はじめに
こんにちは!
ソニーセミコンダクタソリューションズの秋田です。
本記事では、
「A 1/2.3inch 12.3Mpixel with On-Chip 4.97TOPS/W CNN Processor Back-Illuminated Stacked CMOS Image Sensor」
という論文の紹介をします。
本論文は、半導体集積回路技術の最も権威ある国際会議の一つであるISSCC(International Solid-State Circuits Conference) に、2021年に採択されました。ISSCCは、最先端のチップ設計技術が集結する場です。
本論文で紹介される内容は、ソニーが製品化したインテリジェントビジョンセンサー「IMX500」の基盤技術となります。IMX500は、イメージセンサーとAI推論プロセッサを単一の積層チップに統合した革新的なセンサです。
現在、弊社ではIMX500を搭載したカメラモジュールやカメラ製品を提供するとともに、エッジAIソリューションの開発・運用を統合的に支援する「AITRIOS™(アイトリオス)」というエッジAIセンシングプラットフォームを展開しており、VisionAIによる社会実装を推進しています。
備考
論文情報
- タイトル: A 1/2.3inch 12.3Mpixel with On-Chip 4.97TOPS/W CNN Processor Back-Illuminated Stacked CMOS Image Sensor
- 会議: ISSCC 2021 (International Solid-State Circuits Conference)
- セッション: SESSION 9 / ML PROCESSORS FROM CLOUD TO EDGE / 9.6
- 著者: Ryoji Eki, Satoshi Yamada, Hiroyuki Ozawa, Hitoshi Kai, Kazuyuki Okuike, Hareesh Gowtham, Hidetomo Nakanishi, Edan Almog, Yoel Livne, Gadi Yuval, Eli Zyss, Takashi Izawa
- 公開元: https://ieeexplore.ieee.org/document/9365965
IMX500インテリジェントビジョンセンサー
IMX500は、2020年5月にソニーセミコンダクタソリューションズが発表した、世界初のAI処理機能を搭載した積層型CMOSイメージセンサーです。
主な特徴:
- イメージセンサーとロジックチップを積層した革新的な構造
- エッジデバイス上でリアルタイムAI処理が可能
- クラウドへのデータ転送を最小限に抑え、プライバシー保護と低レイテンシを実現
- 多様なアプリケーションに対応可能な柔軟性
詳細情報: ソニー プレスリリース(2020年5月14日)
AITRIOS™ エッジAIセンシングプラットフォーム
AITRIOSは、IMX500を活用したエッジAIソリューションの開発を支援する統合プラットフォームです。
提供内容:
- IMX500を搭載したエッジデバイスの接続、管理機能
- AI推論モデルの開発・デプロイツール
- クラウド連携機能
- アプリケーション開発キット
詳細情報: AITRIOS 公式サイト - IMX500
論文のまとめ(概略図)
本論文の主要な内容をまとめた図を提示します。
ざっと理解したい方向けにはこちらをどうぞ!

