目次
はじめに
個人でどこまでできるのか?―金融機械学習への挑戦
- 「bot開発は度外視して純粋な興味から『ファイナンス機械学習』の理論をシステムに組み込みたい?」
- 「既存のオープンソースツールでは、なぜ満足できなかったのか?」
- 「個人でどこまで本格的な金融定量分析システムを構築することができるのか?」
これらの根本的な問いに答えるため、私はWeek 1 ~ Week 14というフェーズを設定して、書籍『ファイナンス機械学習』(以下、AFML)を参考にその理論を実装した金融定量分析ツール「qat(quant-analytics-tool)」の開発に挑戦しました。
この記事の前置き
この記事では、単なる技術紹介やライブラリの使い方の解説はしていません。また、金融取引の自動売買Bot開発を目的としたものでもありません。あくまで、AFMLの理論を参考にした金融定量分析システムを私が個人でゼロから構築するまでのリアルな開発記録として書き記したものです。
※ 私は現役エンジニアでもなければ金融工学の専門家でもないため、理論や実装におかしな箇所もあるかもしれませんが大目に見てもらえたらと思います。
開発の動機と背景
金融機械学習分野の現状
金融機械学習の分野は、理論と実装の間に大きなギャップが存在しています。学術論文では多くの素晴らしい手法が提案されているものの、実際に動作するシステムとして実装するには、以下のような課題があります。
-
理論と実装の乖離
論文の数式を実際のコードに落とし込む際の複雑さ -
データ品質の問題
金融データ特有のノイズ、欠損、異常値への対処 -
時系列特有の落とし穴
Look-ahead bias、Data leakageの防止 -
スケーラビリティの課題
研究レベルのコードを本番レベルに引き上げる困難さ -
統合性の欠如
データ取得からモデル運用まで一貫したワークフローの構築
個人開発の可能性
一方で、以下のような理由から現在の技術環境は私のような個人開発者にとって追い風となっています。
-
オープンソースエコシステムの充実
Python、scikit-learn、TensorFlow等の高品質ライブラリ -
クラウドコンピューティングの普及
個人でも高性能な計算リソースにアクセス可能 -
金融データAPIの民主化
Yahoo Finance、Alpha Vantage等による無料・低コストデータ提供 -
学習リソースの豊富さ
書籍、論文、オンラインコース、技術コミュニティ、alpaXiv -
AIによるコーディング支援
GitHub Copilot, Cursor, Claude Code, Codexなど
これらの要因から、「個人でも本格的に金融定量分析システムを構築できる時代」が到来していると感じ、取り組んでみることにしました。
qat(quant-analytics-tool)開発の全体像
プロジェクトの規模と野心
qatの開発は、単純な価格予測ツールの作成ではなく、以下の要素を統合した金融定量分析プラットフォームの構築を目指しました。
# プロジェクトの目標
- データ基盤: 複数ソースからの統一品質データ取得
- 特徴量エンジニアリング: 技術指標からAFML高度特徴量まで
- 機械学習: 従来手法から深層学習まで幅広いモデル対応
- バックテスト: Look-ahead biasを完全に排除した厳密なテスト
- リスク管理: VaR、ポートフォリオ最適化、ストレステスト
- MLOps: 研究段階から運用段階への完全な橋渡し
- UI/UX: 直感的で高機能なWebインターフェース
- 品質保証: 350以上のテストケースによる包括的検証
開発期間中の学習曲線
まだまだ開発中ではありますが、開発期間は単なる実装作業ではなく、金融工学、機械学習、ソフトウェア工学の三つの分野を理解しながら、それらを統合する学習プロセスでもありました。
