この記事では機械学習パイプラインを本番環境にデプロイするためのエンドツーエンドなプラットフォームの提供を目指す、TFXについて述べます。
TL;DR
The TFX User Guide が一番詳しいのでこれを読みましょう。
TFX とは
TensorFlow Extended (TFX) は次の3つのうちのいずれかを指します。
- 機械学習パイプラインの設計思想
- 設計思想に基づいて機械学習パイプラインを実装するためのフレームワーク
- フレームワークの各コンポーネントで用いられるライブラリ
以降ではまず、設計思想としての TFX に触れ概略を紹介します。次に、設計思想に基づき、コンポーネントを機械学習パイプラインとしてまとめ上げ、構築を行うライブラリについて紹介します。最後に、各コンポーネントで用いられるライブラリを見ることで、それぞれのライブラリが提供する機能について紹介します。
設計思想としての TFX
まずは TensorFlow を前提とした機械学習パイプラインの設計思想としての TFX を見ていきます。
背景
機械学習は様々な活用事例が発表されていますが、それをシステムに組み込む際にはそれ以外にも様々なものが必要になることが知られています。有名なものとしては例えば、Hidden Technical Debt in Machine Learning Systems では次の図を用いてそれを説明しています。
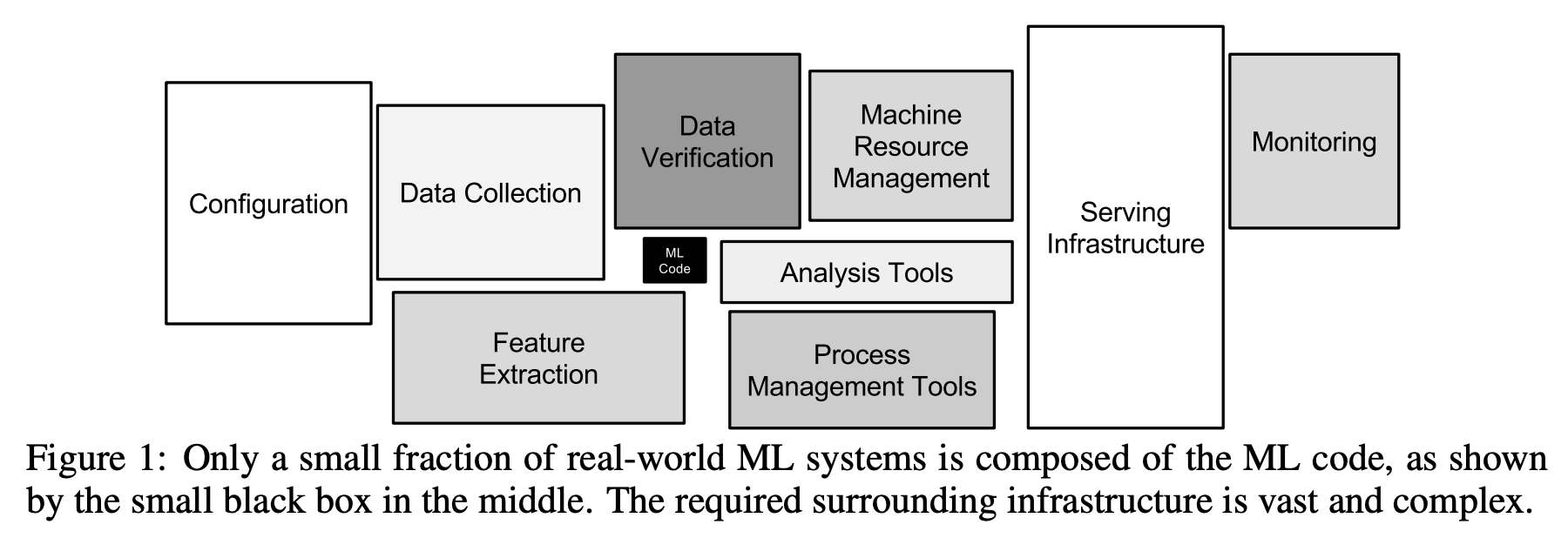
中央の小さな黒い四角が機械学習モデルであり、周囲には設定、データ収集、特徴量の計算、データの検証、計算資源の管理、分析ツール、プロセス管理ツール、それらを乗せるインフラ、監視といった様々なものがあり、全体として複雑性が予想以上に増すことを示しています。
TFX ではこれらに対処することを目指しています。初出は TFX: A TensorFlow-Based Production-Scale Machine Learning Platform で、この論文では Google で実装した機械学習パイプラインの設計について述べています。
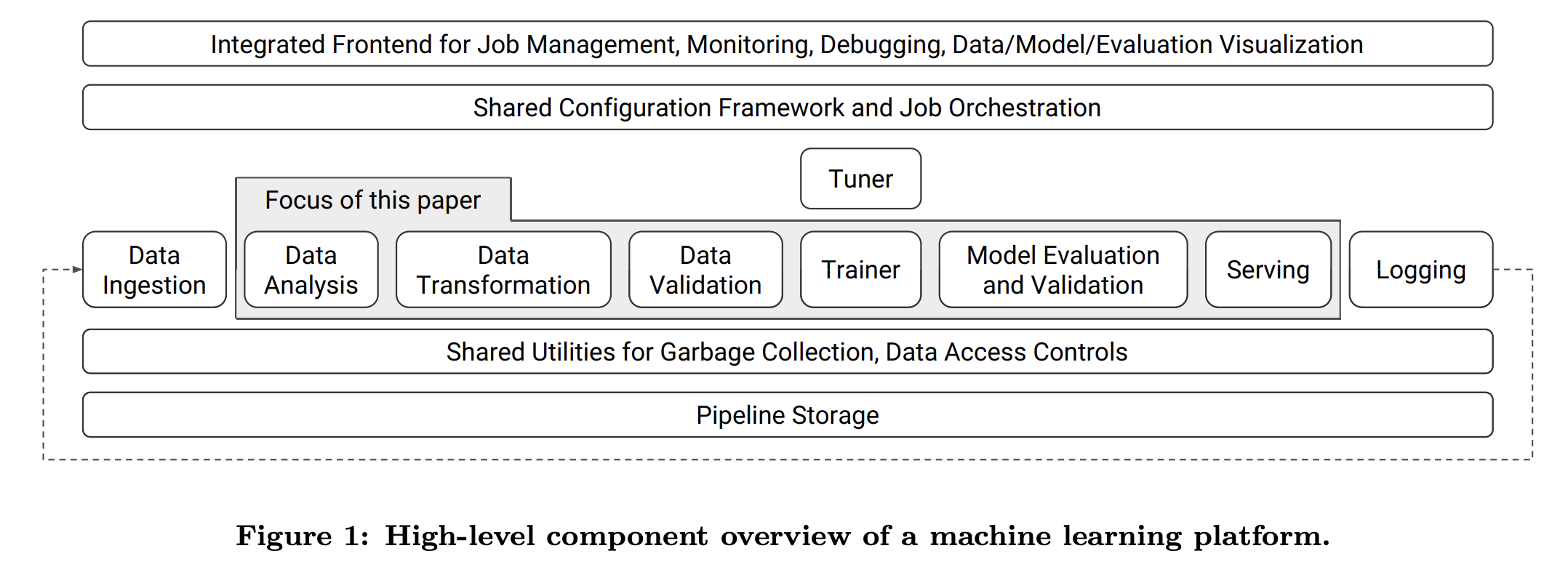
そこではこの図のようにパイプラインに必要な処理を整理し、フロントエンドと、オーケストレーション、データへのアクセス権限管理とガーベージコレクション、一貫したストレージが必要なことが記されています。パイプラインを構成するそれぞれのコンポーネントには次のものが含まれています。
- Data Analysis
- Data Transformation
- Data Validation
- Trainer
- Model Evaluation & Validation
- Serving
それぞれのコンポーネントの役割について見ていきましょう。
1. Data Analysis
ここでは機械学習パイプラインに投入するデータにについて、様々な分析を行います。データに含まれる特徴量の数や、特徴量ごとの欠損値の有無、各特徴量の各種統計量を計算し記録することで、入力されたデータがどのような分布をしているのかを把握します。
2. Data Transformation
