書き込むことで、キャッシュにデータが存在した場合にはprocess/formatせずにデータを利用できます。
read時にキャッシュミスが発生した場合、DBからデータを取得し、そのデータをキャッシュに書き込みます。そのため、キャッシュミスが起きると、readのパフォーマンスが落ちてしまうことに注意が必要です。
また、実際にリクエストが来たデータのみキャッシュされるので効率的ではあります。が、この戦略だけでは、データベースに対する更新がキャッシュと同期されないため、キャッシュの値が古くなる可能性があります。そのためキャッシュ値が古いままにならないようにTTLをうまく設定するか、もしくは次に紹介するwrite throughと組み合わせる必要があります。
write through(proactive approach)
データ更新時に、キャッシュに対してもstore/updateしようというのがwrite throughです。

【引用】memcached を使用してサイトのパフォーマンスを高める
write through戦略を採用することによって、データベースに対する書き込み時にキャッシュに対しても書き込みが行われるので、キャッシュに古い値が含まれないようになります。また、キャッシュに対する書き込みをread時ではなくwrite時に移行することができます。ユーザからすれば、write処理は時間がかかるものだと直感的に感じているため、直感に沿ったユーザビリティになります。(readは早くwriteは遅い。)
write-through方式を採用することでキャッシュも常に最新に更新されていきますが、アプリケーションロジックの組み忘れなど、キャッシュが更新されない可能性は常にあります。そういった場合のためにもTTLを常に設定しておくことは重要です。
TTLを設定するというのは簡単なのですが、実際は何秒/分でexpireさせるのか難しいと思います。データがどのくらいの頻度で変更されるのか、また、古い値を返してしまった場合のリスクなどを考慮して設定する必要があります。また、それぞれのデータのTTLを少しずらしておくことで、TTLがexpireした時のバックエンドの負荷を下げるようにすることも重要なようです。(Cache Thundering Herd問題)
参考
書籍
-
Redis in Action
https://redislabs.com/redis-in-action/ -
Database Internals: A Deep Dive into How Distributed Data Systems Work
https://www.amazon.co.jp/dp/B07XW76VHZ/ref=dp-kindle-redirect?_encoding=UTF8&btkr=1 -
Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems
https://www.amazon.co.jp/Designing-Data-Intensive-Applications-Reliable-Maintainable-ebook/dp/B06XPJML5D
Redis
-
Redisの特徴と活用方法について
https://www.slideshare.net/yujiotani16/redis-76504393 -
アルゴリズムとデータ構造から理解するRedis / Learn Redis from Internal Algorithms and Data Structures
https://speakerdeck.com/kawasy/learn-redis-from-internal-algorithms-and-data-structures -
Redis作者自身によるRedisとMemcachedの比較
https://yakst.com/ja/posts/3243
http://antirez.com/news/94 -
Dive Deep Redis ~ 入門から実装の確認まで ~
https://hayashier.com/article/dive-deep-redis-getting-started
Thread
-
Why isn't Redis designed to benefit from multi-threading?
https://www.quora.com/Why-isnt-Redis-designed-to-benefit-from-multi-threading -
How can Redis give multiple responses for multiple users with a single thread mechanism?
https://www.quora.com/How-can-Redis-give-multiple-responses-for-multiple-users-with-a-single-thread-mechanism -
Concurrency vs Event Loop vs Event Loop + Concurrency
https://medium.com/@tigranbs/concurrency-vs-event-loop-vs-event-loop-concurrency-eb542ad4067b
Memcached
KeyDB
-
KeyDB
https://keydb.dev -
MultiVersion Concurrency Control (MVCC)
https://docs.keydb.dev/docs/pro-mvcc/ -
A Multithreaded Fork of Redis That’s 5X Faster Than Redis
https://docs.keydb.dev/blog/2019/10/07/blog-post/
SQLite
-
Distinctive Features Of SQLite
https://www.sqlite.org/different.html -
In-Memory Databases
https://www.sqlite.org/inmemorydb.html
Cache
-
キャッシュ
https://docs.microsoft.com/ja-jp/azure/architecture/best-practices/caching -
Webアプリケーションにおける正しいキャッシュ戦略
https://buildersbox.corp-sansan.com/entry/2019/03/25/150000 -
Database Caching
https://aws.amazon.com/jp/caching/database-caching/ -
Caching Best Practices
https://aws.amazon.com/jp/caching/best-practices/ -
キャッシュの概要
https://aws.amazon.com/jp/caching/ -
Cache Me If You Can Minimizing Latency While Optimizing Cost Through Advanced Caching Strategies - ATC303 - re:Invent 2017
https://www.youtube.com/watch?v=WFRIivS2mpo&feature=emb_title
その他
-
Modern Main-Memory Database Systems
http://www.vldb.org/pvldb/vol9/p1609-larson.pdf -
Redis vs. Memcached: In-Memory Data Storage Systems
https://medium.com/@Alibaba_Cloud/redis-vs-memcached-in-memory-data-storage-systems-3395279b0941