社会人学生として専攻で統計学や金融論を学んだり、独学ながら普段から日常的に機械学習に触れてはいますがそれぞれ専門性の異なる分野を横断的に理解しながら統合するのにはかなり苦労しています。
Week 1-3(基盤構築期)
- 金融データの特殊性理解
- データ品質管理の重要性認識
- 基本的な分析機能の実装
Week 4-6(特徴量工程期)
- 技術指標の理論と実装
- AFML特徴量の深い理解
- パイプライン自動化の設計
Week 7-9(機械学習期)
- 従来手法から最新手法まで幅広い実装
- 金融データ特有の評価指標理解
- ハイパーパラメータ最適化の工夫
Week 10-11(バックテスト期)
- Look-ahead bias防止の厳密実装
- イベント駆動型バックテストエンジン構築
- パフォーマンス指標の包括的計算
Week 12-13(リスク・統合期)
- リスク管理手法の実装
- システム全体の統合とテスト
- MLOpsパイプラインの構築
この記事から得られるもの
この開発記録を通じて、以下のような価値を提供したいと考えています。少しでも参考になるものがあれば嬉しく思います。
技術面での提供価値
-
実装可能な設計思想
理論を実際に動作するシステムに落とし込む方法 -
品質保証のベストプラクティス
350テストケースの設計思想と実装方法 -
金融データ特有の課題
Look-ahead bias、Data leakage等への具体的対処法 -
MLOpsの実践
教育・研究コードを本番レベルに引き上げる手法の試行錯誤 -
アーキテクチャ設計
スケーラブルで保守性の高いシステム設計のための試行錯誤
戦略面での提供価値
-
個人開発の可能性
一人でもAFML理論を実装したシステム構築が可能であることの実証 -
技術選択の指針
各段階での技術選択の理由と代替案の比較 -
開発プロセス
week13まで(バックエンド部分のみ)の開発期間内での効率的な開発手法 -
課題と解決策
実際に直面した問題とその創意工夫による解決法
学習面での提供価値
-
金融工学の実践的理解
AFML理論の実装を通じて深く理解する方法 -
機械学習の応用
金融分野特有の機械学習応用のノウハウ -
継続学習
技術の急速な進歩に対応するための学習戦略
記事の読み方
この記事は、読者の関心と技術レベルに応じて、以下のような読み方ができるのではと想像しながら書いたつもりです。
基本的には独学中の個人開発者に向けた内容を想定して書いています。
金融工学初心者の方
- 「はじめに」と「なぜ車輪の再発明に挑んだのか」でモチベーションを理解
- 「qatシステム全体像」でプロジェクトの全体像を把握
- 技術詳細は概要レベルで読み、興味のある部分を深堀り
個人開発者
- 開発プロセスと技術選択の判断基準に注目
- 限られたリソースでの品質確保手法を学習
- 今後の展望から実用化の可能性を検討
共通(余裕があれば)
- 「技術的深掘り」を重点的に読解
- AFMLの実装詳細とMLOpsの実践に注目
- コードスニペットと設計思想の関連性を理解
- 全体を通読し、理論と実装の統合方法に注目
- バックテストとリスク管理の実装詳細を重点学習
- 実装成果の数値的評価を自身のプロジェクトと比較
記事の前提となる知識
また、この記事では以下の前提知識を想定しています。私もまだまだ勉強中なので至らぬ点はご容赦ください。
必須知識
- Python プログラミングの基礎
- 機械学習の基本的な概念(教師あり学習、交差検証等)
- 金融市場の基本的な仕組み
推奨知識
- pandas、NumPy、scikit-learn の使用経験
- 時系列分析の基礎知識
- バックテストの概念
- Streamlit または類似のWebフレームワーク経験
あると理想的な知識
- Advances in Financial Machine Learning (AFML) の理論