概略図: IMX500の主要技術と特徴
以下、論文の各セクションを詳しく解説していきます。
1. 論文の概要:積層型CISへのAI機能統合
本研究は、1/2.3インチ、12.3Mピクセル(4056(H) × 3040(V))の裏面照射型積層CMOSイメージセンサー(CIS) に、CNN演算専用のDSPを統合したデバイスの設計と性能を報告しています。
主な特徴
| 項目 | 特徴 |
|---|---|
| 処理性能 | 画像キャプチャとオンチップCNN処理を含めて120fpsで処理可能 |
| 電力効率 | DSPのピーク電力効率は4.97 TOPS/W |
| 構成 |
トップチップ(65nm): 画素アレイ ボトムチップ(22nm): ISPとCNNプロセッサ、8MB L2 SRAM |
既存研究との比較
従来のシステムでは、CISに加え、ISP、CNNプロセッサ、DRAMなど複数のICが必要でした。本技術はこれを単一の積層チップに統合することで、IoT市場が求める以下の要件を実現します:
- 小型サイズ
- 低コスト
- 低消費電力
- プライバシー保護の向上
2. システムアーキテクチャ
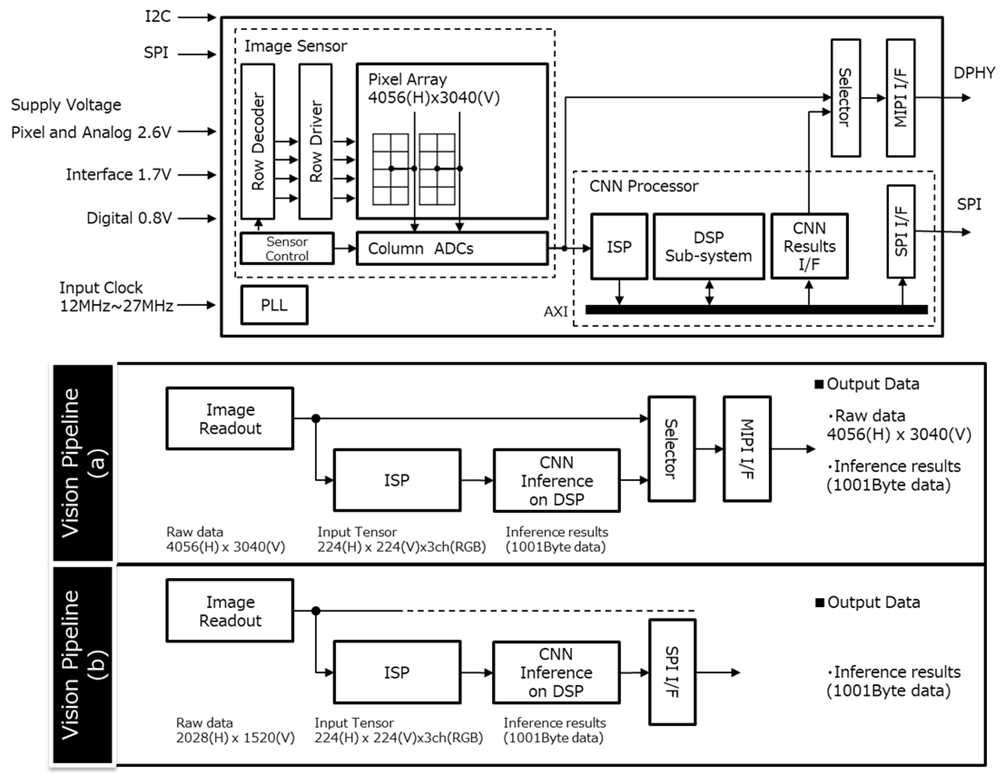
Figure 1: システムダイアグラムとビジョンパイプライン
2.1 全体構成
本デバイスは以下のブロックで構成されています:
- CISブロック: 12.3MピクセルのBayerパターンイメージセンサー、カラムADCアーキテクチャ
-
処理ブロック:
- CNN入力画像の前処理を行うISP
- CNN処理に最適化されたDSPサブシステム
- CNNの重みとランタイムメモリを格納する8MB L2 SRAM
2.2 出力パイプライン
本デバイスは2つのビジョンパイプラインをサポートしています:
ビジョンパイプライン(a):
- キャプチャ画像(RAWデータ)とCNN推論結果の両方を同じフレームでMIPIインターフェース経由で出力
ビジョンパイプライン(b):
- CNN推論結果のみをSPIインターフェースから出力
- 画像データのような大容量通信ではなく、数Kバイト程度のデータ量のため、SPIで対応可能
- MIPI回路を省略し、IC面積・配線・コネクタ数を削減
- 小型カメラの実現が可能
この構成により、画像を外部に出力しない場合、プライバシーの向上も実現できます。
3. DSPサブシステムの特徴
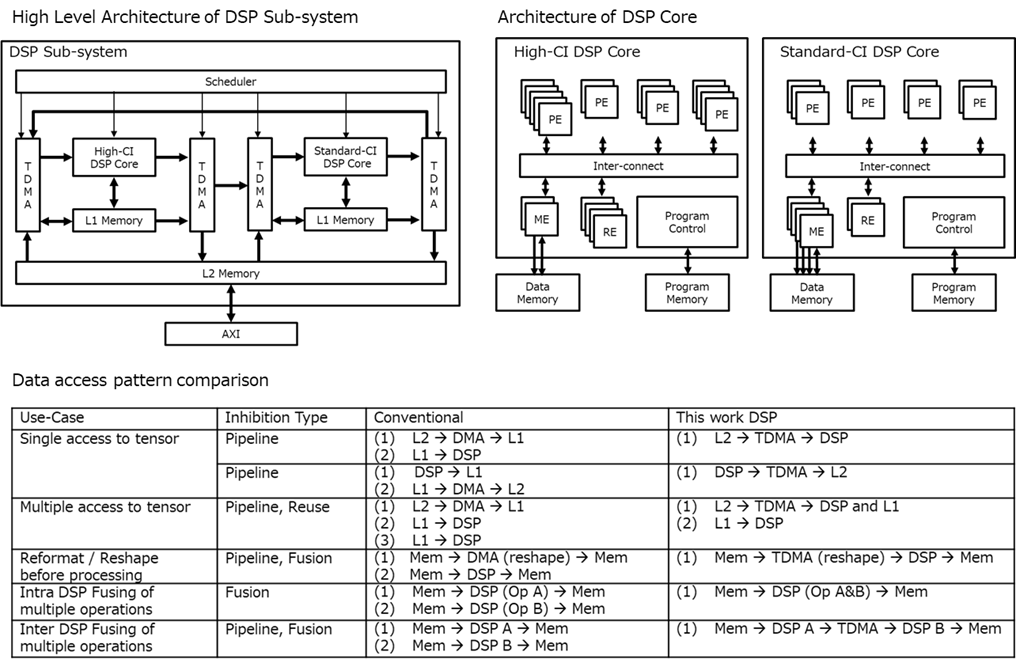
Figure 2: DSPアーキテクチャとデータアクセスパターン