ここではいわゆる前処理を行います。例えば、カテゴリカルな値にIDを割り振るといった処理はここに含まれます。このコンポーネントを学習時と推論時に使うことで、推論時には学習時と違う処理が行われてしまってうまく動かないことを防げます。
3. Data Validation
ここでは入力されているデータに対しての検証を行います。TFXでは本番環境を想定しているため、機械学習パイプラインにはデータが継続的に投入されますが、様々な事情でデータの形式や分布は変わっていきます。このコンポーネントでは予めデータのスキーマを定めておくことで、新たに投入されたデータがそのスキーマに合致しているかどうかを検証します。
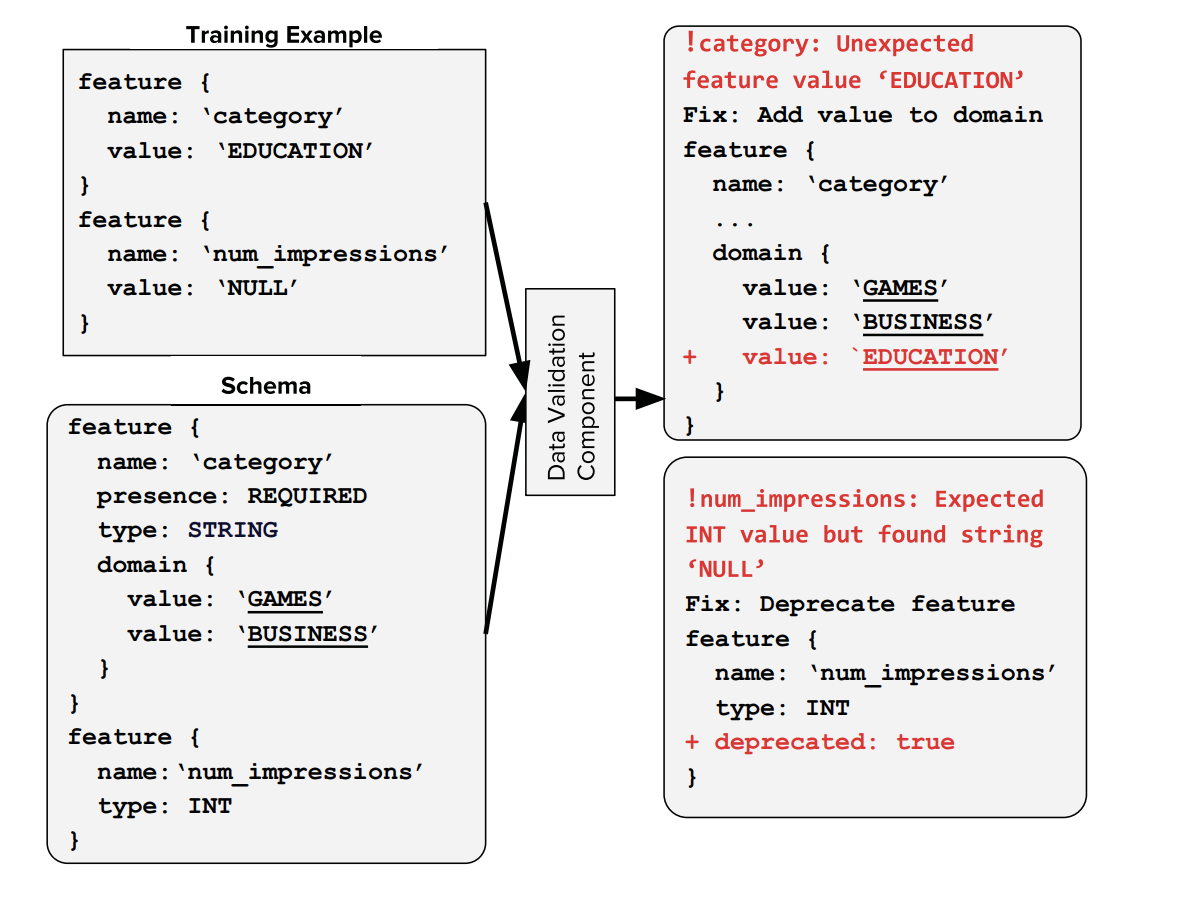
上図では "category" という特徴量について、スキーマに定義されている値 ("GAMES" と "Business") 以外の値 ("EDUCATION") が入力されたことと、"num_impressions" という特徴量にスキーマに定義された型 ("int") 以外の値 ("NULL") が入力されたことの検知を行っている様子を示しています。
4. Trainer
ここでは機械学習モデルを訓練させます。機械学習モデルはそれぞれ別の形の入力データを要求し、用いられるアルゴリズムもまちまちであるため、様々な訓練処理を統一的に扱うためのハイレベルに抽象化されたインターフェースが必要になります。そこで登場したのが Estimator です。

Estimator を用いることで次のような記述ができます。
# Declare a numeric feature:
num_rooms = numeric_column(’number-of-rooms’)
# Declare a categorical feature:
country = categorical_column_with_vocabulary_list(
’country’, [’US’, ’CA’])
# Declare a categorical feature and use hashing:
zip_code = categorical_column_with_hash_bucket(
’zip_code’, hash_bucket_size=1K)
# Define the model and declare the inputs
estimator = DNNRegressor(
hidden_units=[256, 128, 64],
feature_columns=[
num_rooms, country,
embedding_column(zip_code, 8)],
activation_fn=relu,
dropout=0.1)
# Prepare the training data
def my_training_data():
# Read, parse training data and convert it into
# tensors. Returns a mini-batch of data every
# time returned tensors are fetched.
return features, labels
# Prepare the validation data
def my_eval_data():
