はじめに
Explorer は Elixir でデータ分析をするためのモジュールです
Python でいうところの pandas、 R でいうところの tidyverse に当たります
私も今までにいくつか記事を書いています
2023/01/13 に Explorer の v0.5.0 がリリースされました
その中に DataFrame.describe の追加があり、これが非常に便利なので記事に残しておきます
実装したノートブックはこちら
Livebook での実行
pandas の describe と同じ機能です
データフレームの各列について、以下の基本統計量を返してくれます
実際に Livebook で使ってみましょう
セットアップ
Explorer と Kino をインストールします
Mix.install([
{:explorer, "~> 0.5"},
{:kino, "~> 0.8"}
])
エイリアスを付けておきます
alias Explorer.DataFrame
alias Explorer.Datasets
alias Explorer.Series
データの準備
ワインデータセットを使います
wine_df = Datasets.wine()
Kino.DataTable.new(wine_df)

178 本のワインについて、それぞれの種類(class)と各種成分を持っています
describe の実行
データセットに対して describe を実行してみます
wine_df
|> DataFrame.describe()
|> Kino.DataTable.new()
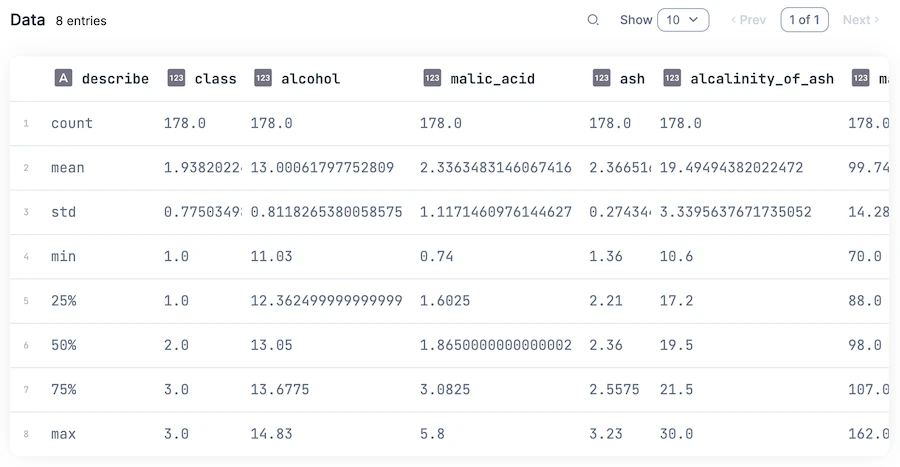
各列毎に基本統計量が表示できました
データの性質をザックリ把握したいときに非常に便利です
パーセンタイルの指定
パーセンタイルについては任意の位置を指定できます
wine_df
|> DataFrame.describe(percentiles: [0.33, 0.66])
|> Kino.DataTable.new()
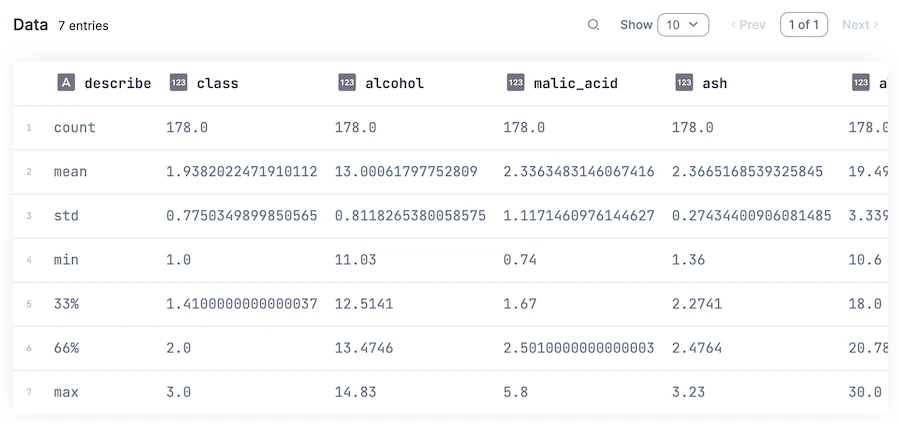
文字列の扱い
文字列に対してはどうなるか見たいので、別のデータセットを使います
fuels_df = Datasets.fossil_fuels()
Kino.DataTable.new(fuels_df)
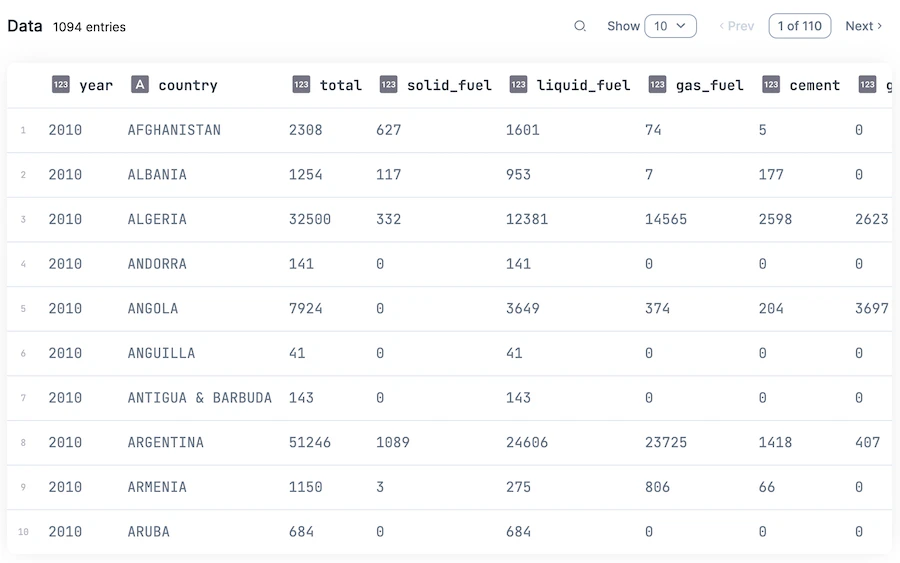
年毎、国毎の化石燃料由来 CO2 排出量のデータセットです
これに対して describe を実行します
fuels_df
|> DataFrame.describe()
|> Kino.DataTable.new()
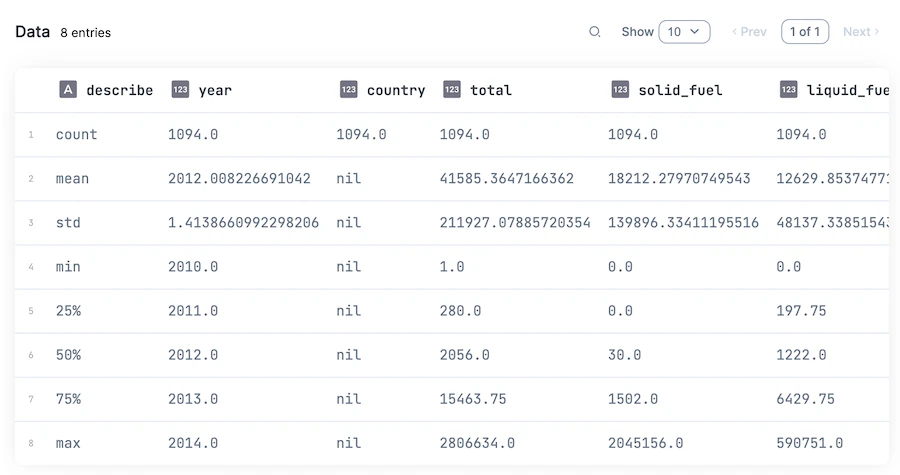
文字列型の country は件数以外 nil になりました
まとめ
簡単に基本統計量を表示できるので、最初にデータのおおよその傾向を見るときに便利ですね