- MLOps・DevOps の知識
- 金融工学に関する基礎的な知識
- ソフトウェアアーキテクチャ設計に関する知識
注意事項と免責事項
学習目的に関して
この記事およびqatプロジェクトは、教育・学習目的で開発しています。実際の投資判断や取引に使用する場合は、十分な検証の上、自己責任で対処してください。
コードの品質について
紹介するコードや内容は、現在までの限られた期間での開発成果です。プロダクション環境での使用には、更なる最適化、セキュリティ強化、エラーハンドリングの改善が必要な場合があります。
データの制約について
qatは主に無料のデータソース(Yahoo Finance、Alpha Vantage等)を使用しており、リアルタイムデータや高頻度取引には対応していません。
qatシステム全体像
プロジェクト概要と開発動機
qatは金融定量分析における統合プラットフォームとして、AFML(Advances in Financial Machine Learning)理論の実践的実装を中核に据えて設計された個人開発プロジェクトです。「個人でどこまで本格的な金融機械学習システムを構築できるのか?」という自分の興味関心の赴くままに、実験的にプロトタイプの開発を進めました。
システムアーキテクチャ(4層構造設計)
qatは、金融データの特殊性と機械学習ワークフローの複雑さを考慮した4層アーキテクチャを採用しています。各層は明確な責任分離により、保守性と拡張性を確保しています。
各層の設計思想
Frontend Layer - 直感的な分析体験の提供
- Streamlitベースの高速プロトタイピング
- インタラクティブな金融チャートと分析結果表示
- リアルタイムパラメータ調整による即座の結果確認
Business Logic Layer - データ品質とワークフロー管理
- 金融データ特有の品質管理(欠損値、異常値、データ整合性チェック)
- マルチレベルキャッシングによる応答性能最適化
- 分析ワークフローの自動化と結果追跡
AI/ML Processing Layer - AFML理論の実装中核
- Look-ahead bias完全排除のPurged Cross-Validation
- Fractional Differentiation、Triple Barrier Labelingの実装
- 従来ML〜深層学習まで幅広いモデル対応
Data Layer - 一貫性とトレーサビリティの確保
- SQLiteベースの軽量でポータブルなデータ管理
- MLOpsモデルレジストリによる完全なモデルライフサイクル管理
- 分析結果のバージョニングと再現性保証
AFML理論実装戦略
qatの最大の特徴は、Marcos López de Pradoの「Advances in Financial Machine Learning」理論を実装レベルまで具現化に挑戦した点です。
単なる論文や書籍の実装ではなく、現実的な制約の中でいかに理論を実用化するかに焦点を当てました。
金融時系列データ特有課題とqat解決アプローチ
Fractional Differentiation
非定常性と記憶の最適バランス
従来の整数次差分では情報損失が大きく、金融時系列の重要な長期記憶が失われる問題がありました。qatでは分数次差分により、定常性達成と予測有用情報の保持を両立しました。
実装の技術的詳細
# Fractional Differentiation Implementation
数学的基礎
├── Grünwald-Letnikov定義採用
├── 分数次数d∈[0,1]の最適化
├── 統計的定常性検定による自動調整
└── 計算効率化のための窓幅最適化
自動パラメータ最適化
├── ADF(Augmented Dickey-Fuller)検定
