導入
「マテリアルズインフォマティクス」「医療インフォマティクス」「都市インフォマティクス」など、最近は “○○インフォマティクス” という言葉をよく見かけます。
では、そもそも インフォマティクス(informatics / 情報学) とは何で、いま何が起きているのでしょうか。
本記事では専門分野が違っても共通に使えるように、
- インフォマティクスの基本的な考え方
- 「○○インフォマティクス」が増える背景
- 現状の技術トレンドと課題
- 実務・研究で“再現可能に回す”ための要点
- これからの展望と、始め方
をなるべく平易に整理します。
TL;DR
- インフォマティクスは、データ・知識・プロセスを扱い、意思決定や価値創出までを再現可能な手順でつなぐ学際領域。
- 近年の変化は「AIが強くなった」だけでなく、データ基盤・運用(MLOps/LLMOps)・ガバナンスが重要になったこと。
- 「○○インフォマティクス」が増えているのは、各分野で データが増え、判断が複雑化し、再現性・説明責任が求められるようになったから。
- 成功の鍵はモデル精度だけではなく、問いの設計 → データ整備 → 評価設計 → 運用設計の一貫性。
- 入口は小さくてよいので、1つの意思決定を選び、データ→モデル→現場アクション→改善を回すこと。
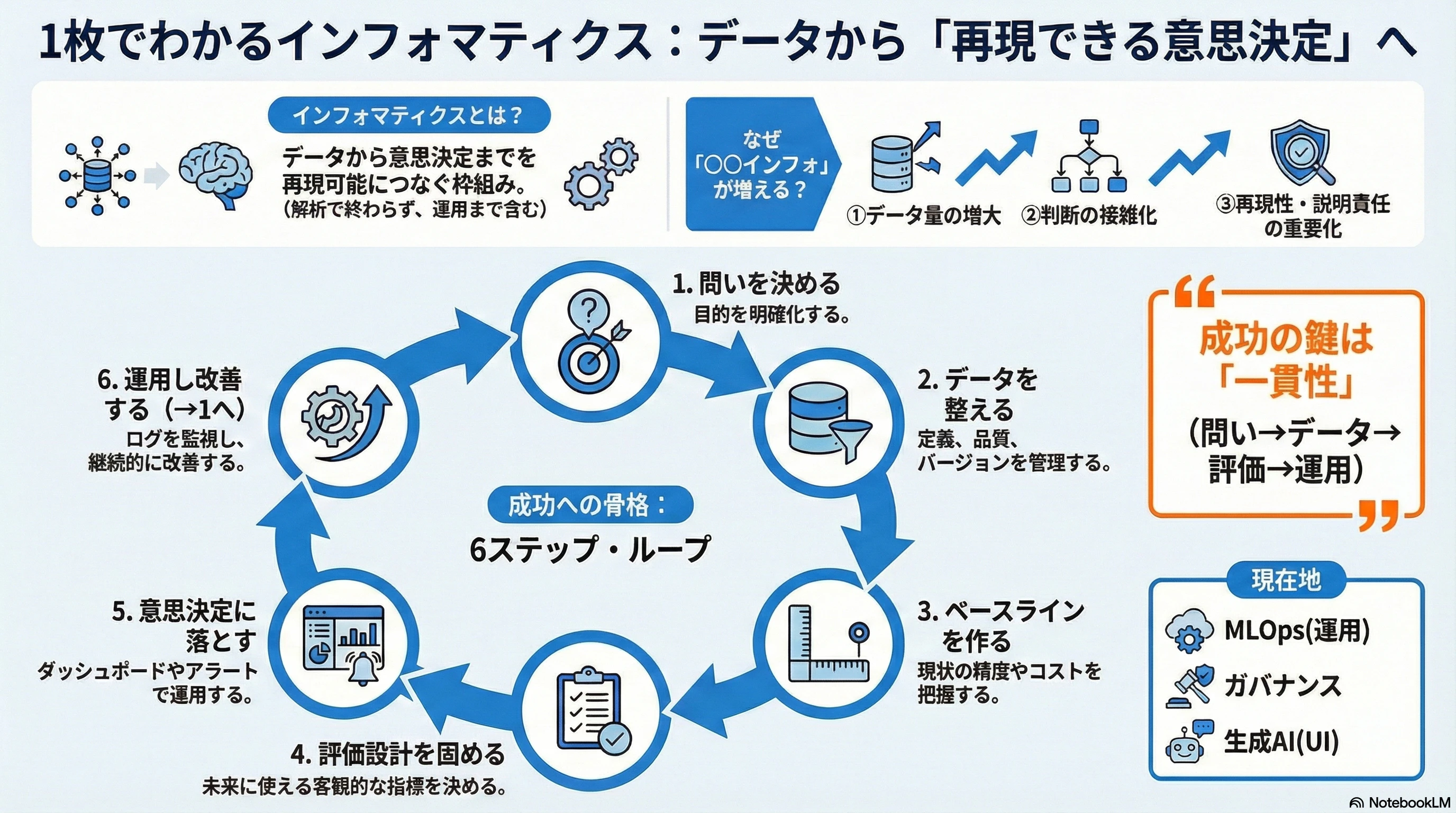
インフォマティクスとは?
