この記事は 防災アプリ開発 Advent Calendar 2025 の8日目の記事です。
私の日本語能力はまだ高くないため、この記事の作成にはAI翻訳を補助ツールとして使用しております。もし不自然な点や分かりにくい表現などがありましたら、誠に申し訳ございません。可能であれば、ぜひご指摘いただけますと幸いです。
はじめに
私は趣味で「EQuake」という全球地震情報ソフトウェアを開発しています。
ソフトウェアの画面描画部分には、WindowsプラットフォームのDirect2D APIを使用しています。このAPIは、1つのデバイスコンテキスト(DeviceContext)から複数の互換レンダリングターゲット(CompatibleRenderTarget)を作成することをサポートしており、それらの関係は次のように喩えられます:
デバイスコンテキスト:1枚のメインキャンバス
互換レンダリングターゲット:複数枚の下書き用紙
下書き用紙には個別に内容を描画でき、キャンバスと下書き用紙の間では、それぞれに描画された内容を相互に共有(コピー)することができます。これに基づき、ソフトウェアの画面描画部分にいくつかの最適化を施し、極端な状況でのパフォーマンス不足の問題を緩和しています。
説明を簡便にするため、以下では「画面」と「キャッシュ層」という用語で、「デバイスコンテキスト」と「互換レンダリングターゲット」をそれぞれ指すこととします。
最初の様子
まず、ソフトウェアが正常に動作している場合の単一フレームの画面を見てみましょう。

スクリーンショットからわかるように、画面には主に以下の要素が含まれています(階層は下から上へ):
- 地図層
- 観測点アイコン、P/S波アニメーションなどの動的コンテンツ
- ユーザー情報インターフェース
まず地図から考えてみます。フレームごとに地図を再描画すると、時間が非常に長くかかることが予想されます。実測の結果、i5-12400 + 内蔵GPU環境では 1 フレームあたり約20~40ms(約50~25fps)でした。他のプログラムを実行している場合、パフォーマンスはさらに低下する可能性があります。明らかに、これは好ましい方法ではありません。
そこで、まずこれを最適化することにしました。
