はじめに
猫の画像認識から始まり、世界中の開発者を虜にし、今や大規模言語モデルを支える基盤となった TensorFlow 。
その裏には、Googleの大胆な決断、ライバルとの予期せぬ協力、そしてコミュニティの力が隠されていました。

TensorFlow
Googleが開発した機械学習フレームワークです。データフローグラフを用いた計算モデルにより、深層学習を中心とした機械学習の開発が容易になります。Python APIが主流で、GPUによる高速な計算処理に対応し、画像認識や自然言語処理などの幅広い分野で活用されています。
なぜGoogle最大の機密プロジェクトは、世界に公開されることになったのか。その波乱の歴史を紐解いていきます。
TensorFlowの黄金時代(2015-2022)
TensorFlowがオープンソース化されてから急速に普及していく過程には、予期せぬ出会いと戦略的な判断が交差していました。その激動の7年間を振り返ってみましょう。
DistBeliefから生まれた意外な理由
2011年、GoogleはDistBeliefという社内用の機械学習システムを開発していました。これは大規模なニューラルネットワークを分散処理できる画期的なシステムでしたが、完全にGoogle内部用で、使いやすさより性能を重視した複雑なシステムでした。
そんな中、2012年にGoogle Brainチームが驚くべき発見をします。DistBeliefを使って学習した大規模ニューラルネットワークが、猫の画像を自動的に認識できるようになったのです。この成果は大きな注目を集め、Googleは機械学習の可能性に大きな期待を寄せるようになります。
しかし、DistBeliefには大きな問題がありました。システムが複雑すぎて、Google社内でさえも新しい研究者が使いこなすのに数ヶ月かかってしまうのです。これはイノベーションの速度を落としかねない深刻な課題でした。
そこでJeff Deanらのチームは大胆な決断を下します。DistBeliefを一から設計し直し、使いやすさを重視した新しいフレームワークを作ることにしたのです。これがTensorFlowの誕生につながります。
2015年11月、GoogleはTensorFlowをオープンソースとして公開します。この決断の背景には興味深い戦略がありました。機械学習の研究開発を加速させるには、できるだけ多くの開発者が参加できる環境が必要だと考えたのです。また、優秀な人材の採用にもつながると考えました。
予想以上の反響がありました。公開から1年もしないうちに、GitHubでは最もスター数の多いプロジェクトの一つとなり、数多くの企業が採用を表明。まさに機械学習フレームワークの事実上の標準となったのです。
Kerasとの運命的な出会い
しかし、TensorFlowにも課題がありました。低レベルAPIは柔軟性が高い反面、初心者には扱いづらかったのです。一方、François Cholletが開発したKerasは、直感的で使いやすいAPIで人気を集めていました。
当初、GoogleはKerasをライバル視していました。しかし、PyTorchが急速にシェアを伸ばし始めたことで、状況は変化します。
PyTorchの直感的なインターフェースは研究者たちの心を掴み、特に研究用途で急速に支持を拡大していました。この流れの中で、GoogleはTensorFlowの使いやすさを向上させる必要性を強く認識することになります。
2017年、GoogleはKerasをTensorFlowの公式の高レベルAPIとして採用することを決定。さらに2019年のTensorFlow 2.0では、Kerasを完全に統合し、デフォルトのインターフェースとしました。この決断は、使いやすさを求める開発者コミュニティの声に応えたものでした。
Kerasの作者であるChollet氏は後にGoogleに入社し、TensorFlowの開発に直接携わることになります。ライバルだったフレームワークが統合され、新たな強みを生み出すという、思わぬ展開が実現したのです。※Chollet氏は2024年11月にgoogleを退社しました。
