日本大学文理学部にはパンダがいる
5歳のシャンシャンが中国に返還されて半年以上が経過し、多くの日本国民が悲しみを少し忘れかけていた頃、日本大学文理学部のキャンパスがある千代田区には、17歳で居続けるパンダがいる。
良いアイコンですね。
なんとなく自分もアイコンを作りたいなと思い続けて、気づいたら着任して3年目、そろそろアイコンを作らないと任期が終わる。。。 こんにちは、Sabbrovski Endiです。
任期が終わる前に人気の出そうなアイコンを作る、ということで、
「こういうイメージのアイコンを作りたい、というのを適当に指示したらなんかよしなに作ってくれる」
そういうのを今から簡単に試してみようと思います。
Stable Diffusionについて
なんとなく動作原理も解説したら長くなって書いた感のある記事になるかと思いましたが、 QiitaはStable Diffusionの解説記事や、触ってみたという記事で実は溢れかえっています。私がこれから解説を書いたとしても、特別何かそれらと差のあるものは書けないでしょう。
実際、基本的なDiffusionモデルの動作原理を知るぐらいなら
https://qiita.com/omiita/items/ecf8d60466c50ae8295b
こういう記事や、動かすだけなら
https://qiita.com/deg84/items/4f44af83397d95b4dfd3
https://qiita.com/sowallows10/items/2bcb57b6b2c3a0ef92c2
この辺りの記事を見れば良いと思います。
今回は、金の匂いがしないからQiita上では人気のない"非商用"のDeepFloydIFを試してみようと思います。今回はGoogle Colab上で課金したものを使おうと思います。というか、色々試してみたところ、DeepFloydはColabの無料枠で動かすにはメモリの制約が厳しいのと、何回かColabが落ちたりするので、やむなくという感じです。(どうりでQiitaではDeepFloydの記事が少ないわけだ・・・)
DeepFloydIFの使用に向けて、アクセストークンの生成
StableDiffusionを使いたい人は、まずHagging Faceにユーザー登録をしましょう。
https://huggingface.co/join
アカウントを作ったら、DeepFloydIFのページにアクセスします。
https://huggingface.co/DeepFloyd/IF-I-XL-v1.0
DeepFloydIFは最初のライセンス同意のあたりが少々めんどくさいです。広く知られているMIT Licenceなどとは異なり、長いライセンス文を読まないといけません。ただし、この辺をいい加減にかいつまんで読む人はエンジニアになってはいけない人なのでちゃんと読みましょう。
https://huggingface.co/spaces/DeepFloyd/deepfloyd-if-license
(要約すると〜です。みたいな記事も世の中に散見されますが、ライセンスの要約だけ読んで本文を読まない人はこういうのむやみに使わない方がいいです。)
そして、ライセンスの内容に同意できるのであれば、Organization/Affiliationを埋めて (email and usernameと書いてあるのでそれを入れる)、Previously related publicationsを入れます。基本的にPreviously related publicationsは空でもいいと思います。そして同意しましょう。
その後、HaggingFaceのUser access tokensを作っておきます。
作り方
https://huggingface.co/docs/hub/security-tokens#what-are-user-access-tokens