# Read, parse validation data and convert it into
# tensors. Returns a mini-batch of data every
# time returned tensors are fetched.
return features, labels
estimator.train(input_fn=my_training_data)
estimator.evaluate(input_fn=my_eval_data)
高度に抽象化されたインターフェースに依存することで、開発時の生産性を高く保つことができます。
5. Model Evaluation & Validation
ここではモデルの評価と妥当性の確認を行います。モデルの評価においてはオンラインでのテスト (A/Bテスト) を行うことはコストがかかるため、過去データを対象にしたオフラインテストを行い AUC などの指標が適切な範疇にあるかを評価します。また、カナリアリリースを行い、モデルが適切な振る舞いをしているかモニタリングをします。
6. Serving
ここではモデルを本番環境にデプロイします。モデルのデプロイには TensorFlow Serving を用いてスケーラブルにします。データのシリアライゼーションには tf.Example を利用します。
実例
ここまでで見てきた設計思想は実際に Google Play のリコメンドシステムに用いられたものです。上記の設計思想に基づく実装を行ったことで次の効果があったと述べられています。
- Data Validation と Data Analysis コンポーネントによ、り学習時とサービス提供時のデータの歪みの検知を支援できた
- 埋め込みを除き、モデルをスクラッチから学習させ続けることで、新鮮なデータを使って学習させたモデルを継続的にデプロイで来た
- Model Validation コンポーネントにより、古いモデルと新しいモデルのパフォーマンスの差異に関するトラブルシュートを支援できた
- Serving コンポーネントによりプロダクションへのモデルのデプロイを、高い性能と柔軟性を持って配備することができた
フレームワークとしてのTFX
ここまででは設計思想としての TFX を扱ってきましたが、次に、機械学習パイプラインのフレームワークとしての TFX を見ていきます。以降ではより具体的な実装についての話が多くなってきます。
概要
設計思想に基づき機械学習パイプラインをフレームワークとして実装しているものが TFX モジュール1 です。
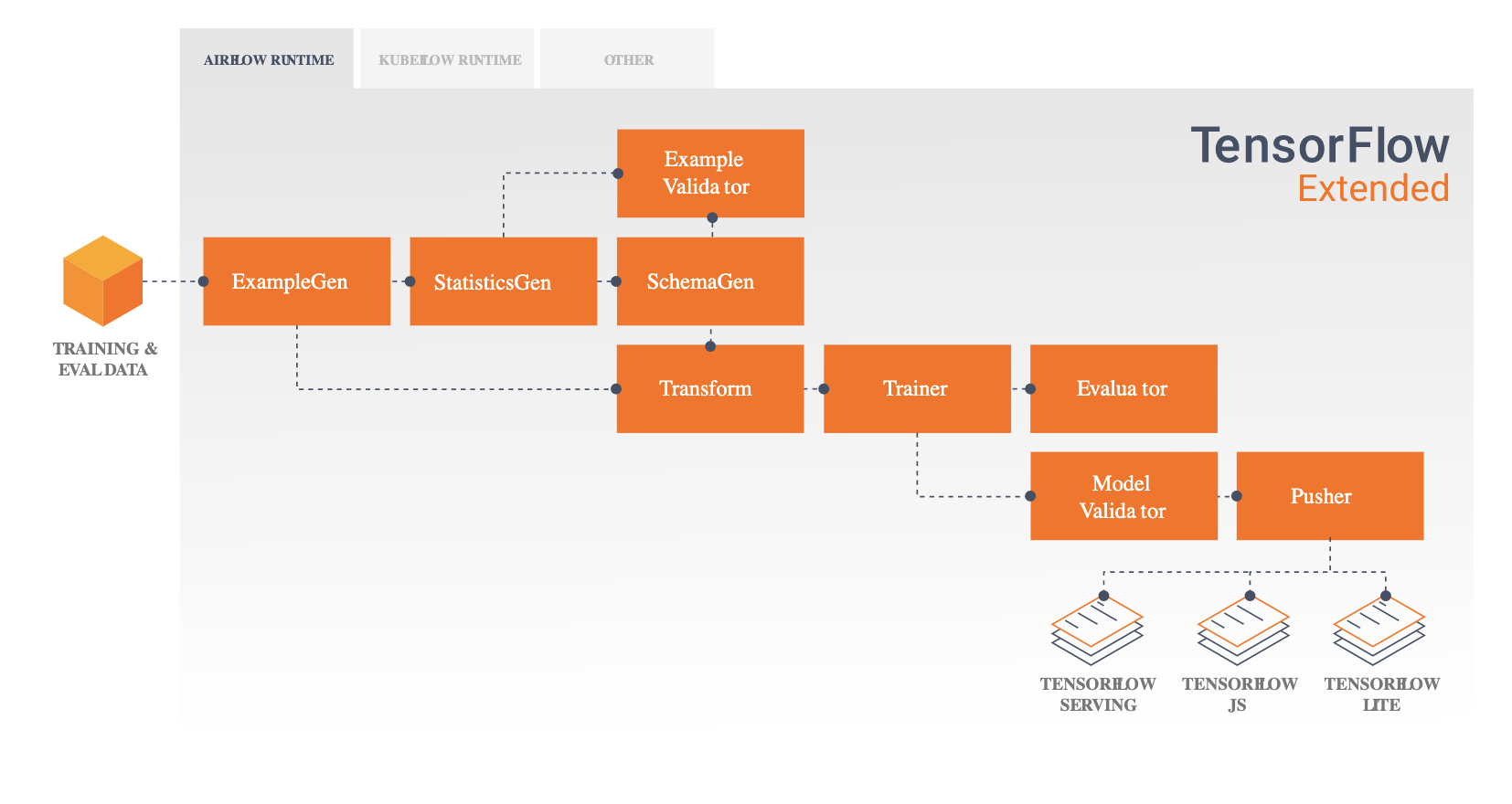
設計思想で説明されたコンポーネントと、フレームワークで提供されるコンポーネントを対比すると次のようになります。
| 設計思想におけるコンポーネント | フレームワークで提供されるコンポーネント |
|---|---|
| (なし) | ExampleGen |
| Data Analysis | StatisticsGen |
| Data Analysis | SchemaGen |
| Data Validation | ExampleValidator |
| Data Transformation | Transform |
| Trainer | Trainer |
| Model Evaluation | Evaluator |
| Model Validation | ModelValidator |
| Serving | Pusher |
以降では単に TFX やコンポーネントといったときにはモジュールそのものやモジュールで提供されるものを指すものとします。それぞれのコンポーネントの詳細な説明は、後ほどライブラリに関する説明をする際に行います。
コンポーネントの実装
TFX で提供されるコンポーネントはすべて共通の設計思想に基づいている点が特徴的です。
設計思想に出現する様々なコンポーネントには次の共通する特徴があります。
