1. はじめに
仮想通貨の値動きは株式やFX等の既存の金融市場と比べて激しいため、上手く値動きを予測してシステムトレードを実装すれば高い収益を得られるのでは?と考えこの記事を作成しました。
1.1 記事の概要
本稿では前編と後編にわたってディープラーニングを用いた仮想通貨の収益率予測とPyhonによる自動売買Botの実装について書いていきたいと思います。今回の前編で予測モデルの作成を中心に行っていき、次回の後編では自動売買をしていきます。
1.2 構成
前編
WaveNetと呼ばれる深層学習により仮想通貨の1時間足の収益率を予測するモデルを構築し、結果の検証を行う。また作成した予測モデルを使って特定の時間の予測結果を返す簡易WEBアプリをFlaskを使って作成する。
後編
前編で作成した予測モデルを用いて自動売買を行うスクリプトファイルを作成する。
1.3 環境・使用ツール等
- Python3.9
- google colaboratory
ディープラーニングの学習を行うためGPUを使用 - GMOコインのAPIキー
仮想通貨の価格を取得するために使用 - heroku
WEBアプリをデプロイするために使用
1.4 WaveNetとは
CNNを何層にもわたって重ねたネットワークであり、残差ブロックとスキップコネクションをネットワーク全体に採用することで、より深い学習と多様な特徴抽出を可能にする。
WaveNetのCNNでは時系列データに対してConvolutionを組み込んでおり、層が深くなるにつれて畳み込むユニットをスキップする仕組みとなっている。(Dilated Causal Convolution)
入力から出力までの流れは下図のようになる。
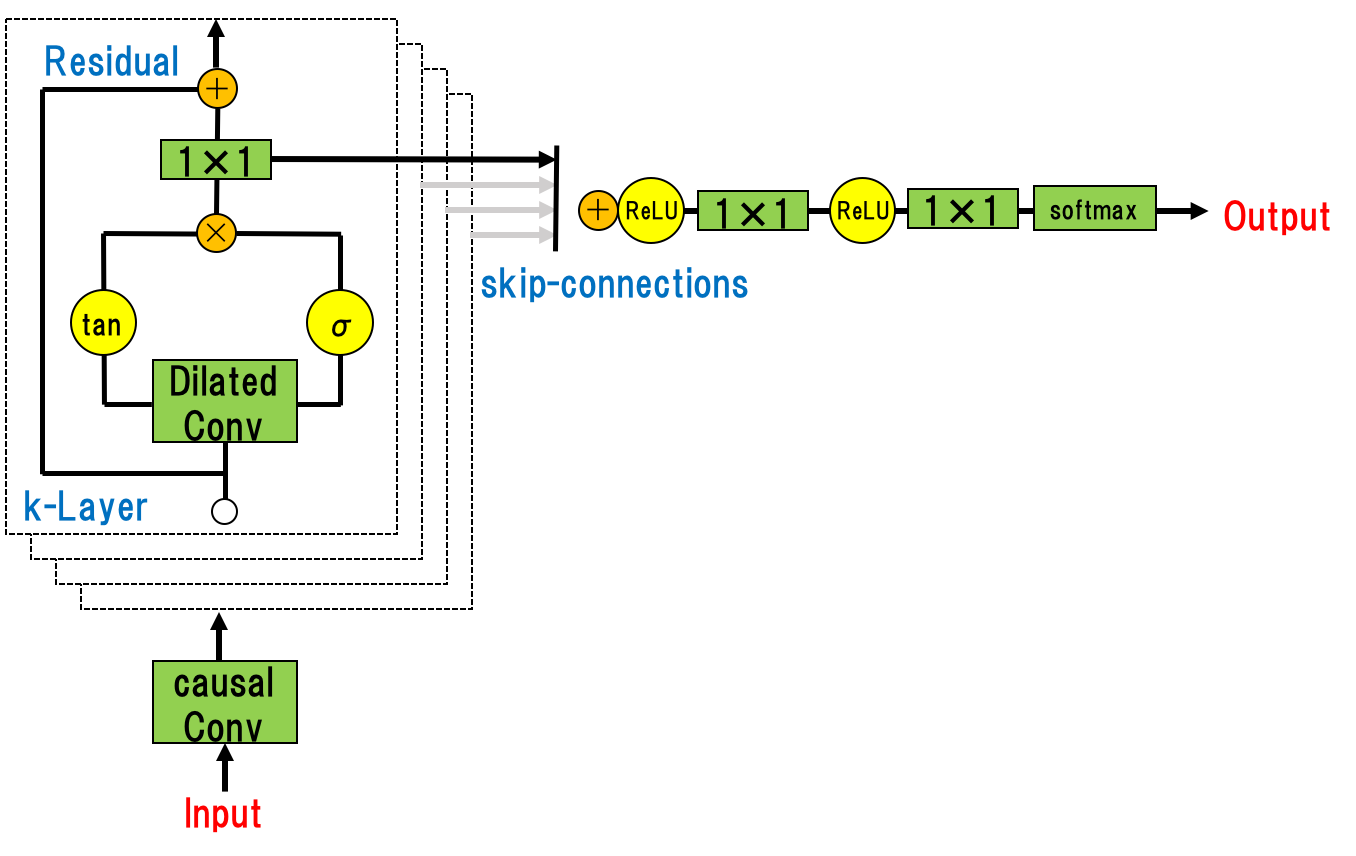
引用 https://arxiv.org/pdf/1609.03499.pdf
WaveNetについて詳しくはこちらを参照。
今回はこれをビットコインのリターン予測に応用する。
2. 予測モデルの作成
WaveNetを使って収益率の予測を行う。
使用したデータは2021/06/07~2022/10/01
2.1 データ取得
GMOコインのAPIドキュメントを参考に1時間足データを集める。
デフォルトだと1日分のデータしか取ることができないため、長期間のデータを取得するために以下のコードを実装した。
ここでは2022年10月1日までの480日分の1時間足データを集めている。
今回使うデータはBitcoinとEthereumの始値、終値、高値、低値、取引高。
import json
import numpy as np
import pandas as pd
import requests
from datetime import datetime
from datetime import timedelta
def get_data(symbol='BTC', interval='1hour', date=''):
'''1日分の1時間足データを取得する'''
endPoint = 'https://api.coin.z.com/public'
path = f'/v1/klines?symbol={symbol}&interval={interval}&date={date}'
response = requests.get(endPoint + path)
r = json.dumps(response.json(), indent=2)
r2 = json.loads(r)
df = json_normalize(r2['data'])
# 日本時間に変える
if len(df):
date = []
for i in df['openTime']:
i = int(i)
tsdate = int (i / 1000)
loc = datetime.utcfromtimestamp(tsdate)
date.append(loc)
df.index = date
df.index = df.index.tz_localize('UTC')
df.index = df.index.tz_convert('Asia/Tokyo')
df.drop('openTime', axis=1, inplace=True)
return df
today = '20221001'
# 'YYYYMMDD'の形式で1日前を取得
day = datetime.strptime(today, '%Y%m%d')
day -= timedelta(days=1)
day = str(day)
day = day.replace('-', '')
day = day.replace(' 00:00:00', '')
# ビットコインとイーサリアムの価格を取得
btc_today = get_data(symbol='BTC_JPY', interval='1hour', date=day)
eth_today = get_data(symbol='ETH_JPY', interval='1hour', date=day)
if len(eth_today) == 0:
eth_today = pd.DataFrame(data=np.array([[None for i in range(24)] for i in range(5)]).T, index=btc_today.index, columns=['eth_open', 'eth_high', 'eth_low', 'eth_close', 'eth_volume'])