このように、TensorFlowの歴史は、オープンソース化という大胆な決断と、コミュニティの声に耳を傾けた柔軟な対応によって形作られてきました。それは、単なる技術の進化だけでなく、機械学習の民主化にも大きく貢献することになったのです。
ChatGPT時代への突入(2022-現在)
ChatGPTの登場により機械学習の世界は大きな転換期を迎えましたが、TensorFlowもまた、この新時代で重要な役割を担うことになります。その意外な展開を見ていきましょう。
Transformer革命の立役者として
実は、ChatGPTの基盤となったTransformerアーキテクチャは、Google発の革新でした。2017年、GoogleのResearch팀が発表した論文「Attention is all you need」は、機械学習の歴史を大きく変えることになります。
この論文には面白い裏話があります。当初、研究チームはこのモデルを「AIAYN」(論文タイトルの略)と呼んでいました。しかし、あまりにも発音しづらいため、データの変換(Transform)を行うという特徴から「Transformer」という名前に落ち着いたそうです。
その後、GoogleはTransformerを基にした新たなモデルを次々と発表します。2018年にはBERTを公開。このモデルはWikipediaとBooksCorpusで事前学習され、11個のNLP(自然言語処理)タスクで最高性能を記録。まさに、言語モデルの新時代の幕開けでした。
さらにGoogleは野心的なT5(Text-to-Text Transfer Transformer)を発表。このモデルはNLPタスクをテキスト生成問題として統一的に扱うアプローチを採用し、Transformerアーキテクチャの柔軟性をさらに引き出しました。
HuggingFaceとの蜜月関係
ここで意外な展開が起きます。新興企業HuggingFaceが開発したTransformersライブラリが、爆発的な人気を獲得したのです。
当初、GoogleはTensorFlowとの競合を懸念していました。しかし、HuggingFaceのアプローチは異なっていました。彼らは特定のフレームワークに依存せず、TensorFlowとPyTorchの両方をサポート。さらに、モデルの共有プラットフォームとしても機能し、研究者たちの支持を集めていました。
2020年、GoogleはHuggingFaceと公式に提携。TensorFlowハブにHuggingFaceのモデルを統合し、相互運用性を強化します。この決断は大きな成功を収めます。
開発者たちは、TensorFlowの高性能な学習基盤と、HuggingFaceの使いやすいインターフェースの両方を選択的に活用できるようになりました。ただし、HuggingFaceの多くのユーザーは依然としてPyTorchを主に使用しており、両者の共存が進んでいます。
現在では、HuggingFaceのModel Hubで公開されているモデルの多くがTensorFlowをサポート。オープンソースの大規模言語モデルの開発や展開に、両者の技術が不可欠となっています。まさに「対立から協調へ」という、オープンソースならではの展開と言えるでしょう。
この協力関係は、ChatGPT以降の新たな時代においても、オープンソースAIの発展を支える重要な基盤となっています。商用の巨大モデルに対抗する、オープンな選択肢を提供し続けているのです。
意外な活用と次の一手
大規模言語モデルが脚光を浴びる中、TensorFlowは意外な分野で着実に存在感を示していました。エッジデバイスでの活用から次世代の学習手法まで、その多彩な展開を見ていきましょう。
エッジAIという切り札
ChatGPTのような大規模モデルが注目を集める中、TensorFlowは意外な場所で存在感を示していました。
それがスマートフォンやロボットなどのエッジデバイスです。
TensorFlow Liteは、当初はあまり注目されていなかったプロジェクトでした。しかし、プライバシーへの関心の高まりや、リアルタイム処理の需要により、状況は一変します。
例えば:
- Androidスマートフォンでの顔認識
- 自動運転車での物体検出
- スマートスピーカーでの音声認識
- ロボットの自律制御