- 要求される実行順序がある: 例えば、Trainer の前にはData Transform を実行する必要がある
- 分岐する: Data Transform の出力は Data Validation でも Trainer でも利用される
- 出力結果を保存する必要がある: トラブルシュートのため
- コンポーネント単位でのスケーラビリティが要求される: そもそも大きなデータを扱っているため
TFX ではこれらの特徴をもとに、コンポーネント間で共通するインターフェースと、各コンポーネントの標準的な実装を提供しています。
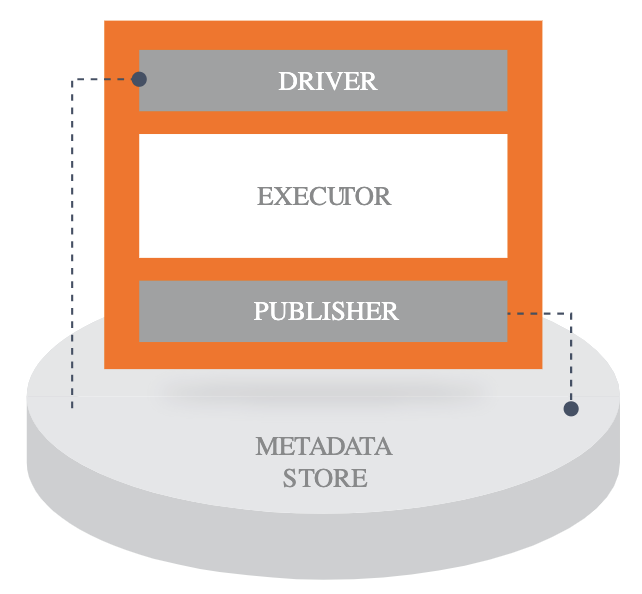
コンポーネントは次の3つの部分からなります。
- Driver : コンポーネントを起動し、データを読み込む
- Executor : コンポーネントで行う処理そのものを行う
- Publisher : コンポーネントの処理結果を書き込む
Executor の処理は Apache Beam により分散処理が行われます。Beam の処理基板には Apache Flink, Google Cloud Dataflow, Spark など Beam がサポートされるものを利用できます。もちろん、Beam の Direct Runner を用いてローカルで実行することも可能です。
例えば、ExampleGen の1つであるExample GenではCSVを読み込む処理が次のように実装されています。
parsed_csv_lines = (
pipeline
| 'ReadFromText' >> beam.io.ReadFromText(
file_pattern=csv_pattern, skip_header_lines=1)
| 'ParseCSVLine' >> beam.ParDo(csv_decoder.ParseCSVLine(delimiter=',')))
column_infos = beam.pvalue.AsSingleton(
parsed_csv_lines
| 'InferColumnTypes' >> beam.CombineGlobally(
csv_decoder.ColumnTypeInferrer(column_names, skip_blank_lines=True)))
return (parsed_csv_lines
| 'ToTFExample' >> beam.ParDo(_ParsedCsvToTfExample(), column_infos))
各コンポーネントの入出力は Artifact と呼ばれます2。これらの実態は ProtocolBuffer です。Artifact の型はコンポーネントごとにtfx.types に定義され、厳格に決められます。Artifact 自体はストレージ (例えば GCS やローカルのファイルストレージ) に保存されます。
また、コンポーネントはメタデータストアにアクセスすることで Artifact のメタデータ (例えば id やモデルの名前) を読み書きします。メタデータストア自体の役割についてはライブラリついて紹介する際に改めて行います。
オーケストレーション
機械学習パイプラインの設定や実行を管理するためのオーケストレーションも TFX では提供されます。
TFX を用いると機械学習パイプラインを次のステップで構築できます。
- 各コンポーネントを作成する
- それらを Pipeline を用いてつなぎ合わせる
- 各種 Runner に Pipeline を渡し、実行する
Runner では次のものを処理基盤として利用できます。
- Apache Airflow
- Apache Beam
- Kubeflow Pipelines
すべての Runner は TfxRunner を継承し、統一されたAPIで利用できます。例えば、ローカルで実行する場合には次のように実装します3。