作る際に、Roleがreadになっていますが、writeにしておきましょう。
名前は、恥ずかしくないものなら基本的になんでもいいです。
これで事前準備は終わりです。
Google Colabで準備
まずはGoogle Colabを起動して、ランタイムをGPUに変えましょう。

こんな感じで、接続ボタンの近くにある▼マークから「ランタイムのタイプを変更」をクリックすると設定を変えることができます。
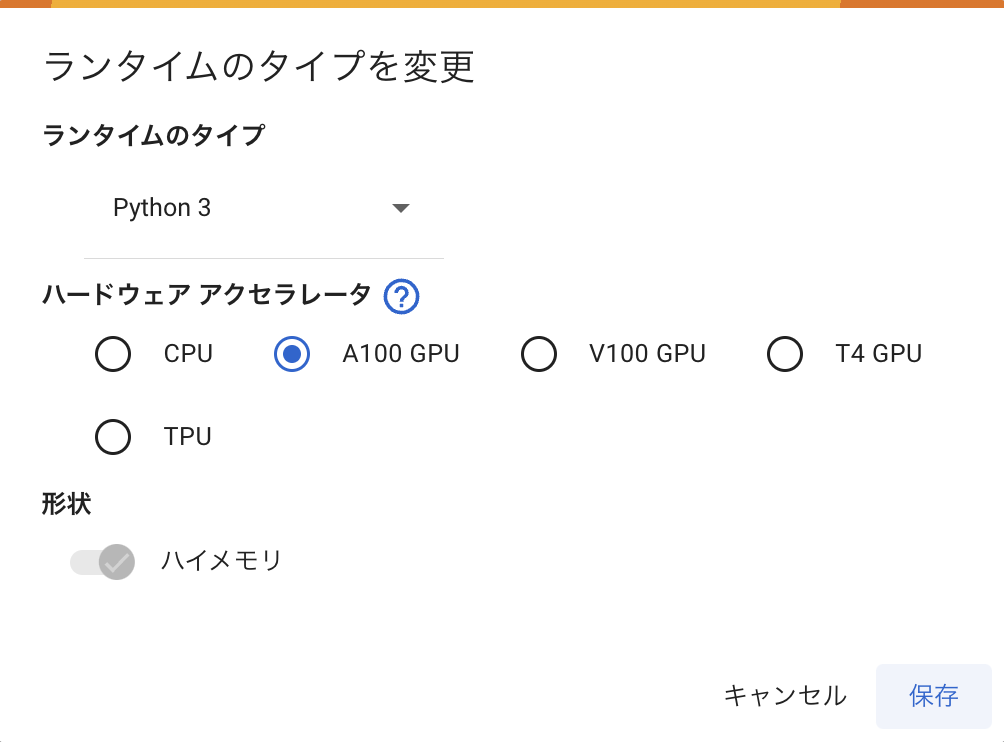
有料版だとGPUが色々選べます。DeepFloydを動かすなら、V100かA100あたりのメモリが必要なので、A100あるいはV100を推奨します。
ちゃんとGPUが認識できているかどうかは、いくつか確認する方法がありますが、基本的には
!nvidia-smi
これをColab上で実行してもらえればOKです。GPUが認識できていれば、ランタイムの設定で貼ったスクショのように、認識されているGPUの情報がざっと出てくるはずです。
無事にGPUが認識できたら、DeepFloydを動かすために必要なライブラリをインストールしましょう。
# Deep-Fyoidに必要なライブラリのインストール
! pip install --upgrade \
diffusers~=0.16 \
transformers~=4.28 \
safetensors~=0.3 \
sentencepiece~=0.1 \
accelerate~=0.18 \
bitsandbytes~=0.38 \
torch~=2.0 -q
# haggingface_hubのアップデート
!pip install huggingface_hub --upgrade
ただし、若干バージョンの古いライブラリがあって、torch周りの依存性を解決しないといけないですが、今回のモデルを動かす部分では特に問題ないので公式ドキュメントのものをそのまま使います。
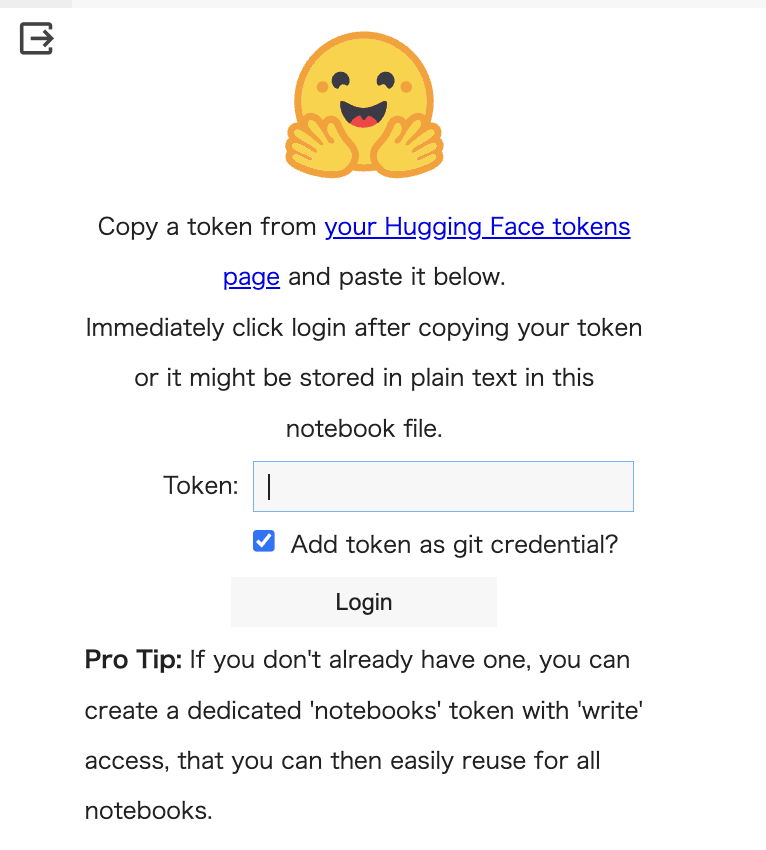
そして、HaggingFaceにログインをします。
# haggingfaceへのログイン(writeトークンが必要)
from huggingface_hub import login
login()
そうすると、パァッ(ᐛ👐) が出てくるので
https://huggingface.co/settings/tokens
よりwrite権限で作っておいたtokenを貼り付けてログインしましょう。
DeepFloydのモデル準備
DeepFloydは、大きく3つのステージに分かれていて、各ステージの途中でも画像の生成結果を見ることができます。最初のステージで96x96, 2つ目のステージで256x256, 最後のステージで1024x1024のサイズの画像ができます。私が作りたいのはステージ2までで十分ですし、256x256の画像を作るようにしてみます。とはいえ、ただサイズアップするだけなら、96x96でもいい気がしてきたので、stage1までの出力で色々試してみようと思います。
コードは単純です。先ほどまでの準備があれば、あとはモデルをステージごとに読み込むだけです。
# モデル呼び出し(stage1:96x96,stage2:256x256)
from diffusers import DiffusionPipeline
from diffusers.utils import pt_to_pil
import torch
# stage 1
stage_1 = DiffusionPipeline.from_pretrained("DeepFloyd/IF-I-XL-v1.0", variant="fp16", torch_dtype=torch.float16)
