はじめに
この記事は限界開発鯖アドベントカレンダー15日目(12/15)の記事です。
最近発表された物体検出モデルであるYOLOXとMultiple Object Trackingのライブラリであるmotpyを利用して、物体のトラッキングをしてみます。
自己紹介
七瀬真冬様に憧れて西行響希という名前でV高専生やってます。最初は技術系ゴリゴリでやっていこうかと考えていたのですが、VTuberによくある話で完全なるネタ枠になってしまいました。
ディープラーニングを利用したシステム開発を研究としていて、その他にもC#でゲーム制作をしています。
以下に各SNS等のリンクを載せておきますので良かったらフォローなどよろしくお願いします。
Twitter GitHub YouTube
MOTとは
動画に映っている複数の物体を追跡する手法です。MOTでは追跡物体に個別IDを割り振りますが、同じ物体にはなるべく同じIDを与え続けます。
MOTは研究が盛んな分野であり多くのアルゴリズムが開発されています。広く使われているTracking by Detectionと呼ばれる手法では、まずは物体検出モデルによって動画の各フレームから追跡対象の物体を検出し、次にフレーム間で同じ物体に対して同一のIDを割り振っていきます。MOTにおいて動画中の物体の位置は一つの矩形で表され、Bounding Boxと呼ばれます。MOTのモデルは、動画の各フレームで検出された同じ物体のBounding Boxに対して一意なIDを割り振ることによって、物体を「追跡」します。
バウンディングボックスから追跡IDを振る部分では、過去のBounding Boxからカルマンフィルターで予測されたBounding Boxと実際のBounding Boxの差異から現在のフレームのBounding BoxがどのIDかを決定します。
今回は物体検出モデルにYOLOX、バウンディングボックスから追跡IDを振る部分にmotpyを使用します。
YOLOXとは
YOLOXとは2021年7月に発表された物体検出モデルです。YOLOXは毎年アメリカで開催されるコンピュータビジョンに関する世界トップレベルのカンファで2021年に行われたCVPR2021の、Automous Driving WorkshopのStreaming Perception Challengeで1位を獲得したモデルです。
YOLOv3-SPPがベースとなっており、従来のYOLOをアンカーフリーに変更し、Decoupled HeadとSimOTAを導入した物体検出モデルです。アンカーフリーとは、アンカーボックスと呼ばれる、特定の高さと幅の事前定義された境界ボックスのセットが無いモデルのことです。アンカーモデルでは、物体がある予想位置に対して何通りもあるアンカーボックスを1つ1つ当てはめてどのボックスが1番精度が良いか比較します。1
物体検出においては、クラス分類とBounding Boxの位置の計算を同時に行うため、競合が発生して精度が低下することが知られています。この問題に対して、Decoupled headを使用する方法が提案されていますが、従来のYOLOシリーズでは使用されてました。YOLOXではこのCoupled headをDecoupled headに置き換えることで高精度化を行っています。
SimOTAはLossの最適化関数で、OTAを改良したものになります。
- YOLOX-Nano
- YOLOX-Tiny
- YOLOX-S
- YOLOX-M
- YOLOX-L
- YOLOX-X
- YOLOX-Darknet53
YOLOXには上の7種類のモデルがあり、Darknet53以外は上からモデルサイズが小さい順に並んでいます。
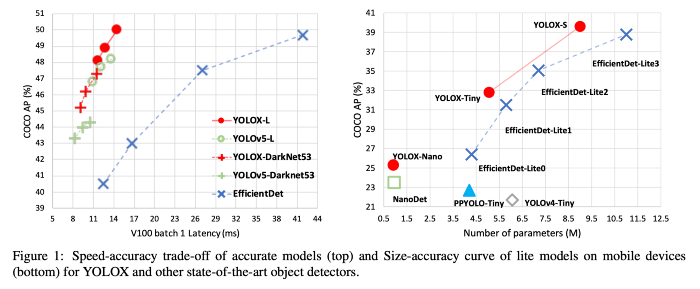
以下にYOLOXのベンチマーク2を示します。YOLOX-Lは同サイズのYOLOv5-LやEfficientDetに対して優位性があります。また、モバイル向けのサイズではEfficientDet-LiteはYOLOv4-Tinyなどの多くのモデルに対して優位性があります。
motpyとは
motpyはMOTの中で、トラッキング部分のみを気軽に実装することに長けているライブラリです。FairMOTやFastMOTはそれ自体がニューラルネットワークのモデルとなっていて、バックボーンモデルと密接に結合していたり、モデル変更時に学習が必要になったりとするのですが、motpyはライブラリとしてまとまっていて、物体検出モデルの出力フォーマットを合わせて上げれば基本的にどの物体検出モデルでも気軽に使用することができます。
実装
今回はYOLOX側のインストールがやや面倒なため、今回はインストール手順は省きます。
また、YOLOXのGitHubリポジトリに公開されている重みファイルは、setup.pyを同階層にweightsフォルダを作成してそこに保存していることを前提にしています。YOLOX-Sの重みファイルをあらかじめダウンロードしておきましょう。
物体検出の可視化
まずは、YOLOXのデモコードに検出結果のウインドウ表示機能が無いので、足してあげましょう。tools/demo.pyのimageflow_demo関数を以下のように変更します。
def imageflow_demo(predictor, vis_folder, current_time, args):
cap = cv2.VideoCapture(args.path if args.demo == "video" else args.camid)
width = cap.get(cv2.CAP_PROP_FRAME_WIDTH) # float
height = cap.get(cv2.CAP_PROP_FRAME_HEIGHT) # float
fps = cap.get(cv2.CAP_PROP_FPS)
if args.save_result:
save_folder = os.path.join(
vis_folder, time.strftime("%Y_%m_%d_%H_%M_%S", current_time)
)
os.makedirs(save_folder, exist_ok=True)
if args.demo == "video":
save_path = os.path.join(save_folder, os.path.splitext(args.path.split("/")[-1])[0] + '.mp4')
else:
save_path = os.path.join(save_folder, "camera.mp4")
logger.info(f"video save_path is {save_path}")
vid_writer = cv2.VideoWriter(