eth_today.columns = ['eth_open', 'eth_high', 'eth_low', 'eth_close', 'eth_volume']
df = pd.concat([btc_today, eth_today], axis=1)
for i in range(480):
# 480日分取得
day = datetime.strptime(day, '%Y%m%d')
day -= timedelta(days=1)
day = str(day)
day = day.replace('-', '')
day = day.replace(' 00:00:00', '')
btc = get_data(symbol='BTC_JPY', interval='1hour', date=day)
eth = get_data(symbol='ETH', interval='1hour', date=day)
if len(eth) == 0:
eth = pd.DataFrame(data=np.array([[None for i in range(24)] for i in range(5)]).T, index=btc.index, columns=['eth_open', 'eth_high', 'eth_low', 'eth_close', 'eth_volume'])
eth.columns = ['eth_open', 'eth_high', 'eth_low', 'eth_close', 'eth_volume']
tmp_df = pd.concat([btc, eth], axis=1)
df = pd.concat([tmp_df, df], axis=0)
2.2 前処理
以下の手順でデータの前処理を行う。
-
目的変数の作成
終値を始値で割り、対数変換したものを収益率とする。
1時間後の収益率を予測するモデルを作成する。 -
欠損値穴埋め
イーサリアムの価格が2か所欠損だったため前の時間の値で埋める。 -
特徴量生成
ビットコインの始値、終値、高値、低値、イーサリアムの始値、終値、マーケットの方向性(収益率がプラスであれば1, そうでなければ-1)を特徴量として用いる。
また、どれくらい前までの情報を含むかが重要となるが、今回はそのシーケンスの幅を20とする。つまり、20時間分のデータを用いて1時間後の収益率を予測する。 -
window normalization
データのスケーリング手法として今回はwindow normalizationを用いる。各ウィンドウごとに正規化をしていくというもので、各windowのi番目の値は以下のように変換される。
$n_i = \frac{p_i}{p_0} - 1$
詳しくはこちらの記事を参照。
import numpy as np
import pandas as pd
from numpy.lib.stride_tricks import sliding_window_view
# イーサリアムの価格が2か所欠損だったため前の時間の値で埋める
df.fillna(method='ffill', inplace=True)
df[df.columns] = df[df.columns].astype(float)
df['return'] = np.log(df['close'] / df['open'])
df['sign'] = df['return'].apply(lambda x: 1 if x >= 0 else -1)
open = df['open'][:-1].values
close = df['close'][:-1].values
high = df['high'][:-1].values
low = df['low'][:-1].values
sign = df['sign'][:-1].values
eth_open = df['eth_open'][:-1].values
eth_close = df['eth_close'][:-1].values
# 過去20時間分のデータを予測に使う
seqence_width = 20
open_df = sliding_window_view(open, seqence_width)
close_df = sliding_window_view(close, seqence_width)
high_df = sliding_window_view(high, seqence_width)
low_df = sliding_window_view(low, seqence_width)
sign_df = sliding_window_view(sign, seqence_width)
eth_open_df = sliding_window_view(eth_open, seqence_width)
eth_close_df = sliding_window_view(eth_close, seqence_width)
x_open = open_df[:, :, np.newaxis]
x_close = close_df[:, :, np.newaxis]
x_high = high_df[:, :, np.newaxis]
x_low = low_df[:, :, np.newaxis]
x_sign = sign_df[:, :, np.newaxis]
x_eth_open = eth_open_df[:, :, np.newaxis]