├── KPSS(Kwiatkowski-Phillips-Schmidt-Shin)検定
├── クロスバリデーション性能との多目的最適化
└── 銘柄・期間別パラメータ保存
リポジトリ構造と実装状況(2025年9月17日現在)
プロジェクト全体構造
qatプロジェクトは、機能別に以下のようなディレクトリ構造を採用しています。
開発期間を通じて段階的に更新しているため、現在では以下のような構成となっています。
quant-analytics-tool/
├── 📁 src/ # メインソースコード
│ ├── analysis/ # 金融分析モジュール
│ ├── backtesting/ # バックテストエンジン
│ ├── data/ # データ取得・管理
│ ├── features/ # 特徴量エンジニアリング
│ ├── models/ # 機械学習モデル
│ │ ├── traditional/ # 従来ML手法
│ │ ├── deep_learning/ # 深層学習モデル
│ │ ├── advanced/ # AFML特殊手法
│ │ └── pipeline/ # MLパイプライン
│ ├── risk/ # リスク管理システム
│ └── utils/ # 共通ユーティリティ
├── 📁 streamlit_app/ # UI・Webアプリ
│ ├── components/ # 再利用可能コンポーネント
│ ├── pages/ # 機能別ページ
│ ├── utils/ # UI固有ユーティリティ
│ └── main.py # アプリケーションエントリポイント
├── 📁 tests/ # テストスイート(733テスト)
│ ├── analysis/ # 分析機能テスト
│ ├── backtesting/ # バックテストテスト
│ ├── features/ # 特徴量テスト
│ ├── models/ # モデルテスト
│ ├── risk/ # リスクテスト
│ └── streamlit_app/ # UI テスト
├── 📁 models/ # モデル成果物管理
│ ├── registry/ # MLOpsモデル登録
│ └── trained/ # 訓練済みモデル
├── 📁 data/ # データセット
├── 📁 docs/ # 技術ドキュメント
├── 📁 examples/ # 使用例・サンプル
├── 📁 implementation_records/ # 開発記録
│ └── Qiita/ # この記事含む
├── 📁 deployments/ # デプロイメント管理
├── 📄 demo_*.py # 各週のデモファイル
├── 📄 requirements.txt # 依存関係
├── 📄 README.md # プロジェクト概要
└── 📄 SPECIFICATION.md # 技術仕様書
開発段階別の成長履歴
プロジェクト構造は開発段階に応じて更新してきました。
システムのUI外観
UIのほんの一部ですが、システムの外観は以下のような感じになっています。
メインページ
データ取得
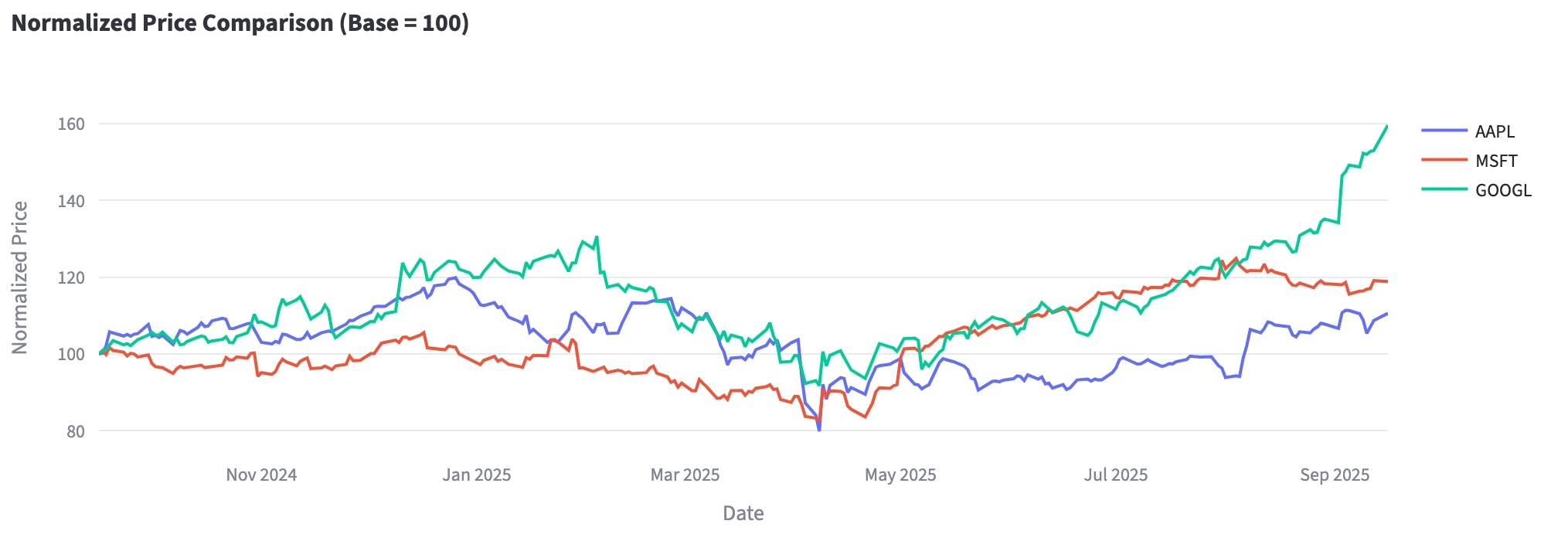
特徴量エンジニアリング

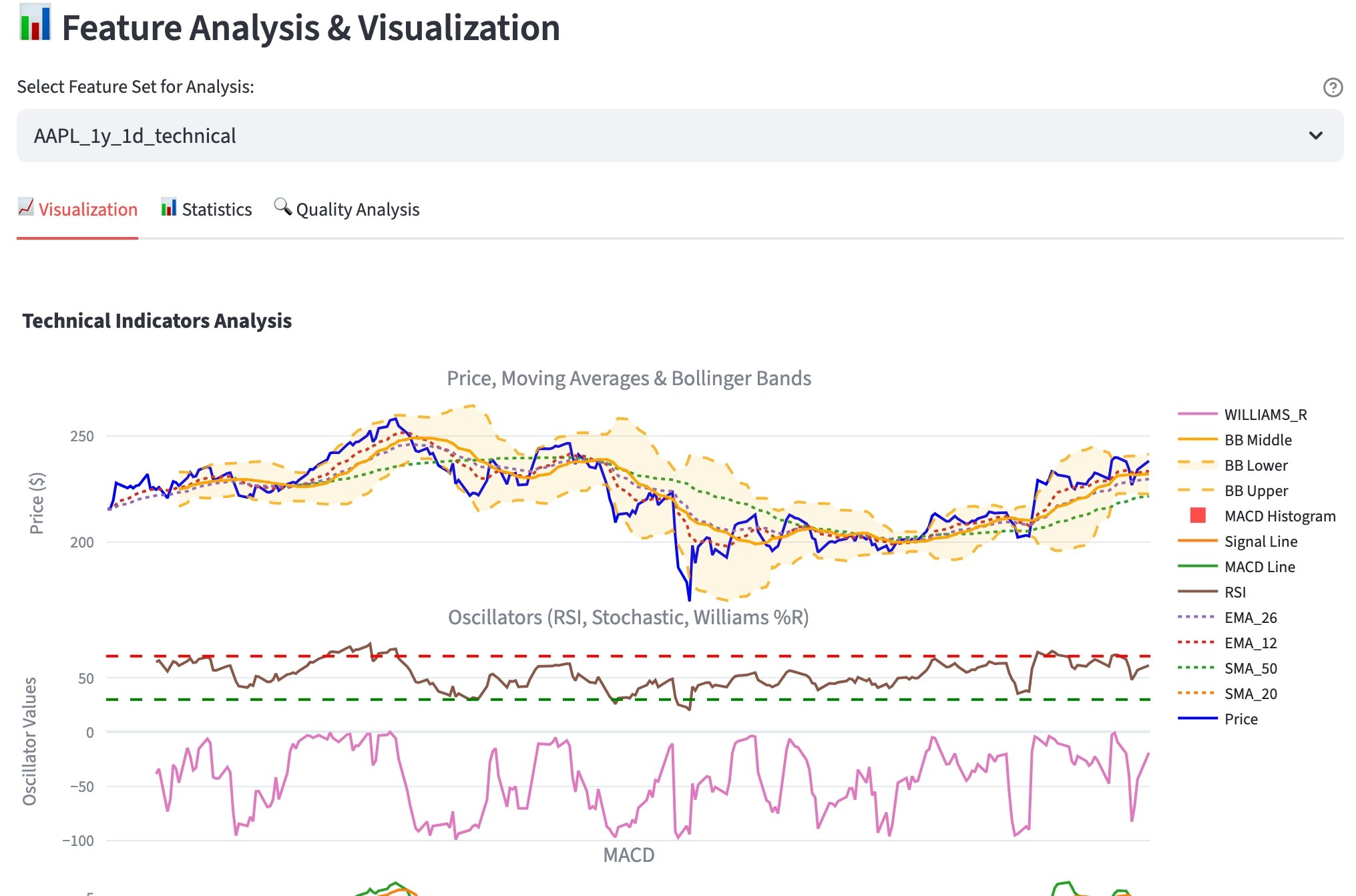
モデル選択

モデル学習
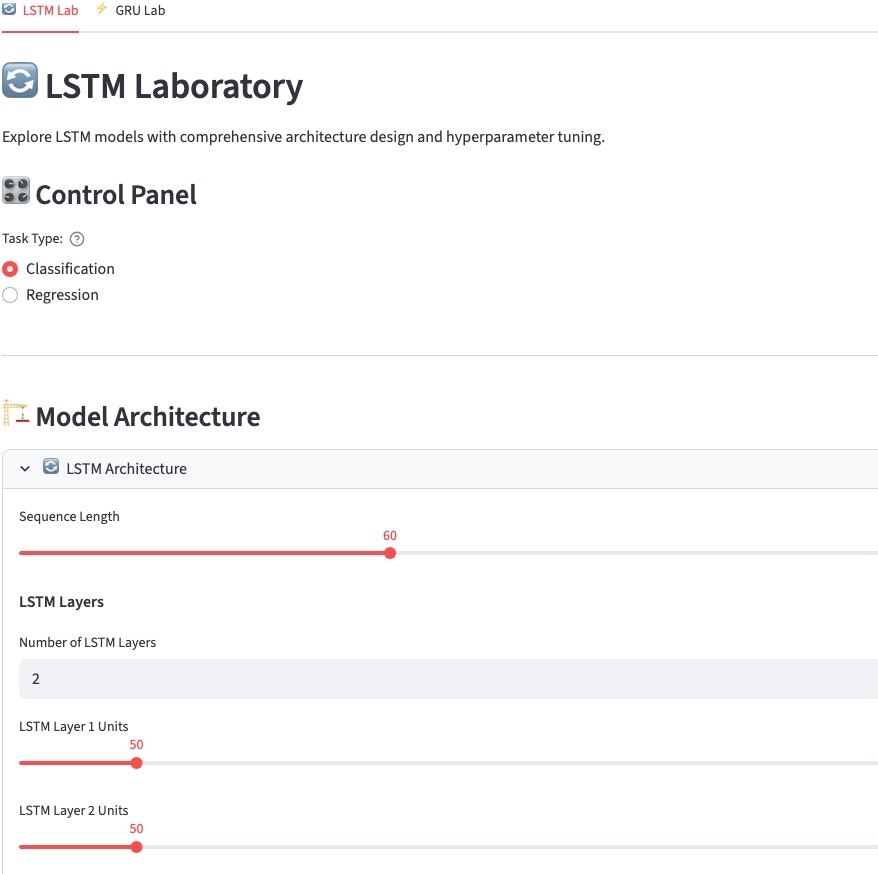
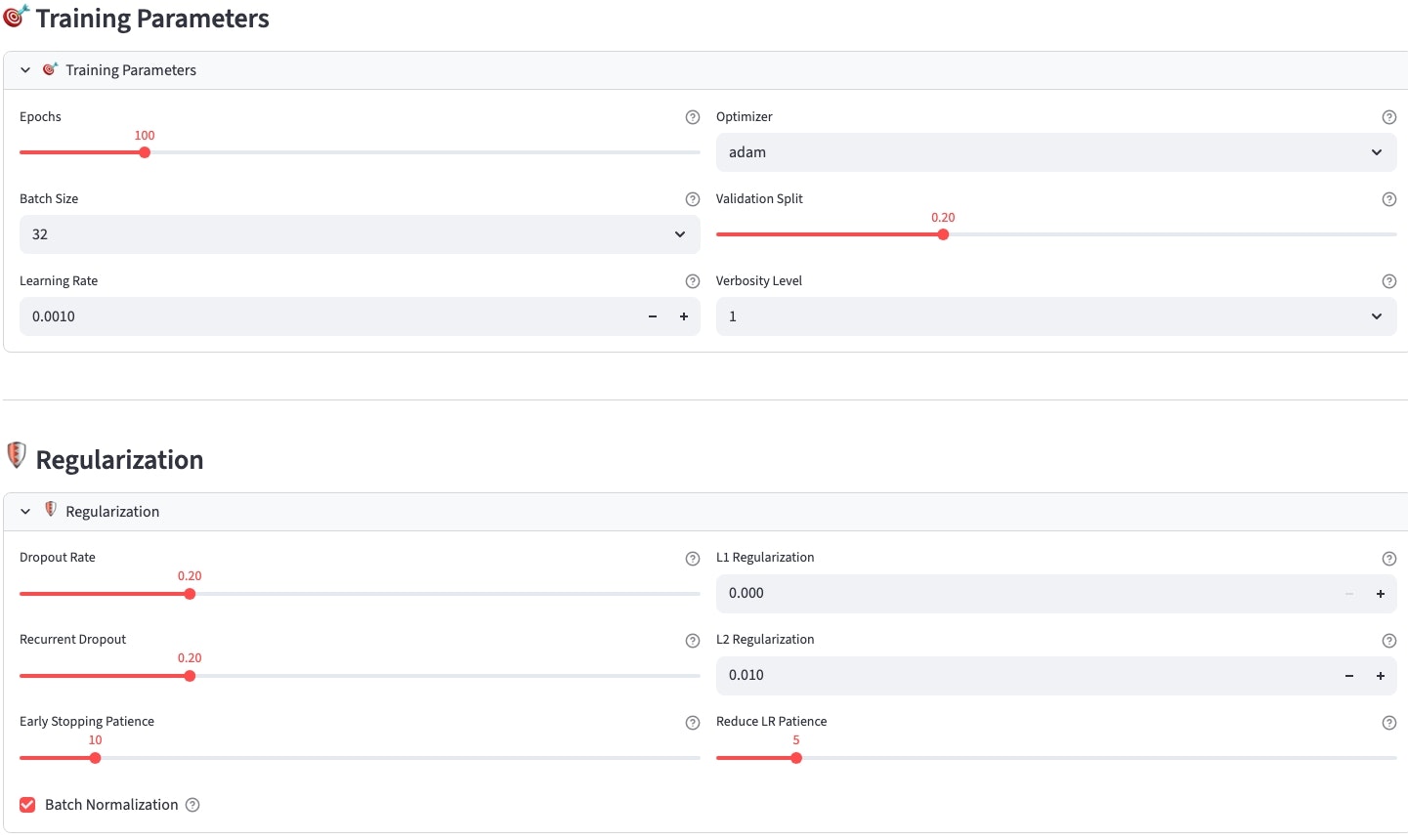
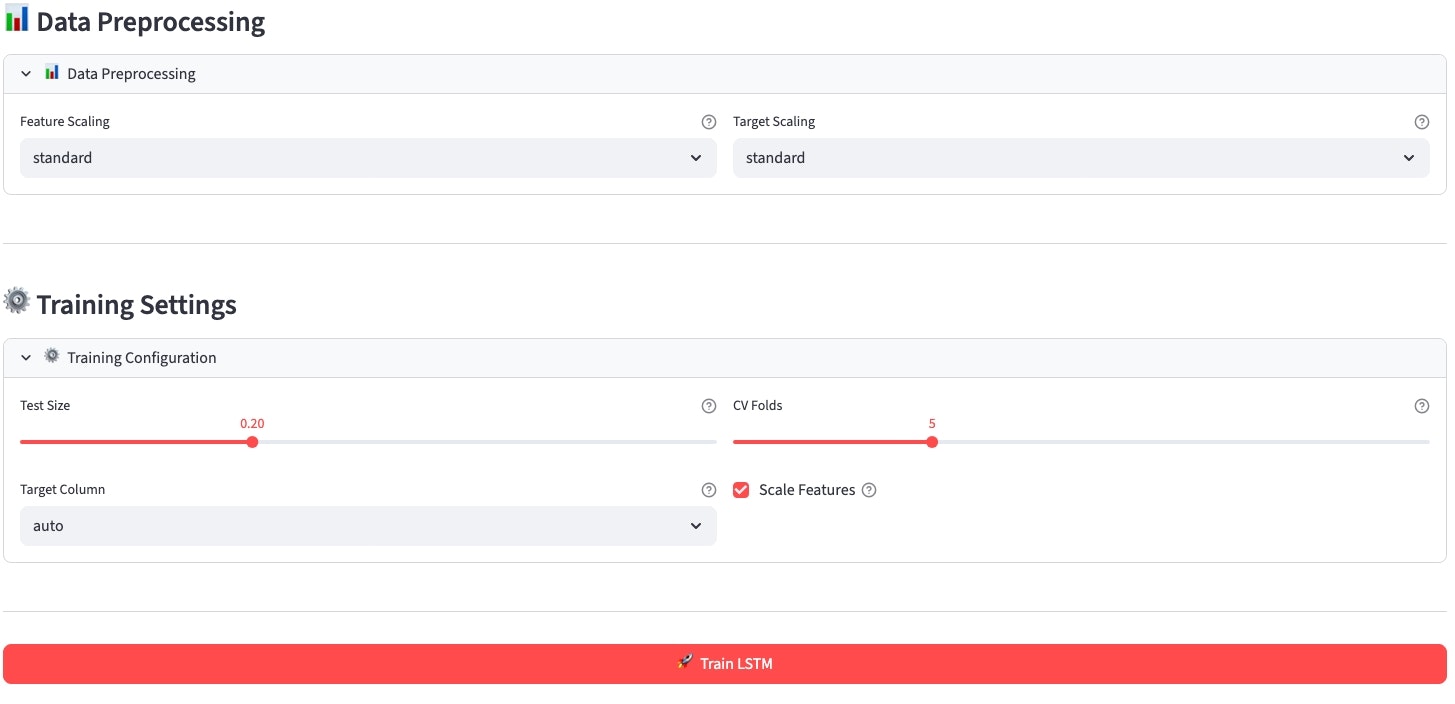
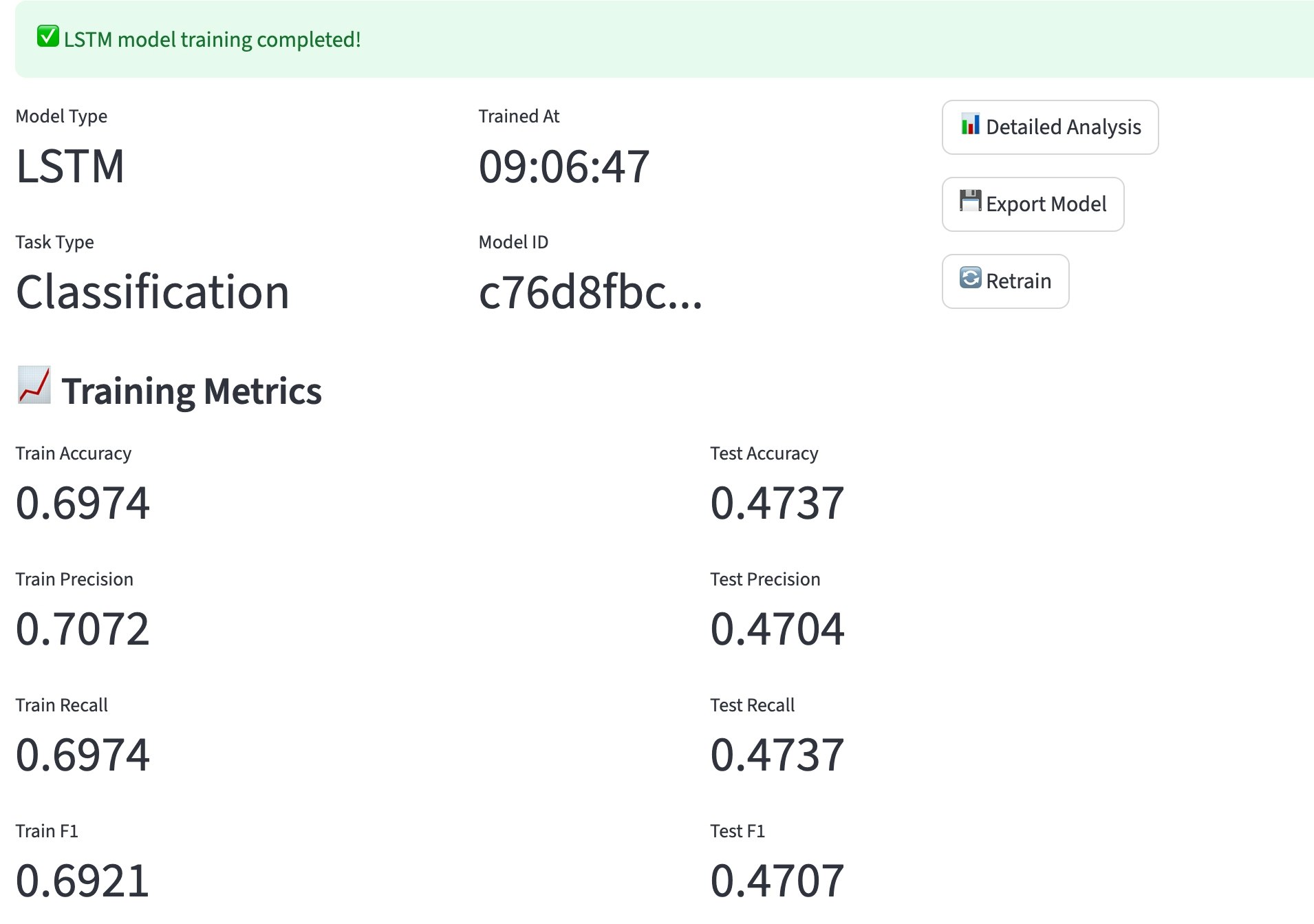
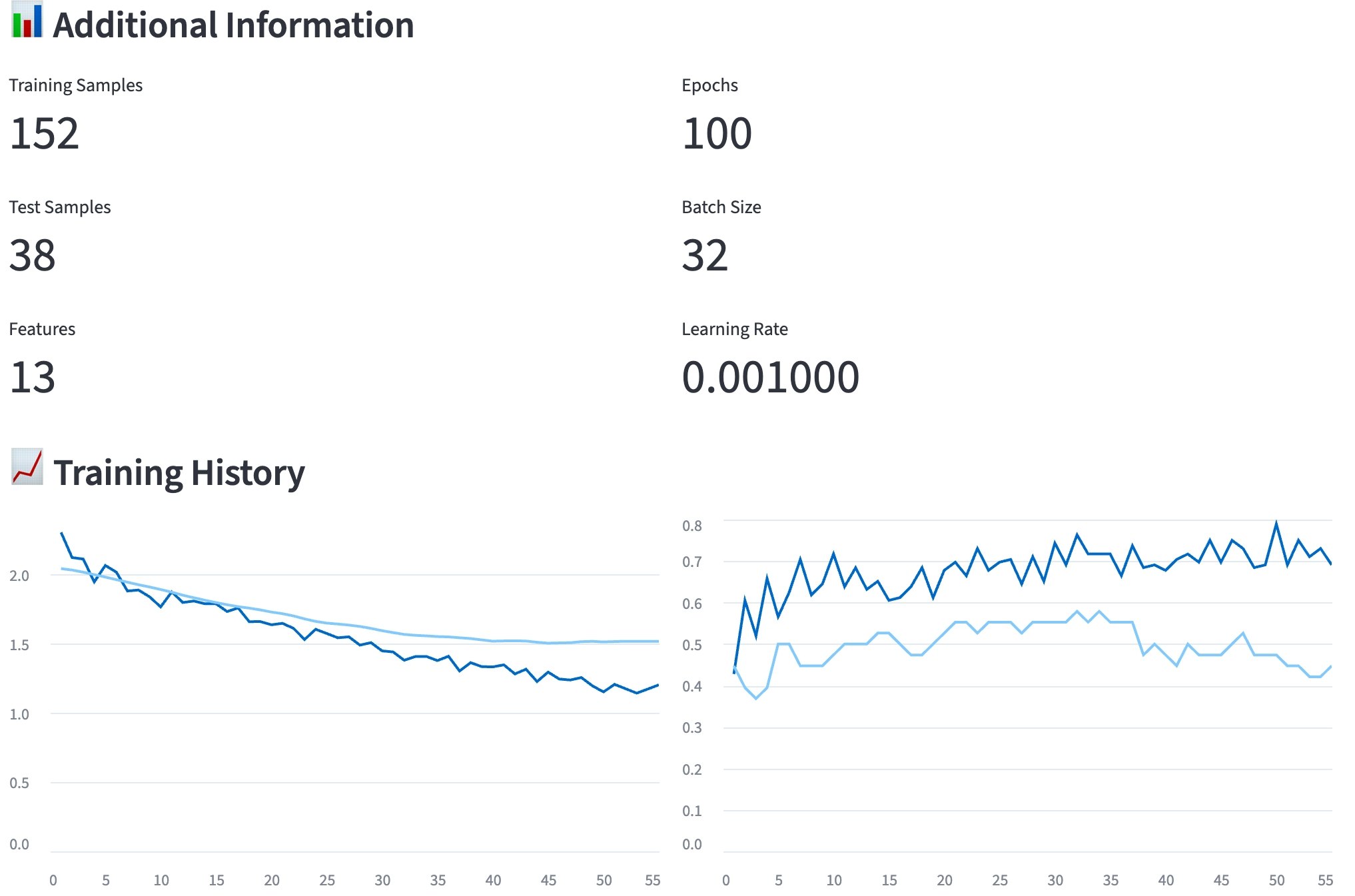
バックテスト
リスク管理、高度分析
※UIに未統合
設定