save_path, cv2.VideoWriter_fourcc(*"mp4v"), fps, (int(width), int(height))
)
while True:
ret_val, frame = cap.read()
if ret_val:
outputs, img_info = predictor.inference(frame)
result_frame = predictor.visual(outputs[0], img_info, predictor.confthre)
if args.save_result:
vid_writer.write(result_frame)
else:
cv2.imshow('frame', result_frame)
ch = cv2.waitKey(1)
if ch == 27 or ch == ord("q") or ch == ord("Q"):
break
else:
break
コードを変更したら、MOT Challengeからドライブレコーダーの動画をダウンロードします。これをsetup.pyと同じ階層に保存します。
python tools/demo.py video -n yolox-s -c .\weights\yolox_s.pth --path MOT16-13-raw.webmを実行すると以下のような動画が表示されると思います。(gpu環境が使える人は最後に「--device gpu」を付けましょう。)

もし動画として保存したい場合は、最後に--save_resultを付けるとYOLOX_outputs内にサブフォルダができその中に動画が生成されます。
motpyでのトラッキング
物体検出の表示ができたら、次にmotpyでのトラッキング機能を追加しましょう。
インポート部に以下を追加します。
from motpy import Detection, MultiObjectTracker
from motpy.testing_viz import draw_track
追跡のためのMOTクラスを追加します。
class MOT:
def __init__(self):
self.tracker = MultiObjectTracker(dt=0.1)
def track(self, outputs, ratio):
if outputs[0] is not None:
outputs = outputs[0].cpu().numpy()
outputs = [Detection(box=box[:4] / ratio, score=box[4] * box[5], class_id=box[6]) for box in outputs]
else:
outputs = []
self.tracker.step(detections=outputs)
tracks = self.tracker.active_tracks()
return tracks
imageflow_demoを以下のように変更します。
def imageflow_demo(predictor, vis_folder, current_time, args):
mot = MOT()
cap = cv2.VideoCapture(args.path if args.demo == "video" else args.camid)
width = cap.get(cv2.CAP_PROP_FRAME_WIDTH) # float
height = cap.get(cv2.CAP_PROP_FRAME_HEIGHT) # float
fps = cap.get(cv2.CAP_PROP_FPS)
if args.save_result:
save_folder = os.path.join(
vis_folder, time.strftime("%Y_%m_%d_%H_%M_%S", current_time)
)
os.makedirs(save_folder, exist_ok=True)
if args.demo == "video":
save_path = os.path.join(save_folder, os.path.splitext(args.path.split("/")[-1])[0] + '.mp4')
else:
save_path = os.path.join(save_folder, "camera.mp4")
logger.info(f"video save_path is {save_path}")
vid_writer = cv2.VideoWriter(
save_path, cv2.VideoWriter_fourcc(*"mp4v"), fps, (int(width), int(height))
)
while True:
ret_val, frame = cap.read()
if ret_val:
outputs, img_info = predictor.inference(frame)
#result_frame = predictor.visual(outputs[0], img_info, predictor.confthre)
result_frame = frame
tracks = mot.track(outputs, img_info['ratio'])
for trc in tracks:
draw_track(result_frame, trc, thickness=1)
if args.save_result:
vid_writer.write(result_frame)
else:
cv2.imshow('frame', result_frame)
ch = cv2.waitKey(1)
if ch == 27 or ch == ord("q") or ch == ord("Q"):
break
else:
break
先ほどと同じように、python tools/demo.py video -n yolox-s -c .\weights\yolox_s.pth --path MOT16-13-raw.webmを実行すると以下のような動画が表示されると思います。

動画を見てみると、それぞれのbounding boxの右上に個別のIDが割り振られていて、同じ物体のIDはフレームが異なっても変わっていません。
まとめ
YOLOXとmotpyを使ってMOTをやってみました。bounding boxごとに個別のIDを取れれば、代表点を取って物体の速度を予測したり、撮影範囲にどれくらい滞在したかの情報を取得したりすることができます。最後にMOTしたときのdemo.pyの全文を掲載するので、面倒な人はコピペでどうぞ。
