目的
- ChatRWKV を CPU で動作させる
- あわよくば GPU で動作させる
環境
- debian11
- cpu ryzen 1700
- geforce 1080 8G
- mem 64G
- m.2 1T
- swap 500G
- python 3.9
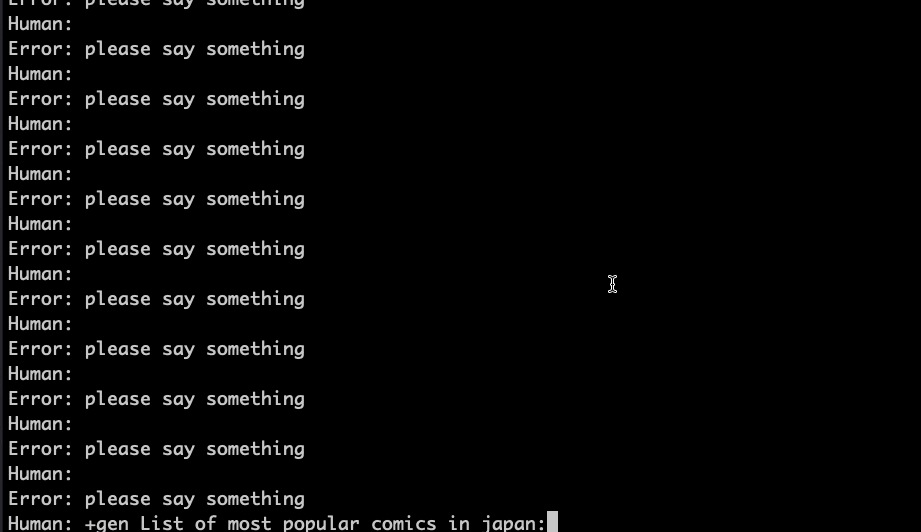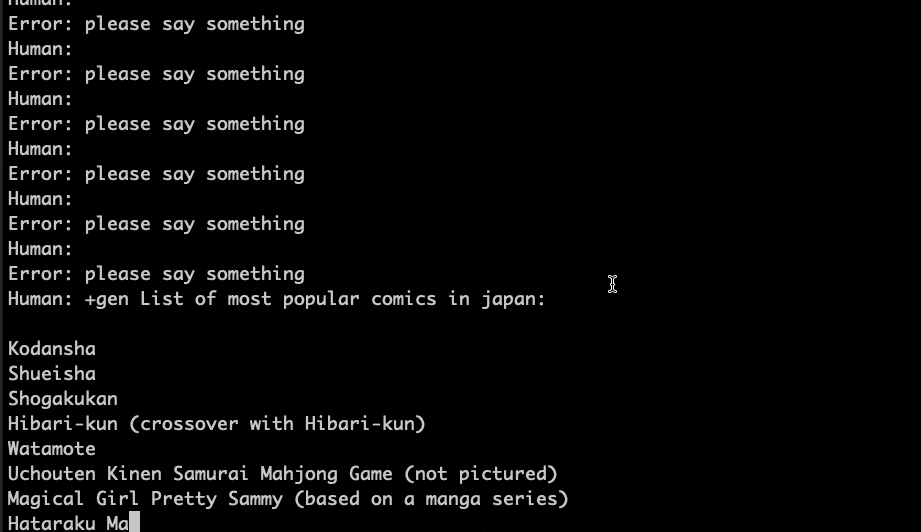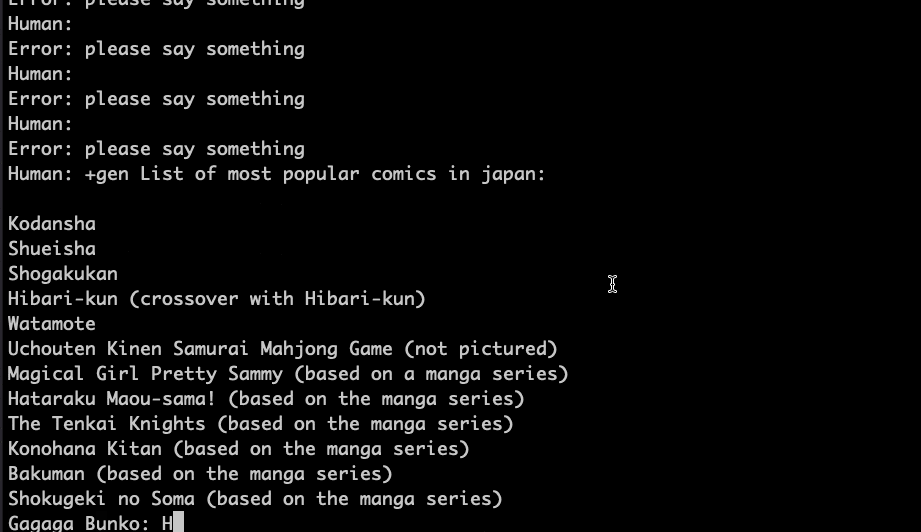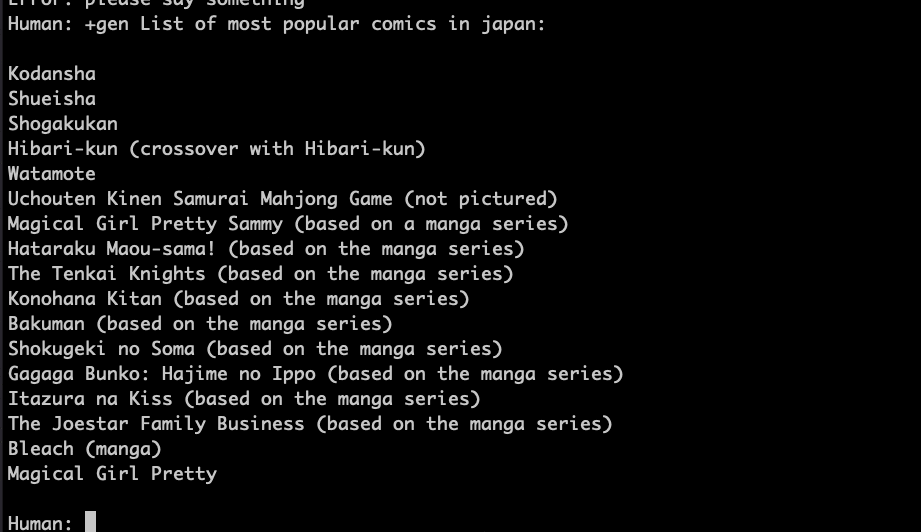
GPU での動作状態
動作速度が十分なのは見てとれると思います
RWKV について
rwkv-lm
rwkv-lm は, RNN の LLM
ChatRWKV
setup
download model
実行に用いる model を download する.
様々あるので, 後述の source に記述されている model を落とすと良いと思う.
// model size(3b, 7b, 14b など)によって必要環境が異なるので, mem 容量などと相談
install
git clone https://github.com/BlinkDL/ChatRWKV.git
cd ./ChatRWKV
pip install -r requirements.txt
pip install torch
processer 選択
cd v2
vi chat.py
# 以下のコメントを外し
args.strategy = 'cpu fp32'
# 以下をコメントする
args.strategy = 'cuda fp16'
- GPU を使用する場合は, 上記の逆の設定にする
- fp16i8 を選択すると memory 消費量が低減される
model 選択
先程落とした model file を選択する
args.MODEL_NAME = 'DLした model を記述'
実行
python chat.py
所管
- CPUでは動作がだいぶ遅い.
- 1文字数秒かかる
- まともに会話できる速度ではない
- マルチスレッドで動いていない様に見える
- GPU
- 実用的な速度で反応してくれる
- 大きな model を実行するには大量のGPU memory が必要
- 8G では, 7B model を使用できず
- 計算量
- 大量の計算資源が必要なのがわかる
- mac: m1, mem 16G
- 大容量 model は mem 不足かまともに動かない