3.1 従来のアーキテクチャとの違い
従来の高性能・低消費電力CNN推論システムは、ハードワイヤードまたは構成可能なアクセラレータアーキテクチャとDMAエンジンを組み合わせたものが一般的でした。これらのアーキテクチャには以下の課題がありました:
- ホストプロセッサの従属的な位置づけ
- CNNアクセラレータでサポートされないAI操作はホストプロセッサで処理(非効率)
- DMAエンジンはメモリ間のデータ転送のみ
3.2 本研究のDSPアーキテクチャ
本研究では、完全に命令レベルでプログラマブルな、高性能DSPアーキテクチャを採用しています。
ヘテロジニアス構成
DSPサブシステムは以下の異種要素で構成されています:
-
2種類の命令レベルプログラマブルDSPコア:
- 高CI(Computation Intensity)最適化コア
- 標準CI最適化コア
- 複数のTensor DMA(TDMA): データ移動とテンソル形式・形状の変換が可能
- 階層的メモリシステム
- 高スループットデータ転送用インターコネクト
- DSPコアとTDMAを制御するスケジューラ
サポートする演算
- 8bit、16bit、32bitの固定小数点演算をサポート
データ移動の最適化
本アーキテクチャは、以下の3つの方法でデータ移動を抑制します:
- Pipeline: メモリストレージなしの直接転送
- Fusion: 中間結果を保存せずに連続した操作を実行
- Reuse: 複数の計算に対して単一のメモリアクセス
3.3 DSPコアの詳細設計
各DSPコアは以下の要素で構成されています:
- 複数のProcessing Elements(PE): 処理要素
- Memory-access Elements(ME): メモリアクセス要素
- Registers(RE): レジスタ
- インターコネクト: これらの間のデータ転送を処理
高CI最適化コアの特徴
高CI DSPコアは、標準CIコアと比較して:
- メモリアクセスあたりの処理能力が高い
- 内部ストレージ容量が大きい
畳み込み演算のような非常に高いCIを示す操作では、高CI最適化DSPコアは以下を実現します:
- 特徴マップと重みの高い再利用率
- 中間結果をメモリに保存する必要がほとんどない(またはまったくない)
- 最大負荷時に平均してMAC演算あたり1ビット未満のメモリアクセス
- データのスパース性に依存しない性能
プログラマビリティの利点
命令レベルのプログラマビリティにより、以下をサポートできます:
- 任意のカーネル形状とサイズ、ストライド、ダイレーション、グルーピング