ソースコード全文
import argparse
import os
import time
from loguru import logger
import cv2
import torch
# add
from motpy import Detection, MultiObjectTracker
from motpy.testing_viz import draw_track
from yolox.data.data_augment import ValTransform
from yolox.data.datasets import COCO_CLASSES
from yolox.exp import get_exp
from yolox.utils import fuse_model, get_model_info, postprocess, vis
IMAGE_EXT = [".jpg", ".jpeg", ".webp", ".bmp", ".png"]
def make_parser():
parser = argparse.ArgumentParser("YOLOX Demo!")
parser.add_argument(
"demo", default="image", help="demo type, eg. image, video and webcam"
)
parser.add_argument("-expn", "--experiment-name", type=str, default=None)
parser.add_argument("-n", "--name", type=str, default=None, help="model name")
parser.add_argument(
"--path", default="./assets/dog.jpg", help="path to images or video"
)
parser.add_argument("--camid", type=int, default=0, help="webcam demo camera id")
parser.add_argument(
"--save_result",
action="store_true",
help="whether to save the inference result of image/video",
)
# exp file
parser.add_argument(
"-f",
"--exp_file",
default=None,
type=str,
help="pls input your experiment description file",
)
parser.add_argument("-c", "--ckpt", default=None, type=str, help="ckpt for eval")
parser.add_argument(
"--device",
default="cpu",
type=str,
help="device to run our model, can either be cpu or gpu",
)
parser.add_argument("--conf", default=0.3, type=float, help="test conf")
parser.add_argument("--nms", default=0.3, type=float, help="test nms threshold")
parser.add_argument("--tsize", default=None, type=int, help="test img size")
parser.add_argument(
"--fp16",
dest="fp16",
default=False,
action="store_true",
help="Adopting mix precision evaluating.",
)
parser.add_argument(
"--legacy",
dest="legacy",
default=False,
action="store_true",
help="To be compatible with older versions",
)
parser.add_argument(
"--fuse",
dest="fuse",
default=False,
action="store_true",
help="Fuse conv and bn for testing.",
)
parser.add_argument(
"--trt",
dest="trt",
default=False,
action="store_true",
help="Using TensorRT model for testing.",
)
return parser
def get_image_list(path):
image_names = []
for maindir, subdir, file_name_list in os.walk(path):
for filename in file_name_list:
apath = os.path.join(maindir, filename)
ext = os.path.splitext(apath)[1]
if ext in IMAGE_EXT:
image_names.append(apath)
return image_names
class Predictor(object):
def __init__(
self,
model,
exp,
cls_names=COCO_CLASSES,
trt_file=None,
decoder=None,
device="cpu",
fp16=False,
legacy=False,
):
self.model = model
self.cls_names = cls_names
self.decoder = decoder
self.num_classes = exp.num_classes
self.confthre = exp.test_conf
self.nmsthre = exp.nmsthre
self.test_size = exp.test_size
self.device = device
self.fp16 = fp16
self.preproc = ValTransform(legacy=legacy)
if trt_file is not None:
from torch2trt import TRTModule
model_trt = TRTModule()
model_trt.load_state_dict(torch.load(trt_file))
