はじめに
今更WaveNetの解説?と思われる方もいると思いますが、個人的に得られる知見が多かったディープラーニングのモデルだったので、実装した当時のメモや記憶を頼りにアウトプットしていきたいと思います。
ソースコードはgithubで公開しています。
https://github.com/kshina76/keras_wavenet
環境
python3.7.3
Anaconda3
keras2.2.4
tensorflow1.13.1
WaveNetとは
CNN(畳み込みニューラルネットワーク)を何層にもわたって構築されたネットワーク。論文が発表された当初、とても流暢な英語や日本語を発声させることができるとして話題になった技術でした。論文が発表される以前の音声合成では、機械に発声させるとロボットのような声でとても人間とは程遠い発声でしたが、WaveNetの登場により、人間の声なのか機械が作り出した声なのか判別できなくなるほどのものを作り上げることができるようになりました。
音声の研究者も「このような音声合成技術ができるのに10年はかかると思った」といわれるほど、衝撃的な技術だったそうです。
また、WaveNetはGoogle assistantに音声合成技術として搭載されているようです。
詳しいモデル構成を説明するにあたって、まずはデータの取り扱いや前処理について説明する必要があるので、そのことを説明したのちにモデル構成の説明に入っていこうと思います。
データの前処理
今回は、音声データとしてvctk corpusを使用しました。
無音区間の除去
WaveNetでは、切り出した音声区間がすべて無音だと、無音を学習してしまうことにより生成する音声が無音になってしまうという不具合があるそうです。なので、まずは無音区間の除去を行うことにします。
※指定した音声区間とは、receptive field(受容野)という区間のことで、説明は後述するので、ここではWaveNetの学習の際に入力するサンプル長だと思ってください。
音声データ取得
まずは、音声ファイルのパスを一覧取得するメソッドを実装します。directoryには、複数の音声ファイルが置かれているディレクトリを指定してください。
def get_files(self, directory):
files = []
for dir_path,dir_name,file_name in os.walk(directory):
for file_name in file_name:
files.append(os.path.join(dir_path,file_name))
return files
音声ファイルのパスから音声を取り込むメソッドを実装します。サンプリングレートは16000とします。
def get_audio(self, files, sample_rate):
for file in files:
audio, _ = librosa.load(file, sr=sample_rate)
yield audio
除去と正規化
それでは、実際に無音区間の除去を実行しましょう。今回thresholdは、20に設定しています。ついでに正規化も行っておきます。
for audio in get_audio(files, sample_rate):
audio, _ = librosa.effects.trim(audio, top_db=threshold)
audio /= np.abs(audio).max()
μ-law量子化
人間の聴覚に合わせた量子化方法。音が大きくなればなるほど粗い量子化幅になり、小さければ小さいほど細かい量子化幅になる特殊な量子化。この量子化方法により、少ない量子化ビット数でも量子化誤差の低減を可能にする。
WaveNetでは8bit量子化をしてからモデルに入力として渡すので、'mu'は256とする
def transform(x):
x = x.astype(float_type)
y = np.sign(x) * np.log(1 + mu * np.abs(x)) / np.log(1 + mu)
y = np.digitize(y, 2 * np.arange(mu) / mu - 1) - 1
return y.astype(int_type)
def itransform(y):
y = y.astype(float_type)
y = 2 * y / mu - 1
x = np.sign(y) / self.mu * ((1 + self.mu) ** np.abs(y) - 1)
return x.astype(float_type)
paddingとtrimming
今回は、WaveNetの入力として7680サンプルとるので、7680サンプルに満たない音声が入力されたら足りない分をゼロで埋める処理(ゼロパディング)をします。
逆に7680を超えている音声が入力されたら7680サンプルに合わせるようにトリミングをします。
また、切り取る区間はランダムで指定するようになっています。
if self.threshold is not None:
if len(audio) <= self.receptive_field:
# padding
pad = self.receptive_field - len(audio)
audio = np.concatenate((audio, np.zeros(pad, dtype=np.float32)))
# padding with middle of quantized audio
quantized = np.concatenate((quantized, self.quantize // 2 * np.ones(pad)))
quantized = quantized.astype(np.int64)
else:
# trimming audio into receptive_field (trimming)
start = random.randint(0, len(audio) - self.receptive_field - 1)
audio = audio[start:start + self.receptive_field]
quantized = quantized[start:start + self.receptive_field]
以上で前処理は終了しますが、実用的なWaveNetとしては、メルスペクトログラムを計算して話者の特定をすることで、自由自在なモデルを構築できるようになります。その処理をglobal conditioningといいます。githubで公開しているのでそちらを見てください。
WaveNetモデルの構築
WaveNetの全体像