- マルチクラスNon-Maximum-Suppression
- Crop-and-Resize操作
- その他の複雑な操作
これらの操作は、従来のCNNアクセラレーションソリューションでは処理できず、ホストプロセッサに大きな負荷、複雑さ、電力消費をもたらしていました。
4. 性能評価
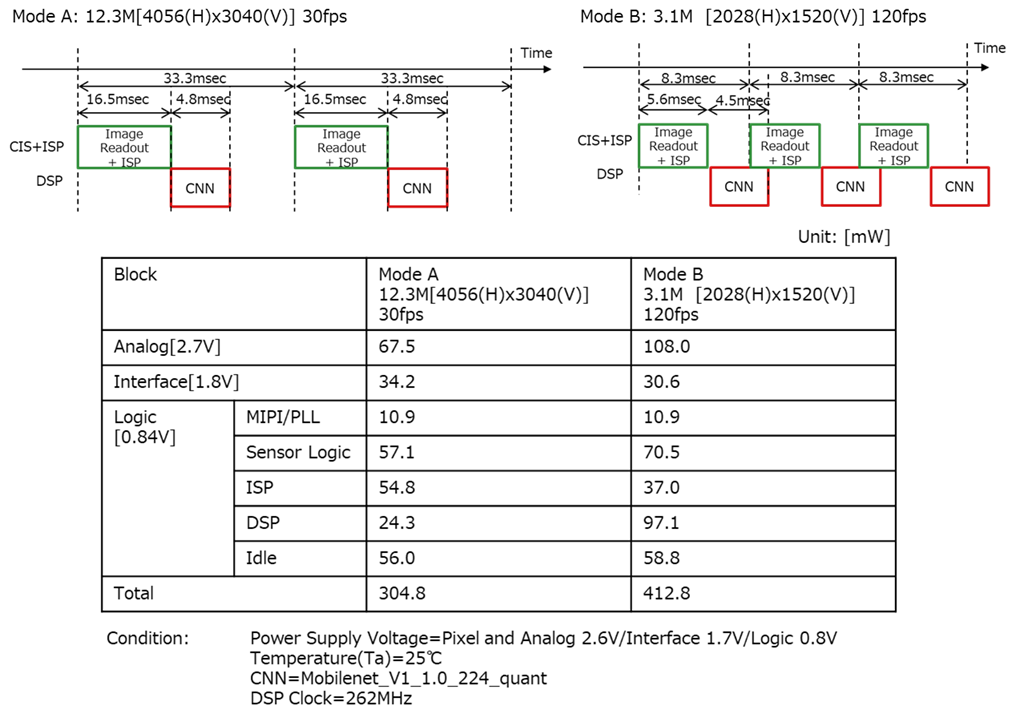
Figure 3: タイミングチャートと消費電力
4.1 動作モード
本デバイスは2つの動作モードをサポートしています:
モードA: 高解像度モード
- 12.3Mピクセル画像の読み出しと処理を16.5ms以内で完了
- 画像読み出しとISP処理は並列実行
- CNN処理時間: 4.8ms
モードB: 高速動作モード
- 3.1Mピクセル画像の読み出しとISP処理を5.6ms以内で完了
- CNN処理時間: 4.5ms
両モードとも、画像読み出しとDSPサブシステム上のCNN処理を並列化することで、120fpsでの動作を実現しています。
両モードのタイミングチャートは、MobileNet_V1_1.0_224_quantをベースに測定されました。
4.2 消費電力測定結果
モードAの消費電力
- アナログ(2.6V): 65.0mW
- インターフェース(1.7V): 32.3mW
- ロジック(0.8V):
- MIPI/PLL: 9.6mW
- Sensor Logic: 49.5mW
- ISP: 53.1mW
- DSP: 16.65mW
- Idle: 52.8mW
- 合計: 278.8mW
モードBの消費電力
- 合計: 379.1mW
4.3 CNN推論結果の例
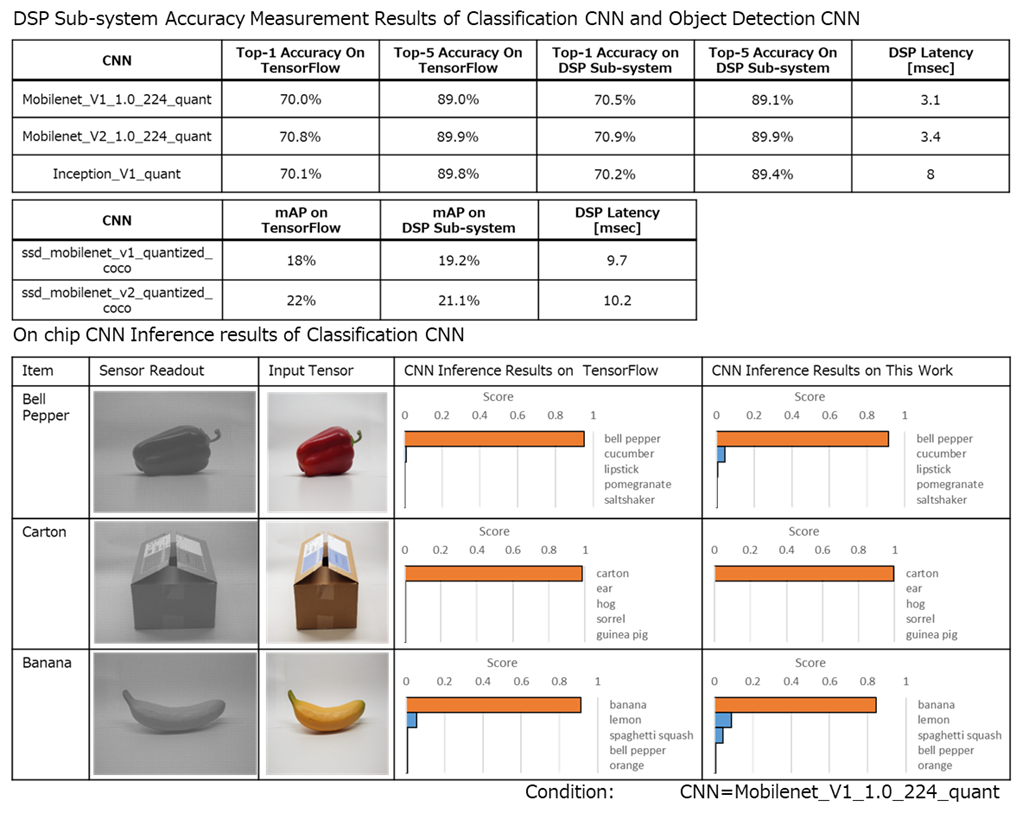
Figure 4: CNN推論の測定結果
本デバイス上でのCNN推論結果は、TensorFlowでの推論結果と有意な差がないことが示されました。
測定されたCNNモデルの精度(Top-1 Accuracy):
| CNNモデル | DSP Sub-system | TensorFlow |
|---|---|---|
| MobileNet_v1_quant | 70.8% | 69.8% |
| Inception_v1_quant | 70.1% | 69.8% |
| MobileNet_v2_quant | 70.8% | 70.8% |
5. 他DSPとの比較
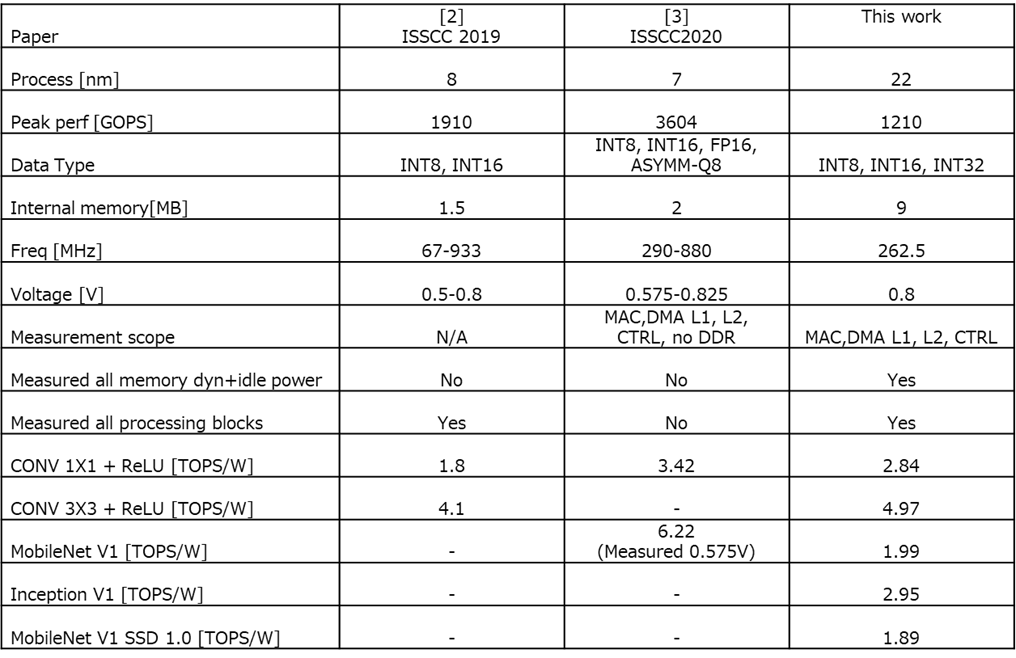
Figure 5: DSP比較表
比較表の重要なポイント