x = torch.ones(1, 3, exp.test_size[0], exp.test_size[1]).cuda()
self.model(x)
self.model = model_trt
def inference(self, img):
img_info = {"id": 0}
if isinstance(img, str):
img_info["file_name"] = os.path.basename(img)
img = cv2.imread(img)
else:
img_info["file_name"] = None
height, width = img.shape[:2]
img_info["height"] = height
img_info["width"] = width
img_info["raw_img"] = img
ratio = min(self.test_size[0] / img.shape[0], self.test_size[1] / img.shape[1])
img_info["ratio"] = ratio
img, _ = self.preproc(img, None, self.test_size)
img = torch.from_numpy(img).unsqueeze(0)
img = img.float()
if self.device == "gpu":
img = img.cuda()
if self.fp16:
img = img.half() # to FP16
with torch.no_grad():
t0 = time.time()
outputs = self.model(img)
if self.decoder is not None:
outputs = self.decoder(outputs, dtype=outputs.type())
outputs = postprocess(
outputs, self.num_classes, self.confthre,
self.nmsthre, class_agnostic=True
)
logger.info("Infer time: {:.4f}s".format(time.time() - t0))
return outputs, img_info
def visual(self, output, img_info, cls_conf=0.35):
ratio = img_info["ratio"]
img = img_info["raw_img"]
if output is None:
return img
output = output.cpu()
bboxes = output[:, 0:4]
# preprocessing: resize
bboxes /= ratio
cls = output[:, 6]
scores = output[:, 4] * output[:, 5]
vis_res = vis(img, bboxes, scores, cls, cls_conf, self.cls_names)
return vis_res
class MOT:
def __init__(self):
self.tracker = MultiObjectTracker(dt=0.1)
def track(self, outputs, ratio):
if outputs[0] is not None:
outputs = outputs[0].cpu().numpy()
outputs = [Detection(box=box[:4] / ratio, score=box[4] * box[5], class_id=box[6]) for box in outputs]
else:
outputs = []
self.tracker.step(detections=outputs)
tracks = self.tracker.active_tracks()
return tracks
def image_demo(predictor, vis_folder, path, current_time, save_result):
if os.path.isdir(path):
files = get_image_list(path)
else:
files = [path]
files.sort()
for image_name in files:
outputs, img_info = predictor.inference(image_name)
result_image = predictor.visual(outputs[0], img_info, predictor.confthre)
if save_result:
save_folder = os.path.join(
vis_folder, time.strftime("%Y_%m_%d_%H_%M_%S", current_time)
)
os.makedirs(save_folder, exist_ok=True)
save_file_name = os.path.join(save_folder, os.path.basename(image_name))
logger.info("Saving detection result in {}".format(save_file_name))
cv2.imwrite(save_file_name, result_image)
ch = cv2.waitKey(0)
if ch == 27 or ch == ord("q") or ch == ord("Q"):
break
# change
def imageflow_demo(predictor, vis_folder, current_time, args):
mot = MOT()
cap = cv2.VideoCapture(args.path if args.demo == "video" else args.camid)
width = cap.get(cv2.CAP_PROP_FRAME_WIDTH) # float
height = cap.get(cv2.CAP_PROP_FRAME_HEIGHT) # float
fps = cap.get(cv2.CAP_PROP_FPS)
if args.save_result:
save_folder = os.path.join(
vis_folder, time.strftime("%Y_%m_%d_%H_%M_%S", current_time)
)
os.makedirs(save_folder, exist_ok=True)