一言でいうと
インフォマティクスは、
情報(データ、知識、文書、ログ)を
集め、整理し、解析し、共有し、運用し、
現実の意思決定や価値創出に結びつけるための学問・技術の総称
と捉えると分かりやすいです。
ここで重要なのは「解析して終わり」ではなく、意思決定までつなぐという点です。
つまり、インフォマティクスは「分析」だけではなく、**仕組み(システム)と運用(プロセス)**も含みます。
コンピュータサイエンス/データサイエンスとの関係
ざっくり整理すると、次のように見ると混乱が減ります。
- コンピュータサイエンス:計算そのもの、アルゴリズム、ソフトウェア、計算機の理論と実装
- データサイエンス:データからの推定・予測・可視化・統計的推論(モデルと評価が中心)
- インフォマティクス:上の両方を使いながら、ドメイン(現場)で使える形に落とし込む(データ基盤・運用・意思決定設計まで含む)
もちろん境界は重なりますが、インフォマティクスは特に 「現場に届く」ところまでを重視します。
「○○インフォマティクス」が増える理由
いま多くの分野で「○○インフォマティクス」が立ち上がる背景には、共通の構造があります。
1. データが増えた(測れるようになった)
センサー、計測技術、実験自動化、デジタル化によって、データが“取れる”分野が増えました。
取れるようになると、次は「整理・統合・品質管理」がボトルネックになります。
2. 問いが複雑化した(単一指標では決められない)
現実の意思決定は、多くの場合「精度」だけでは決まりません。
- コスト
- 安全性
- 速度
- 透明性
- 規制や倫理
- 現場の制約(人員、設備、時間)
こうした多目的の最適化やトレードオフの整理こそ、インフォマティクスが必要になる理由です。
3. 再現性と説明責任が重要になった
「誰がやっても同じ結果になる」「なぜそう判断したか説明できる」ことが、研究でも産業でも強く求められています。
ここでは、モデルよりも データ管理・評価設計・運用ログが効いてきます。
現状のトレンド
ここでは、特定分野に依らず多くのインフォマティクス領域に共通する“現在地”をまとめます。
データ基盤が主戦場になった
モデルを作る前に、まず必要なのが
- データの所在が分かる
- 定義が統一されている
- 欠損や異常が検知できる
- 更新が追跡できる
という状態です。
「良いモデルが作れない」の原因が、実は データ品質・定義の揺れ・サイロ化にあることは珍しくありません。
Notebook/Workflow の再現性(再実行できる形)が価値になった
研究でも実務でも、「結果」より 手順が資産になります。
- どのデータを使ったか
- どんな前処理をしたか
- どの指標で評価したか
- どんな条件で比較したか
これらが揃って初めて、改善や引き継ぎが可能になります。
MLOps/LLMOps(運用)への関心が急増
モデルや生成AIは「作って終わり」ではなく、運用が本番です。
- データ更新に追従できるか
- 性能劣化(ドリフト)を検知できるか
- いつ誰が何を変えたか残せるか
- 事故が起きたときに戻せるか
この運用設計が、インフォマティクスの中核テーマになっています。
生成AIの“使いどころ”が「文章生成」から「業務の橋渡し」へ
生成AIは便利ですが、重要なのは「書ける」ことよりも、
- どの情報を参照したか(根拠)
- 誰が最終判断するか(責任)
- どこまで自動化するか(境界)
を設計することです。