マップの描画が大きなパフォーマンスコストを伴うなら、描画しなければいいのではないか。
以下の図に示すように、マップの描画を独立したマップキャッシュ層に移動させました。これにより、フレームごとの描画時には、マップ層の内容をキャンバスにコピーし、他の要素を描画して出力するだけでよくなります。視点の移動が発生していない状況下では、この方法により頻繁なマップ描画による大幅なパフォーマンス低下を完全に回避できます。

この最適化により、1フレームあたりの平均所要時間は7.5284ms、約132fpsとなりました。マップ描画を分離しただけで、約3.5倍のパフォーマンス向上がもたらされました。

新たな性能ホットスポット
地図層の分離により、フレームレートは大幅に向上しました。しかし、特に大規模地震発生時など、画面上に動的要素が大量に出現する極端なシナリオでは、新たなボトルネックが浮かび上がってきました。
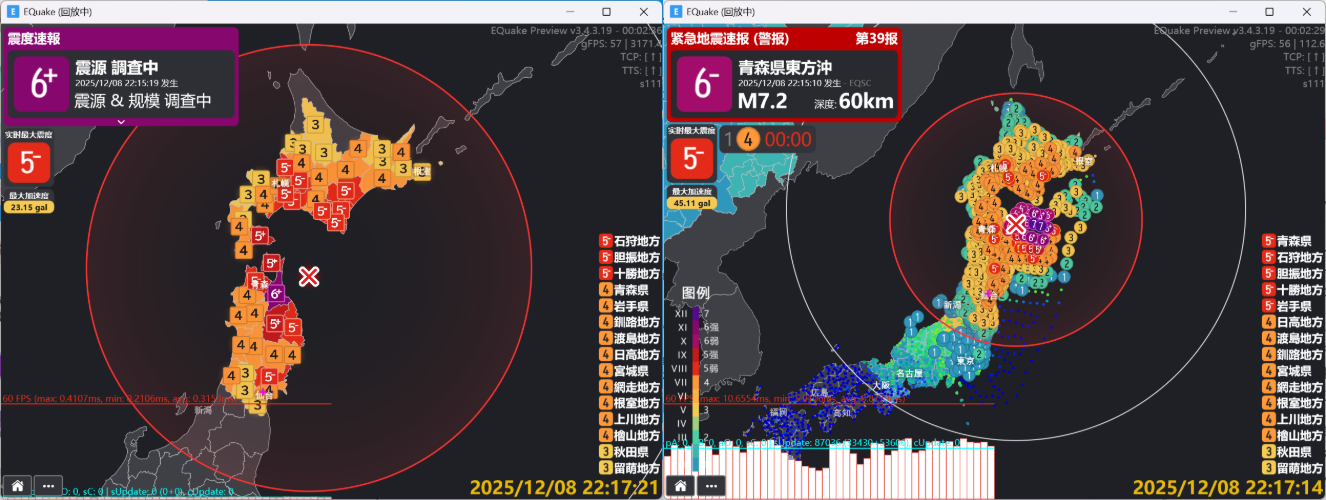
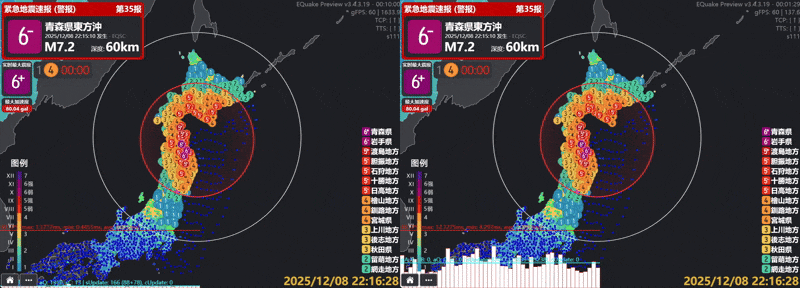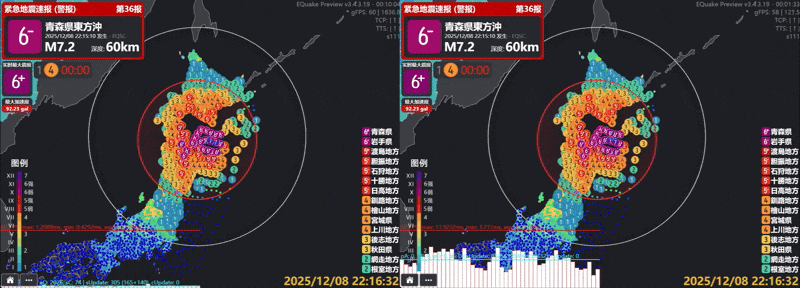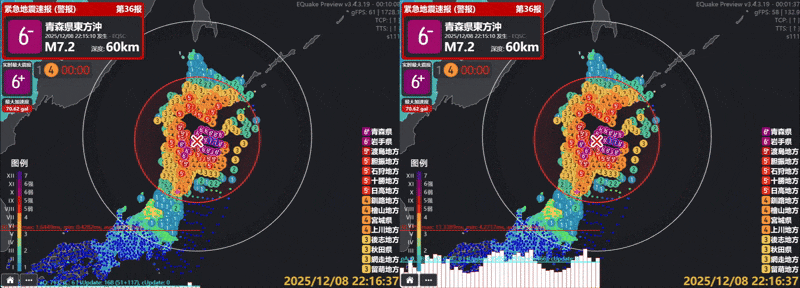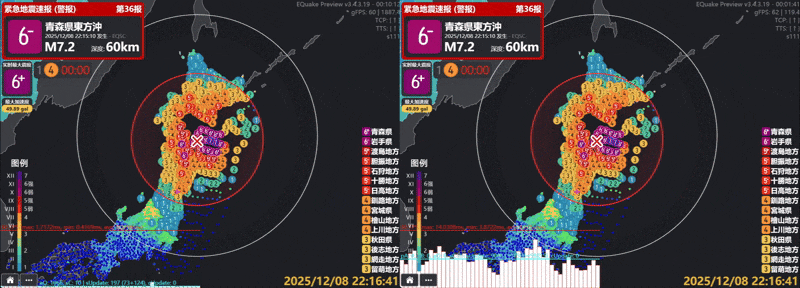
これは、12月8日に青森県東方沖で発生したMj7.5の大地震時の画面です。
左下のフレーム消費時間分析が示すように、パフォーマンスの新たな焦点、つまりボトルネックは、観測点アイコンに代表される動的コンテンツの描画部分に移りました。
これらの要素は地図とは異なり、常に変化・移動するため、マップキャッシュ層のような静的なキャッシュ手法をそのまま適用することはできません。特に地震発生時など、画面上に同時に多数の要素が描画される極端なシナリオでは、これらの動的オブジェクトの描画コストが再びパフォーマンスの足かせとなる可能性があります。
では、この新たな課題に対して、どのような最適化が考えられるでしょうか?鍵は、「変化する部分」と「変化しない部分」をさらに細かく分離し、描画の重複を徹底的に排除することにあるかもしれません。
さて、上述のように観測点アイコンは、動的要素の中でも特にパフォーマンス消費が大きく、処理が困難な代表例です。