if args.demo == "video":
save_path = os.path.join(save_folder, os.path.splitext(args.path.split("/")[-1])[0] + '.mp4')
else:
save_path = os.path.join(save_folder, "camera.mp4")
logger.info(f"video save_path is {save_path}")
vid_writer = cv2.VideoWriter(
save_path, cv2.VideoWriter_fourcc(*"mp4v"), fps, (int(width), int(height))
)
while True:
ret_val, frame = cap.read()
if ret_val:
outputs, img_info = predictor.inference(frame)
#result_frame = predictor.visual(outputs[0], img_info, predictor.confthre)
result_frame = frame
tracks = mot.track(outputs, img_info['ratio'])
for trc in tracks:
draw_track(result_frame, trc, thickness=1)
if args.save_result:
vid_writer.write(result_frame)
else:
cv2.imshow('frame', result_frame)
ch = cv2.waitKey(1)
if ch == 27 or ch == ord("q") or ch == ord("Q"):
break
else:
break
def main(exp, args):
if not args.experiment_name:
args.experiment_name = exp.exp_name
file_name = os.path.join(exp.output_dir, args.experiment_name)
os.makedirs(file_name, exist_ok=True)
vis_folder = None
if args.save_result:
vis_folder = os.path.join(file_name, "vis_res")
os.makedirs(vis_folder, exist_ok=True)
if args.trt:
args.device = "gpu"
logger.info("Args: {}".format(args))
if args.conf is not None:
exp.test_conf = args.conf
if args.nms is not None:
exp.nmsthre = args.nms
if args.tsize is not None:
exp.test_size = (args.tsize, args.tsize)
model = exp.get_model()
logger.info("Model Summary: {}".format(get_model_info(model, exp.test_size)))
if args.device == "gpu":
model.cuda()
if args.fp16:
model.half() # to FP16
model.eval()
if not args.trt:
if args.ckpt is None:
ckpt_file = os.path.join(file_name, "best_ckpt.pth")
else:
ckpt_file = args.ckpt
logger.info("loading checkpoint")
ckpt = torch.load(ckpt_file, map_location="cpu")
# load the model state dict
model.load_state_dict(ckpt["model"])
logger.info("loaded checkpoint done.")
if args.fuse:
logger.info("\tFusing model...")
model = fuse_model(model)
if args.trt:
assert not args.fuse, "TensorRT model is not support model fusing!"
trt_file = os.path.join(file_name, "model_trt.pth")
assert os.path.exists(
trt_file
), "TensorRT model is not found!\n Run python3 tools/trt.py first!"
model.head.decode_in_inference = False
decoder = model.head.decode_outputs
logger.info("Using TensorRT to inference")
else:
trt_file = None
decoder = None
predictor = Predictor(model, exp, COCO_CLASSES, trt_file, decoder, args.device, args.fp16, args.legacy)
current_time = time.localtime()
if args.demo == "image":
image_demo(predictor, vis_folder, args.path, current_time, args.save_result)
elif args.demo == "video" or args.demo == "webcam":
imageflow_demo(predictor, vis_folder, current_time, args)
if __name__ == "__main__":
args = make_parser().parse_args()
exp = get_exp(args.exp_file, args.name)
main(exp, args)
-
https://medium.com/axinc/yolox-yolov55を超える物体検出モデル-e9706e15fef2 ↩
-
YOLOX: Exceeding YOLO Series in 2021 https://arxiv.org/abs/2107.08430 ↩