class DirectRunner(TfxRunner):
"""Tfx runner on local"""
def __init__(self, config=None):
"""config には Apache Beamやメタデータストア、Airflowなどの設定が含まれる """
self._config = config or {}
def run(self, pipeline):
"""受け取ったpipelineからコンポーネントを取り出し、順に実行する"""
# Merge airflow-specific configs with pipeline args
self._config.update(pipeline.pipeline_args)
for component in pipeline.components:
self._execute_component(component)
return pipeline
def _execute_component(self, component):
"""コンポーネントを実行する、ここではローカルで実行するための処理を書いている"""
# parse parameters
input_dict = {key:value.get() for key, value in component.input_dict.items()}
output_dict = {key: value.get() for key, value in component.outputs.get_all().items()}
exec_properties = component.exec_properties
# create executor
additional_pipeline_args = self._config.get('additional_pipeline_args') or {}
executor = component.executor(beam_pipeline_args=additional_pipeline_args.get('beam_pipeline_args'))
executor.Do(input_dict, output_dict, exec_properties)
Runner を利用するときには次のようにします。
pipeline = Pipeline(
pipeline_name="TFX Pipeline",
pipeline_root=_pipeline_root,
components=[
example_gen,
statistics_gen,
infer_schema,
example_validator,
transform,
trainer,
model_analyzer,
model_validator,
pusher,
]
)
DirectRunner().run(pipeline)
このようにして、ローカルでの開発時と本番環境でのデプロイ時に同じコードを使い回すことができることは TFX の特徴の一つです。
サンプル
オーケストレーションに Airflow を用いて TFX を実行する場合のサンプルコードが GitHub のリポジトリにあります (tfx/taxi_pipeline_simple.py)。
コメントを含めて全部で157行と比較的短いコードで書かれていることがわかります。
TFX に関連するライブラリ
TFX で行われる様々な処理のために、各種ライブラリが開発されています。ここではそれらのライブラリについて見ていきます。
概要
コンポーネントで行われる処理には TensorFlow Core には無い機能が必要になるので、実装を行うための各種ライブラリが存在します。
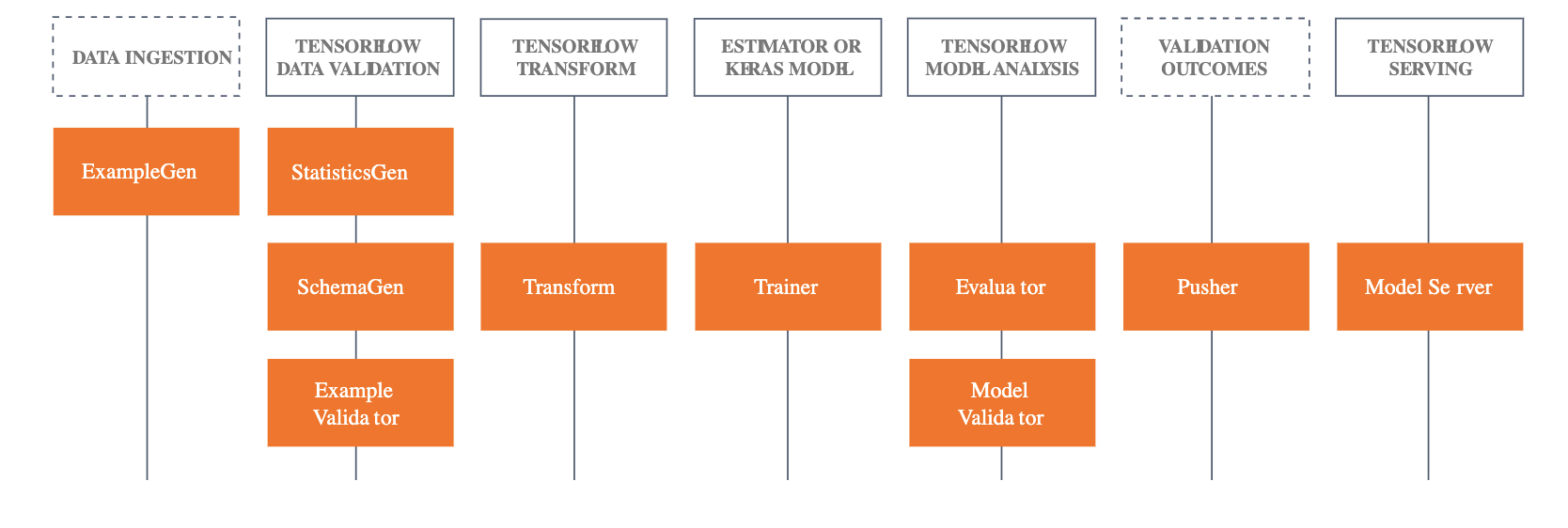
それぞれのライブラリについて、これまでに見てきたフレームワーク、モジュールとの関連は次のようになっています。
| 設計思想におけるコンポーネント | フレームワークにおけるコンポーネント | コンポーネントが利用するライブラリ |