x_eth_close = eth_close_df[:, :, np.newaxis]
x_data = np.concatenate([x_open, x_close], axis=2)
x_data = np.concatenate([x_data, x_high], axis=2)
x_data = np.concatenate([x_data, x_low], axis=2)
x_data = np.concatenate([x_data, x_eth_open], axis=2)
x_data = np.concatenate([x_data, x_eth_close], axis=2)
x_data = np.concatenate([x_data, x_sign], axis=2)
# Window normalizationの定義
def normalise_windows(window_data, single_window=False):
''' window normalization'''
normalised_data = [] # 正規化したデータを格納
window_data = [window_data] if single_window else window_data
for window in window_data:
normalised_window = []
for col_i in range(window.shape[1]): # Windowの幅
# 各値を初期の値で割る
normalised_col = [((float(p) / float(window[0, col_i])) - 1) for p in window[:, col_i]]
normalised_window.append(normalised_col)
# reshape and transpose array back into original multidimensional format
normalised_window = np.array(normalised_window).T
normalised_data.append(normalised_window)
return np.array(normalised_data)
x_data = normalise_windows(x_data)
y_data = df['return'][seqence_width:]
2.3 データセット分割
得られたデータセットを時系列順に学習用、検証用、テスト用に分割する。
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, shuffle=False)
x_tr, x_valid, y_tr, y_valid = train_test_split(x_train, y_train, test_size=0.2, shuffle=False)
2.4 学習
WaveNetの構築する。構築方法についてはこちらのサイトを参考にした。
調整するパラメータは以下の通り。
- num_filters: 畳み込み層のフィルター数
- kernel_size: 畳み込み層のカーネルサイズ
- stacked_layer: 積み重ねる残差ブロックの数(今回は5層で行う)
- batchsize: バッチサイズ
- lr: 学習率
import tensorflow as tf
from keras.layers import Input
from tensorflow import keras
from tensorflow.keras import backend as K
from tensorflow.keras.utils import get_custom_objects
from tensorflow.keras.layers import Activation
def mish(x):
'''活性化関数の定義'''
return tf.keras.layers.Lambda(lambda x: x*K.tanh(K.softplus(x)))(x)
get_custom_objects().update({'mish': Activation(mish)})
def WaveNetResidualConv1D(num_filters, kernel_size, stacked_layer):
'''WaveNetの構築'''
def build_residual_block(l_input):
resid_input = l_input
for dilation_rate in [2**i for i in range(stacked_layer)]:
l_sigmoid_conv1d = tf.keras.layers.Conv1D(num_filters, kernel_size, dilation_rate=dilation_rate, padding='same', activation='sigmoid')(l_input)
l_tanh_conv1d = tf.keras.layers.Conv1D(num_filters, kernel_size, dilation_rate=dilation_rate, padding='same', activation='mish')(l_input)
l_input = tf.keras.layers.Multiply()([l_sigmoid_conv1d, l_tanh_conv1d])