インフォマティクス的には、生成AIは「新しいUI」として、データや知識へのアクセスを変えつつあります。
よくある落とし穴
インフォマティクスは“全部つなぐ”分、失敗パターンも定番があります。
問いが曖昧(何を良くしたいのか分からない)
「AIを使いたい」「データ活用したい」では、プロジェクトが迷走しがちです。
まず必要なのは「どの意思決定を改善するか」です。
評価設計が弱い(現場の成功と指標がズレる)
精度が上がっても、現場の損失が減らなければ失敗です。
評価指標は、現場のコスト構造や意思決定と接続して設計する必要があります。
データの“定義”が揺れる(同じ言葉で違うものを見ている)
売上、顧客、成功、異常、危険…。
定義が揺れると、分析結果は信頼されません。最初に「定義とデータ契約」を固めるのが効きます。
実装・運用を軽視する(PoCで止まる)
PoC はできたのに実装されない典型理由は、
- 入力データが自動で入ってこない
- 誰が毎日見る/対応するか決まっていない
- 間違えたときの責任が曖昧
- 現場の業務フローに合わない
です。インフォマティクスは、ここまで含めて設計する必要があります。
インフォマティクスの基本形:データから意思決定まで
分野が違っても、成功するプロジェクトはだいたい次の流れを持っています。
-
問い(意思決定)を決める
- 例:どの候補を次に試すか、誰を優先対応するか、どこを改善するか
-
データを集めて整える
- 定義、品質、メタデータ、バージョン管理
-
ベースラインを作る
- まずは単純な方法で「現状の精度・コスト」を把握する
-
評価設計を固める
- 現場での成功指標、検証の分割(過去→未来、内挿→外挿など)
-
意思決定に落とす(UI/運用)
- ダッシュボード、アラート、提案、レビュー、承認フロー
-
運用し、改善する
- ログ、監視、再学習、継続的改善
この6ステップが、インフォマティクスの“骨格”です。
今後の展望
「学際」から「横断の基盤」へ
分野ごとの○○インフォマティクスは今後も増えますが、同時に
- データ標準
- 評価の共通フレーム
- ガバナンス
- 再現性の文化
といった「横断の基盤」がますます重要になります。
モデル中心から「意思決定設計中心」へ
モデルの性能が上がるほど、差が出るのは
- どの問いを立てたか
- どのデータをどう整えたか
- どの評価で意思決定に接続したか
- どう運用したか
という“設計”の部分です。
インフォマティクスは、ここに価値が集まっていくはずです。
これから始める人へのロードマップ
最後に、入り口を具体化しておきます。
- 自分の分野で「判断が難しい場面」を1つ選ぶ
- その判断に必要なデータを、表(列)に落とす
- 欠損・外れ値・定義の揺れを洗い出す
- まずは単純な可視化とベースラインで現状を理解する
- 評価のしかたを決める(未来に使える形か?)
- 現場の運用(誰がいつ何をするか)まで書き出す
これだけでも、インフォマティクスの“全体像”が手触りとして分かってきます。
まとめ
インフォマティクスは、データサイエンスやAIを「現場で効かせる」ために、
- 問いの設計
- データ基盤
- 評価設計
- 運用(MLOps/LLMOps)
- ガバナンス
までを含めて扱う学際領域です。
「○○インフォマティクス」という分野名の違いはあっても、
データから意思決定までを再現可能につなぐという共通テーマは変わりません。
この記事が、各インフォマティクス分野を横断して読むための“地図”になれば幸いです。