LoRA(Low-Rank Adaptation)は、Stable Diffusionをはじめとする生成AIモデルを小規模な追加学習によってカスタマイズできる手法として広く定着しています。しかし、実際にWebUIでLoRA学習を行う場合、環境構築やGPUの要件、学習パラメータの調整など、多くの工程が必要になり、想像以上に手間がかかると感じる方も少なくありません。また、学習速度や再現性がローカル環境に大きく左右される点も課題です。
一方、PixAIではブラウザだけでLoRA学習が完結し、セットアップ不要・高速処理・安定した結果という利点があります。特に「なぜ軽量で高速に学習できるのか」という点には、UIの抽象化や学習パイプラインの最適化など、技術的な理由が存在しています。
本記事では、LoRAの技術的な仕組み、PixAIのLoRA学習が軽量・高速である理由、WebUIとの仕組み・工程の違い、実際の学習実験と結果、どのようなプロジェクトに向いているかといった内容を技術的な視点から整理し、PixAIがLoRA学習においてどのような価値を提供しているのかを解説していきます。
LoRAについて

LoRA(Low-Rank Adaptation)は、大規模な生成AIモデルに対して「モデル全体を再学習することなく、一部の重みに小さな追加行列を挿入することで効率的に微調整を行う手法」です。Stable Diffusionをはじめとする画像生成モデルで広く利用されており、数MB〜数百MBの軽量なデータで画風やキャラクター性を学習できる点が大きな特徴です。
従来のファインチューニングでは、数GB規模のモデル重みをすべて更新する必要があり、高性能GPUや長時間の学習が求められました。これに対しLoRAでは、以下の仕組みによって学習コストを大幅に削減しています。
LoRAの基本構造