l_input = tf.keras.layers.Conv1D(num_filters, 1, padding='same')(l_input)
resid_input = tf.keras.layers.Add()([resid_input, l_input])
return resid_input
return build_residual_block
# 学習
# パラメータの設定
num_filters_ = 16
kernel_size_ = 8
stacked_layers_ = [20, 12, 8, 4, 1]
batchsize=128
lr=0.0001
shape_ = (None, x_train.shape[2])
l_input = Input(shape=(shape_))
x = tf.keras.layers.Conv1D(num_filters_, 1, padding='same')(l_input)
x = WaveNetResidualConv1D(num_filters_, kernel_size_, stacked_layers_[0])(x)
x = tf.keras.layers.Conv1D(num_filters_*2, 1, padding='same')(l_input)
x = WaveNetResidualConv1D(num_filters_*2, kernel_size_, stacked_layers_[1])(x)
x = tf.keras.layers.Conv1D(num_filters_*4, 1, padding='same')(l_input)
x = WaveNetResidualConv1D(num_filters_*4, kernel_size_, stacked_layers_[2])(x)
x = tf.keras.layers.Conv1D(num_filters_*8, 1, padding='same')(l_input)
x = WaveNetResidualConv1D(num_filters_*8, kernel_size_, stacked_layers_[3])(x)
x = tf.keras.layers.Conv1D(num_filters_*16, 1, padding='same')(l_input)
x = WaveNetResidualConv1D(num_filters_*16, kernel_size_, stacked_layers_[4])(x)
x = tf.keras.layers.GlobalMaxPooling1D()(x)
l_output = tf.keras.layers.Dense(1)(x)
model = tf.keras.Model(inputs=[l_input], outputs=[l_output])
optimizer = keras.optimizers.Adam(learning_rate=lr)
model.compile(loss='mse', optimizer=optimizer)
es_callback = keras.callbacks.EarlyStopping(monitor='val_loss', patience=5)
history = model.fit(x_train, y_train, validation_data=[x_valid, y_valid], callbacks=[es_callback], epochs=200, batch_size=batchsize)
2.5 結果
検証用のデータを用いてモデルの精度を算出する。
予測結果がプラスであれば買い、マイナスであれば売りと判断して収益率を算出する。
-
各種指標の明示
WaveNetによる予測の正解率とすべてのタームにおいて買いと判断した場合やバイアンドホールドとWaveNetによる予測を行った場合のリターンを比較する。
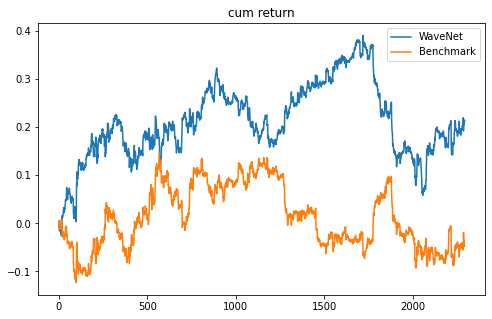
結果的に正解率が51.5%、利益率が21.2%となりベンチマーク(-4.8%)やバイアンドホールド(-1.6%)を上回った。 -
グラフによる可視化
累積収益率のグラフをみてもおおよそずっとベンチマークを上回っている。
from sklearn.metrics import accuracy_score
print('評価データのMSE')
print(model.evaluate(x_test, y_test))
print('---------------------------------------------------')
print('買い(1.0)と売り(-1.0)の回数')
print(pd.DataFrame(np.sign(model.predict(x_test))).value_counts())
y_pred = model.predict(x_test)
predict_df = pd.DataFrame(y_pred, columns=['predict'])
predict_df['predict'] = predict_df['predict'].apply(lambda x: 1 if x >= 0 else -1)
return_df = pd.DataFrame(df[['open', 'return', 'sign']][-y_test.shape[0]:])