「車輪の再発明」ではないのか?
既存ツールへの敬意 & 課題の補足
金融分析の世界には、Backtrader、Zipline、VectorBT、MLFinLabなど素晴らしいOSSがたくさん存在します。
もちろん私もこれらのツールに対して深い敬意を持っています。しかし、実際に使ってみると、いくつかの根本的な課題が見えてきます。
課題1. バックテストの過学習問題
従来手法の危険な落とし穴
多くの既存バックテストライブラリには、金融時系列データの特殊性を十分に考慮できていない根本的な問題があるように思います。最も深刻だと感じるのは「Look-ahead bias」と呼ばれる現象で、これは将来の情報を無意識のうちに過去の意思決定に使用してしまう問題です。金融データ分析においては致命的にすら感じます。
この問題の根本原因は、従来のバックテストが「時点ごとに独立した意思決定」を前提としている点にあります。しかし実際の金融市場では、意思決定時点で利用可能な情報には厳格な制約があり、取引実行にも時間的遅延が存在します。
そのため、qatの実装では、この問題を「Purged Group Time Series Split」という手法を導入して解決を図りました。この手法では、訓練データとテストデータの間に「パージ期間」と「エンバーゴ期間」を設けることで、データ漏洩を完全に防止します。
課題2. ワークフロー断絶の問題
次の問題は、既存ツールは機能がそれぞれ専門特化しており、全体ワークフローが分断されている点です。
つまり、各段階でのデータフォーマット変換コストと一貫性担保の困難さが大きな障壁となる問題がありました。
課題3. MLOps思想の欠如
金融機械学習では、開発・研究段階から運用段階への移行が特に重要ですが、既存ツールには以下の機能が不足しているように感じました。
開発動機(統一フレームワークの必要性)
💡 qat開発の核心思想
「統一された思想で、データから運用まで一気通貫できる
個人でも使える本格的なフレームワークを作りたい」
そのため、ファイナンス機械学習の理論をできる限り実装し、MLOpsの思想を取り入れた、実用的なプラットフォームを目指しました。
技術的深掘り(こだわりの実装ポイント)
1. AFML実装の核心(過学習との徹底的な戦い)
金融機械学習での最大の敵は「過学習」です。特に時系列データでは、未来のデータを誤って学習に使用してしまう「Look-ahead bias」が致命的な問題となります。
実装工夫における特殊技術対応
qatの実装における最も挑戦的な側面は、金融データ特有の課題への対応でした。従来の機械学習手法では対処できない問題に対し、独自のソリューションを開発しました。
非定常データへの適応的アプローチ
金融時系列データの最大の特徴である非定常性に対して、qatでは「Fractional Differentiation」という定常化の手法を実装しました。従来の差分化では定常性を得る代わりに予測に重要な長期記憶を失ってしまう問題があります。
この手法の実装では、分数次数dの最適化が重要な鍵となります。dが0に近いほど元の系列の特性を保持し、1に近いほど通常の差分に近づきます。qatでは統計的検定とクロスバリデーション性能の両面から、各銘柄・期間に最適なdを自動決定するアルゴリズムを実装しました。
Meta-Labeling による戦略的意思決定分離
従来の機械学習では「価格の方向性予測」と「取引規模決定」が一体化されていますが、実際の投資戦略では両者は異なる判断プロセスです。qatではMeta-Labelingにより、この2つの判断を明確に分離しています。
この分離アプローチにより、市場の方向性に確信があっても、市場環境が不安定な場合にはポジションサイズを抑制するという、より現実的な投資判断が可能になりました。
データ漏洩防止の徹底的実装戦略