まず、大規模な地震が発生すると、画面上に大量の観測点アイコンが出現します。先ほどの事例では、その描画回数が毎秒87,036回にも達する驚異的な数値となっており、これほど大量かつ個別に描画を実行する画像は、当然ながら膨大な処理コストを消費します。
さらに、観測点アイコンは震度の更新に合わせて内容を刷新する必要があり、隣接するアイコン同士が頻繁に重なり合う可能性もあります。そのため、単純に「更新時に一度再描画すれば済む」という問題ではなく、より複雑な描画管理が要求されるのです。
では、震度が上昇するシナリオから、その更新ロジックを具体的に考えてみましょう。
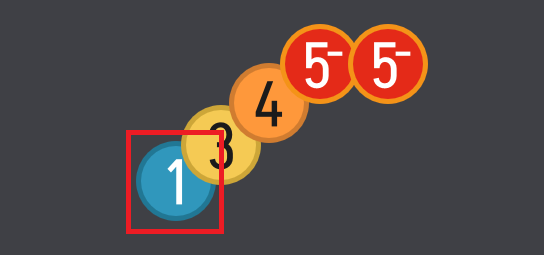
この画面において、赤枠内の「震度1」のアイコンを「震度2」に更新する場合、他にどのアイコンを連動して更新すべきでしょうか?
一般論として、震度の高いアイコンは常に低いアイコンの上に表示されることが求められます。したがって、この場合の答えは、最も右側の「5弱」アイコンを除くすべてのアイコンが再描画の対象となるということです。
具体的に説明すると、「震度1」が「震度2」に更新されると、その周囲には更新後の「震度2」よりも高い「震度3」のアイコンが重なって存在します。このため、「震度3」のアイコンも描画順を正すために再描画が必要になります。この論理が連鎖的に適用され、最終的に最も右側の「5弱」のアイコンまで更新の連鎖が及びます。ただし、その左側にある更新対象の「5弱」アイコンは、すでに同じ震度(5弱)であるため、これ以上は更新の連鎖が伝播せず、処理が終了します。
したがって、以下の結論が導き出されます。あるアイコンが更新される際には、その更新は、周辺にあってそのアイコンを覆っている(上位にある)すべての、より震度の高いアイコンに対しても同時に伝播する必要があります。 この原則は、震度が下がるもののアイコン自体が消えない場合にも同様に適用されます。
次に、震度が下がり、アイコンが描画不要となる(消える)場合について考えてみましょう。

このシナリオにおいて、赤枠内の観測点の震度が低下し、もはやアイコンの描画が必要なくなった場合、その周辺のアイコンはどのように更新されるべきでしょうか?