LoRAは、Attention層などの重み(W)に対し、「W ≈ W₀ + B × A」という形で、低ランク行列 A(Rank × d)、B(d × Rank)を追加し、AとBだけを学習するというシステムになっています。
W₀:元のモデル(変更しない)
A / B:LoRAが学習する追加パラメータ(非常に小さい)
これにより、元モデルは保持されます。また、必要な学習量が最小限で済み、GPUメモリの消費も少なく高速になるメリットが生まれるのです。
LoRAがカバーするクリエイターニーズ
・キャラクターの特徴を学習させたい
・特定の画風やタッチを再現したい
・ブランドカラー・世界観の統一を出したい
・SDモデルの個性付けをしたい
・Webサービスで大量生成するために軽量な学習が望ましい
LoRAは上記のようなクリエイターニーズをカバーします。大規模モデルの内部構造をほぼ変えずに追加学習できるため、モデルの拡張パーツのように扱うことになります。この拡張性こそが、LoRAが普及した大きな要因です。
LoRAは技術者からの評価も高い
・軽量な追加パラメータで管理しやすい
・学習コストが低く、反復実験がしやすい
・元モデルを更新しないため安全性が高い
・実験条件を明確に再現できる
・複数LoRAを組み合わせて拡張できる
LoRAは、モデル本体を保持したまま必要な部分だけを追加学習できるため、開発・検証・運用のすべてにおいて扱いやすい構造を持っています。特に、軽量で再現性が高く、複数のLoRAを組み合わせられる拡張性は、Stable Diffusionのような大規模モデルを安全かつ効率的に運用するうえで大きなメリットとなっています。
PixAIのLoRA学習はなぜ軽量で高速?
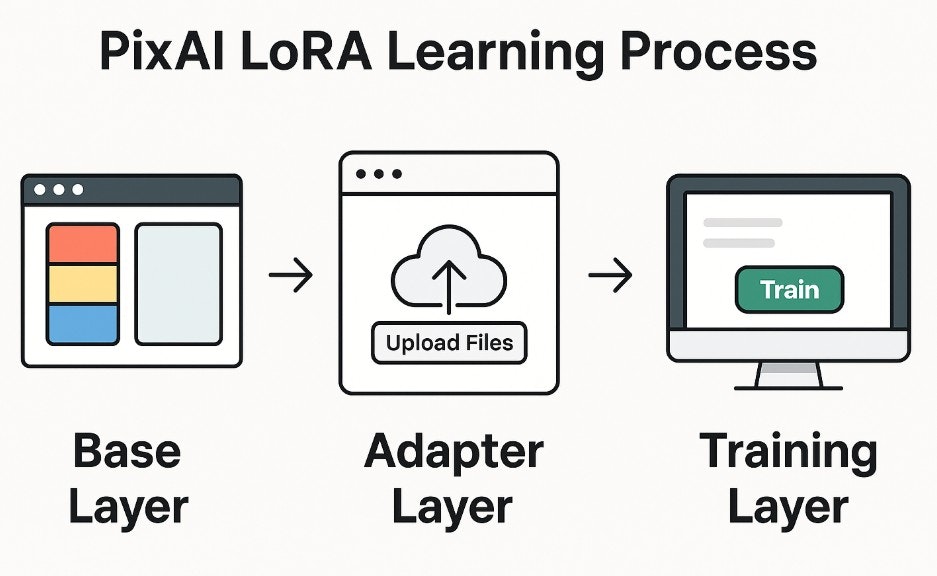
PixAIのLoRA学習は、ローカル環境のStable Diffusion WebUIよりも設定項目が少なく、学習フローが整理されているのが特徴です。これからLoRAを作ってみたいという初心者層には特におすすめです。
LoRA作成ステップごとにPixAIのLoRAプロセスを紹介します。
Base Layer:ベースモデルの選択
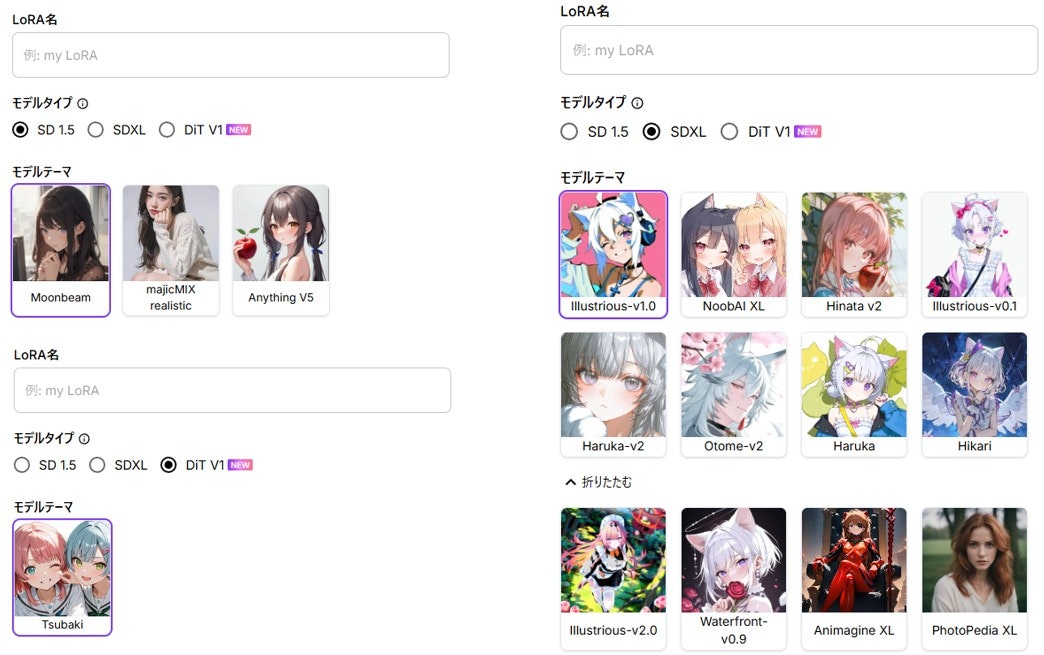
PixAIでは、LoRA学習に使用するベースモデル(モデルテーマ)を最初に選択します。SD1.5・SDXL・DiTといった複数のモデルファミリーが利用可能で、学習に適したモデルを用途に応じて選べます。
ベースモデル内部のレイヤー構造やアテンションの挙動を調整する必要はなく、ユーザーはモデルを選択するだけで学習をスタートできるのです。
一方でWebUIの場合は、LoRA学習に使うベースモデルを自分で探してダウンロードし、モデルごとの互換性も自分で判断しなければなりません。これは特に初心者にとって大きな手間です。
参照:How to Train Your Own LoRAs on PixAI
Adapter Layer:LoRAの追加パラメータ(抽象化された設定)