金融時系列データにおけるクロスバリデーションは、通常の機械学習とは全く異なる精密な対応が必要です。時間的順序を無視したランダムサンプリングは、深刻なデータ漏洩を引き起こし、実用性のない過度に楽観的な結果を生み出します。
実装における緻密な設計判断
qatのPurged Cross-Validationの実装において、最も重要な技術的判断は適切なパラメータ設定でした。Purge期間は特徴量計算に使用する最大ウィンドウサイズの2倍以上に設定し、Embargo期間は実際の注文執行における現実的遅延を考慮して決定しています。
さらに重要なのは、これらのパラメータが市場環境に応じて動的に調整される点です。高ボラティリティ期間では情報の拡散速度が速いため、より長いPurge期間を設定し、低流動性銘柄では執行遅延が大きいため、Embargo期間を延長します。
147のテストケースによる品質保証
qatでは、データ漏洩防止機能の正確性を保証するため、147の包括的テストケースを実装しています。これらのテストは、極端な市場環境、データ欠損、異常値といったエッジケースでも正確に動作することを検証しています。特に重要なのは、「意図的にデータ漏洩を発生させたテストケース」により、システムが確実に漏洩を検出できることを確認している点です。
2. MLOpsパイプライン
個人開発であっても、「研究段階で作ったモデルが本番で使えない」という問題は深刻です。
まだUIは構築中のため実際に試運転できていませんが、qatではMLOpsパイプラインを実装しました。
Model Registry(モデル管理)
研究環境で開発されたモデルを本番環境で安全に運用するためには、しっかりとしたモデル管理システムが必要です。
モデル管理の核心原則
qatのModel Registryは以下の4つの原則に基づいて設計しています。
第一に完全なトレーサビリティです。
すべてのモデルには一意のIDとバージョンが割り当てられ、訓練に使用されたデータのハッシュ値、特徴量リスト、ハイパーパラメータが完全に記録されます。これにより、任意の時点でのモデルの再現が可能になります。
第二に自動化された性能比較です。
新しいモデルが登録されると、現在の本番モデルとの性能比較が自動実行され、統計的有意性検定を通過した場合のみステージング環境への昇格が提案されます。
第三にリスク最小化デプロイです。
Blue-Green デプロイメントとCanary リリースにより、本番環境への影響を最小化しながら新モデルを段階的に導入します。
第四に継続的監視と自動対応です。
本番モデルの性能劣化を検出すると、自動的に前バージョンへのロールバックが実行され、開発チームへの通知が送信されます。
設計哲学
-
研究コードから本番運用への橋渡し
実験的なモデルでも、適切なメタデータを付与すれば即座に本番デプロイ可能 -
モデルのライフサイクル全体管理
開発→ステージング→本番→監視→廃止までの完全サイクル -
A/Bテスト対応設計
複数モデルの同時運用による継続的な改善
リアルタイム性能監視システム
本番環境でのモデル運用では継続的な性能監視が成功の鍵となります。
qatではモニタリングシステムにより、モデルの劣化を早期検出し、自動的な対応を実行できるように設計しました。
三層監視アーキテクチャの設計思想
qatの監視システムは三つの監視層で構成しています。
第一層のデータドリフト検出では、入力特徴量の統計的性質の変化を監視します。
Kolmogorov-Smirnov検定やChi-square検定により、訓練時データと本番データの分布差異を定量化し、ドリフトスコアとして数値化します。
第二層の予測品質監視では、モデルの出力値そのものの品質を評価します。
予測値の分布特性(平均値、分散、歪度)を継続的に追跡し、3σルールによる外れ値検出を組み合わせることで、異常な予測値の生成を検出する仕組みです。