震度が上昇するケースとは異なり、アイコンが消去される際には、その下にある地図自体を再描画する必要が生じます。その結果、元のアイコンが占めていた領域内に存在するすべての要素が再描画の対象となります。したがって、この場合の答えは次のようになります:画面内にある全てのアイコンが、元のアイコンが占めていた領域内に存在するため、更新が必要です。
この分析に基づき、次の結論を導き出すことができます:震度が低下してアイコンの描画が不要になった場合、その更新は、そのアイコンが覆っていた(下にあった)すべてのアイコンと、そのアイコンを覆っていた(上にあった)すべてのアイコンに伝播する必要があります。
これまでの検討により、震度アイコンの更新伝播に関する二つの基本規則が明確になりました。
-
震度が上昇(または変更されても存続)する場合:更新は、対象アイコンを覆っている(上位にある)すべての、より震度の高い隣接アイコンに伝播する。
-
震度が低下してアイコンが消失する場合:更新は、そのアイコンが覆っていた(下位の)アイコンと、それを覆っていた(上位の)アイコンの両方向に伝播する。
これらの規則に基づき、効率的な更新伝播アルゴリズムの実装へと進むことができます。
実装を始める
前述の通り、観測点アイコンが更新される際、その更新を上位または下位のアイコンへと伝播させる必要があります。原理は単純ですが、これを実現するためには、まず各観測点アイコン間の「覆い被さる関係」を計算しなければなりません。
NIED(防災科学技術研究所)が提供する震度観測点は1,000地点を超えるため、ある1つの観測点を更新する際に他の全観測点を走査するような実装は、明らかに現実的ではありません。したがって、計算量を大幅に削減するための高速な空間インデックスが求められます。
幸いなことに、前段階の開発において、私はNIEDが提供する震度分布画像を16x16ピクセルの矩形領域に分割し、それぞれを「地域セル」として管理する仕組みを既に構築していました。各セルには、その地理的範囲と、隣接する他のセルの情報が予め記録されています。このセルのサイズは、ほとんどのケースで1つの観測点アイコンの描画範囲をカバーするのに十分です。
この観点から見ると、この「地域セル」のネットワークは、事前に計算済みであり、追加の演算をほとんど必要としない、非常に高速な粗略な空間インデックスとして機能します。これにより、あるアイコンからの更新影響が及ぶ可能性がある観測点を、隣接するセル内のみに絞り込むことができ、全観測点との比較という非現実的な計算を回避できるのです。
単一の地域セルのデータ構造は、例えば以下のようになります:
[71]
RECT.left=225
RECT.top=225
RECT.right=240
RECT.bottom=240
regionName=栃木県
nearbyRegionCount=8
nearbyRegionPos=72,70,77,63,78,64,76,62
このデータは、ID 71 のセルが「栃木県」に関連付けられ、72 , 70 など合計8つのセルと隣接していることを示しています。
実装における次のステップは、この空間インデックスを利用して、更新が必要な震度アイコンを効率的に見つけ出すアルゴリズムを構築することです。基本的なアプローチは以下のようになります:
- 更新が発生した震度アイコンが属する「地域セル」を特定する。
-
起点となる地域セルと、その
nearbyRegionPosに列挙された全ての隣接セルに含まれる観測点アイコンのみを対象として、前述の「更新伝播ルール」を適用し、再描画が必要なアイコンのリストを精査する。
この方法により、計算量は更新起点の周辺地域のみに限定され、1,000点を超える全観測点を扱う際のパフォーマンス問題は解消されます。
さて、この方法に基づいて計算を行うことで、各観測点には、そのアイコンと直接重なり合う他の観測点との「覆い被さる関係」 を、「上位」(この観測点を覆っているもの)と「下位」(この観測点が覆っているもの)の2つのカテゴリーに分けて記録することができます。これにより、更新処理の中で必要な関係性を迅速に参照できるようになります。
この課題が解決されると、最後に残る重要なポイントは、効率的な更新伝播アルゴリズムそのものの設計です。
「更新を伝播させる」という主問題は、「各観測点が、自身と重なり、かつ更新が必要な他の観測点に対して、それぞれ更新を伝える」というサブ問題に分解できます。このような問題構造を考えた時、最も自然に思いつくのは再帰アルゴリズムによる実装でしょう。
もともとEQuakeは「易語言」で開発されているため、その中国語のソースコードは読みづらいかもしれません。ここでは、理解を容易にするために、AIを用いてそのロジックをPythonコードに変換した例を以下に示します。
def MAP_PushStationUpdateEventAbove(object, processStartTimeStamp=None, pt=None, mpt=None, depth=None, srcPt=None, srci=None):
global CallCount_PushAbove, CallCount_ArrayOperation, japan_monitorData
if depth >= 1000:
print("[Above] 再帰深度制限に達しました!", pt, mpt)
return
if (japan_monitorData[pt]['monitor'][mpt]['isDead'] == True or
japan_monitorData[pt]['monitor'][mpt]['isUnavailable'] == True):
if srcPt == 0 or srci == 0:
return
MAP_DeleteStationFromArray(japan_monitorData[srcPt]['monitor'][srci]['sAbove'], pt, mpt)
return
if (japan_monitorData[pt]['monitor'][mpt]['lastProcessTimeStamp'] == processStartTimeStamp and
japan_monitorData[pt]['monitor'][mpt]['lastProcessIsAbove'] == True):
return
japan_monitorData[pt]['monitor'][mpt]['lastProcessIsAbove'] = True
japan_monitorData[pt]['monitor'][mpt]['lastProcessTimeStamp'] = processStartTimeStamp
sindoLevel = japan_monitorData[pt]['monitor'][mpt]['sindoLevel']
MAP_AddStationToArray(object[sindoLevel]['station'], pt, mpt)
CallCount_ArrayOperation += 1
sAbove_list = japan_monitorData[pt]['monitor'][mpt]['sAbove']
total = len(sAbove_list)
i = 0
while i < total:
ptID = sAbove_list[i]['pt']
mptID = sAbove_list[i]['mpt']
if ptID == 0 or mptID == 0:
del japan_monitorData[pt]['monitor'][mpt]['sBelow'][i]
total -= 1
continue
if japan_monitorData[ptID]['monitor'][mptID]['sindoLevel'] <= japan_monitorData[pt]['monitor'][mpt]['sindoLevel']:
del japan_monitorData[pt]['monitor'][mpt]['sAbove'][i]
total -= 1
continue
intLevel = japan_monitorData[ptID]['monitor'][mptID]['sindoLevel']
if intLevel <= 1:
i += 1
continue
MAP_AddStationToArray(object[intLevel]['station'], ptID, mptID)
CallCount_ArrayOperation += 1
MAP_PushStationUpdateEventAbove(
object, processStartTimeStamp, ptID, mptID, depth + 1, srcPt, srci
)
i += 1
return
おかげさまで、主要な部分は完成したように見えます。しかし、まだ一つ重要な問題が残されています。
それは再帰処理のリスクです。
地図の表示範囲が広い場合、単一のアイコン更新が複雑な重なり関係を介して連鎖的に伝播し、膨大な回数の再帰呼び出しを引き起こす可能性があります。EQuakeの基盤であるC/C++環境では、関数呼び出しはスタック上で実行され、深度には限界があります。仮に最大深度が1,000であっても、極端なケースではスタックオーバーフローによるクラッシュの危険性が無視できません。
そこで、より安全な手法として「反復(ループ)への変換」を検討します。これが私たちの解決策です。
反復アルゴリズムの核心は、関数呼び出しの度に新たなスタックフレームを消費するのではなく、自前の配列(またはリスト)を「待ち行列スタック」として管理する点にあります。処理の流れは以下のようになります:
- 初期化: 更新の起点となる観測点を、この「処理待ち配列」に入れます。
-
ループ処理: 配列のインデックスを先頭から順に進めながら、各ループで次の処理を行います。
- 現在のインデックスが指す観測点を「実行者」として取り出します。
- この実行者を起点に、更新を伝播させる必要のある他の観測点を特定します。
- 新たに見つかった観測点があれば、それを配列の末尾に追加します。
- 終了: 配列の最後まで処理が進めば、すべての必要な伝播が完了したことになります。
この手法により、制御を一手に握った単一のループ内で全ての更新伝播を完結させることができます。関数呼び出しの深さは常に1であり、スタックオーバーフローのリスクを根本的に排除しながら、再帰と同じ論理的結果を達成できます。