本研究と先行研究との最も重要な違い:
先行研究:
- 内部電力のみを測定
- ネットワーク推論のための外部メモリと相互接続の電力を除外
- 大規模な外部メモリアレイの静的・動的電力は無視できない
本研究:
- CNNネットワーク推論に必要な全てのメモリを含む
- サブシステムのすべての静的・動的電力を測定・計上
測定条件
すべてのネットワーク測定は以下の条件で実施:
- オリジナルのネットワークを使用(所有者が公開したまま)
- オリジナルの重みを使用
- 削減技術を適用せず
6. チップ仕様

Figure 6: チップ特性
6.1 製造プロセス
| チップ | プロセス | 主な機能 |
|---|---|---|
| トップチップ | 65nm | 画素アレイ |
| ボトムチップ | 22nm | ISP、CNNプロセッサ、L2 SRAM |
6.2 画素仕様
- 有効ピクセル数: 4056(H) × 3040(V) = 12.3Mピクセル(光学ブラックピクセルを除く)
- ピクセルピッチ: 1.55μm(オンチップマイクロレンズ付き)
- チップサイズ: 7.558mm(H) × 8.206mm(V)
6.3 動作仕様
| 項目 | Option 1 | Option 2 |
|---|---|---|
| 出力先 | MIPI CSI-2 + raw DPHY 2 lanes/lane | SPI 350Mbps |
| DSP | Number of MACs | 2304MACs |
| Peak Power efficiency | 4.97TOPS/W | |
| Total SRAM | 262.5Kbit | |
| センサー読み出し時間 | 12.3M [4056(H)×3040(V)] | 16.32msec |
| 3.1M [2028(H)×1520(V)] | 5.53msec | |
| 消費電力 | 12.3M [4056(H)×3040(V)] 30fps | 278.8mW |
| 3.1M [2028(H)×1520(V)] 120fps | 379.1mW |
6.4 その他の仕様
- 入力クロック: 12~27MHz
-
出力フォーマット:
- センサー: Bayer RAW
- 入力テンソル: RGB or YUV
-
供給電圧:
- Pixel and Analog: 2.3V~2.9V
- Interface: 1.7V~Logic 0.8V
6.5 ダイ写真

Figure 7: ダイ写真(トップチップ:画素アレイ、ボトムチップ:CNNプロセッササブシステム)