|---|---|---|
| (なし) | ExampleGen | (なし) |
| Data Analysis | StatisticsGen | Tensorflow Data Validation |
| Data Analysis | SchemaGen | Tensorflow Data Validation |
| Data Validation | ExampleValidator | Tensorflow Data Validation |
| Data Transformation | Transform | TensorFlow Transform |
| Trainer | Trainer | TensorFlow |
| Model Evaluation | Evaluator | TensorFlow Model Analysis |
| Model Validation | ModelValidator | TensorFlow Model Analysis |
| Serving | Pusher | Serving |
また、機械学習パイプライン全体を通じて関連するライブラリに、機械学習パイプラインに関するデータ形式の提供やメタデータの保管を行うためのライブラリとして、TensorFlow Metadata と ML Metadata (MLMD) があります。
以降ではそれぞれのライブラリの提供する機能について見ていきます。
TensorFlow Data Validation (TFDV)
TensorFlow Data Validation (TFDV) は次の機能を提供します。
- 学習データ・テストデータの要約統計量の算出
- データのスキーマの自動算出
- データの欠損や、閾値を超えた値などのデータの異常値の検知
- 上記を補佐するビューワー
学習データ・テストデータの要約統計量算出では Facets を用いてインタラクティブにデータの様子を知ることができます。
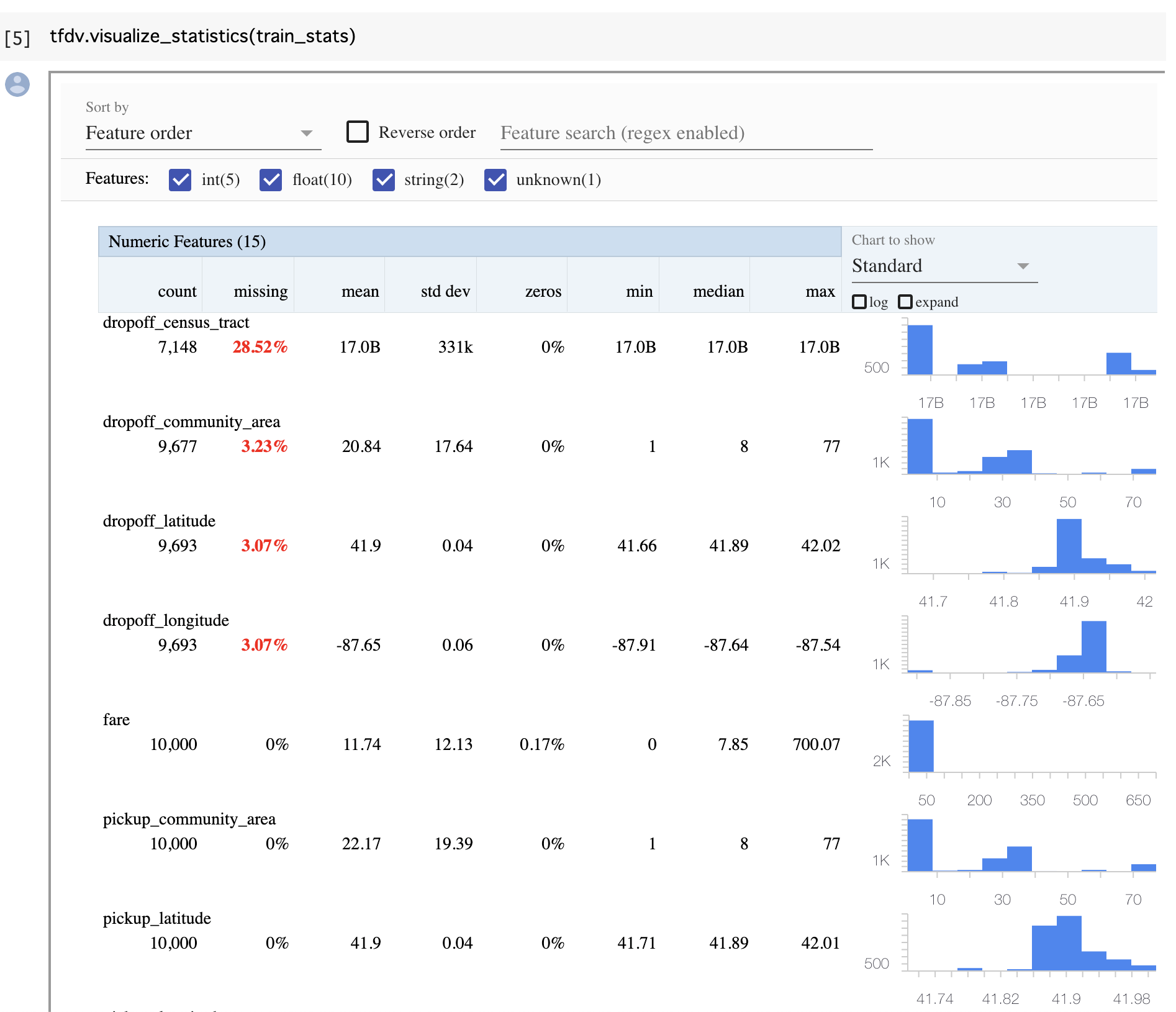
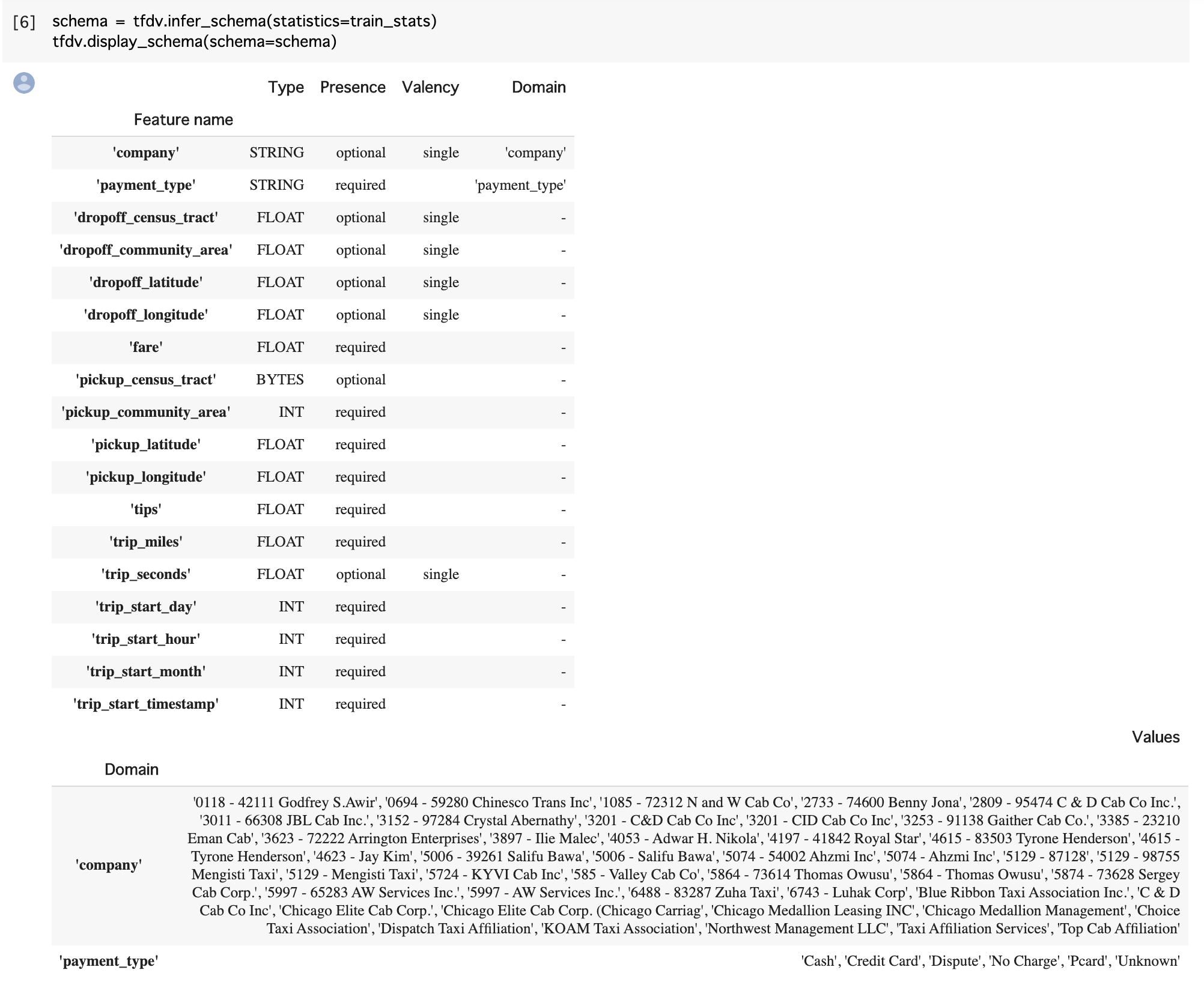
また、データのスキーマは次のように自動算出されます。これは自動算出したものをそのままサービスで使うというものではなく、自動算出したものをもとに人手で修正してサービスで利用するという意図のものである点には注意が必要です。
データの欠損や、閾値を超えた値などのデータの異常値の検知については、与えた2つのデータ (例えば、評価データとテストデータ) が同一の分布をしているかという観点で行われます。こちらも Facets を用いた可視化が可能です。
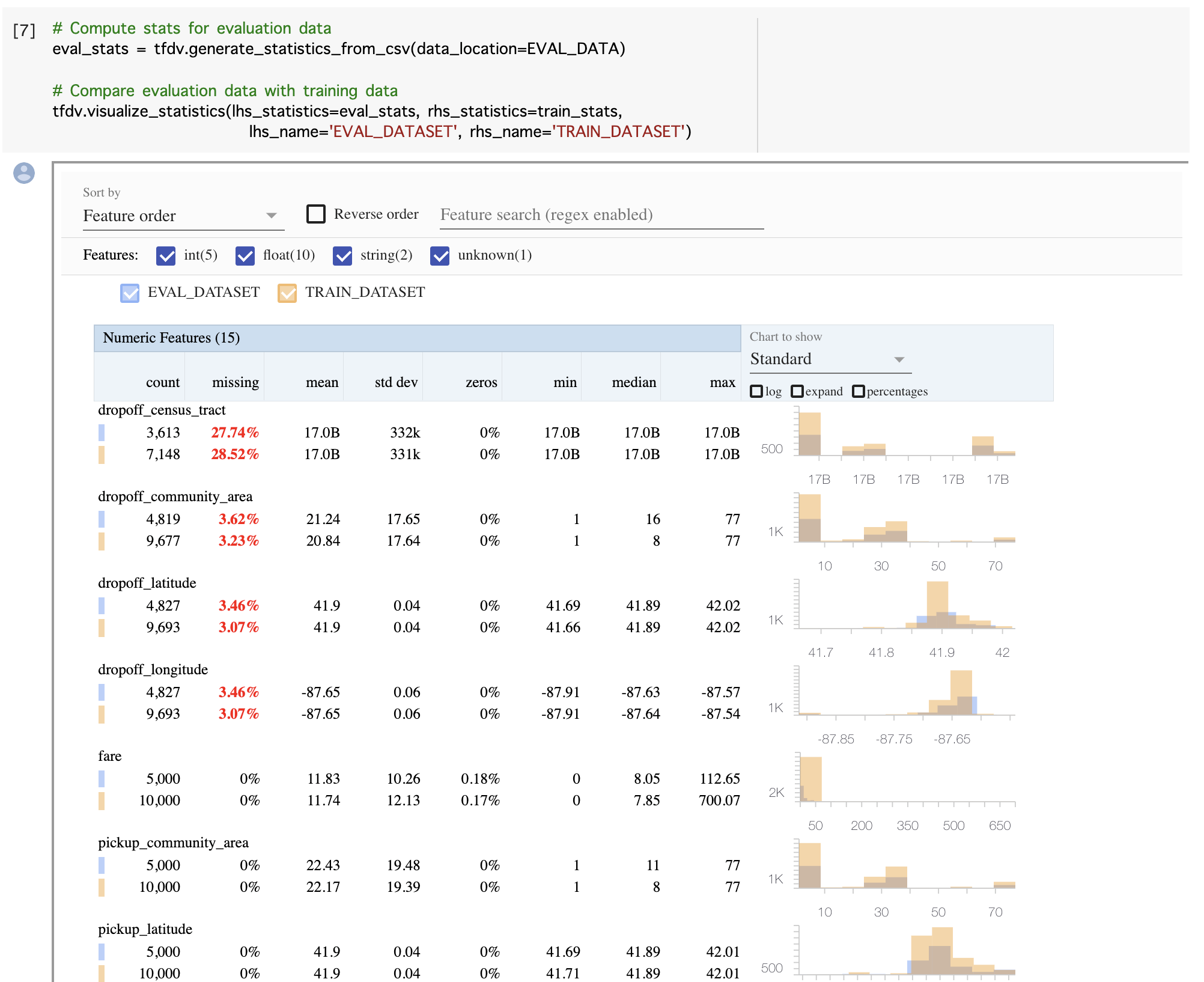
また、異常値については作成済みのスキーマを用いた比較が行われます。例えば、次の例ではカテゴリカル変数である company と payment にスキーマ作成には定義されていない値が出現していることを示しています。

これらの機能については、TensorFlow Data Validationのチュートリアル から試すことができます。 (TFDV のインストール後、エラーが発生したときに手動でランタイムの再起動が必要 な点には注意が必要です)
TensorFlow Transform (TFT)
TensorFlow Transform (TFT) は TensorFlow を用いてデータを前処理するためのライブラリです。Apache Beam を用いて並列処理を行う点が特徴的です。
TFT による前処理を行うためにはまず、preprocessing_fn と呼ばれる関数を定義ます。実装は例えば次のようになります。
def preprocessing_fn(inputs):
"""Preprocess input columns into transformed columns."""
