はじめに
Elixir で画像を複数ノードで分散処理してみます
※同一マシン上で別ノードを起動します。別マシンで起動する場合はまた別途
この記事は @zacky1972 さんが ElixirConf US 2022 で発表した内容の一部を Livebook 上で実行したものです
ElixirConf US 2022 の @zacky1972 さんの発表動画はこちら
参考にした @zacky1972 さんの Gist はこちら
実行したノートブックはこちら
https://github.com/RyoWakabayashi/elixir-learning/blob/main/livebooks/distributed_image_processing/distributed_main.livemd
https://github.com/RyoWakabayashi/elixir-learning/blob/main/livebooks/distributed_image_processing/distributed_worker_1.livemd
https://github.com/RyoWakabayashi/elixir-learning/blob/main/livebooks/distributed_image_processing/distributed_worker_2.livemd
https://github.com/RyoWakabayashi/elixir-learning/blob/main/livebooks/distributed_image_processing/distributed_worker_3.livemd
https://github.com/RyoWakabayashi/elixir-learning/blob/main/livebooks/distributed_image_processing/distributed_worker_4.livemd
前回記事の画像分割、並列画像処理はこちら
実行環境
以下のリポジトリーのコンテナ上で実行しています
Livebook におけるノード
Livebook では実行しているノートブック毎に別ノードが起動されています
Livebook の左メニュー、 IC チップらしきアイコンをクリックすると、 Node name の項目で現在のノートブックのノード名が確認できます