そのコードは以下の通りです:
def MAP_PushStationUpdateEventAbove(object, processStartTimeStamp=None, _pt=0, _mpt=0, _srcPt=0, _srci=0):
global japan_monitorData, CallCount_PushAbove, CallCount_ArrayOperation
PUSH_UPDATE_STACK_DEFAULT_PRE_ALLOCATE_SIZE = 16
PUSH_UPDATE_STACK_EXTEND_SIZE = 64
PUSH_UPDATE_MAX_STACK_SIZE = 1040
stack = [None] * PUSH_UPDATE_STACK_DEFAULT_PRE_ALLOCATE_SIZE
stackAllocatedSize = PUSH_UPDATE_STACK_DEFAULT_PRE_ALLOCATE_SIZE
stackSize = 1
stackPt = 0
stack[0] = {'pt': _pt, 'mpt': _mpt, 'srcPt': _srcPt, 'srci': _srci}
while stackPt < stackSize:
CallCount_PushAbove += 1
current = stack[stackPt]
pt = current['pt']
mpt = current['mpt']
srcPt = current['srcPt']
srci = current['srci']
if japan_monitorData[pt]['monitor'][mpt]['isDead'] or japan_monitorData[pt]['monitor'][mpt]['isUnavailable']:
if srcPt == 0 or srci == 0:
stackPt += 1
continue
MAP_DeleteStationFromArray(japan_monitorData[srcPt]['monitor'][srci]['sAbove'], pt, mpt)
stackPt += 1
continue
if (japan_monitorData[pt]['monitor'][mpt]['lastProcessTimeStamp'] == processStartTimeStamp and
japan_monitorData[pt]['monitor'][mpt]['lastProcessIsAbove']):
stackPt += 1
continue
japan_monitorData[pt]['monitor'][mpt]['lastProcessIsAbove'] = True
japan_monitorData[pt]['monitor'][mpt]['lastProcessTimeStamp'] = processStartTimeStamp
sindoLevel = japan_monitorData[pt]['monitor'][mpt]['sindoLevel']
MAP_AddStationToArray(object[sindoLevel]['station'], pt, mpt)
CallCount_ArrayOperation += 1
sAbove = japan_monitorData[pt]['monitor'][mpt]['sAbove']
total = len(sAbove)
i = 0
while i < total:
ptID = sAbove[i]['pt']
mptID = sAbove[i]['mpt']
if ptID == 0 or mptID == 0:
del sAbove[i]
total -= 1
continue
if japan_monitorData[ptID]['monitor'][mptID]['sindoLevel'] <= japan_monitorData[pt]['monitor'][mpt]['sindoLevel']:
del sAbove[i]
total -= 1
continue
intLevel = japan_monitorData[ptID]['monitor'][mptID]['sindoLevel']
if intLevel <= 1:
i += 1
continue
MAP_AddStationToArray(object[intLevel]['station'], ptID, mptID)
CallCount_ArrayOperation += 1
stackObject = {'pt': ptID, 'mpt': mptID, 'srcPt': pt, 'srci': mpt}
stackSize += 1
if stackSize > stackAllocatedSize:
stackAllocatedSize += PUSH_UPDATE_STACK_EXTEND_SIZE
if stackAllocatedSize > PUSH_UPDATE_MAX_STACK_SIZE:
print("[Above] Max Stack Size Reached, Abort.")