x = inputs['x']
y = inputs['y']
s = inputs['s']
x_centered = x - tft.mean(x)
y_normalized = tft.scale_to_0_1(y)
s_integerized = tft.compute_and_apply_vocabulary(s)
x_centered_times_y_normalized = (x_centered * y_normalized)
return {
'x_centered': x_centered,
'y_normalized': y_normalized,
's_integerized': s_integerized,
'x_centered_times_y_normalized': x_centered_times_y_normalized,
}
実装した preprocessing_fn を Beam に渡して実行します。
def main():
# Ignore the warnings
with tft_beam.Context(temp_dir=tempfile.mkdtemp()):
transformed_dataset, transform_fn = ( # pylint: disable=unused-variable
(raw_data, raw_data_metadata) | tft_beam.AnalyzeAndTransformDataset(
preprocessing_fn))
transformed_data, transformed_metadata = transformed_dataset # pylint: disable=unused-variable
print('\nRaw data:\n{}\n'.format(pprint.pformat(raw_data)))
print('Transformed data:\n{}'.format(pprint.pformat(transformed_data)))
TensorFlow Model Analysis (TFMA)
TensorFlow Model Analysis (TFMA) はモデルの評価を行うためのライブラリです。特徴量を指定すると、その特徴量の値に対するモデルの制度をヒストグラムとして見ることができます。また、こちらも対話的に指標を色々と変更して確認ができます。
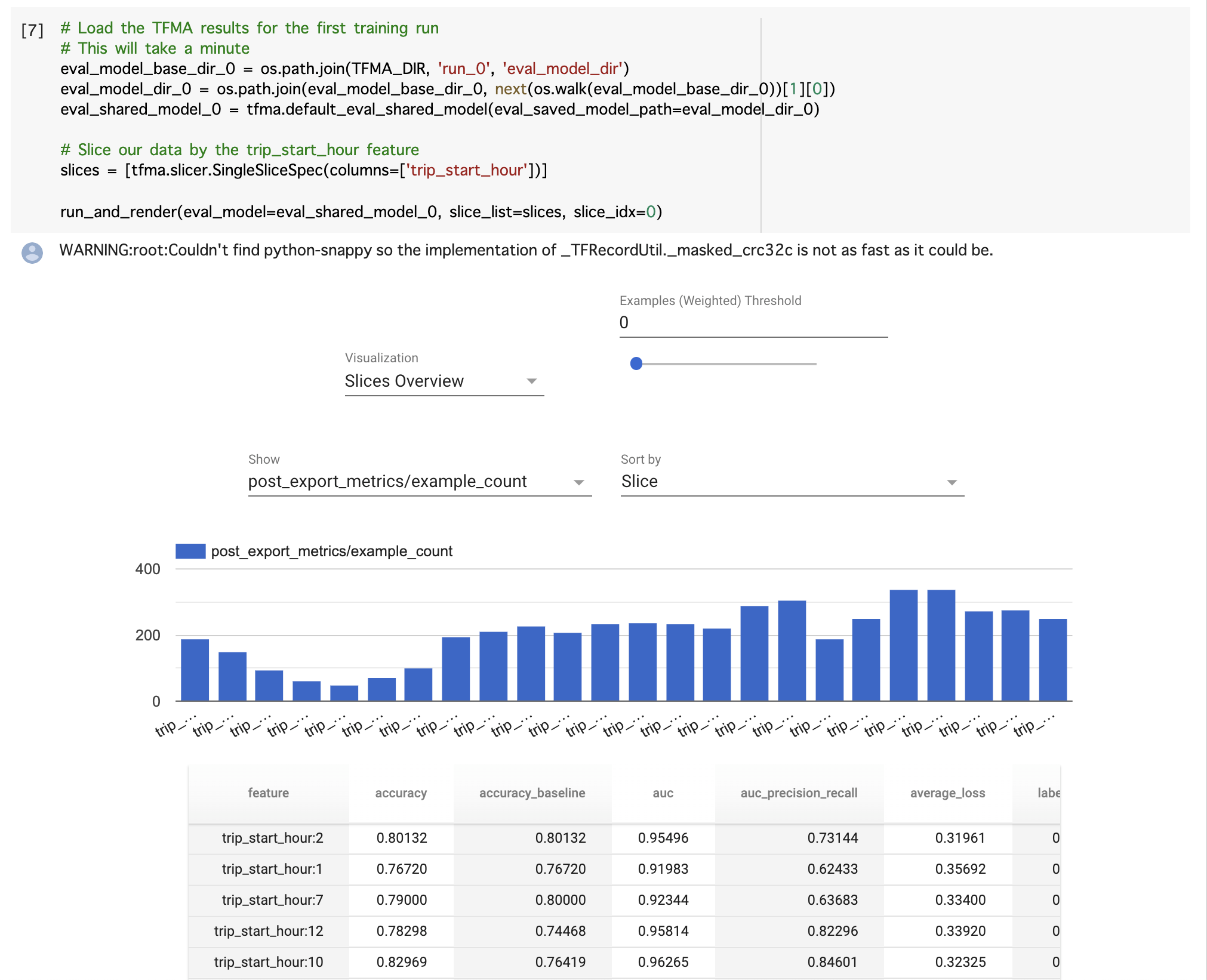
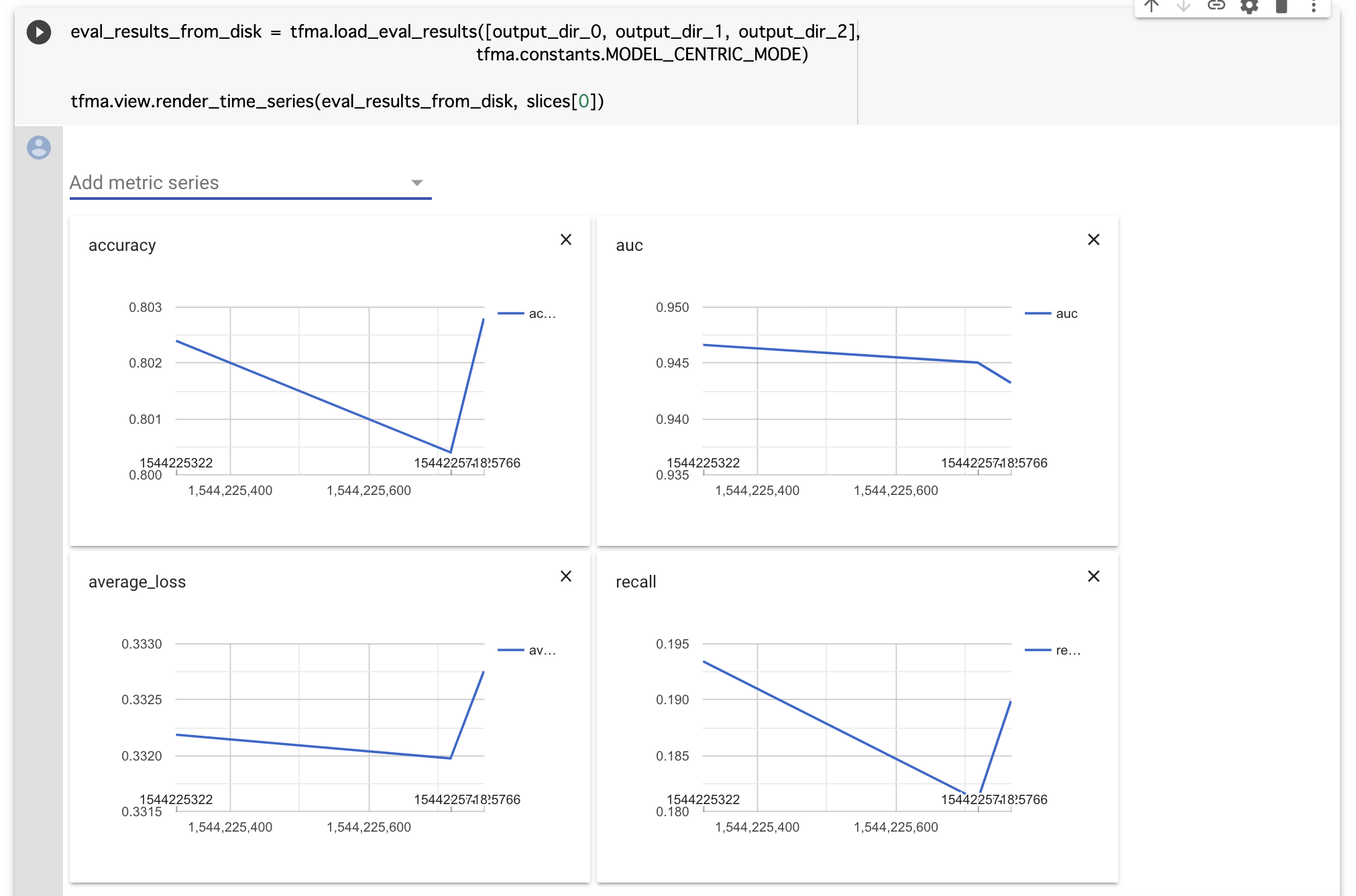
また、モデルに異なるデータセットを入力したときの精度の比較も可能です。これは例えば、機械学習モデルの精度を日毎に比較したい場合に役立つでしょう。
TensorFlow Metadata (TFMD)
TensorFlow Metadata (TFMD) はこれまでに見てきた TFX の各ライブラリで用いるためのメタデータを提供します。
ML Metadata (MLMD)
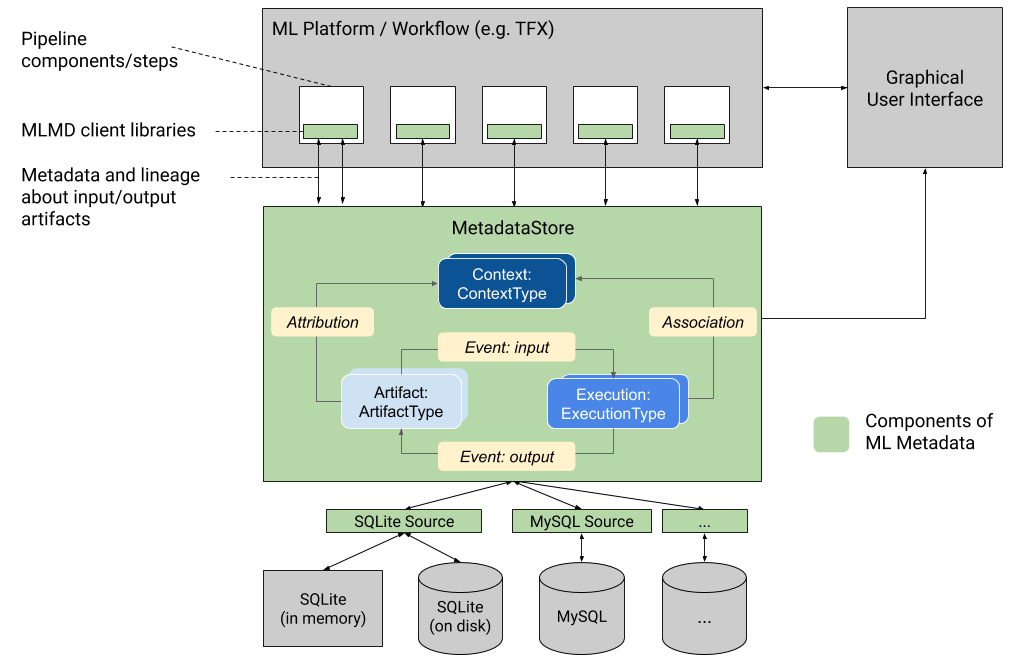
ML Metadata (MLMD) は TFX のコンポーネントが入出力を行うためのメタデータストアを提供します。SQLite または MySQL をバックエンドとして、メタデータの管理を行います。
MLMD は次の3つの役割を持ちます。
- 機械学習パイプラインの各コンポーネントの生成物に関するメタデータの保管
- 機械学習パイプラインの各コンポーネントの実行状態の保管
- 機械学習パイプラインそのものに関するメタデータの保管
MLMD により次の事柄が可能になります。