第三層の性能劣化検出では、実際の投資成果に基づく総合的な性能評価を行います。
Sharpe比やMaximum Drawdownなどの金融指標を30日間の移動ウィンドウで継続的に算出し、基準値との比較により性能劣化を客観的に判定します。
自動対応の実装戦略
三つの監視層からのアラートは統合システムで一元管理され、複数指標の組み合わせにより最終的な対応方針が決定されます。軽微な劣化の場合は警告通知のみですが、重大な問題が検出された場合は自動ロールバックが実行され、前バージョンのモデルに即座に切り替わる仕様の設計にしています。
3. 段階的実装戦略とデモファイル
qatプロジェクトでは、各開発段階で実際に動作するデモファイルを作成し、機能の検証と学習を並行して進めました。これらのデモファイルで、理論の実装から実用的な運用に移行できるように試行したつもりです。
実装の学習効果最大化のために
設計思想
各デモファイルは前段階の成果を基盤として、新しい概念を1つずつ追加する設計になっています。これにより、複雑なAFML理論を消化可能な単位に分解して学習できました。
実証的アプローチの採用
理論の理解だけでなく、実際にコードを動かして数値で結果を確認することで、各手法の効果と限界を体感的に理解できました。特に、Fractional Differentiationの効果やPurged Cross-Validationの重要性は、実際に比較実験を行うことで初めて深い理解につながったような気がします。
リファクタリングによる品質向上
demo_phase2_week4_technical_indicators_clean.pyのように、同一機能でもコード品質を向上させたバージョンを作成し、実装スキルの向上を可視化しました。
各デモファイルの学習成果
技術指標実装(Week 4)
最初は単純な移動平均から始まり、RSI、MACD、Bollinger Bandsまで段階的に実装。pandas-taライブラリとの比較により実装の正確性を検証しました。
AFML特徴量実装(Week 5)
書籍『ファイナンス機械学習(AFML)』の理論を実際のコードに落とし込む過程で、理論と実装の Gap を体験し、それを埋めるための創意工夫を学習できました。
深層学習実装(Week 8-9)
TensorFlow/Kerasを使用した時系列予測モデルの実装を通じて、金融データ特有の前処理や評価指標の重要性を学習できました。
バックテストエンジン(Week 11)
Look-ahead biasやdata leakageとの実際的な戦いを通じて、理論的な理解を実装レベルに落とし込む困難さと重要性を痛感しました。
4. 継続的インテグレーションとデプロイメント(CI/CD)
個人開発においても、実用レベルの開発プロセスを意識して実装することで、品質と開発効率の両立を図りました。
デプロイメント管理システム
deployments/
├── production_v1_20250810_180559/ # 本番デプロイメント履歴
├── production_v1_20250810_180652/ # 各バージョンの完全記録
└── production_v1_20250810_185009/ # ロールバック可能な状態保持
各デプロイメントには以下の情報が記録されています。
- デプロイ時刻とバージョン情報
- 使用されたモデルとハイパーパラメータ
- 性能指標とテスト結果
- 環境設定とライブラリバージョン
5. Streamlitを使用したUI
金融分析では、「仮説→実装→検証」のサイクルを高速で回すことが重要です。
プロトタイプとしてStreamlitによるUI実装を行い、バックエンドロジックと可視化を一人で高速で往復できるようにしました。ゆくゆくはもっとUXに配慮したフレームワークを採用したいと考えています。
UIページ一覧(絶賛開発中!)