図に示されるように、トップチップには4056×3040の画素アレイが配置され、ボトムチップにはCNNプロセッササブシステム、DAC、カラムADCが実装されています。
7. まとめ
本論文で提案されたインテリジェントビジョンセンサーは、以下の点でIoT市場に貢献します:
7.1 実現した価値
✅ 小型フォームファクター: 複数のICを単一チップに統合
✅ 低システム電力: 効率的なDSPアーキテクチャにより4.97TOPS/Wを達成
✅ 低システムコスト: 少数のICで構成可能
✅ プライバシーの向上: チップから画像を出力しない運用が可能
7.2 技術的革新
-
積層技術の活用: 画素チップ(65nm)と処理チップ(22nm)を積層し、各機能に最適なプロセスを採用
-
完全統合型AI処理: 外部メモリに依存せず、オンチップで完結するCNN推論
-
柔軟なDSPアーキテクチャ: 命令レベルのプログラマビリティにより、新しいCNN層やアーキテクチャへの高い適応性
-
データ移動の最適化: Pipeline、Fusion、Reuseの3つの手法により、メモリアクセスを最小化
7.3 今後の展望
本技術は、以下の分野での応用が期待されます:
- スマートシティ向けカメラシステム
- 小売店舗の分析カメラ
- セキュリティカメラ
- 産業用検査システム
- 自律移動ロボット
エッジでのAI処理能力を持つカメラ製品の実現により、クラウドのみに依存するシステムの課題(レイテンシ、通信コスト、プライバシー懸念)を解決し、次世代のスマートカメラエコシステムの構築に寄与すると考えられます。
参考文献
[1] J. Song et al., "An 11.5 TOPS/W 1024-MAC Butterfly Structure Dual-Core Sparsity-Aware Neural Processing Unit in 8nm Flagship Mobile SoC," ISSCC, pp. 130-132, 2019.
[2] C. Lin et al, "A 3.4-to-13.3TOPS/W 3.6TOPS Dual-Core Deep-Learning Accelerator for Versatile AI Applications in 7nm 5G Smartphone SoC," ISSCC, pp. 134-136, 2020.
[3] A. G. Howard et al., "Mobilenets: Efficient Convolutional Neural Networks for Mobile Vision Applications," CoRR, abs/1704.04861, 2017.