上記のWaveNetモデルを3つのセクションに分けて実装していきます。
Residual Block
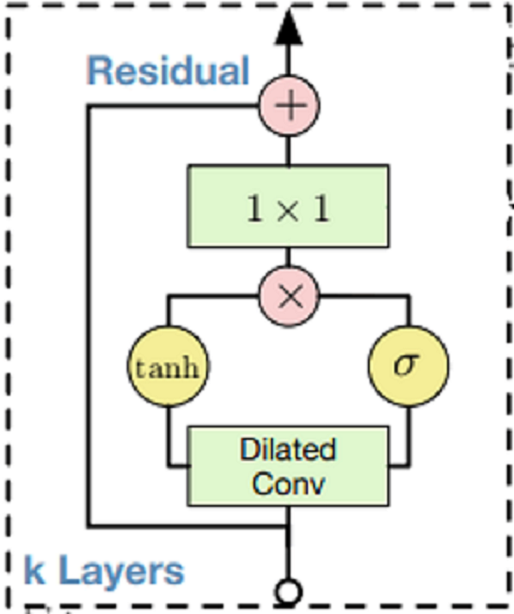
def ResidualBlock(self, block_in, dilation_index):
res = block_in
tanh_out = Conv2D(self.d_channels, (self.filter_size, 1),padding='same',
dilation_rate=(dilation_index, 1), activation='tanh')(block_in)
sigm_out = Conv2D(self.d_channels, (self.filter_size, 1), padding='same',
dilation_rate=(dilation_index, 1), activation='sigmoid')(block_in)
marged = Multiply()([tanh_out, sigm_out])
res_out = Conv2D(self.r_channels, (1,1), padding='same')(marged)
skip_out = Conv2D(self.s_channels, (1,1), padding='same')(marged)
res_out = Add()([res_out,res])
return res_out, skip_out
ResidualNet
さっき作ったResidualBlockを重ねることでResidualNetを構築していきます。

def ResidualNet(self, block_in):
skip_out_list = []
for dilation_index in self.dilation:
res_out, skip_out = self.ResidualBlock(block_in, dilation_index)
skip_out_list.append(skip_out)
block_in = res_out
return skip_out_list
WaveNet
ResidualNetとその他のactivationをつなげることでWaveNetの完成です。

def wavenet(self):
inputs = Input(shape=(self.img_rows, self.img_columns, self.a_channel))
causal_conv = Conv2D(self.r_channels, (self.filter_size, 1), padding='same')(inputs)
skip_out_list = self.ResidualNet(causal_conv)
skip_out = Add()(skip_out_list)
skip_out = Activation('relu')(skip_out)
skip_out = Conv2D(self.a_channel, (1,1), padding='same', activation='relu')(skip_out)
prediction = Conv2D(self.a_channel, (1,1), padding='same')(skip_out)
prediction = Flatten()(prediction)
prediction = Dense(self.a_channel, activation='softmax')(prediction)
model_wavenet = Model(input=inputs,output=prediction)
optimizer = Adam()
model_wavenet.compile(optimizer=optimizer,loss='categorical_crossentropy',metrics=['accuracy'])
model_wavenet.summary()
return model_wavenet