stage_1.enable_model_cpu_offload()
# stage 2 ※画像を大きくしたい人はここのコメントアウトを外す
'''
stage_2 = DiffusionPipeline.from_pretrained("DeepFloyd/IF-II-L-v1.0", text_encoder=None, variant="fp16", torch_dtype=torch.float16)
stage_2.enable_model_cpu_offload()
'''
あとは、プロンプトに応じて画像が描画されるように、関数を一つ作ったら終わりです。
画像をColabにアクセスしているアカウントのドライブ上に保存するため、以下のようにします。
from google.colab import drive
drive.mount('/content/drive')
def make_image(prompt):
prompt_embeds, negative_embeds = stage_1.encode_prompt(prompt)
generator = torch.manual_seed(0)
image = stage_1(prompt_embeds=prompt_embeds, negative_prompt_embeds=negative_embeds, generator=generator, output_type="pt").images
# ↓は256x256にしたい時にコメントアウトを外す
#image = stage_2(image=image, prompt_embeds=prompt_embeds, negative_prompt_embeds=negative_embeds, generator=generator, output_type="pt").images
pt_to_pil(image)[0].save("./drive/MyDrive/Images/"+prompt+".png")
最後の
pt_to_pil(image)[0].save("./drive/MyDrive/Images/"+prompt+".png")
を編集すれば、好きなところに保存できます。
Colab上で保存したファイルは、左にあるフォルダのアイコンをクリックしたら、マウントしたドライブの中身が確認できます。
試しに、好きな動物に関するプロンプトを入れて描画してみます。
描画するのは非常に簡単
sample_prompt = "Brown Anime Owl with white background"
make_image(sample_prompt)
DeepFloydのプロンプトは英語で書く必要があります。まあ昨今だと直訳をDeepLでやってもらえればいいだけなので、大した手間ではないと思いますが・・・
作られた画像はこれ、まあまあ指示に忠実って感じですね。

さて、今回は最終目標のアイコン作りなので、色々と思っているプロンプトを試してみて、make_image関数を何回か回してみると・・・!


なぜか顔が見切れている亀ばっかり生成されます。しかもやや気持ち悪い。
欲しいアイコンを作るのは、結構難しいんですね。
おわりに
とりあえず綺麗な画像を作ってくれるDiffusionモデルを色々なプロンプトで試してみたい、と思いましたが、プロンプト職人ってのは頑張ってるんだなあと思いました。
ここまでのColabの実装はここで公開しています。無料版だと動かないですが、Colabに貢いで試してみてください。
https://colab.research.google.com/drive/16H0P-wNkVRKP0zUICg5q9copucTZ7_-e?usp=sharing