特に興味深いのが軽量化技術です。TensorFlow Liteは「量子化」という技術を使って、モデルのサイズを数分の1に圧縮することに成功。32ビット浮動小数点を8ビット整数に変換しつつ、性能をほぼ維持するという離れ技を実現しました。
TensorFlow Lite
GoogleがTensorFlowの軽量版として開発したモバイルおよびエッジデバイス向けの軽量機械学習フレームワークです。独自の量子化技術により、モデルサイズを大幅に圧縮しながら性能を維持することができます。Android、iOS、組み込みLinuxなど様々なプラットフォームに対応し、スマートフォンでの顔認識や自動運転車での物体検出など、リアルタイム処理が必要な場面で広く活用されています。
オープンソースLLMの台頭
2022年末、ChatGPTの登場で状況が一変します。しかし、TensorFlowコミュニティは独自の道を歩み始めました。
その中心となったのが、オープンソースLLMの開発です。
例えば:
- T5をベースにした多言語モデル
- BERTの軽量版モデル
- 特定分野に特化した小規模モデル
特筆すべきは、これらのモデルが「小さくても強い」という特徴を持っていることです。数千億のパラメータを持つGPT-3と比べ、数億パラメータでも特定のタスクで十分な性能を発揮します。
コミュニティの底力も見逃せません。
TensorFlowのGitHubリポジトリには
- 3,000以上のコントリビューター
- 170,000以上のスター
- 世界中からの日々の改善提案
こうしたオープンな開発は、AI技術の民主化に大きく貢献しています。誰もが自由にモデルを改良し、新しいアイデアを試すことができる環境が整っているのです。
特に注目すべきは、「連合学習」への取り組みです。
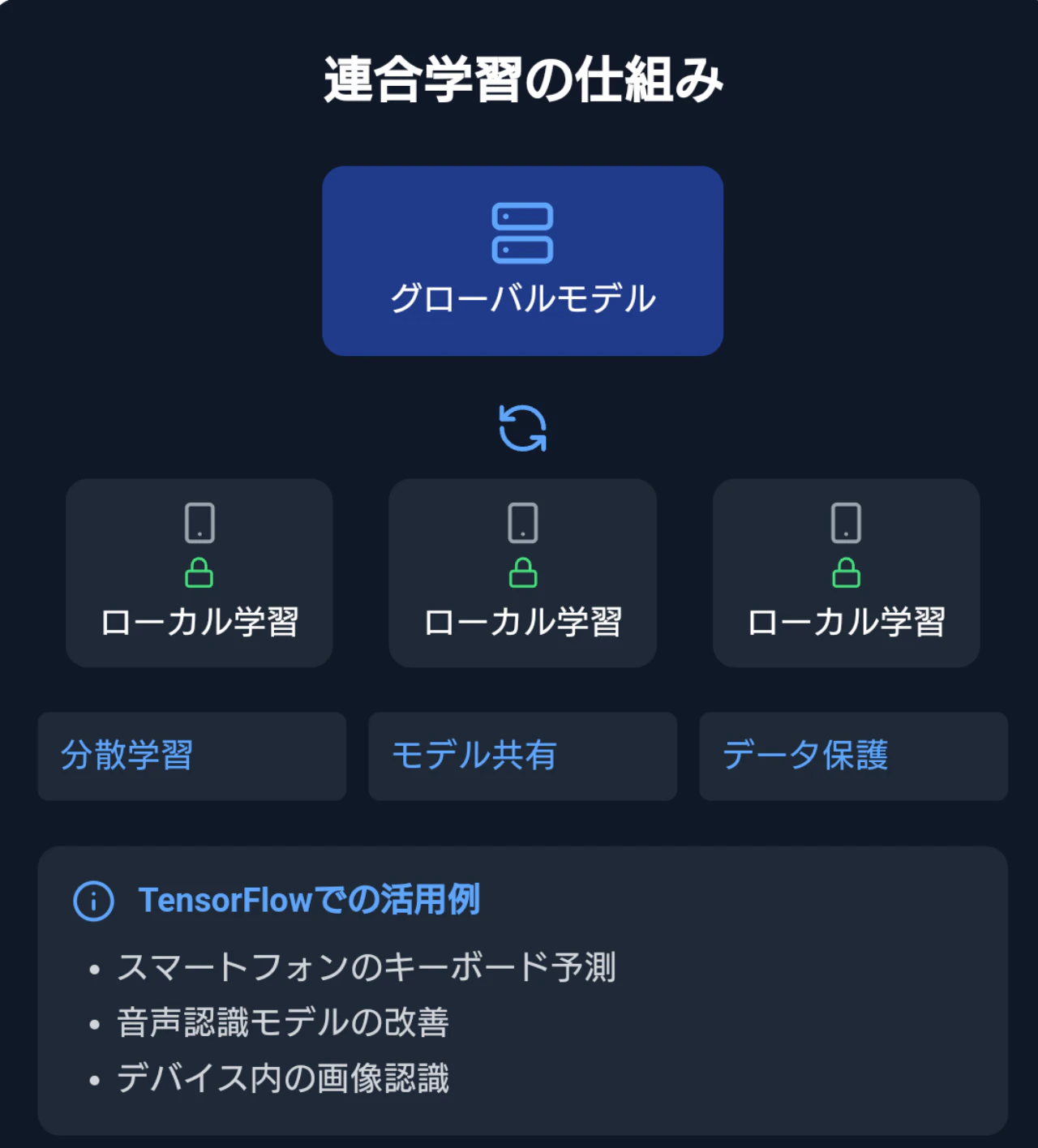
デバイス上でモデルを学習させ、プライバシーを保ちながら全体の性能を向上させる。この技術は、今後のAI開発の新しいパラダイムとなる可能性を秘めています。
このように、TensorFlowは大規模モデルとエッジAIの両方で、独自の進化を続けています。オープンソースの強みを活かし、より多様なAI活用の可能性を広げているのです。
エピローグ:TensorFlowは何を目指すのか
ChatGPTに代表される商用の大規模言語モデルが話題を席巻する中、TensorFlowは意外な進化を遂げています。
大規模モデル時代の意外な立ち位置
当初、多くの人々はTensorFlowの影響力が低下すると予測しました。しかし、実際は逆でした。TensorFlowは「大規模モデルを作る」という競争から一歩引き、代わりに「誰もが使えるAI」という新たな領域を切り開いています。(一方で、大規模モデルの開発においてはPyTorchが引き続き優勢な状況です。)
例えば:
- スマートフォンで動作する超軽量モデル
- プライバシーを守りながら学習できる連合学習
- 特定分野に特化した小規模だが高性能なモデル
オープンソースの底力と未来
TensorFlowの真の強みは、実はコミュニティの存在でした。世界中の開発者が日々新しいアイデアを持ち寄り、それを実装し、共有する。この「オープンソースの生態系」は、巨大企業でさえ簡単には真似できない強みとなっています。
そして今、TensorFlowは新たな挑戦を始めています。
- エッジとクラウドのハイブリッドAI
- オープンソースLLMの民主化
- 次世代の学習アーキテクチャの探求
2015年、「猫」を認識することから始まったTensorFlowの物語。その歴史は、技術の進化だけでなく、「AIを誰のものにするか」という問いへの一つの答えとなっているのかもしれません。
最後に、GoogleのJeff Dean氏のツイートをTensorFlowの未来像として紹介したいと思います。
AIは特別な技術である必要はない。それは、誰もが使える道具であるべきだ。
これからのAI開発は、巨大な言語モデルだけでなく、より身近で、より実用的な応用へと広がっていくでしょう。その時、TensorFlowとそのコミュニティは、また新たな可能性を切り開いているはずです。