今回は分散処理を呼び出すメインと、分散処理を実行するワーカー 1 〜 4 のノートブックをそれぞれ実行します
メインの準備
ノートブックを起動して、以下のコードを実行してセットアップします
Mix.install(
[
{:download, "~> 0.0.4"},
{:evision, "~> 0.1"},
{:kino, "~> 0.7"},
{:nx, "~> 0.4"},
{:flow, "~> 1.2"},
{:benchee, "~> 1.1"}
],
system_env: [
{"EVISION_PRECOMPILED_CACHE_DIR", "/tmp/.cache"}
]
)
セットアップ対象
- download: データダウンロード
- evision: 画像処理
- kino: 出力可視化
- nx: 行列演算
- flow: 並列処理
- benchee: ベンチマーク
環境変数 EVISION_PRECOMPILED_CACHE_DIR を指定することで、メインと各ワーカーで Evision のキャッシュを使いまわします
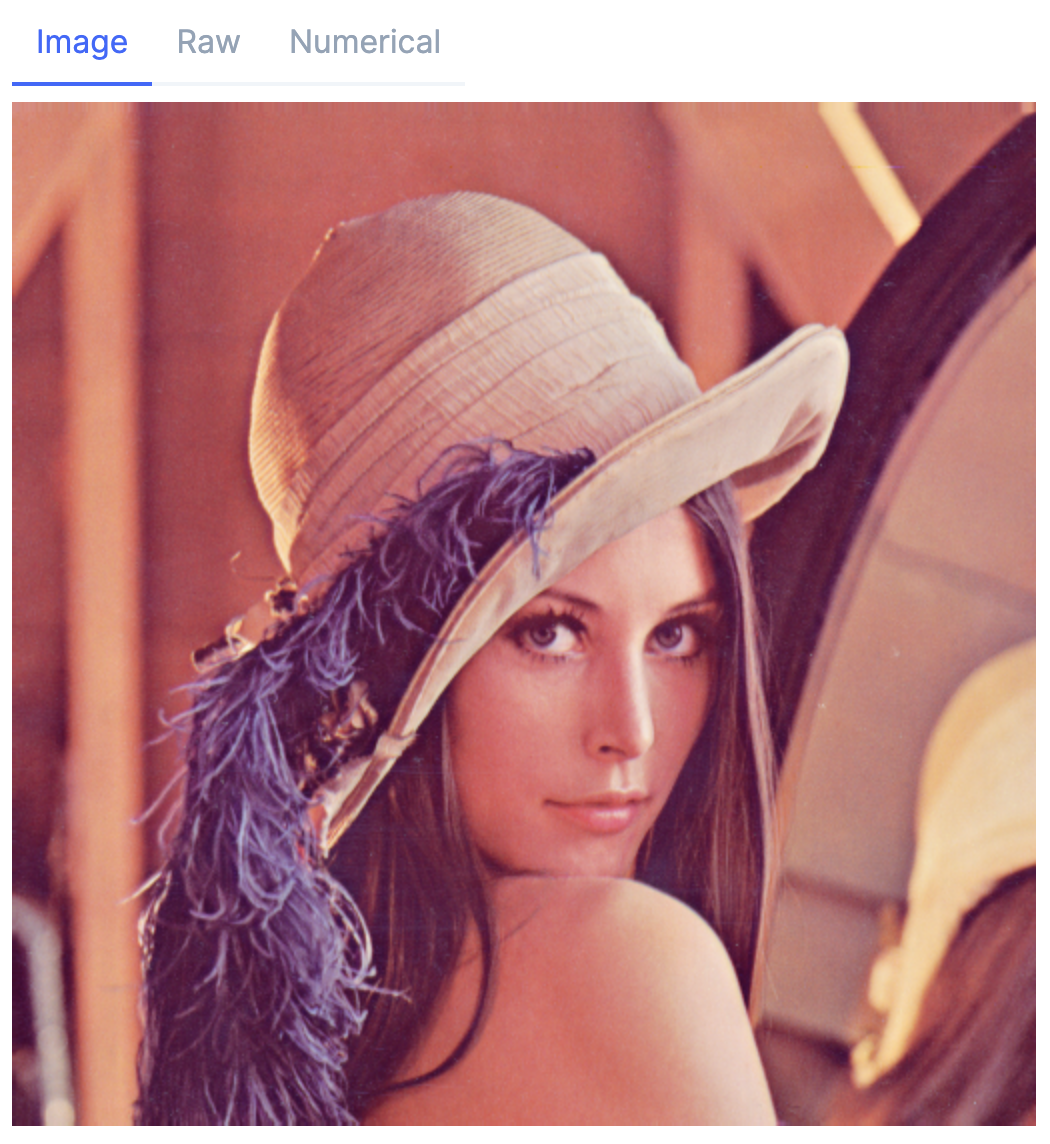
画像ダウンロード
処理する画像をダウンロードしてきます
# 再実行時、Download.from()でeexistエラーになるのを防止
File.rm("Lenna_%28test_image%29.png")
lenna =
Download.from("https://upload.wikimedia.org/wikipedia/en/7/7d/Lenna_%28test_image%29.png")
|> elem(1)
画像を読み込みます
mat = Evision.imread(lenna)
処理内容
分散処理の内容を個別に実行してみます
まず、分散処理ではメインと各ワーカーの間でデータを送受信するため、 Evision のマトリックスからバイナリに変換する必要があります
また、ワーカー上で Evision のマトリックスに戻すため、元の型と形も送受信します
img = Evision.Mat.to_nx(mat)
type = Nx.type(img)
shape = Nx.shape(img)
binary = Nx.to_binary(img)
今回は閾値処理と、文字の描画を行います
分散処理実行時間、どのノードで実行されたのか分かりやすいよう、ノード名を描画するようにしています
dst_binary =
binary
# バイナリからマトリックスに変換
|> Nx.from_binary(type)
|> Nx.reshape(shape)
|> Evision.Mat.from_nx_2d()
# 閾値処理
# image processing
|> Evision.threshold(127, 255, Evision.Constant.cv_THRESH_BINARY())
|> elem(1)
# 文字を描画
|> Evision.putText(
# 自分のノード名
Node.self() |> Atom.to_string(),
# 描画位置
{10, 30},
# フォント
Evision.Constant.cv_FONT_HERSHEY_SIMPLEX(),
# 文字サイズ
1.0,
# 文字色
{0, 0, 0},
# 文字の太さ
[{:thickness, 2}]
)
# マトリックスからバイナリに変換
|> Evision.Mat.to_nx()
|> Nx.to_binary()
|> dbg()

ワーカーから返ってきたバイナリを Evision のマトリックスに変換して表示します
dst_img =
dst_binary
|> Nx.from_binary(type)
|> Nx.reshape(shape)
|> Evision.Mat.from_nx_2d()

今回はノートブック内で実行しているので、自分のノード名が描画されています
ノード接続確認
ノートブック間で接続できることを確認します
現在の接続ノードを確認します
Node.list(:connected)

メインのノートブックは Livebook 本体のノードだけに接続されています
新しくノートブックを起動し、以下のコードでセットアップします
※以降、コードブロックの上に「★○○」の形でどのノートブック用のコードなのかを示します
★ワーカー1
Mix.install(
[
{:evision, "~> 0.1"},
{:kino, "~> 0.7"},
{:nx, "~> 0.4"},
{:flow, "~> 1.2"}
],
system_env: [
{"EVISION_PRECOMPILED_CACHE_DIR", "/tmp/.cache"}
]
)
ワーカーのノード名を取得します
★ワーカー1
Node.self()