return
new_stack = [None] * stackAllocatedSize
new_stack[:len(stack)] = stack
stack = new_stack
stack[stackSize - 1] = stackObject
i += 1
stackPt += 1
こうして、従来の「地図キャッシュ層」と最終出力画面の間に、新たな階層が追加されました: 「地図+観測点アイコンキャッシュ層」 です。
これにより、毎フレームの描画処理では、このキャッシュ層上で更新が必要な観測点アイコンのみを部分更新し、その結果を出力画面(メインキャンバス)にコピーした後、最後にパフォーマンス消費の少ないその他のUI要素(ユーザー情報など)を出力画面上に直接描画するだけで済むようになりました。
実際のレイヤー構造は以下の図の通りで、左から右へ順に、地図キャッシュ層、地図+観測点アイコンキャッシュ層、出力画板(最終出力画面)となっています。
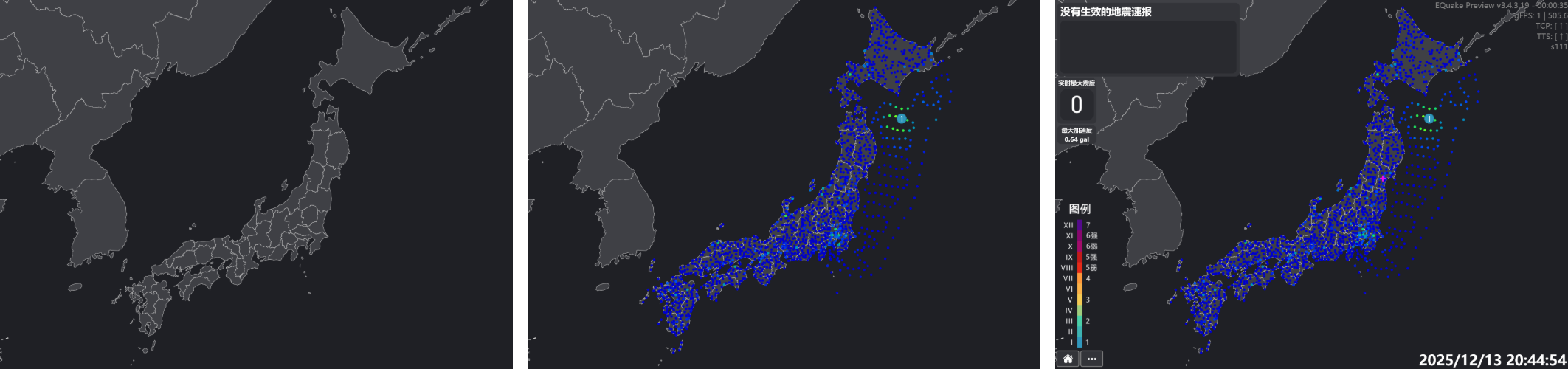
以上で、更新伝播アルゴリズムを含む一連の最適化が完成しました。それでは、その実装効果を実際にご覧いただきましょう!
結果 · あとがき
実測では、描画されるアイコン数は毎秒90,090回から162回へ(約556分の1に) 減少し、単一フレームの処理時間も約7ms(約142fps)から約0.6ms(約1660fps)へ低下しました。
二段階にわたる最適化を経て、アプリケーションの描画パフォーマンスは 当初の25~50fpsから約1660fpsへと向上 し、実に約45倍の大幅な性能改善を実現することができました。
結果はすでに非常に優秀に見えますが、実際、現在の「地域セル」に基づく空間インデックスは、16x16ピクセルという固定サイズです。より動的で最適なサイズ選択や、四叉樹(Quadtree)などのより高度な空間分割データ構造の導入は、さらなる検索効率化の道筋として考えられます。
最適化は終わりのない旅です。
以上となります。今回が初めてのこの種の記事執筆となるため、至らぬ点も多かったかと存じます。最後までお読みいただき、誠にありがとうございました。この記事が、読者の皆様の開発作業の一助となり、あるいは何らかの発見のきっかけとなれば幸いです。
また、もしご興味があれば、EQuake の GitHub リポジトリは以下になります:
改めまして、ご覧いただきありがとうございました。
何か質問やご意見がございましたら、遠慮なくコメントやリポジトリのイシューなどでお寄せください。