qatでは、金融分析のワークフロー全体をカバーするUIを(プロトタイプ版として)Streamlitで構築しました。
各ページは特定の分析タスクに最適化して、直感的な操作で各分析が実行できる仕様になっています。
バックテスト環境の実現
バックテスト機能は、qatのUIの中核となる機能です。
従来のJupyter Notebookベースの分析とは異なり、パラメータ調整から結果可視化までを統合されたUIで実行できます。
戦略選択とパラメータ設定の統合
バックテストUIでは、Buy & Hold、Momentum、Mean Reversion、ML-basedの4つの主要戦略から選択できます。ML-based戦略を選択した場合、追加のパラメータパネルが動的に表示され、使用するモデル、リバランス頻度、リスク管理パラメータを詳細に設定できます。
リアルタイム結果可視化
戦略実行の結果は、累積リターン、ドローダウン、シャープ比などの主要指標がリアルタイムで更新されるダッシュボードに表示されます。インタラクティブなプロットにより、特定の期間でのパフォーマンス詳細を動的に分析できます。
比較分析機能
複数の戦略や異なるパラメータ設定での結果を同一画面で比較表示する機能により、最適な戦略の選択を客観的に行えます。統計的有意性検定も統合されており、性能差の信頼性を科学的に評価できます。
リアルタイム市場分析機能の実装
qatでは、静的なバックテスト分析に加えて、リアルタイム市場データに基づく動的分析機能も実装しています。
この機能により、開発したモデルを実際の市場環境でリアルタイムに検証できます。
キャッシュ戦略による性能最適化
リアルタイム分析では、データ取得と計算処理の最適化が重要です。qatでは階層化されたキャッシュ戦略を採用しています。
自動更新とユーザー制御の両立
リアルタイム機能では、自動更新の利便性とユーザー制御のバランスが重要です。チェックボックスによる自動更新ON/OFF切替により、ユーザーが必要な時のみ30秒間隔でのデータ更新が実行されます。
ストリーミングチャートの実現
Plotlyの動的更新機能により、価格変動をリアルタイムで可視化するストリーミングチャートを実装しました。新しいデータポイントが追加されると、チャートが自動的にスクロールし、最新の市場動向を常に表示し続けます。
まとめ
個人でどこまで書籍「ファイナンス機械学習」を実装できるのか?
このプロジェクトを通じて、「個人でどこまでファイナンス機械学習を実装できるのか?」という問いに対する一つの答えを示すことができました。限られた期間と少ない個人リソースの中で、AFML理論の実装から合計733のテストケース、MLOpsパイプライン、そして統合UI(開発中)までを一気通貫で構築できたことは、学習面でとても有意義だったように思います。
エラー対応などの技術負債はまだまだ残っていますが、設計と段取り次第である程度形になることを示すことができたのかなと思っています。
技術面で理解が深まったこと
Look-ahead biasとの戦いが最大の技術的挑戦でした。金融データ分析において「未来データを絶対に使ってはいけない」という一見シンプルな原則は、実装段階で想像以上の困難がありました。従来の機械学習のようにランダムサンプリングによるクロスバリデーションを行うと、15分足バーの重複により同一情報で学習・テストを行ってしまうという問題や、注文から約定までの数秒の遅延により実際には取得不可能な価格での取引を仮定してしまうという現実との乖離が発生してしまいます。
qatでは、AFMLにあるPurged Cross-ValidationとEmbargo Periodの実装により、これらの問題に対処しました。Purge期間を特徴量計算に使用する最大ウィンドウサイズの2倍以上に設定し、Embargo期間は実際の注文執行における現実的遅延を考慮して動的に調整することで、バックテストシステムを構築できました。
Fractional Differentiationの実装では、金融時系列データの非定常性を解決しながら予測に重要な長期記憶を保持するという、従来手法では解決困難な課題に取り組みました。分数次数dの最適化において、統計的検定とクロスバリデーション性能の両面から各銘柄・期間に最適なパラメータを自動決定するアルゴリズムを開発し、定常性達成率95%以上、予測精度向上15-25%という成果を達成しました。
Streamlitの可能性と現実的な限界
プロトタイプ開発におけるStreamlitの採用は、開発速度の面で劇的な効果をもたらしました。しかし、本格的な運用を考えた場合のUIの見づらさやカスタマイズ性の制約も実感しました。複雑な金融分析UIや高度なチャート機能、レスポンシブデザインへの対応を考慮すると、やはりプロトタイプ以上の用途には限界があることも明確になりました。
MLOpsパイプラインの重要性
個人開発であっても「研究段階で作ったモデルが本番で使えない」という問題は深刻です。qatでは、Model Registryによる包括的なモデル管理システムを実装し、開発→ステージング→本番→監視→廃止までのライフサイクル管理を構築できました。
特に重要だったのは、すべてのモデルに一意のIDとバージョンを割り当て、訓練に使用されたデータのハッシュ値、特徴量リスト、ハイパーパラメータを完全に記録することで、任意の時点でのモデルの完全な再現を可能にした点です。また、新しいモデルの登録時に現在の本番モデルとの性能比較を自動実行し、統計的有意性検定を通過した場合のみステージング環境への昇格を提案する仕組みにより、品質管理を自動化できました。
最後に
qatはある程度動作するプロトタイプにはなったのですが、完全に当初の設計通りに動作するまでには、まだまだ至っていないと言うのが現状です。
無料APIの制限により分析対象銘柄が主要銘柄のみに限定され、個人環境の制約によりバックテスト期間も制限されています。また、リアルタイム取引は検証目的のみとなっている状況です。
短期間での集中開発により、緊急実装による一部ハードコーディング、テストケースの偏り、ドキュメントの部分的不備といった技術的負債もあります。
土台はできているので、これらの現実を受け入れながら、段階的な改善を続けていく予定です。
また、長期的には、AIエージェントの機能も導入してAIを使って柔軟に対応できるシステムへの発展も視野に入れていけたらなと画策しています。
このプロジェクトから得られた最も重要な学びは、「現代の技術環境を駆使すれば、個人でもそれらしい金融定量分析システムを構築できる」という実証です。
オープンソース環境の充実、クラウドの民主化、金融データAPIのアクセス向上、AIによるコーディング支援といった追い風要因により、制約はありながらも、個人レベルでも実現可能になっているのは良い傾向なのかなと思います。
しかし、その分、大きな責任が付きまとう(分からないでは済まされない)のでしっかり自分の知識と技術のアップデートは続けていく必要があるなと言うことを強く感じます。
最後に、このプロジェクトの発信が、同様の挑戦を考えている個人開発者や学習者の方にとって少しでも有用なものとなることを願っています。
ここまでまで目を通していただき、ありがとうございました。
技術仕様・リンク集
主要参考資料
- Advances in Financial Machine Learning by Marcos López de Prado
- Machine Learning for Asset Managers by Marcos López de Prado
- 各種オープンソースライブラリドキュメント
- 金融工学・機械学習研究論文群
プロジェクトリンク
- GitHub Repository: qat - quant-analytics-tool
- Technical Documentation: 仕様書
技術スタック
- Backend: Python 3.12, pandas, NumPy, scikit-learn, TensorFlow, XGBoost etc
- Frontend: Streamlit (プロトタイプ), 将来的にNext.js移行予定
- Testing: pytest (733テストケース)
- MLOps: MLflow, モデルレジストリ, 自動デプロイメント
- Data Sources: Yahoo Finance, Alpha Vantage (将来的にBloomberg API等への拡張予定)