Shimodasと申します。
Python初心者が躓きやすいデータ結合について復習する機会があったのでまとめます。
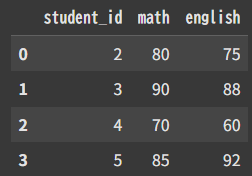
Score.csv:sc
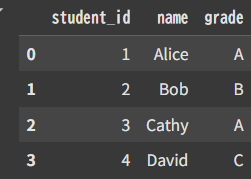
Student.csv:st
GPTに比較表を出してもらった
| 種類 | 処理内容 | 結果の特徴 | サンプル出力 |
|---|---|---|---|
| concat (axis=0: 縦結合) | データを上下にくっつける📚 | 同じ列名があれば並ぶけど、違う列は NaN 入る | id=1,2 は value NaN、id=5,6 は name NaN |
| concat (axis=1: 横結合) | データを横に並べる📒 | index 基準で結合、ズレると NaN 発生 | name と value が横並びだけど、id 5,6 は NaN |
| inner join | 共通するキーだけ取り出す✨ | 両方に存在する id のみ残る | id=3,4 のみ表示 |
| left join | 左(df1)を基準に結合💅 | df1 全部残る、df2 にないと NaN | id=1,2 が残るけど value NaN |
| right join | 右(df2)を基準に結合💎 | df2 全部残る、df1 にないと NaN | id=5,6 が残るけど name NaN |
| outer join | 両方のデータを全部含める🌍 | どっちにもない値は NaN 埋め | id=1〜6 ぜんぶ出てくる |
AI時代は1次情報こそ大事。ということで順に触れていこう。
df = pd.concat([sc,st],axis=0)
df = pd.concat([sc,st])
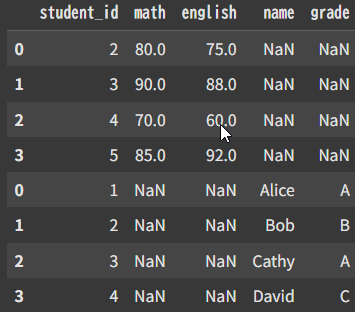
index順で縦にそのままくっつけた,って感じ?
ちなみに軸を指定しない場合は axis=0 (デフォルト設定)
df = pd.concat([sc,st],axis=1)
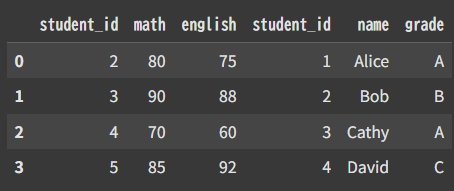
こっちはindexを軸にして横にそのままくっつけた感じかな?
concatのまとめ
| 種類 | 処理内容 | 結果の特徴 | サンプル出力 |
|---|---|---|---|
| concat (axis=0: 縦結合) | データを上下にくっつける📚 | 同じ列名があれば並ぶけど、違う列は NaN 入る | id=1,2 は value NaN、id=5,6 は name NaN |
| concat (axis=1: 横結合) | データを横に並べる📒 | index 基準で結合、ズレると NaN 発生 | name と value が横並びだけど、id 5,6 は NaN |
たしかに,student_id のカラムは1つに統合されていたっぽい。
df = pd.merge(sc,st)
df = pd.merge(sc,st,how=”inner”)
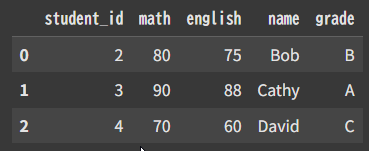
共通するカラム”student_id”を軸に結合
id共通しない部分は削除,NaN発生しない
df = pd.merge(sc,st,how=”left”)
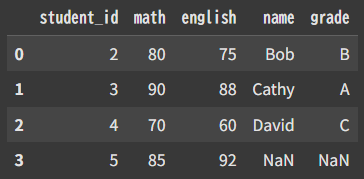
left(左) = sc : 第1引数 のこと?
leftのカラムを基準に結合 → student_id=5の人はnameとgradeがNaNに
df=pd.merge(sc,st,how=”right”)
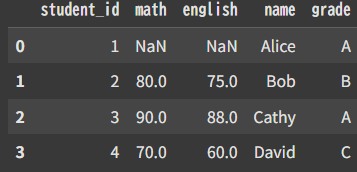
right(右) = st:第2引数のことみたい。
rightのカラムを基準に結合→Aliceちゃんは数学・英語の点数がNaNになった
df = pd.merge(sd,st,how=”outer”)
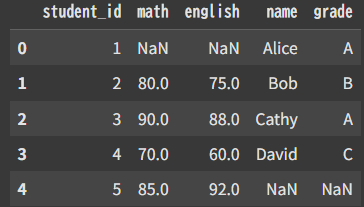
left と right 両方やってる感じ。
student_idは共通のカラムなので統一されてる。
| inner join | 共通するキーだけ取り出す✨ | 両方に存在する id のみ残る | id=3,4 のみ表示 |
|---|---|---|---|
| left join | 左(df1)を基準に結合💅 | df1 全部残る、df2 にないと NaN | id=1,2 が残るけど value NaN |
| right join | 右(df2)を基準に結合💎 | df2 全部残る、df1 にないと NaN | id=5,6 が残るけど name NaN |
| outer join | 両方のデータを全部含める🌍 | どっちにもない値は NaN 埋め | id=1〜6 ぜんぶ出てくる |
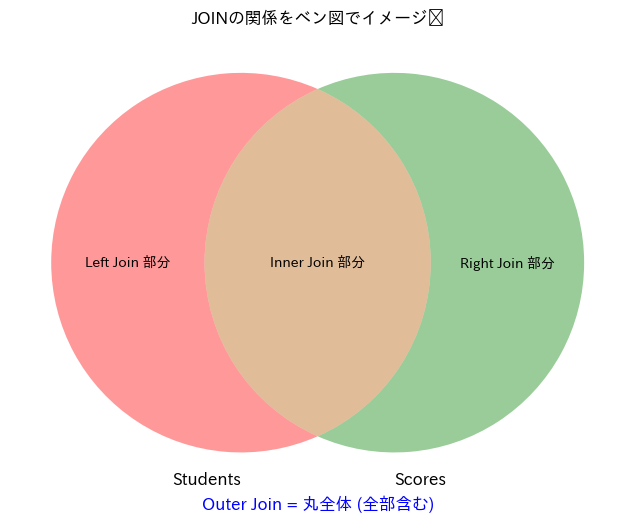
Left = A
Right = B
Inner = A∩B
Outer = A∪B
みたいな関係にできそう。
※誤った内容がある場合はご指摘いただけますと幸いです!