- 特定の型を持った Artifacts の一覧の取得
- 同じ型を持った Artifacts 同士の比較
- ある DAG に関連するすべての処理と入出力結果の表示
- ある出力結果に関連するすべてのイベントの取得
- ある入力から作成された出力結果の特定
- 過去に同一の入力に対する処理が実行されているかどうかの確認
- ワークフローが実行されるときのコンテキストの記録
TFX に関連するライブラリ利用者
TFX に関連する各種ライブラリの利用者についてはいくつかの企業が存在するようです。 TensorFlow Extended (TFX) Overview and Pre-training Workflow (TF Dev Summit '19) では次の企業が紹介されています。

- airbnb : TensorFlow Serving を利用している
- paypal : 詳細不明
- Twitter : モデルの解釈のために TFMA を利用している
他にも、Spotify は彼らのリポジトリの中で spotify-tensorflow/spotify_tensorflow/tfx として TFX のライブラリに関するサンプルコードを提供しています。
また、 merpay が利用しているとの話も聞いたことがありますが、こちらはどうやら公開されている情報はないようです。
TFX に関する現状の課題
最後に、TFX に関する現状の課題についていくつか見ていきましょう。
設計思想としての TFX
TFX の設計思想については、設計に活かしやすいように思います。実際、最近の機械学習のデザインパターンに関する調査でも、TFX の設計思想と共通するものがいくつか見られます。

フレームワークとしての TFX
TFX と関連するライブラリは現在アクティブに開発が進んでいるもののため、アップデートが頻繁に行われているほか、ドキュメントとコードの整合性も保たれていない状態です。現状では機械学習パイプラインの運用を TFX を用いて行うのは相当な覚悟と努力4が必要とされるでしょう。
TFX の提供するライブラリ群
TFX の提供するライブラリ群については確かに魅力的なものも多いため、既存のパイプラインに追加で組み込み、運用上で監視やトラブルシュートに用いることは可能だと考えます。
ただし、すべてのライブラリはまだアクティブに開発中であるため、プロダクションへの一連のデータの流れを止めないような配慮は必要でしょう。例えば、データの流れをフォークして、データやモデルの学習結果の検証用のコンポーネントを、サービスには影響を与えない形で実行するのが望ましいでしょう。
最後に
TFX は機械学習パイプラインについてのエンドツーエンドなプラットフォームを提供するという野心的なプロジェクトであり、筆者が最も注目しているプロジェクトの一つでもあります (もう一つは Swift for TensorFlow) 。また、 Fairness での取り組みが取り込まれつつあるという開発速度の早さも魅力の一つです。
機械学習パイプラインのベストプラクティスについて多大な示唆を与えてくれるため、個人的には今後も継続してキャッチアップを続ける価値があるプロジェクトだと考えます。
-
フレームワークなんですが PyPI からインストールできるのでモジュールとしています ↩
-
TFX version 0.15 から ↩
-
TFX 0.14 を前提に書いているので現在では異なる書き方が必要でしょう ↩
-
例えば、この記事を書くためにチュートリアルを改めて実行しましたがうまく動かなかったため、修正のPRを作成しました。 このようにサンプルコードが動かなかったりドキュメントがなかったりすることは現状では日常茶飯事です。 ↩