return_df.reset_index(drop=True, inplace=True)
df2 = pd.concat([return_df, predict_df], axis=1)
df2['strategy'] = df2['return']*df2['predict']
print('テスト期間の利益: ', df2['strategy'].sum())
print('ベンチマーク: ', df2['return'].sum())
print('Buy and Hold: ', (df2['open'][y_test.shape[0]-1] - df2['open'][1]) / df2['open'][1])
print('正解率', accuracy_score(df2['predict'], df2['sign']))
評価データのMSE
72/72 [==============================] - 0s 4ms/step - loss: 1.1577e-04
0.00011576819088077173
---------------------------------------------------
買い(1.0)と売り(-1.0)の回数
-1.00 1319
1.00 974
dtype: int64
テスト期間の利益: 0.212247289412898
ベンチマーク: -0.0478711836247418
Buy and Hold: -0.016113039686000873
正解率 0.5154819014391626
print('累積リターン')
plt.figure(figsize=(8, 5))
plt.plot(df2['strategy'].dropna().cumsum(), label='WaveNet')
plt.plot(df2['return'].dropna().cumsum(), label='Benchmark')
plt.legend()
plt.title('cum return')
plt.show()
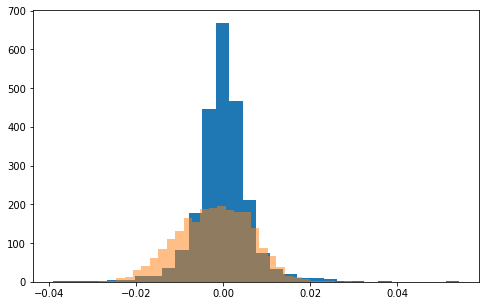
print('リターンの分布')
plt.figure(figsize=(8, 5))
plt.hist(y_test, bins=30, alpha=1)
plt.hist(y_pred, bins=30, alpha=0.5)
plt.show()
3. Flaskで予測結果を返すアプリを作成
herokuを使って、収益率を予測するアプリを公開した。
3.1 アプリ概要
年月日時を入力すると、先ほどのセクションで作成したWaveNetモデルにより該当日時におけるマーケットの方向性(プラスorマイナス)が表示される。比較のためWaveNet以外にもLogisticモデルとLightGBMも選択可能。
またVisualizeページでは入力日数分の過去の価格推移グラフが表示される。
3.2 ディレクトリ構成
コード詳細はGitHubを参照。
https://github.com/SY122095/BTC_prediction_app
┣━ app
┃ ┣━ app.py # アプリケーション本体とエンドポイントを記述
┃ ┣━ static
┃ ┃ ┗━ style.css # cssファイル
┃ ┗━ templates
┃ ┣━ index.html # トップページ
┃ ┗━ visualize.html # 可視化ページ
┣━ data
┃ ┣━ make_data.py # データセットを作成する関数を記述
┃ ┗━ data.csv # 予測に用いるデータ
┣━ features
┃ ┗━ build_features.py # 特徴量を生成する関数を記述
┣━ models
┃ ┣━ models.py # モデルを構築する関数を記述
┃ ┣━ wavenet.h5 # WaveNetモデル
┃ ┣━ lgbm.pickle # LightGBM
┃ ┗━ logistic.pickle # Logisticモデル
┣━ prep.py # 最新データの取得からモデルの更新までを行う
┣━ run.py # アプリケーションを読み込んで起動する
┣━ Procfile
┣━ requirement.txt
┣━ runtime.txt
┗━ upload.bat # prep.pyを実行してherokuにpushするバッチファイル
3.3 データ更新の頻度
バッチファイルを毎日0時に実行して、最新のデータを取得しモデルを更新している。
4. 補足
- 今回の検証期間ではWaveNetを用いた予測のほうがバイアンドホールドよりも大きなリターンを生み出す結果となったが、期間を変えるとあまりリターンが大きくなかったりロジスティックモデルで予測したほうが精度が高かったりもしたため、有効な特徴量を増やすことや複数モデルによるアンサンブルを実施する必要性を感じた。
- 試しに'bitcoin'をキーワードとするGoogle Trendを特徴量として用いたが精度の向上にはつながらなかった。おそらくポジティブな情報とネガティブな情報が出た時にどちらの場合でも数値が大きくなるためだと思われる。そのためTwiiter APIを用いて取得したツイートに対して感情分析を行うと良いかもしれない。
- S&P500やNVIDIAの株価を特徴量として用いた時もGoogle Trendの場合と同様に精度の向上にはあまり寄与しなかった。よりオンチェーン分析を深く行っていくほうが効果的かもしれない。