メインノートブックにワーカーノートブックのノード名用入力エリアを用意し、ワーカー1のノード名を入力します
★メイン
worker_1_input = Kino.Input.text("WORKER_1_NODE_NAME")

文字列のままだと使いにくいので、 atom に変換しておきます
★メイン
worker_1_atom =
worker_1_input
|> Kino.Input.read()
|> String.to_atom()

ワーカー1に接続します
★メイン
Node.connect(worker_1_atom)
true が返ってくれば接続成功です

現在の接続ノードを確認します
★メイン
Node.list(:connected)

Livebook 本体のノードに加えて、ワーカー1のノードにも接続できていることが確認できます
後で改めて接続するので、一旦接続解除しておきます
★メイン
Node.disconnect(worker_1_atom)
★メイン
Node.list(:connected)
画像のコピー
複数画像を分散して処理するため、画像を32枚コピーしておきます
src_file_ext = Path.extname(lenna)
src_file_basename = Path.basename(lenna, src_file_ext)
src_files =
Stream.unfold(0, fn counter -> {counter, counter + 1} end)
|> Stream.map(&"#{src_file_basename}_#{&1}#{src_file_ext}")
# コピー枚数
copy_count = 32
src_file_paths =
mat
|> List.duplicate(copy_count)
|> Enum.zip(src_files)
|> Enum.map(fn {img, dst_file} ->
Evision.imwrite(dst_file, img)
dst_file
end)

処理の定義
分散処理するモジュールを定義します
distribute にワーカーと画像の一覧を渡すと、各ワーカーに元画像をバイナリに変換して送信します
各ワーカーが process_image でバイナリをマトリックスに変換し、画像処理を実行します
画像処理後のマトリックスを再びバイナリに変換してワーカーがメインに返します
メインは受信したバイナリをマトリックスに変換し、画像ファイルに保存します
このモジュールは全ノード共通なので、メイン、ワーカー1の両方で同じものを実行しておきます
★メイン、ワーカー1
defmodule DistributedImageProcessing do
def distribute(workers, images_stream) do
# ワーカーノードに接続する
Enum.each(workers, &Node.connect/1)
# worker_stream is generated repeatedly
worker_stream =
Stream.repeatedly(fn -> workers end)
|> Stream.flat_map(& &1)
sender_pid = self()
worker_stream
|> Stream.zip(images_stream)
|> Flow.from_enumerable(stages: 4, max_demand: 1)
|> Flow.map(fn {worker, image} ->
IO.puts("enter spawn_link")
{
Node.spawn_link(worker, fn ->
# worker receives an image from main
receive do
{:img, sender_pid, img} ->
# call process_image
{dst_file, img} = process_image(img)
# An image should be converted into binary, shape and type before sending.
binary = Nx.to_binary(img)
shape = Nx.shape(img)
type = Nx.type(img)
send(sender_pid, {dst_file, type, shape, binary})
IO.puts("respond")
end
end),
image
}
end)
|> Flow.map(fn {pid, src_file} ->
IO.puts("enter reader")
img =
src_file
|> Evision.imread()
|> Evision.Mat.to_nx()
# An image should be converted into binary, shape and type before sending.
binary = Nx.to_binary(img)
shape = Nx.shape(img)
type = Nx.type(img)
send(pid, {:img, sender_pid, {src_file, type, shape, binary}})
end)
|> Enum.to_list()
|> Enum.map(fn _ ->
IO.puts("enter receiver")
receive do
{dst_file, type, shape, binary} ->
save_image({dst_file, type, shape, binary})
end
end)
|> Enum.to_list()
end
def process_image({src_file, type, shape, binary}) do
IO.puts("enter processor")
# file name conversion
src_file_ext = Path.extname(src_file)
src_file_basename = Path.basename(src_file, src_file_ext)
dst_file = "#{src_file_basename}_d#{src_file_ext}"
dst_img =
binary
# reconstruction of an image
|> Nx.from_binary(type)
|> Nx.reshape(shape)
|> Evision.Mat.from_nx_2d()
# image processing
|> Evision.threshold(127, 255, Evision.Constant.cv_THRESH_BINARY())
|> elem(1)
|> Evision.putText(
Node.self() |> Atom.to_string(),
{10, 30},
Evision.Constant.cv_FONT_HERSHEY_SIMPLEX(),
1.0,
{0, 0, 0},
[{:thickness, 2}]
)
|> Evision.Mat.to_nx()
{dst_file, dst_img}
end
def save_image({dst_file, type, shape, binary}) do
img =
binary
|> Nx.from_binary(type)
|> Nx.reshape(shape)
|> Evision.Mat.from_nx_2d()
Evision.imwrite(dst_file, img)
dst_file
end
end
自身のノードで1つだけ実行
メインのノートブックで直接画像処理だけ実行してみます
★メイン
{lenna, type, shape, binary}
|> DistributedImageProcessing.process_image()
|> then(fn {dst_file, dst_img} ->
{dst_file, Nx.type(dst_img), Nx.shape(dst_img), Nx.to_binary(dst_img)}
end)
|> DistributedImageProcessing.save_image()
|> Evision.imread()
|> dbg()