PixAIでLoRA作成時に必要なのは、ベースモデルの選択に加えて、画像データセットのアップロードとLoRA名やトリガーワードの指定のみです。
サービス側で適切な既定値が準備されているため、ユーザーは専門的設定を意識せずにLoRAを学習できる構造になっています。
WebUIが学習率やレイヤー設定、batchサイズや解像度調整など、多くの技術的パラメータを自分で管理する必要があるのと比べるとかなりシンプルです。
なお、PixAIは「普段自分がよく使っているモデルをベースにLoRAを学習する」ことを推奨しており、同じモデルファミリー内でLoRAを運用することで、最も安定した結果が得られると説明しています。
Training Layer:クラウドGPUによる学習

PixAIのLoRA学習はすべてクラウド側で実行され、ユーザーはブラウザから学習を操作・管理します。つまり、WebUIのように自分で高価なGPUを組まなくてもいいのです。
一方で、いくつかの注意点があるので掲載しておきます。
★解像度について
・最低:512×512以上
・SDXL系:768〜1024四方が推奨
・NG例:ぼやけた画像、小さすぎる画像、文字が多く載った画像
これは、普通の解像度の画像があれば問題ないですね。
★種類別推奨枚数(例)
・キャラLoRA:15〜30枚(DiTでは30〜100枚推奨)
・スタイルLoRA:20〜40枚
・ポーズLoRA:10〜20枚
・衣装LoRA:15〜25枚 など
また、DiT LoRAに関しては30〜100枚程度の一貫したデータセットと共通した特徴やテーマを持つ画像、解像度・サイズの統一といった条件が推奨されています。WebUIのサンプリング数とこれはそれほど大差ないです。
● 学習時間の目安
数分〜数十分程度とかなり早いです。完成予想時間が表示されます。これはクラウドで大規模な計算リソースを利用できる点が大きいです。
WebUIではハイエンドのPCの場合も、数分〜数十分と極めて早く学習が終了するケースもありますが、かなりデバイスコストがかかるため一般的ではありません。
公式はDiT LoRAについて、既存モデルより学習時間が長く、約70分程度を想定すべきしています。しかし、待ち時間の表示はあくまで目安であり、実際の学習時間とは多少ズレる可能性があります。
参照:DiT LoRA Training Guide: PixAI’s New Multi-Version Support and Dataset Reuse Features
PixAIのLoRA学習 vs WebUIの比較表

上記の比較表は、PixAIとWebUIがどのように役割分担されているかを整理したものです。PixAIは「誰でも失敗なくLoRAを作れる環境」、WebUIはより細かな「カスタマイズ性」を提供します。
特に PixAI では、環境構築・GPU管理・依存関係トラブルといった技術的負担を極力排除しており、クリエイターが制作に集中できるよう最適化されている点に特徴があります。
まとめ
本記事では、LoRAの仕組みからPixAIの学習フロー、そしてWebUIとの違いまで解説してきました。PixAIは、データセット準備・ベースモデル選択・バージョン管理・再学習といった一連の工程を統合し、クリエイターが短時間で高品質なLoRAを制作できるよう設計されています。
一方、WebUIは細かいパラメータ調整やローカル制御に向いており、研究用途や独自実験で大きな力を発揮します。
LoRA制作では、「どこに時間を使いたいか」が最も重要になります。キャラクター再現やスタイル化を効率よく進めたいならPixAI、学習アルゴリズムそのものを深く調整したいならWebUI──このように目的別で選ぶことで、制作の成果と満足度が大きく変わります。
ぜひ、自分の制作スタイルに最適な環境を選び、より柔軟で創造的なLoRA制作を楽しんでください。