[4] MobileNet_v1, MobileNet_v2, Inception_v1 Source Code: https://www.tensorflow.org/lite/guide/hosted_models
[5] SSD MobileNet_v1, SSD MobileNet_v2 Source Code: https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/tf1_detection_zoo.md
読んだ感想+終わりに
いかがでしたでしょうか?
自分の感想としては:
- 画素とチップを結合させる設計は世界でも初めてで、学術的かつ技術的に面白いチップである
- チップ積層とDSPアーキテクチャ設計により中間データ転送を大幅に減らせ、非常に小型でありながら高速かつエコで、後段に画像を送らないセキュリティに配慮したCNN処理が可能。
という事を再認識できました。
一方で、製造回りの知見(積層方法やチップ化など)の知見は論文に語られていなかったので、気になりました。NPUチップと接続する場合と比較した歩留まりや工数とか知りたいですよね。。
また、今後の展望として:
- 画素はともかく、後段チップのプロセス長は22nmということで、参考文献にある他のNPUチップよりは長め
- 備考:イメージセンサの論理回路部としては一般的な長さ
- また、8MBのRAM制約があり、搭載できるAIモデルは限られるので、用途の吟味は必要
と、Future Planも理解できました。
IMX500を試してみたい方へ
是非、本チップを搭載したカメラを使ってみたい方は、ご連絡頂けますと幸いです!
また、Raspberry Pi AI Cameraとして一般販売もしています:
製品情報:
Raspberry Pi AI Cameraは、IMX500を搭載したRaspberry Pi用カメラモジュールで、手軽にエッジAI処理を体験できます。物体検出、姿勢推定、セグメンテーションなど、様々なAIアプリケーションの開発が可能です。
困った時は
もし、記事で気になることがある場合は、気軽にこの記事にコメントください、
AITRIOSやIMX500のことについては以下のサポートのページもご覧ください。
コメントのお返事にはお時間を頂く可能性もありますがご了承ください。
Support (FAQ)
また、記事の内容以外で AITRIOS についてお困りごとなどあれば以下よりお問い合わせください。
Contact Us