きちんと処理できています
ワーカーノード1つで1枚だけ実行
ワーカー1で1枚だけ処理してみましょう
★メイン
[worker_1_atom]
|> DistributedImageProcessing.distribute([lenna])
|> Enum.at(0)
|> Evision.imread()

ワーカー1のノード名が描画されており、確かにメインではなくワーカー1で画像処理が実行されています
ワーカーノード1つで32枚実行
ではコピーした32枚の画像に対して実行してみましょう
まず対象画像の一覧を取得します
★メイン
# 存在するファイルを取得
images_stream =
Stream.unfold(0, fn counter -> {counter, counter + 1} end)
|> Stream.map(&"#{src_file_basename}_#{&1}#{src_file_ext}")
|> Stream.take_while(fn filename -> File.exists?(filename) end)
実行して、先頭3件の実行結果を見てみましょう
★メイン
[worker_1_atom]
|> DistributedImageProcessing.distribute(images_stream)
|> Enum.slice(0..5)
|> Enum.map(fn dst_filename ->
dst_filename
|> Evision.imread()
|> Kino.render()
end)

3枚とも処理されていますね
ワーカーノード4つで分散処理
3つ新しくノートブックを起動し、ワーカー1と同じ内容を実行します
★ワーカー2、3、4
Mix.install(
[
{:evision, "~> 0.1"},
{:kino, "~> 0.7"},
{:nx, "~> 0.4"},
{:flow, "~> 1.2"}
],
system_env: [
{"EVISION_PRECOMPILED_CACHE_DIR", "/tmp/.cache"}
]
)
★ワーカー2、3、4
Node.self()
★ワーカー2、3、4
defmodule DistributedImageProcessing do
...
省略
...
end
メインでそれぞれのノード名を入力します
★メイン
worker_2_input = Kino.Input.text("WORKER_2_NODE_NAME")
★メイン
worker_3_input = Kino.Input.text("WORKER_3_NODE_NAME")
★メイン
worker_4_input = Kino.Input.text("WORKER_4_NODE_NAME")

ワーカー1〜4のノード名を atom にします
★メイン
workers =
[worker_1_input, worker_2_input, worker_3_input, worker_4_input]
|> Enum.map(fn input ->
input
|> Kino.Input.read()
|> String.to_atom()
end)
ワーカー1〜4で32枚の画像を処理します
★メイン
workers
|> DistributedImageProcessing.distribute(images_stream)
|> Enum.slice(0..5)
|> Enum.map(fn dst_filename ->
dst_filename
|> Evision.imread()
|> Kino.render()
end)

それぞれ異なるノード名が描画されました
速度比較
せっかくなので、ノード数による速度比較をしてみましょう
速度比較用の関数を用意します
★メイン
distributed = fn worker_input_list ->
worker_input_list
|> Enum.map(fn input ->
input
|> Kino.Input.read()
|> String.to_atom()
end)
|> DistributedImageProcessing.distribute(images_stream)
end
Benchee で速度比較を実行します
★メイン
Benchee.run(%{
"1 worker" => fn -> distributed.([worker_1_input]) end,
"2 workers" => fn -> distributed.([worker_1_input, worker_2_input]) end,
"4 workers" => fn -> distributed.([worker_1_input, worker_2_input, worker_3_input, worker_4_input]) end
})
実行結果は以下のようになりました
Name ips average deviation median 99th %
4 workers 1.78 561.06 ms ±6.85% 554.79 ms 659.99 ms
2 workers 1.69 591.77 ms ±7.87% 574.77 ms 694.21 ms
1 worker 1.57 638.71 ms ±6.90% 632.23 ms 717.61 ms
Comparison:
4 workers 1.78
2 workers 1.69 - 1.05x slower +30.71 ms
1 worker 1.57 - 1.14x slower +77.65 ms
実態は同じ1台のマシンの中なのでそんなに速くはなりませんが、4ワーカーが最も速くなりました
まとめ
Livebook でも各ノートブックをノードとして接続することで、分散処理が実行できました
次は複数台のマシンで Livebook を起動して分散させてみましょう